
基于BtLSTM的社交媒体虚假新闻检测
2022-05-26 08:56郭亚杰纪淑娟赵金升
软件导刊 2022年5期
郭亚杰,纪淑娟,曹 宁,赵金升
(1.山东科技大学计算机科学与工程学院,山东青岛 266590;2.山东鑫超网络科技有限公司,山东泰安 271000)
0 引言
在现代社会,相较于传统新闻媒介,越来越多的人倾向于从自媒体新闻平台上获得消息。发生这种变化的原因与自媒体平台的以下性质有关:①在自媒体上阅读新闻往往比传统新闻媒体(如报纸或电视)更及时、更方便;②在自媒体上更容易与朋友或其他读者分享、讨论新闻;③自媒体的语言文字更加简洁,形式多样,甚至以短视频或图片的方式呈现。
生活中比较常见的自媒体平台包括微博、微信公众号、抖音、快手、知乎等,均具有明显的普泛化、私人化、基层化特点,其中微博作为当前影响力最深、用户基数最大、知名度最广的自媒体平台,为广大网民提供了一个可以自主发由言论和进行交流的平台。微博的准入门槛较低,用户鱼龙混杂,所有用户都可以直接使用手机、电脑等终端随时发表言论。因此,很多人为弥补在现实生活中不被重视的缺失,通过在微博中发布虚假新闻博人眼球,还有一些第三方通过雇佣水军在微博上发布一些虚假消息[1],从而牟取利益。微博具有的评论、转发功能使得虚假信息能够轻易地在社交媒体中大范围传播和扩散,并且可以从网络传播演化为现实生活中的传播。此外,社交机器人在新闻传播过程中扮演着重要角色。研究表明[2],社交机器人的存在比例在真实新闻和虚假新闻传播过程中有很大差异,这也使得真实新闻和虚假新闻的传播范围有所不同。由图1(彩图扫OSID 码可见,下同)可以看出,社交机器人能够使得虚假新闻在短时间内大范围扩散,而真实新闻的扩散范围则相对较小,其中红色圆圈表示真实用户,蓝色圆圈表示社交机器人。

