
移动智能终端人工智能芯片算力评测方法
2022-06-08 07:09:52庞涛沙通崔思静杨婷婷
移动通信 2022年5期
庞涛,沙通,崔思静,杨婷婷
(中国电信股份有限公司研究院,广东 广州 510630)
0 引言
人工智能的三大要素是算力、数据与算法。互联网与移动通信的结合产生了海量的数据,深度神经网络的快速发展推动着算法精度的不算提升,英伟达GPU、谷歌TPU 等高性能硬件的大规模产业化解决了云端算力问题[1,20]。但是,移动终端设备在实际运行中会受到传输时延、功耗、成本、安全性等各项制约因素的影响,其中,算力尤其是单位能耗可提供的算力是制约移动智能终端AI 能力的主要因素[2]。
近年来,移动终端的人工智能计算能力呈现出大幅增长的态势,移动芯片制造厂商推出的中高端手机芯片都提供了深度神经网络模型的加速计算能力。业界也随之出现了针对端侧人工智能加速计算的各种评测方法和工具[3],本文接下来将针对移动智能终端的AI 芯片算力及其评测方法展开研究。
1 端侧AI加速技术及评测工具
2010 年之前,手机终端仅能提供600 MHz 左右的单核CPU 及百兆内存资源用于运行简化版的机器学习模型;2010 年之后,移动终端上开始配置多核处理器CPU、GPU;2017 年,苹果、华为海思、高通、联发科等芯片厂商陆续推出NPU、AIP 和APU 等适合机器学习和深度学习任务的专用AI 加速硬件单元[4-6],越来越多的AI 应用在移动终端上落地。
在深度学习模型中,计算量最大的算子是卷积,而卷积的本质是矩阵的乘加计算(MAC)。在基于深度学习的AI 应用中,95% 以上的运算为MAC,因此现阶段移动智能终端上大量的软硬件优化方案均是用来加速这部分运算[19]。硬件层面,芯片内置专用的神经网络运算单元对神经网络中的矩阵运算进行加速,例如,华为手机配置的海思麒麟820、990 等芯片内置了NPU;苹果A13、A14 等系列芯片搭载了Neural Engine。软件方面,需要通过SDK 运行移动终端上所支持的机器学习框架[5],调度CPU、GPU、DSP 及其他加速计算单元。其中,端侧框架包括操作系统上层的AI 加速运行时(Runtime)、AI 加速能力API、AI 算法模型和AI应用能力接口等。除了芯片厂商提供的专有机器学习框架,众多互联网企业也推出了各自的移动端深度框架,例如谷歌TensorFlow Lite、百度Paddle Lite 等框架。
