
基于改进SARSA算法的直升机CGF路径规划
2022-06-04 12:25:26姚江毅李雄伟王艳超
兵器装备工程学报 2022年5期
姚江毅,张 阳,李雄伟,王艳超
(陆军工程大学石家庄校区 装备模拟训练中心,石家庄 050003)
1 引言
计算机生成兵力(computer generated force,CGF)指的是由计算机创建并能对其全部或部分动作和行为实施自主控制或指导的虚拟作战兵力对象,构建CGF的核心任务是对战场环境中作战实体的行为进行建模。CGF路径规划是CGF行为建模中的重要环节,既是任务规划、协同等行为的基础,又是机动、冲击等动作的前提,因此研究CGF路径规划问题对CGF行为建模具有重要意义。现有路径规划问题常采用遗传算法、蚁群算法、粒子群算法、A算法以及人工势场法等方法进行研究。但现有方法在路径规划的过程中通常要求环境模型是完全可知的,需要提前获取全局精确信息,而复杂多变的战场环境要求CGF实体能够针对环境变化实时生成应对策略,因此将现有方法直接应用到CGF路径规划中具有一定局限性。
强化学习不需要完备的先验知识,学习者面对陌生环境能够通过与环境的动态交互自主获得最优行为策略,因此将强化学习应用到CGF路径规划中具有一定优势。本文针对军用仿真系统中CGF实体路径规划问题进行研究,基于红蓝对抗系统构建直升机CGF突袭雷达阵地模型,结合人工势场原理构建动态奖赏函数对强化学习SARSA算法进行改进。实验表明改进SARSA算法性能有明显提升,能够为直升机CGF规划出安全路径。
2 模型构建
2.1 问题描述
某红蓝对抗系统中包含以下作战单元:
1) 蓝方直升机CGF:搭载有射程为8 km的空地导弹,告警装置能够捕获雷达波束从而判断自身是否被雷达锁定。蓝方CGF的任务是突袭50 km以外的红方雷达阵地,其飞行过程坠机概率与飞行高度相关,可表示为
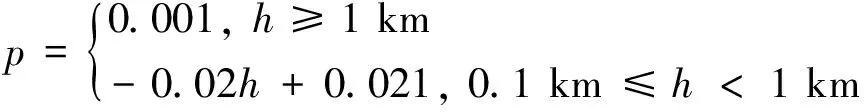
(1)
