
基于高可用性的分布式云化交易型系统设计方法研究
2022-05-23 10:23白海洋台运红
江苏通信 2022年2期
白海洋 台运红
1.中国电信股份有限公司江苏分公司;2.三江学院
0 引言
通信运营商IT系统上云是践行“数字中国”发展战略的重要举措。在去IOE(IBM小型机、Oracle数据库、EMC高端存储)的趋势背景下,云资源池硬件稳定性面临挑战。如何通过架构优化及云原生技术的应用来提升系统整体可用性,是IT系统上云需要重点解决的问题。
容灾备份是提升IT系统可用性的重要手段,随着郑州暴雨等灾情的发生,异地容灾再次成为人们关注的热点。IT系统上云为异地多中心的容灾环境建设创造了有利条件,如何在资源允许范围内建立起灾备系统,也成为云化改造需要关注的重点课题。
本文针对交易型系统上云改造提出“同城双活”高可用架构以及“两地三中心”容灾部署方案,可以有效提升系统的高可用性。
1 相关概念
1.1 交易型系统
“交易型系统”是“交易密集型系统”的简称,与之对应的是“计算密集型系统”。交易型系统是OLTP(Online Transaction Processing,联机事务处理)系统的一类,具有并发请求高、事务一致性要求高、服务可用性要求高等特点。在通信运营商领域,支付系统、充值系统、营业受理系统均可以归为此类。
1.2 系统高可用
IT系统的可用性是衡量其稳定服务能力的关键指标,具体标准一般包括:持续稳定服务时间、故障影响程度、故障恢复时间等。
高可用系统中需要考虑的设计原则一般包括:负载均衡、熔断降级、限流、流量调度、故障隔离、超时与重试、事务一致性与回滚、幂等校验等。考虑到高并发的场景,一般还需要考虑缓存、异步与并发、扩缩容等因素。
1.3 容灾系统关键指标
