子空间结构保持的多层极限学习机自编码器
2022-05-28 10:34陈晓云
自动化学报 2022年4期
陈晓云 陈 媛
自编码器(Autoencoder,AE)[1]是一种非线性无监督神经网络,也是一种无监督特征提取与降维方法,通过非线性变换将输入数据投影到潜在特征空间中.AE 由编码器和解码器组成,可将输入数据编码为有意义的压缩表示,然后对该表示进行解码使得解码输出与原始输入相同,即解码器输出和输入数据间的重构误差最小.当投影的潜在特征空间维数低于原始空间时,AE 可视为非线性主成分分析的一种表示形式[1].随着深度学习的成功,其在多个领域取得了重要突破[2],而深度自编码器作为一种无监督深度神经网络被用于数据降维[3-4]、图像降噪[5]和信号处理[6-7]以提取数据的深层表示特征.例如深度子空间聚类(Deep subspace clustering,DSL-l1)[8]通过深度自编码器对稀疏子空间聚类进行扩展,在深度自编码器的编码器和解码器间引入自表达层,用反向传播算法对编码器的输出进行自表示系数矩阵的学习,以该自表示系数矩阵作为原始样本的相似度矩阵.DSL-l1模型是全连接卷积神经网络并使用l1范数,求解模型的反向传播算法时间及空间复杂度较高.为提高计算效率,需先执行主成分分析法对数据降维.
无监督的极限学习机自编码器(Extreme learning machine autoencoder,ELM-AE)[9]是一种单隐层前馈神经网络,其输入层到隐层的权值和偏置值随机给定,学习过程只需通过优化最小二乘误差损失函数即可确定隐层到输出层的权值.最小二乘损失函数的优化问题有解析解,可转化为Moore-Penrose 广义逆问题求解[10].因此本质上相当于直接计算网络权值而无需迭代求解,相比反向传播和迭代求解的神经网络学习方法,学习速度快、泛化性能好,因此本文以ELM-AE 作为基础自编码器.
极限学习机自编码器与极限学习机(Extreme learning machine,ELM)[11]类似,主要不同之处在于ELM-AE 的网络输出为输入样本的近似估计,ELM 的网络输出为输入样本的类标签.极限学习机自编码器虽然学习速度快,但仅考虑数据全局非线性特征而未考虑面向聚类任务时数据本身固有的多子空间结构.
除极限学习机自编码器以外,无监督极限学习机(Unsupervised extreme learning machine,USELM)[12]也是一种重要的无监督ELM 模型,它采用无类别信息的流形正则项替代ELM 模型中含类标签的网络误差函数,经US-ELM 投影后保持样本间的近邻关系不变.US-ELM 虽考虑了样本分布的流形结构,但其流形正则项在高维空间中易出现测度 “集中现象”且未考虑不同聚簇样本间的结构差异.在US-ELM 模型基础上,稀疏和近邻保持的极限学习机降维方法(Extreme learning machine based on sparsity and neighborhood preserving,SNP-ELM)[13]引入全局稀疏表示及局部近邻保持模型,可以自适应地学习样本集的相似矩阵及不同簇样本集的子空间结构,其不足之处在于需迭代求解稀疏优化问题,运行时间较长.
综合上述分析,本文以ELM-AE 为基础自编码器,引入最小二乘回归子空间模型(Least square regression,LSR)[14]对编码器的输出样本进行多子空间结构约束,提出子空间结构保持的极限学习机自编码器(Extreme learning machine autoencoder based on subspace structure preserving,SELM-AE)及其多层版本(Multilayer SELM-AE,ML-SELM-AE),使面向聚类任务的高维数据经过ML-SELM-AE 降维后仍能保持原样本数据的多子空间结构,并可获取数据的更深层特征.
1 极限学习机自编码器
极限学习机自编码器降维方法通过将输入作为网络输出学习极限学习机网络,其学习过程分为编码和解码过程,学习目标是最小化重构误差.图1给出ELM-AE 模型网络结构.对于由n个样本组成的聚类数据集xi是网络输入变量,网络输出为xi的近似估计.
ELM-AE 网络的目标是计算最优的隐节点到输出节点的权值矩阵β,使得在该权值下的网络输出与期望输出xi间的误差最小.对n个样本xi(i=1,2,···,n)组成的数据集X,ELM-AE 网络的优化模型定义为:

h(xi)=(g(w1,b1,xi),···,g(wnh,bnh,xi))为隐层关于xi的输出向量,nh为隐节点个数;wj为第j个隐节点的输入权值,bj为第j个隐节点的偏差,输入权值wj和隐节点偏差bj均随机产生,其取值区间为[-1,1];g(wj,bj,xi)为第j个隐节点的激励函数,本文采用Sigmoid 函数:

模型(1)第1 项与ELM 模型相同,最小化隐层到输出层的权值矩阵β的l2范数,以控制模型的复杂度;模型第2 项为重构误差,表示ELM-AE网络的输出H(X)β与原始输入数据X的误差,重构误差越小,β越优.c为平衡模型复杂度和误差项的参数.理想情况下,ELM-AE 网络的输出H(X)β与真实值X相等,即X=H(X)β,此时误差为零.
ELM-AE 模型与ELM 模型不同之处在于ELM 隐层到输出层的最优权矩阵β通过最小化网络输出H(X)β与真实类标签Y的误差得到;而ELM-AE 隐层到输出层的最优权矩阵β通过最小化网络输出H(X)β与输入数据矩阵X的误差得到,因此ELM-AE 可以看成是对数据矩阵X的非线性特征表示.为实现数据降维,增加对输入权向量w及偏置b的正交约束.当样本xi原始维数m大于隐节点个数nh时,输入样本可被投影到较低维特征空间,其对应的隐含层输出向量h(xi)为:

