
Intelligent fitting global real-time task scheduling strategy for high-performance multi-core systems
2022-05-28 15:17JunpengWuEnyuanZhaoSizhaoLiYanqiangWang
Junpeng Wu|Enyuan Zhao |Sizhao Li |Yanqiang Wang
College of Computer Science and Technology,Harbin Engineering University,Harbin,China
Abstract With the development of high-performance computing,it is possible to solve large-scale computing problems.However,the irregularity and access characteristics of computing problems bring challenges to the realisation and performance optimisation.Improving the performance of a single core makes it challenging to maintain Moore's law,and multicore processors emerge.A chip brings together multiple universal processor cores of equal status and has the same structure supported by an isomorphic multi-core processor.In high-performance computing,the granularity of computing tasks leads to the complexity of scheduling strategies.Satisfying high system performance,load balancing and processor fault tolerance at a minimum cost is the key to task scheduling in the highperformance field,especially in specific multi-core hardware architecture.In this study,global real-time task scheduling is implemented in a high-performance multi-core system.The system adopts the hybrid scheduling among clusters and the intelligent fitting within clusters to implement the global real-time task scheduling strategy.In the cluster scheduling policy,tasks are allowed to preempt the core with low priority,and the priority of tasks that access memory is dynamically improved,higher than that of all the tasks without memory access.An intelligent fitting method is also proposed.When the data read by the task is in the cache and the cache access ability value of the task is within a reasonable threshold,the priority of the task is promoted to the highest priority,preempting the core without the access memory task.The results show that the intelligently fitting global scheduling strategy for multi-core systems has better performance in the nuclear utilisation rate and task schedulability.
KEYWORDS genetic algorithms,intelligent systems
1|INTRODUCTION
With the expansion of application requirements and the progress of software technology,the demand for computing tasks on computing power increases sharply [1].The method of improving system performance by increasing processor frequency is limited by power consumption,cost and volume;so multi-core processors emerge as the times require[2].Multicore processor refers to the use of multiple processor cores on a chip,and each core performs the same or similar tasks,the whole chip acts as a unified structure to provide external services,output performance,to meet the needs of improving performance and achieving load balance at a minimum cost[3].The future development of high-performance computing will come from the development of multi-core processor technology [4].The system tends to be composed of multi-core,and multi-core forms a cluster hierarchically [5].Furthermore,many-core,with hundreds or thousands of cores,will provide the computing potential for petaflops of high performance/supercomputing [6].Only by making the best use of parallel multi-core architecture can the performance of multi-core be brought into full play,and the new algorithm oriented to multicore architecture will become the main direction to give full play to high performance [7].Ensuring multi-core load balancing through proper scheduling mechanism and policy,giving full play to the performance characteristics of each processor and improving the throughput of the whole system is the core of multi-core task scheduling research [8].
Due to the cache effect [9],effective use of the cache can significantly reduce access to the main memory,thereby saving memory bandwidth and reducing the interference of the main memory.The memory cache replacement algorithm has been relatively mature,such as LRU[10],LFU[11],FLRU[12]etc.At the application level,more caching applications are added to give full play to the cache effect.In multi-core systems,many optimisation methods based on cache have emerged for scheduling strategies.However,these strategies are all cache-based scheduling strategies in a specific application environment,which lacks versatility and fit [13].Therefore,this study proposes an intelligent fitting global real-time task scheduling strategy for high-performance multi-core systems.The earliest intelligent fitting of single-target intelligent fitting,the evolutionary algorithm has only one objective function.In order to solve the expansive problem in intelligent fitting,many scholars have proposed various solutions to single-target intelligent fitting.There are many shortcomings,among which a serious problem is the expansion of the expression.With the execution of the evolutionary algorithm,the complexity of the expression has become larger and larger.In order to control the complexity of the expression,the evolutionary algorithm can produce good fitting accuracy.Furthermore,for expressions with low complexity,people have proposed an intelligent fitting algorithm based on multi-objective optimization.Among them,the most mainstream method is to change the intelligent fitting from a single objective to a multi-objective fitting,that is,an intelligent fitting algorithm based on multi-objective optimisation [14].Wang et al.[15]took the size of the expression as the first target and the mean square error of the expression as the second target.They also designed a mathematical model to fit the implicit expression,which could fit both the display expression and the implicit expression at the same time and proposed a multiobjective genetic programming approach (MOGPA).Bleuler et al.[16] also took the complexity of an expression tree as another target and used the SPEA2 algorithm to solve the swelling problem of the intelligent fitting.Yang et al.[17]applied the intelligent fitting of multi-objective optimisation to fit the expression of the change of oil production per year,thus inferring the subsequent oil production.Sotto and Melo [18]redesigned the expression storage form for the multi-objective evolutionary algorithm.
However,one of the shortcomings of the traditional intelligent fitting is its slow convergence and blindness in the evolutionary process.No algorithm can change an expression into a better one;and all the types of improved algorithms mentioned above have not fundamentally improved the blindness of intelligent fitting.Therefore,this study adds traditional fitting into the intelligent fitting algorithm to improve the blindness of intelligent fitting and improve the performance of the intelligent fitting method.In the field of high-performance particle computing,its field energy and other parameters are approximately affected by its neighbouring particles.Therefore,only the coherent parameters of its own and its neighbour nodes need to be calculated.For scheduling tasks among clusters,the tasks that are related to the computation block are scheduled into a cluster set.In the process of intra-cluster scheduling,the priority of tasks is dynamically optimised according to the computing time of the tasks and the storage capacity of the tasks is calculated by the model to realise efficient task allocation.
To sum up,to solve the contradiction between the high access requirements in HPC and the weak access capability of the HPC platform,we propose an intelligent fitting global realtime task scheduling strategy.This strategy can increase cache application at the application level,give full play to the cache effect,and ensure unobstructed memory access.This study has made the following contributions:
· For the scheduling of tasks among clusters,the tasks related to computing blocks are scheduled into a cluster set to ensure the data reuse rate.It also facilitates related tasks to be performed in the same cluster.
· In the in-cluster scheduling,an improved intelligent fitting algorithm is used to build a model based on task cache access.The model can classify the tasks,ensure unobstructed access,save computation cost,and optimise the global real-time task scheduling strategy in a highperformance multi-core system.