RTO(Recovery Time Objective):系统发生灾难性故障后的恢复时间。
RPO(Recovery Point Object):灾难发生后切换到灾备系统的数据损失量。
容灾半径:生产系统和容灾系统之间的地理距离。
ROI(Return of Investment):容灾系统的投入产出比。
2 “同城双活”高可用系统架构设计
2.1 系统架构总体描述
“同城双活”系统架构是指在同城机房中部署两套应用环境,同时对外提供服务。该架构设备资源利用率高、并发吞吐量大、数据一致性难度低,通过负载均衡、流量调度等策略可以起到一定的故障转移效果,在运营商系统上云改造中被广泛应用。
本文提出“同城双活”高可用设计方案,部署架构如图1所示。
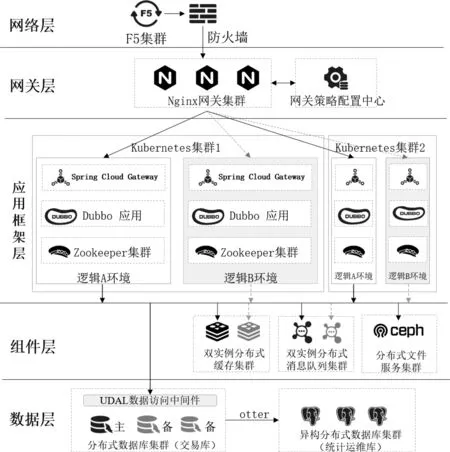
图1 “同城双活”高可用部署架构图
2.2 网关层流量调度算法及工具实现
2.1.1 多集群、多环境流量调度算法设计
(1)流量调度算法的形式化表述
本方法实现的流量调度算法支持对多集群、多环境的选择转发,算法描述如下。定义一个四元组,在单条流量的作用下,从变量承载方式M中,获取业务变量V,决定作用条件C,从而得到作用结果R,确定转发到的集群及环境。具体解释如下:
1)V是业务变量的集合,根据实际业务场景,通常可选用V = {area_code, app_id, service_id, staff_code}的集合。其中area_code为地区编码,app_id为接入应用编码,service_code为应用服务编码,staff_code为操作人员编码。
