
留学生中介字数据库建设若干问题讨论
2022-06-06 13:24:46张瑞朋
华文教学与研究 2022年2期






[关键词] 中介字数据库;建设;语料属性;标注;功能
[摘 要] 目前关于中介字数据库的建设和研究相对较少。文章以中山大学留学生全程性中介字数据库为例,论述了中介字数据库建设过程中应该注意的几个问题:语料要真实自然,这是基本属性;语料要具备连续性和全程性,将有利于纵向和渐进性研究;中介字标注内容包括错字、似别字、别字、不规范字的标注,并详细讨论了偏误类型和偏误原因的标注方法和规范。同时,强调标注要遵循科学性和渐进性。文章还介绍了数据库的功能和价值,并结合实践提出了建库过程中一些可资借鉴的方法和建议。
[中图分类号]H195.3 [文献标识码]A [文章编号]1674-8174(2022)02-0086-09
近年来,汉语中介语语料库的建设呈现繁荣局面,数量增多,语料库类别也多种多样。这些语料库不但为研究者探索汉语的语言现象提供了更多的语料资源,也极大地提高了汉语作为第二语言教学研究的水平。汉字是对外汉语教学界公认的重点和难点,但是关于“汉字”的专门数据库却很少见。数据库和语料库为语言现象测查和定量研究提供了相当可靠而便捷的条件,大量的数据信息和语料使研究成果更为客观,更具应用价值。
目前,国内可使用的中介字数据库十分有限。北京语言大学建有“欧美留学生错别字数据库”,但该库至今未开放。根据戴媛媛(2007),该库基于30多万字的外国学生HSK高等考试作文,收集了2000多个错别字字形,但数据库国别只限于欧美学生,学生水平主要是参加HSK高等考试的学生,而且只包含错字和別字两种偏误汉字形式。
另外,台湾师范大学建有“汉语学习者汉字偏误数据资料库”,该库曾经开放,但近年来关闭,由邓守信教授创建于2009年。它收集了2000多个错字字形,并对其偏误类型进行了细致分类,但该数据库收集的只是错字,而且整个系统基于繁体字,字库收集的是单个错字,没有上下文语料,无法查看其语境,并且书写者只限英语母语者。
中山大学“留学生全程性中介字数据库”(下文简称“中介字数据库”)自2016年开始,基于中山大学“汉字偏误连续性书面语语料库”(下文简称“中介语文本库”)建立。“中介语文本库”于2015年建成,包含了60多個国家留学生的初中高等水平学生日常作文语料,目前大概420万字,其重点标注了汉字偏误。利用“中介语文本库”可以检索汉字偏误情况,也能检索词、短语、句子等语言成分。后来,随着对汉字认识的发展,进一步完善细化了汉字偏误标注的内容和项目,增加了似别字和不规范字的标注,细化了错字和别字类型,并且增加了偏误原因标注。以此文本库为基础,抽取各种汉字偏误标注信息,统计频率,人工录入正字相关信息,建立了“中介字数据库”。
“中介字数据库”是指留学生在习得汉字过程中书写的汉字形式的数据库。“中介字”是本研究提出的一个新概念,专指留学生书写的汉字形式,它和“中介语”相对应,是一个独立的系统。“中介字”概念的提出,表明研究视角由传统汉字向外国留学生汉字书写的转变。这里的“中介字”除了汉字,也可以推广到其他文字系统,其他语言文字的二语学习者书写时也会有“中介字”状态。本文以“中介字”命名,尝试引领起对汉字中介状态的系统研究,包括中介字形式、偏误类型、偏误原因等。
