
基于大数据环境的海洋石油钻完井数据分析系统建构
2022-06-07 09:40朱玉高
粘接 2022年5期
朱玉高
(延安职业技术学院 石油和化学工程系,陕西 延安 716000)
中海油公司自2004年引入钻完井数据分析数据库系统以来,经过10余年发展,已经形成了完善的钻完井日报及钻完井工报制度,各钻台分别形成了相对完善的钻完井数据分析数据库系统且已经实现了钻完井数据的同构融合工作。但是,钻完井数据如果要发挥更大的数据价值,则需要实现针对地质报告、材料报告、三电耗能报告、人事管理报告等相关数据的充分异构融合。即通过完善钻完井数据库系统与其他管理信息系统数据之间的接口架构,实现对钻完井数据的深度挖掘。
在钻完井数据分析领域,最初钻完井数据分析过程,仅是通过钻完井日报和钻完井工报形成更长周期的数据统计,如钻完井周报、钻完井月报、钻完井年报等,且可以自动统计分析不同井台不同钻机的钻完井数据工报统计。近10年内,根据上述数据和深度迭代数据回归分析神经网络系统,可以实现对钻完井数据前推若干周期的曲线估计计算,对未来一定周期内的钻完井数据进行预报分析。本文研究中,计划引入钻完井数据深度分析系统,实现对地质预报、材料及能源消耗、人力资源成本等诸多关联异构数据的基于深度迭代数据回归分析神经网络系统的曲线估计计算分析。
该研究创新点在于使海洋钻井平台的钻完井数据作为核心驱动数据,实现对海量关联异构数据的曲线估计分析,使钻完井数据发挥更大作用。
1 钻完井数据构成模式及接口设计
1.1 钻完井数据构成模式
钻完井数据主要包括以下构成:
(1)施工队伍编号及相关工作人员,含各责任人信息,包含班组长、钻完井工程师、材料员、司机等;
(2)井台中心点坐标信息,包括水平坐标和高程坐标,该信息受RTK系统定位,因为半潜式平台可能会导致井台中心点坐标发生微小变化,所以要求实时监测平台中心点坐标信息;
(3)钻头坐标信息,包括水平坐标和高程坐标,该信息受到定向钻头定位系统控制;
(4)井筒长度信息和井筒深度信息,该信息受到历史钻头坐标信息控制;
(5)钻头温度、压力等信息,该信息由钻头内物联网探头系统获取;
(6)当班的材料消耗信息,如钻杆、钻头、井筒套管及其他配件;
(7)当班气象及水文条件信息,如气温、风速、浪高、洋流、水温等。
1.2 钻完井的数据接口及数据边界
分析上述内部数据,可发现钻完井数据与外部数据库之间存在多种数据关联,这些数据关联均可构成异构数据联合分析的数据接口。如图1所示。
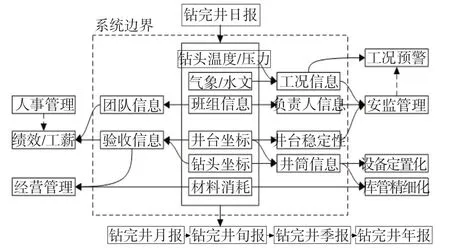
