
基于YOLO训练网络的茶园植物智能识别算法设计与实践应用
2022-05-30 10:48:04李佳奇
电脑知识与技术 2022年28期
李佳奇


摘要:为了顺应时代发展,为智能农业赋能,该文为茶园农业提出了一种茶草识别算法。在综合考虑准确性检测效率等因素后,选择采用YOLOv5算法,在数据集准备中选择了叶片标记和植株标记两种方法,比较后得出叶片标记效果更好,在算法运行中又用数据增强的方式进行了改进,而结显示算法效果很好,可以进行产业化应用。
关键词:YOLOv5;数据增强;标记方式;深度学习;损失函数
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2022)28-0020-03
1 引言
随着我国各大产业的现代化,传统行业的智能化成为了一个重要任务,农业的智能化、自动化是其中最重要的部分,这也给茶园智能管理提供了理论依据。智能分别出杂草,从而实现浇水、施肥、除杂草一系列环节的自动化,可以为茶园农业省下大量的人力物力,为农业赋能。
对于自动检测设备,在茶园中最适合使用的是无人机检测。无人机检测的特点是体积小、灵活、续航好,最重要的是写好的算法编入无人机简便,易于大量工业生产。笔者开发采用的也是无人机检测模式,很大原因是无人机检测便于在实验室不断测试实际效果进行改进,其他大型的方式如卫星等很难做到实时改进。
深度学习方法是非常优秀的目标检测方法,其优势在于它可以自动提取模型的特征点,随着数据量的不断增大,模型的精确度也会不断提高。过去卷积神经网络CNN和循环卷积网络RNN两个系列被广泛运用,这两种网络的精度和容错率都得到了保证,但这两个网络都模型巨大,难以去实现开发,而且不易于改进算法。本文采用的YOLO算法是近些年出现的新型算法。在YOLO几次升级中,通过轻量化的改进实现了开发端的人性化。
本文采用的是YOLOv5算法,YOLOv5分为YOLOv5s、TOLOv5l、YOLOv5m、YOLOv5x四种,它们在输入端具备了图片自动计算处理、图片自动缩放等功能,而且继承了YOLOv4的Mosaic数据增强功能[1]。由于茶草是相对较小的物体,这里采用了速度偏低一些,但是精确率更高的YOLOv5l算法。
2 数据集准备与预处理
本文采用的数据集图片是通过无人机在茶园中拍摄,拍摄照片的基本要求是同时包含茶与草,光线充足、茶草具有明显特征[2]。采用无人机拍摄有两个好处,第一是数据集的准备需要大量的资源和素材,并且要经过层层筛选来选出合适的图片,而且数据集图片数量并非越多越好,因为要保证算法的运行效率,所以照片品质尤为重要,无人机拍摄的方式可以保证照片的品质。第二是本文所研究的算法最终服务于产业,无人机识别是产业最常用、效果最好的方式,将算法安置在无人机上,如果数据集也是在无人机上拍摄,使用效果會更好。
为了不断让训练更精进,本文拍摄的图片源于不同季节和不同角度,并且,人为地对茶草之间的区别分级,使训练集中既存在茶草混淆的照片又存在茶草区别很大的照片。最终将拍摄的照片分成三个训练集,通过结果比较得出最优,不至于一个训练集过大导致速度缓慢。
本文对训练集的照片进行了旋转与剪裁处理,消除无用照片面积,避免其余事物的混淆,并且设置了不同效果的光强,从而使训练网络得出的结果更加泛化,普适性更高,同时还将照片的茶草比例进行对照处理,使照片中茶草之间的比例差异很大,处理后将照片转为xml格式。
本文采用了两种方式对训练集进行标记,一种是将茶草整体进行分别标记,一种是将茶叶片与草叶片进行标记,其中对叶片进行标记结果更加准确,并且没有明显降低训练速度,这种识别算法的设计使得除草等环节运转更加流畅。此外,整体标记法的应用则符合识别潮流的趋势。
3 算法实现与改进
3.1 YOLOv5算法简介