式(1)描述的ELM-AE 模型是凸优化问题且该问题仅含单变量β,对其目标函数关于β求导并令导数等于0,即可得到该问题的解析解如下:

其中,β*是nh×m矩阵.据文献[9],ELM-AE 通过对原始高维数据X乘以隐含层与输出层间的权值矩阵β实现降维,即X'=X(β*)T就是所需的降维后样本.
2 子空间结构保持多层极限学习机自编码器
极限学习机自编码器ELM-AE 虽然实现了无监督非线性降维,但未考虑面向聚类任务的高维数据所蕴含的多子空间结构,难以保证降维结果与聚类目标相匹配.因此,本文提出子空间结构保持极限学习机自编码器SELM-AE,该模型在ELM-AE输出层之后增加自表示层,使ELM-AE 输出H(X)β保持输入数据X的多子空间结构不变.
2.1 子空间结构的获取
为获取数据的子空间结构,通常采用样本矩阵作为字典,得到数据自表示模型X=XZ(Z∈Rn×n),即每一样本用所有其他样本的线性组合表示,所有样本的组合系数构成自表示系数矩阵.由此学习到的自表示系数矩阵Z隐含了样本间的相似关系与子空间结构,理想情况下多簇数据的自表示系数矩阵具有块对角性.
文献[15]已证明,在假设子空间独立情况下,通过最小化Z的F范数,可以保证Z具有块对角结构,即当样本点xi和xj位于同一子空间时Zij≠0,位于不同子空间时Zij=0.关于Z的自表示优化模型可采用最小二乘回归(LSR)模型,即
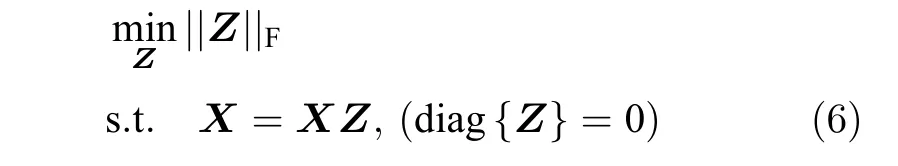
在实际应用中,观测数据通常包含噪声,噪声情况下该模型可扩展为:

2.2 子空间结构保持极限学习机自编码器(SELMAE)
由式(7)学习得到的自表示系数矩阵Z=[Z1,···,Zn] (Zi∈Rn为xi的表示系数),包含数据的子空间结构信息.为使极限学习机自编码器的网络输出=H(X)β仍保持这种子空间结构,在极限学习机自编码器的输出层之后增加自表示层,使得网络输出与输入的自表示系数相同,即(H(X)β)T=(H(X)β)TZ.SELM-AE 的网络结构如图2 所示,其中图2(a)用于根据式(7)学习X的自表示系数矩阵Z;图2(b)在 ELM-AE 网络的输出层之后增加网络输出H(X)β的自表示层,使网络输出H(X)β与输入X有相同的子空间结构.

图2 SELM-AE 网络结构Fig.2 Network structure of SELM-AE
图2(b)将输入数据X的自表示系数矩阵Z引入子空间结构保持的极限学习机自编码器(SELAAE)的自表示层,其优化模型如下:

模型前两项与式(1)描述的 ELM-AE 模型相同,第3 项则为自表示误差项,也称子空间结构保持项,用以使SELM-AE 的网络输出H(X)β保持原始数据的子空间结构,c是自编码重构误差项的平衡参数,λ是自表示误差项的平衡参数.
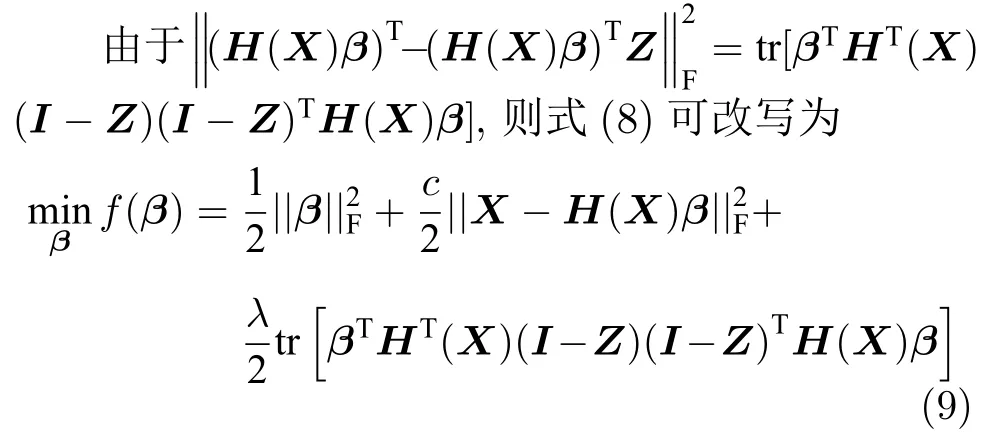
2.3 模型求解
为求解SELM-AE 模型即式(9),可令A=(IZ)(I-Z)T,则式(9)等价表示为
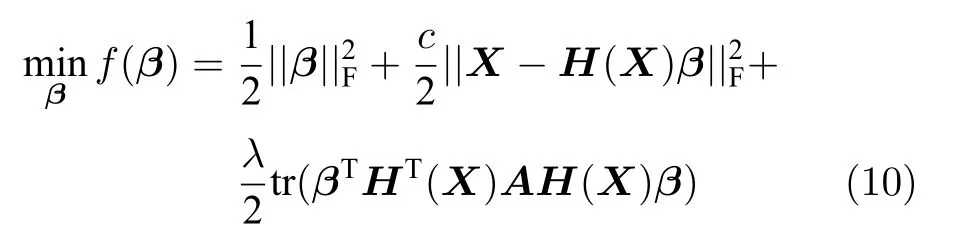
式(10)是凸优化问题,对其目标函数f(β)关于β求导并令导数为0 得到

