
孪生Bi-LSTM模型在语音欺骗检测中的研究
2022-05-27 01:05甘海林雷震春杨印根
小型微型计算机系统 2022年6期
甘海林,雷震春,杨印根
(江西师范大学 计算机信息工程学院,南昌 330022)
1 引 言
随着自动说话人确认(Automatic Speaker Verification,ASV)的用户验证身份的场景实例范围和频率的不断增加,针对ASV系统的语音欺骗攻击也更加频繁.ASV系统本身的安全性对金融交易、公共服务、刑事司法等领域至关重要,而重放[1,2]、语音合成和语音转换等语音欺骗攻击已经对ASV系统构成了威胁[3-6],设计有效的反欺骗对策来确保ASV系统安全可靠,意义重大.
在语音欺骗检测模型中,经典的高斯混合模型(Gaussian Mixture Model,GMM)是多个高斯分布函数的线性组合,理论上可以拟合任意类型的分布,通常被用作基线系统[7,8].Hanilçi等人[9]在ASVspoof 2015数据集上对GMM模型+通用背景模型、GMM模型+支持向量机和GMM模型+最大似然等5种分类器进行比较,使用最大似然(Maximum Likelihood,ML)准则训练的GMM模型获得的结果最好,其在评估集上的等错误率为3.01%.在基于GMM模型的语音欺骗检测过程中,通常在真实语音数据集和欺骗语音数据集上分别训练得到两个GMM,对一条新的语音,计算它在这两个GMM上的得分,并将其差作为最后评判得分.计算语音在GMM上得分的过程中,GMM通过加权方式累加语音特征帧在各个高斯分量上的概率密度值,而忽略了这些概率密度值的具体分布情况.由于真实语音和欺骗语音在特征空间中的分布不一样,使得这两类语音特征在GMM的各个高斯分量上的得分分布也不一样,这种得分分布信息可用来区分语音是真实语音还是欺骗语音.本文根据语音特征帧在GMM的各个高斯分量上的得分,提出高斯概率特征(Gaussian probability features,GPF),并将其用于语音欺骗检测.
随着深度学习技术的发展,神经网络模型用于语音欺骗检测变得越来越普遍,许多研究者利用神经网络模型获得比GMM更好的欺骗检测性能.Marcin等人[10]使用具有极大特征映射激活函数来简化轻卷积神经网络(Light Convolutional Neural Networks,LCNN),在ASVspoof 2017挑战中获得了最佳性能.Tian 等人[11]提出使用时序卷积神经网络(Temporal convolutional network,TCN)模型来检测语音转换和语音合成等语音欺骗攻击,最终在ASVspoof 2015语料库上取得了显著的效果.Zhang 等人[12]研究了ASVspoof 2015数据集中用于语音转换和语音合成欺骗检测的深度学习框架,还提出了卷积神经网络(Convolutional Neural Networks,CNN)+循环神经网络(Recurrent Neural Network,RNN)模型.黎荣晋提出了多特征整合网络结构和多任务学习机制[13],在ASVspoof 2017和ASVspoof 2019评测集上验证了多特征多任务学习机制的有效性.
在传统GMM模型中,其独立地累计所有帧的分数,而忽略相邻帧之间的前后关系.在语音欺骗检测中语音帧的前后都存在关联,捕捉语音帧之间的前后依赖关系,有助于提高语音欺骗检测效果.Graves等人[14]首次将双向训练应用于长短期记忆(Long Short-Term Memory,LSTM)网络,并在TIMIT语音数据库上分别测试LSTM和RNN的双向和单向变体的语音帧分类能力,结果证明双向网络优于单向网络.故本文采用双向长短期记忆(Bidirectional Long Short-Term Memory,Bi-LSTM)网络作为语音欺骗检测的模型.