2)M是变量承载方式集合,表示从报文中获取到V的具体位置或方式。HTTP协议中,M={header,cookie,urlparam},其中header方式适用于API接口请求,特点是效率高、方便解析;cookie方式适用于界面请求,例如js、jss等静态资源请求;url_param是指链接中的参数,适用于链接跳转类请求。
3) C是作用条件的集合,本方法中,即IP地址和端口号;
4)R是作用结果集合,决定最终的转发方向,在本方法中,即集群和逻辑环境。
(2)基于Nginx的集群及环境切换原理
最终的转发结果R是由作用条件C决定的。C集合的IP决定了R集合的Cluster,指向集群的路由配置策略原理如图2。例如,当期望路由目标地址为集群1,可配置Nginx的IP转发策略到IP1。
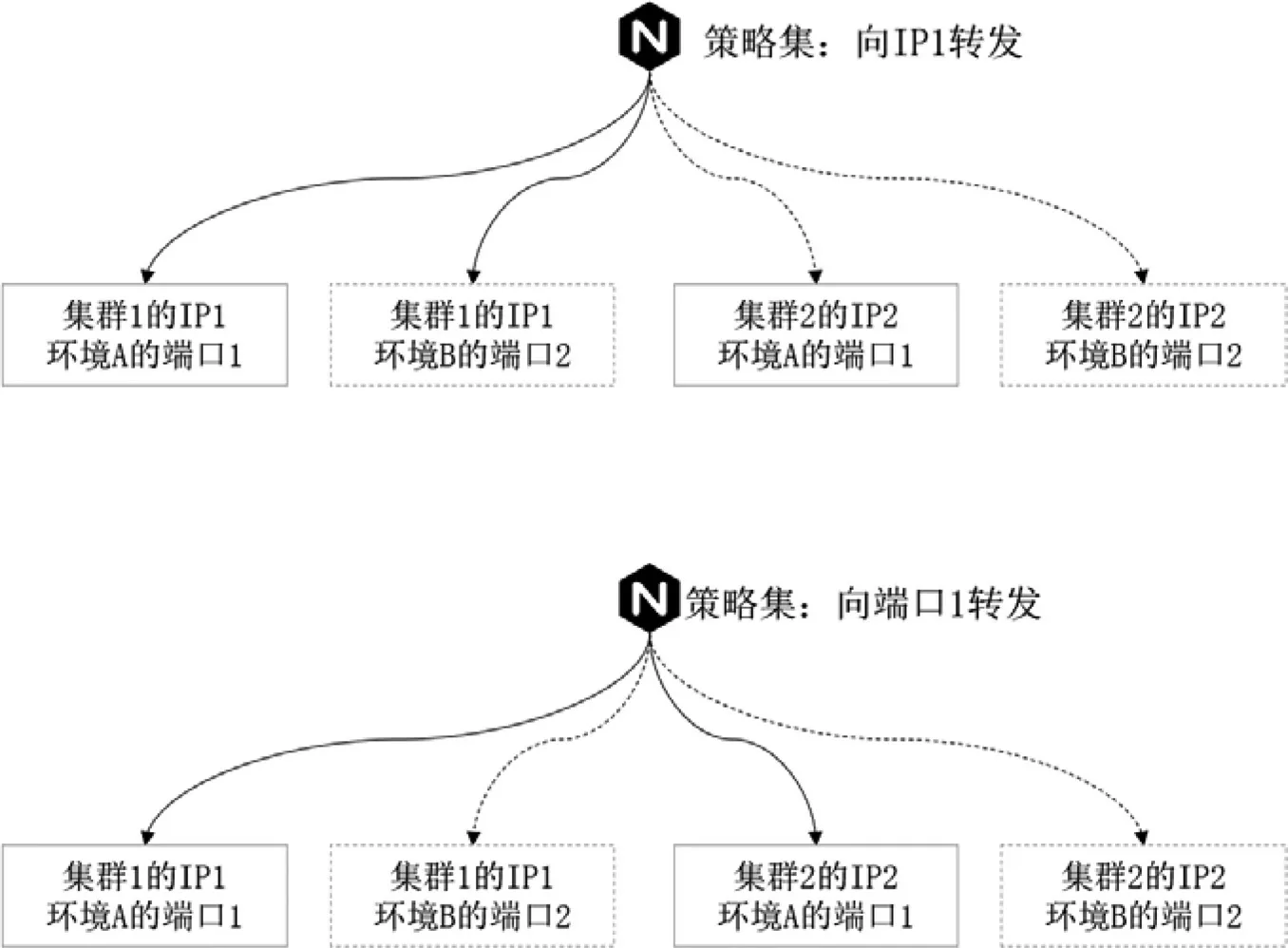
图2 Nginx节点选择集群及逻辑环境原理图
C集合中的Port决定了R集合的Env。例如,当期望目标的应用环境为A环境,可配置Nginx端口转发策略到端口1。
基于以上集群、逻辑环境的配置原理,通过IP与端口的配置组合,可以控制流量转发任一集群的逻辑环境,以实现双中心的容灾切换及版本灰度发布。
(3)根据业务需求的流量切换原理
当需要根据指定的业务逻辑进行流量转发时,可通过控制V集合的条件来实现。
例如,需要南京(区号025)、徐州(区号0516)的流量转发到环境B做灰度验证,需要将流量配置转发到端口2,其配置伪代码如下:

2.1.2 网关策略配置管理及同步工具设计
网关的策略在分布式配置中心Apollo中管理和持久化。为了实现各个Nginx节点配置的同步下发、同步生效,本文设计了配置同步变更工具,其方法和流程如图3所示,算法描述如下:
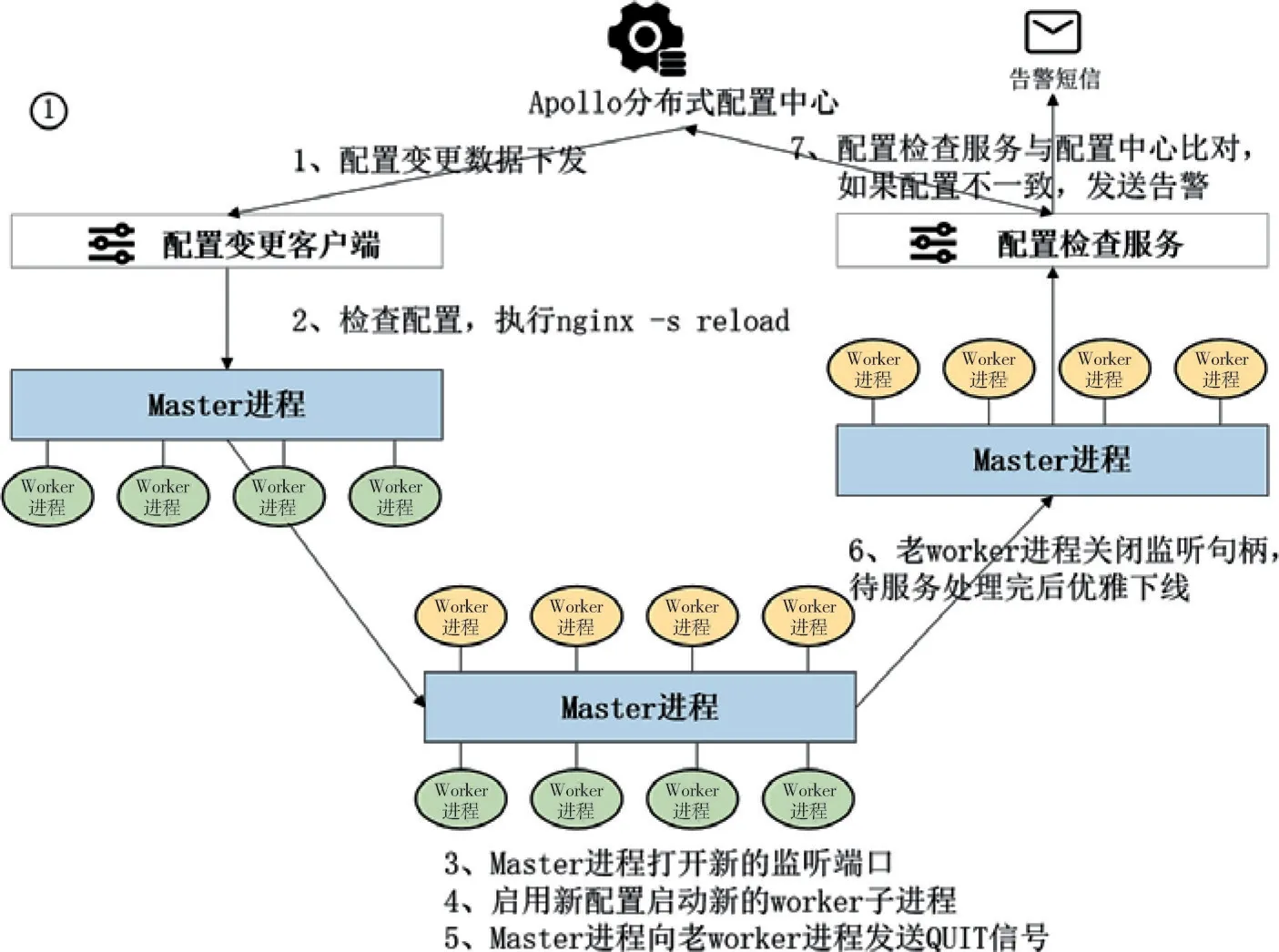
图3 Nginx集群配置同步变更工具执行流程图
