
基于DAM和CNN-LSTM的辅助动力装置性能参数预测模型
2022-06-01 13:16王力,马宪
计算机测量与控制 2022年5期
王 力,马 宪
(1.中国民航大学 职业技术学院,天津 300300; 2.中国民航大学 电子信息与自动化学院,天津 300300)
0 引言
飞机辅助动力装置(APU,auxiliary power unit)本质上是一个小型涡轮燃气发动机,其结构简单,重量小,功率大,主要用于辅助飞机主发动机启动并为机载用电设备供电。APU作为第二动力系统,为飞机的安全性与乘客的舒适性提供保障,是一个不可缺少的重要子系统。
排气温度(EGT)作为一个关键的气路性能参数,可以直接反应APU的健康状态,因此可以利用历史时刻EGT组成的时序数据预测未来一段时间APU的状态。APU是一个复杂非线性系统,多个部件共同作用使EGT呈现出非线性的时变规律,故对EGT的预测要考虑到APU内各种性能参数。
国内外学者对排气温度预测展开了大量研究,文献[4]利用排气温度与其他性能参数间的关系对EGT进行预测。文献[5]采用遗传算法优化支持向量机参数来提高预测精度。文献[7]采用优化后的最小二乘支持向量机模型预测EGT。虽然上述的方法取得了较不错的预测效果,但是对长时间序列,进行多变量和多时间步预测时效果不是很好。近些年深度学习发展迅速,在处理长时间多变量的时序数据有着明显的优势。长短期记忆网络(LSTM)是循环神经网络的一个变种,解决了序列长时间被遗忘的问题。卷积神经网络(CNN)可以挖掘输入数据的特征,提取深层次的变量间局部依赖关系,一定程度上提高预测精度。在时序预测中引入注意力机制可以为重要特征和时刻加权,加强重要信息的对输出的影响,从而提高预测模型精度。粒子群算法(PSO)可以对长短期记忆网络的超参数进行优化,提升预测模型的性能,从而提高预测精度。文献[16]提出基于LSTM的多变量时间序列预测模型。文献[17]提出了一种基于CNN和LSTM的混合模型预测短期电力负荷。文献[18]提出了一种基于长短期记忆神经网络和注意力机制的模型,对短期光伏功率进行预测。文献[19]提出一种基于自适应PSO的LSTM预测模型,对股票价格进行预测。
本文提出一种基于DAM和CNN-LSTM的模型对APU的气路参数EGT进行多变量预测,首先在CNN中引入通道注意力机制,对各特征通道进行加权,突出重要特征的表达,提高了CNN提取重要特征的能力;然后在LSTM输出侧引入时序特征注意力机制,加强历史时刻重要信息对预测输出的影响。最后利用改进的粒子群算法对该模型的关键参数进行寻优,使用优化后的模型对EGT进行预测。此方法旨在使用深度神经网络的不同结构,更有效的处理EGT数据特征信息,达到准确预测EGT动态变化的目的。
1 深度学习理论
1.1 CNN原理结构
CNN是一种得到深度学习领域广泛使用的前馈神经网络。其卷积层通过局部连接和权值共享的方式有效提取原始数据的局部特征信息,保留了平面结构信息。由于时序序列具有局部相关性,故可以使用1DCNN处理其局部特征。CNN结构如图1所示,主要由卷积层、池化层和全连接层组成。卷积层对输入数据进行特征提取,公式如下:
F
=f
(W
×X
+b
)(1)
式中,W
为卷积核权重矩阵,X
为输入参数向量,b
为偏置向量,f
(·)为激活函数。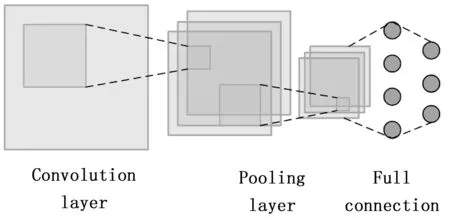
图1 CNN结构
1.2 LSTM原理结构
LSTM网络是在在循环神经网络(RNN,recurrent neural network)的基础上改进而来,可以弥补RNN中固有的无法处理长距离的依赖的缺陷。LSTM在RNN的基础上增加了细胞状态和3个门,控制各个门的状态来对上一时刻旧信息和输入的新信息进行舍弃、保存和更新,最后得到的隐藏层输出由多个函数共同作用,避免了梯度消失问题。这种复杂的网络结构使LSTM比RNN能长期记住更多过去的有用信息。LSTM的网络结构如图2所示。
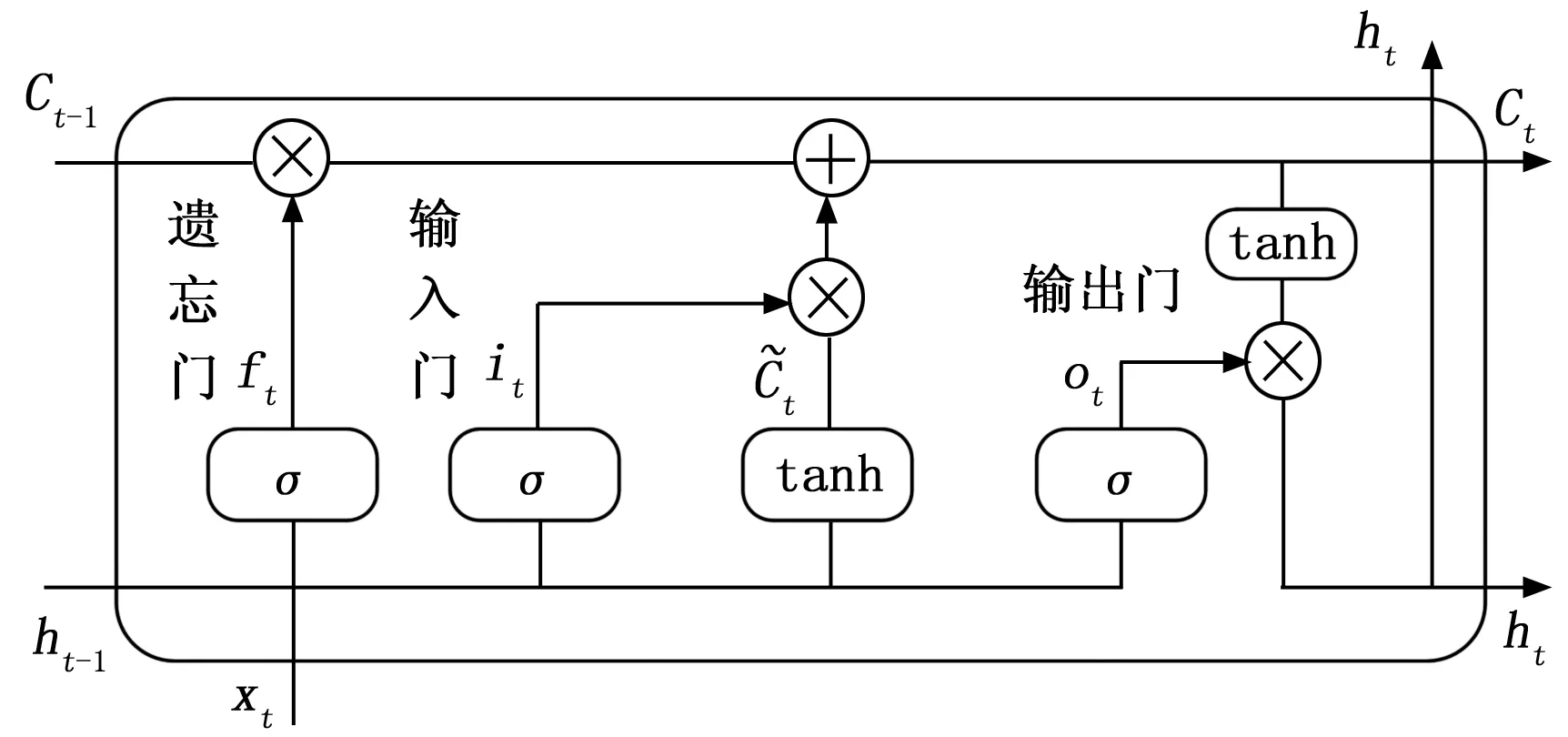
图2 LSTM结构图

f
=σ
(W
(h
-1,x
)+b
)(2)
i
=σ
(W
(h
-1,x
)+b
)(3)
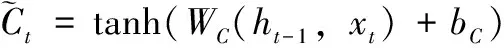
(4)
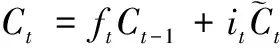
(5)
o
=σ
(W
(h
-1,x
)+b
)(6)
h
=o
tanh(C
)(7)
式中,x
为t
时刻的输入;h
-1和h
为t
-1时刻和t
时刻隐藏层状态;f
,i
,o
分别为遗忘门、输入门和输出门;C
-1和C
分别为t
-1和t
时刻的细胞状态;,,,分别为不同状态门的权重矩阵;b
,b
,b
,b
分别是不同状态门的偏移量;σ
表示sigmoid激活函数。1.3 注意力机制
注意力机制本质上是一种权重分配机制,受到人类视觉注意力机制的启发而提出。深度学习中的注意力机制的核心目标是令神经网络更加关注数据出现的趋势和变化,对关键信息赋予更多的概率权重以提高神经网络对关键信息的提取。在时序预测中,注意力机制既可以加入到CNN中,为重要的特征通道信息赋予更大的权重,从而降低无关特征信息对预测结果的影响,也可以作用到LSTM网络输出侧,加大历史时刻关键信息对当前输出的影响。
1.4 粒子群算法
粒子群算法是通过模拟鸟群觅食行为而发展起来的一种基于群体协作的随机搜索算法,被广泛的应用在各种优化问题。粒子群算法中每个粒子的初始位置都是随机的,其位置代表优化问题的解。所有的粒子都有一个由被优化的函数决定的适应值,适应值是评价粒子位置是否为最优解的一个评价指标。粒子仅具有位置和速度两个属性,进行迭代寻优的过程中会不断更新自身的位置和速度。在搜索空间内,每个粒子单独搜索全局最优解,个体间通过协作和信息共享的方式来调整位置与速度。粒子速度、位置更新公式为:
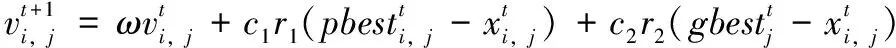
(8)
