基于背景值和结构相容性改进的多维灰色预测模型
2022-05-28 10:34缪燕子王志铭李守军
自动化学报 2022年4期
缪燕子 王志铭 李守军 代 伟
灰色预测模型(Grey model,GM)是灰色系统理论的基础和核心内容,其研究重点在于解决小样本、贫信息的不确定性问题,且灰色预测模型在众多领域都得到了广泛的运用[1].GM(1,1)模型是灰色预测的核心内容,是最简单、应用最广泛的单变量灰色预测模型.但GM(1,1)模型只包含一个因变量,不考虑外部其他因素对系统发展的影响,大量研究表明GM(1,1)模型的性能不够稳定,模拟精度不理想[2-5].因此提出了一种具有一个因变量和N-1个相关因素变量的多维灰色预测GM(1,N)模型[6].但传统的GM(1,N)模型由于背景值表达式构造的不精确,导致模型预测误差较大,且当取N=1时,其不能转化为对应的GM(1,1)模型,说明传统的GM(1,N)与GM(1,1)模型在结构上是不相容的[7].因此,在某些情况下GM(1,N)模型的预测精度甚至会低于GM(1,1)模型.在考虑多变量预测的同时,为了提高GM(1,N)模型的预测精度,国内外学者针对模型的结构、参数优化、背景值的优化等方面进行了相关研究分析[8-9].
针对背景值优化的问题,主要有插值法和拟合法等改进措施.为提高预测精度,文献[10] 通过Goldfeld-Quandt 检验区分GM(1,1)模型的异方差性,并采用插值法对背景值进行了优化,以此最小化原始序列平方误差之和的函数来构建其模型;文献[11]利用一次累加具有非齐次灰指数规律,构建动态序列模型,从积分几何意义的视角,利用函数逼近的思想,结合复化梯形公式改进模型背景值;文献[12]提出了一种优化背景值和调整初始系统参数的组合优化方法,通过优化灰色微分方程中的背景值来模拟和预测无偏指数分布的序列;文献[13]提出一种寻找模型平均拟合误差(ARPE)最小值的方法,采用粒子群优化算法对模型背景值系数进行优化,当ARPE 最小时的背景值系数取值即是模型的最优解,但其优化是针对传统背景值表达式,在背景值表达式构造上仍存在一定误差.
针对模型结构缺陷问题,主要有基于智能算法的结构选择及参数和结构融合优化等方法.文献[14-16]对初始条件、累加生成顺序、发展系数和背景值分布系数进行了参数优化,研究结果表明上述参数的优化对提高多维灰色预测模型的性能有积极的作用,但当N=1 时,GM(1,N)模型仍然不能等价于GM(1,1)模型,意味着这些改进的灰色预测模型在结构相容性上仍存在缺陷;文献[17] 提出了一种基于数据算法自适应选择模型结构的灰色预测模型,称为离散灰色多项式模型,该模型具有代表最普遍的同构和非同构离散灰色模型的能力,并且可以归纳出一些其他新颖的模型,从而突出了模型与其结构之间的关系;文献[18]在模型中加入了相邻变量滞后项、线性校正项和随机扰动项,其中线性校正项反映了因变量和自变量之间的线性关系,消除了解释变量之间的多重共线性问题,使模型的预测性能得到了显著的提高.
基于现有的文献我们发现传统GM(1,N)、GM(1,1)模型在构造背景值表达式时存在一定误差,且模型结构单一,从而导致模型预测精度不高,结构相容性不强等问题.因此,本文对以上两个问题进行了深入研究.
首先针对模型背景值的构造方法不准确,考虑传统模型背景值表达式固定用几何梯形面积近似方程来表示,而现有文献中的工作亦是基于该公式对参数进行优化,未能从根本上减小误差.本文从背景值函数表达式的几何意义出发,构造了一个新的背景值表达式,并采用MATLAB 数值分析对背景值系数的取值进行优化,使背景值系数的取值更灵活,减小了系统参数计算的误差,进而提高模型的预测精度.其次针对模型结构的缺陷,考虑传统灰色预测模型结构单一,结构相容性弱,泛化性能差,虽然现有文献中对各种系统参数及结构参数有所改进,但仍不能使模型具有较好的结构相容性.本文在预测模型中加入了灰色作用量,以反映自变量数据变换关系,改善了模型的结构相容性,提高模型的泛化能力,使模型预测性能得到显著提高.
本文所提的改进背景值及结构相容性的多维灰色预测模型(Improved background value and structure compatibility of grey prediction model,IBSGM(1,N))解决了传统多变量灰色预测模型预测性能不稳定的问题,该模型结构泛化能力强,鲁棒性好,适用于大部分多变量灰色预测系统.同时,本文突破了传统的模型改进思想,有效解决了对系统参数优化的同时使模型结构泛化性提高的问题,对多维灰色预测模型的改进方法上提供了新的思路.
1 多变量灰色预测模型及分析
灰色预测方法是一种用来对灰色系统进行预测的方法.通过对系统因素发展趋势之间的相关性分析,生成和处理原始数据,以找出系统的变化规律,生成一组有更明显规律的数据序列,并基于该数据序列建立微分方程模型,对事物的未来发展状态进行预测.
单变量GM(1,1)预测模型的基本原理是:对某一数据序列使用累加的方法生成一组变化趋势明显的新序列,对新的数据序列建立模型并进行预测,然后利用累减方法逆向计算,使其恢复为原始序列,得出预测模型结果[19].
多变量GM(1,N)预测模型的预测原理与单变量GM(1,1)预测模型类似,不同之处在于输入数据变量是N个.
GM(1,N)模型的建模过程如下:
设系统有特征数据序列:

