
黄河流域月尺度灌溉用水量的推算及其时空变化规律分析
2022-05-24 05:07:52王建辉冉金鑫沈莹莹韩振中崔远来罗玉峰
中国农村水利水电 2022年5期
王建辉,冉金鑫,沈莹莹,韩振中,崔远来,罗玉峰
(1.武汉大学水资源与水电工程科学国家重点实验室,武汉 430072;2.中国灌溉排水发展中心,北京 100054)
0 引 言
2019年,黄河流域农业用水量约为流域用水总量的68.8%[1]。然而,黄河以占全国2%的径流量,向占全国15%的耕地和12%的人口供水[2]。目前国内的农业灌溉用水量统计资料主要来自每年发布的水资源公报,均为年尺度数据,对于月尺度数据,需要由各级灌区逐一统计上报,统计难度较大[3]。同时,加上黄河流域内各地区种植结构不同,其用水规律不一致,月尺度灌溉用水量对于区域农业水土资源管理和农业生产用水高效管理具有重要意义。
过去国内外学者对灌溉用水量推算采用基于数理统计规律的方法。Satti[4]等提出了非线性回归模型,考虑了降雨和气温的变化对灌溉用水量的影响;刘小花[5]等建立了含周期项、趋势项和随机项的ARMA(p,q)模型,对开封市水资源的利用进行了预测,结果合理可行。但这类方法需要长系列的资料来建立模型,所需参数单一,适用于参数变化较小的预测[6,7]。目前国内外学者多采用启发式算法。Zhang[8]等引入非线性协整理论和小波神经网络方法,建立了灌溉水量小波非线性协整预测模型。迟道才[9]等提出了把人工神经网络和灰色预测方法结合成并联型灰色神经网络预测方法。刘玲[10]等提出了基于改进BP神经网络的农业灌水量预测模型,对天津市里自沽灌区的年灌水量进行预测,取得较好的效果。以往学者所建立的灌溉用水预测模型大都针对典型灌区的单一作物的年灌水量预测,并未探究作物生育期内的用水动态变化,对年内用水分配管理指导意义不强。本文以黄河流域为研究对象,基于TensorFlow 架构分区分作物构建BP 神经网络模型,推算灌溉分区不同作物生育期内的月灌溉用水量,探究月尺度灌溉用水量的时空变异规律。
1 数据与方法
1.1 研究区概况
黄河流域面积总计约79.5 万km2(含内流区面积约4.3 万km2),占全国土地总面积的8.3%。从西到东横跨青藏高原、内蒙古高原、黄土高原和黄淮海平原4 个地貌单元,地势西高东低,包含了青海、甘肃、宁夏、内蒙古、陕西、山西、四川、河南及山东在内的9 个省(区),如图1 所示。流域年平均气温在-4~14 ℃之间,总的趋势是由东南向西北递减。流域内大部分地区年降水量在200~650 mm 之间,总的趋势是由东南向西北递减。
1.2 资料收集
灌溉分区资料来自流域内各省(区)发布的《用水定额》,作物种植面积、灌溉面积来源于国家统计局(http://www.stats.gov.cn/)、各省(区)统计年鉴、《中国农业统计年鉴》以及《黄河统计年鉴》等。气象资料包括黄河流域内122 个气象站点(见图1)的2015年1月1日-2018年12月31日的逐日气象数据,数据来源于中国气象数据网(http://data.cma.cn/)。作物实测灌水资料(2015-2018年)和灌溉水有效利用系数(2018年)来自各灌区管理部门。