最优权值矩阵β*与隐层输出H(X)相乘既可得到网络的输出H(X)β,该输出是网络对输入X的最佳估计.网络权值矩阵β是隐含层到网络输出层即输入数据的线性变换,可通过最优权值矩阵β*进行降维,降维后样本为X'=X(β*)T.
2.4 多层极限学习机自编码器(ML-SELM-AE)
由第2.3 节讨论可知,通过SELM-AE 模型可以直接计算隐含层到输出层的最优权值矩阵β*,计算速度快,泛化性好.SELM-AE 网络以数据降维表示为目标,其降维后样本维数与隐层节点数相等,因此隐层节点数量通常远小于原始维数和样本数.但作为单层神经网络,较少的隐层节点会降低其对非线性投影函数的逼近能力.受文献[16]的深度有监督极限学习机方法启发,本文扩展单层子空间结构保持极限学习机自编码器SELM-AE 为多层子空间结构保持极限学习机自编码器ML-SELMAE (如图3),以获取数据的深层特征.
图3 所示的多层子空间结构保持极限学习机自编码器相当于多个SELM-AE 自编码器的堆叠,利用上述式(11)计算每一层最优权值矩阵β(l)(l=1,2,···,L),将上一层输出X(l)(β(l))T作为下一层输入.ML-SELM-AE 网络第l层(l=1,2,...,L)随机产生正交输入权矩阵W(l)和偏置向量b(l);第1 层初始输入为原始数据X(1)=X,第l层(l=1,2,···,L)的权值矩阵β(l)根据式(11)改写为:

图3 ML-SELM-AE 网络结构Fig.3 Network structure of ML-SELM-AE

第l+1 层输入X(l+1)可通过下式计算:
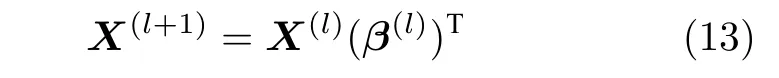
其中,β(l)为第l层解码器的输出权矩阵.若自编码器有L层,则第L层的输出X(L+1)=X(L)(β(L))T,即为降维后数据,对降维后数据X(L+1)使用k-means算法完成聚类.
多层子空间结构保持极限学习自编码器MLSELM-AE 求解算法归纳如下:
算法1.ML-SELM-AE 算法