YOLOv5的整体框架相对于先前版本并没有变化,仍然是分为输入端、Backbone、Neck、Prediction四个部分。
输入端实现了Mosaic数据增强、自适应计算、自适应图片缩放的效果。其中的Mosaic数据增强是在v4版本中最早提出的,它的原理是将多张图片各取一部分进行裁剪,将裁剪出的各部分组合成一张新的照片,这可以使算法识别的泛型更大,这样很多实验数据统计也可以计算到多张图片。自适应计算使得我们可以人为决定自动设置框的大小,参数则可以进行人工设置。自适应图片缩放则是将准备的尺寸不一的图片归一化并对有的图片加上黑边处理。
Backbone包含了Focus结构和CSP结构。CSP继承于v4版本,其原理是利用卷积核和激活函数来增强网络的学习能力,比如将一组物体的特征分为两部分,在不同层次上进行合并,来实现降低内存损耗的效果。Focus结构是将图像分成多个切片,为之后的特征提取做准备[3]。
Neck运用于Backbone与输出层中间,主要目的是将物体特征进行融合方便更好地识别,比如从下往上分层级不断传输特征,在每一层级都将特征进行融合。
输出端包含了Bouding box损失函数和nms非极大值抑制。Bouding box是反映交并比的重要参数,它可以比较出预检测框与真实检测框之间的差距,计算方式可通过位置矢量、最小封闭相交矩形等进行计算[4]。nms非极大值抑制可实现目标框筛选的操作,v5版本采用的是加权nms方式。
YOLOv5算法一个典型的特点是极其轻量级,它在继承了前身结构的完整性和YOLO系列独特优点的同时,放弃了很多耗时过大、占有内存过大的功能或流程,转而使用一些重复且又简单的算法替代,而且YOLOv5的几种算法符合各种需求,数据集的不同会导致需要的最佳算法不同,YOLOv5恰当地解决了这一问题。
3.2 YOLOv5算法改进
YOLOv5算法是所有Yolo系列算法中所需内存最少的,内存只有14M左右,可以方便地部署在无人机上对农田进行检测。但是YOLOv5的问题就在于虽然灵活,但是准确度不够,尤其是小物体多目标的检测,而对于叶片的标记就是多目标小物体聚集在一起,不利于准确识别。
本文采用数据增强的方式加强识别,如果是对input层进行数据拼接来实现数据增强的话,就会导致原有目标失真,并不能完全体现原有目标的所有特征,虽然提高了精度、操作成本降低,但是整个算法泛化能力下降很多。
本文采用加入自动数据增强算法,数据增强算法现在已经广泛应用于各类目标检测,它主要应用在CNN中,对于识别视觉会有很大的提高,而现在这一类算法已经成熟,易于实现。数据增强方法可分为颜色操作和几何操作两种。颜色操作主要是对物体的颜色、亮度等进行算法改变,而几何操作就是对物体的缩放、平移、旋转等操作[5]。通过这些操作可以将原有数据集中的图片进行改变,生成新的图片,从而扩大数据集。改进后,对于目标检测可以实现多尺度多方位的检测,充分利用了物体的每一个特征,且对于茶草叶片、颜色操作与几何操作并不会导致失真,仍会保持其特征。
4 运行结果
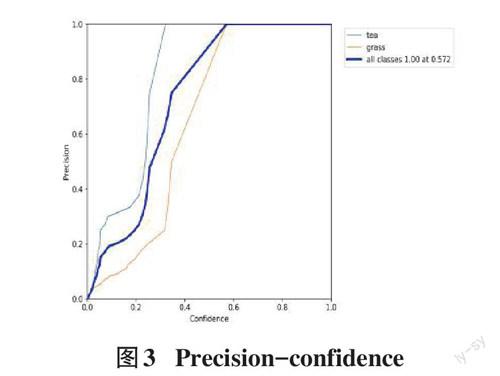
本文从多个维度,采用多种方式对运行结果进行分析,图1为F1-curve结果,纵坐标F1和横坐标confidence代表了置信度和F1分数的关系图。图2为precision-confidence关系图,代表了预测准确度与置信度关系图。图3为recall-confidence关系图,代表召回率与置信度关系图。
由图1~图3可以看出,检测关注点应该更多放在草的识别而不是茶的识别,在无人机去茶园识别的过程中,茶的数量远远大于草的数量,这个算法可以很轻易地检测出茶,却对检测出草有一定的难度,但是前面提到的叶片标记法,使得结果对检测草的精确率很高。
图4为损失函数结果图,表示运行过程中一系列损失函数的计算。