“中介字数据库”由错字数据库、别字数据库、似别字数据库、不规范字数据库等4个子库组成,包含了中介字的偏误信息、所在文本信息和对应正字情况等。它们以“正字”为共同字段互相关联,信息共享。截止目前,数据库中包含了3362个正字的30665个错字形式,9151个别字形式,351个似别字形式,15673个不规范字形式。数据库还有方便的检索和统计功能,方便用户查阅使用。这两个库都在不断更新,自建成便面向学界公开使用。
“中介字数据库”属于专项语料库,它既有一般语料库的基本属性和特点,也有作为专项语料库的特别之处。本文以“中山大学留学生全程性中介字数据库”为例,就中介字数据库建设中的若干问题提出一些思考。
1. 语料属性
1.1 语料的真实性和自然性
真实性和自然性是语料库建设最基本的属性。如果语料不真实、不自然,就失去了研究的基础和价值。中介字数据库和一般的文本语料库有所不同,中介字数据库是针对留学生书写的汉字,真实性和自然性主要体现在以下几个方面:
(1)保持学生书写汉字的原貌,尤其是体现出错字的错误特点。正字和别字能直接打出来,容易呈现,但错字要怎么呈现才真实?目前也有语料库采用扫描错字,再切字的方式,但由于每个留学生写字的大小规格不同,切出来的汉字大小不一,有的可能模糊不清。中山大学中介语文本库和中介字数据库对错字采用truetype造字方式,以图片格式保存,这样可以使图片大小一致。由于对错字的主观认识和造字技术水平不同,所造错字和原字之间难免有距离,但我们认为只要在部件位置、笔画关系等这些大的错误特征上保持一致,体现出原错字的错误之处即可,至于原字笔画粗细、书写风格可以适当忽略,因为这些不影响汉字偏误特征的呈现。
(2)体现汉字书写的各种中介形式。除了错字、别字,数据库还根据大量汉字书写实际,归纳出似别字、不规范字,尽量全面真实表现汉字的中介形式。这是留学生汉字书写真实性和自然性的特别体现。
(3)学生用字选字真实自然。因为“中介字数据库”的信息来源于“中介语文本库”,“中介语文本库”来自中山大学国际汉语学院和中文系国际汉语中心留学生的日常作文,学生选词用字时没有考场的压力,用词造句真实自然。同时,为了防止学生在写作中抄袭,语料失真,在收集语料之前,教师都尽量检查学生作文,并且录入语料前避免录入教师修改过、加工过的二手语料,力求反映学生真实水平(张瑞朋,2012)。因此中介字数据库收集的中介字也具备了用字的真实自然性。
1.2 语料的连续性和全程性
1.2.1 连续性
连续性指学生各个学习水平等级是连续的,不是只有单个水平等级。根据张瑞朋(2012),中山大學中介语文本语料库的语料收集了相同学生的初、中、高级水平的语料,具有连续性,来源于该语料库的“中介字字库”也因此涵盖了相同学生不同等级水平汉字书写的状态,具备了“连续性”,可供纵向研究。纵向研究的作用是:
(1)对比不同国家学生的错字、别字等发展过程。不同国家由于书写背景和认知方式不同,错字、别字形状类别和频次的发展变化也不同,根据收集的连续性语料可以考察这一变化。(2)对比不同水平阶段学生的错字、别字及其他中介字形式的书写和数量,考察中介字的发展变化情况,以便为汉字教学提供启发。(3)纵向考察同一母语背景学生在不同阶段汉字书写的发展变化,包括正确用字、偏误汉字的错误类型及比例变化。近年来,对外汉语教学界在这方面成果颇丰。如:鹿士义(2002)、江新(2004)、郝美玲(2018)等。这些研究都是通过实验和小规模收集汉字材料进行。中山大学中介字数据库集中反映外国学生汉字书写现象,将有助于汉字习得与认知研究从一个新视角观察并获取大量真实的数据,深入开展研究。