· In the process of scheduling,based on the dynamic and preemptive nature of the system,the new task reads data from the memory or cache according to its own needs.After the new task reads the data,it is suspended,and the original suspended task continues to run to ensure unobstructed memory access.
The rest of the study is organised as follows:The second section is a brief introduction to the task model of this article.The third section is the intelligent fitting global real-time task scheduling strategy for high-performance multi-core systems,which is divided into two parts.First,it introduces the hybrid scheduling strategy between clusters and then analyses the global real-time task scheduling strategy within the cluster.In the global real-time task scheduling strategy in the cluster,in addition to the scheduling algorithm,we also propose an improved intelligent fitting algorithm to build a model to measure the task memory access ability to improve the fitting effect.Section 4 gives the experimental results and comparisons with other models.Section 5 concludes this study.
2|TASK MODEL
SelectingΓ={τ1,τ2,…,τn} from the real-time task set asNparallel tasks,and the global scheduling ofNtasks in a cluster set of multi-cluster system requires that the tasks share data in the task set.The research premise of this study is as follows:(1)There are no dependencies between tasks,which can be executed on any computing core.(2)Tasks can be preempted,and task switching and scheduling time are ignored.The task switching and scheduling time are negligible compared with the tremendous amount of computing time.(3) Tasks in the task set can share data.(4)More thanmkernels are not allowed to access the memory simultaneously in each task set.(5) Mutex synchronisation is used when parallel real-time tasks read and write shared data.For each computing task,τi Γhas the following parameters:Tirepresents the period of taskτi,Eirepresents the parallel real-time task cache access capability of taskτi,Direpresents the relative deadline of taskτi,andζrepresents the priority of taskτi.
The core has an independent instruction execution and control unit,an independent functional unit,an independent controller,and a complete instruction pipeline.The core processors can be divided into single-core multi-threaded processors,multi-core processors and multi-core multithreaded processors.The single-core multi-threaded processor is composed of single-core CPU,the multi-core processor is composed of a multi-core chip,and each core of the multicore multi-threaded processor is multi-threaded.The processor has one(L1)or two(L2)levels of caching.Compared to caches connected via a foreign bus,in-chip caches reduce processor activity on the foreign bus,resulting in reduced execution time and overall improved system performance.When the required instructions and data are cached in the chip,access to the bus is eliminated.Because the data path inside the processor is short compared to the bus length,accessing the on-chip cache is even faster than a bus cycle in a zero-wait state.Moreover,during this time,the bus is idle and can be used for other data transfers.Typically,L1 caches have two,one dedicated to instructions and one dedicated to data.Figure 1 shows the hierarchical structure characteristics of a typical multi-core cluster,in which the inter-chip communication speed within a node is slower but much faster than the inter-node communication speed,and the access locality and synchronisation of the memory hierarchy need to be considered in the node.
All available cores in the system are grouped.Multiple cores share the cache as a cluster,and a local scheduling queue is established in each cluster.The task poolp(τ),that is ready to be executed is maintained.There is no dependency between the tasks in the task pool and they can run on any kernel.When a task is in the execution phase,the kernel is occupied by this task and cannot do other calculations.Besides,each task must be executed continuously and cannot be run in parallel on multiple cores.The cluster consists of a multi-core chipCi(1:(i:(c)))withcidentical cores,C={C1,C2,…,Cc},there aremstoresMj(1:(j:(m))),M={M1,M2,…,Mm}.The main memory is a globally shared resource that can be accessed by any kernel.However,if all the kernels are allowed to access the memory at the same time,conflicts will cause all the tasks to slow down access to the main memory.To prevent primary memory access conflicts,the number of kernels that can access the primary memory concurrently without conflict is limited tom.As long asmor fewer kernels access the memory at the same time,the memory bandwidth is not saturated.With a preemptive schedule,a task can be preempted at any time,and its execution can be resumed later.
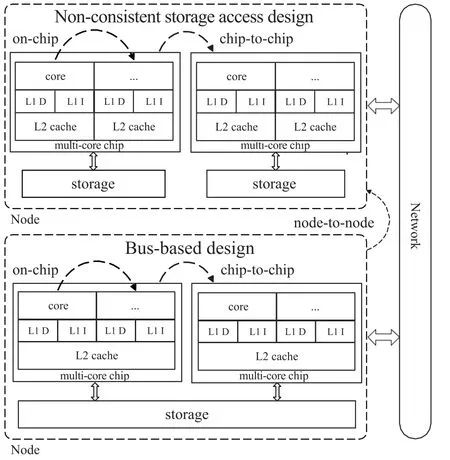
FIGURE 1 The hierarchical structure of a typical multi-core cluster
3|SCHEDULING STRATEGY
In this system,mixed scheduling among clusters and intelligent fitting of the global real-time task scheduling strategy within clusters are adopted.In order to reduce the data communication overhead,the core of the shared cache is grouped as a cluster.Then,the scheduling of global real-time tasks,which are intelligently fitted within the cluster set,can reasonably change its priority according to the cache access ability of the task to improve the computing efficiency of the highperformance multi-core system.
3.1|Hybrid scheduling between clusters
Different from traditional global scheduling and local scheduling,the inter-cluster hybrid scheduling strategy divides all available cores in the system intoZgroups.Each group of cores sharing the cache is treated as a cluster set,and a local scheduling queue is established within each cluster set.The hybrid scheduling strategy involves independent scheduling among clusters,similar to the local scheduling strategy,in which tasks are first statically assigned to each processor cluster set,and then each cluster set schedules its ready tasks in the local queue.The unified scheduling of all cores in the cluster is similar to the global scheduling policy.The scheduling scheme of the hybrid scheduling algorithm based on the cluster set is shown in Figure 2.