当前业界已有众多移动智能终端的AI 能力评测工具,能够对手机、平板等移动智能终端进行不同场景下的运算精度和速度的评测,主流的评测工具包括AIbenchmark[4-5]、MLPerf[8]、DNN Benchmark、AIT 以及一些商业评测软件,例如鲁大师的AImark、安兔兔AI 评测等。其中,AIT(AI Testing)是由中国电信研究院研发的一款AI 芯片评测工具,通过该工具我们定期跟踪评测最新款手机终端芯片的AI 能力,相关评测结果在每年度的中国电信终端洞察报告中发布。AIT 的评测项目包含了图像分类、图像识别、图像分割和超分等模型,并从模型推断的性能、能耗和耐久模式出发,对芯片的AI 能力进行综合评估。接下来本文重点研究的AI 芯片算力评测方法已在AIT 上实现,文中实验数据均来源于AIT 评测。
2 AI算力评测方法研究
2.1 算力的定义
算力是指硬件设备的计算能力,业界一般采用每秒操作数量(OPS,Operations Per Second)作为衡量硬件算力水平的一个性能指标[18]。特别地,针对浮点计算领域,常用每秒浮点运算次数(FLOPS,Floating-Point Operations Per Second)来衡量硬件执行浮点计算的速度。业界往往用计算单元的理论值来标称AI 芯片的算力,但在实际应用中,硬件所能表现的算力水平受到数据量、吞吐量等诸多因素的影响,表现出来的算力水平距离理论值差距较大,故需要研究一种标准化、可复现的算力评估方法,用其评测AI 芯片时能够尽量接近理论算力。
文中使用OPS 作为浮点和整型计算算力的统一度量单位,通常一次MAC 运算可看作是两次深度学习的运算操作。
(1)在不考虑能耗的情况下,移动终端进行AI 运算所能表现的峰值算力计算公式如下:

其中OPs为操作数量,Tinf为推断时间,MACs 为乘加运算次数。
(2)在考虑移动终端单位能耗下的算力水平时,单位能效算力计算公式如下:

其中OPs为操作数量,Tinf为推断时间,W推断时间内的功率消耗。
2.2 模型与算力的关系研究
(1)模型及其理论运算数量
模型的MACs 或OPs 由其本身的结构确定,通常用作模型复杂度的一种描述。在不考虑激活函数运算的情况下,一个包含偏置(bias)的卷积层的MACs 可通过下述公式确定:

其中Ci为输入通道数,C0为输出通道数,K为卷积核大小,H和W分别为输出特征图的长和宽。
而同样在不考虑激活函数运算的情况下,一个包含偏置(bias)的全连接层的MACs值为:

其中I为输入神经元总数,O为输出神经元数量。
为验证MACs 和算力表现的关系,我们在PC 端CPU上进行了测试,在参数量和MACs 都相同的情况下,三层全连接模型和三层核大小为1×1 的卷积模型体现出的CPU 算力几乎没有差别,测得全连接模型算力大小为247.25 GOPS,卷积模型算力为247.86 GOPS。最大池化层中本身不含乘加运算,在计算OPs 的时候忽略其内部的操作数。因此,在算力评测时主要利用卷积计算进行算力评估是合适的。