为简化建模过程,传统GM(1,N)预测模型的背景值表达式固定为几何面积近似方程,致使模型参数估计产生误差;其次,模型结构单一,泛化性能不强,导致模型预测鲁棒性较差.因此,本文从改进背景值表达式及模型结构方面入手,提出一种新的多维灰色预测模型.
2 IBSGM(1,N)多维灰色预测模型
2.1 背景值优化
根据对构建灰色GM(1,N)预测模型的研究发现,参数a和b是影响模型预测精度的重要因素,而a和b的取值取决于背景值的参数估计公式,因此,提高背景值表达式构造的准确性,将直接提高模型的预测精度.
称Z(1)={Z(1)(2),Z(1)(3),···,Z(1)(n)} 为序列改进后的背景值序列,式(3)为改进的背景值表达式,其中参数λ为背景值函数的调节因子,称为背景值系数,且背景值系数的选取将会直接影响系统参数a和b的计算值,进而影响模型预测性能.
定理 1.对于给定的原始数据序列,定义1所给的优化背景值表达式(3)存在的误差小于传统背景值表达式存在的误差.即


图1 背景值几何示意图1Fig.1 Schematic diagram 1 of the background value


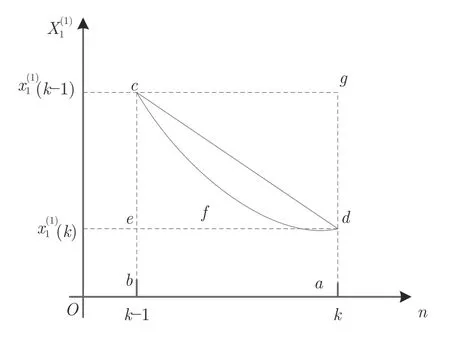
图2 背景值几何示意图2Fig.2 Schematic diagram 2 of the background value