Fig.1 Spreading path of real news and fake news based on social robot图1 基于社交机器人的真实新闻与虚假新闻的传播路径
虚假新闻的广泛传播会对个人和社会产生严重负面影响。首先,虚假新闻会打破信息生态系统的平衡。例如最受欢迎的虚假新闻在微博上的传播范围明显超过最受欢迎的真实新闻;其次,虚假新闻会有意地说服阅读者接受有偏见或错误的信息,例如一些报告显示俄罗斯通过创建虚假账户和社交机器人传播虚假故事[2]。因此,及时对虚假新闻进行检测具有重要的现实意义。
1 相关研究
现有信息传播研究方法主要分为基于内容特征和基于传播特征两大类。然而,基于传播特征的方法受到数据缺失、数据噪声和数据收集困难的限制,研究者必须沿着虚假新闻传播的路线,不断捕捉其相关行为。相比之下,基于内容特征的方法更为简单方便,多通过提取文本特征检测虚假新闻。
深度学习方法可以自动提取特征,受到新闻行业的极大关注。例如,贺刚等[3]将符号、关键词分布、时间差以及文本特征、用户特征等作为特征模板,然后利用支持向量机(Support Vector Machines,SVM)对微博谣言进行识别;Yu 等[4]通过卷积神经网络(Convolutional Neural Network,CNN)提取文本内容的语义特征;Popat[5]发现语言风格对理解文章的可信度起着至关重要的作用;Castillo 等[6]基于文本内的问号、表情符号、情感词等进行特征提取,然后通过决策树对Twitter信息进行识别。
在深度学习技术自动提取特征的基础上,一些学者基于新闻内容进行虚假新闻检测。例如,Li 等[7]提出多级卷积神经网络,引入了局部卷积特征和全局语义特征,以有效捕捉文本中的语义信息,进而对新闻进行真假分类;段大高等[8]将博主的用户属性与微博的文本属性进行融合,然后使用BP 神经网络进行微博谣言检测;刘知远等[9]提出一种基于CNN 的虚假新闻早期检测模型,能够自动寻找可信检测点,并实现高精度检测。在真实数据集上的实验结果表明,该模型具有较高的识别准确率;刘政等[10]首先将微博文本进行向量化,然后通过CNN 挖掘文本的深层特征,从而获得更好的检测效果;Zubiaga 等[11]利 用Word2Vec对Twitter进行向量表示,从而进行谣言检测。
还有一些研究者从新闻的评论回复中提取特征以检测信息真伪,包括用户转发、点赞和评论等。理论上来说,人们对新闻的反应不仅包含新闻的社会属性,还包含这篇新闻在社交媒体上传播以及人们如何与之互动的结构信息。基于此,Ma 等[12]采用递归神经网络(Recurrent Neural Network,RNN)对与新闻事件相关的转发、评论进行分类,在虚假新闻早期检测中取得了不错的效果;Jin 等[13]利用微博中自相矛盾的观点进行虚假新闻检测。