由于军用直升机坠机概率数据通常是保密的,式(1)采用的是简化后的概率模型。
2) 红方雷达阵地:阵地包含雷达和防空武器系统,防空导弹的射程为10 km。红方受训人员可以操控雷达及时发现蓝方CGF并锁定,待蓝方CGF进入防空导弹射程后将其击毁。已知雷达侦测半径最大为45 km,由于受到地面反射杂波以及探测角度等因素的影响,通常雷达难以探测到低空飞行的目标,雷达能够探测到蓝方CGF的概率与蓝方CGF同雷达间距离以及蓝方CGF的飞行高度均相关,具体可表示为

(2)
由式(2)可得雷达探测概率模型如图1所示。
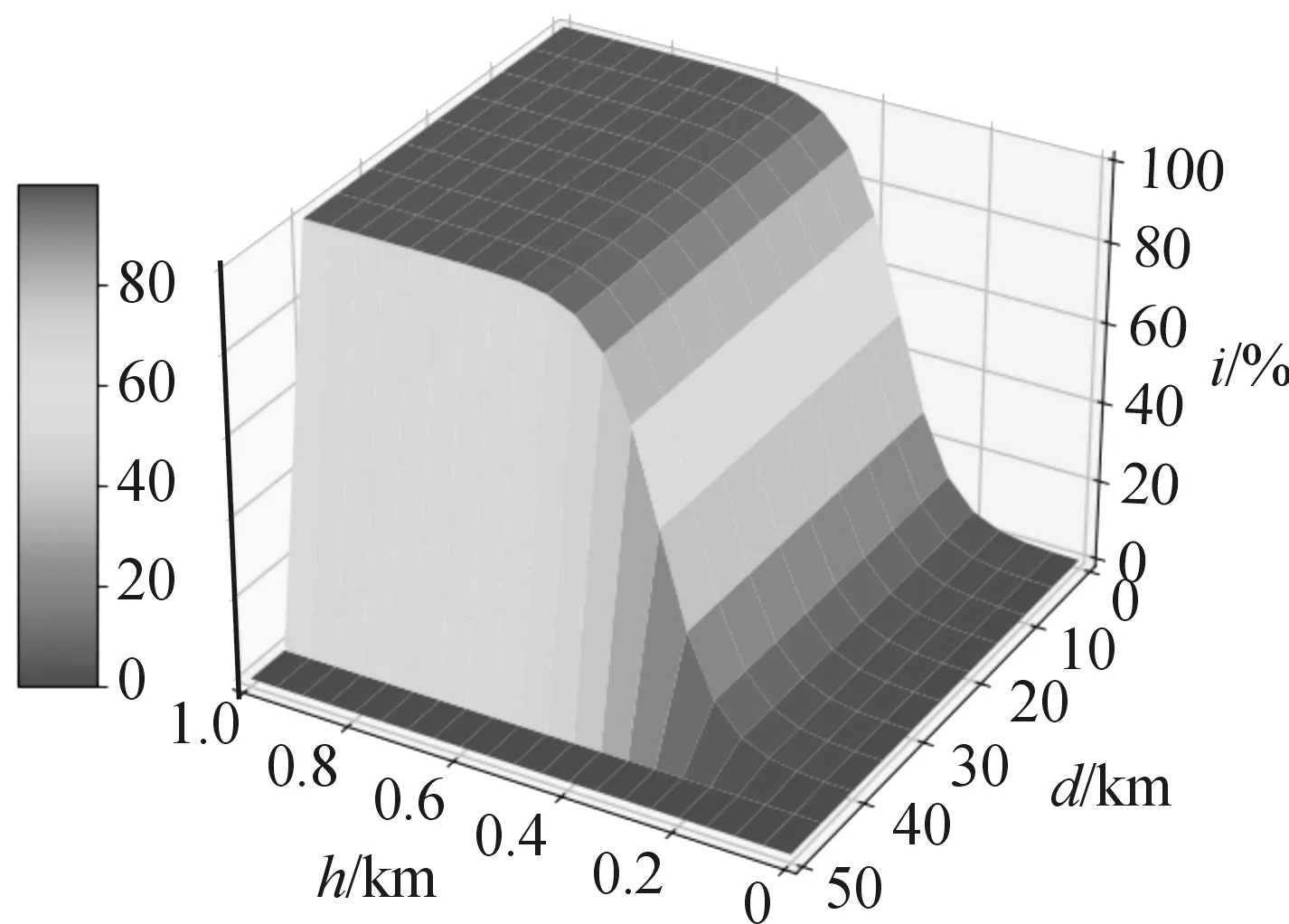
图1 雷达探测概率模型示意图
红蓝对抗系统中,蓝方直升机CGF是红方受训人员的打击对象,理想的蓝方CGF应具有足够的智能性,能够随着红方受训人员的训练水平提升而提高自身能力,从而进一步砥砺受训人员。目前蓝方CGF建模通常采用有限状态机、行为树、规则脚本等知识工程方法,构建的蓝方CGF行为方式相对固定,红方人员经过多次观察后便能掌握其行动规律,不利于进一步训练。此次研究目的是结合强化学习算法使蓝方直升机CGF拥有自主学习能力,能够根据系统环境信息平衡坠机概率和雷达探测概率,选取适当高度飞行自主规划出突袭安全路径,从而提高其智能性。
假设红蓝双方攻击时均能保证百分百命中率,则蓝方胜利的条件是至少飞抵距红方雷达阵地8 km的空域,并且在飞行过程中蓝方CGF应避免被红方雷达侦测到。据图1可知,蓝方CGF在雷达探测范围之外飞行时不会被发现,在雷达探测范围内时,如果在0.2 km以下高度飞行也能够躲避雷达探测。因此,蓝方CGF可以利用图中探测概率较低的区域进行突袭。
2.2 战场建模
对战场环境建模是CGF路径规划的前提。战场建模是将战场环境中与CGF路径规划相关的元素抽象为适合算法输入的内部模型信息,从而将战场区域划分为可通行区域和不可通行区域。将战场空间栅格化是研究路径规划问题常用的方式之一,栅格化可以将战场空间中的连续信息离散化,便于强化学习算法的输入,且离散化后的信息便于存储和维护,本文采用栅格法进行战场环境建模,具体建模情况如下。