(2)不同模型的算力表现
为验证不同模型对算力的影响,我们选择移动端常见的三个图像分类模型在手机终端运行,对比其各自表现出来的算力水平,模型的MACs 数量见表1:

表1 MobileNet、ResNet50和VGG16等模型的MACs
使用AIT 评测软件分别运行在装备AI 芯片的五款手机终端上,分别测试MobileNet_V2、ResNet50、VGG16和19 剪裁后三层的模型,对比不同模型运行在不同终端上的芯片算力表现,结果如图1 所示:
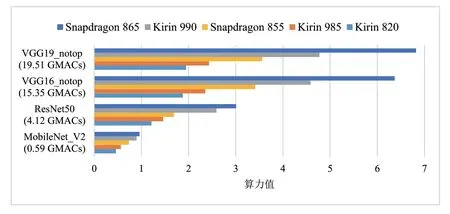
图1 芯片在INT8模型上的算力测试结果
图中纵坐标是不同的DNN 模型(标注了MAC 数量),横坐标是测出的算力值,每种颜色代表一款手机跑出的AI 算力,单位TOPs/s(TOPS),从测试结果看出,MACs 越多的模型,表现出的算力值越高。因此在手机端尽管当前的应用趋势是模型轻量化,但是从测试的角度,要想充分展示出加速计算硬件的理论性能,还需要重载模型的加持。
(3)定制化VGG 模型的算力表现
1)VGG 模型剪裁
图1 中的VGG_notop 指的是裁剪掉最后三个全连接层和损失层(Softmax)后的VGG16 或VGG19,去掉全连接层的VGG_notop 模型结构主要出于以下因素的考虑。其一,现如今三个全连接层接在CNN 末端已不是常见的结构设计,如图2 所示,位于VGGNet[9]模型末端的三个全连接层主要起到的是特征融合和特征降维的作用,在卷积神经网络发展初期,这种设计是常见的。
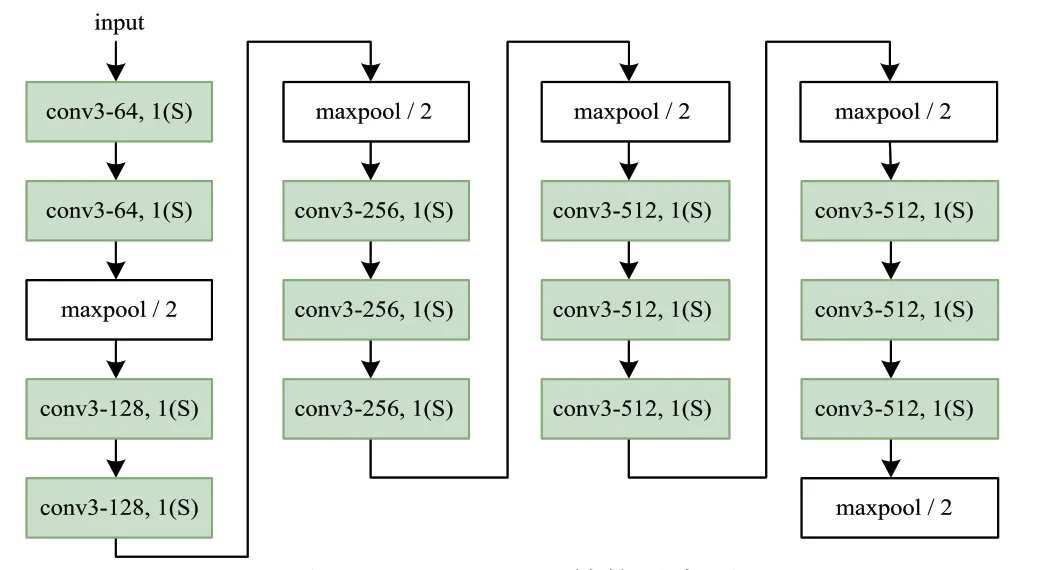
图2 VGG16_notop结构示意图
然而,多层的全连接层易使模型本身结构变得臃肿,在VGG19 中全连接层参数占到了模型参数总量的86%,在VGG16 中该占比达到了89%。2014 年,参考文献[13] 中提出了使用全局平均池化层(GAP,Global Average Pooling)替代全连接层的做法,GAP在降维的同时极大地减少了网络参数,且保留了特征中部分空间信息,起到防止过拟合的作用。随后,一层GAP 后接一层全连接层(或一到两个核大小为1×1的卷积层)做进一步特征降维被业界普遍应用,在InceptionNet[14-16]和MobileNet[10,17]等模型中,都可以看到这种结构设计。
同时,对于移动端有限的存储和运算能力来说,VGG_notop 的模型大小和其纯卷积层的结构都更加友好和实用。我们使用AIT 测试软件同样运行在5 款手机上,对标准VGG 模型和裁剪后的VGG_notop 模型的算力进行了实验对比,根据图3 的测试结果可以看到,无论哪一款终端,VGG_notop 模型由于其更精简的结构,在算力测试中都更好地展现了芯片的计算能力。因此,出于对模型参数量和实际应用的考虑,在移动终端算力评测中所考虑的VGGNet 模型是裁剪掉全连接层和Softmax层的VGG_notop。