图1 钻完井系统数据接口与数据边界示意图Fig.1 Schematic diagram of data interface and data boundary of drilling and completion system
图1中展示了该系统部分数据外部接口。因为钻完井工作是钻井平台的核心工作,所以,钻完井系统应是钻井平台管理信息系统的钻完井数据核心驱动数据,通过对该数据与其他相关管理信息系统进行数据联合,可以提供可供数据深度挖掘使用的核心数据。
1.3 数据接口的实现模式
钻完井数据如果要实现与其他相关系统的数据接口,则必须突破独立系统之间的数据屏障。因为几乎所有独立系统均会开发数据保护安全管理子系统,任何外部系统调用本系统数据,均会面临数据访问规则限制、数据解密方案限制、数据库及数据仓库的用户密钥限制、数据结构限制等诸多限制,即便在前三者中均可因为所有相关系统的管理方为同一法人而轻易获得相应资料,但数据结构限制会成为数据接口实现过程的主要屏障,脱离原系统数据解释层模块的支持,外部系统很难有效对其数据进行解释,从而使读取数据即便使用全部合法密钥后,仍无法进行有效解析。所以,API服务器构建的数据逻辑连接成为大部分工业平行系统进行跨系统数据调用的重要手段。其调用方式详如图2所示。
图2中,在数据仓库任务主机的驱动下,基于数据库平台云主机,将数据仓库中相关数据形成元数据,并将元数据POST到数据应用系统的元数据中,进而读入到数据应用系统的数据仓库中。此时,两侧系统中的4台主机具有明确分工。其中,数据仓库任务主机负责整合数据仓库主机集群中的资源并进行数据联合调动,数据库平台云主机运行数据库平台软件,比如MySQL等,用于执行相应的SQL指令,数据解释模块云主机运行数据系统分层结构中的解释层模块,对数据进行解释和编译,API服务器主机负责发出并解析数据请求(Ask)并返回数据反馈(Request)。数据的实际流量在数据仓库任务主机中经过相应子系统的背板交换机连接到接入路由器中,进而通过IDC系统的背板交换机实现数据的物理层和链路层互联。
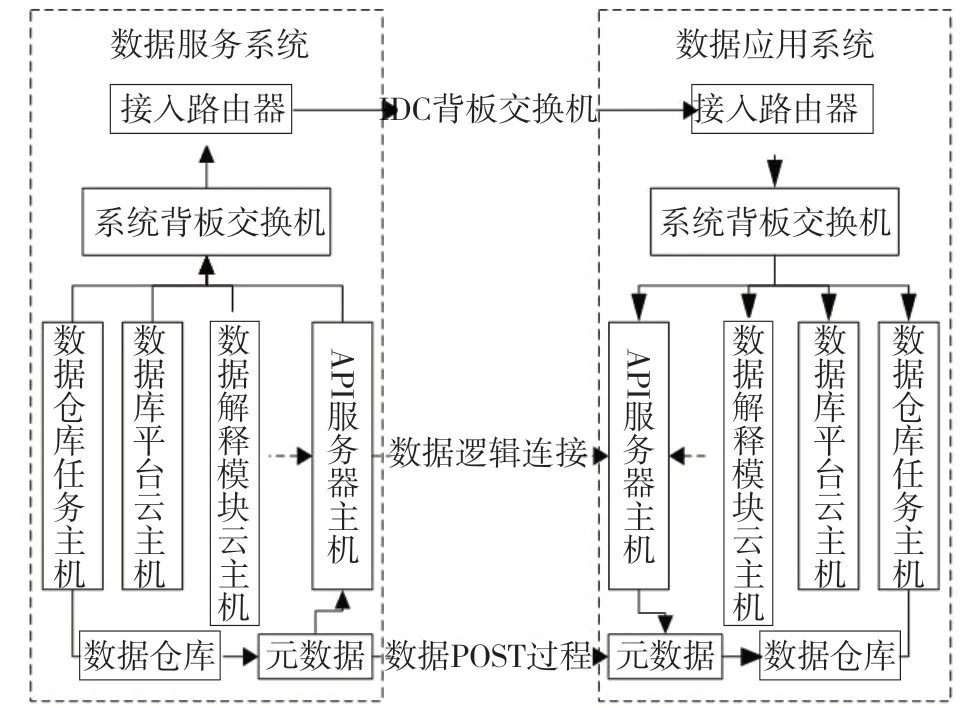
图2 基于API的数据共享数据流示意图Fig.2 Schematic diagram of data flow of data sharing based on API
2 数据分析方案
2.1 数据治理方法
不论是钻完井数据还是其他相关数据,在各自数据库中均已经形成了标准化数据,这些标准化数据如果进行联合分析,必须进行去量纲计算,但不同的数据分析需求需要不同的去量纲方式,当前较为常用的数据去量纲方式有minmax算法和Z-Score算法。