结合系统信息,采用50×10的栅格对战场环境进行仿真,利用二维直角坐标即可确定战场环境中相关元素空间位置,并对每个栅格从左至右,从上到下依次标号得到图2。
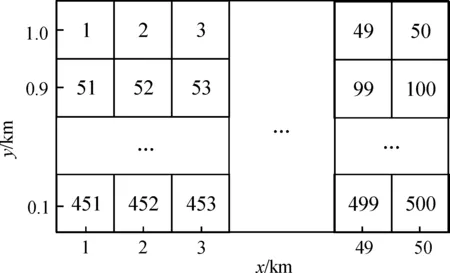
图2 栅格战场环境示意图
图2中每个栅格包含飞行高度和飞行距离二维信息,方格内隐含雷达探测概率和环境影响因素等。蓝方直升机CGF在栅格内运动方向为前、后、上、下4个方向,飞行过程中如果被红方雷达侦察到或发生坠机事件则视为任务失败,若蓝方CGF和红方雷达阵地距离小于8 km则视为突袭成功。
3 SARSA学习算法分析与改进
3.1 传统SARSA学习算法
强化学习是从环境状态到动作映射的学习,目的是让智能体(Agent)的动作从环境中获得的累积奖赏最大,从而学习到最优策略。在强化学习算法中,SARSA算法是一种采用实际值进行迭代更新的在线学习算法。SARSA算法迭代更新时需要借助五元组(,,+1,+1,+1)进行,其中表示当前状态;表示当前状态下选择的动作;+1是选择动作后获得的奖赏;+1和+1则分别代表后续的状态和动作,具体更新方式如下:
(,)=(,)+(+1+(+1,+1)-(,))
(3)
式中(,)表示状态下选择动作的期望奖赏值(表 1),∈(0,1]为学习率,用来控制学习过程中未来奖赏的占比,∈(0,1)为衰减因子,表示未来奖赏的衰减,随着和的增大,算法收敛速度会加快,但是震荡也会增大。对于式(3),如果每个状态和动作被无限访问,且参数取合适值,那么值就会最终收敛到固定值。
按照上述迭代公式,算法会形成状态与动作对应的Q表,最终Agent可按照Q表根据贪婪策略来进行动作决策。贪婪策略定义探索因子,当随机数大于,Agent随机选择可选动作;而随机数小于时,Agent基于Q表选择当前状态下对应奖赏最大的动作,因此随着增大,Agent会变得愈发“短视”,不利于进一步探索次优动作。对于参数、和的取值,要根据实际情况经过探索最终确定。表1为4个状态、2个动作的Agent生成的Q表示例。