ML-SELM-AE 算法中步骤 1)的时间开销主要用于矩阵乘法与n阶矩阵逆的计算,时间复杂度分别为O(n2m)和O(n3);若多层极限学习机网络层数为L,则步骤3)需循环L次计算每一层SELMAE 的输出权值β(l)及输出X(l),每次循环的时间开销主要用于权值β(l)的计算,包括计算矩阵乘法与nh阶矩阵的逆,矩阵乘法计算时间复杂度分别为O(nh2m)和O(nhnm),矩阵逆的计算时间复杂度为O(nh3).对于高维小样本数据集,样本数n远小于样本维数m,故而当样本维数m小于隐层节点数nh时,算法总时间复杂度为O(Lnh3);当样本维数m大于隐层节点数nh时,算法总时间复杂度为O(Lnh2m).
3 实验
3.1 实验对比方法及参数设置
为验证本文所提的子空间结构保持单层极限学习机降维自编码器SELM-AE 和多层极限学习机自编码器ML-SELM-AE 的降维效果和有效性,本文对两种方法进行数据可视化及高维数据降维聚类实验.
实验对比的其他降维方法有以下几种:
1)线性无监督降维
主成分分析法(Principal component analysis,PCA)[17]:以最大化投影方差为目标,方差虽可以刻画全局分布散度,但无法描述样本间的近邻关系.
局部保持投影法(Locality preserving projections,LPP)[18]:以保持降维前后样本间的近邻关系不变为目标.
近邻保持嵌入法(Neighborhood preserving embedding,NPE)[19]:以最小化k近邻重构误差为目标,旨在保持降维前后样本间的局部近邻结构.
2)传统无监督ELM
US-ELM:无监督极限学习机,利用无类别信息的流形正则项代替含类标签的误差函数,将有监督极限学习机转化为无监督极限学习机,实现原始数据向低维空间的非线性映射,并能够得到显式的非线性映射函数.但该方法预定义的近邻矩阵不具有数据自适应性.
ELM-AE:极限学习机自编码器,用原始数据替代误差函数中的类标签,将有监督极限学习机转化为无监督式的极限学习机自编码器,实现原始数据向低维空间的非线性映射.但该方法仅考虑数据全局非线性特征.
ELM-AE 的多层版本(Multilayer ELM-AE,ML-ELM-AE):其多层扩展的思想与本文提出的ML-SELM-AE 相同.目的在于和ML-SELM-AE(子空间结构保持的多层极限学习机自编码器)进行对比.
3)面向聚类的子空间结构保持无监督ELM
SNP-ELM:基于稀疏和近邻保持的极限学习机降维算法,该方法引入稀疏及近邻保持模型学习US-ELM 模型流形正则项所需的近邻矩阵,具有较好的数据自适应性.但需迭代求解稀疏优化问题,运行时间较长.
SELM-AE:本文提出的子空间结构保持极限学习机自编码器.该模型在ELM-AE 模型基础上,采用样本自表示模型刻画样本数据的子空间结构和样本间近邻关系,使网络输出数据保持子空间结构不变,具有较好的数据自适应性.
ML-SELM-AE:本文提出的SELM-AE 模型多层版本.
3.2 实验数据集
实验采用2 个脑电数据集、3 个高维基因表达谱数据及UCI 中的IRIS 数据集[20]进行测试,脑电数据集包括BCI 竞赛II 数据集IIb 中的Session 10 和Session 11、BCI 竞赛III 数据集II 中的Subject A 训练集[21],基因表达数据集包括DLBCL、Prostate0 和Colon[22].
研究表明,脑电数据中C3、Cz、C4、Fz、P3、Pz、P4、PO7、PO8 和Oz 这10 个电极的可分性更好[23],因此选取BCI 竞赛II 数据集Data set IIb 的该10个电极通道每轮行或列刺激后600 ms 的脑电数据作为实验数据并进行0.5~30 Hz 的巴特沃斯滤波;对BCI 竞赛III 数据集Data set II 选取相同10 个电极通道每轮行或列刺激后1 s 的脑电数据作为实验数据并进行0.1~20 Hz 的巴特沃斯滤波.数据集具体描述如表1 所示.
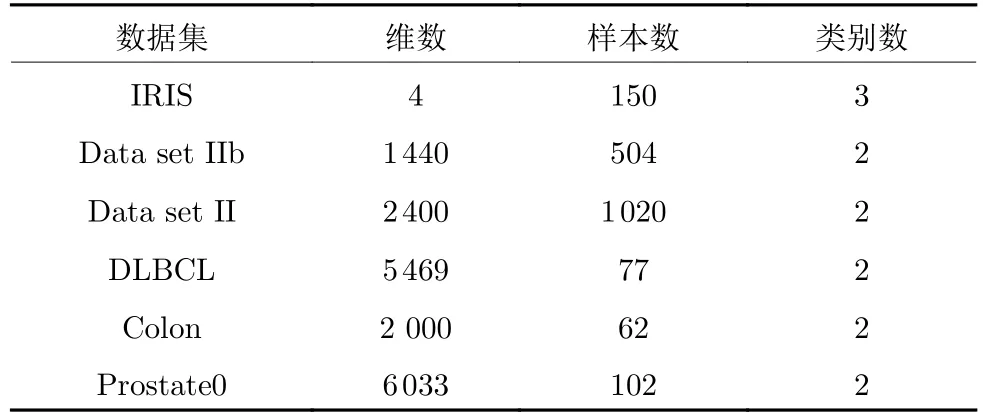
表1 数据集描述Table 1 The data set description
3.3 可视化实验
本实验分别用PCA、LPP、NPE、US-ELM、ELM-AE、SNP-ELM 和SELM-AE 七种方法将一个人造数据集和一个真实UCI 数据集投影到一维和二维空间,并选取每种降维方法的最优结果进行展示.
数据可视化及数据降维聚类实验采用相同的参数设置.LPP、NPE 和US-ELM 的近邻数k均取5.ELM-AE、SNP-ELM 和SELM-AE 的平衡参数c和λ均采用网格搜索策略设置,统一参数搜索范围为{10-3,10-2,···,103}.所有极限学习机算法的激励函数均采用Sigmoid 函数,含流形正则项的极限学习机降维方法US-ELM 和SNP-ELM 降维后样本维数由特征方程的特征向量个数决定,其隐层节点数设为1000.极限学习机自编码器降维方法ELM-AE 和SELM-AE 隐层节点数与降维后样本维数相同.多层算法 ML-ELM-AE 和 ML-SELMAE 中每一层的隐节点数均与第1 层相同,隐含层层数为 3.
3.3.1 一维可视化
本实验使用的二维人造双月数据集如图4 所示,该数据包含2 类,每类有150 个样本.该实验将双月数据用7 种不同降维方法降至一维后的结果如图5 所示.

图4 人造双月数据集Fig.4 Artificial double moon data set
从图5 可以看出,PCA 以投影后的样本方差最大为目标,其降维结果近似于把该数据投影到双月数据方差最大的X轴方向,投影后2 类样本交叠明显、可分性差;基于流形思想的LPP、NPE 和USELM 均以降维后样本保持原样本的近邻结构为目的,但US-ELM 投影到 1 维后的可分性明显优于LPP 和NPE,其降维后不同类样本的交叠程度较LPP 和NPE 更低.原因在于双月数据是非线性数据,而US-ELM 包含非线性神经网络结构,其对非线性特征的表示能力比仅采用流形思想的LPP 和NPE 更强.ELM-AE 也是基于极限学习机的非线性降维方法,其通过自编码网络刻画数据全局非线性特征,较之基于数据局部流形结构的US-ELM 方法,其降维后样本的可分性进一步改善.