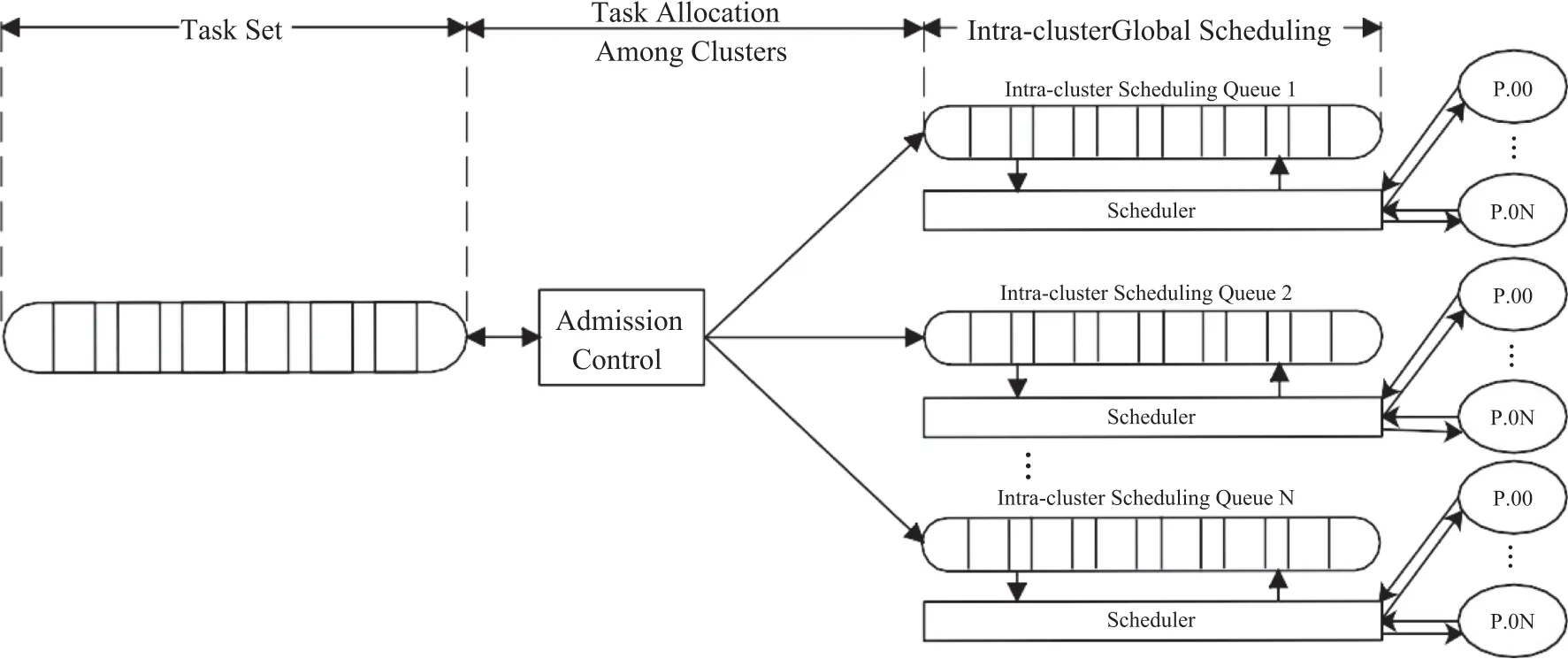
FIGURE 2 Diagram of a typical multi-core cluster structure
Compared with the local scheduling algorithm,each cluster in the hybrid scheduling algorithm contains two or more processor cores.When the task allocation algorithm allocates tasks with high utilisation to a processor core,this processor core will process the current task,and the other cores will be idle.The remaining processing power can be combined with the remaining processing power of other processor cores in the same cluster.Therefore,the processing power of the processor cores in the hybrid scheduling algorithm can be more fully utilised.Compared with the global scheduling strategy,in the system adopting the hybrid scheduling strategy,there is a scheduling queue in each cluster.When the system scale is large,the increase in the number of tasks will not cause the scheduling overhead to increase sharply.On the other hand,the clustered hybrid scheduling strategy only allows tasks to migrate within clusters but not between clusters,and so the system overhead caused by task migration is reduced to a certain extent.When using hybrid scheduling,multiple cores sharing the cache in the system are used as a cluster,and datadependent tasks can be allocated to the same cluster to reduce cache failure.In this system,users statically allocate tasks to each cluster before the scheduler runs and then perform global scheduling within the cluster.
3.2|Determination of access capacity under global scheduling
The global scheduling strategy in the cluster is divided into two levels of scheduling.The first level schedules ready realtime tasks in the task pool to the processor core,and the second level schedules parallel real-time tasks to the processor core.Parallel real-time shared data tasks are assigned a priority based on rate monotonic,that is,tasks with a shorter period are given higher system priority.The cluster tasks are relatively independent,and the RM algorithm can generate a pre-priority sequence based on the task cycle,which can ensure the efficient reduction of the number of remaining tasks.The purpose of using the RM algorithm is to get the priority sequence of the tasks in the cluster again under the memory access capability model,which we intelligently fit.The RM algorithm is used as the preposition,which ensures the relative speed of processing tasks and ensures unobstructed memory access behaviour.It allows tasks to preempt cores running on low-priority tasks.In order to prevent the task running speed from slowing down due to interference caused by access to the memory,tasks running on a maximum ofmcores are allowed to access the memory simultaneously.If there are more thanmtasks ready to access the memory,the lower priority task is blocked.The priority of the tasks that access memory is dynamically increased,higher than all tasks that do not access memory.When the data read by a task is in the cache,and the task cache access capability value of the task is within a reasonable threshold,the priority of the task is raised to the highest priority,and the task is immediately scheduled to preempt the task that does not access the memory core.Since the data is already in the cache,these tasks do not need to be read from the memory but read from the cache.Since all the tasks in the memory-read phase have higher priority than the tasks in the execution phase,if the number of tasks in the main memory-read phase is less thanm,the tasks in the memory-read phase immediately preempt the cores of the tasks in the execution phase.After accessing the memory,the priority of these tasks is restored to the original priority,and these tasks are in a suspended state and continue to run preempted tasks.Since the scheduled task has completed the memory-read phase,as long as the kernel is idle,the task can be executed immediately.Therefore,the global scheduling strategy within the cluster improves memory utilisation,core utilisation,and task response time.