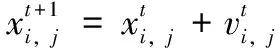
(9)

2 基于双阶段注意力机制的CNN-LSTM混合模型
2.1 模型描述
长序列数据包含许多潜在的规律信息,传统的预测模型处理数据时,无法提取数据特征信息之间的潜在规律,导致了相对较大的预测误差。CNN通过局部链接和权值共享的方式对原始数据进行高维特征映射,能够挖掘出数据的特征信息。但通过卷积进行特征提取时,产生的冗余特征会对预测精度产生影响,对含有不同特征的通道使用注意力机制,在训练过程中学习各个通道的权重,给重要特征分配更大的权重,从而获得预测模型更多的关注,降低无关特征对预测结果的影响。LSTM网络通过门控状态选择信息的保存与更新,保存需要长时间记忆的关键信息,遗忘无关信息。在处理具有长期依赖的时序数据时有较好的表现。由于排气温度的预测值受历史状态影响较大,为了使预测值能自主处理历史状态信息,加强对当前时刻输出影响大的历史时刻信息表达,在LSTM网络的输出侧加入时序注意力机制,能够得到更接近真实值的预测值。因此提出基于双阶段注意力机制的CNN-LSTM混合模型,引入注意力机制加强模型对关键信息的关注,使网络学习到更多关键信息的特征,进而提高预测精度。
2.2 通道注意力机制
为更好的利用重要的特征通道信息,在CNN卷积层后加入通道注意力模块,突出重要特征通道的表达。具体细节如图3所示。

图3 通道注意力机制
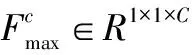
F
)=σ
(MLP
(AvgPool
(F
))+MLP
(MaxPool
(F
)))=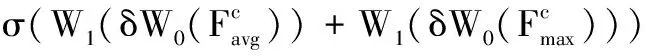
(10)
其中:σ
代表sigmoid激活函数,δ
代表relu激活函数,∈R
×和∈R
×分别为全连接层的两个权重矩阵。最后,将通道注意力矩阵(F
)与输入特征图F
相乘,并且通过残差的方式与原始的输入特征图相加,得到该通道注意力模块的最后输出。最终,每个特征通道都乘上了学习到的相应权重,增强了网络对某些重要通道信息的注意力,能够更好的提取数据的时空特征。2.3 时序注意力机制
在EGT预测中,当前时刻的预测值与历史时刻预测值有较大联系,但每个历史时刻信息对当前输出的影响程度不同,为了突出重要历史时刻信息的影响,在LSTM网络的输出侧加入时序注意力模块为重要历史信息分配更大的权重。具体细节如图4所示。
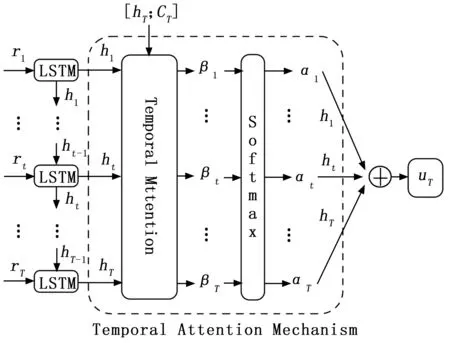
图4 时序注意力机制
在t
时刻,CNN提取的特征参数向量r
与LSTM上一时刻隐层状态h
-1一同输入到LSTM网络中,得到t
时刻的输出h
,表示为:h
=f
(h
-1,r
)(11)
式中,f
表示LSTM网络单元。时序注意力机制的输入为经过LSTM网络处理过的特征矩阵,随后时序注意力机制会对历史时刻隐层状态信息分配权重系数,其计算公式如下:β
=V
tanh(W
[h
;C
] +U
h
+b
)(12)