1.2.2 全程性
全程性主要指汉字书写发展经历形式的全面性,包括错字、似别字、别字、不规范字、正字几种形式。汉字是语言要素之一,像中介语一样,中介字也有其独特系统,是一个渐进发展的连续统。“错字”是不成形的,在连续统的最左端,是汉字习得的最低阶段。别字比错字正字法意识强。根据大量书写材料,我们发现在错字和别字之间还存在“似别字”。此外,还存在“不规范字”。“正字”是目标汉字,在连续统的最右端,是汉字习得的目的形式。从“错字”到“正字”,经历了似别字、别字、不规范字等阶段,反映了留学生习得汉字是一个逐步迈向目标汉字的渐进的连续统过程,也反映了中介字的复杂性和特殊性。
数据库包括了各种中介字的书写情况,尤其使处于中间阶段的中介字状态(似别字、不规范字)的界定具备一定可操作性,一定程度上反映了中介字的发展过程和习得顺序,为构建汉字习得模型,强化汉字习得机制提供了基础,对于全面研究留学生汉字习得情况,提升汉字教学效果有重要意义。
2. 语料标注
语料标注是“语料深加工的重要环节,也是一个语料库建设水平的重要标志”( 刘连元,1996)。这说明语料标注的内容与质量决定了一个语料库的功能与使用价值。对于一般语料库中词语、短语级别的标注,学界讨论很多。关于汉字标注,目前探讨比较详细的是张宝林(2019:69-87)。这本书对中介语语料库中字、词、短语等各级语言单位标注规范的确定有很大贡献,但这本书的汉字标注规范主要是“为‘通用型’(语料库)服务的,而不是服务于汉字的专项研究”(张宝林,2019:72)。不同类型的语料库标注深度和标注项目不同。同样是汉字标注,通用型语料库“只是从整体角度指出了汉字偏误类型,在各类别下不再分细类”(张宝林,2019:72)。专门的汉字数据库则需要对各类偏误汉字进行尽可能细致的研究,标注方式和内容也不同于通用型语料库。中山大学留学生全程性数据库是专门的汉字数据库,在汉字偏误标注方面也更细致、更全面。在建设数据库过程中,我们遇到了一些问题,也总结了一些经验,下面尝试讨论归纳。
2.1 标注项目和规范
中介字的偏误和母语者的写字偏误不能完全等同。母语者的写字偏误主要是错字和别字,但中介字的偏误有其特殊性和复杂性。汉语二语学习者和母语学习者有不同的文字背景和汉字习得机制,在书写汉字时除了错字、别字,还有其他中介字形式。本文提出了“似别字”“不规范字”这些中间状态。 因此,本文的中介字标注涉及错字、似别字、别字、不规范字几种形式。在标注中,我们尽量给错字、似别字、别字和不规范字各自设立互相区别、不交叉不重叠的类别,使其具有一定可操作性。
错字偏误原因包括形似、形旁相近、声旁相近、基本汉字书写未掌握、母语影响、上下文影响、受合成词影响等7种。其中上下文影响(张瑞朋,2015)和受合成词影响是数据库吸取的偏误原因的新因素。
别字标注包括正字、别字、偏误原因。偏误原因包括音同音近、形近、义近、音形皆近、音义皆近、形义皆近、音形义皆近、音形义无关、上下文影响、双字词内部混用等10种。
似别字标注包括正字、似别字。似别字是本研究提出的一个新概念,它是错字和别字之间的一种中间状态。错字是由于学生没有掌握汉字形体,从而写成了汉字中不存在的字;别字是书写正确但使用不对的字;似别字则是学生没有掌握汉字形体,不会书写,但误打误撞而写成了汉字中存在的字。因为它确实在汉字中存在,所以不能算“错字”;但它又不是因为使用错误而导致,学生头脑中并没有这个字,所以不能算“别字”。