2.2 IBSGM(1,N)预测模型


定理 2.对于定义2 中的IBSGM(1,N)模型,时间响应函数为


2.3 模型的结构相容性
在灰色系统理论中,有许多常见的单变量或多变量预测模型,如GM(1,1)、GM(1,N),不同的模型具有不同的结构和表达式,其对应的适用场景也有所差异.从传统GM(1,N)预测模型表达式中不难看出,当N=1 时,该模型并不能等价于GM(1,1)预测模型,因此,GM(1,N)与GM(1,1)模型结构不相容,即传统GM(1,N)模型泛化能力弱,适用性较差.而本文所提出的IBSGM(1,N)模型在满足一定条件时可以等价为传统GM(1,1)、GM(1,N)模型,具有较好的结构相容性.
命题 1.对于所提出的IBSGM(1,N)模型与传统的GM(1,1)模型,不考虑对背景值所做的优化改进,当N=1,a·b·γ0 时,IBSGM(1,N)模型即为GM(1,1)模型.
证明.对于所提IBSGM(1,N)模型,当N=1,a·b·γ0时,式(23)变为

根据定义1 提出的改进背景值表达式:

IBSGM(1,N)模型表达式可写为:
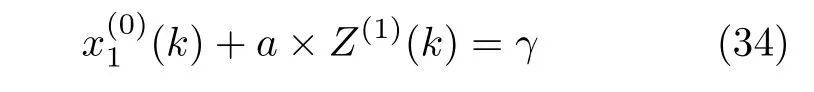
显然,式(34)即为GM(1,1)模型表达式,也就是说当N=1,a·b·γ0 时,不考虑对背景值所做的优化改进,IBSGM(1,N)模型可以等价为GM(1,1)模型,称其与GM(1,1)模型具有结构相容性.□
命题 2.对于所提出的IBSGM(1,N)模型与传统的GM(1,N)模型,不考虑对背景值所做的优化改进,当N>1,a·b0,γ=0 时,IBSGM(1,N)模型即为GM(1,N)模型.
证明.对于IBSGM(1,N)预测模型,当N>1,a·b0,γ=0 时,式(23)变为
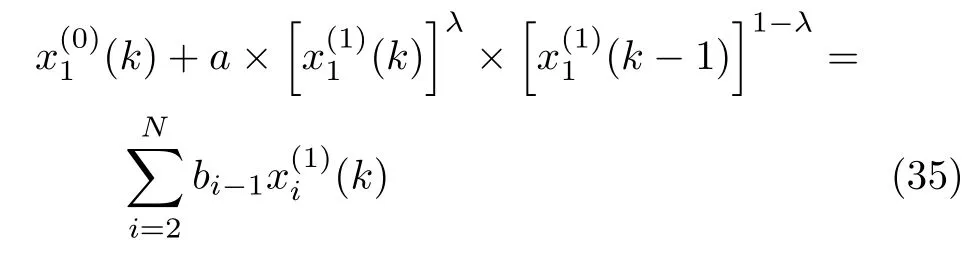
根据定义1 提出的改进背景值表达式:

IBSGM(1,N)模型表达式可写为:

显然,式(37)即为GM(1,N)模型表达式,也就是说当N>1,a·b0,γ=0 时,不考虑背景值所做的优化改进,IBSGM(1,N)模型可以等价为GM(1,N)模型,称其与原GM(1,N)模型具有结构相容性.
3 模型性能比较与分析
3.1 背景值系数的估计
为了确定背景值系数的取值,采用MATLAB对多维灰色预测模型进行数值分析,通过穷举法计算在不同λ取值下IBSGM(1,N)模型的平均拟合误差ε,使ε达到最小值时的λ取值即为改进多维灰色预测模型的最优背景值系数.
具体步骤如下:
步骤 1.输入原始特征序列及相关因素序列在MATLAB 中建立IBSGM(1,N)预测模型;

步骤 2.初始化背景值系数λ=0;
步骤 3.λ以步长0.01 增加至1 迭代计算模型平均拟合误差ε;
由定理2 可得一次累加序列模拟值:


步骤 4.求得使平均拟合误差ε取得最小值时的λ值即为IBSGM(1,N)预测模型的最优背景值系数解.