图5 人造双月数据集一维可视化Fig.5 The 1D visualization of artificial double moon data set
SNP-ELM 和SELM-AE 也是非线性降维方法,均在极限学习机降维基础上引入子空间结构保持特性,SNP-ELM 使降维后样本同时保持数据的近邻结构和稀疏结构,SELM-AE 使自编码网络输出数据保持子空间结构不变,这两种方法尽可能保持原样本的潜在结构使该数据投影到1 维后2 类样本完全分离,不同类样本间没有交叠,且本文提出的 SELM-AE 方法投影后样本的内聚度较之SNPELM 更佳,类间可分性最优.
3.3.2 二维可视化
本实验使用的IRIS 数据包含3 类150 个样本,每个样本有4 个特征.分别采用PCA、LPP、NPE、US-ELM、ELM-AE、SNP-ELM 和SELM-AE 七种降维方法将IRIS 数据投影至2 维后如图6 所示.从图6 可以看出,二维可视化与一维可视化实验结论类似,即在七种降维方法中,SELM-AE 降维后样本同类聚集性最好,不同类样本交叠程度最低、可分性最优.

图6 IRIS 数据集的二维可视化Fig.6 The 2D visualization of IRIS data set
3.4 降维聚类对比实验
在6 个实验数据集上分别采用本文方法SELMAE、ML-SELM-AE 与对比方法PCA、LPP、NPE、US-ELM、ELM-AE、ML-ELM-AE、SNP-ELM 进行降维.其中多层极限学习机自编码器ML-ELMAE 和ML-SELM-AE 的层数L设为3,每层极限学习机的隐层节点数固定为降维维数.所有模型的最优参数均通过网格搜索得到,降维维数的搜索范围为{21,22,23,···,210};参数c和λ的搜索范围为{10-3,10-2,···,103};模型SNP-ELM 参数η和δ的搜索范围为[-1,1],搜索步长为0.2.
3.4.1 k-means 聚类
对降维后样本进行k-means 聚类,为避免kmeans 随机选取初始中心导致聚类结果的随机性,以10 次聚类的平均准确率为最终准确率[24].3 种传统降维方法PCA、LPP 和NPE 的聚类准确率(方差,维数)如表2 所示,6 种ELM 降维方法的聚类准确率(方差,维数)如表3 所示.表2 和表3 是网格搜索最优参数得到的最佳平均聚类准确率、方差及对应维数.
表3 中粗体值代表9 种降维方法中聚类准确率最高者,下划线值代表第2 高者,第3 高者采用粗体加下划线标记.由记.由表2~ 3 可以看出:

表2 传统降维方法的聚类准确率(%)(方差,维数)Table 2 Comparison of clustering accuracy of traditional methods (%)(variance,dimension)

表3 ELM 降维方法聚类准确率(%)(方差,维数)(参数)Table 3 Comparison of clustering accuracy of ELM methods (%)(variance,dimension)(parameters)
1)经3 种传统方法降维后的聚类准确率明显低于6 种 ELM 降维方法.原因在于PCA、LPP 和NPE 是全局线性降维模型,其对非线性数据特征的描述能力低于非线性极限学习机降维方法.
2)本文提出的ML-SELM-AE 在5 个数据集上取得最高的聚类准确率,在IRIS 数据集的准确率也接近最高值.主要原因在于子空间结构保持项和多层编码器结构分别揭示了原始数据的子空间结构和非线性特征.ML-SELM-AE 对应的单层方法SELM-AE 和未引入子空间结构保持项的多层自编码器ML-ELM-AE 聚类准确率均低于ML-SELMAE,SELM-AE 低0.3%~ 3.1%,ML-ELM-AE 低1.6%~ 5.6%,说明在准确率提升方面子空间结构保持项的作用优于编码器层数的增加.多层MLSELM-AE 与单层SELM-AE 在多数数据集上的聚类准确率不相上下,且单层SELM-AE 的计算速度更快.
3)对比方法SNP-ELM 的聚类准确率略低于ML-SELM-AE,与SELM-AE 相当,但优于未考虑子空间结构保持项的其他降维方法,且优势明显.进一步说明子空间结构保持的重要性.
SNP-ELM 模型的局限在学习样本的近邻表示和稀疏表示存在迭代求解过程,耗时较长.而本文的SELM-AE 模型有解析解,计算效率明显高于SNP-ELM,即使在多层情况下也快于SNP-ELM.从表4 给出的SNP-ELM、SELM-AE 和ML-SELMAE 运行时间便可以看出,SNP-ELM 的运行时间明显高于SELM-AE 和ML-SELM-AE,是二者的100 倍~1 000 倍.因此,综合考虑准确率和效率,本文提出的SELM-AE 和ML-SELM-AE 较之SNPELM 更有优势.