似别字不同于别字,在教学中要区别对待。别字和正字在音、形、义上可能相关,似别字和正字一般只有字形相关。别字在学生的心理词典中是单独储存的,学生书写别字,往往是因为对正字和别字两个字的整体混淆。似别字则大多是因为笔画或部件出错,误打误撞写成了汉字中存在的字,它在学生的心理词典中没有清晰独立的单独储存位置。因此,在教学中似别字和别字要采用不同的纠错方法。对于别字,学生一般学过,教师可以从音、形、义几方面和正字做整体对比,使别字和正字在学生心理词典中牢固储存。对于似别字,具体分两种情况:一是似别字和正字使用频率相差较大,可以确定学生没有学过,比如,爱—*爰,西—*酉,仇—*仉。教师在教学中可以重点指出书写错误之处,不用全面比对两个汉字。还有一种情况是,似别字使用频率和正字相当,学生可能学过也可能没学过,要靠教师根据实际情况判断。比如:平—*采、人—*入。在实际教学中,对于学生学过的汉字,教师可以像“别字”一样处理,从音、形、义几个方面整体对比,帮助学生识记汉字。对于学生没学过的,则像第一种情况,强调其错误之处即可。数据库中把有似别字可能的汉字都标注出来,用户在教学和学习时要注意分辨。似别字现象在数据库中并不少见,应该引起注意。
不规范字标注包括正字、不规范字。根据现行语言文字规范,不规范字包括错字、别字、繁体字、异体字、旧字形。错字属于书写不规范字,其余属于使用不规范字。这是一种广义的不规范字。北京语言大学“全球汉语中介语语料库”和“HSK动态作文语料库”都对广义的不规范字进行了标注。本文说的不规范字是狭义的,专指书写不规范字。汉语二语学习者的汉字书写形式复杂多样,书写不规范除了“错字”,还有一些中间状态。如果对其总结分类,加强引导,学生会逐步走向规范,更好地书写汉字。
这里需要说明的是受宋体印刷体影响的不规范字。根据施春宏(2020:135),宋体以手写楷书为基础发展而来,在发展过程中,又吸收了篆书和隶书的某些特征,因此有些字的印刷体和手写体在字形上存在分歧。目前大部分教材使用印刷字体,有的初学者在学写汉字时,会模仿宋体字形抄写,导致写出的汉字字形呆板僵硬,甚至笔画出现错误。因此,在汉语教学中,特别是面对初级汉语学习者,在电脑屏幕或印刷资料上呈现的印刷字体,更适合采用与手写字体接近的楷体,以利于学习者模仿。同时,教师要了解哪些汉字的宋体和手写体不同,在学生出现此类不规范字时,以便及时指出原因,帮助改正。
在设定上述类别时,我们注重几个问题:一是每个类别的语言现象要足量,如果不足量,标注出来也没有多少实用价值。二是不同中介字形式内部类别之间要界限明确,互相区分。比如:错字几个类别之间,不规范字几个类别之间要容易区分。三是不同中介字形式之间要区别开来,要有切实可判断的标准,尤其是错字和不规范字之间的区分会有模糊地带,规范设置要尽量明确。特别是错字的部件错位、笔画错位和不规范字的部件位置不规范、笔画位置不规范之间的区分,达到什么程度算是不规范,达到什么程度算错,数据库有较明确划分和规范。比如,对于部件错位和部件位置不规范的区分,目前主要以是否导致汉字本身结构关系改变为准。
2.2 标注方法和格式