表1 寸草塔煤矿日均瓦斯浓度及影响因素Table 1 Daily average gas concentration and influencing factors in Cuncaota Coal Mine
利用MATLAB 仿真实验,当λ∈[0,1] 时,λ从0 开始以0.01 的精度逐渐增大,求得模型拟合误差最小值ϵ=0.0337,此时λ=1.由此可得,在该组实验数据下,当背景值系数λ=1 时,模型拟合误差最小、预测精度最高,且IBSGM(1,N)模型拟合误差为3.37%,较传统GM(1,N)预测模型拟合精度有显著提高.IBSGM(1,N)与GM(1,N)模型预测模拟值对比见表2.

表2 IBSGM(1,N)与GM(1,N)模型预测模拟值误差对比Table 2 Comparison of prediction and simulation errors between IBSGM(1,N)and GM(1,N)model
3.2 预测结果对比分析
为了检验所提出的IBSGM(1,N)模型的性能,本文进行了三个实例研究,计算了IBSGM(1,N)多维灰色预测模型分别在三组实验数据下的模拟值和预测结果误差,并与其他常用的单变量和多变量灰色预测模型的拟合情况及预测性能进行了对比分析.
例 1.文献[22]提出了一种可以构造出自变量与因变量之间函数关系预测模型,称为OGM(1,N)预测模型,利用该模型对一种材料在400℉至1100℉温度范围内的抗拉强度和布氏硬度的实验数据进行了实验,实验数据如表3 所示,由于温度条件的限制,该组样本只有400℉至1100℉范围内的8 组数据,具有小样本数据集特征.本文采用同样的数据比较了IBSGM(1,N)模型与其他灰色预测模型的模拟和预测性能.

表3 一种热处理钢在400℉至1100℉的抗拉强度及布氏硬度Table 3 The tensile strength and Brinell hardness of a heat-treated steel from 400°F to 1100°F
示例实验数据中有三个变量,其中为特征序列抗拉强度(MPa),相关因素序列为布氏硬度(HBW),为温度(℉).取前七组数据作为建模样本,第八组数据作为测试样本,利用MATLAB建立的IBSGM(1,N)模型进行计算,得到模型参数值 [a,b1,b2,γ,λ]T结果如表4 所示,模型预测结果及误差对比如表5 所示.

表4 IBSGM(1,N)模型的参数值Table 4 Parameter values of IBSGM(1,N)model

表5 四种模型下预测结果和误差对比Table 5 Comparison of prediction results and errors under the four models
由表4 可以看出,针对该组数据,IBSGM(1,N)模型平均拟合误差为0.0573%,GM(1,1)模型拟合误差小于1%,但预测误差接近5%,GM(1,N)模型拟合及预测误差较大,预测性能不稳定.相较于传统GM(1,1)和GM(1,N)灰色预测模型,IBSGM(1,N)模型的平均拟合误差及预测结果相对误差均要小得多,且相较于文献[22]中提出的OGM(1,N)模型,IBSGM(1,N)模型的模拟及预测性能也更胜一筹.
四种模型的模拟预测结果如图3 所示,可以看出IBSGM(1,N)模型实现了高精度预测,且GM(1,N)模型拟合性能较GM(1,1)更差,验证了GM(1,N)模型缺陷分析的准确性,OGM(1,N) 与IBSGM(1,N)模型曲线均贴合实际值曲线,但IBSGM(1,N)模型的模拟和预测性能更好.

图3 例1 中四种模型的模拟预测结果曲线图Fig.3 Curves of simulated prediction results of the four models in Example 1
例 2.文献[13]提出了一种改进动态背景值系数OBGM(1,N)模型,通过粒子群算法寻找系统相对误差最小值以此求解背景值系数,利用该模型对文献[23]中给出的中国无线通信用户人数和其他影响因素的数据进行了模拟预测,实验数据如表6所示,该文献只公布了2000 年至2010 年相关数据,属于小样本数据集.本文采用同样的数据比较了IBSGM(1,N)模型与其他灰色预测模型的模拟和预测性能.