In the first-level cluster scheduling process,for the task's cache data reading and writing,this study uses an event counter-performance monitor unit (PMU) integrated into the multi-core system to collect and analyse the task's cache access behaviour.Three events related to task cache access characteristics recorded by PMU are L2 cache access number,L2 cache miss number,and memory read and write instructions.The literature[19]believes that all the above three events have a particular linear relationship with the shared cache competitiveness of the process,but they all have specific errors.Taking the degree of process performance degradation as the objective function,the above three main events are used to establish a fitting model for task cache access abilityE,and the above three indicators can be linearly fitted.Finally,a fitting formula for task cache competition access abilityEis established as follows:
In the above formula,molecules represent the number of memory instructions loaded and written,and OPIP reflects the frequency at which the cache interacts with the memory.The above formula can calculate theEvalue[20].According to the calculated result ofE,the cache access competitiveness of tasks can be classified:tasks withEvalue below 0.2 have weaker cache access competitiveness and tasks withEvalue above 0.2 have more substantial cache access competitiveness.This policy can quickly determine the task cache access abilityEof tasks in the task pool,but in the mixed scheduling among clusters,the three events CMR,CRR and OPIP of each cluster set are dynamically changing.The above method cannot dynamically fit the cache contention access abilityE.Therefore,this study proposes an intelligent global real-time task scheduling strategy,which can dynamically obtain the cache contention access abilityEof tasks within the cluster set.Differentiated scheduling of tasks with different cache access competitiveness can improve the performance of the tasks.Using this memory access decision model,combined with the following inter-cluster scheduling,a task priority sequence based on memory access capability can be obtained.
3.3|Intelligently fitting global real-time task scheduling strategy
Intelligent fitting is a genetic algorithm that evolves expressions based on the data to be fitted [21].Genetic algorithm(GA) is a method used to search for the optimal solution by simulating Darwin's natural evolution process.GA starts from a population,and a population is composed of a certain number of genetically encoded individuals.These individuals may be randomly generated,or maybe a population initialised according to specific problems.The difference between individuals is reflected by the different ways in which genes are composed.Each different individual has its fitness for the problem model to be solved.The better the fitness of the individual,the closer the problem to be solved.The fitness of the individual obtained is as good as possible.Through generation-by-generation evolution,individuals with better fitness are produced.In each generation,individuals are selected according to the fitness of the individuals in the problem domain,and these individuals are cross-mutated.Operate to generate new individuals,and finally generate progeny populations.The progeny populations perform fitness solving and evolution operations again until the termination conditions of GA are reached.When the final algebra is reached,the individual with the best fitness in the population is the optimal solution to the problem.
GA is widely used in artificial intelligence,data mining,function optimisation,production scheduling and other fields.Intelligent fitting is a genetic algorithm that evolves expressions by minimising errors [22].Individuals in a population are expressions,and genes are the operators that make up the expression,including operators,random numbers,and independent variables.The algorithm follows the characteristics of each operator to form a significant expression.The intelligent fitting method is universal and easy to understand,which can solve the swelling problem of intelligent fitting of a single object.However,for other intelligent fitting problems,such as blindness,diversity and overfitting,it still cannot be improved.
Therefore,an improved intelligent fitting algorithm is proposed to improve the performance of intelligent fitting by adding traditional fitting expressions into intelligently fitting populations.The process of the improved intelligent fitting method is shown in Figure 3.
As can be seen from the above figure,most of the improved intelligent fitting algorithms are based on intelligent fitting.The difference is that the traditional fitting is added to guide the evolution of the population in the initial stage and the evolution stage.The blindness of intelligent fitting is caused by the genetic algorithm used in intelligent fitting.The crossover,mutation and other operators in the genetic algorithm change individuals randomly,and there is no way to guarantee that these operators will produce good accuracy.Sometimes,these operators even produces a worse precision expression,so when the data to be fitted by the intelligent fitting is more complicated,the intelligent fitting may converge slowly.The fitting process takes much time,and sometimes does not converge the phenomenon.In order to guide the evolution direction of intelligent fitting in the evolution process of intelligent fitting,this study improves the performance of intelligent fitting by adding traditional fitting expressions to the population of intelligent fitting.The improved intelligent fitting algorithm (intelligent fitting based on traditional linear fitting algorithm) is as follows:

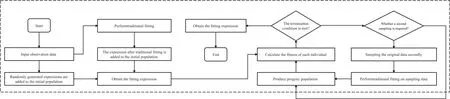
FIGURE 3 Improved flow chart of the intelligent fitting algorithm

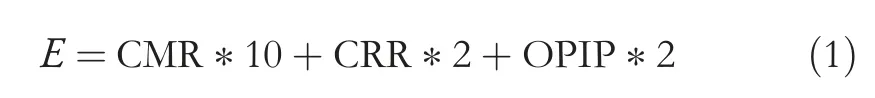
Among them,CMR represents the L2 cache miss rate,and the calculation formula is:

In Formula (2),L2 cache misses represents the number of misses accessing the L2 cache,and instructions represents the total number of instructions executed.CRR represents the L2 cache access rate,and the calculation formula is

In Formula(3),L2 cache references represents the number of times the process has accessed the shared L2 cache,and instructions represents the total number of instructions executed.OPIP represents the ratio of memory to read and write instructions.The calculation formula is
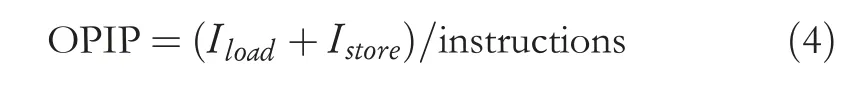
In order to make the population of intelligent fitting individuals at a higher level in the initial stage,this study divides the initial population of intelligent fitting into two parts,one is a randomly generated expression,and the other is obtained by traditional fitting on the original data expression.The process of random initialisation is to randomly select an operator from the operator,create the operator,use recursion,create the suboperator of the operator,and cut off when the created expression is a valid expression.In the algorithm,first,initialise the parameters,perform traditional linear fitting on the original data,and add the linear fitting expression to the initial population.In this study,the expression obtained by linear fitting is added to the initial population,and linear fitting is used to perform traditional fitting of the expression.In the process of population evolution,traditional fitting expressions are added.Then,progeny populations are generated,and traditional fitting is added to the progeny populations.If the conditions for adding traditional fitting expressions are met,the original data will be uniformly sampled.The sampled data will be traditionally fitted to obtain a series of expressions;the original data is uniformly sampled,the sampled data is traditionally fitted to obtain a series of expressions,and these two expressions are added to the progeny population.When the offspring population is dissatisfied,some expressions are generated by the generation algorithm and added to the offspring population.When the termination condition is met,the algorithm stops getting the fitting expressionEnabout the calculation cluster.