minmax算法是将数据等比例投影到[0,1]区间上,加权minmax算法可以将数据等比例投影到任何区间上。其基函数为:
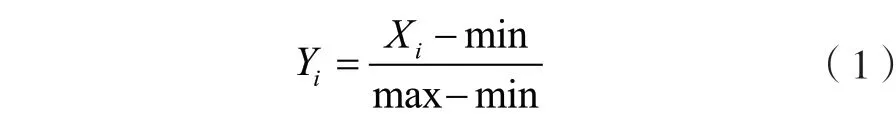
式中:X,Y分别为数据列中第个输入数据及其对应的输出数据;min为该列数据的最小值;max为该列数据的最大值;minmax加可以将数据投影区间下限调整到值,乘可以将数据投影区间上限调整到+值。
Z-Score算法是根据数据离开算数平均中值的位移与标准差的比例将数据的变化区间进行等比例投影。其基函数为:
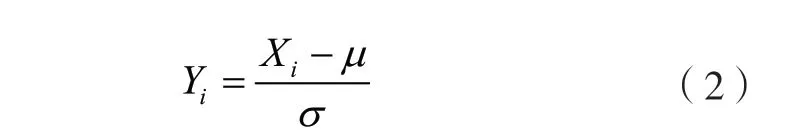
式中:Y,X分别为数据列中第个输入数据及其对应的输出数据;为该列数据的均值;为该列数据的标准差;其中:

式中:为该列数据元素X的数量;其他数学符号含义同前文;
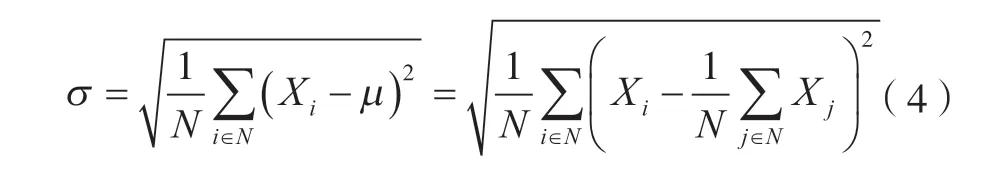
式中:数学符号含义同前文;
所以,将式(3)、式(4)代入式(2),可得:
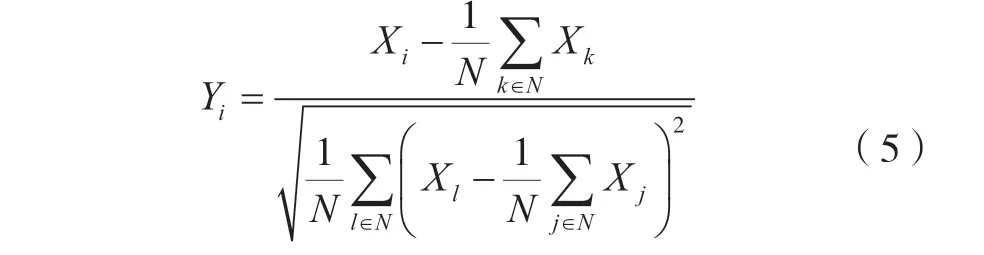
式中:数学符号含义同前文;
上述式(1)描述的minmax算法,主要应用于需要在不同量值区间不同量纲数据之间的趋势比较算法的前置数据治理,式(5)描述的Z-Score算法主要应用于对数据趋势分析和数据曲线估计为核心目的的前置数据治理。将该两种数据治理算法模块进行提前准备并独立开发后,可供后续数据分析过程直接调用。
2.2 数据联合分析模型
图1中数据经过多种数据联合,可以进行更为复杂的数据联合分析。如钻完井井筒进度数据与材料消耗数据相结合,可以形成单位井筒长度的材料消耗情况变化趋势分析;钻头深度数据与材料消耗数据相结合,可以形成深度标尺下的单位材料消耗数据分析。所以,统观研究两列数据的整合模式,可以得到图3。
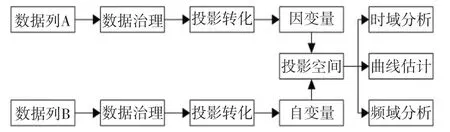
图3 数据联合分析模型Fig.3 Data joint analysis model
图3中,数据治理过程根据实际数据分析需求和数据工程学特征选择使用公式(1)的minmax算法或者公式(5)的Z-Score算法进行数据治理,经过数据治理的方式,可以通过区间分析法通过加N及乘M的方式进行数据区间调整,或使用对数法进行非线性密集数据关系放大。经过数据治理和投影转化的数据,形成投影空间的因变量和自变量,从而在投影空间中进行相关的后续分析。