表4 运行时间对比(s)Table 4 Comparison of running time (s)
4)对比ELM-AE、SELM-AE 和相应的多层版本ML-ELM-AE、ML-SELM-AE,多层版本聚类准确率均高于对应的单层版本,差距普遍在0.2%~4.0%之间,说明增加网络层数可以提取更丰富的非线性特征,提高降维样本的聚类准确率.
3.4.2 多种聚类方法对比实验
为观察不同聚类方法的影响,进一步对降维前后数据应用三种子空间聚类方法进行聚类,包括最小二乘回归子空间聚类(LSR)[14]、低秩表示子空间聚类(L R R)[25]和潜在低秩表示子空间聚类(LatLRR)[26].为取得最优结果,3 种聚类模型的最优参数λ均通过网格搜索得到,LSR 和LRR 的参数搜索范围为{10-3,10-2,···,103},LatLRR 的参数搜索范围为{10-5,10-4,···,1}.
在6 个实验数据集上对未降维数据和采用MLSELM-AE 降至2 维后数据进行聚类实验,不同聚类方法的聚类准确率及方差如表5 所示.
从表5 可以看出,对于未降维高维数据,子空间聚类方法 LSR 和 LRR 均优于k-means 聚类.但经过ML-SELM-AE 降维后,k-means 聚类的准确率明显高于三种子空间聚类方法,且比未降维时的聚类准确率有显著提高.该实验结果进一步说明采用多层极限学习机和子空间结构保持可使降维数据蕴含更丰富的聚簇信息,聚类划分更容易.
3.4.3 多层极限学习机隐层节点数对聚类结果的影响
为观察多层极限学习机隐层节点数的不同设置对聚类结果的影响,将ML-ELM-AE 和ML-SELMAE 两种三层极限学习机自编码器的隐层节点数分别设为500-100-2、500-100-10、500-100-100 及2-2-2、10-10-10、100-100-100,并对高维数据集Data set IIb、Data set II、DLBCL、Colon 和Prostate0 进行降维和聚类,取得的k-means 聚类准确率如表6所示.
从表6 可以看出,在5 个实验数据集上,无论是ML-ELM-AE 还是ML-SELM-AE,三层隐层节点数均取2 时的聚类准确率最优.且隐层节点数取固定值与非固定值的聚类准确率差别不明显,固定隐层节点数的聚类准确率总体略好于不固定隐层节点数.
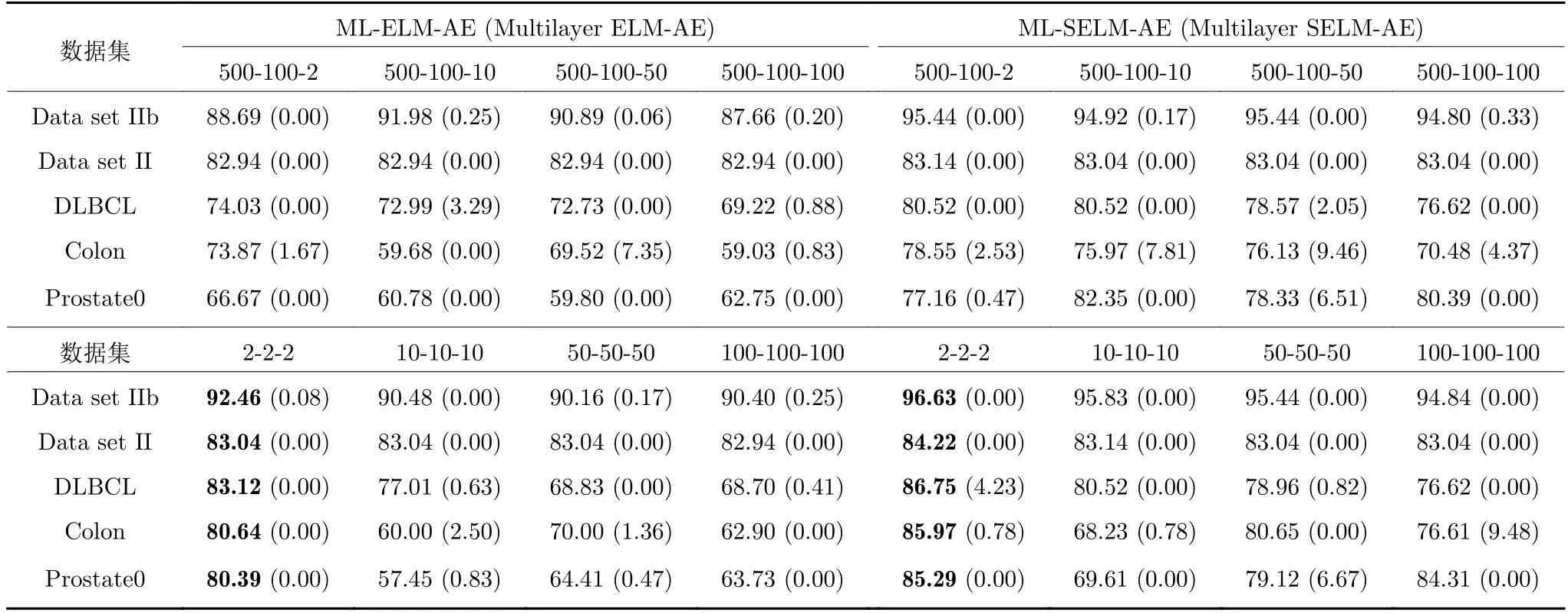
表6 三层极限学习机自编码器隐层节点数与聚类准确率(%)(方差)Table 6 The number of hidden layer nodes and clustering accuracy for three-layer extreme learning machine autoencoder (%)(variance)
3.5 SELM-AE 模型参数分析
由表5 的实验结果可知,本文提的SELM-AE模型将数据投影到2 维时便能取得较高的k-means聚类准确率,因此取固定维数2 情况下进行参数分析.SELM-AE 模型的参数c和λ,分别是目标函数中自编码重构误差项和子空间结构保持项的平衡参数.
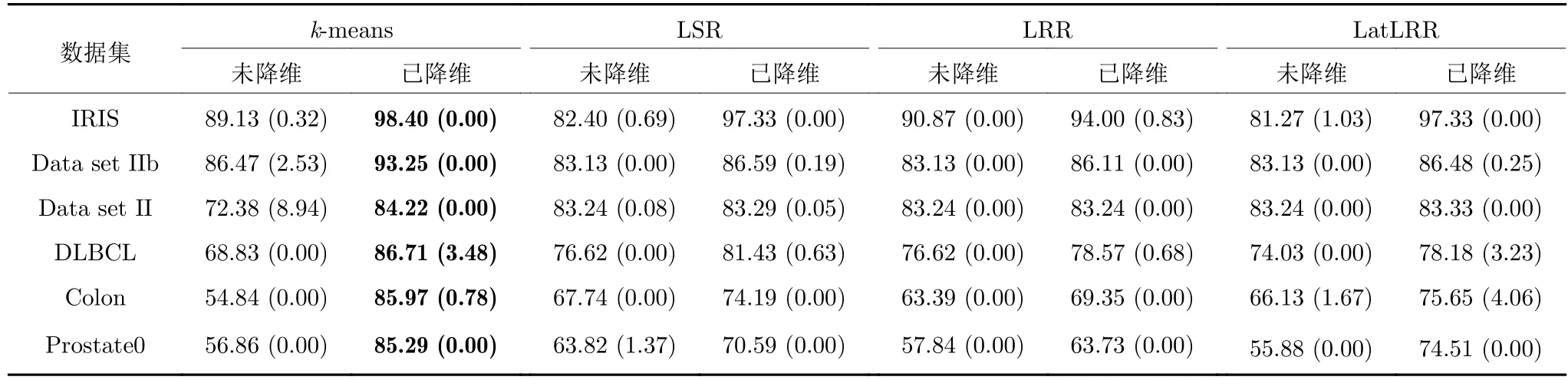
表5 ML-SELM-AE 降维前后数据的聚类准确率(%)(方差)Table 5 Clustering accuracy before and after ML-SELM-AE dimensionality reduction (%)(variance)
3.5.1 目标函数值随参数c 与λ 的变化情况
SELM-AE 模型以最小化目标函数值为目标.本实验目的在于观察模型的目标函数值随参数c和λ变化情况(如图7),c和λ的取值范围均为{10-3,10-2,···,103}.
由图7 可以看出,参数λ的变化对目标函数值的影响较小,而参数c的变化对目标函数值的影响较大.总体来看,参数c和λ在区间[0.001,10]内取值时,目标函数值最小.