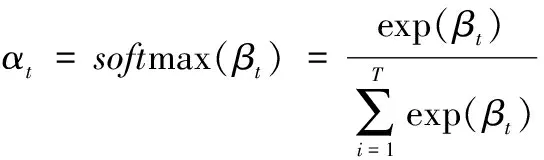
(13)
式中,[h
;C
]是LSTM单元隐层状态与细胞状态的拼接;β
是LSTM单元隐层状态h
和[h
;C
]的相关性分数;,,为时序注意力相应的权重矩阵;b
为偏差项;α
为经过softmax函数归一化的注意力权重系数。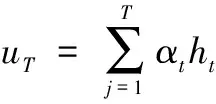
(14)
α
对t
时刻隐层输出h
与当前时刻[h
;C
]的相关性进行了量化,提高与当前时刻输出关联密切的历史信息的影响,最后各时刻的隐层输出加权求和得到了时序注意力机制的输出u
,u
经过全连接层进行维度变换得到最终的EGT预测值。2.4 粒子群算法改进
传统的粒子群算法粒子速度的改变总是保持同一水平,导致了算法收敛速度慢并且搜索全局性差,易陷入局部最优值。通过改进惯性因子来调节粒子的全局和局部寻优能力。改进后的惯性因子ω
公式为:
(15)
式中,ω
和ω
分别为惯性因子的最大值与最小值,一般设ω
=0.9,ω
=0.4,t
为当前迭代次数,T
为最大迭代数。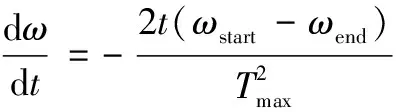
(16)
惯性因子代表粒子对当前速度的继承程度,上式为惯性因子的微分,代表惯性因子的变化率。在迭代次数t
较小时,ω
接近最大值,粒子能快速分布到整个搜索空间,以找出最优值的大概范围;随着迭代次数的增加,ω
下降的越来越快,粒子速度变小确保了局部搜索的精度。使用非线性惯性因子调节粒子速度,使搜索的全局性与局部性达到动态平衡,提高了粒子群算法寻优的性能。改进PSO算法对LSTM网络超参数寻优的具体步骤如下:
1)输入经过预处理的训练集数据;
2)设置初始粒子群种群大小、迭代次数、学习因子等相关参数;
3)利用改进PSO算法对LSTM网络的学习率lr,步长step进行寻优,并确定搜索范围;
4)粒子的适应度计算与对比,以LSTM的预测平均绝对百分比误差作为目标函数,计算各粒子的适应度值并进行比较,找到粒子的全局最优值gbest;
5)利用式(8)和式(9)对粒子的速度和位置进行更新;
6)判断是否达到最大迭代次数或最小误差。若两个条件均不满足则返回步骤4);
7)输出LSTM网络的最优学习率与步长。
在改进的粒子群算法中设置最大迭代次数为100,种群规模为20,学习因子c
=2,c
=2,惯性因子最大值与最小值分别为0.9,0.4。LSTM网络训练过程中使用adam优化器,损失函数采用均方误差(MSE),学习率取值范围为[0.001,0.01],步长的取值范围为[1,10],改进PSO搜索到的最优组合参数学习率为0.003,步长为6。2.5 基于双阶段注意力机制的CNN-LSTM混合模型
整个预测模型结构如图5所示,原始数据经过输入层进行预处理,然后输入到1D卷积层进行特征提取,利用通道注意力机制为各特征通道分配权重,再经过池化层、全连接层的处理,信息进入LSTM网络,其隐层状态作为时序注注力机制的输入,时序注意力机制实现了选择不同时刻特征的重要性,加权后的特征信息经过全连接层维度变换后得到最后的预测值。