表1 Q表Table 1 Q table
3.2 传统SARSA学习算法分析
为使SARSA算法顺利更新,需要设置合适的奖赏集合,通常情况下设置Agent完成任务时获得奖赏,其他状态则无奖赏。对于此次研究,系统中直升机CGF(Agent)从初始状态开始探索时存在探索状态空间爆炸的问题,假设最简单的情况下,Agent需要50个状态步到达目标空域,每走一步均可做4种选择,因此50步可做出的选择组合为4,如果采用上述奖赏设置方法,则仅在Agent到达目标区域时的状态步才会获得奖赏,在此之前的49个状态步均为无效状态,这种奖赏设置方式会导致算法收敛困难。
对于上述问题,可以通过奖励塑造方式来解决。奖励塑造指的是利用先验人工知识来设计附加奖励函数从而引导Agent完成期望任务。由先验知识可知,此次模型中直升机CGF(Agent)的后退和上升高度动作是相对无效的动作,结合奖励塑造的思想可以对这2个方向的动作进行约束,并且在Agent每完成一个状态转换且自身安全时都给予奖赏,如果完成状态转换后发生坠机或者被敌方雷达发现则给予惩罚,这种奖赏规则能够克服稀疏奖励引起的系统发散问题。但是引入人工先验知识容易使算法陷入局部最优,且人工设计奖赏函数的过程繁琐效率较低,为了进一步优化解决方式,本文将结合人工势场法原理构建动态奖赏函数对SARSA算法进行改进。
3.3 改进SARSA学习算法
人工势场指的是战场空间在障碍物和目标点的共同作用下会形成一个虚拟力场,其中障碍物会被斥力势场所包围,其产生的排斥力会随着Agent与障碍物距离的减小而增大,排斥力的方向是背离障碍物的,而目标点则会被引力势场所包围,其产生的吸引力会随着Agent与目标位置的接近而减小,吸引力的方向则指向目标点。最后将战场空间中的障碍物和目标点所产生的势能求和,沿着势能函数梯度下降的方向就可以规划出无碰路径。