关于语料标注方法,张宝林(2013)分为“只标不改”和“既标且改”。这两种方法的区别主要是是否涉及汉字偏误,是否有利于分词进行。“只标不改”是只标注出错误,但不改正,较适用于词及以上级别语言成分。“既标且改”是要把错误的语言成分改正过来,这种方法更适合于中介汉字的标注。把正确汉字写出来,可以提高分词的正确率,同时方便偏误汉字和正确汉字之间的对比以及频率统计。具体标注格式示例如下:
似别字:<爰>SBZ【爱】(<>中是似别字,“SBZ”表示似别字,黑括号中是正字。)
别字:得意<扬>BZ【洋,偏误原因:音同音近】(<>中是别字,“BZ”表示别字,黑括号中是依次是正确汉字、偏误原因)
2.3 偏误类型和原因的标注
上述中介字项目的标注内容大都包括正确字、偏误类型、偏误原因。其中偏误类型和偏误原因是标注过程中较难判断和争议较多的。如果存在多个偏误类型或偏误原因,是单标还是多标?判断顺序是怎样的?对于词汇、短语、句子、篇章类的偏误,大多语料库采用“从大到小,一错一标”,认为语料标注应尽量简化,不宜过于复杂,“一错多标”只能有限使用(张宝林,2013)。汉字偏误标注是否也是这样?这要根据汉字实际情况来决定。
2.3.1 偏误类型的标注
下面谈谈标注过程中遇到的两类问题。
(1)一个错字存在多个偏误类型
这里的多个偏误又可分为:多个不同层级偏误和多个同一层级偏误。下面分别论述。
(2)对同一偏误现象存在不同理解
因为标注由人做,就带有人为的主观认识活动。在汉字标注中存在对某一偏误现象有不同理解的情况。比如:“被”写为“”,可以看作“礻”遗漏了“丶”,也可看作是“衤”被“礻”误代。如果书写者不熟悉“礻”这个部件, 书写时因为遗漏 “丶” 而恰巧写成 “礻”,则应标注笔画遗漏;如果书写者熟悉这两个部件,因混淆部件而发生错误,则应标注部件误代。这其中涉及到书写者的心理活动,但大规模数据库标注不可能对汉字书写者进行一一心理活动调查,即使调查能够进行,书写者有时也说不清自己为什么这样写。这种涉及对汉字偏误现象的不同理解时,采取全标,把可能的信息全部提供给用户,由用户进一步取舍判断。
综上所述,和词汇、短语、句子等语言单位不同,汉字由不同构件组成,可能不同构件存在多个偏误,也可能对同一偏误现象存在不同理解,两种情况都可采取全标。这说明汉字偏误标注类型适合“一错多标”。这样处理可以发现不同的偏误类型,这对于全面、准确地认识汉字偏误非常重要。
2.3.2 偏误原因的标注
偏误原因的标注主要是针对错字和别字。偏误原因可以分为外部因素和汉字内部因素两方面。错字偏误原因包括3种外部因素:受上下文影响、受母语文字影响、受原合成词影响;4种汉字内部因素:形似、形旁相近、声旁相近、基本汉字书写未掌握等。别字偏误原因包括2种外部因素:受上下文影响、原合成词内部混用;8种汉字内部因素:音同音近、形近、義近、音形皆近、音义皆近、形义皆近、音形义皆近、音形义无关。
在实际标注过程中,我们先从外部因素考察,再从汉字内部特点考察。比如,在标注别字偏误原因时,先看是否存在受上下文影响或合成词内部混用这些外部因素;如果没有,再根据别字和正字之间音形义的关系来判断。如果明显同时存在多方面偏误原因,可以全标。比如:批评—批*抨,从外部因素看,别字“抨”受上下文影响;从别字和正字关系看,是音形义皆近,两种偏误原因可以全标。
值得一提的是,数据库还标注了一种可能的新的偏误原因:受原合成词影响。有的错字和别字形成可能跟原合成词语境有关。比如:“婚礼”写成“*结礼”,跟“结婚”这个合成词语境有关,学生可能没有分清“结”和“婚”。“缺点”写成“缺*”,“”的书写可能跟“点心”这个词有关,学生把两个汉字杂糅导致出错。这种偏误原因的具体论证参看张瑞朋(2021)。数据库把有这种倾向的偏误因素标注出来,方便用户调查研究。