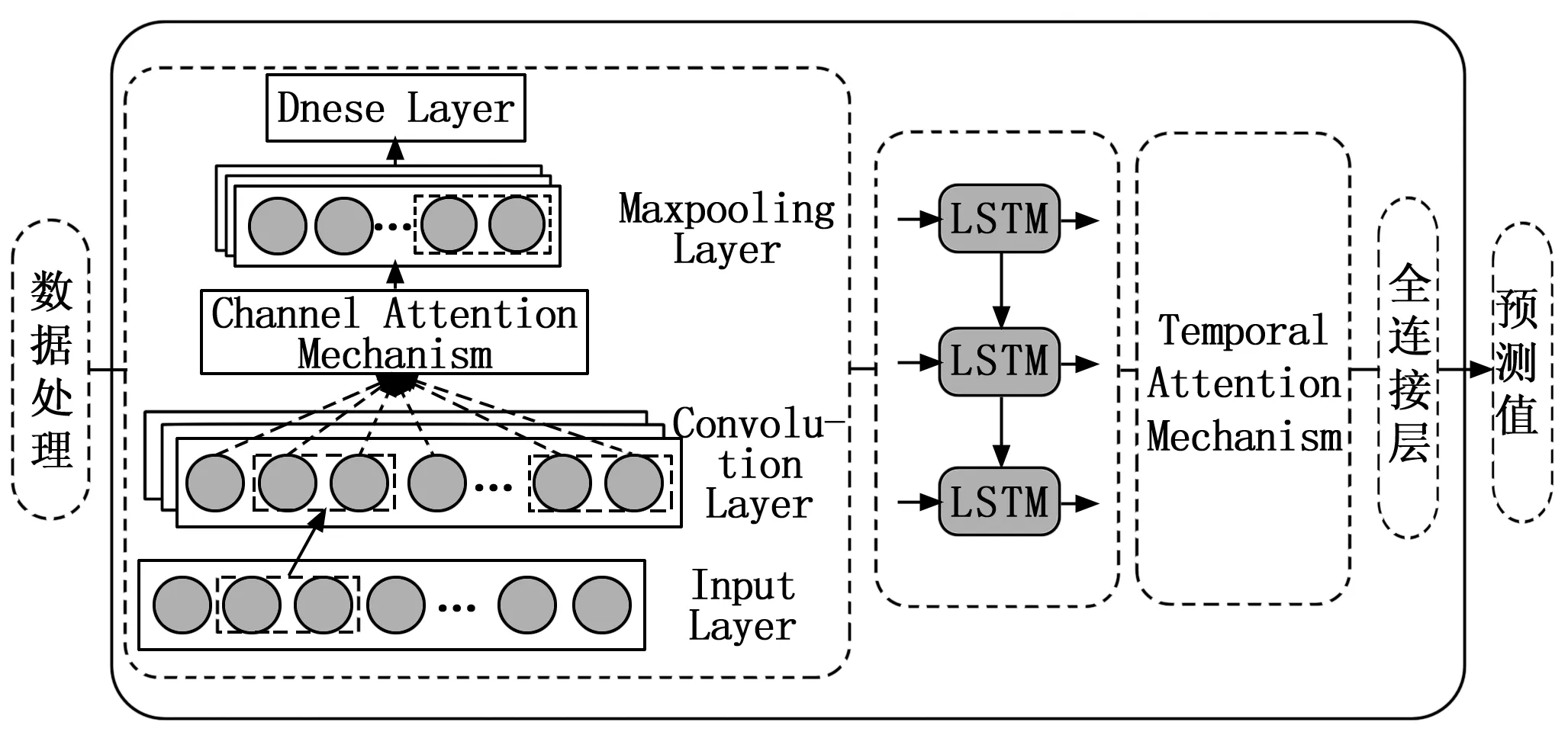
图5 DAM和CNN-LSTM模型结构
模型中的每层描述如下:
1)输入层:对原始输入数据进行预处理,使输入数据满足预测模型的要求。
2)引入通道注意力机制的CNN层:对经过预处理的数据进行特征提取。CNN由卷积层、池化层和全连接层组成,APU性能参数为时序数据,具有局部相关性,故将卷积层设计为一维卷积便于处理其局部特征,该卷积层包含64个1×1的卷积核,其激活函数选取Relu函数,相比sigmoid函数和tanh函数,Relu函数缓解了梯度消失问题并加快了模型收敛速度。它将小于0的输入直接输出为0,使得神经网络中的神经元具有了稀疏激活性,能够一定程度上防止过拟合。通道注意力模块为经过卷积层的特征分配权重,突出重要特征信息的表达。池化层选择最大池化,能够保留更多的特征信息。为了避免过拟合,在池化层和全连接层中增加Dropout层,以一定概率随机断开神经元的连接,最后经过全连接层转换数据维度将其输出。
3)引入时序注意力机制的LSTM层:LSTM网络对CNN层提取的特征向量进行学习,挖掘出具有长期依赖性的特征。LSTM网络学习率为0.003,隐层神经元节点数为128,步长为6,batch_size为64。时序注意力机制为LSTM网络的输出分配权重。时序注意力机制的输入为LSTM输出的特征向量H
=[h
,h
,…,h
]。4)输出层:其输入是时序注意力机制模块的输出。由全连接层输出最后的预测值,激活函数选取sigmoid函数。
3 实验结果与分析
3.1 数据预处理与评价指标
本文实验数据采用航空公司某型飞机快速存取记录器(QAR,quick access recorder)系统采集的APU数据,其中包括滑油温度(T
)、引气压力(P
)、引气流量(W
)、发电机负载(G
)、APU转速(N
)、EGT,共3 300组数据。EGT的变化受多个APU性能参数影响,但过多的输入参数会造成预测模型网络复杂化,还会使模型学习到与输出无关的特征,从而影响预测精度。相关性是衡量不同参数间变化一致程度的指标,选择与EGT相关的性能参数作为输入数据可以保存大量特征信息并降低计算量。因此采用数据分析软件SPSS计算各参数间的Pearson相关系数,如表1所示。

表1 不同参数的相关系数比较
通常情况下,相关系数绝对值大于0.8,认为参数间高度线性相关。在0.5~0.8之间,认为参数间具有显著线性相关性。在0.4以下,一般认为有极弱线性相关性或不存在线性相关。在进行多步预测时,具有高度相关性的输入数据有助于加强神经网络模型的学习过程,提高预测结果的准确率。
根据表1不同参数相关系数选择模型输入参数为APU转速N
、引气流量W
、发电机负载G
。由于APU排气温度与相关的特征参数在APU工作过程中波动范围较大,且各个特征参数的量纲级别也不同,为了防止各特征参数数值差异过大造成奇异解,加快模型收敛速度,需要对原始数据进行归一化以适应模型训练。
