
一种隐私保护的联邦学习框架*
2022-06-07 08:56:34杨东宁谢潇睿吉志坤姬维维
电子技术应用 2022年5期
杨东宁,谢潇睿,吉志坤,姬维维
(1.云南电网有限责任公司 信息中心,云南 昆明 650011;2.西南林业大学 大数据与智能工程学院,云南 昆明 650224;3.云南云电同方科技有限公司,云南 昆明 650220)
0 引言
大数据时代,数据的安全性和隐私性受到了越来越多的重视和关注[1]。欧盟及我国都分别相继通过了《一般数据法案》《欧洲数据保护通用条例》《中华人民共和国网络安全法》等相关法案,以保护数据的安全和隐私。
南方电网公司“十四五”数字化规划明确提出:电力智慧投资将以项目储备库为基础,通过输入约束条件和投资分配参数,并结合规划部门的配网规划数据、基建部门的基建结算数据和财务部门的财务数据,运用机器学习训练生成的投资预测模型,自动生成投资计划项目及费用估算建议。但是,目前的电力投资系统依赖集中式的方式训练模型,要求训练涉及的多方数据和训练过程必须在数据中心。在此过程中,各部门自有数据中的隐私信息可能会被泄露。此外,各部门出于数据安全和隐私保护的需求,不可能将自有数据上传到数据中心。因此,如何在确保各方数据安全和隐私的情况下打破数据孤岛、共同训练模型,成为了急需解决的挑战。
联邦学习使得机器学习或深度学习算法能从不同组织或部门的大量数据中获得更好的经验[2]。这种技术允许多个组织或部门在数据不直接共享的情况下协作完成模型的联合训练[3]。具体来讲,各组织或部门的私有自有数据可以不离开本地,通过本地模型参数的更新和全局模型参数的聚合,在确保各自数据隐私性和安全性的情况下,联合训练一个共享的全局模型。因此,联邦学习被视为解决数据孤岛和打破数据壁垒的有效可行技术[4]。
为了解决电力投资系统面临的数据孤岛和隐私保护问题,本文提出了一个隐私保护的联邦学习框架,在各部门数据不出本地的情况下,联合训练投资预测模型。具体地,本文主要贡献如下:
(1)提出了一种基于客户端-服务器的联邦学习架构。与传统集中式的模型训练方式相比,该架构支持在隐私保护的情况下,分布式地联合训练模型。
(2)提出了隐私保护的联邦平均学习流程,引入同态加密技术,防止参数聚合过程实施成员推理攻击。该流程主要包括4 个阶段:局部模型训练、参数加密、参数聚合和局部模型更新。
(3)实验结果表明所提方法具有较好的收敛性,而且联合训练得到的模型具有较好的精度。
1 相关工作
Lim 等人[5]从通信代价、资源分配、安全性和隐私性四方面对联邦学习进行了综述。进一步,Yang 等人[6]一方面从安全多方计算、差分隐私和同态加密三方面讨论了安全的联邦学习框架;另一方面,将安全的联邦学习框架划分为3 种类型:水平联邦学习、垂直联邦学习和迁移联邦学习。王健宗等人[4]重点从通信负载、异步聚合等方面讨论了联邦学习的优化算法。
