
使用OpenMP+MPI的矩阵乘法并行实现
2022-05-26 10:42:54苟悦宬
电脑与电信 2022年3期
苟悦宬
(北京交通大学计算机与信息技术学院,北京 100044)
1 引言
矩阵乘法是线性代数中的基础运算,也是科学研究、工业生产中很常见的计算。可它往往会因为矩阵规模过大而出现运算时间过长等耗费时间的现象,在现实用于生产时,显然无法承受性能低下带来的经济损失。
基于集群计算机的并行算法主要有MPI 和OpenMP 两种[1]。其中,MPI是一种消息传递编程模式,其实现关键在于正确地进行消息传递,它的编程模式复杂,需要分析和合理地划分计算程序[1]。OpenMP是一套用于共享内存并行系统多线程程序设计的指导性注释(compiler directive),是为共享内存的多处理器系统设计的并行编程方法,OpenMP 特别适合用在多核处理器计算机上运行的并行程序设计[2]。MPI+OpenMP 混合并行程序执行流程图如图1 所示[3]。OpenMP用于每个结点上的计算密集型工作,MPI用于实现结点间的通信和数据共享。在集群内采用MPI技术,减少消息传递的次数以提高速度,在集群的每个成员上又采用OpenMP 技术,节省内存的开销,综合两种并行的优势,可以提升并行程序的执行效率。
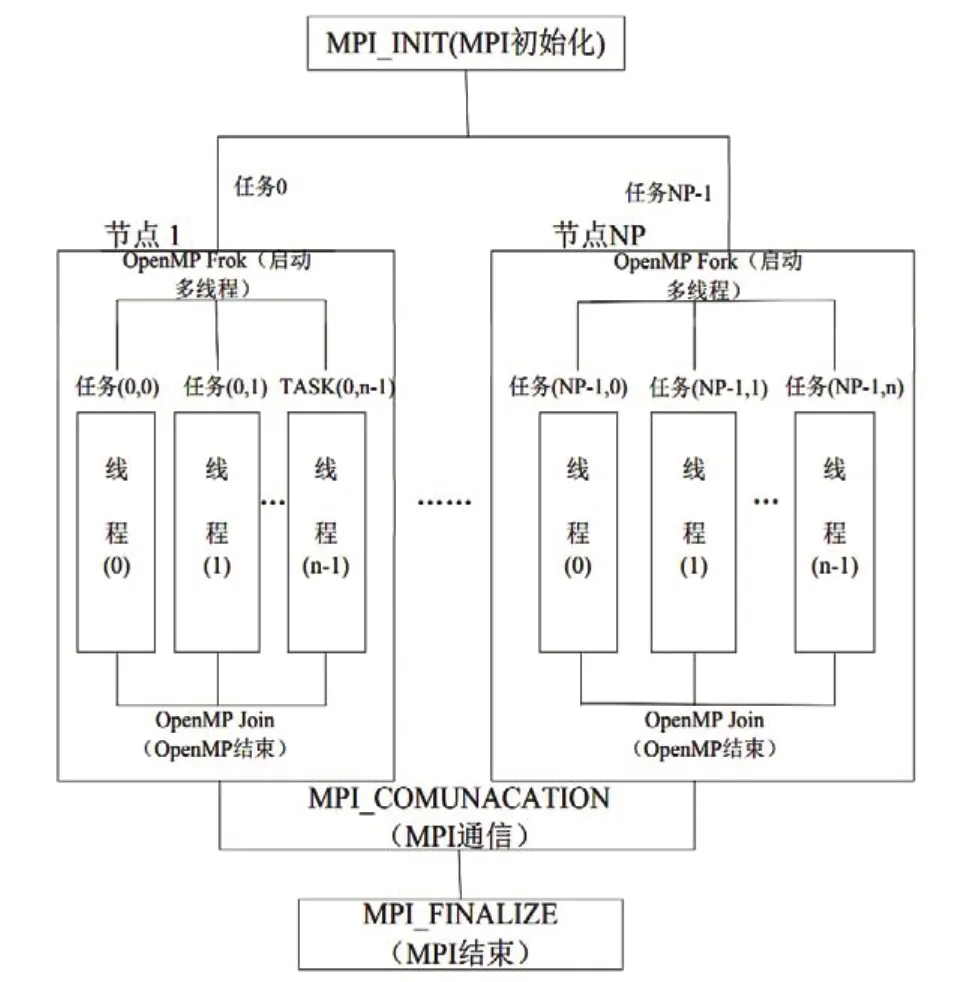