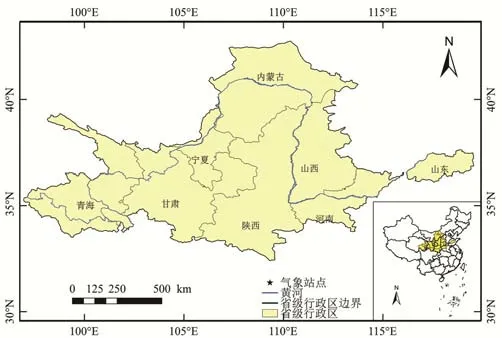
图1 黄河流域地理位置概况图Fig.1 Overview of geographical location of the Yellow River Basin
本文结合各省出台的灌溉定额分区情况及黄河流域界限,将黄河流域划分为24 个灌溉分区。研究区域灌溉分区情况如图2所示。

图2 黄河流域灌溉分区图Fig.2 Irrigation zoning map of the Yellow River Basin
1.3 基于TensorFlow架构的BP神经网络模型
BP(Back Propagation)神经网络是一种按误差逆传播算法训练的多层前馈网络。模型包括正向传播和误差反向传播两部分:①正向传播过程,与所有前馈神经网络一样,数据传播方向为输入层→隐藏层→输出层,最后计算出网络产生的总误差。②误差反向传播过程,从输出层到输入层反向遍历所有层,逐层计算网络内部各层误差,作为修正各层神经元权值的依据[12]。
TensorFlow 是一个采用数据流图进行数值计算的开源智能软件库,里面内置了很多神经网络的优化算法,常用于机器学习和神经网络方面的研究[13]。TensorFlow 具有高度的灵活性、可移植性、可视化等优点,同时可使用Python 语言实现其库功能。本文使用TensorFlow 深度学习框架实现BP 神经网络模型算法,用于黄河流域月灌溉用水量的推算。
本文按照灌溉分区不同作物类型进行建模。选取的模型数据集包括各灌溉分区内不同作物生育期内的月份、月降雨量、月ET0以及实测月灌溉定额。基于2000-2014年黄河流域长系列的降雨资料,计算黄河流域不同频率水文年:25%丰水年、50%平水年、75%枯水年的平均年降雨量,分别为:554.89、514.19 以及489.73 mm,2015-2018年流域年平均降雨量分别为:535.3、612.1、564.6、616.0 mm,可见2015年属于平水年,2016-2018年均属于丰水年。因此,以2016-2017年的数据为主、2015年数据为辅,作为模型的训练集,以2018年的数据作为测试集。模型训练结果可代表丰水年类型的月灌水量推算。在24 个灌溉分区中,共有11 个灌溉分区的25 种作物有历史实测灌溉定额数据,利用这11 个灌溉分区的实测数据构建BP 神经网络模型。剩下13个无实测历史资料的灌溉分区,利用相邻灌溉分区训练好的BP神经网络模型进行推算。
月降雨量、月ET0能够从水量平衡机理层面解释灌水量的变化,使模型具有较好的解释性和精确性。此处建立的模型是一种灌水量推算模型,因此不考虑未来灌水量的预测,只考虑典型年全流域的灌水量推求。月份m代表模型输入的时间序列,降雨P来源于气象站点的逐日降雨量,ET0值采用Penman-Monteith公式计算[14]:
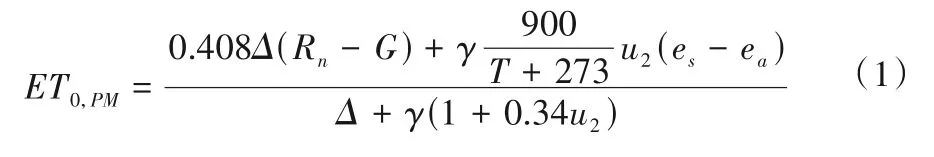