此外,其他工作研究了联邦学习在不同场景中的应用。Liu 等人[3]将联邦学习应用于交通预测领域,提出了一种基于联邦学习的隐私保护的交通预测方法。Ye 等人[7]将联邦学习和边缘计算相结合,提出了一种基于边缘计算的优化联邦学习方法。Yu 等人[8]将联邦学习应用于边缘计算环境中的内容缓冲,提出了一种车联网环境下基于点对点联合学习的主动式内容缓存方法。进一步,Yu 等人[9]在考虑车辆移动性和缓存内容的过期性的情况下,提出了一种基于联合学习的移动感知主动边缘缓存方案。Kim 等人[10]将联邦学习和区块链相结合,提出了一种基于区块链的节点感知动态加权方法,用于提高联邦学习的性能。
与上述工作相比,本文工作主要关注将联邦学习应用于电力行业,解决电力投资系统面临的数据孤岛和隐私保护问题。此外,本文将同态加密技术引入联邦平均学习流程,用于保护上述模型参数,以防止实施成员推理攻击。
2 架构和问题定义
2.1 架构
目前,联邦式学习的架构分为两种:客户端-服务器架构[7]和对等网络架构[11]。本文提出了一种基于客户端和服务器的联邦学习架构,如图1 所示。该架构包含:多个部门及部门自有的数据库、多个部门的局部模型、1个中心服务器和1 个全局模型。
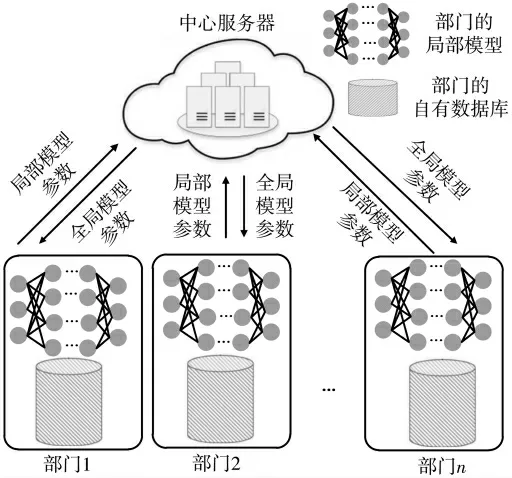
图1 面向电力投资系统的联邦学习架构
与传统集中式训练模型相比,图1 所示的架构允许分布式地联合训练模型。具体而言,首先,各部门使用自有数据库在本地训练自己的局部模型;其次,将局部模型的参数经加密后上传汇总到中心服务器进行参数聚合计算,更新全局模型;最后,各部门将更新后的全局模型参数下载到本地,并更新本地模型。直至本地模型的性能收敛并足够好,分布式的训练模型过程结束。
由图1 可以看出,分布式的模型训练方式通过聚合局部模型参数和使用全局模型参数更新局部模型,允许各部门的自有数据在不离开本地的情况下训练模型,既保护了各部门的数据,又共同联合训练了模型。
2.2 问题定义
对于图1 所示的联邦学习架构,令O={O1,O2,…,On}表示部门的集合,D={D1∪D2∪…∪Dn} 表示各部门自有数据库的并集。
定义1(集中式训练模型)给定部门集合O 和数据集D,集中式训练得到的模型记为Mc←f(D),其中,f(·)表示学习函数。
定义2(联邦式训练模型)给定部门集合O 和各部门自有数据库(D1,D2,…,Dn),联邦式训练得到的模型记 为,其中wi表示权重,fi(·)表示学习函数f(·)的本地版本。
定义3(ε-精度损失)[6]令集中式模型Mc的预测精度为Pc,联邦式模型Mf的预测精度为Pf,若满足式(1),则称联邦式学习算法达到ε-精度损失。

3 隐私保护的联邦平均学习流程
基于图1 所示的架构,提出了隐私保护的联邦平均学习流程,包括4 个步骤:局部模型训练、参数加密、参数聚合和局部模型更新。
3.1 局部模型训练
在各部门同意联合训练模型会,中心服务器将向各部门发布模型的初始参数。各部门使用自有数据对初始化后的模型进行本地训练。训练接收后,将本地训练计算得到的模型参数梯度进行上传。
对于部门Oi,令{xj,yj}∈Di,其中xi∈Rd表示输入样本向量具有d 个特征,其中yj∈R 表示xi对应的标记输出值。对于局部模型训练,如果输入样本向量xj,则希望从Di中学习到模型参数向量ω∈Rd,使得ω 尽可能接近yj。为此,代价函数定义如下:
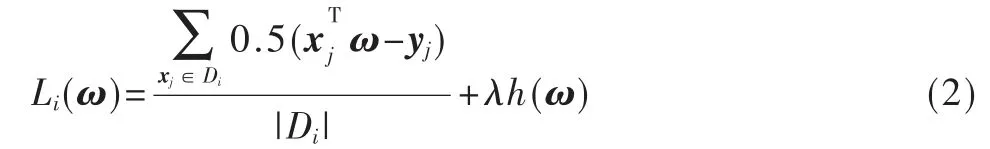
其中,λ∈[0,1],h(·)表示正则化函数,|Di|表示部门Oi自有数据库的条目数量。
3.2 参数加密
已有研究表明[12]:在联邦学习中,好奇的中心服务器通过共享的参数梯度,可以实施成员推理攻击,并获得训练数据信息。为了防止成员推理攻击,本文采用了同态加密技术对上传的梯度参数进行加密。
与差分隐私保护[13]和安全多方计算[14]相比,同态加密技术分别具有数据不失真和计算复杂性小的优点。由于参数聚合过程只涉及加法和乘法,将使用无需多项式近似的加法同态加密技术对梯度参数进行加密。其加密的基本原理如下:
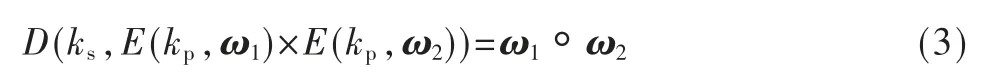
其中,ω1、ω2分别表示部门1 和部门2 上传的梯度参数,ks、kp分别表示私钥与公钥,E()、D()分别表示加密运算和解密算,◦、×分别表示明文域和密文域的运算。
3.3 参数聚合
中心服务器将接收到来自各个部门的局部模型参数梯度,并对这些参数梯度进行聚合。具体而言,参数的聚合过程如下:
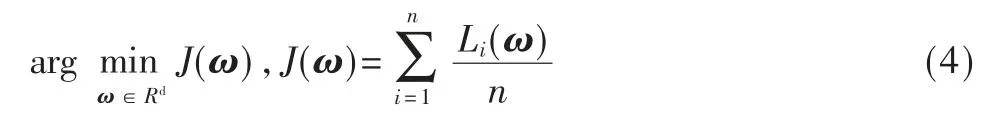
根据式(2),式(3)可进一步重写为:

3.4 局部模型更新
局部模型更新是指各部门从中心服务器下载聚合后的全局模型参数梯度,并将解密后的参数梯度用于本地局部模型的更新。具体地,对于部门Oi,更新本地模型参数的计算如下:

其中,wg表示解密后得到的全局模型参数梯度。
3.5 算法
目前,常见的联邦学习算法是谷歌公司提出的FedAvg算 法(Federated Averaging)[15]。基于FedAvg 算法,引入同态加密算法,提出了隐私保护的联邦平均学习算法,记为PP-FedAvg,如算法1 所示。
算法1:联邦平均学习算法PP-FedAvg
输入:部门k 的自有数据库Dk,b 是本地Batch 的大小,E 表示epoch 的数 量,α 表示学习率,▽L(·,·)表示梯度优化函数;
输出:更新后的局部模型参数ω。

其中,算法1 中第6 行调用的算法LocalUpdate(k,ωt)如算法2 所示。
算法2:LocalUpdate 局部模型更新
输入:部门k 的自有数据库Dk,b 是本地批次的大小(Batch),E 表示迭代周期的数量(epoch),α 表示学习率,▽L(·,·)表示梯度优化函数;
输出:局部模型的参数ωt。
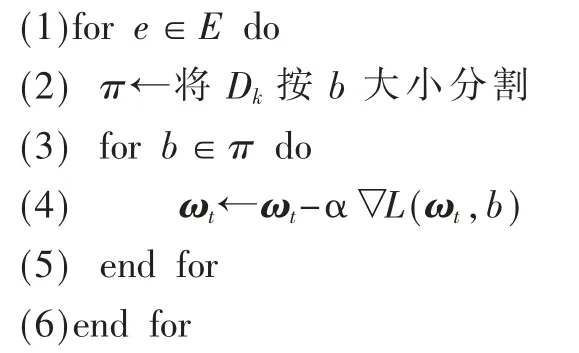
(7)输出更新后的参数ωt
需要注意的是,在算法1 中,当每轮参数聚合后,中心服务器需要确定是否需要继续执行联邦平均学习算法。
4 实验
4.1 实验设置
实验环境考虑了由1 个中心服务器和10 个部门组成的联邦学习架构。当从中心服务器下载初始模型参数后,10 个部门在本地并行训练模型,并将训练得到的模型参数同步发送到中心服务器进行全局聚合。这被视为一轮通信的结束。