图1 MPI+OpenMP 混合并行程序执行流程图[3]
关于OpenMP和MPI的一些更具体的对比见表1。
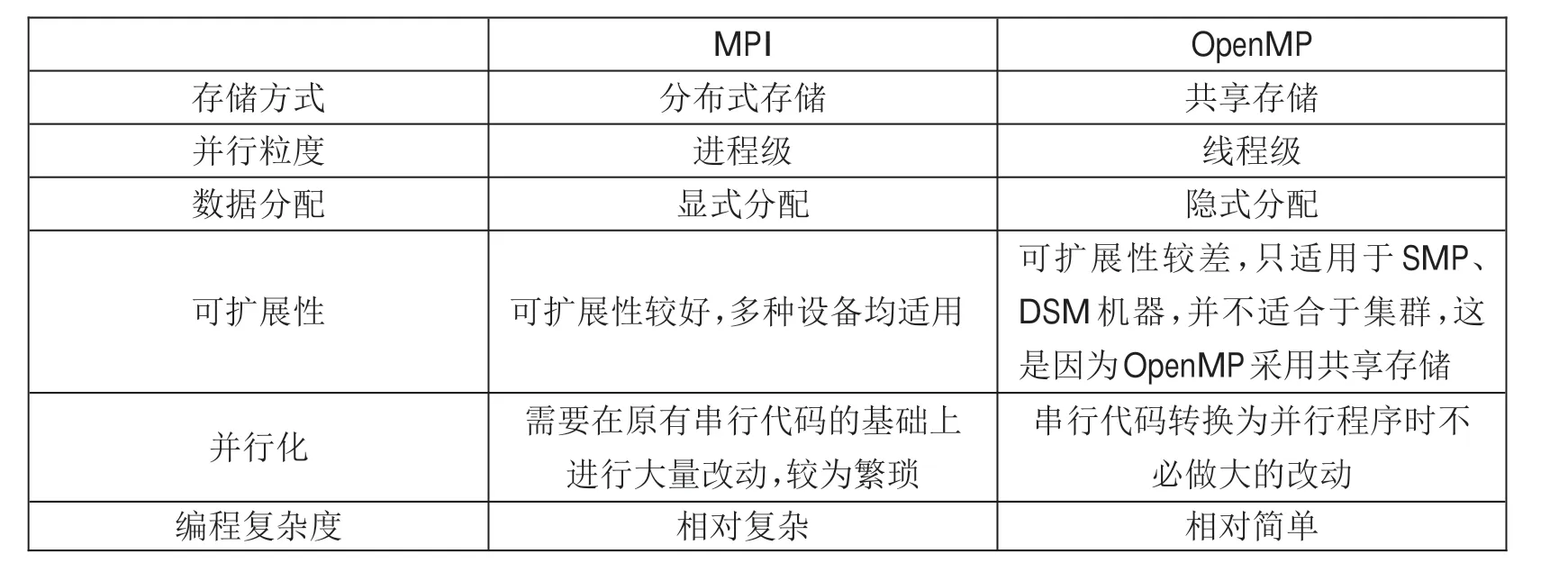
表1 OpenMP和MPI的比较
此外,本实验在PC 机与华为鲲鹏处理器上完成,鲲鹏920 处理器采用华为自主开发的处理器内核,兼容ARMV8.2 指令集,通过优化分支预测算法、提升运算单元数量、改进内存子系统架构等一系列微架构设计,大幅提高了处理器单核性能[4],且集成了64核,主频提升至2.6GHz[5]。
本实验选取两个1000*1000 的矩阵相乘,在此种规模矩阵的相乘下设计了MPI+OpenMP混合编程的优化方法,采用OpenMP在每个结点计算,使用MPI进行进程间通信。并在PC机、华为鲲鹏服务器上得到了不同线程的运行结果,并给出了性能分析与相关结论。
2 并行算法的设计与实现
本实验取两个1000*1000 矩阵Matrix_one和Matrix_two进行乘法运算,运用MPI_Scatter 数据分发的思想将Matrix_one分为数个行数为1000除以进程数、列数为1000的小矩阵,并使用MPI_Bcast将Matrix_two广播至每个进程,在每个MPI 进程中,使用OpenMP 辅助进行小矩阵和Matrix_two的相乘运算。最后再用MPI_Gather聚集运算结果,并显示时间性能的相关信息。图2是在进程数为4时的运算流程。