表6 中国无线通信用户数量和相关因素Table 6 Number of wireless communication users and related factors in China

表7 IBSGM(1,N)模型的参数值Table 7 Parameter values of IBSGM(1,N)model
由表8 可以看出,IBSGM(1,N)预测模型在该组实验数据下的平均拟合误差为0.25%,而传统GM(1,N)模型的拟合误差高达21.59%,相较于传统GM(1,1)和GM(1,N)灰色预测模型,IBSGM(1,N)模型的平均拟合误差及预测结果相对误差均要小得多,且IBSGM(1,N)模型的模拟及预测性能比文献[10]中的OBGM(1,N)模型性能更好.
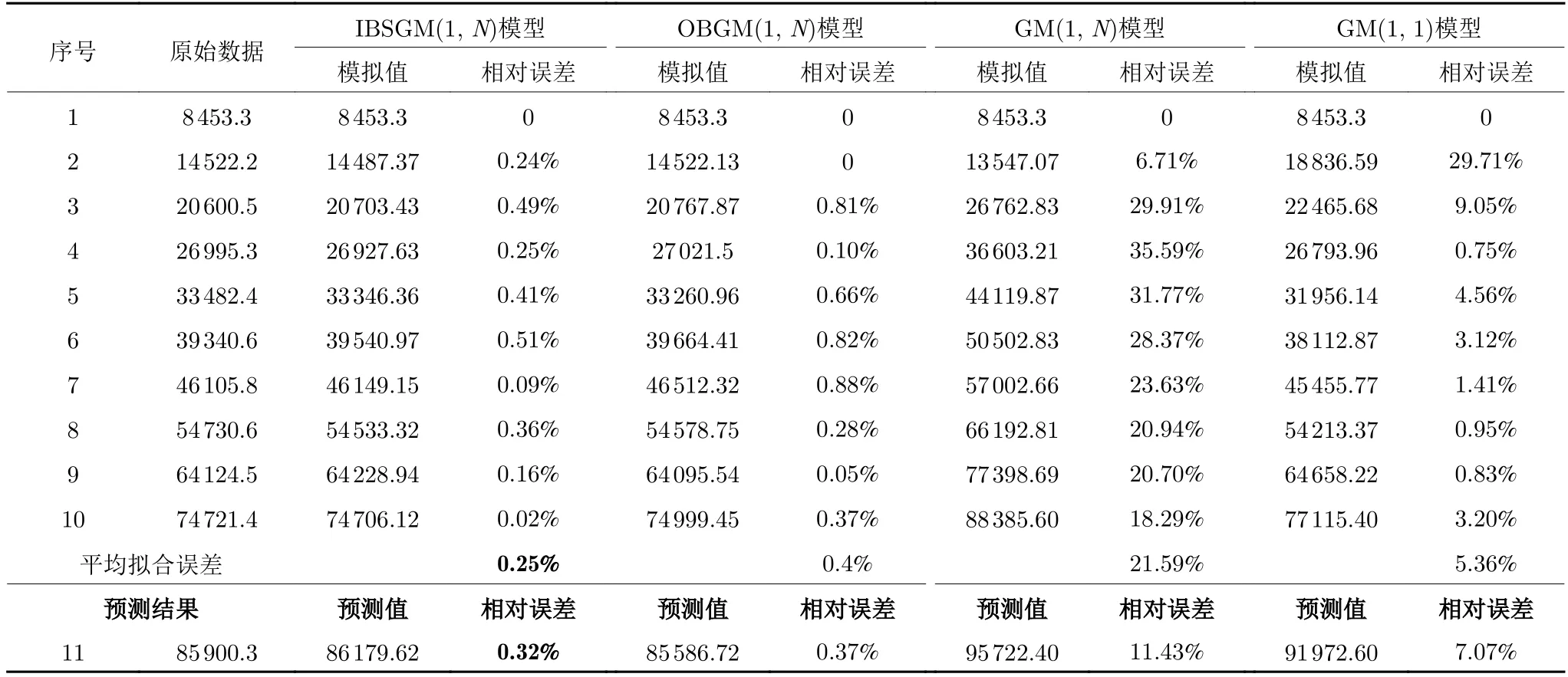
表8 四种模型下预测结果和误差对比Table 8 Comparison of prediction results and errors under the four models