步骤1:更改Apollo配置中心数据后,启动配置变更数据下发,由客户端程序接收;
步骤2:Nginx集群各个节点检查配置,执行nginx -s reload;
步骤3:Nginx主进程Master打开新的监听端口;
步骤4:Nginx主进程Master通过新配置启动新的worker子进程;
步骤5:Nginx主进程Master进程向老的worker进程发送QUIT信号;
步骤6:老worker进程关闭监听句柄,待服务处理完后优雅下线;
步骤7:配置检查服务与配置中心比对,如果配置不一致,发送告警。
基于该流程,可以实现路由策略的不停机无缝切换,切换前历史请求仍按原路返回,保证业务的持续性。
在应用过程中,应用系统应避免socket长连接的设计。长连接的引入将导致流量切换时难以快速生效,在Nginx reload过程中,由于老的worker进程不能及时释放,多次切换后还可能导致内存溢出故障。
2.3 应用框架层高可用设计
(1)服务健康检查及故障恢复机制设计
利用kubernetes(简称K8S)的就绪探针(readinessProbe)和存活探针(livenessProbe)实现服务启动和运行阶段的健康检查。就绪探针健康检查的工作原理如图4所示。
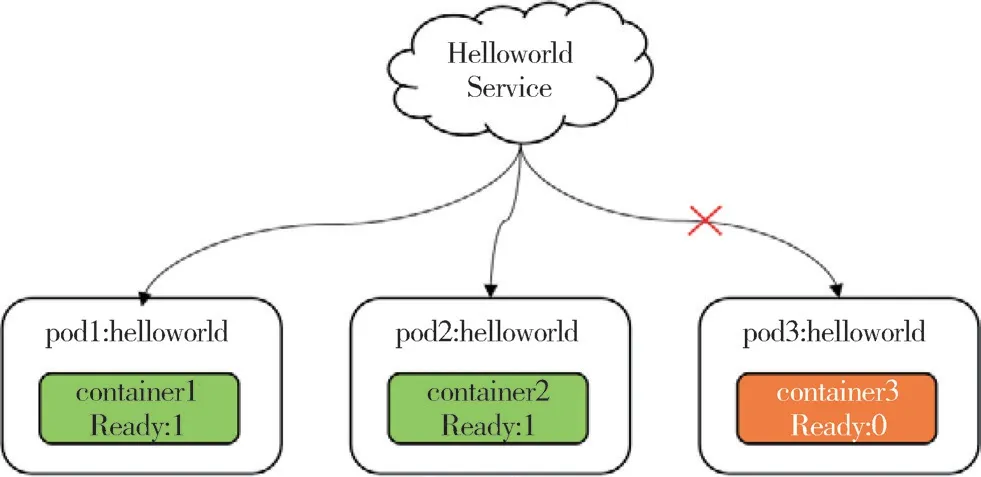
图4 K8S Service向Pod负载流量的健康检查机制
K8S中通过Service向外暴露服务,提供向内部各个Pod(K8S资源管理的最小单元)的负载均衡。Service通过Label Selector匹配当前就绪的Pod,还未就绪的Pod不会出现在Service的endpoints(目标节点),即流量不会向其转发。