可以看出,偏误原因的形成有多方面原因,偏误原因的标注又和标注者的理论认识水平有关。这里的标注也只提供一种可能性,供用户参考。
2.4 标注的科学性和渐进性
语料标注的科学性也关系到语言学界对某个项目的理解是否清楚,是否基本统一。如果理解很不一致,则很难标注。具体对策是:先标注成熟项目;逐步增加标注项目;标注项目确定后,可设计标注规范和便于检索的表达法,进而制作辅助标注的工具软件,以提高标注的准确性和效率。也就是说,语料库的标注应该是渐进的,是随着学术的发展以及建库者思想的深化而逐步细化、深入发展的,而不是一劳永逸,一成不变的。
比如,语料库标注项目的变化。原先中介语语料中有字词语法偏误标注,后来集中力量建设汉字偏误标注的文本语料库,再到现在构建专门的中介字数据库。语料库系统三个入口、三个版本,既体现了语料库的不同目的和适用性,也体现了建库者和标注者对汉字偏误的认识深化。
又比如:对中介字标注项目和内容的变化。在建库初期,当时学界对于留学生别字和错字研究成果较少,为了避免分类过细导致误判,我们把错字和别字统一标为CBZ。后来随着研究进展,把错字和别字分开标注。到今天,数据库对错字和别字类别都进行了细化,设计了详细的标注规范,增加了偏误原因的标注,吸收了最新偏误原因成果;并且增加了似别字和不规范字的标注。首次提出了“似别字”的概念,并对其进行界定标注,还对不规范字进行细致分类并且标注。这里包含了学术界的新成果和进展,也体现了建库者不断深化发展的学术观念。当然,这些界定和标注也会随着将来学术水平的发展而变化。
这里需要提出的是,语料标注在很大程度上是标注者对书写者客观书写材料的主观判断。当书写者的客观书写材料可以从多方面解释,而又无法从书写者本人求证时,容许几种可能性都标出来也是一种科学性的表现。比如,前文对偏误类型和偏误原因的多项标注,提供了多种可能,也就离事实真相更近一步。
任何语料库的加工和标注都体现了当时的学术理论背景、建库者的观念和认识,任何人都不可能制定出超出时代和本人学养的所谓全面的标注项目,没有绝对全面和正确的标注项目。
3. 数据库建设框架和用户功能
3.1 建设框架
中介字数据库的中介字字段内容来自已建成的中介语文本库。数据库基本框架如下图:
从图1可看出,错字、似别字、别字、不规范字四个子库都包括了正字信息(“正字”、“形声字、“结构”字段)、中介字信息(“频次”、“类型”、“偏误原因”字段)、中介字上下文信息(“上下文”字段)和书写者信息(“母语”、“水平等级”字段)。这些信息既有利于了解中介字本身情况,又可看到中介字的上下文语境,同时也有利于了解书写者情况,可供多角度研究汉字。
3.2 用戶功能
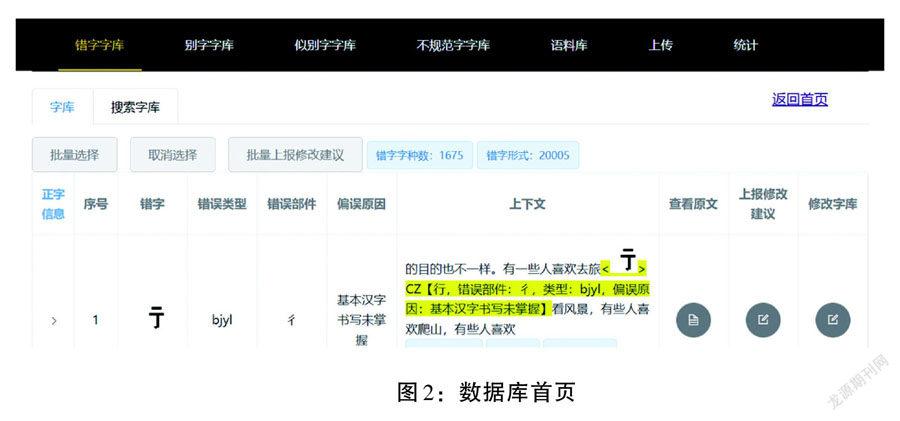
根据上述框架,在数据库首页相应包括错字数据库、别字数据库、似别字数据库、不规范数据库、语料库、统计等几个选项卡。点击可进入各个子库。首页如图2所示:
可以看出,用户不仅可以检索数据库,查看原文,还可以对于数据库中的错误信息“上报修改建议”,数据库由指定专业人员审核后修改。因此,数据库不光在应用方面对外开放,在建设修改方面也吸纳用户建议。下面重点介绍检索功能和统计功能。