结合上述原理,引入动态奖赏机构对SARSA算法进行改进。对于SARSA算法,假设目标点对Agent既有引力作用也有斥力作用,且引力随着Agent 与目标位置的接近而增大,斥力则随着Agent与目标位置的接近而减小,可引入动态奖赏机构将目标点对Agent引力与斥力作用分别转化为Agent执行动作后得到的奖赏和受到的惩罚,引入动态奖赏函数:
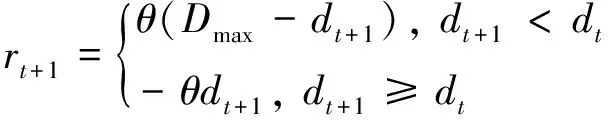
(4)
式中:∈(0,∞)为奖赏系数,为当前状态时Agent和目标距离,+1为后续状态Agent和目标距离,为取值大于任意位置Agent和目标距离最大值的常数。
由式(4)可知,在Agent每次位置发生变化后,如果离目标更近,则可获得奖赏,如果离目标更远,则会受到惩罚(负奖赏),这与强化学习的基本原理一致。分析奖赏函数可知,Agent与目标位置较远时,在负奖赏的约束下会快速向目标点靠近,而随着Agent靠近目标点,负奖赏的约束能力逐渐减弱,正奖赏的激励作用增强,Agent可以在靠近目标点得同时适当探索次优动作(采取次优动作不会受到大力度惩罚),从而顺利规划出最优路径。改进SARSA算法学习框图如图3。
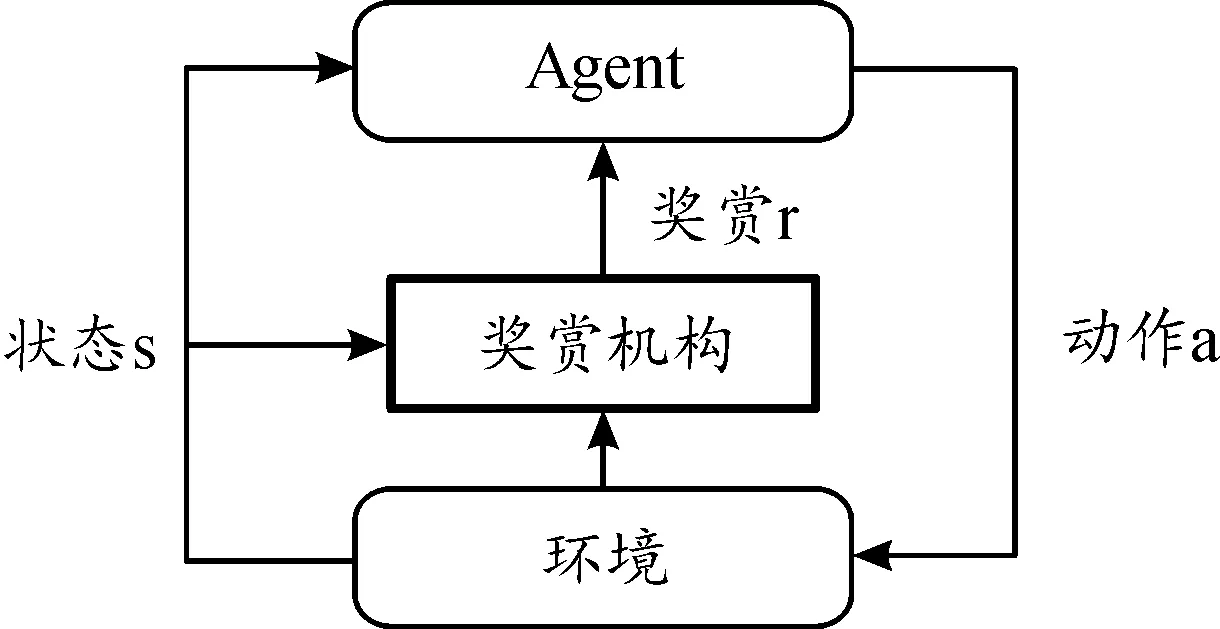
图3 改进SARSA算法学习框图
改进SARSA算法的主要改变是在Agent的学习过程中引入动态奖赏机构,Agent执行动作后并不会立即得到奖赏,而是需要待奖赏机构结合环境信息和Agent的状态变化情况生成实时奖赏,生成的奖赏值能够反映出Agent当前状态与任务目标之间的关系。与采取奖励塑造方式人工设计得奖赏函数相比,此次改进能够简化奖赏函数设计过程,提高效率,且动态奖赏函数继承了人工势场法良好平滑得控制性能,相对人工设计的固定奖赏而言能够根据连续预估得代价场信息进行优化搜索,从而具有更为平滑的奖赏累积过程。改进SARSA算法具体流程如算法1所示:
1改进SARSA算法
1) 初始化:(,)=0,∀(,)∈×
2) repeat (对于每一个迭代回合)
3) 初始化状态
4) 状态下,根据贪婪策略选择动作
5) repeat (对于回合中的每一步)
6) 采取动作,获得后续状态+1
7) 比较状态和状态+1获得奖赏+1
8) 在状态+1下,根据贪婪策略选择动作+1
9)(,)=(,)+(+1+(+1,+1)-(,))
10)←+1,←+1
11) end repeat (为终止状态)
12) end repeat (训练结束)
13) 输出Q表
4 仿真实验与分析
4.1 算法对比分析
为了验证改进SARSA算法性能,基于本文构建的模型环境选择传统SARSA算法和改进SARSA算法进行对比实验。结合栅格战场,将Agent当前状态(飞行高度、飞行距离、是否坠机和是否被雷达侦察到)做为算法输入,直升机CGF(Agent)在栅格内运动方向为前、后、上、下4个方向,分别用F、B、U、D表示,这样此次训练形成的Q表容量为500×4,Agent起始位置在(1,1.0)处,雷达位置为(50,0.1)。按照算法1流程,算法完成初始化得到Q表后,结合当前Agent状态信息根据贪婪策略选择相应动作,动作执行完毕得到对应奖赏对Q表进行更新,待迭代完成得到经过训练的Q表,Agent依据训练过的Q表行动便能得到规划路径。此次对比实验的目的是验证改进SARSA算法性能,因此2种算法均采用相同参数,其中学习率为0.01,衰减因子为0.1,探索因子为0.9,传统SARSA算法奖赏函数表示为
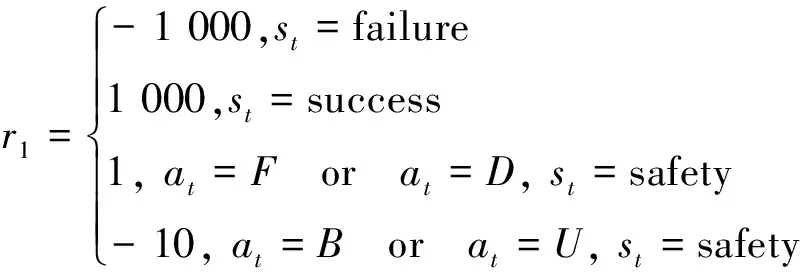
(5)
改进SARSA算法奖赏函数表示为
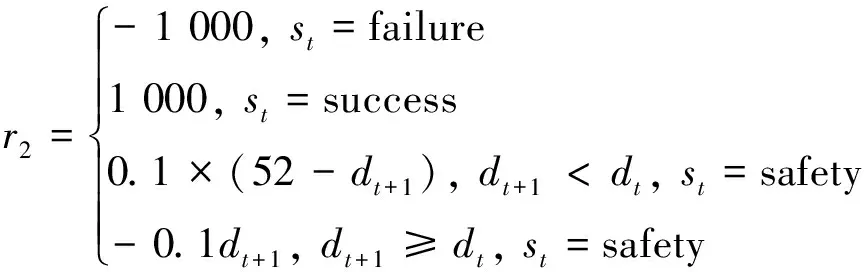
(6)