We substitute the relevant parameters of each task in the cluster intoEnto obtain theEvalue of the characteristic function.In order to classify the processes scientifically,it is necessary to determine the approximate range ofEcorresponding to processes whose cache competitiveness is strong or weak.Through the experiment of the program of the test assembly,this article tests the cache miss rate,access rate and other indicators of each process when it is running,then calculates the characteristic function value of each process,and divides the top 55%of the processes into cache competitiveness.For ‘strong’ processes,the last 45%of the processes are classified as processes with‘weak’cache competitiveness.Keeping the ratio of the two the same,this division helps the scheduler to select a suitable combination of processes.In order to simplify the calculation and improve the operating efficiency of the kernel,the process is divided into tasks with weak cache competitiveness and theEvalue is quantified to the threshold boundary,thereby distinguishing the strength of the task cache competitiveness in the cluster.Combined with the RM strategy,this algorithm can provide an effective means for subsequenttask priority selection.
Scheduling tasks with different cache access competitiveness can improve the performance of the tasks.In this system,the priority of tasks with weak cache access competitiveness can be improved,which can not only ensure the use of cache speed to save time but also reduce the number of cache invalidation caused by the task cache access competitiveness,which is too high,to get the maximum performance of the task operation efficiency.First-order scheduling algorithm is an intelligent scheduling algorithm for ready real-time task scheduling.The input parameters are parallel real-time tasksΓ={τ1,τ2,…,τn},parallel real-time task priority task collectionζ=d{(τ1),d(τ2),…,d(τn)},collection of parallel real-time task cache access capabilitiesE={e(τ1),e(τ2),…,e(τn)},processor coreC={c1,c2,…,cn},memoryM={m1,m2,…,mm} and task poolp(τ).The scheduling algorithm ISRT is described as follows:

When more than one task is available,the shortest task cycle is serviced first,and the high-priority task is dispatched to the processor core.If memory bandwidth is available,the task that accesses memory is dynamically prioritised over all the tasks that do not access the memory.When the data read by the task is in the cache,and its cache-access competitiveness is intelligently fitted within the reasonable threshold,the priority of the task is promoted to the highest priority,and the task is immediately scheduled to preempt the core that does not have access to the memory task.In the process of cluster scheduling,parallel real-time tasks are scheduled on the processor core.The algorithm can dispatch the ready real-time tasks from the task pool to the processor core,and the priority sequence of the tasks in the computation core can be re-obtained by using the RM algorithm and the intelligently fitted memoryaccess capability model proposed.Since the scheduled task has completed the read memory phase,as long as the kernel is idle,it is immediately ready to run the execution task.The parallel real-time task scheduling algorithm based on processor core is described as follows:
Algorithm 3 schedule is based on the dynamic and preemptive nature of the system,and when a new task arrives,if the running task does not have access to the memory,the running task is immediately suspended,ceding the kernel to the new task.The new task reads the data from the storage or cache according to its requirements.After reading the data,the new task is suspended,and the previously suspended task continues to run.When a task has finished running,if the task is the priority running task of another task,it is removed from the priority running task set of other tasks.The above multi-core system intelligent fitting global real-time task scheduling strategy,in which the hybrid scheduling between clusters centres on memory and cache,divides the computing core of the shared memory into a cluster set and gives full play to the performance advantage of the cache.Algorithms 2 and 3 are two-level scheduling,corresponding to inter-core scheduling and up-core scheduling,respectively.Algorithm 1 provides a filtering model for the subsequent algorithms.The cluster of the intelligent fitting realtime task scheduling strategy shapes a model that can judge the cache access ability of parallel real-time tasks and can be used to classify tasks differently.The task is further partitioned based on whether the data is read from the memory to achieve better parallelism.The intelligent fitting global real-time task scheduling strategy fits a polynomial of parallel real-time task cache access capability in the budget stage of high-performance computing,and the computational complexity isO(logn).The first-level scheduling algorithm(intelligent scheduling algorithm for ready real-time task scheduling) and the second-level scheduling algorithm (parallel real-time task scheduling algorithm based on processorcore)are complicated in the scheduling decision process of task pool scheduling and real-time task scheduling.The degree isO(n).The complexityof the process of updatingthe task pool and changing the task priority isO(n).The computational complexity of priority ranking in first-level scheduling isO(nlogn).In summary,the computational complexity of the entire scheduling strategy isO(nlogn).

4|EXPERIMENTS
According to the scheduling strategy proposed in Section 3,we design related experiments of hybrid scheduling between clusters and intelligently fitting global real-time task scheduling strategy.First,a performance test of the inter-cluster hybrid scheduling is carried out.Compared with global scheduling,it is proved that the schedulable upper limit performance of the hybrid scheduling of the system is improved.Second,it designs a performance test on improving the intelligent fitting global real-time task scheduling strategy and compares it with the global earliest deadline first (GEDF) scheduling strategy and the traditional intelligent pseudo-scheduling strategy.
4.1|Experiment settings
The test platform in this article includes multiple core groups of the SW26010 processor.Many-core SW26010 CPU includes four core groups (CGs) [23],each of which includes one management processing element (MPE),one computing processing element (CPE) cluster with eight by eight CPEs,and one memory controller(MC).With 260 processing elements in one CPU,a single SW26010 provides a peak performance of over three TFlops [24].Both MPE and CPE are full 64-bit RISC cores but play different roles in computing.MPE supports full interrupt functionality,memory management,processing management,task planning and data communication and can run in the system mode and user mode.Each MPE has a 32 KB L1 cache and a 256 KB L2 cache for instructions and data in terms of the storage hierarchy.