四种模型的模拟预测结果如图4 所示,可以看到在四种模型中IBSGM(1,N)预测模型具有最高的预测精度,与实际数据拟合度最高,拟合误差明显小于GM(1,N)与GM(1,1)模型,虽然OBGM(1,N)模型也取得了较高的精度,但IBSGM(1,N)模型由于背景值取值更加灵活,结构相容性更强,预测性能更好.
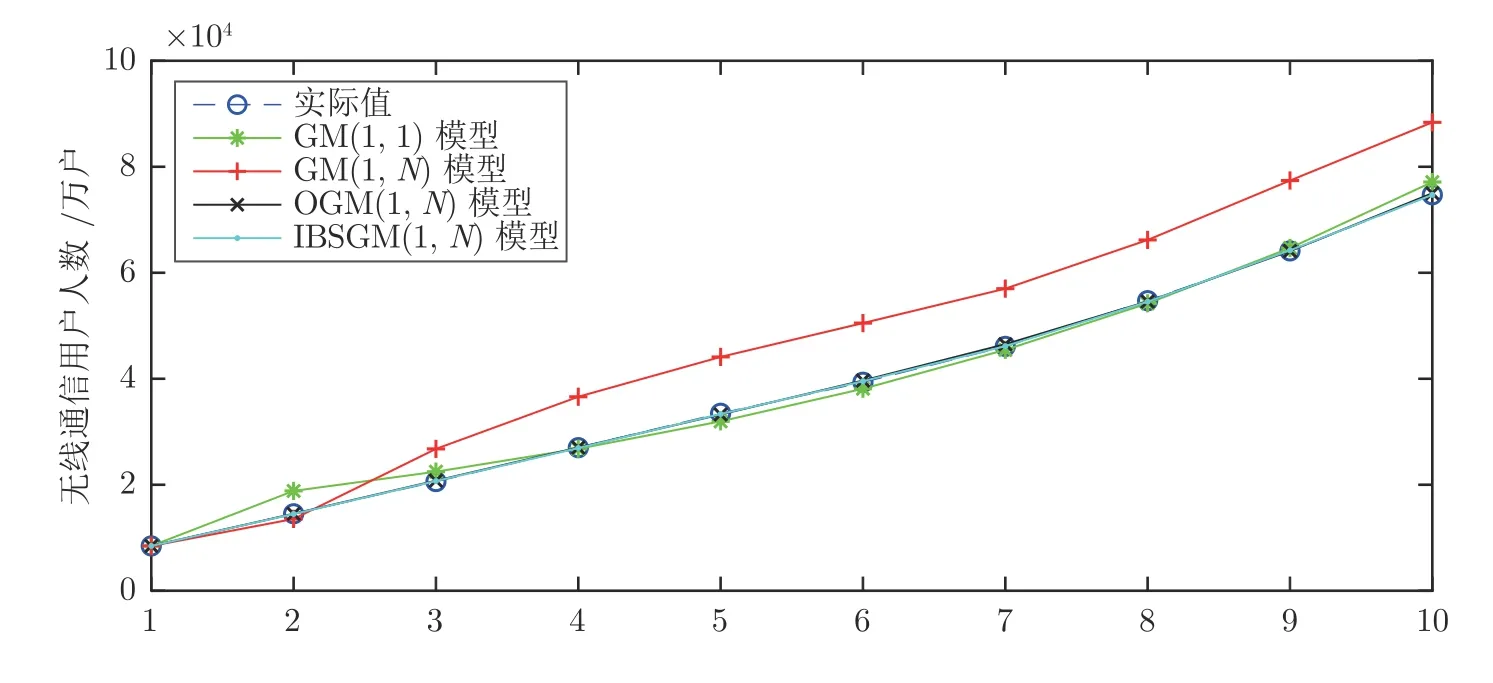
图4 例2 中四种模型的模拟预测结果曲线图Fig.4 Curves of simulation prediction results of the four models in Example 2
例 3.文献[24]提出了一种改进的多变量时滞GM(1,N)预测模型,利用该模型对浙江省经济总产值与固定资产投资额进行预测,实验数据如表9所示,由于所用数据时《浙江省统计年鉴》只公布了2003~ 2011 年的固定资产投资额数据,具有小样本数据集特征.本文采用同样的数据样本比较了IBSGM(1,N)模型与其他灰色预测模型的模拟和预测性能.

