
基于MobileNetV3-YOLOv4超市取货机器人目标检测策略优化设计
2022-05-30 01:49杨登杰叶爱芬袁舸凡郭熔王环
电脑知识与技术 2022年30期
杨登杰 叶爱芬 袁舸凡 郭熔 王环

摘要:具有自主工作能力的超市取货机器人能够大大降低人工成本使其得到广泛应用,对超市取货机器人的目标检测策略进行持续的优化改进具有重要的现实意义。针对超市取货机器人目标检测策略存在泛化性、效率低的问题,提出了基于MobileNetV3-YOLOv4超市取货机器人目标检测策略的设计。该策略中将根据检测商品的特征有针对性地构建数据集,并且轻量化改进YOLOv4的主干特征网络,将原来的YOLOv4的CSPDarknet53主干特征网络用轻量级网络MobileNetV3替换,最终提高 YOLOv4算法的训练速度、检测精度以及网络模型的泛化能力。最终场地测试结果表明,上述控制策略在提升超市取货机器人泛化性和鲁棒性,同时提高了执行效率。
关键词:MobileNetV3-YOLOv4;CSPDarknet53主干网络;余弦退火衰减;鲁棒性;泛化能力
中图分类号:O246;TP311.1 文獻标识码:A
文章编号:1009-3044(2022)30-0018-05
开放科学(资源服务)标识码(OSID):
当前,人工智能、深度学习在目标检测[1-3] 、机器人控制等领域得到广泛应用,这些成功应用得益于芯片技术、计算机算力和系统优化技术的持续进步和发展。为了降低人工成本支出,超市取货机器人在超市的卸货、补货、取货等方面应用广泛。超市中商品种类繁多,如何对商品进行快速的目标检测识别直接影响着整个超市的运行效率。为提高目标检测算法的运行效率,当前的研究工作集中于形态学图像处理与卷积神经网络(CNN ,Convolution Neural Network)两个方面进行相关的研究。文献[4]中提出一种基于图像特征匹配的超市货物检测方法,该方法的优点是算法稳定、具有很强的可行性,缺点是算法适用范围窄,特征匹配较慢,受光线强弱和商品识别角度影响,会导致识别结果不准确。
在 CNN 方面,刘永豪[5]提出的一种基于Faster R-CNN和 SSD在货架商品检测上的实际项目中的改善。
由边缘检测算法例如Canny得到结果然后将结果分层分割,获得分开的各个商品图像元素,对于这些元素使用Faster R-CNN和SSD两种检测模型对上述图像元素进行最后的检测。在实际应用中,对红色蓝色方块图像进行识别测试,该改进有效地提高了商品上的检测准确率,该方法识别精度和准确度较高,缺点在于训练时间长,且识别较久。目前计算机视觉通常趋向于更广、更复杂,深度更深的网络[6-8]。训练更大的网络或将多个模型组合在一起就能得到更好的网络,比如YOLOv4[2-9] [10-11] 目标检测算法在速度和精度方面均表现优异,但YOLOv4的主干网络使用全关联的神经网络的方式提取特征,网络结构烦琐、参数量冗余,因此一般选择处理能力较强的计算机对运行该算法来达到预期的效果。针对上述问题,本文提出了基于MobileNetV3-YOLOv4超市取货机器人目标检测策略的设计[12]。为了解决上述提及的缺点与问题,降低识别算法的硬件需求,兼顾图像识别的准确度与速度,该策略用MobileNet轻量级网络替换原 YOLOv4的CSPDarknet53[13]主干网络,以便获取MobileNetV3-YOLOv4 模型,大大降低了目标检测网络的参数量,在保证识别精度的前提下进一步提升了检测速度。
1 MobileNet模型优化
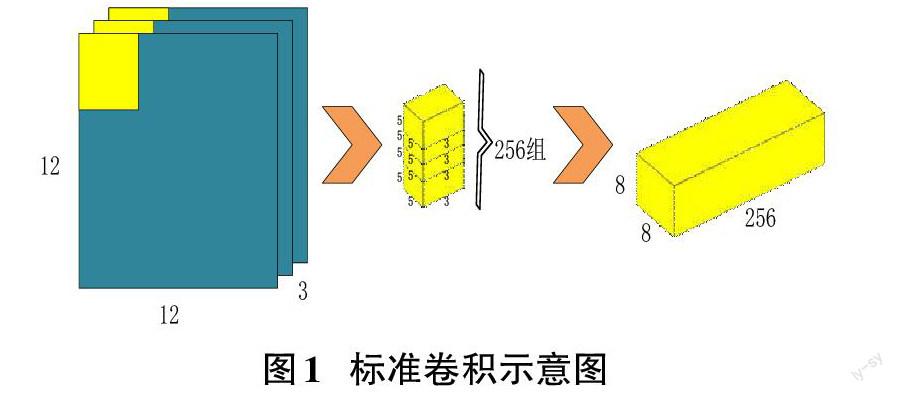
MobileNet模型由谷歌开发,这款模型针对的对象是手机等嵌入式设备。这是一款轻量级的神经网络,它里面最核心和最新颖的就是使用了可离散的深度卷积的方式取代如图1所示标准卷积[14]。
深度可分离卷积涵盖两个部分:深度卷积和逐点卷积,此两部分如图2所示,其根据输入通道数目的不同而采用不同的卷积核进行卷积运算,最后结果的通道的调整是通过单位为1的卷积核进行处理。
这里将卷积核拆分成单通道形式,在不改变输入特征图像的深度的条件下,所有通道都进行卷积,得到的输出特征图与输入特征图通道数相同。深度卷积如图3所示,输入为12×12×3,通过5×5×3的深度卷积处理,最后得到8×8×3的输出特征图流程图如下。
在图3的流程里,最终将特征图处理为8[×]8[×]3的卷积核,然后作为输入并使用256个大小为1[×]1[×]3的卷积核对其进行卷积,得到最终的输出特征图,逐点卷积如图4所示。