式中:ET0,PM为参考作物蒸散量,mm;Rn为净辐射量,MJ/(m2·d);G为土壤热通量,MJ/(m2·d);T为日平均温度,℃;u2为距地面2 m 高处风速,m/s;es为饱和水汽压,kPa;ea为实际水汽压,kPa;Δ为饱和水汽压与气温关系曲线上的斜率,kPa/℃;γ 为干湿温度计常数,kPa/℃。
模型输出数据集为灌溉分区的月灌溉定额。根据样点灌区各典型田块历次灌水记录,可计算出样点灌区不同作物灌溉定额,对每一种作物在样点灌区测算的灌溉定额进行算术平均,作为灌溉分区该种作物的月灌溉定额,按下式计算:

式中:Ii,j,k表示灌溉分区i的第j种作物生育期内第k个月的灌溉定额;Tj,k、Aj,k分别表示某样点灌区第j种作物田块第k月的灌溉用水量、实灌面积。
模型的隐含层节点数取值范围为3~13。将分区分作物模型不断进行调试,选取最优的隐含层层数及节点数,如表1 所示。模型的隐含层层数大多数均为1 层,每层的节点数最少为8,最多为12,均在设定的3~13的范围内。

表1 模型隐含层最优参数设定Tab.1 Optimal parameter setting of model hidden layer
误差函数采用均方误差MSE评价模型训练的精度。TensorFlow 里面还提供了很多参数初始化的方法。本文对权重w、偏差b、训练次数、学习率有如下设置:初始权重w设为一个服从标准正态分布的随机数,初始偏差b设为0.5,训练次数设为5 000,学习率设为0.005。最后模型在session中启动,开始训练网络。
1.4月毛灌溉用水量计算
利用模型推算出的灌溉分区月净灌溉定额,结合灌溉水有效利用系数和作物有效灌溉面积,按定额法计算得到各灌溉分区逐月毛灌溉用水量,具体计算公式如下:

式中:Wi,灌为某灌溉分区第i月的灌溉用水量,亿m3;wij为分区内作物j的有效灌溉面积,hm2;wij为作物j当月的灌溉净定额,m3/hm2;η表示分区灌溉水有效利用系数;δ为单位换算系数:1 × 10-8。
2 结果与分析
2.1 灌溉用水量推算精度评价
按式(3)计算得到2018年黄河流域各灌溉分区全年的逐月毛灌溉用水量,将同一月份灌溉用水量相加,得到流域逐月灌溉用水量,如图3 所示。全年1-12月的毛灌溉用水量分别为3.18 亿、1.52 亿、6.97 亿、22.80 亿、37.27 亿、46.91 亿、42.60 亿、35.48 亿、17.21 亿、4.54 亿、0.46 亿及1.34 亿m3,总计220.28 亿m3,实际灌溉用水量为226.98 亿m3。
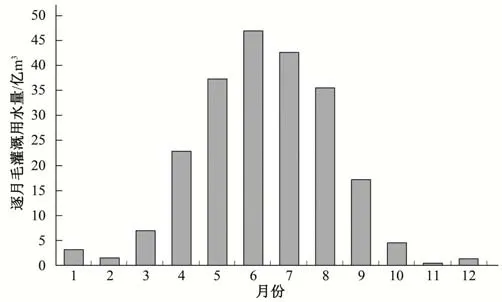
图3 流域逐月毛灌溉用水量Fig.3 Monthly irrigation water consumption of the basin
表2统计了不同省(区)的实际灌溉用水量与推算灌溉用水量的对比,由表可知,8 个省份中,宁夏回族自治区的灌水量仿真误差最大,为18.30%,陕西省的灌水量仿真误差最小,为2.25%,总体误差平均值为2.96%。结果说明本文所构建的模型仿真精度较好,可用于该流域的灌溉用水量推算。
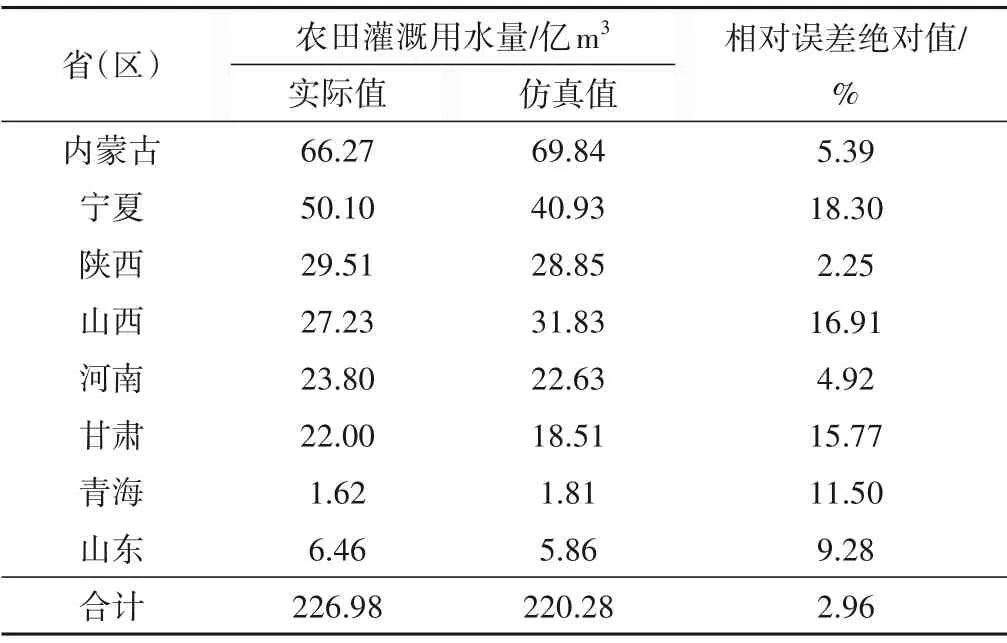