4.2|Inter-cluster scheduling performance test
The performance test simulates the running time of a multi-core system in a variety of clustering situations.In consideration of the scalability of system validation,we control the number of calculated cores.During the experiment,the number of tasks in the task pool was kept constant,and the number of computing cores and the number of computing clusters were changed.This setting can effectively show the effect of scheduling policy allocation among clusters and check the operation effect of tasks within the cluster.Considering the computing performance of the clustering strategy,the experiment controls the number of clusters.In other words,the computing performanceof different core numbers under different clustering conditions is considered.Thirty-thousand real-time tasks were randomly generated in the task pool,and the test results are shown in Figure 4.
In Figure 4,Noc represents the number of clusters under different clustering strategies.It can be seen from the figure that increasing the number of calculation cores can effectively reduce the calculation time.Nevertheless,as the number of cores increases,so does the efficiency of computing.The cluster mixed scheduling strategy is used to divide the cores of the shared data cache into a cluster set,which is scheduled independently among the clusters,and the global scheduling within the cluster is realised by setting an available ready queue within the cluster.With the increase of clustering,the computing efficiency is improved,and the computing time is reduced.In terms of the scheduling mode,this system adopts the distributed scheduling mode,and all processors run the scheduler peer to peer,and the problems of communication and synchronisation in the distributed scheduling mode are solved.The cluster scheduling strategy can increase computational efficiency and shorten computation time and has good scalability in a multi-core system.
4.3|Improved intelligent fitting scheduling strategy

FIGURE 4 Multi-core system clustering performance test results
The intelligent fitting global real-time task scheduling strategy first increases the priority of tasks that access the main memory and increases their priority above all tasks that do not access the main memory so that these tasks have priority access to the main memory.Then,the cache access capability of the task is determined by the improved intelligent fitting algorithm.When the data read by a task is in the cache,and the cache access capability value of the task is within a reasonable threshold,the priority of the task is immediately increased above all other tasks so that these tasks do not need to read the data from the main memory,and it is read from the cache.When these tasks have read the required data,when the core is idle,these tasks are immediately scheduled to run,which improves task parallelism and core utilisation.The performance of the intelligent fitting global realtime task scheduling strategy is verified through experiments,and the task schedulability rate of the GEDF scheduling strategy and the traditional intelligent pseudo-scheduling strategy is compared and analysed in different memory banks.(The schedulable task rate is the sum of the completion rate of each task,i.e.,the number of completed tasks divided by the total number of tasks.) Finally,two parallel scales of 32 computing cores and 64 computing cores are used to fit traditional intelligence and improve intelligent fitting compared with the acceleration performance of the GEDF parallel program,and the parallel program is tested and analysed.
The experimental parameters set the number of corescof the multi-core processor to 1-80,the number of memory banksmto 2-8,and the number of task setswto 9000.Realtime tasks are randomly generated,and each task is assigned a priority according to RM,that is,tasks with a shorter period are given a higher system priority.For comparative analysis,the global EDF scheduling strategy [25] and the traditional intelligent fitting global real-time task scheduling strategy are selected and compared with the improved intelligent fitting global real-time task scheduling strategy proposed in this study.The experimental results are shown in Figure 5.
The relationship between the kernel number and task schedulability rate of the improved intelligent fitting,GEDF and traditional intelligent fitting scheduling strategy is shown in Figure 5.In Figure 5a,when the number of storage bodies is 2,improved intelligent fitting and traditional intelligent fitting have higher task schedulability than GEDF.Since the improved intelligent fitting scheduling policy takes into account the influence of cache and improves the utilisation of the memory and core,the task schedulability rate of the improved intelligent fitting scheduling policy is higher than that of the GEDF scheduling policy.When the number of storage bodies is 4,the relationship between the kernel number and task schedulability rate of the improved intelligent fitting,GEDF and traditional intelligent fitting scheduling strategy is as shown in Figure 5b.It can be seen from Figure 5b that increasing the number of storage bodies improves the task scheduling rate of intelligent fitting,GEDF,and traditional intelligent fitting.In Figure 5c and d,with the increase in the number of storage bodies,the task scheduling rate of the intelligent fitting is improved more obviously,which reflects good scalability.In a real-time system,memory bandwidth has a significant influence.The improved intelligent fitting scheduling strategy takes the memory bandwidth into account and prevents the memory interference caused by the kernel's competing access to the memory.The improved intelligent fitting scheduling strategy allows tasks to preempt the running core of low-priority tasks and dynamically increases the priority of tasks to access the memory above all tasks that do not access the memory.Simulation results show that the global real-time task scheduling strategy can improve task parallelism and schedulability.
In this experiment,three sets of different scales were constructed,the total number of which were 32,64 and 128,respectively.The CPU utilisation of the above three algorithms are compared on different job sets.The node utilisation under different scheduling policies is shown in Table 1.