随着语音欺骗技术的发展,欺骗语音和真实语音越来越相似,这使得欺骗语音检测变得愈发困难.Chopra等人[15]提出了一种基于数据的相似性度量训练方法,该方法采用孪生网络结构,适用于训练过程中类别数目非常大且未知的情况.在2018年Kaggle座头鲸识别挑战比赛中,Martin Piotte利用孪生网络取得第1名的成绩,其结果比第2名精度高14个百分点,这体现了孪生网络在计算相似度场景下的巨大优势.在欺骗语音和真实语音高度相似的情况下,采用孪生网络能有效地提高欺骗检测的效果.因此本文在构建高斯概率特征的基础上,结合双向长短期记忆(Bidirectional Long Short-Term Memory,Bi-LSTM)网络和孪生结构,提出孪生双向长短期记忆网络(Siamese Bidirectional Long Short-Term Memory,SBi-LSTM)模型来进行语音欺骗检测研究.
本文在ASVspoof 2019数据集上测试了SBi-LSTM模型的性能,还与Bi-LSTM和ASVspoof 2019挑战赛官方提供的基准模型(GMM模型)等当前主流的语音欺骗检测模型进行了实验对比.为了进一步提高语音欺骗检测的性能,本文还对SBi-LSTM模型和GMM模型进行了得分融合.此外本文还对LFCC和GPF进行了实验对比,来验证GPF对于提高模型语音欺骗检测性能的有效性.实验结果表明,本文提出的SBi-LSTM模型较GMM和Bi-LSTM等主流模型,具有更好的语音欺骗检测能力,并且经过得分融合后语音欺骗检测性能得到了提高.此外模型采用GPF的性能要优于采用LFCC的性能,这证明了GPF有效提高了语音欺骗检测能力.
2 相关理论
2.1 高斯混合模型
GMM是一种广泛使用的聚类模型,能够有效捕捉语音特征的分布,在语音欺骗检测中通常用作基线系统.对于特征向量x∈D,GMM的概率密度函数的表示形式如公式(1)所示:
(1)
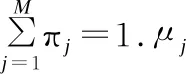
(2)
GMM进行语音欺骗检测时,首先对语音进行特征提取,然后在真实语音和欺骗语音的数据集上分别训练得到两个GMM:λb是真实语音数据集训练得到的GMM,λs是欺骗语音数据集训练得到的GMM.对一条新的测试语音x,累加所有特征帧在GMM上的得分并求平均,将两个得分值的差作为最终的判决得分,如公式(3)所示:
scoreGMM(x)=logp(x|λb)-logp(x|λs)
(3)
scoreGMM(x)是用于判决语音x的对数似然比分数.p(x|λb)和p(x|λs)分别表示语音x在真实语音和欺骗语音对应的GMM模型下的似然函数输出.
2.2 LSTM模型
2.2.1 LSTM模型介绍
长短期记忆(Long Short-Term Memory,LSTM)模型是一种特殊的RNN模型,由多个共享权值的LSTM区块连接而成,具有长期记忆的能力,能够处理长距离依赖问题.LSTM输入输出以及内部状态更新受遗忘门,输入门和输出门协同控制.假定在t时刻LSTM神经网络的输入序列xt∈M,隐藏层状态ht∈D.LSTM网络对xt按照公式(4)-公式(9)进行处理.
ft=σ(Wfxt+Ufht-1+bf)
(4)
it=σ(Wixt+Uiht-1+bi)
(5)
(6)
(7)
ot=σ(Woxt+Uoht-1+bo)
(8)
ht=ot⊙tanh(ct)
(9)
其中W∈D×M为状态-输入权重矩阵,U∈D×D为状态-状态权重矩阵,b∈D为偏置向量.tanh(·)为Tanh函数,其输出区间为(-1,1),σ(·)为Logistic函数,其输出区间为(0,1).ft∈[0,1]D、it∈[0,1]D和ot∈[0,1]D分别为遗忘门、输入门和输出门.⊙为向量元素乘积,ht-1为上一时刻的外部状态,ct-1为上一时刻的记忆单元;是通过非线性函数得到的候选状态.在每个时刻t,LSTM网络的内部状态ct记录了截止到当前时刻的历史信息.