实验选择开源数据集MNIST 作为数据集。该数据集包含60 000 个训练图像和10 000 个测试图像。其中,每个图像的分辨率为28×28,对应于10 个(0~9)可能数字中的1 个。为了确保每个部门数据集满足非独立同分布,根据数字大小,将60 000 个训练数据排序并划分为20 份(每份300 个图像),并随机地分配2 份给10 个部门。
实验采用的编程语言为Python,使用的深度学习模型为卷积神经网络(CNN),如图2 所示。该模型的输入是28×28 的图像,输出是数字。具体地,模型由2 种类型卷积层、2 个最大池化层和1 个全连接层组成。第一种类型的卷积层包含两层卷积(层2 和3),分别使用16 个3×3 的卷积核,步长为1。第二种类型的卷积层包含两层卷积(层5 和6),分别使用32 个3×3 的卷积核,步长为1。两个最大池化层均使用2×2 的卷积核。全连接层包含10 个神经单元。
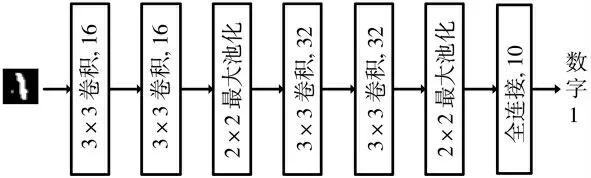
图2 卷积神经网络的结构
为了验证所提隐私保护联邦学习框架的有效性,将框架分布式联合训练模型的方法(记为PFedAvg)与集中式训练模型的方法(记为CTCNN)做对比。
4.2 实验结果与分析
图3 显示了PFedAvg 和CTCNN 训练模型的损失。从结果来看,用PFedAvg 训练模型的损失与用CTCNN 训练模型的损失没有显著差异。这不仅表明PFedAvg 训练的模型具有良好的收敛性,还表明PFedAvg 训练的模型具有较好的精度。
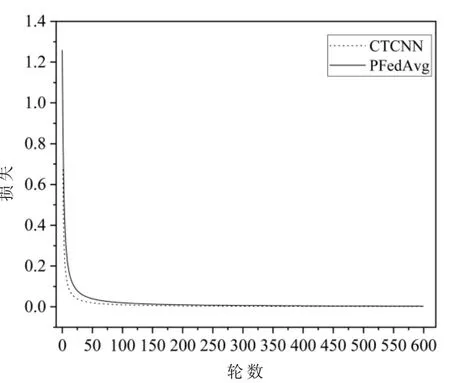
图3 PFedAvg 和CTCNN 训练模型的损失
图4 比较了在不同的批次大小和迭代周期,PFedAvg训练模型的精度随通信轮数的变化趋势。从结果来看,当批次大小设置为10、迭代周期为12 时,PFedAvg 训练得到的模型精度最高。

图4 在不同批次大小和迭代周期下PFedAvg 模型的精度
5 结论
为了解决电力投资系统面临的数据孤岛和隐私保护问题,本文将联邦学习应用于电力行业,提出了一种隐私保护的联邦学习框架。实验结果表明了该框架的有效性。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18 07:31:10
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
汽车工程(2021年12期)2021-03-08 02:34:30
家庭影院技术(2020年10期)2020-12-14 07:54:16
家庭影院技术(2019年7期)2019-08-27 02:42:06
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电信科学(2017年6期)2017-07-01 15:45:17
电测与仪表(2015年22期)2015-04-09 11:42:18
电视技术(2014年19期)2014-03-11 15:38:20
