
中文医学命名实体识别算法研究*
2022-06-06 09:37李梦蝶李功利
医学信息学杂志 2022年3期
李梦蝶 张 平 李功利 姜 伟
(电子科技大学生命科学与技术学院 成都 610054) (四川省屏山县人民医院 屏山 645350)
李 科 蔡培强
(电子科技大学生命科学与技术学院 成都 610054) (四川省屏山县人民医院 屏山 645350)
1 引言
1.1 研究背景与意义
电子病历(Electronic Medical Records,EMR)是患者就诊过程中生成的电子化病历信息,包括医生问诊产生的文本数据,实验室检查产生的数字、图像、图表数据,这些信息为医疗诊断和医学研究提供重要数据支持[1]。大量有用信息存在于叙述性文本中,计算机能够自动利用的结构化数据有限,采用自然语言处理技术进行文本结构化成为医学信息学研究热点[2]。命名实体识别(Named Entity Recognition,NER)是自然语言处理中的重要方法,该技术可识别医学文本中特定的医学实体,标识其蕴含信息,加快医院信息化进程,还可以提供医疗决策支持,改善医疗质量,提高医疗人员工作效率,减少临床决策失误,促进临床医学研究。
1.2 命名实体识别研究方法
1.2.1 实体识别常用的机器学习方法 基于词典和规则是最早的命名实体识别方法。李毅、保鹏飞和薛万国[3]基于中文电子病历特点,构建一套生物医学命名实体规则、实体词和用于分类的词表。实体识别常用的机器学习方法包括隐马尔科夫模型(Hidden Markov Model,HMM),支持向量机(Support Vector Machine,SVM),条件随机场模型(Conditional Random Fields,CRF)等[4]。Zhang J、Shen D和Zhou G等[5]提出第1个处理级联现象的HMM实体识别系统,该系统不仅集合拼写、形态学多种特征,还加入命名实体缩写,在GENA3.0语料上F值达到66.5%。Lee K J、Hwang Y S和Kim S等[6]提出一个基于SVM的蛋白质和DNA实体识别系统,该系统在确认已知词性标注的实体边界后,利用单词信息和上下文构造特征集进行实体识别,在GENA3.0语料上测试F1值达到74.8%。2016年Bhasuran B、Murugesan G和Abdulkadhar S等[7]以CRF作为基础分类器,结合模糊字符串匹配算法识别罕见疾病名称,该应用在 CDR(Chemical Disease Relations)语料库的训练集上测试F值达到89.12%。词典与机器学习相结合的方法也常用来进行实体识别[8]。
1.2.2 神经网络算法 逐渐被迁移到自然语言处理中,常用来实体识别的一般有卷积神经网络和递归神经网络。Zhao Z、Yang Z和 Luo L等[9]基于多标签的卷积神经网络模型进行疾病识别,级联了字符、单词、词典特征,最终模型在美国国家生物技术信息中心(National Center for Biotechnology Information,NCBI)数据集上测试F值达到85.17%。2019年Cho H和Lee H[10]提出一个基于双向长短时记忆(Bi-Directional Long Short-Term Memory,BiLSTM)和CRF的生物医学命名实体识别系统,在NCBI和CDR语料库上都取得不错的识别效果。
1.2.3 预训练模型 由于具备可提供初始化参数等优点而常用于医学实体识别。Zhang X、Zhang Y和Zhang Q等[11]利用Bert(Bidirectional Encoder Representation from Transformers)模型训练词向量,该模型在其自建的癌症语料上测试F1值达到93.53%。罗凌、杨志豪和宋雅文等[12]训练一个基于ELMo(Embeddings from Language Models)语言模型的命名实体模型,模型中引入包含汉字内部结构的笔画信息,最终在中国知识图谱与语义计算大会数据集上测试F值达到91.75%。