2.2.2 LSTM语音欺骗检测
基于LSTM的语音欺骗检测模型主要由两部分组成:LSTM层和分类层.LSTM进行语音欺骗检测时,语音的特征向量xt∈M输入LSTM层,进行前向计算后,将最后时刻的隐状态向量作为分类层的输入.分类层包括一个全连接层和一个softmax层,将LSTM隐藏层计算得到的状态映射为向量p,向量p是通过公式(4)-公式(9)计算得到的,整个过程亦可用公式(10)表示:
p=LSTMforward(xi,ci-1,hi-1)
(10)
其中ci-1和hi-1为前一个LSTM神经元的内部状态和隐藏层的外部状态,xi为当前输入特征序列.位于全连接层的softmax分类器将向量p的每一个元素值转换成语音为真实语音或欺骗语音的概率.模型训练的优化目标函数是交叉熵损失函数,如公式(11)所示:
(11)
2.3 Bi-LSTM模型
2.3.1 Bi-LSTM模型介绍
在有些任务中,一个时刻的输出不仅和之前的信息相关,也和后续时间的信息有关.在这些任务中,研究者通过增加一个按照时间逆序传递信息的网络层,来增强网络的能力.在语音欺骗检测中,前后的语音帧之间保留了语音的相关信息,捕捉前后语音帧的信息能有效提高语音欺骗检测的能力,而Bi-LSTM模型就很适合完成这样的任务.
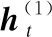
(12)
其中⊕为向量拼接操作.
Bi-LSTM基本结构如图1所示,x1,x2,…,xn表示输入序列,箭头表示信息流方向,cf0,cf1,…,cfn和cb0,cb1,…,cbn表示内部状态,af0,af1,…,afn和ab0,ab1,…,abn表示隐藏层的外部状态,WF和WB表示前向层和后向层的LSTM神经单元.由图1可知,前向层和后向层之间无信息流,这样一来确保了Bi-LSTM网络是无环结构,便于反向传播时更新梯度的值.
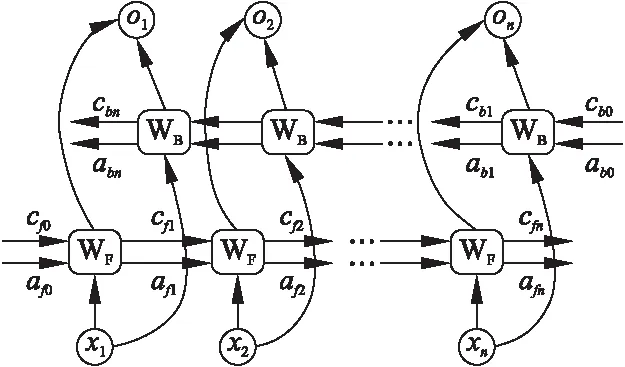
图1 Bi-LSTM模型基本结构
2.3.2 Bi-LSTM语音欺骗检测流程
Bi-LSTM模型语音欺骗检测框图如图2所示,基于Bi-LSTM模型语音欺骗检测过程与LSTM模型类似,语音特征序列分别经由前向层和后向层,首先输入序列分别经由前向层(LSTM_F)和后向层(LSTM_B)的隐藏层计算,得到两个特征向量,分别包含了语音的前向信息和后向信息;然后将这两层最后时刻的隐藏层输出向量合并,再输入到全连接层和softmax层进行分类,判断语音为真实语音或欺骗语音.
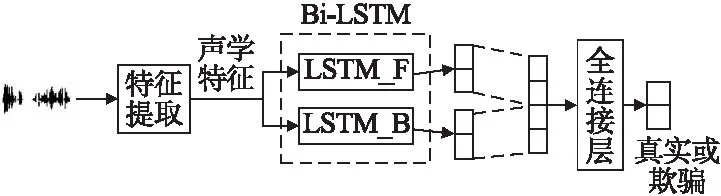
图2 Bi-LSTM模型语音欺骗检测框图
3 本文所提方法
3.1 总体框架
本文提出的基于SBi-LSTM模型进行语音欺骗检测的流程如图3所示,完整的语音欺骗检测流程包括特征提取和欺骗检测两个阶段.在特征提取阶段,首先系统分别在真实和欺骗语音数据集上提取语音特征,来训练GMM模型;然后利用训练好的GMM模型来计算每条语音的均值和方差;最后将得到的语音的均值和方差进行标准化处理,得到GPF.