此处数据建立关联的方式主要2种:
(1)主键关联数据的关联,在数据列A中,寻求关联主键字段KA,在数据列B中,寻求关联主键字段KB,当KA(i)=KB(j)时,认为A(KA(i))与B(KB(j))存在数据关联。如图4所示。
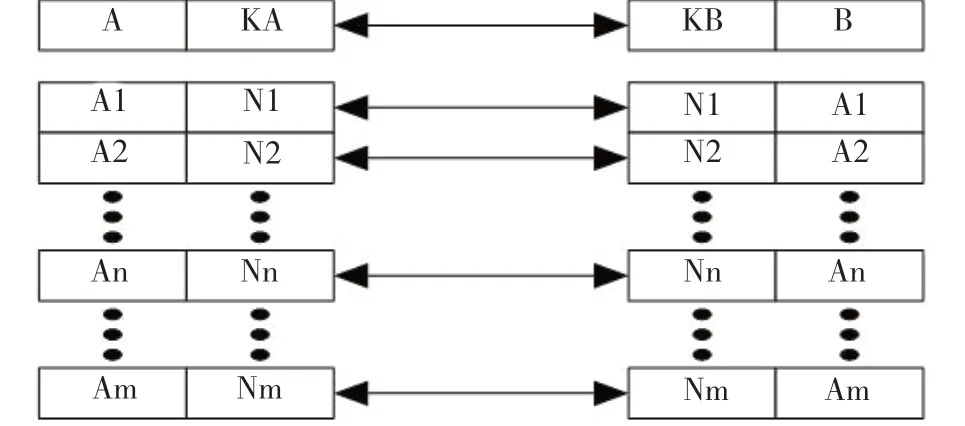
图4 主键关联数据的关联模式示意图Fig.4 Schematic diagram of association mode of primary key associated data
图4中,线性矩阵KA、KB可能不相等,但在线性矩阵KA、KB中可能存在KA(i)=KB(j),而KA、KB的工程学数据意义一致,此时以KA、KB为纽带,可以构建出A(KA(i))与B(KB(j))的联系。此时,KA、KB对应的数据列为自变量,而A、B对应的数据列为因变量。构建联系后,A、B可互为自变量。
(2)逻辑关联数据的关联,如果数据列A与数据列B产生于同一个数据表,那么该数据表的主键K数据列就可以将A、B直接关联。如图5所示。
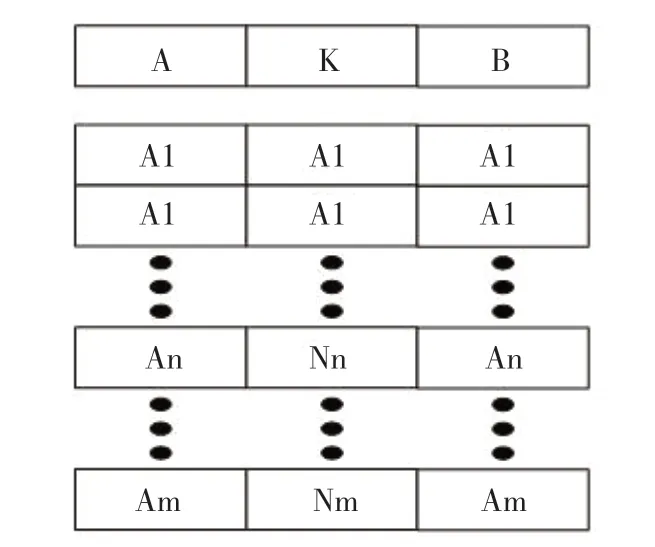
图5 逻辑关联数据的关联模式示意图Fig.5 Schematic diagram of association mode of logical association data
图5中,数据列A与数据列B构建数据关联后,可在后续数据处理中抛弃数据列K而直接互为自变量进行处理。在包含钻完井数据库系统在内的大部分工业数据库中,主键K一般为时序标志,那么基于主键K对数据列A、B进行直接分析,则被称作时域分析,在时域分析基础上进行频域转化,如小波分析、傅里叶分析等,即被称作频域分析,但数据列A与数据列B直接构成数据关联后,也可在互为自变量的条件下进行基于非时序自变量的等效时域分析并进行等效频域分析。该理念在上述主键关联分析中同样有效。
3 系统模型效能验证
如果将大数据系统分为5个层次,分别为硬件层、数据层、治理层、解释层、应用层,那么该模型就其数据层和治理层进行了升级。大数据系统的硬件层主要负责提供数据存储介质和数据库管理平台的管理主机系统和内部网络背板、内部网络控制系统;数据层为大数据硬件中存储的数据信息以及数据管理和数据应用产生的数据流;治理层包括数据的去量纲、脱敏、加密解密、接口协议等;解释层包括数据格式的强制转化、流媒体的二进制分解和重组等;应用层主要提供相应的应用功能,比如数据曲线估计、时域频域分析、数据预警、曲线估计等,常规数据分析中经常用到的神经网络、模糊矩阵等均在应用层相应模块中。