1.2.4 融合特征Albert的中文医学命名实体识别算法 基于规则和词典识别效果理想,但建立模板、维护词典成本较高,且移植性差。机器学习解决了移植性问题,但其严格特征提取影响实体识别效果。深度学习克服了机器学习中的问题,但神经网络模型参数多,医学数据集较小,容易过拟合。基于通用语料训练的预训练模型提供初始化参数,在下游任务中微调即可,具有更好的泛化能力,在小量的医学实体语料上表现不错。综上,本文提出一种融合特征Albert(A Lite Bert,轻量级Bert)的中文医学命名实体识别算法,该算法旨在训练融合文本短语、语言语义的字向量特征,将融合的字向量特征与句子向量特征相加以提高实体识别效果。
2 模型结构
2.1 构建融合特征Albert+BiLSTM+CRF模型
针对现有研究方法局限性提出一种融合特征Albert的中文医学命名实体识别算法。其核心在于训练的字向量融合文本短语、语言学、语义学特征,然后将融合的字向量特征和句子向量特征相加,最终可以更高效地进行命名实体识别。与其他字向量特征模型相比,本文算法能够充分学习到预测文本的字信息、词语信息、语言语义信息、句子信息、语篇级信息。算法流程实现分为数据预处理、词嵌入、句子嵌入、命名实体识别4个阶段,见图1。
2.2 词嵌入阶段
2.2.1 Bert模型 2018年Bert模型被提出[13],旨在解决以往预训练模型不能学习文本上下文特征的问题。模型主要框架是编码器模型,将完形填空和下一个句子预测作为训练目标,基于大规模数据训练词向量能有效捕捉文本前后文特征,见图2。
2.2.2 Albert模型 主干结构与Bert相似,在Bert的基础上主要进行3方面改进,分别是嵌入因式分解参数化、跨层参数共享、句子间一致性损失,减少了参数但是性能有较大提升[14]。嵌入因式分解参数化在Bert中字嵌入E和隐藏层H是相等的。语言模型建模时,字嵌入和隐藏层分离可以更充分地利用模型参数。实际应用上训练词典大小为V,嵌入矩阵为V*E,如果H变大E随着变大,此时嵌入矩阵V*E将会变大,最终导致训练过程中数十亿参数仅有少部分更新。而Albert中采用的因式分解是先将one-hot向量映射到低维空间,然后映射到隐藏层中,最终使模型参数从O(V*H)减少到O(V*E+E*H)。与仅共享前馈神经网络层参数和仅共享注意力层参数不同,Albert选择共享所有层参数,通过测量L2距离和余弦相似度,表明跨层共享参数的方法能够稳定网络参数。在Bert模型中以预测下一个句子为训练目标时,属于下一句来自同一文档连续片段,属于非下一句来自不同文档片段,这种包含主题预测和一致性预测的方法较为简单。因此Albert提出基于句子顺序预测损失,正例的选取与Bert相同,反例是相同的两个连续片段但顺序交换。本文发现Albert算法在低层网络中学习词语特征、中层网络中学习语言学特征、高层中学习语义特征,所以提出融合不同层的训练特征,用来解决单个字向量或词语向量问题。
2.3 句子嵌入阶段
2.3.1 概述 长短期记忆(Long Short-Term Memory,LSTM)是循环神经网络(Recurrent Neural Network,RNN)的改进版,有效解决了梯度消失和梯度下降问题,而BiLSTM是由前向LSTM和后向LSTM构成的算法。

2.3.3 LSTM计算过程 在确定当前时刻的隐藏层状态时,先计算需要被遗忘的信息。遗忘门输出由当前时刻输入状态和上一时刻隐藏层状态控制,如公式(2-1)所示,输出范围从0到1。
ft=σ(Wf*(ht-1,xt)+bf)