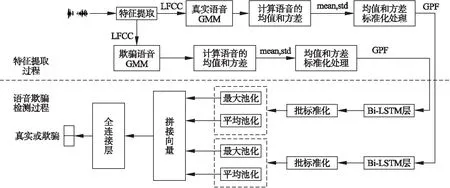
图3 语音欺骗检测框图
在语音欺骗检测阶段,系统将GPF输入SBi-LSTM模型,Bi-LSTM层分别对输入序列进行正向和逆向处理,来捕获输入序列的正向和逆向信息.自适应池化层对Bi-LSTM层输出的向量分别进行最大池化和平均池化计算.系统将池化处理后的向量拼接合并,并将其输入带有softmax分类器的全连接层进行分类,判断语音为真实语音或欺骗语音,从而实现语音欺骗检测.
3.2 高斯概率特征
在传统的GMM模型中,对每一帧语音特征,GMM通过加权方式累加特征在各个高斯分量上的概率密度值,这些高斯分量上的概率密度值的具体分布信息却忽略了.由于真实语音和欺骗语音在特征空间中的分布不一样,使得这两类语音特征在GMM的各个高斯分量上的得分分布也不一样.这种得分分布信息可用来区分语音是真实语音还是欺骗语音.本文根据语音特征帧在GMM的各个高斯分量上的得分,基于LFCC[17]对每个高斯分量上的分数进行建模,来构建高斯概率特征.
对于一个原始的语音帧特征xi,Nj是单个高斯分量对应的概率分布密度函数,新特征fi的大小是高斯混合模型的阶数,πj是高斯分量在模型中所占的权重,分量fij大小表示如公式(13)所示:
fij=ln(πj·Nj(xi))
(13)
GMM模型训练完成后,计算每条语音的均值和方差,为提高GPF特征的鲁棒性,系统对训练集所有语音的均值和方差进行标准化处理.
3.3 SBi-LSTM网络结构
在传统的GMM模型中,GMM独立地累计所有帧的分数,而忽略了相邻帧之间的前后关系.本文采用Bi-LSTM对特征序列进行建模,用于捕获特征的上下文信息.同时,针对GPF特征是以GMM为基础的特点,以真实语音的GMM和欺骗语音的GMM为基础,提出SBi-LSTM模型进行语音欺骗检测.
SBi-LSTM网络结构如图4所示,其特征提取部分是分别使用真实和欺骗语音GMM.SBi-LSTM语音欺骗检测的网络结构部分包含两个独立且架构完全相同的Bi-LSTM网络,以及进行组合池化(最大池化和平均池化)的自适应池化层和进行二分类的全连接层.
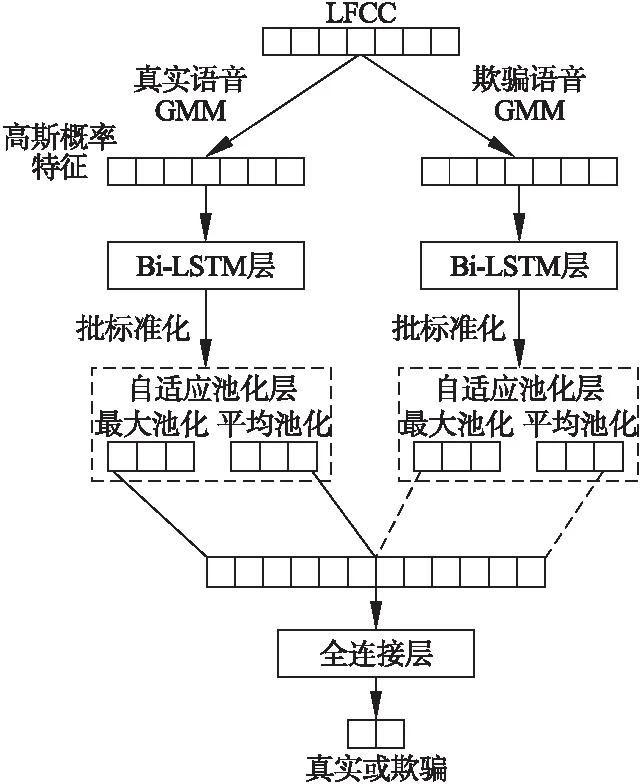
图4 SBi-LSTM网络结构
神经网络将GPF作为输入序列,采用Bi-LSTM层对输入序列进行建模.系统对Bi-LSTM层的输出进行批标准化处理,来提高模型训练时对于不同超参(学习率、初始化)的鲁棒性、让大部分的激活函数能够远离其饱和区域,梯度变得更加平滑,收敛更快,提高训练速度.系统将批标准化处理的特征序列输入自适应池化层,分别进行最大池化和平均池化,得到两个向量,然后将这两个向量拼接为一个向量,并将其输入带有softmax分类器的全连接层进行分类.