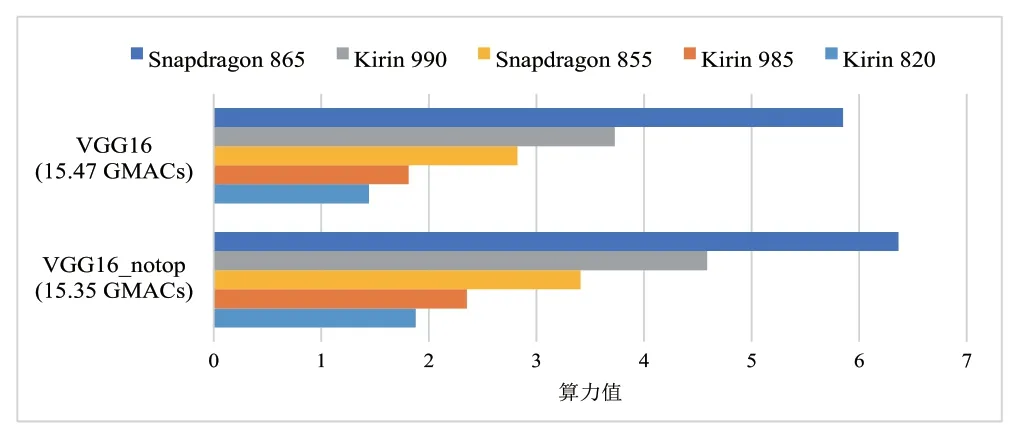
图3 INT8模型VGG16与VGG16_notop的算力对比
2)不同卷积核对算力的影响
在实际情况下,不同芯片的计算单元处理能力会存在差异。我们的研究方案是用一组MAC 值不同的模型进行算力测试,选取其中测得的算力峰值来作为芯片能力的表现。这要求所使用的一组模型拥有相似的结构和参数分布,且尽量不因结构变化而增加I/O。
遵循上述思路,我们采用了一组定制化的VGG_notop模型组,组内模型沿用了VGG16_notop 和VGG19_notop的层次结构,但每个模型的卷积核大小各异。为了区分不同卷积核尺寸采用简写表示,卷积层全采用3×3 核的VGG16_notop 模型,表示为VGG16_notop_conv3,其中为方便表示,将其简写为v16_notop_conv3,应用其它核大小的模型以此类推,VGG19_notop 模型同理。图4 为VGG16_notop_conv5 结构图。
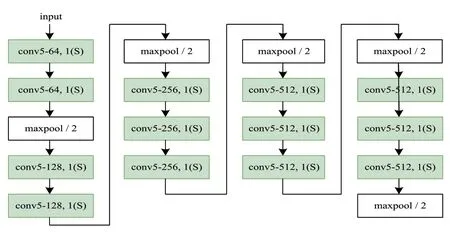
图4 VGG16_notop_conv5结构图
由此,该定制化VGG_notop_convk 模型组内共有10个MAC 值不同的模型,如表2 所示。为了简便,所有模型内的参数全部设置为0.001,即w=const(0.001)。
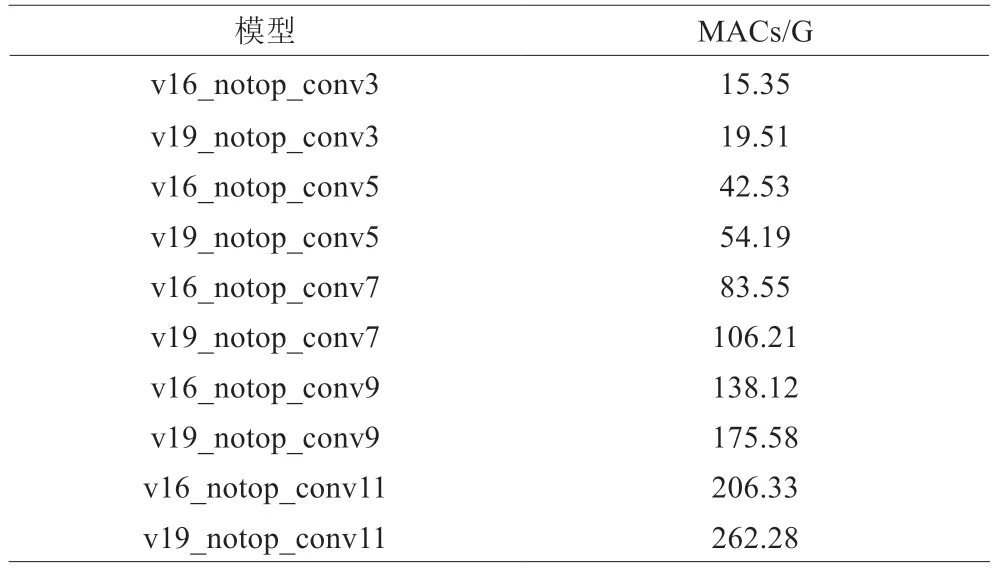
表2 VGG_notop_convk模型组的MACs
可以看出,随着卷积核的增大,模型的MAC 数量也同步增长。我们将这组模型分别在PC 端的CPU 上以及不同的手机终端芯片上进行了测试。对于PC 端的CPU 而言,由于CPU 没有对MAC 计算进行专门的加速处理,可能是由于内部IO 增加,CPU 的算力表现会随着卷积核的增大而逐步减少。
PC 端CPU VGG_notop FP32 算力对比如图5 所示:
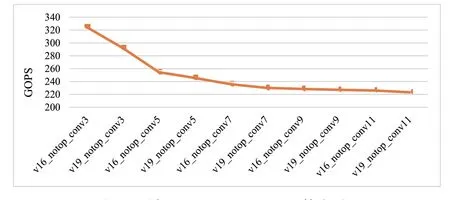
图5 PC端CPU VGG_notop FP32算力对比
而在移动终端上,由于各芯片厂商的AI 加速方案差异较大,因此我们实验对比的高通骁龙和海思麒麟的AI 加速芯片在不同卷积核下的算力表现趋势并不一致。高通的两款芯片骁龙855 和骁龙865,并不能很好地支持7×7 以上的卷积核,整体算力表现趋势大致与CPU 类似。