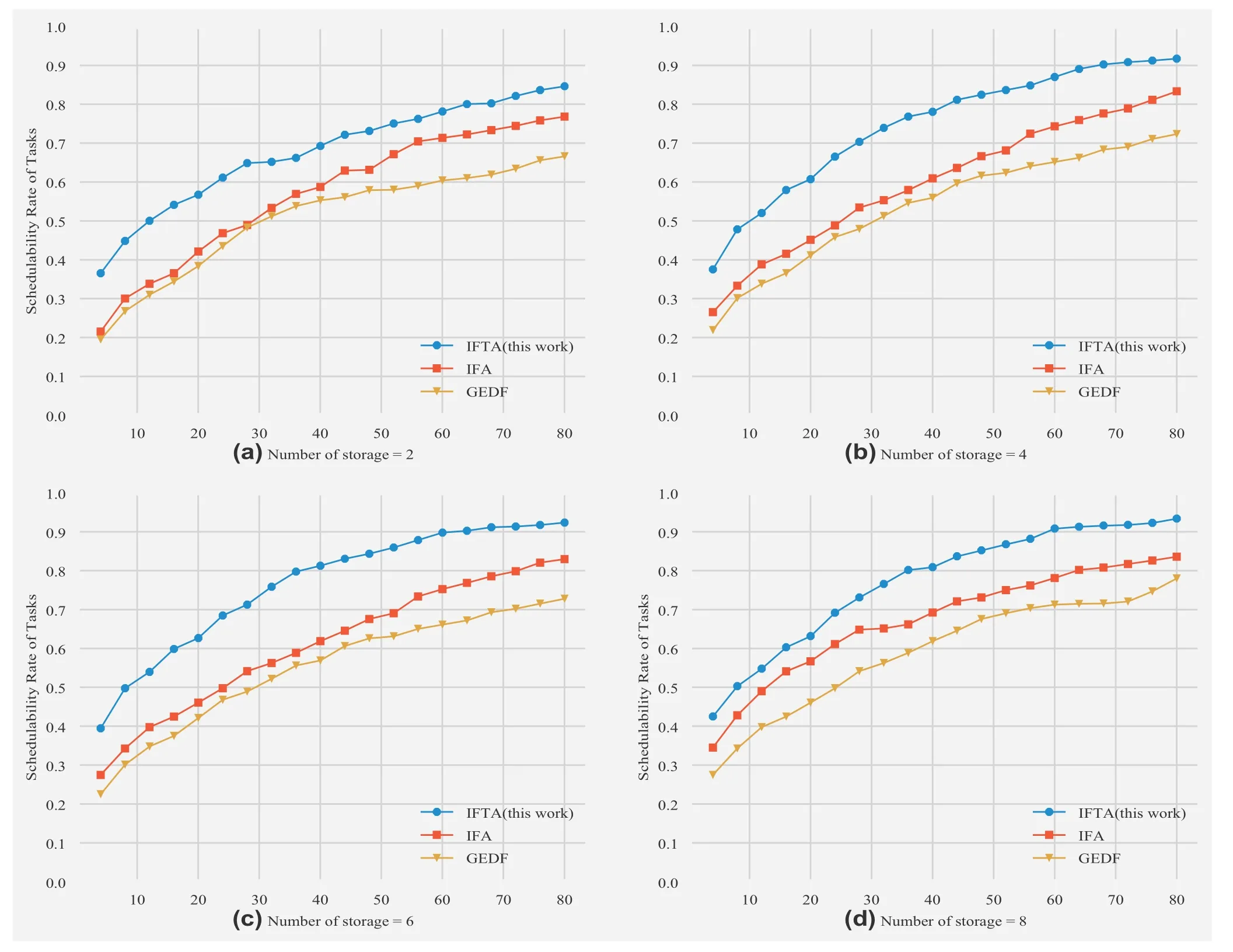
FIGURE 5 Task schedulable rate experiment of GEDF+IFA and IFTA algorithm
As shown in Table 1,the worst value and average value of the CPU utilisation of the IFTA algorithm are optimal under different job scales,which reflects the rationality and superiority of the IFTA algorithm compared to other algorithms in the job scheduling process.Compared with the IFA algorithm,the IFTA algorithm adds traditional fitting factors in the initial and evolutionary process to improve the fitting accuracy.The worst value and average value of the CPU utilisation of the IFA algorithm are higher than the GEDF algorithm,which reflects the superiority of priority scheduling in the scheduling strategy.When the data read by a task is in the cache,the priority of the task is raised to the highest priority,and the task is scheduled immediately,preempting the cores that do not access the memory task,preventing memory interference and improving the utilisation of processor cores.
Finally,based on the above three parallel strategies,using two parallel scales of 32 computing cores and 64 computing cores,the acceleration performance of traditional intelligent fitting and improved intelligent fitting parallel programs compared with GEDF parallel programs is tested and analysed.Compared with the acceleration performance of GEDF,the intelligent fitting parallel program has been tested initially,as shown in Figure 6.
In Figure 6,during the test of the 32 processes,the overall acceleration of the traditional intelligent quasi-merged line program was 1.61 times that of the original GEDF parallel program,and the overall acceleration of the improved intelligentquasi-merged line program was compared with that of the original GEDF parallel program 2.55 times.With the increase in the number of processes,the parallel advantages of traditional intelligent fitting and optimised intelligent fitting are more significant.Among them,compared with the original GEDF parallel program,the overall acceleration of the traditional intelligent quasi-merged line program is 1.991 times,and the overallacceleration of the improved intelligentquasi-merged line program is compared with the original GEDF parallel program 3.25 times.
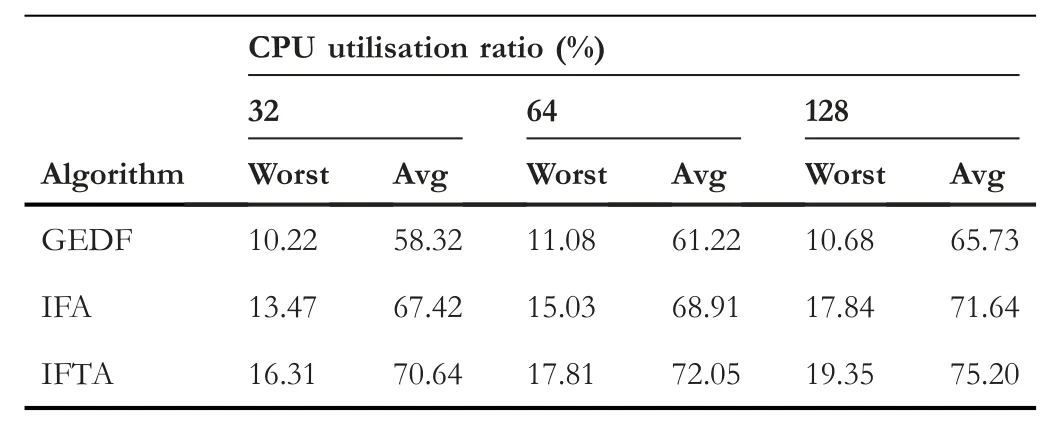
TABLE 1 The CPU utilisation under different scale of operation
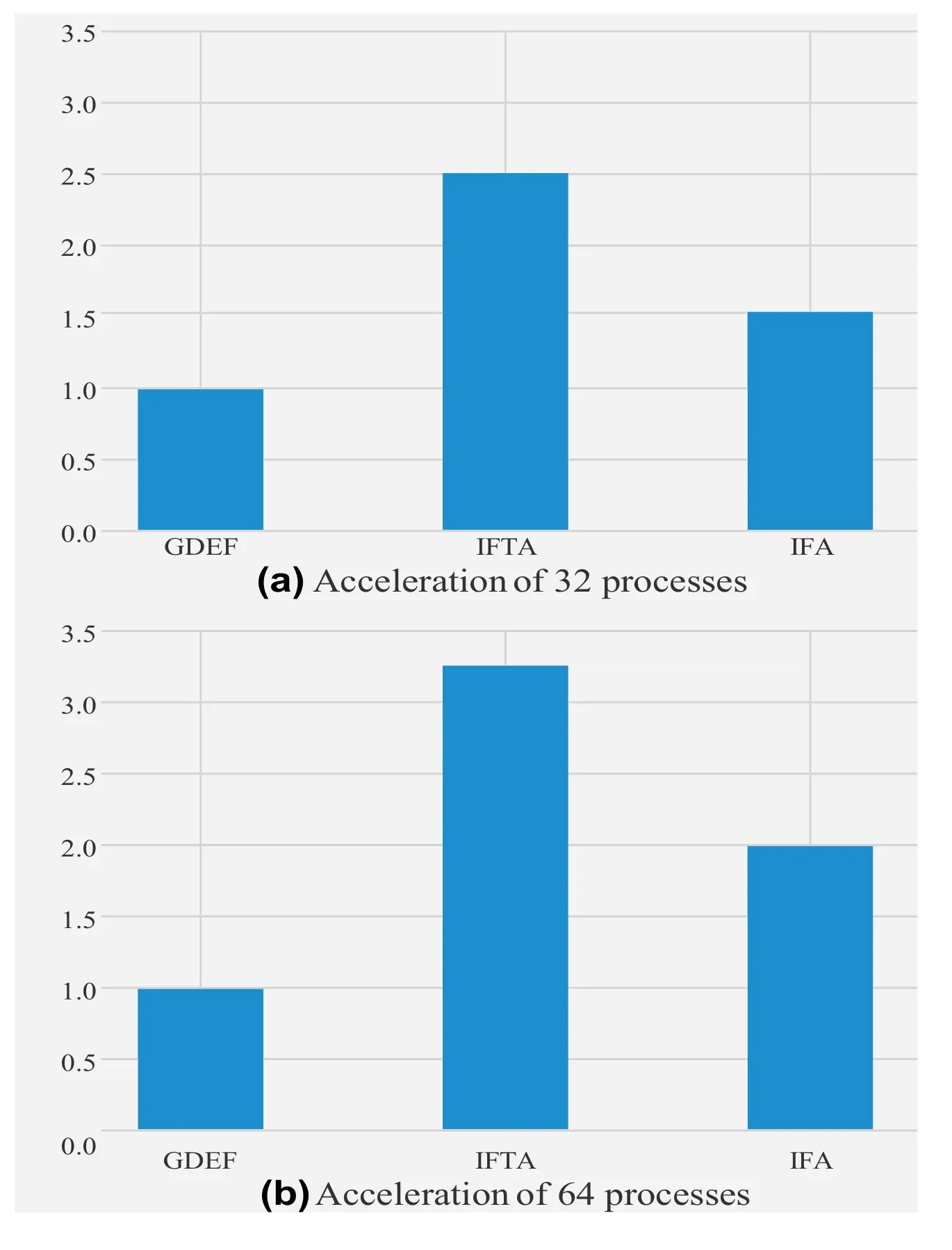
FIGURE 6 The speedup of different kernels experiment of GEDF+IFA and IFTA algorithm
5|CONCLUSIONS