3.4 得分融合
为了进一步提高语音欺骗检测性能[18,19],本文在分数层面对GMM模型和SBi-LSTM模型所得分数进行加权融合.融合权重系数α(GMM:SBi-LSTM中GMM所占权重比)是通过开发集数据调试确定的.分数融合计算公式如公式(14)所示:
score=α×scoreGMM+(1-α)×scoreSBi-LSTM
(14)
scoreGMM和scoreSBi-LSTM分别是测试语音在GMM模型和SBi-LSTM模型上的得分.
4 实 验
4.1 实验配置
实验使用Pytorch 深度学习框架来实现SBi-LSTM模型,并使用NVIDIA GeForce 1080Ti来加速模型训练.实验在ASVspoof 2019 数据集[20,21]上运行,该数据集由真实和欺骗语音组成,这些语音来自VCTK基本语料库[22].ASVspoof 2019 数据集专注于文本语音合成、语音转换攻击和语音重放这3种欺骗攻击类型.ASVspoof 2019 数据集分为逻辑访问场景和物理访问场景,这两种场景又分别被划分为训练集、开发集和评估集3部分.ASVspoof 2019数据集的数据分布情况如表1所示.
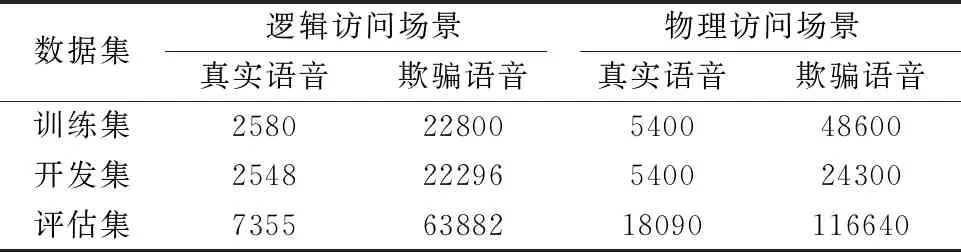
表1 ASVspoof 2019数据集统计
本文在训练神经网络模型的过程中采用交叉熵损失函数,并使用学习率为0.001的Adam优化器对损失函数进行优化.在训练过程中,当准确率停止改善时,SBi-LSTM模型动态下调学习率.在特征提取过程中,时间窗长度为20ms,快速傅里叶转换的频仓大小为512,滤波器数量为20,GMM高斯分量数设置为512,期望最大化(Expectation-Maximum,EM)算法迭代次数设置为20.在SBi-LSTM模型训练过程中,批次大小设置为128,隐藏层的节点数设置为256,dropout为0.5.
4.2 评价指标
实验采用ASVspoof 2019挑战赛中提出的级联检测代价函数(tandem-Detection Cost Function,t-DCF)[23]作为主要的度量标准,采用等错误率(Equal Error Rate,EER)作为辅助度量.
1)等错误率
错误接受率(False Acceptation Rate,FAR),表示欺骗语音被判定为真实语音的概率.错误拒绝率(False Reject Rate,FRR),表示真实语音被判定为欺骗语音的概率.当错误接受率和错误拒绝率相等时,这个值称为等错误率(Equal Error Rate,EER).