(2-1)

it=σ(Wi*(ht-1,xt)+bi)
(2-2)
(2-3)
丢弃和更新信息确定后,第3步是将上一时刻细胞状态更新为当前时刻细胞状态。如公式(2-4)所示。
(2-4)
最后就是单元结构LSTM输出。输出门由sigmoid层、当前时刻输入、上一时刻隐藏层状态决定,如公式(2-5)所示。当前时刻输出门状态乘以通过tanh层变换的当前时刻细胞状态即可得到当前时刻隐藏层状态输出ht,见式(2-6)。
Ot=σ(WO*(ht-1,xt)+bO)
(2-5)
ht=Ot*tanh(Ct)
(2-6)
2.3.4 BiLSTM算法 上述4步是一个完整单元的LSTM计算过程,将前向的LSTM和后向的LSTM拼接即本文使用的BiLSTM。对句子“咳嗽伴头晕”编码,前向LSTM输入“咳嗽”“伴”“头晕“,输出隐藏层状态{hL0,hL1,hL2},后向LSTM输入“头晕”“伴”“咳嗽”,输出隐藏层状态{hR0,hR1,hR2},将前向后向的隐藏层状态拼接得到具有上下文特征的隐藏层状态{[hL0,hR0],[hL1,hR1],[hL2,hR2]},即{h0,h1,h2}。拼接后的hi就是输入词对应的预测标签,来自于实体分类中概率最大的。
2.4 构建命名实体识别模型
为解决BiLSTM的输出仅在每一时刻选出一个最大的概率标签,而各个时刻输出之间不存在关系的问题,设计引入具有转移矩阵的CRF,在其中加入约束规则以保证最终预测结果的合法性。假设给定一个输入序列X,其预测标签序列为y,输入序列的预测标签概率为p(y|X)。
X=(X1,X2,…,Xn)
(2-7)
y=(y1,y2,…,yn)
(2-8)
(2-9)
(2-10)
其中,Ayi,yi+1为从yi到yi+1的转移矩阵,大小为(n+2)*(n+2),n为所有标签个数,+2是增加了起止位置。Pi,yi为第i个位置softmax输出为yi的概率,起止位置记为0。在计算预测得分s(X,y)中,加上实体标签之间转移概率,给模型加入约束规则:句子总是以“B-”或“O”开始,开头出现“I-”时就是错误标签;“I-实体标签a”出现在“B-实体标签a”之前时,该标签无效; “B-实体标签a”“I-实体标签b”是非法标签。利用最大似然法训练转移矩阵参数,其损失函数如公式(2-11)所示,待模型训练完毕,采用维特比算法找出最优路径,也就是更合理的输入序列的预测标签。
(2-11)
最终构建完成本文的医学实体识别算法,如图4所示,输出预测文本“咳嗽伴头晕”,在Albert阶段,模型学习预测文本内的短语、语言语义学特征,并将融合这些特征的字向量输出,作为BiLSTM输入,以进一步学习预测文本的上下文特征,然后在CRF层加入实体名称约束规则,最终可输出较为合理的实体标签预测结果。
3 实验及结果分析
3.1 实验环境及评价标准
实验在Inter core i5-4590 3.3GHz的CPU上运行,能够为文中涉及命名实体识别模型提供硬件支持。所有模型均采用Python语言编写,版本号为3.6,用Tensorflow搭建神经网络学习框架。使用命名实体识别领域的3个指标作为模型衡量标准:准确率P(Precision)、召回率R(Recall)以及F1值(F-score),TT表示真实命名实体是正例,预测结果也是正例,FT表示真实命名实体是反例,但预测结果为正例,TF表示真实命名实体是正例,但预测结果为反例,FF表示真实命名实体是反例,预测结果也为反例。
(3-1)
(3-2)
(3-3)
3.2 实验数据
3.2.1 概述 本研究数据来自临床电子病历并进行脱敏处理。最终完成900份辅助检查、200份体格检查、5 000份主诉的语料标注,分别列作3个实验项目,辅助检查项目中实体数量最多的是检查指标、最少的是检查值,体格检查项目中实体数量最多的是结果、最少的是项目值,主诉项目中实体数量最多的是症状、最少的是伴随部位。