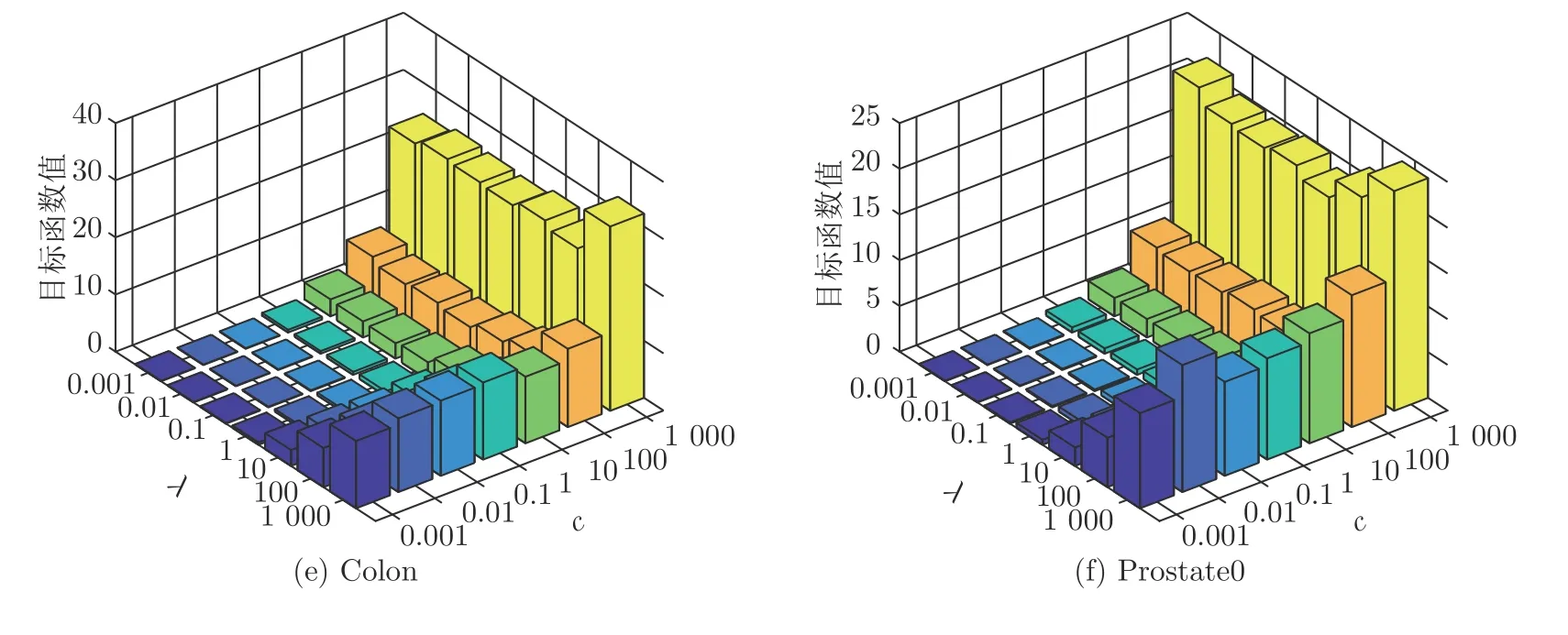
图7 不同c 和λ 下的目标函数值Fig.7 Objective function value under different c and λ
3.5.2 聚类准确率随参数c 与λ 的变化情况
为进一步观察SELM-AE 模型聚类准确率随参数c和λ的变化情况,图8 给出参数c和λ取不同值时的k-means 聚类准确率,其中c和λ的变化范围为{10-3,10-2,···,103}.由图8 可以看出,参数c和λ在区间[0.001,10]内取值时,能取得最高的聚类准确率,该参数的最佳取值区间与图7 的分析结论一致.