2)级联检测代价函数
反欺骗系统(CounterMeasure,CM)和ASV系统级联时,最终检测结果同时受CM系统和ASV系统影响,如果仅仅以EER作为性能评价指标,是无法客观反映CM和ASV系统对最终结果的影响,自然无法可靠反映语音欺骗检测模型的性能.为了弥补以上不足,ASVspoof 2019挑战使用t-DCF作为主要的评估度量,EER作为辅助度量,来对级联的CM和ASV系统的表现进行整体评估.级联检测代价函数定义如公式(15)所示:
(15)
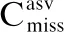
4.3 实验结果分析
为了验证GPF特征和SBi-LSTM模型对于语音欺骗检测的有效性,实验对GMM、LSTM、Bi-LSTM和SBi-LSTM等模型进行性能比较,特征分别使用LFCC和GPF.根据SBi-LSTM的结构可知(详见图4),LFCC不适用于作为SBi-LSTM的输入,故对比实验中不考虑LFCC+SBi-LSTM的组合.
4.3.1 逻辑访问场景下的实验结果
ASVspoof 2019数据集的逻辑访问场景是由17种不同的语音合成和语音转换系统生成的真实和欺骗语音数据组成,其中6种欺骗攻击为已知攻击,剩余的11种为未知攻击.训练集和开发集只包含已知攻击,为了在不匹配的条件下获得更通用的系统,评估集中包含2种已知和11种未知的欺骗攻击.在已知的6种欺骗攻击中,有2种是语音转换攻击,4种是语音合成攻击.11种未知攻击中,包含2种语音转换攻击、6种语音合成攻击和3种语音(转换-合成)混合攻击,这些攻击通过生成对抗网络和频谱滤波等方法来实现.表2显示了在逻辑访问场景下,各个模型以及得分融合后的实验结果.
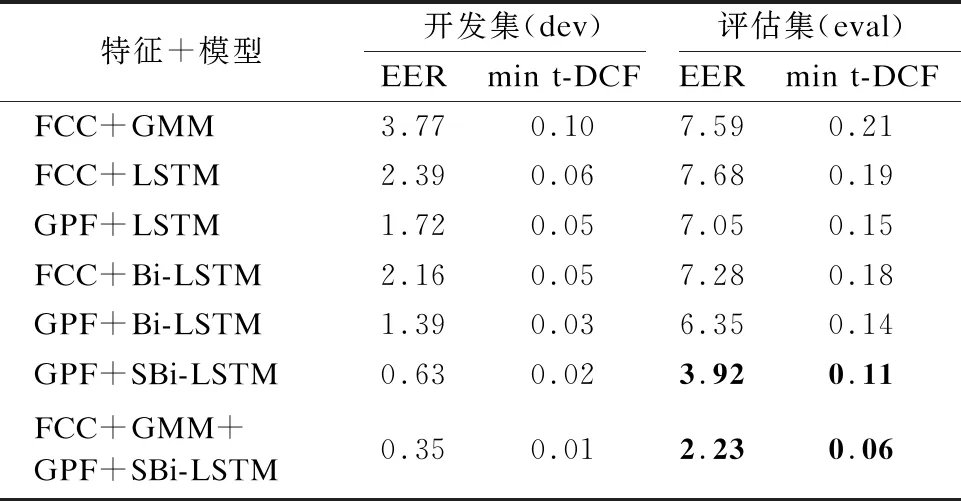
表2 在ASVspoof 2019逻辑访问场景上得到的以EER(%)和min-tDCF表示的实验结果
在ASVspoof 2019逻辑访问场景下,本文提出的GPF+SBi-LSTM在开发集和评估集上均优于LFCC+GMM、GPF+LSTM和GPF+Bi-LSTM等模型.具体来说,在开发集上,GPF+SBi-LSTM较LFCC+GMM而言,分别将min t-DCF和EER降低了80%和83.29%.在评估集上,GPF+SBi-LSTM也在LFCC+GMM的实验结果基础上分别将min t-DCF和EER降低了47.62%和48.35%.将开发集和评估集得到的实验结果进行对比来看,不论是GPF+SBi-LSTM还是其他模型,其在评估集上的表现远不如在开发集上的表现.产生这种现象的原因在于,ASVspoof 2019的训练集和开发集的欺骗语音,是由6种不同的已知欺骗算法混合生成,而评估集中却包含11种未知的语音欺骗攻击.这也侧面地反映了一个问题,利用已知欺骗攻击算法训练得到的模型存在过拟合现象,模型的泛化能力有待加强.