3.2.1 检索功能
用户可以点击进入各个子库中详细检索。比如:错字数据库检索界面如图3。
如图3所示,用户可以根据正字、偏误原因、错字类型、错误部件、正字结构、造字法、笔画数等相关信息分别检索。在上图“偏误原因”“所有错字类型”“所有结构”“所有造字法”下拉框中都罗列了相应全部信息。用户根据自己需要输入或选择相关信息即可获得大量数据。比如,如果用户想调查“部件错位”类错误,只需选择相关类型,便可穷尽统计所有部件错位的错字数量,并可查看书写者的信息、偏误字所在上下文、对应正字等信息,根据研究需要再分类分析。如果用户想调查因“受母语文字影响”而出错的汉字,在偏误原因中选择后,即可检索到全部此类偏误汉字信息。
需要指出的是,因数据库中的错字是图片,目前不能支持图片检索,在以后的语料库建设中我们将引进林民等(2009)的“汉字字形处理技术及字形分析工具软件”。使用者只要具有图形认知能力就可以使用该工具描画输入各种汉字(包括错字、异体字、拼合字等),并且直接输入错字或错误部件就可以进行检索,还可对某些错误部件统计分析,并能利用计算机进行字形比对分析。
点击图3页面的“语料库”,就会进入“中介语文本库”,并可以进行各种字词、短语、句子等语言成分的检索,详见张瑞朋(2012)。
别字字库提供了偏误原因、别字、正字等搜索项目。似别字、不规范字数据库也分别根据其标注项目提供了相关搜索功能。检索方法类似错字数据库,因篇幅限制,不再赘述。
3.2.2“统计”功能
上图3中的“统计”功能汇总了各数据库信息,可以统计每个汉字的错字、似别字、别字、不规范字各种形式的总频次和总使用量,并自动计算所占比例。界面如下图:
如果点击汉字后面的“分布”和“数据”,可看到四种偏误形式在“母语”“性别”“水平等级”中的具体分布和数据。如:点击“我”后的“看分布”,会统计出“我”在不同性别、母语、水平等级中的偏误形式分布情况。点击“看数据”,可看到“我”的详细使用情况。这对研究每个汉字的正确使用和偏误情况非常便利。王骏(2011)曾说,汉字教学和研究要取得实质突破,需要穷尽性研究每个汉字的书写和具体使用特点。本数据库的建设为该任务的完成提供了可能。
“统计”功能还为汉字大纲的制定和教材编写提供了数据依据。想知道哪些汉字出错率高、别字频率高,可以根据前面序号排序筛选。序号靠前,偏误率高;序号靠后,偏误率低。大纲制定和教材选字以此为依据,可以提高编排科学性。
4. 余论
建立一个包括各个水平等级的错字、似别字、别字、不规范字、正字的中介字数据库,既可对留学生汉字书写状况进行横断面研究,也可对汉字书写进行纵向和渐进性研究。数据库涵盖多种母语背景,可以研究不同母语背景学生的汉字输出及偏误情况,并做对比研究,为国别化汉字研究和汉字教学提供数据支持。
一切研究最终都要服务于教学才能体现其最终价值。数据库的建立除了对汉字研究有重要作用,也可供教师教学时参考。比如:教师在教学前可以先查阅数据库,哪些字出错频率高,哪些部件容易写错,某个国别学生容易发生哪些汉字错误。在备课时做到心中有数,教学中做好预防和引导。在偏误发生后,教师可以利用语料库中提供的语料为学生编制练习,帮助学生改正错误。从偏误发生前的预防和教学引导到偏误发生后的教学练习,中介字数据库都可以提供多样的一手材料。
[参考文献]
戴媛媛 2007 “欧美学生错别字数据库”的建立和基于数据库的错字别字考察[D]. 北京语言大学硕士论文.