标准卷积与深度可分离卷积的过程对比后得出:深度可分离卷积的过程中使用的参数很大程度上减少了,使得运算量也减轻了很多,节约了处理器的算力,将卷积乘法变成加法来实现相同的效果。本文MobileNet综合了深度分离卷积操作、同时兼顾逆残差结构和采用h-swish函数代替swish[15]函数等。不同点是用h-swishj替换swish激活函数后,不仅减少了运算量,并提高图像识别能力。h-swish公式如下(1):
[h-swish[x]=xReLU6(x+3)6] (1)
这里的MobileNetV3采取一个矩阵大小为9的标准卷积核用于特征提取,使用最大池化层[16]获得了最后的分类结果。MobileNetV3 包括两种结构,分别是Large结构和Small结构,本文选择如下表1所示的MobileNetV3的Large 结构。为完成超市商品的识别功能,设待识别的图像大小设置为 416×416。
Input表示特征层在处理过程中的尺寸变化;
Operator表示特征层在处理过程前即将通过block结构,在改进型的网络处理过程中使用了大量的bneck结构。
Exp size表示特征层经过bneck结构后的通道数目。out也表示特征层经过bneck结构后的通道数目。
SE表示注意力机制是否在这一层被引入。
NL为激活函数种类,h-swish简化成HS表示,RELU由RE表示。
s表示经过block结构所用的步长。
2 改进型MobileNetV3-YOLOv4框架方案设计和功能实现
2.1 MobileNetV3-YOLOv4整体框架
改进型MobileNetV3-YOLOv4整体算法结构如图5所示 。
YOLOv4是一个单阶段目标检测算法,网络结构包括CSPDarknet53 、PAnet [17]和YOLOhead三个部分 ,其可检测目标并对目标进行分类, YOLO4算法框架流程图如图6所示。
MobileNetV3-YOLOv4用 MobilenetV3 替换YOLOv4网络结构中的 CSPDarknet53网络,其结构如图7所示。SPP金字塔模块分别使用尺寸为 13 × 13、9 × 9、5 × 5的卷积核对上面的输出特征进行卷积,输出的新的特征层包含3个处理后的结果,这个流程提高网络的深度。PANet 模块是对改进后的MobileNetV3 主干网络的特征提取的结果分别进行了上下采样。经过不同层池化的自适应处理,在下采样中,使得该网络的特征网格与特征层融合,并把结果传入预测模块进行反馈和分类。预测返回值通过 PANet结构后输出结果为 3 个大小分别为 52 × 52、26 × 26、13 × 13的特征层。
2.2 预测模块改进
IoU就是所说的交并比,是目标检测中最常用的指标,anchor-based的方法用来评估输出框和ground-truth的长度。
[IOU=|A∩B||A∪B|] (2)
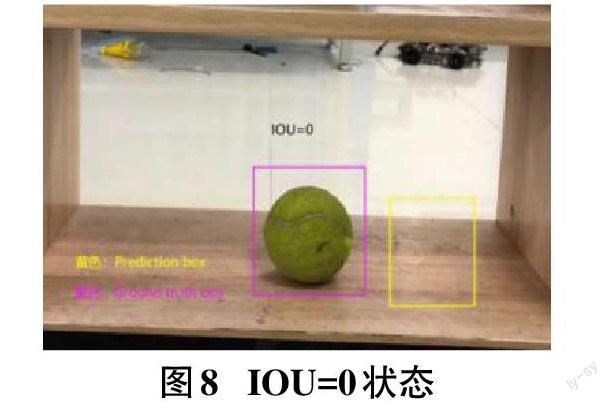
但Iou Loss存在两个缺点,一是无法反映重合度(图8 IOU=0):即假设两个框没有重叠部分,根据定义,IoU=0,所以这并不能反映两个框之间的间距,如图8 IOU=0。同时因为loss=0,无梯度回传,不能模型训练。二是无法区分两者相交的情况(图9 IOU=0.28):两种情况IoU的值即覆盖率都相等,但很明显状态2回归的效果较好,状态1回归效果较差。
针对以上两种情况,本文用 CIoU Loss 取代 Iou Loss,真实框与预测框的重叠率、尺度等因子作为权重,让预测框稳定,避免了IoU中出现的不稳定情况, CIoU Loss如图10所示。在预测框和真实框最外层外接一个最小的矩形,用c表示图中外接框的对角线的距离,这个距离就能衡量两个框的距离;同时求出预测框和真实框的中心点的欧式距离d,这欧式距离就能衡量两者的相交情况。
CIOU公式如下(3):
[CIOU=IOU-ρ2(b,bgt)c2-αν] (3)
公式中,在度量长宽比的相似度的变量使用v表示,如图10中在表示黄色矩形框的中心点和紫色矩形框的中心点时分别使用[b,bgt]表示,紫色矩形框和黄色矩形框所包含的最小矩形的对角线距离使用字母c表示。α表示权重量,其公式如下(4)(5):
[α=υ1-IOU+υ] (4)
[υ=4π2(arctanwgthgt-arctanwh)2] (5)
完整的 CIOU 损失函数定义如(6):
[LossCIOU=1-IOU+ρ2(b,bgt)c2+αυ] (6)
2.3采用Mish激活函数