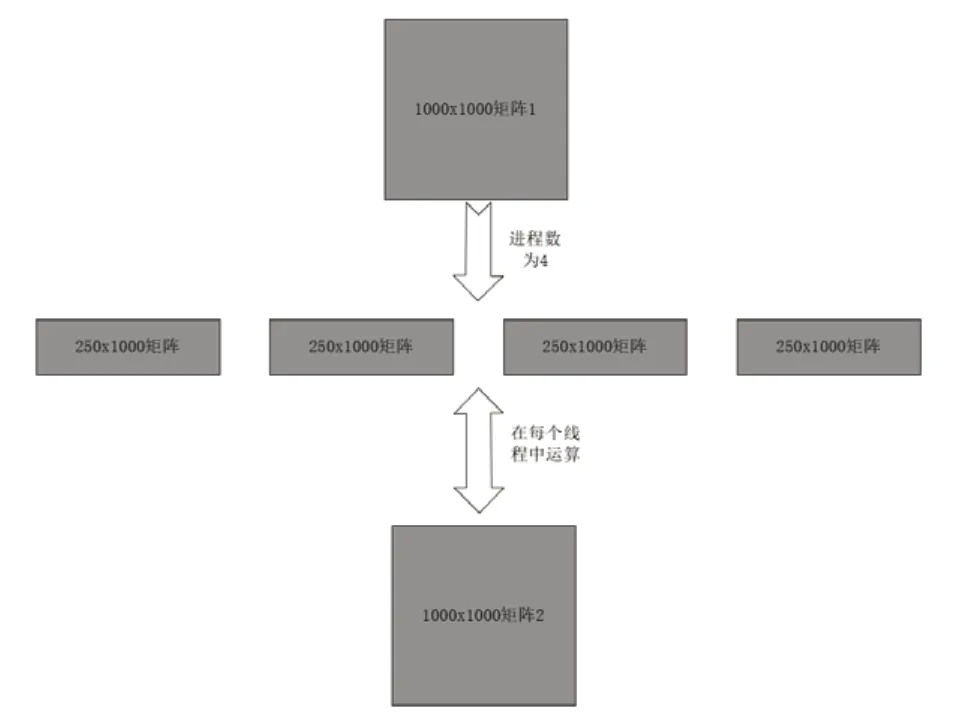
图2 MPI+OpenMP 混合并行程序执行示意图
2.1 两个矩阵的形成
为进行运算首先需要生成两个矩阵,采用rand()%10 生成每个单元都为10以内的整数的矩阵,代码如下:
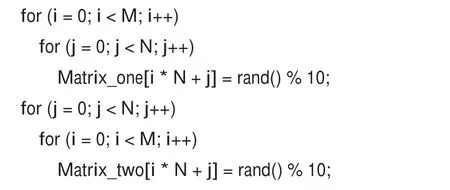
这里矩阵2生成的时候相当于直接将一个矩阵的转置存入,这是为方便后续运算时两个矩阵都是每一行对应相乘,读取是连续的,速度较快。
2.2 数据分发与广播
此处实现将矩阵1 分块并将矩阵2 广播给各线程的工作,做好并行计算的准备。代码如下:

2.3 OpenMP计算部分
矩阵1 分成的小矩阵和矩阵2 相乘采用OpenMP 执行,实现代码如下,注意此处ii和kk两个局部变量需要在线程内部定义,否则会出现多线程使用同一变量的局面,造成运行失败。代码如下:

此外,对于不能整除的情况,即分割过程中矩阵1剩余的行,直接在线程0中计算即可,过程与上述类似。
2.4 结果聚集
使用MPI_Gather 汇聚计算结果,如有需要,也可以将结果矩阵输出至文件观察。汇聚结果的代码如下:
MPI_Gather(local_result, local_M * N, MPI_INT, result_Matrix,local_M*N,MPI_INT,0,MPI_COMM_WORLD);