就绪探针在Pod的启动阶段根据配置策略开始探测服务是否可用,如果探测成功则容器进入ready状态。当一个Pod中的所有的容器进入ready状态后,该Pod的ready状态为true,此时可被Service发现并纳入流量转发节点。如果就绪探针探测失败,则流量不会向其转发。配合spec.restartPolicy重启策略的定义,可以自动实现启动失败pod的自动重启,直至正常启动进入ready状态后,才向外提供服务。
就绪探针的执行原理与存活探针类似,通过健康检查策略配合重启策略,可对异常Pod及时清理,从而实现运行期间的故障自动恢复。
需要注意的是,一旦容器发生不可恢复的异常,单纯依赖K8S的健康检查将无法彻底排除故障。例如,当应用连接的数据库异常导致容器在启动阶段或运行阶段异常退出,Pod重启后将始终不能进入ready状态。此时应当配合Pod重启的告警及时人为干预排障。
(2)应用网关的熔断降级、限流和重试机制设计
当遇到诸如秒杀购物、抢票等超高流量并发场景,系统承载能力已不能满足实际的并发量时,为了避免流量洪峰冲垮整个系统,同时为客户提供友好的报错信息,需要由应用网关来做熔断降级和限流。为避免由于网络传输导致的偶发性异常,可通过重试机制来提高服务可用性。
本方法的熔断降级机制采用令牌桶限流算法。该算法在限制调用平均速率的同时还允许一定程度的突发调用。
2.4 核心应用组件一键应急切换工具设计
为避免单机房组件整体故障的风险,核心应用组件分布式缓存、分布式消息队列在自身主备切换功能的基础上,本方法设计了备用组件一键应急切换的工具,原理如图5所示。
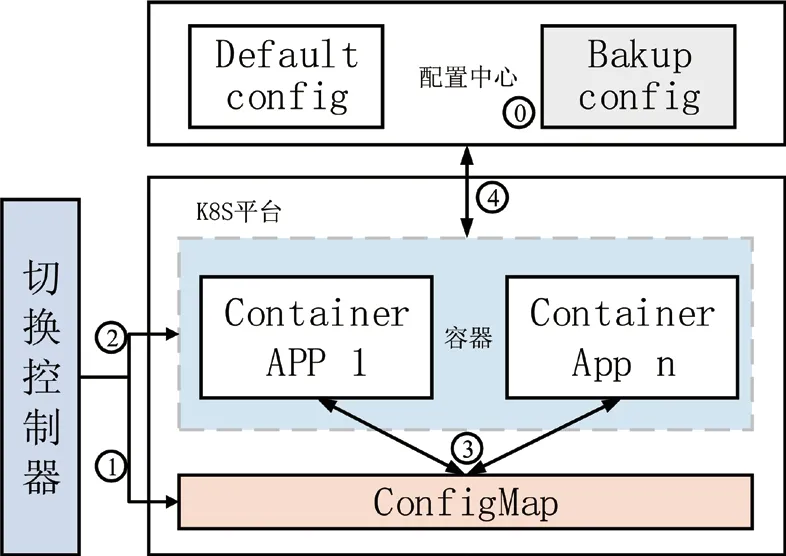
图5 备用组件一键应急切换工具执行流程图
其算法执行步骤:
步骤1:在配置中心中准备好备用组件的配置集;