式中: failure代表直升机CGF坠机或者被雷达发现,success和safety分别代表直升机CGF完成任务以及自身安全,对比式(5)和式(6)可知传统SARSA算法通过奖励塑造方式对Agent动作进行了约束,改进SARSA则采用了动态奖赏。在上述参数下分别对2种算法进行1 000次迭代训练,选择算法收敛时所需迭代次数和经过训练CGF完成任务的成功率两个指标对算法优劣进行评价。为消除实验误差,每种算法各进行5次实验,并对实验结果进行平均处理,得到表2、表3。
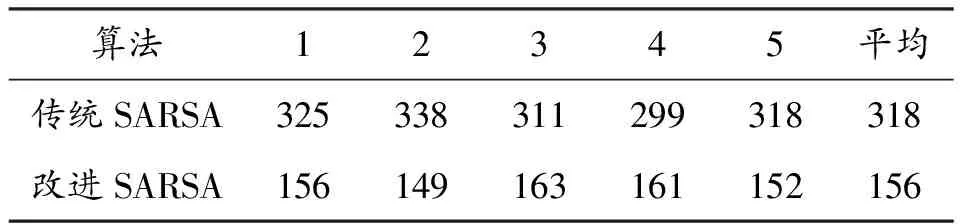
表2 算法收敛所需迭代次数
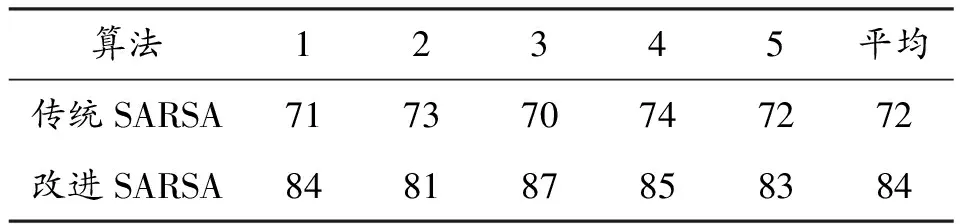
表3 完成任务成功率
对比实验结果可知,收敛所需迭代次数方面,改进SARSA算法收敛时所需迭代次数是传统SARSA算法的一半,能够以更少迭代次数收敛。完成任务成功率方面,经过1 000次迭代,改进SARSA算法完成任务成功率平均为84%,传统SARSA仅为72%,成功率提升12%,表明改进SARSA算法拥有更好的训练效果。
改进SARSA算法收敛速度快的原因在于路径规划时,奖赏机构能够根据Agent状态实时生成动态奖赏,激励Agent快速向目标位置靠拢,提高了算法训练效率。在动态奖赏的作用下,改进SARSA算法能够综合环境信息,探索出最优飞行高度进行突袭,从而有效提高完成任务的成功率。
4.2 路径规划实践
为了使Agent能够充分利用模型环境信息,利用改进SARSA算法对Agent进行十万次训练,训练结果如图5所示,图5中横坐标为算法迭代次数,纵坐标为直升机CGF(Agent)完成突袭任务的成功率。由图5可知经过10万次训练Agent完成突袭任务的成功率能够稳定在95%以上,能够满足作战仿真需求。训练完成之后,将直升机CGF(Agent)完成突袭任务经过的坐标位置输出,便可绘制出路径规划结果,同人工规划的结果一起作图得到图6。
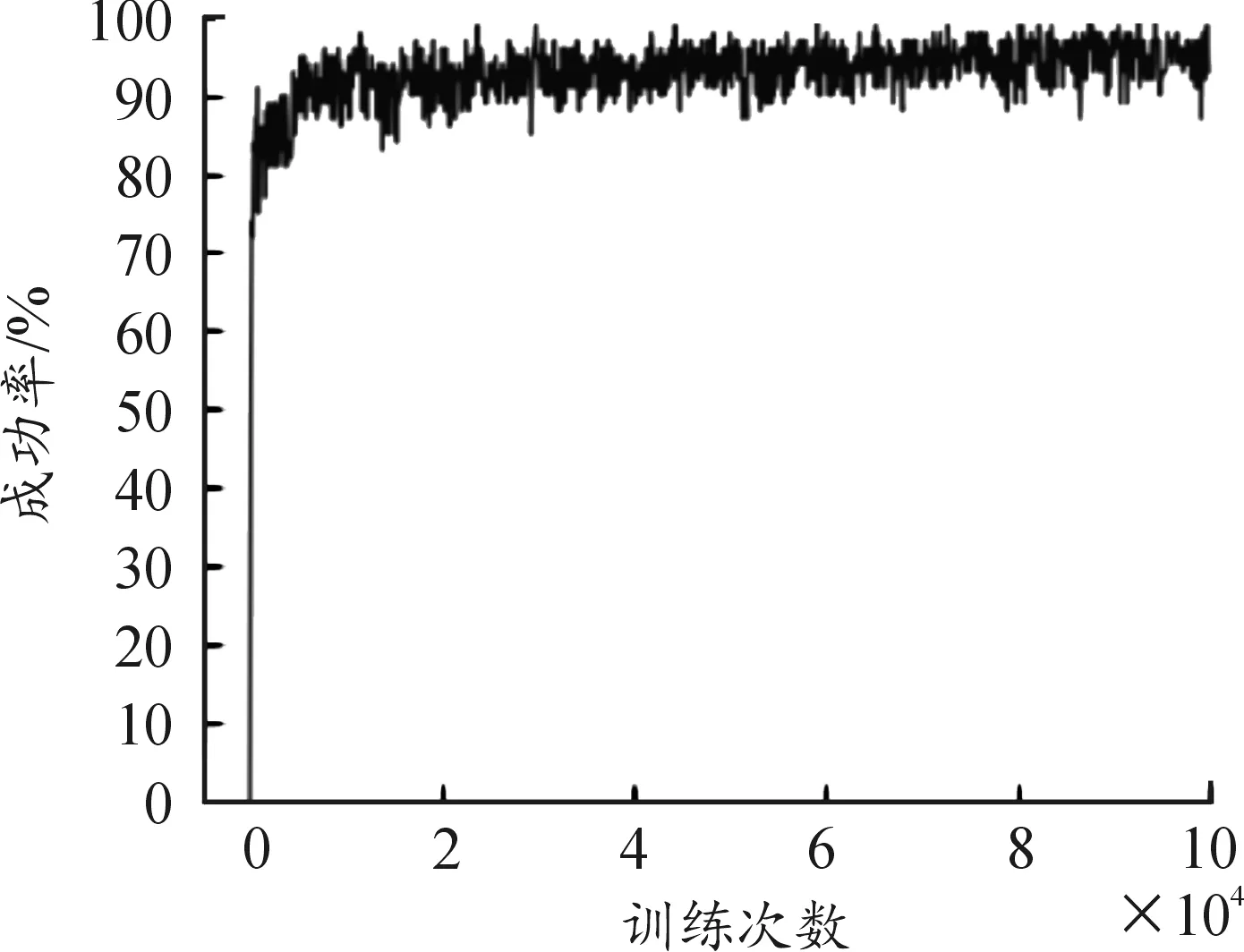
图5 100 000次训练结果曲线