江 新 2004 拼音文字背景的外国学生汉字书写错误研究[J]. 世界汉语教学(1).
郝美玲 2018 高级汉语水平留学生汉字认读影响因素研究[J]. 语言教学与研究(5).
林 民,宋 柔 2009 汉字的笔段网格字形描述及字形比对算法[J]. 计算机辅助设计与图形学学报(2).
刘连元 1996 现代汉语语料库研制[J]. 语言文字应用(3).
鹿士义 2002 母语为拼音文字的学习者汉字正字法意识发展的研究[J]. 语言教学与研究(3).
施春宏 2020 汉语基本知识(汉字篇)[M]. 北京:北京语言大学出版社.
王 骏 2011 外國人汉字习得研究述评[J]. 华文教学与研究(3).
张宝林 2013 关于通用型汉语中介语语料库标注模式的再认识[J]. 世界汉语教学(1).
——— 2019 汉语中介语语料库标注规范研究[M]. 北京:北京大学出版社.
张瑞朋 2012 留学生汉语中介语语料库建设若干问题的比较研究[J]. 语言文字应用(2).
——— 2015 上下文语境对留学生汉字书写偏误的影响因素分析[J].语言教学与研究(5).
——— 2021 英美高级学生别字书写研究及理论特点蕴含[J].语言教学与研究(5).
On the construction of an interlanguage database of Chinese characters of
international students: The case of Chinese character database of
international students of Sun Yat-sen University
ZHANG Ruipeng
(Chinese Department, Sun Yat-sen University, Guangzhou, Guangdong 510275, China)
Key words: interlanguage character database; construction; corpus attribute; tagging; function
Abstract: At present, there are relatively few researches on constructing an interlanguage database of Chinese characters of international students. Taking as an example of the whole-process interlanguage database of Chinese characters of international students in Sun Yat-sen University, this paper discusses some problems in the process of the construction of the database: the realness and naturalness of corpus which is the basic property, the continuity and wholeness of corpus which is beneficial to longitudinal and progressive research, and the tagging content of intermediate characters which should include the tagging of wrong characters, similar characters, different characters and non-standard characters. The tagging methods and norms of error types and error causes are discussed in detail. At the same time, it is emphasized that the tagging should follow the scientific and progressive nature. The paper also introduces the function and the value of database and puts forward some useful methods and suggestions in the process of database construction.
【责任编辑 刘文辉】
[收稿日期] 2021-03-17
[作者简介] 张瑞朋,女,中山大学中文系副教授,主要从事语言学及应用语言学研究。电子邮箱:36278393 @qq.com。
[基金项目]国家社科基金项目“留学生全程性中介字字库建设及汉字习得研究”(16BYY106)
猜你喜欢
中华诗词(2022年6期)2022-12-31 06:41:24
中国外汇(2019年18期)2019-11-25 01:41:56
电子制作(2018年14期)2018-08-21 01:38:28
人大建设(2017年10期)2018-01-23 03:10:17
民生周刊(2017年19期)2017-10-25 10:29:03
中国科技论坛(2017年7期)2017-07-25 08:49:53
妈妈宝宝(2017年2期)2017-02-21 01:21:24
国际汉语学报(2016年1期)2017-01-20 08:21:20
中国中医药现代远程教育(2014年22期)2014-03-01 04:32:55
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:54