步骤2:切换控制器发出切换配置指令到K8S的ConfigMap中,修改其环境变量为备用配置集;
步骤3:切换控制器向相关容器发出重启指令;
步骤4:容器重启时,读取ConfigMap中的环境变量,获取备用配置集的信息;
步骤5:从配置中心读取备用组件的配置集,完成重启。
备用组件保持可用状态的关键:
(1)缓存组件:在做缓存配置变更时,应同时向备用缓存中上载配置。
(2)消息队列组件:在建立Topic、消费组时,应保持备用环境与生产环境的一致。
通过以上策略,组件应急切换可以在生产环境默认组件全阻的情况下,实现向备用应急组件的快速切换,降低故障恢复时间。
3 “两地三中心”容灾架构设计
在“同城双活”部署的基础上,扩展异地容灾热备部署,其架构设计如图6所示。综合考虑故障恢复时间RTO、故障期间数据损失率RPO、投出产出比ROI三个指标,其部署特点如下:
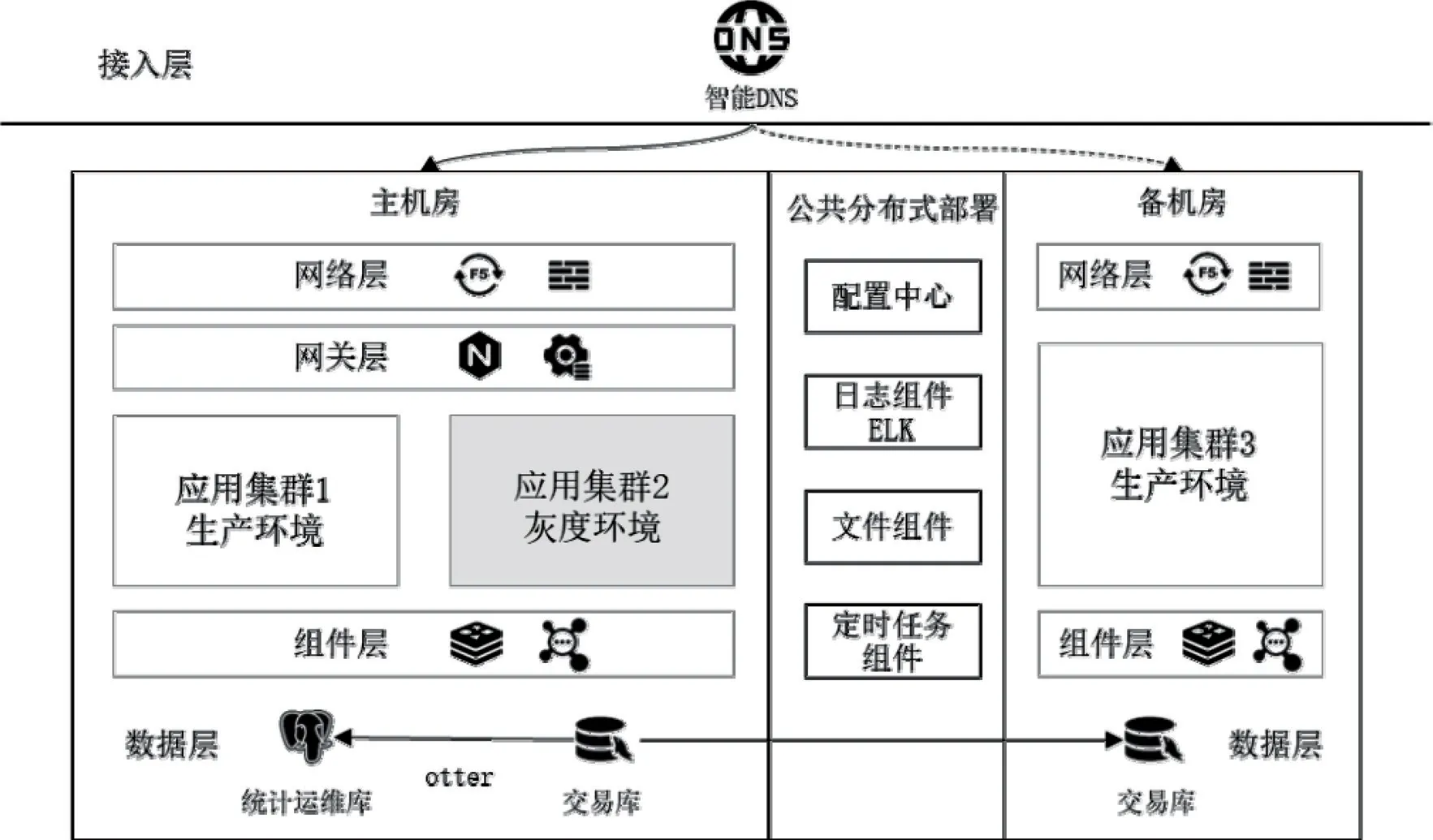
图6 两地三中心容灾部署架构
(1)机房流量调度:通过智能DNS实现向容灾环境的流量调度。
(2)备机房的部署:备机房采用单集群部署模式,保持当前生产环境的软件版本。
(3)公共组件分布式部署:对实时性要求不高、读写频率较小的组件,可采用分布式部署方式,保持数据一致,其中备机房的节点数可采用最小化设置。推荐公共部署的组件有:配置中心、日志中心、分布式文件系统、定时任务组件等。
(4)数据库同步及一致性保证:从主机房交易库通过otter工具向备机房交易库同步数据。备机房根据资源条件及业务需要决定是否设置运维库。
4 方法实现
该高可用性系统设计方法已在“江苏电信新一代支付中心”系统上应用实现,支付中心的可用性和容灾性得到显著提升。为了验证其高可用的设计效果,通过破坏性测试、压力测试等手段,得到测试结论如表1所示。