3 测试结果
3.1 PC机测试结果
首先进行PC机的测试,所用PC机具有8核CPU,分别分配1/2/4/8个进程,所得运行时间如表2。
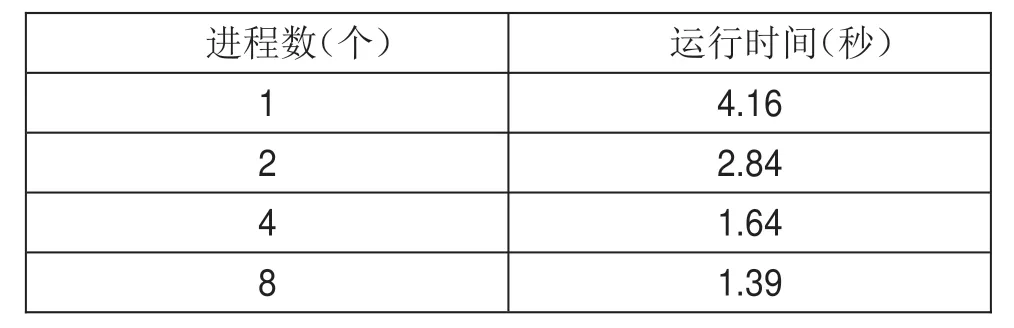
表2 PC机测试结果
3.2 鲲鹏处理器测试结果
单个华为鲲鹏处理器的运行结果如表3,分别在进程数为1/2/4/8/16/32的情况下进行。
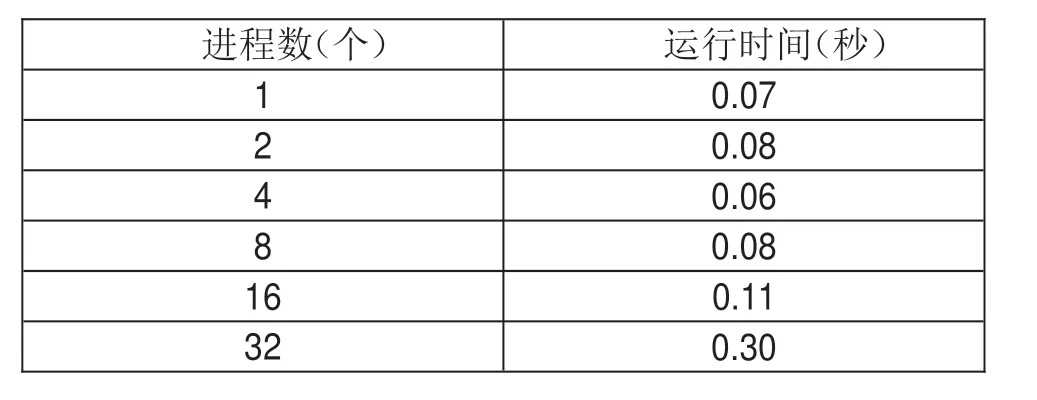
表3 鲲鹏处理器(单机)测试结果
多机运行结果为表4,其分配的线程数量与单机一致。
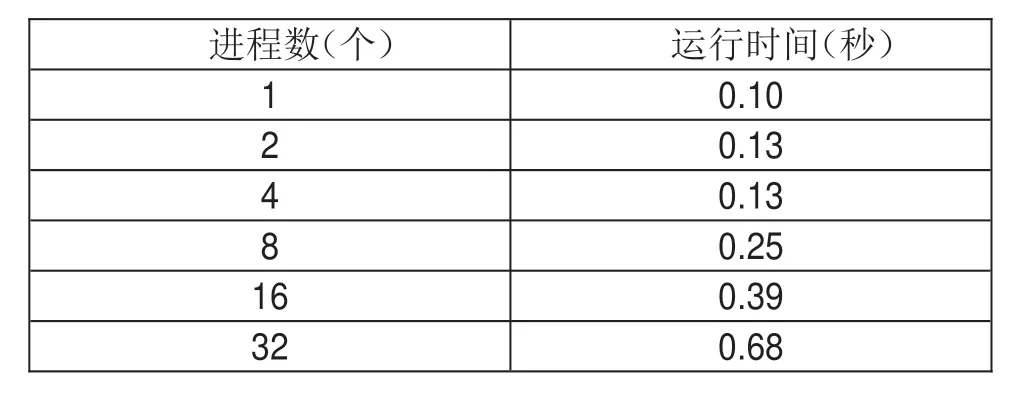
表4 鲲鹏处理器(多机)测试结果
4 性能分析
PC 机运行结果折线图如图3,可见在一般的8 核CPU中,1000*1000 规模的矩阵乘法运算速度随着进程数提高而显著加快。
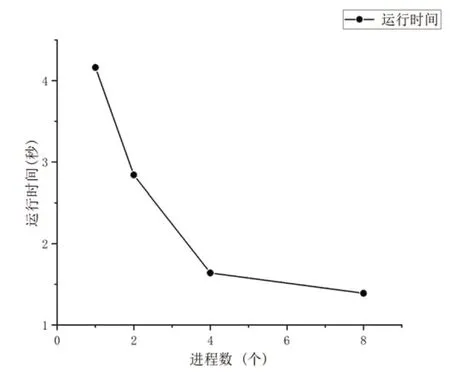
图3 PC机结果折线图
鲲鹏处理器的运行结果折线图如图4,可见鲲鹏处理器的性能比一般PC 机CPU 高很多,但是这里出现的情况是运行时间随着进程数的增加、处理器数量的增加而增加。由此可见并不是进程数越多运算就越快,还涉及进程通信的时间损耗、硬件资源的环境限制、问题的规模大小等诸多因素。