Mish[18]是一个平坦光滑曲线,这样的激活函数可以通过更优质的图像信息深入神经网络,获得更好的识别准确性;Mish具有无上界的特性,它的好处是能够避免导致训练速度急剧下降的梯度饱和进而加快训练过程。同时Mish是有递增也有递减的函数,这种性质使其在小于零时不会有截断点,使较小的负梯度进入神经网络,能够使网络梯度流更加稳定。Mish具有较好的泛化和识别精度的有效优化能力,可以提高结果的质量。
Mish函数如公式(7):
[fx=x*tanh (?x)] (7)
softplus函數如公式(8):
[(?x=ln(1+ex)] (8)
ReLU、tanh、softplus、Mish激活函数如图11所示。
3 实验方法及结果分析
3.1测试准备
本文所用材料都在实验室模拟超市货框环境下拍摄,不同商品混合并列摆放,商品包含:雪花罐、特仑苏、红牛罐、AD钙瓶、网球、红色方块、蓝色方块、可口可乐罐、雪碧罐、王老吉罐十种商品。每张照片六类商品分上下三个并排摆放。拍摄设备使用苹果手机然后批量转换为jpg格式,拍摄距离在20~30cm之间,分辨率为3 024×4 032,拍摄角度为正面拍摄,数据集最终添加200张网络图片作为训练集,所以训练集1400张,验证集400张,测试集400张,总共2200张数据集。训练前需要先对图片进行标注,标注时用矩形框标注,这个流程使用LabelImg可视化图片标注工具。
环境内容为torch 为1.2.0版,torchvision 为0.4.0版,scipy为 1.2.1版,numpy为 1.17.0版,matplotlib为 3.1.2版,opencv_python 为4.1.2.30版,tqdm 为4.60.0版,Pillow为 8.2.0版,h5py为 2.10.0版,同时安装Anaconda方便环境管理,可以同时在一个电脑上安装多种环境。
3.2测试结果分析
在模拟场地的目标检测中,漏检的目标商品个数用FN(False Negatives)表示,正确检测到的目标商品的数量使用TP(True Positives)表示, 错误检测到的目标商品的数量用FP(False Positives)表示,测试图片400张。Recall和Precision的定义如式(9)与式(10)所示,在模拟超市环境下所得实验结果如下表2所示。
[Precision=TPTP+FP] (9)
[Recall=TPTP+FN] (10)
在测试集上的检测结果如图12所示,目标商品被预测框标注,并显示对应的商品名称与置信度。最终得出检测准确率为 0.992,召回值为 0.997,平均每张检测完毕消耗时间0.8s。
为了验证本方案的有效性,分别将数据集在YOLOv4主干提取网络为MobileNetV3和CSPDarknet53上进行训练,每训练出一层就记录下该层的损失量,如图13所示,是所记录的网络的损失函数曲线。两者验证误差收敛速度很快,但本文改进后的算法较改进前的算法在参数解冻前和解冻后训练一层所消耗时间都有较大改善,MobileNetV3-YOLOv4 在参数解冻前训练完成一层所消耗时间约 5min20s,解冻后所消耗时间约为 6min45s;YOLOv4 参数解冻前训练完成一层所消耗时间约为13min58s,解冻后训练文训练完一层所消耗时间约为 32min49s。
4 结论
本文在YOLOv4 目标检测网络的基础上改进后,获得 MobileNetV3-YOLOv4模型。在模拟超市环境下进行目标检测来验证该网络模型的有效性,最终在模拟环境下进行目标检测实验,结果表明改进后的模型识别速度在改进前提升了约 21%,同时改进后的网络数据集总量降为原来的 1/5,简化了参数的复杂程度。但局限于商品种类不是很多,并存在漏检。为进一步增强模型的泛化能力,我们后续会尝试使用更多商品种类和拍摄角度进行训练和改进。
参考文献:
[1] Liu W,Anguelov D,Erhan D,et al.SSD:single shot MultiBox detector[C]//Computer Vision–ECCV 2016,2016.
[2] Tian Y N,Yang G D,Wang Z,et al.Apple detection during different growth stages in orchards using the improved YOLO-V3 model[J].Computers and Electronics in Agriculture,2019,157:417-426.