3.2.2 标注规则及实体类别阶段 在临床医生指导下制定3个类目的标注规则,分别是辅助检查、体格检查、主诉。辅助检查实体包括检查日期、检查项目、检查结果、检查值、检查指标、指标结果、指标值。体格检查实体包括部位、查体项目、结果、状态、项目值。主诉实体包括症状、部位、持续时间、伴随症状、伴随部位、伴随时间、既往史。
3.2.3 数据标注阶段 语料库构建采用BIO标注体系,标注工具是开源doccano软件。标注小组由3人组成,各环节有异议的部分讨论确定并立即更新标注规则。
3.3 实验及实验参数
为验证本模型的可行性和有效性设计3组对比实验,对比模型分别是未融合字向量特征的Albert+BiLSTM+CRF、BiLSTM+CRF和Bert+BiLSTM+CRF。本研究词嵌入的最大句子长度为300,学习率为2e-05,迭代次数为40,这些参数已经使模型识别效果达到最佳。
3.4 实验结果
3.4.1 与未融合向量模型的识别效果对比 实验训练集与测试集为7∶3。提出的融合字向量特征与未融合字向量特征相比,在主诉这个语料库中表现最明显,精确率P明显高于2.0%,召回率R明显高于1.0%,F1值高于2.0%。在辅助检查的语料库中表现次之,精确率和F1值明显高于1.5%,召回率R高于1.4%。在体格检查语料库上表现略低,不过F1值高于0.4%,见表1。
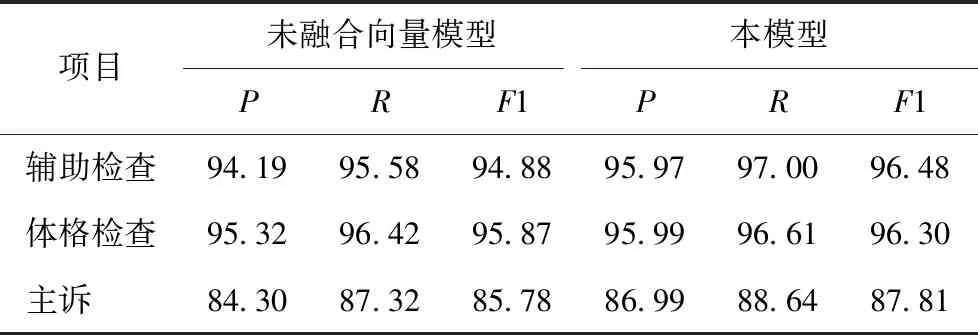
表1 本模型与未融合向量模型在3个项目上的识别效果对比(%)
实验结果表明本文提出的词嵌入阶段融合字向量特征可以有效提取字的特征信息,与单纯词嵌入相比,提升了命名实体识别成功率,同时也证明本文提出的融合字向量特征是可行的。
3.4.2 与其他经典模型的识别效果对比 与BiLSTM+CRF、Bert+BiLSTM+CRF进行对比可以发现加入Bert的BiLSTM+CRF模型相比于原始模型F1值均提高了2%以上。在BiLSTM+CRF模型中,BiLSTM被用来学习文本的句子特征,CRF用来预测输出最优实体标签,此模型缺少字向量特征,而Bert可以学习到字符级别信息,所以加入Bert的BiLSTM+CRF模型具有更好的识别效果。另外,本文提出的融合字向量特征模型相比于Bert+BiLSTM+CRF模型F1值均有所提高,平均F1值达到93.53%。虽然Bert和Albert都能学习到字符级别的特征,但在Albert进行字向量训练时高中低层学习到的特征不同,所以将这些特征融合可以有效提高实体识别能力,见表2。综合精确率P、召回率R、F1值3个指标,本文提出的模型效果更好,具有更佳的识别能力。

表2 本模型与其他经典模型在3个项目上的识别效果对比(%)
4 结语
本文提出一种融合Albert不同层训练特征的中文医学命名实体识别算法。算法结合中文电子病历的语言结构特点,在词嵌入阶段进行优化,使之可提取预测文本中短语、语言学、语义学特征,然后融合这些特征并与句子特征相加进行实体识别。基于临床病历,利用BIO标注体系构建辅助检查、体格检查、主诉3个语料,利用这些语料训练测试本算法,然后与其他模型进行对比,结果表明本文提出的融合特征模型在3个项目上的F1值都高于其他3个模型,平均F1值达到93.53%,具有更好的识别效果。本文构建的语料库量还比较小,对模型识别效果有一定影响,未来可引入主动学习、众包标注等方法构建更大的语料库;可加入修饰词的识别,丰富算法识别广度。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
中国诗歌(2017年12期)2017-11-15
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