高通骁龙的芯片VGG_notop_conv 算力对比如图6 所示:
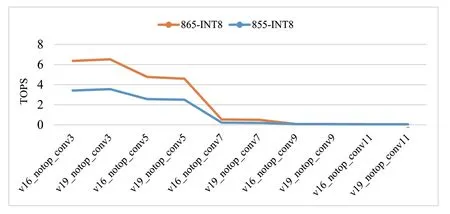
图6 高通骁龙的芯片VGG_notop_conv算力对比
麒麟990 芯片对于7×7 以上的卷积核都能运行,在MAC 值增加的情况下算力也能保持上升趋势,但上升态势渐趋平缓。
麒麟990 芯片INT8 与FP16 下VGG_notop_conv 算力对比如图7 所示:
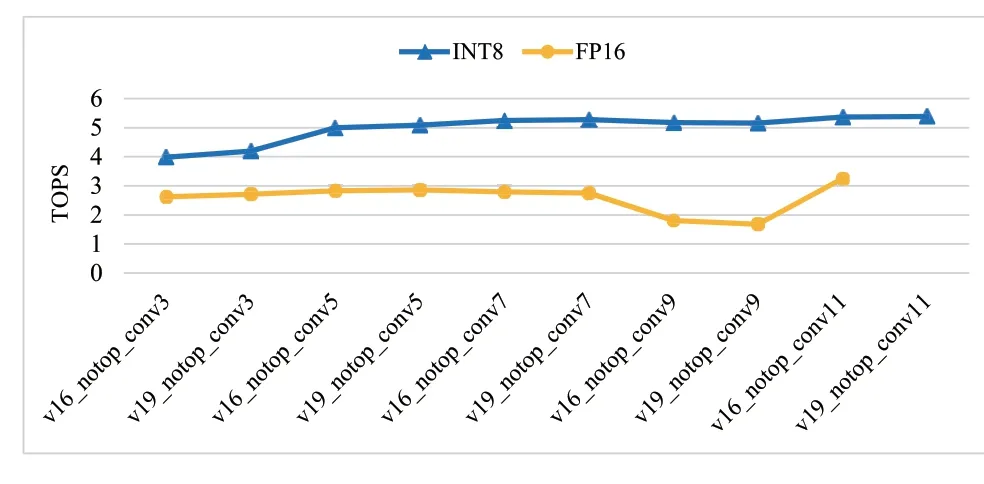
图7 麒麟990芯片INT8与FP16下VGG_notop_conv算力对比
从对比可见,各芯片厂商针对不同卷积计算的优化策略也不相同。当前采用7 对比以上卷积核的模型在移动端并不常见,出于模型通用性和测试一致性的考虑,采用上文所述的VGG_notop 作为基准算力评测模型是合适的。基于VGG_notop_convN(N=5,7,9,11……)的算力测试结果可作为参考,反映被测芯片的潜在算力峰值以及它对卷积核算子的支持程度。
(4)INT8 和FP16 的算力表现
相较于PC 端中常使用的FP64 或FP32 模型,在移动端部署的DNN 模型的参数一般需要压缩。FP16 和INT8是其常用的两种数据格式。
两种数据类型的DNN 模型在推断表现上有各自的优势。由于数据信息折损较少,FP16 浮点模型在准确率方面常有更好的推断表现。而INT8 模型则会有更快的推断速度,因此在算力表现上会更好。当然,将FP16 和INT8 两种模型直接进行算力比较并不可取,因为它们的性质不同且模型的准确率也不相同,图8 对比了三款芯片的FP16和INT8 算力表现,可以看出骁龙855 和865 芯片基本上没有浮点运算的加速能力(其浮点运算能力来自于CPU 和GPU),而麒麟990 二者兼有,这是由各家厂商对端侧AI芯片选择了不同的技术路线造成的。
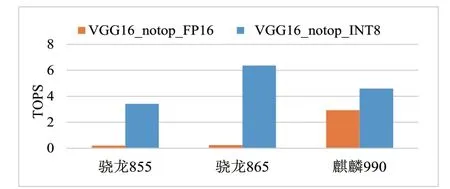
图8 FP16与INT8芯片算力对比
在实际应用中,模型数据类型的选择常取决于特定的任务以及设备功耗上的要求。对于高精度训练和推断的应用场景来说,浮点模型是更好的选择;而对于纯推断以及低功耗、低RAM 的设备,INT8 模型则更胜一筹。因此,在移动终端芯片的算力评测中,我们考虑的是两种数据类型的DNN 模型各自的算力表现。
3 AIT算力评测实践
3.1 评测方法
算力评测的过程主要测量的是VGG_notop 网络对一张图片做特征提取所需的时间,而后基于已知的模型MAC值,通过式(1)得到峰值算力结果。同时,为防止芯片一味追求高算力而忽略功耗,单位能耗算力将作为辅助指标,反映芯片在高计算量下的功耗性能。