(17)
式中,x
为输入数据x
的最大值,x
为最小值。对各特征参数数据进行min-max标准化,线性变换到[0,1]区间,适应sigmoid和tanh激活函数。在模型的输出阶段,需要对数据进行反归一化,使得输入数据和输出数据保持一致。
本文选取3种误差评价指标衡量模型的预测精度,分别是MAE(mean absolute error)、MAPE(mean absolute percentage error)与RMSE(root mean square error),计算公式如下:
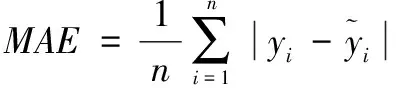
(18)
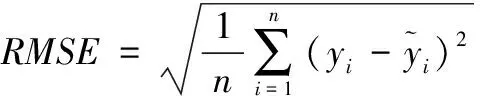
(19)

(20)
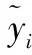
3.2 模型收敛性
设置最优模型参数后,需要对训练过程中DAM和CNN-LSTM混合模型的收敛性进行验证。计算该模型训练过程中的损失值,并与CNN-CAM-LSTM模型、CNN-LSTM-TAM模型、CNN-LSTM模型进行比较。各模型收敛性如图6所示。
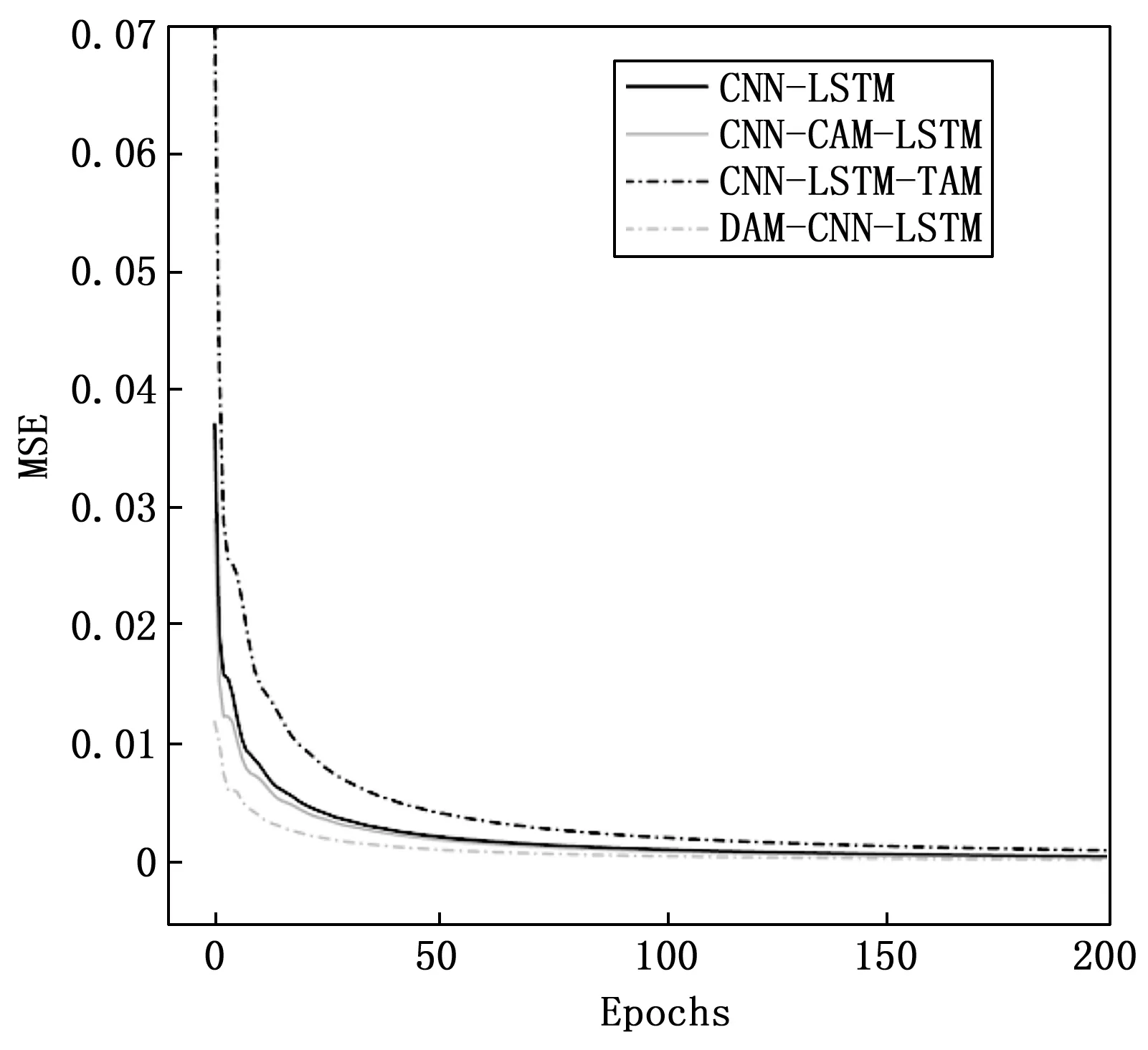
图6 不同模型进行EGT预测的损失收敛
实验中各模型参数均相同,采用均方误差MSE(mean square error)作为模型训练的损失函数。由图6可以看出各模型在经过200次迭代后其损失函数MSE趋于平稳。在整个训练过程中本文所提模型的损失函数MSE的值均小于另外3种模型,具有更好的收敛效果。
3.3 实验结果分析
为验证双阶段注意机制对特征提取和时序依赖关系的有效性及优化效果,对样本数据采用本文提出的DAM和CNN-LSTM混合模型、CNN-CAM-LSTM模型、CNN-LSTM-TAM模型、CNN-LSTM模型进行排气温度预测。上述模型中使用的LSTM网络均采用相同的超参数(学习率为0.003,隐层神经节点数为128,步长为6,batch_size为64);1DCNN的卷积核个数为64,卷积核大小为1,最大池化层为2,dropout为0.3。数据集前90%作为训练集,后10%作为测试集。在模型训练过程中选择Adam算法优化模型参数,Adam算法吸收了AdaGrad和RMSProp两种梯度下降算法的优点,既能适应稀疏梯度,又缓解了梯度震荡问题。文中预测模型的代码都是用Python编写,使用Pytorch深度学习框架进行开发。采用本文选取的3种误差评价指标来评价不同模型的预测性能与精度,实验对比结果如表2所示。
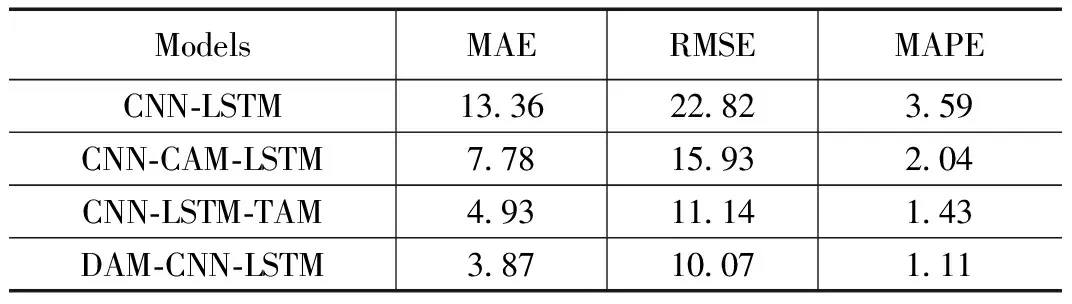
表2 不同模型预测精度比较