LSTM和Bi-LSTM在ASVspoof 2019逻辑访问场景中的开发集和评估集上得到的实验结果,无论是在开发集上还是评估集上,采用GPF得到的实验结果都要比采用LFCC得到的实验结果要好.实验结果证明了GPF有助于提高模型语音欺骗检测的能力.
本文还对GPF+SBi-LSTM和LFCC+GMM进行了得分融合.在开发集上,得分融合后的实验结果较LFCC+GMM得到的实验结果,min t-DCF和EER分别降低了90%和90.72%.评估集上降低幅度稍小,但也分别降低了71.43%和70.62%.在进行得分融合权重比选择的时候,本文对不同的权重比进行调试,得分融合结果如图5所示,其中EER对应左侧主坐标轴,右侧次坐标轴对应min t-DCF.当权重系数α设置为0.8时,无论是评估集或开发集,其对应的EER和min t-DCF都相对更优.
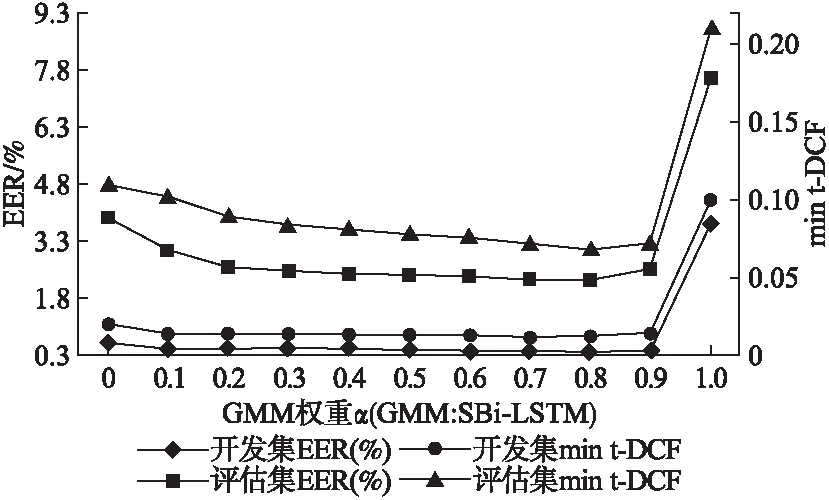
图5 在ASVspoof 2019逻辑访问场景中开发集和评估集上不同权重系数α对应的实验结果
4.3.2 物理访问场景下的实验结果
ASVspoof 2019数据集的物理访问场景下训练集和开发集包含27种不同的声音配置和9种不同的重放配置.声音配置包括3种房间尺寸、3种混响和3种说话人到ASV麦克风距离的详尽组合.重放配置包括3类攻击者到说话人的录音距离和3类扬声器质量.表3显示了各个模型以及得分融合后在ASVspoof 2019物理访问场景下的实验结果.