[3] 李鹏飞,刘瑶,李珣,等.YOLO9000模型的车辆多目标视频检测系统研究[J].计算机测量与控制,2019,27(8):21-24,29.
[4] 赵莹.基于图像特征匹配的商品识别算法[D].上海:上海电机学院电子信息学院,2014.
[5] 刘永豪.基于深度学习的货架商品检测技术研究[D].杭州:浙江大学 ,2017.
[6] Russakovsky O,Deng J,Su H,et al.ImageNet large scale visual recognition challenge[J].International Journal of Computer Vision,2015,115(3):211-252.
[7] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014. 2, 4.
[8] C. Szegedy, S. Ioffe, and V. Vanhoucke. Inception-v4,inception-resnet and the impact of residual connections on learning. CoRR, abs/1602.07261, 2016. 2.
[9] BOCHKOVSKIY A,WANG C Y,LIAO H Y. Yolov4:optimal speedand accuracy of object detection[DB/OL]. https://arXiv:2004.10934.
[10] 胡丹丹,張莉莎,张忠婷.基于改进YOLOv3和立体视觉的园区障碍物检测方法[J].计算机测量与控制,2021,29(9):54-60.
[11] 王林,刘盼.基于卷积神经网络的行人目标检测系统设计[J].计算机测量与控制,2020,28(7):64-68,96.
[12] Howard A,Sandler M,Chen B,et al.Searching for MobileNetV3[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV).Seoul,Korea (South).IEEE,:1314-1324.
[13] Wang C Y,Mark Liao H Y,Wu Y H,et al.CSPNet:a new backbone that can enhance learning capability of CNN[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW).Seattle,WA,USA.IEEE,:1571-1580.
[14] HOWARD A G,ZHU M,CHEN B,et al. Mobilenets:efficient con?volutional neural networks for mobile vision applications[DB/OL].https://arxiv.org/abs/1704.04861.
[15] Ramachandran P , Zoph B , Le Q V.Searching for Activation Functions[Z].2017.
[16] He K M,Zhang X Y,Ren S Q,et al.Spatial pyramid pooling in deep convolutional networks for visual recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(9):1904-1916.
[17] Liu S,Qi L,Qin H F,et al.Path aggregation network for instance segmentation[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,UT,USA.IEEE,:8759-8768.
[18] Misra D.Mish:A Self Regularized Non-Monotonic Neural Activation Function[Z].2019.
【通聯编辑:梁书】
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
疯狂英语·新策略(2019年10期)2019-12-13
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