根据实验结果分析,加入双阶段注意力机制对预测效果的提升显著,MAE、RMSE、MAPE均有明显下降。为验证通道注意力机制和时序注意力机制对模型性能的提升效果,将两种注意力机制单独加入到CNN-LSTM模型(CAM为通道注意力机制; TAM为时序注意力机制)。由表2可以看出,在输出侧加入时序注意力机制对模型预测性能的提升更为明显。
本文所提模型比CNN-LSTM模型,CNN-CAM-LSTM模型,CNN-LSTM-TAM模型的MAE分别降低了71.03%、50.26%、21.50%;RMSE分别降低了55.87%、36.79%、9.61%;MAPE分别降低了2.48%、0.93%、0.32%。本文算法在3种误差评价指标上都有明显的降低,证明了该模型在多步多变量排气温度预测的可行性。
各模型在测试集上的预测输出曲线对比如图7所示。
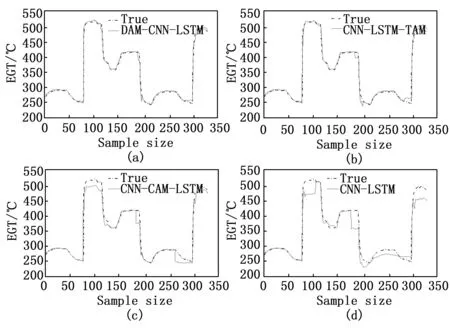
图7 不同模型的EGT预测温度比较
由图7(d)可以看出CNN-LSTM模型在高低峰值和大幅波动区间的预测输出值与真实值拟合程度较低,难以反映EGT真实值的变化趋势。图7(c)为CNN-CAM-LSTM模型的预测值,该模型在特征提取阶段加入通道注意力机制对特征通道分配权重,加强了模型对重要特征通道的关注,在高低峰值区间的预测效果有一定的提升,但在高峰阶段的预测值与真实值仍有较大误差,无法准确的预测出排气温度的峰值,从而忽视因排气温度超温而引起的故障。CNN-LSTM-TAM模型在LSTM输出侧加入时序注意力机制加强了历史关键时刻信息对当前输出的影响,由图7(b)可以看到整个区间的预测精度均有明显提升,在高低峰值和大幅波动区间的预测输出值与真实值拟合度较高。由图7(a)可以看出本文提出的DAM和CNN-LSTM混合模型在整个区间的预测输出与EGT真实值拟合程度很高,准确的捕捉到了EGT变化规律。其他几种预测模型在部分区间虽然也有较好的预测效果,但在高低峰值和大幅波动区间的预测精度均低于本文所提模型。
总体而言,提出的DAM-CNN-LSTM方法能够有效地学习参数数据的内部变化规律,可以用于未来排气温度预测。该预测方法可为未来APU健康状态预测提供预警作用,预测未来EGT,并结合其他APU性能参数,查看是否在合理的范围内,及时排查潜在故障原因保障APU正常运行。
3.4 不同步长效果验证
为了进一步验证本文方法的泛化性和稳定性,使用不同步长进行EGT预测,采用上文提出的3种误差评价指标对4种模型的预测性能进行评估与分析。
图8和图9分别为步长为10和15时,4种模型的MAE、RMSE、MAPE值。从图中可以看出随着步长的增加,3种误差评价指标值均升高,说明步长的增加导致各模型的泛化性和稳定性变差。与6步预测结果相比,各模型在进行10步预测时,RMSE分别增长了32.11%、35.10%、33.67%、35.02%,在进行15步预测时,RMSE分别增加了37.33%、39.01%、42.37%、41.31%。本文方法的RMSE增幅还是较高,但与其他方法相比,RMSE增长率最低,说明在步长增加的情况下,预测精度下降的更缓慢,MAE和MAPE也明显低于其他方法。总体而言,本文提出的预测模型在十步和十五步预测中,3种误差评价指标是最低的,表明其预测性能要优于其他预测模型。