train/box_loss:在bounding box损失中,YOLOv5是采取GIOU Loss衡量的方式,这个数值越小,就代表识别的方框范围更准确;train/obj_loss:这个数值主要是衡量目标检测过程中Loss的均值,数值越小,目标检测越准确;train/cls_loss:这个数值是用来衡量目标在分类过程中Loss的均值,数值越小,目标检测越准确;Metrics/Precision:这个数值用来表示精度,是用来表示准确找到的正类与所有找到的正类之间的比值;Metrics/Recall:真实为positive的准确率,也就是样本所能够召回的概率。Recall从真实结果角度出发,描述了测试集中的真实正例有多少被二分类器挑选了出来,即真实的正例有多少被该二分类器召回。Val/box_loss:验证集bounding box损失;Val/obj_loss:验证集目标检测loss均值;Val/cls_loss:验证集分类loss均值。
复训练是提高算法设计精度以及贴合实际的最好方法,复训练的前提是有几组完整的实验数据,因此将所有损失函数罗列出来是很有必要的,哪个曲线不够理想,就分析讨论这种曲线可能出现的问题去进行改进。目标检测类型的算法是永远没有最优解的,只能是不断地改进与分析让算法接近理想化。而分析的过程又避不开实践环节,后续将对算法进行多次实践,讨论发现问题再对其进行改进。
5 总结
(1) 我国农业智能化发展迅速,而对于茶园农业,高效快速识别方式会为智能农业赋能。传统的檢测算法已经不能满足现代产业化的需要,而YOLOv5这个版本在检测效果上较好,而且具有内存小的成本优势,便于安置在无人机上,本文采用的智能识别算法可以大大减少浇水、除草、观测等环节的时间,实现高效率和高准确率的结合。
(2) 相较于之前的版本,YOLOv5算法整体的框架并没有改变,因此在可靠性上有一定保证,在创新的基础上确保了不会有太多的缺陷。而且YOLOv5是轻量级算法,所占内存较小。本文采用了YOLOv5最适合叶片检测的版本,对于多目标、小物体的检测大大降低了运行算法所需要的时间。
(3) 采用叶片标记法比植株标记法效果更好,相当于扩充了数据集,由于要提高算法运行的效率,减少算法运行的时间,因此数据集的照片数量要进行限制,而叶片的标记可以让图片的特征提取量给予更多。
(4) 数据增强的方式可以有效避免该YOLO算法的缺点,改善小物体识别、多物体识别的不足,本文采用了几何操作与颜色操作,实现了数据增强。
参考文献:
[1] 蔡鸿峰,吴观茂.一种基于改进YOLO v3的小目标检测方法[J].湖北理工学院学报,2021,37(2):33-36,47.
[2] 张慧春,张萌,边黎明,等.基于YOLO v5的植物叶绿素含量估测与可视化技术[J].农业机械学报,2022,53(4):313-321.
[3] 吴睿,毕晓君.基于改进YOLOv5算法的珊瑚礁底栖生物识别方法[J].哈尔滨工程大学学报,2022,43(4):580-586.
[4] 聂鹏,肖欢,喻聪.YOLOv5预测边界框分簇自适应损失权重改进模型[J/OL].控制与决策:1-8[2022-03-03].
[5] 王粉花,黄超,赵波,等.基于YOLO算法的手势识别[J].北京理工大学学报,2020,40(8):873-879.
【通联编辑:代影】
猜你喜欢
现代商贸工业(2018年23期)2018-09-20 10:50:44
电脑知识与技术(2018年12期)2018-07-12 10:42:54
商业研究(2017年6期)2017-06-27 18:46:12
商业研究(2017年6期)2017-06-27 15:46:14
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