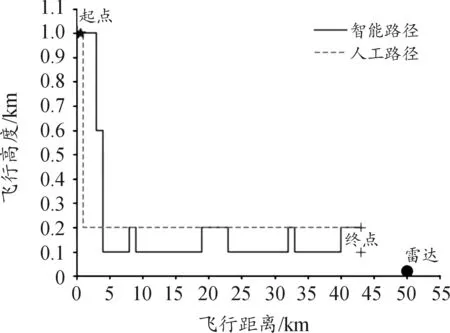
图6 规划路径曲线
图6中横坐标代表飞行距离,纵坐标代表飞行高度,人工路径是根据已知模型信息人为规定的安全路径,智能路径则是经过算法训练的Agent完成突袭任务时经过的路径。由图可知,经过训练后直升机CGF(Agent)在飞抵红方雷达边界前(5 km处)能够主动下降飞行高度从而避免被雷达侦察到,之后选择安全高度(0.1~0.2 km)飞行,且在飞行过程中通过衡量因飞行高度过低而导致坠机概率增加和因飞行高度过高而被雷达侦察到事件之间的关系,从而采取最优飞行高度进行突袭,飞行过程中能够主动变换飞行高度进一步优化自身行动,最终顺利完成突袭任务。对比分析可知,人工规划的路径相对固定灵活性差,容易被红方掌握规律后进行针对性打击,智能规划路径则更为灵活,能够结合环境信息实时规划出安全路径,从而不容易被红方针对。
5 结论
改进SARSA算法相对传统SARSA算法有着更优异的性能,算法收敛速度以及任务完成率都有明显提升。改进SARSA算法实时性好,能够使直升机CGF顺利规划出安全路径,且生成的路径比人工规划路径更灵活。
猜你喜欢
小学生学习指导·高年级(2023年8期)2023-11-19 05:33:56
科技创新与应用(2021年31期)2021-11-09 13:11:18
作文评点报·小学三、四年级(2018年43期)2018-01-08 08:54:28
民间故事选刊·上(2017年5期)2017-05-17 21:54:25
小小说月刊(2015年5期)2016-01-22 08:39:19
微型小说选刊(2015年3期)2015-11-18 07:12:25
弹箭与制导学报(2015年1期)2015-03-11 15:32:23
棋艺(2014年3期)2014-05-29 14:27:14
雷达学报(2014年4期)2014-04-23 07:43:13
哈尔滨工程大学学报(2013年5期)2013-06-05 09:00:36