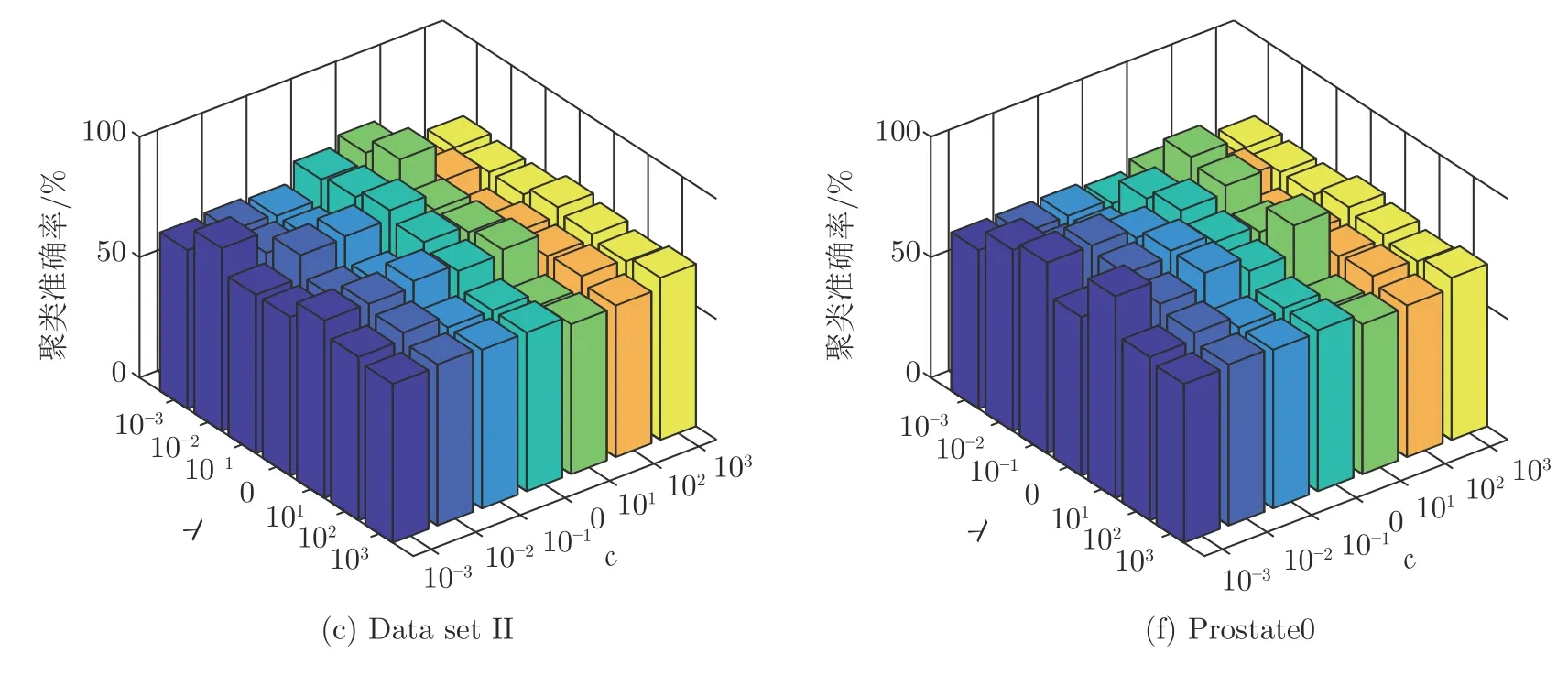
图8 不同c 和λ 取值下的聚类准确率Fig.8 Clustering accuracy under different values of c and λ
4 结束语
在极限学习机自编码器ELM-AE 基础上,本文提出子空间结构保持的极限学习机自编码器SELM-AE 及其多层版本ML-SELM-AE.SELMAE 在极限学习机自编码器的输出层增加自表示层,引入最小二乘回归子空间结构模型,使自编码器输出与输入的自表示系数相同.多层子空间结构保持极限学习自编码器ML-SELM-AE 通过增加 SELMAE 自编码器层数获取数据的深层特征,提高网络的特征提取能力.在6 个数据集上的实验结果表明,经SELM-AE 和ML-SELM-AE 降维后的聚类准确率普遍优于经典降维方法和传统的ELM 降维方法.同时多层ML-SELM-AE 因对非线性投影函数的逼近能力优于单层的SELM-AE 模型,其降维后数据的聚类准确率更高.
猜你喜欢
车主之友(2022年4期)2022-08-27
文萃报·周五版(2021年30期)2021-09-05
新农业(2020年18期)2021-01-07
阿来研究(2020年1期)2020-10-28
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
海峡姐妹(2019年12期)2020-01-14
北京航空航天大学学报(2017年6期)2017-11-23
环球人文地理·评论版(2016年8期)2017-01-19
天津农业科学(2016年12期)2017-01-11