由以上研究可以看出,无论是基于传播结构还是用户特征进行虚假新闻检测,在构建模型的过程中都需要融合新闻文本或评论转发文本特征,文本特征对于虚假新闻检测不可或缺。BERT(Bidirectional Encoder Representations from Transformers)模型[14]能全面表示句子的语义信息,长短时记忆神经(Long Short-Time Memory,LSTM)模型[15]能够解决句子的长距离依赖问题。基于此,本文提出一种基于BtLSTM 的虚假新闻检测模型,将BERT 模型与LSTM 模型融合互补,能更好地区分真实新闻和虚假新闻在语义特征上的差别,有效提升基于文本内容的虚假新闻检测效果。
2 BtLSTM 模型建立
2.1 问题定义
对本文中使用的符号进行定义,其中事件集合M=为第j条新闻文本;wi表示第j条新闻中第i个词语;yj为第j条文本所属的类别,其中0 代表真实新闻,1 代表虚假新闻。BERT 层的输入E={E1,E2,…,En},其中Ei为一条新闻文本中第i个词语的向量表示,Ei∈Rd×1;BERT 层的输出为T={t1,t2,…,tn},其中ti为第i个词语的向量表示,ti∈Rd×1;LSTM层的输入X={x1,x2,…,xn},其 中xi∈Rn×1。
2.2 BtLSTM 模型
图2 为BtLSTM 模型的总体结构。其首先利用预训练的BERT 语言模型提取新闻文本的语义表示,然后使用LSTM 模型进一步提取特征。该模型是对预训练BERT 语言模型的扩展,能够结合上下文理解语义,准确表示多义词的语义信息。同时,该模型利用LSTM 模型的记忆功能进行学习,可最大程度地保留全局语义特征。
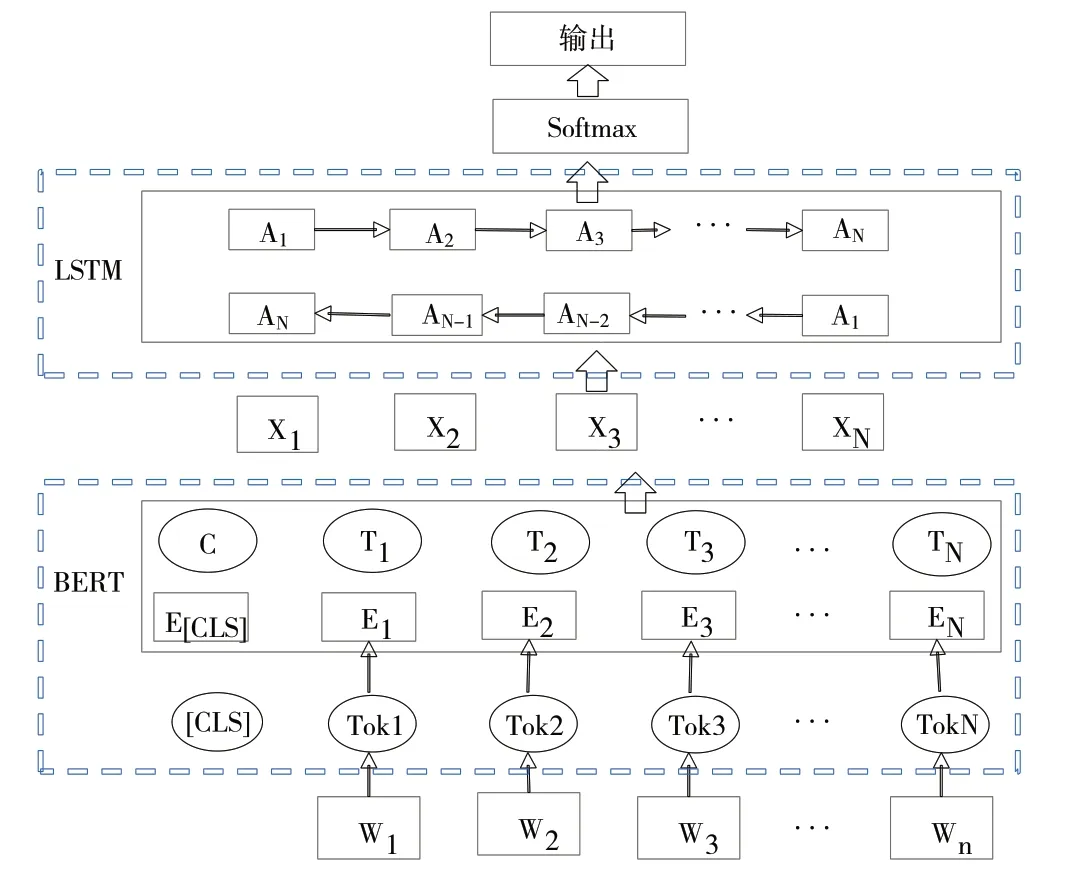
Fig.2 BtLSTM model structure图2 BtLSTM 模型结构
2.2.1 BERT层
BERT 模型的结构如图3 所示,其基于双向Transformer编码器实现,编码器为Encoder-Decoder 结构,利用多头注意力机制[16-17]通过上文信息增强文本的语义表示。
对于BERT 模型的输入,每个词语的向量表示Ei都是通过将词向量(token embeddings)、段向量(segment embeddings)、位置向量(position embeddings)相加得到[18],输入示例如图4 所示。BERT 模型在每条文本前插入了一个[CLS]符号,将该符号的输出向量作为整个文本的语义表示,这个没有明显语义信息的符号能够更加公平地融合各词的语义信息;文本末尾的符号[SEP]表示两条文本的分割符。
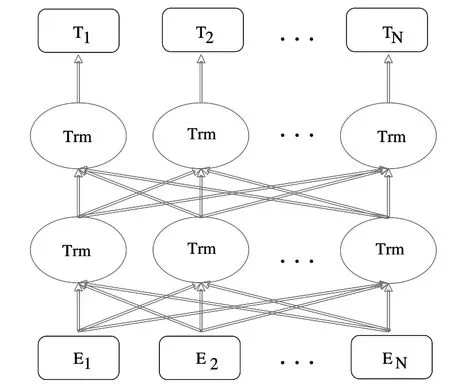
Fig.3 Structure of BERT model图3 BERT模型结构
BERT 模型的预训练采用遮掩语言模型实现,随机对文本中的词语进行遮掩,然后在训练过程中对其进行预测,使得模型依赖上下文信息学习到不同方向的语义特征[19]。通过不断调整模型参数,使得最后模型输出的语义表示向量能够准确刻画出文本的语言本质。经过BERT 层训练后,最后一层的输出为T={t1,t2,…,tn}∈Rd×n,ti为词语的向量表示,其包含融合了整个文本的语义信息。
2.2.2 LSTM层
LSTM 层结构如图5 所示。将BERT 层的输出T经过tanh激活函数后得到X={x1,x2,…,xn}∈Rn×n,并将其作为LSTM 层的输入,其中xi的计算公式为:

式中,wx为权重矩阵,wx∈Rn×d;bx为偏置项;θ为激活函数tanh;xi为词语经过BERT 层后得到的向量表示,xi∈Rn×1。
将得到的向量输入到LSTM 模型中的隐藏层进行计算。本文采用的是双向LSTM 模型,因此要在两个不同方向的隐藏层分别进行计算,并保存前向隐藏层和后向隐藏层在每个时刻的输出[20]。其中,n 时刻前向隐藏层输出向量表示为,后向隐藏层输出向量表示为,计算公式分别为:

Fig.4 Input example of BERT model图4 BERT模型输入示例

Fig.5 Structure of LSTM layer图5 LSTM 层结构

式中,wf为前向隐藏层输出对应的权重矩阵;wb为后向隐藏层对应的权重矩阵;α为sigmoid 激活函数。
将1~n 时刻的所有隐藏层输出进行整合,连接成最终的特征向量H,表示为:

将特征向量H 输入到全连接层,最后将全连接层的输出输入到Softmax 函数进行检测,计算出对应类别的分布概率,表示为:

式中,W为权重矩阵,b为偏置项。
3 实验方法与结果分析
3.1 数据集
采用Song 等[21]于2018 年发布的数据集,该数据集为根据新浪微博不实信息举报平台抓取的中文数据,包含与微博原文相关的转发与评论信息。数据集中共包含1 538条真实新闻和1 849 条虚假新闻,其中标签1 代表虚假新闻,0 代表真实新闻。采用刘政等[12]对数据集的划分方式,将训练集与测试集的比例设定为9∶1,模型训练过程中选取训练集中的10%作为验证集。数据集样例如表1所示。

Table 1 Sample data set表1 数据集样例
3.2 实验设置
使用哈尔滨工业大学讯飞联合实验室发布的中文预训练BERT 模型[16],该模型在Google 发布的中文BERT 模型的基础上进行了改进,主要包括BERT-Base 和BERTLarge 两种语言模型。两者具有相同的网络结构,但参数和大小有所不同,本实验选择BERT-Base 模型。本文使用的BERT 模型、LSTM 模型参数如表2、表3所示。

Table 2 BERT model parameters表2 BERT模型参数

Table 3 LSTM model parameters表3 LSTM 模型参数
3.3 评估标准
采用文献[22]中的评估指标,包括准确率(Precision)、召回率(Recall)和F1 值(F1-score)。为了正确使用这些评估指标,首先定义TP、FN、FP、TN 4 种分类情况,具体如表4所示。

Table 4 Classification index description表4 分类指标说明
在此基础上,准确率、召回率、F1值的定义如下:

3.4 结果分析
将传统的深度学习模型(FastText、CNN、LSTM)、BERT、BtCNN(BERT+CNN)作为基线模型,与本文提出的BtLSTM 模型进行准确率、召回率和F1 值的比较。各模型实验结果如表5 所示。可以看出,BtLSTM 模型在所有模型中效果最好,所有评估指标均为最优。单一LSTM 模型的性能比CNN 模型稍差一些,但当它们分别与BERT 模型结合后,BtLSTM 模型的性能优于BtCNN 模型,这是由于通过BERT 层对文本进行全面的语义表示后,LSTM 模型的记忆功能能更好地利用文本的上下文语义信息,而CNN 模型只能提取局部特征,对上下文信息有所遗漏。此外,相较于通过Word2vec 模型对新闻文本进行向量化的LSTM 模型,本文提出的通过BERT 模型对新闻文本进行向量化的BtLSTM 模型在准确率和F1 值上分别提高了3.52%、3.32%,表明BERT 模型能更好地对文本进行全面的语义表示。

Table 5 Comparison of evaluation indicators of each model表5 各模型评估指标比较(%)
为验证不同模型在各个训练时间所能达到的检测性能,在验证集上对各模型在不同迭代次数下的准确率和F1值变化趋势进行分析,结果见图6、图7。
可以看出,BtLSTM 在较短训练时间内就达到了较好的性能,并能保持平稳状态。这是由于BERT 生成的嵌入词是一种上下文相关的动态表示,因此具有更好的语义表示。当BERT 模型与LSTM 模型结合时,两者相辅相成,优势均能得到最大限度地发挥。BERT 模型和BtCNN 模型也在较短时间内达到了其最好性能,但比BtLSTM 模型稍差一些。CNN 和LSTM 模型的性能差于BERT、BtCNN 和BtLSTM 模型。表现最差的为FastText 模型,在第10 次迭代才到达较为稳定的状态,且性能也较差。
4 结语
目前,越来越多的人开始使用自媒体代替传统媒体获取新闻资讯。然而,自媒体会被一些人用来传播不真实的新闻消息,可能会对个人和社会产生强烈的负面影响。因此,本文提出一种基于BtLSTM 的虚假新闻检测模型,首先利用BERT 层提取新闻的文本特征,然后使用LSTM 模型对向量化的文本进行训练以检测新闻真实性。实验结果表明,动态生成的词嵌入比传统的词嵌入对文本信息的语义表示更加全面,检测准确率更高。然而,本文模型也存在一定的局限性,虚假新闻传播快、危害大,其检测时效性十分重要,后续拟将本文模型与新闻时效性相结合,以获得更高效的虚假新闻检测模型。

Fig.6 Accuracy curve of each model varies with iteration times图6 各模型准确率随迭代次数变化的曲线

Fig.7 F1 value curve of each model varies with iteration times图7 各模型F1值随迭代次数变化的曲线
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
医学食疗与健康(2021年27期)2021-05-13
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
中国交通信息化(2018年5期)2018-08-21
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
大连民族大学学报(2015年2期)2015-02-27
外语学刊(2011年1期)2011-01-22