在手机终端上运行AIT 软件进行算力评测,需要将预训练的32 位浮点DNN 模型量化为FP16 或INT8 DNN模型。采用VGG19_notop_INT8 和VGG19_notop_FP16进行算力评测,该模型实际上为ImageNet 图片集的特征提取器。模型的输入集为已经过预处理的1 000 张大小为224×224 的BGR 图片,输出集为相应的大小为7×7×512 的特征。图片的推断时间通过在模型输入、输出两端打点的方式得到。同时,为了检查芯片在跑分测试中可能发生的作弊行为,还需要考虑对VGG_notop 输出集进行校验。
3.2 实验数据
我们依据本文介绍的测试方法,评估了近两年主流手机终端配备的AI 芯片算力,INT8 和FP16 的算力表现如表3 所示。

表3 中高端AI手机芯片算力评测结果
从实验数据中可知,当代移动终端AI 芯片的算力水平提升迅速,在不考虑能耗限制时中高端芯片的算力差距较大,但是受限于移动终端的体积、电源等,中高端芯片的单位能效算力表现差距并不明显。在绝对算力日渐过剩的趋势下,提高单位能效算力是芯片厂商需要努力的方向。
4 结束语
经过以上分析和实验可以看出,当前AI 芯片主要是对卷积计算做了加速,算力评测以卷积运算的加速为主,因此,使用VGG_notop 来评估移动终端的算力是合适的,但是受限于上层数据的吞吐,评测结果距离厂商宣传的理论算力相差较大,如果要更加接近,需要厂商直接开放底层MAC 单元的输入输出接口直接针对特定硬件单元进行评测。
由于VGG_notop 模型经过剪裁,其输出已经不能简单地用图像分类结果,经过量化的模型与原始浮点模型在算力输出集验证也是必需的,合适的校验方法可以有效地识别芯片是否使用了如跳帧处理等不正当算力优化手段,针对这一问题,我们将在未来进一步开展研究和实验。
猜你喜欢
新华月报(2024年7期)2024-04-08 02:10:56
都市人(2023年11期)2024-01-12 05:55:06
卫星应用(2023年1期)2023-02-21 06:51:50
现代经济信息(2022年22期)2022-11-13 18:32:00
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26 14:09:30
家庭影院技术(2021年2期)2021-03-29 07:19:02
家庭影院技术(2021年1期)2021-03-19 05:14:58
数学小灵通(1-2年级)(2020年6期)2020-06-24 05:57:54
中国自行车(2018年11期)2018-12-03 08:20:30
中国自行车(2017年1期)2017-04-16 02:54:06