In this study,we propose an intelligent global real-time task scheduling strategy for high-performance multi-core systems.Based on the cache effect,a hybrid scheduling strategy between clusters is proposed.Based on the traditional intelligent fitting,an improved intelligent fitting algorithm is proposed to build the fitting model.Then,we carry out relevant experiments on the proposed strategy.First,the performance test of mixed scheduling among clusters is carried out,which mainly tests the influence of different clustering strategies and the number of calculated cores on the performance.Then,the performance test of the improved intelligent fitting global realtime task scheduling strategy is carried out and compared with the global earliest cut-off priority (GEDF) scheduling strategy and the traditional intelligent scheduling strategy.The task schedulability rate of various policies and CPU utilisation of batch jobs under different scheduling algorithms are compared.Finally,two parallel scales,32 and 64 cores are used to test and analyse the acceleration performance of the conventional and improved intelligent fitting parallel program compared with the GEDF parallel program.The experimental design covers the whole task scheduling strategy,which not only demonstrates the high performance of the hybrid clustering scheduling strategy compared with the traditional scheduling strategy but also proves that the improved intelligent fitting algorithm has better performance,schedulability and expansibility compared with the traditional fitting algorithm.The intelligent scheduling strategy for high-performance multi-core systems proposed in this study can better deal with global real-time task fitting.It is worth mentioning that this scheduling strategy can effectively reduce the number of access times and is suitable for the computing platform SW26010 with substantial computing power and weak access capacity.This algorithm is suitable for the task environment where the number of computation tasks is small,but the computational power is considerable.In the mainstream computing platform,or in the environment of many computing tasks,the performance of intelligent fitting global real-time task scheduling in the high-performance multi-core system is not good.
ACKNOWLEDGEMENTS
This research is funded by the National Natural Science Foundation of Heilongjiang Province of China (Outstanding Youth Foundation) under Grant No.JJ2019YX0922 and the Basic Scientific Research Program of China under Grant No.JCKY2020208B045.
DATA AVAILABILITY STATEMENT
None.
ORCID
Enyuan Zhaohttps://orcid.org/0000-0002-2909-4317
Sizhao Lihttps://orcid.org/0000-0002-6557-262X
 CAAI Transactions on Intelligence Technology2022年2期
CAAI Transactions on Intelligence Technology2022年2期
- CAAI Transactions on Intelligence Technology的其它文章
- A comprehensive review on deep learning approaches in wind forecasting applications
- Bayesian estimation‐based sentiment word embedding model for sentiment analysis
- Multi‐gradient‐direction based deep learning model for arecanut disease identification
- Target‐driven visual navigation in indoor scenes using reinforcement learning and imitation learning
- A novel algorithm for distance measurement using stereo camera
- Learning discriminative representation with global and fine‐grained features for cross‐view gait recognition