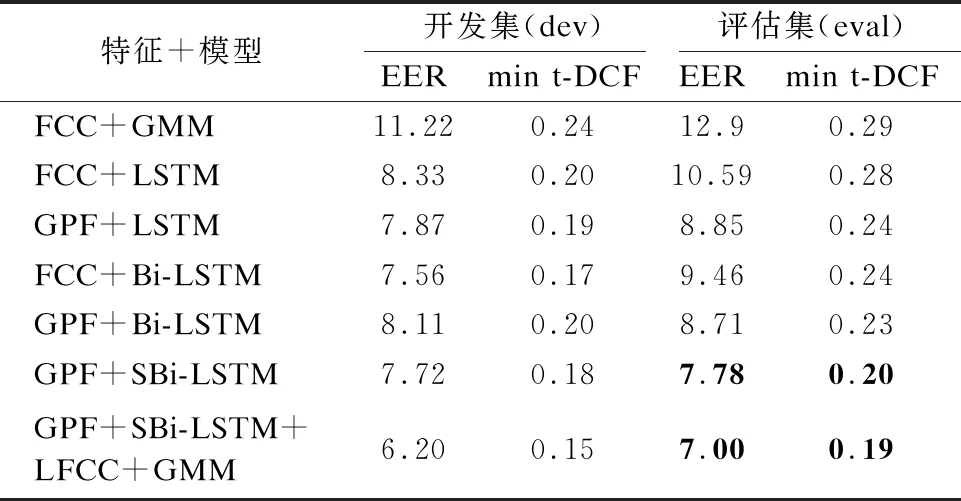
表3 在ASVspoof 2019物理访问场景上得到的以EER(%)和min t-DCF表示的实验结果
从表3可以看到,在ASVspoof 2019物理访问场景评估集下,与LFCC+GMM、GPF+LSTM和GPF+Bi-LSTM等模型相比,本文提出的GPF+SBi-LSTM语音欺骗检测性能提高最大.在开发集上,与LFCC+GMM得到的实验结果相比,GPF+SBi-LSTM分别将min t-DCF和EER降低了25%和31.19%.在评估集上,GPF+SBi-LSTM在LFCC+GMM得到的实验结果基础上分别将min t-DCF和EER降低了31.03%和39.69%.实验结果证明,在物理访问场景下,GPF+SBi-LSTM较其他模型依然有一定程度的性能提高.
GPF+SBi-LSTM和LFCC+GMM得分融合后得到的实验结果,不论是在开发集还是评估集上,都要比单独的GPF+SBi-LSTM或LFCC+GMM得到的实验结果要好.不同权重系数α对应的实验结果如图6所示,与逻辑访问场景一样,当权重系数α设置为0.8时,得分融合后的EER和min t-DCF相对较优.在开发集上,得分融合后的min t-DCF和EER较LFCC+GMM模型分别降低了37.5%和44.74%,在评估集上分别降低了34.48%和45.74%.
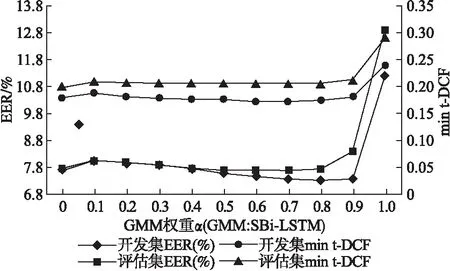
图6 在ASVspoof 2019物理访问场景中开发集和评估集上不同权重系数α对应的实验结果
5 结束语
本文提出GPF特征,采用Bi-LSTM网络进行建模,借助其处理长时间序列的结构优势,捕捉GPF的前后依赖.本文根据GPF的特点,提出SBi-LSTM来进行语音欺骗检测.本文在ASVspoof 2019数据集上的实验结果表明,SBi-LSTM比GMM和Bi-LSTM等模型的语音欺骗检测性能更好.此外,实验表明GPF特征在语音欺骗检测上的表现要比LFCC更好.许多研究表明,将CNN和LSTM相结合可以提高模型的鲁棒性,其原因在于模型结合了CNN捕捉局部特征的能力和LSTM捕捉长序列特征的能力.应用CNN+LSTM模型进行语音欺骗检测,将是本文的未来工作.
猜你喜欢
意林·作文素材(2021年9期)2021-07-06
小天使·二年级语数英综合(2019年4期)2019-10-06
阅读(快乐英语高年级)(2019年5期)2019-09-10
阅读(快乐英语高年级)(2019年2期)2019-09-10
小说界(2018年5期)2018-11-26
文苑(2015年9期)2015-09-10
电影故事(2015年16期)2015-07-14
新课程学习·中(2013年3期)2013-06-14
中学数学研究(2008年3期)2008-12-09