在对数据层的验证中,应分析支持相同功能的数据管理目标下的数据硬件占用量,其验证结果如表1所示。
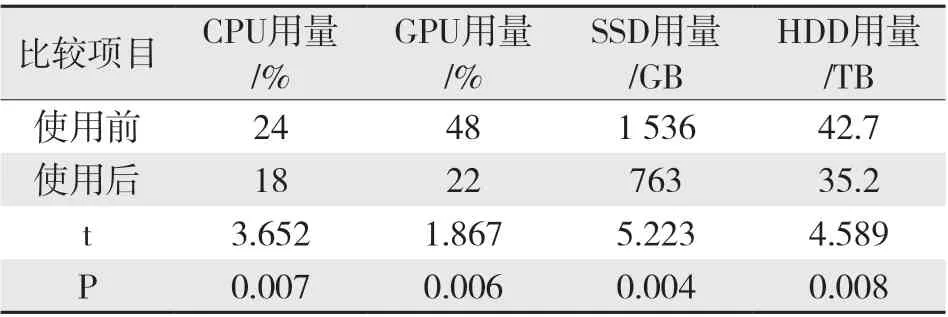
表1 数据层技术革新效果比较Tab.1 Comparison of technical innovation effect of data layer
表1中,该模型使用后的上述四大IDC资源需求量显著降低,其原理是充分提升了数据夸库融合度并充分减少了数据冗余度。其中,CPU指系统中通用中央处理器,GPU指系统中的专用浮点处理器,SSD和HDD指系统的硬盘空间,均采用了SAS硬盘总线且使用RAID备份的冗余硬盘空间未计入该空间需求中。
在对治理层的验证中,应充分考察可用数据查询的量,以及在中央数据仓库可用数据库规模的支持下可以提供的理论最大查询数据规模的比值。其验证结果如表2所示。
表2中,在使用后数据库规模缩小17.56%的前提下,其查询量提升5.59倍,可用查询规模提升11.67倍,导致数据查询放大比从使用前的2.194提升到使用后的31.063。查询量表明数据库可以提供的查询功能,查询放大比指数据在相关系统内的应用场景丰富程度。可见使用该模型对钻完井数据的数据层和治理层进行技术革新优化后,极大程度丰富了数据的应用场景,使数据价值得到充分放大。
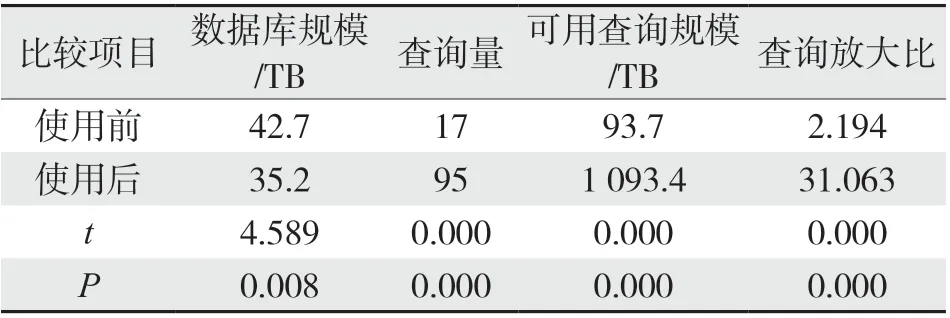
表2 治理层技术革新效果比较Tab.2 Comparison of the effect of technological innovation at the governance level
4 结语
钻完井数据是钻井平台的核心数据,通过构建数据融合接口的方式,使海洋钻井平台内部管理信息化系统之间实现了更加充分的融合。在本文模型下,对钻完井大数据的数据层和治理层进行技术革新,但硬件层、解释层保持不变,此时数据的可挖掘价值大幅度提升,未来可以在应用层开发更加丰富的数据应用,以实现钻完井数据的充分利用。
猜你喜欢
电子乐园·下旬刊(2021年3期)2021-02-08
学苑创造·A版(2018年11期)2018-02-01
数学大王·低年级(2017年12期)2017-12-26
财经(2017年2期)2017-03-10
读者(2017年5期)2017-02-15
国外科技新书评介(2016年8期)2016-11-16
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
棋艺(2014年7期)2014-09-09