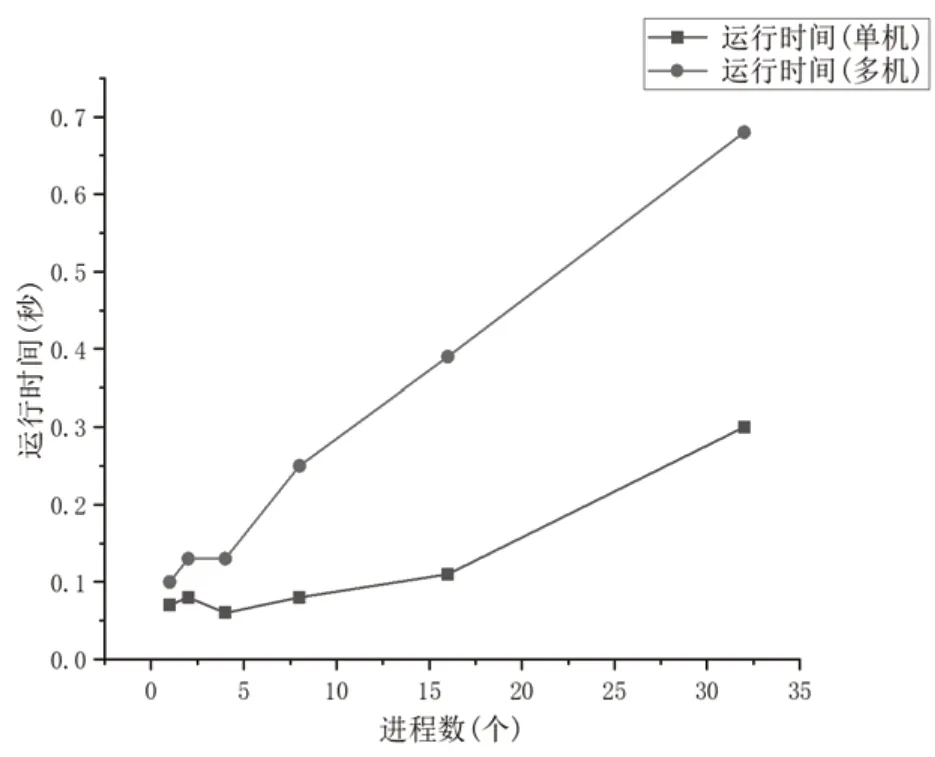
图4 鲲鹏处理器结果折线图
5 结语
本实验完成了规模选取、算法设计、代码编写与调试、结果性能分析的完整过程,得出了运算速度不是单纯地取决于进程数量的结论,这与人们一般的思维方式是不同的,进程通信、服务器交互过程中发生的时间损耗、所用不同硬件环境的资源限制、欲解决问题的规模大小等许多的因素都会影响到运算时间的长短。工业生产等诸多领域都会用到此并行编程模型,对于影响运行性能的要素需要格外注意。
猜你喜欢
汽车观察(2021年11期)2021-04-24 20:47:38
中国外汇(2019年20期)2019-11-25 09:54:58
小哥白尼(军事科学)(2018年12期)2018-12-19 05:17:00
小哥白尼(军事科学)(2018年5期)2018-06-15 09:56:04
电脑与电信(2018年12期)2018-03-23 02:37:40
中华诗词(2017年3期)2017-11-27 03:44:07
制造技术与机床(2017年9期)2017-11-27 02:13:55
电子制作(2017年23期)2017-02-02 07:16:47
民主与科学(2014年3期)2014-02-28 11:23:03
教育与职业(2014年7期)2014-01-21 02:35:04