表2 灌溉用水量仿真值与实测值对比Tab.2 Comparison between simulated and measured irrigation water consumption
2.2 灌溉用水量年内变化分析
流域内各灌溉分区2018年的逐月毛灌溉用水量分布如图4 所示。可以发现各灌溉分区1月、2月、3月及10月、11月、12月的毛灌溉用水量未见明显差异,多数集中在0~0.1 亿m3。从4月开始,各灌溉分区的毛灌溉用水量开始显示差异,5-9月差异最为明显。各灌溉分区的毛灌溉用水量均呈现随着时间的变化,先增加后减小的趋势。不同灌溉分区各月毛灌溉用水量的均值,在6月达到峰值,为1.73 亿m3。
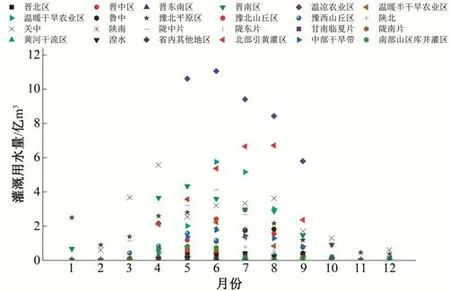
图4 不同灌溉分区逐月毛灌溉用水量Fig.4 Monthly gross irrigation water consumption in different irrigation zones
不同作物的总毛灌溉用水量如图5(a)所示,可以看出小麦和玉米的灌溉用水量最大,分别为58.04 和83.67 亿m3,占总灌溉用水量的26.35%和37.98%。其余作物灌溉用水总量从大到小分别为蔬菜>油料>薯类>水稻>大豆>棉花,分别占总灌溉用水量的9.83%、8.90%、7.92%、6.73%、2.08%及0.21%。
不同作物的逐月毛灌溉用水量变化图如图5(b)所示,随着生育期的变化,不同作物毛灌溉用水量均呈现先增加、后减少的趋势。其中小麦在5月达到灌水顶峰,为14.73 亿m3;薯类和蔬菜在6月达到灌水顶峰,分别为4.14 和4.32 亿m3;玉米和油料作物在7月达到灌水顶峰,分别为19.60 和6.74 亿m3;水稻和大豆在8月达到灌水顶峰,分别为5.47和1.55 亿m3;棉花在9月达到灌水顶峰,为0.16 亿m3。由前面作物种植结构分析可知,小麦和玉米是流域内分布最广、种植最多的作物,因此其灌溉需水量也最大,毛灌溉用水量也相应最多。

图5 不同作物生育期内毛灌水量对比图Fig.5 Comparison of gross irrigation amount in different crop growth periods
2.3 灌溉用水量空间分布规律
将推算得到的全流域各灌溉分区2018年的灌溉用水量数据导入ArcGIS,采用反距离加权插值方法,分别绘制流域全年总灌溉用水量和逐月灌溉用水量的空间分布图。
图6 为黄河流域2018年总灌溉用水量的空间分布图。各灌溉分区的年灌溉用水量介于0.13~47.55 亿m3之间。对于不同灌溉分区而言,灌水量空间分布的总体趋势为从西北部至中部、再到东西部逐渐递减。西北部灌溉用水量值较大,如内蒙古温暖干旱农业区、宁夏北部引黄灌区;位于中南部的陕西关中、中东部的山西晋南区灌溉用水量次之;东西部地区灌水量最小,如青海省内的灌溉分区及山东省的鲁中。从不同省(区)来看,内蒙古、宁夏、山西以及陕西的灌溉用水量较大,河南和甘肃灌溉用水量次之,山东及青海的灌溉用水量最小。