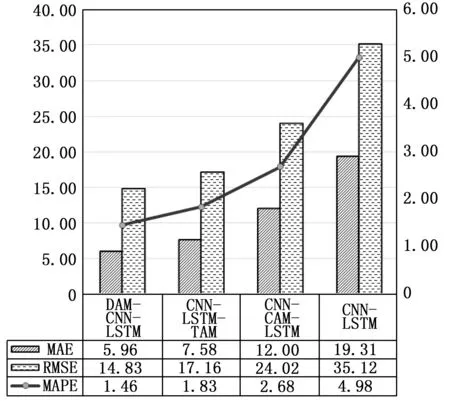
图8 十步预测不同模型的评价指标值
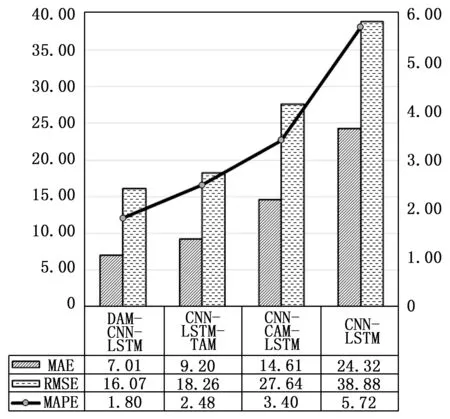
图9 十五步预测不同模型的评价指标值
步长的增加导致了各预测模型的预测性能下降,计算单位步长增加时各预测模型的误差平均增长率,增长率越低,说明预测模型性能衰减的越慢,各预测模型误差平均增长率如表3所示。
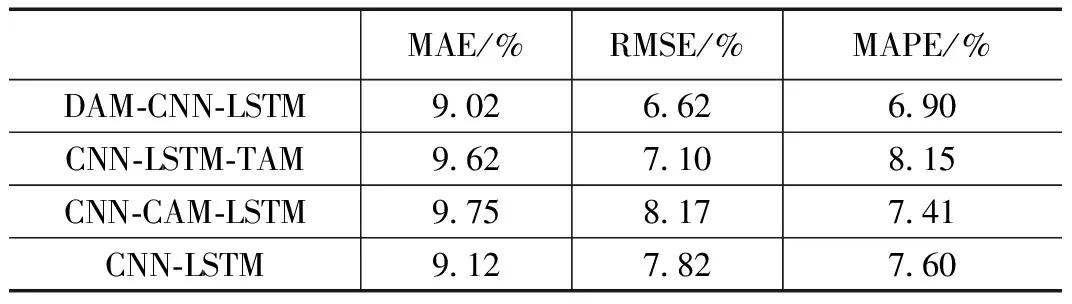
表3 不同预测模型平均误差增长率
由表3可以看出,本文所提预测模型在MAE、RMSE、MAPE的平均增长率分别为9.02%、6.62%、6.90%,均低于其他预测模型。其中MAE是衡量预测模型精度的一个指标;RMSE主要反映模型的稳定性;MAPE百分比表现模型预测性能,该预测模型在引入双阶段注意力机制后,在多步长预测中精度和稳定性均优于CNN-LSTM-TAM模型、CNN-CAM-LSTM模型、CNN-LSTM模型,相比其他模型更适用于多步长预测。
DAM-CNN-LSTM预测模型利用通道注意力机制和时序注意力机制充分学习了特征参数间的内部相关性,可较为准确地对未来APU 的EGT进行预测。
4 结束语
本文提出一种基于DAM和CNN-LSTM的混合模型用来提高APU排气温度短期预测的精度与稳定性,得到了以下结论:
1)多维冗余的无关输入数据会导致模型结构复杂且预测精度下降。为提升预测模型的效率与性能,对输入数据进行相关性分析,选择与EGT相关性较强的性能参数参与预测,提高数据可靠性。
2)在CNN中加入通道注意力机制学习各个特征通道的权重,为重要特征分配更大的权重,从而获得预测模型更多的关注,降低无关特征对预测结果的影响,提高了CNN提取重要特征的能力。在LSTM网络输出阶段加入时序注意机制可以捕捉时序数据间的依赖关系,加强历史关键信息对当前输出的影响,提高模型对长时间序列的预测性能。
3)非线性惯性因子提高了PSO的寻优能力,避免算法陷入局部最优值并加快收敛速度。利用改进的粒子群算法优化LSTM网络的学习率和步长,找到最优组合参数。
4)双阶段注意力机制的加入使模型对重要特征及重要历史信息投入更多的关注,通过实验验证了注意力机制对多变量多步EGT预测模型性能的提升。当预测步长增加时,虽然3种误差评价指标均有所上升,但上升幅度较低,预测精度仍高于其他3种模型,证明了本文所提预测模型的稳定性。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
意林·作文素材(2021年23期)2021-01-22
上海师范大学学报·自然科学版(2019年5期)2019-12-13
科学大观园(2019年10期)2019-09-10
证券市场周刊(2019年18期)2019-08-17
证券市场周刊(2019年19期)2019-05-27