表9 2003-2011 年浙江省经济总产值与固定资产投资额Table 9 2003-2011 Zhejiang province′s total economic output value and fixed asset investment

表10 IBSGM(1,N)模型的参数值Table 10 Parameter values of IBSGM(1,N)model
由表11 可以看出,IBSGM(1,N)模型在该组实验数据下的平均拟合误差为1.52%,而传统GM(1,N)模型的拟合误差高达11.01%,传统GM(1,1)模型拟合误差为2.22%,且相较于文献[24]中提出的时滞GM(1,N)预测模型,本文所提出的IBSGM(1,N)预测模型在拟合效果及预测精度上都有更优的表现,对比三种模型的预测结果,IBSGM(1,N)模型的预测相对误差为0.66%,实现了高精度预测.

表11 四种模型下预测结果和误差对比Table 11 Comparison of prediction results and errors under the four models
四种模型的模拟预测结果如图5 所示,可以看到在四种模型中IBSGM(1,N)预测模型具有最高的预测精度,与实际数据拟合度最高,拟合误差明显小于传统的GM(1,N)、GM(1,1)预测模型及时滞GM(1,N)预测模型.分析实验结果表明,IBSGM(1,N)模型由于背景值取值更加灵活,结构相容性更强,使模型预测性能显著提高.
4 结论
现有的传统GM(1,N)多维灰色预测模型在实际预测领域中应用并不广泛,主要由于其背景值表达式的构造存在较大误差及模型结构上存在缺陷.传统灰色预测模型为简化建模过程,其背景值表达式固定用几何梯形面积近似方程来表示,本文从背景值函数的几何意义出发,构造了一个新的背景值表达式,采用MATLAB 数值分析对背景值系数的取值进行优化,并从理论上证明了新的背景值函数相较传统模型背景值函数的误差更小.考虑到传统GM(1,N)预测模型在结构上与GM(1,1)等基础预测模型不兼容的问题,在模型中加入了灰色作用量,以反映自变量数据变换关系.通过理论证明,改进的IBSGM(1,N)模型具有与传统单变量和多变量灰色预测模型的结构相容性.本文通过对三个实验案例的研究,计算了IBSGM(1,N)的模拟值和预测误差,并与其他常见的灰色预测模型进行了对比分析,可以看出,由于本文所提IBSGM(1,N)模型背景值取值更加灵活,结构相容性更强,使模型预测性能有显著提高.
本文提出的结合背景值优化与改进模型结构相容性方法,在理论证明和实验分析中均取得了较好的结果.本文在对多维灰色预测模型的改进方法上进行了创新,所提出的IBSGM(1,N)模型在预测精度和结构相容性方面有较强的优势,适用于常规条件下的多变量灰色预测,为灰色预测模型提供了新的改进思路.在未来进一步的研究中可采用不同参数优化及模型结构改进方法相结合,针对不同应用环境选取最优的预测模型.
在研究中发现,对于文中实验案例给出的三组数据,IBSGM(1,N)模型的背景值系数取值仅取了0 和1,未作背景值系数取值的定性分析.因此,探究在更多不同实验数据下,背景值系数的取值差异及规律是未来需要继续展开的工作.
猜你喜欢
汽车工程师(2021年12期)2022-01-17
当代陕西(2020年14期)2021-01-08
初中生世界(2020年47期)2021-01-07
奥秘(创新大赛)(2020年7期)2020-07-27
小学生学习指导(低年级)(2020年3期)2020-06-02
安顺学院学报(2020年1期)2020-04-05
现代计算机(2019年6期)2019-04-08
Coco薇(2017年2期)2017-04-25
Coco薇(2017年2期)2017-04-25
为了孩子(3~7岁)(2016年8期)2016-05-14