表1 江苏电信新一代支付中心高可用系统测试案例
为了验证系统持续服务能力,测试期间通过LoadRunner工具对服务进行压力测试,得到测试接口的吞吐量及报错情况。“容器故障恢复”场景测试中,在第4分钟模拟单个容器服务故障,正常触发了容器健康检查和故障恢复。由于故障恢复期间(10s左右)可用节点数降低,接口并发量稍有下降,待容器重启完成重新加入服务列表后,并发量恢复正常。
5 结束语
为提升分布式云化交易型系统的可用性,降低系统故障概率,缩短故障恢复时间,提升系统容灾性,本文设计了“同城双活”和“两地三中心两套高可用系统部署架构,分架构、分层级阐述了高可用系统设计方法。实际应用中可根据业务容灾等级做架构的选型。
本文创新提出基于Nginx的多集群、多环境流量调度原理,并提出网关配置同步变更工具的设计方法;创新提出备用组件一键应急切换工具的设计方法;创新提出了异地容灾环境建设的总体方案。
该方法已在“江苏电信新一代支付中心”系统上应用实现,通过破坏性、压力测试验证了设计方法的有效性,并在实际生产中验证了系统的高可用性。
猜你喜欢
能源工程(2022年2期)2022-05-23
商用汽车(2021年4期)2021-10-13
无线互联科技(2020年10期)2020-08-14
军事运筹与系统工程(2019年4期)2019-09-11
中国交通信息化(2019年12期)2019-08-13
信息化建设(2019年2期)2019-03-27
电子制作(2018年11期)2018-08-04
电子制作(2017年10期)2017-04-18
知识就是力量(2017年2期)2017-01-21
中国市场(2016年45期)2016-05-17