图6 黄河流域2018年总灌溉用水量分布图Fig.6 Distribution of total irrigation water consumption in the Yellow River Basin in 2018
图7 所示为2018年1-12月逐月各灌溉分区的灌溉用水量分布图。总的来看流域内灌水集中区随着时间的变化而不断迁移。1-2月份,流域灌水集中区域位于河南豫北平原区、豫北山丘区以及陕西关中区;3-4月份,灌水集中区为陕西关中区和陕西晋南区;5-9月份,灌水集中区迁移至内蒙古温暖干旱农业区、温凉农业区以及宁夏北部引黄灌区;10-12月份,流域灌水集中区再次迁移至陕西晋南区、陕西关中区和河南豫北平原区。从灌水量分布范围来看,可明显看出1-2月和10-12月份流域内灌水量较少,而该时间段内的主要作物只有冬小麦,由此可知冬小麦种植的主要区域位于陕西晋南区、陕西关中区和河南豫北山丘区,这与各省统计年鉴数据相符。

图7 黄河流域2018年逐月毛灌溉用水量空间分布图Fig.7 Spatial distribution of monthly gross irrigation water consumption in the Yellow River Basin in 2018
3 结 论
以黄河流域为例,借助Tensorflow 架构的BP 神经网络,对流域内月灌溉用水量进行推算,并运用ArcGIS 对黄河流域2018年逐月灌溉用水量的时空变异规律进行了分析。主要结论有:
(1)通过BPNN 预测的黄河流域灌溉用水量与实际值的总体误差平均值为2.96%,模型的验证精度在可接受的范围内。
(2)从种植结构来看,小麦和玉米的灌溉用水量最多,占总灌溉用水量的26.35%和37.98%。其余作物灌溉用水总量从大到小分别为蔬菜>油料>薯类>水稻>大豆>棉花。
(3)从时间上看,各灌溉分区的灌溉用水量均呈现随着时间的变化,先增加后减小的趋势。黄河流域2018年月灌溉用水量在6月达到用水峰值,从4月开始,各灌溉分区的毛灌溉用水量开始显示差异,5-9月差异最为明显。
(4)从空间上看,各灌溉分区的2018年灌溉用水量介于0.13~47.55 亿m3之间。灌水量空间分布的总体趋势为从西北部至中部、再到东西部逐渐递减。流域内灌水集中区随着时间的变化而不断迁移,迁移趋势为由河南、陕西和山西迁移至内蒙古、宁夏,最后再到陕西、山西和河南。
猜你喜欢
现代经济信息(2023年18期)2023-06-25 05:46:22
小学科学(学生版)(2021年5期)2021-07-22 02:40:02
阅读(低年级)(2020年11期)2020-12-28 02:26:35
今日农业(2020年20期)2020-12-15 15:53:19
今日农业(2020年23期)2020-12-15 03:48:26
今日农业(2020年14期)2020-12-14 19:47:34
收藏界(2019年2期)2019-10-12 08:26:10
人大建设(2019年12期)2019-05-21 02:55:42
小天使·三年级语数英综合(2016年4期)2016-11-19 08:41:24
TopGear汽车测试报告(2015年3期)2015-08-18 17:45:15
