
基于特征编码和图嵌入的姓名消歧方法*
2022-05-23 14:29马莹莹吴幼龙唐华
中国科学院大学学报 2022年3期
马莹莹,吴幼龙,唐华,2,3
(1 上海科技大学信息科学与技术学院, 上海 201210; 2 中国科学院上海微系统与信息技术研究所, 上海 200050; 3 中国科学院大学, 北京 100049) (2020年2月17日收稿; 2020年4月3日收修改稿)
近年来,随着数据信息化程度不断上升,网络数据库容量不断增加,如何在数据库中迅速地搜寻到准确的信息成为亟需解决的问题。由于自然语言具有多义性、复杂性和模糊性的多重特点,因此需要将文本中提到的实体与其知识库中的实体连接起来。实体链接主要是要解决实体间的歧义问题,在网络检索、信息提取和知识库填充等问题中有着广泛的应用。实体语义表达的模糊性和数据容量的日益增加,给实体歧义辨别带来很大的挑战。
实体歧义分为2种:一种是多词同义,指多个词语代表同一个意思;另一种是一词多义,是指一个实体名称可以指代多个不同的实体。作者姓名消歧是实体消歧中的一个重要应用,已知同名作者的所有文章集合,需要通过文章的一些属性特征对文章进行聚类,使每一个聚类仅包含一个作者的文章。作者姓名消歧任务在作者文献检索、学术画像分析中有着重要的价值。例如,在学术检索时,研究者需要在文献数据库中寻找名为“Charles”的学者的文献,但是由于“Charles”在数据库中对应着很多不同的实体,系统返回了所有名为“Charles”的作者撰写的文献,这会大大降低文献检索结果的有效性和准确性,从而降低网络搜索的性能。如果将搜索结果分组在一起,则搜索的有效性可以大大提高。另外,当计算学者影响力的时候,需要准确了解每一位学者的文章类型及数目。因此,作者姓名消歧问题是近年来研究者的研究热点之一。
目前,已经有一些文献研究作者姓名消歧问题。一些学者将作者姓名消歧视为分类任务,预测每篇论文的正确标签或预测2篇文章是否由同一作者撰写。分类任务需要大量标签,所以这类任务通常是有监督的。
例如,Wang等[1]提出基于增强树的分类方法,通过文档的标题、作者、机构、摘要等属性判断2篇文章是否由同一作者撰写。深度神经网络模型[2]也被用于提取文档属性特征进行分类。其他一些方法利用了外部数据。如Han等[3]提出朴素贝叶斯概率生成模型和支持向量机模型并将这2种方法分别应用于从Web收集的数据和DBLP数据库。
另外一些工作采用无监督的聚类方法。无监督的姓名消歧任务是将文献分为几个簇,使得每个簇仅包括由一个作者所撰写的文献。
Cen等[4]通过优化线性回归模型对成对文章相似性进行建模,提出一种具有自适应停止准则的层次聚类方法。基于Dempster-Shafer理论(DST)的分层聚类方法[5]将每个文档嵌入到低维向量空间中进行聚类,通过定义2个文档各个特征之间的相似度来计算它们文档之间的相似度,将相似度大于阈值的文档划分到同一个簇中。另外一些学者利用概率模型表示文档之间的相似性[6-8]。
监督方法需要大量的标记数据,而人工标记需要昂贵的人力和财力。但是对于无监督算法,要找到最佳数目的聚类或者合适的相似性阈值具有一定的挑战性。因此也有许多学者提出半监督算法。
Levin等[9]提出一种结合分类和聚类方法的2阶段算法。在第1阶段,他们应用基于论文引用及其他的高精度规则自动生成用于有监督训练的标记数据。在第2阶段,将正例和负例用作有监督的分类器,该分类器用于预测2篇文章是否由同一作者撰写,最后将分类器的预测结果用作聚类中的相似性度量。Louppe等[10]在此基础上提出用于预处理的区域策略,将很有可能属于同一作者的文献放置于同一区域。
随着近2年图网络研究的兴起,由于作者及其刊物可以自然地构建作者-作者网络和文档-文档网络,因此一些基于图的方法也被用于姓名消歧任务。谱聚类[11]可以将图划分为几个部分从而进行聚类。Zhang等[12]提出结合全局度量学习和局部链接图模型,通过文档的属性特征学习文档的低维表征。Zhang和Hasan[13]将文章信息预处理为3个图网络:作者-作者图,文档-文档图和作者-文档图,并将文档数据投影到低维空间中。GHOST模型[14]利用作者图来计算图节点对之间的相似度。除此之外,还有基于文章对的图网络(ADANA)[15]和基于标题与共同作者的图网络(GFAD)[16]。
当前研究方法存在一些问题:1)监督方法因为使用了标注信息,所以消歧性能一般会好于无监督方法。但是由于数据集规模通常较大,人工标注所有的标签会耗费大量的人力和时间。2)现有的大多数研究方法通常只基于文献的属性特征或者基于文献关系、作者关系的研究。利用文献属性特征的方法通常采用大量的属性特征并制定相应的规则,在数据有缺失的时候会导致规则失效。基于关系图的研究往往忽略文档的基础属性特征,降低了消歧的效果。3)目前作者姓名消歧问题中大多数研究方法都是应用于小规模数据集,通常只包含10~20个作者文献集,本研究希望将研究方法应用于更大规模的数据集。
本文针对更大规模的数据集(100个待消歧作者姓名),提出一种基于文献属性特征和关系图网络的姓名消歧方法(如图1所示)。该方法同时考虑文档的属性特征以及多个关系网络的信息,通过无监督学习的方法寻找文档表征向量,使用簇数标签进行层次聚类,取得良好的姓名消歧效果。在作者数据集AMiner上的测试结果表明:该方法优于使用大量文档标签和簇数的半监督方法[12],也优于其他基于图网络的方法[13-14]。另外,本文通过可视化的方式增加了模型的可解释性。

图1 基于特征编码和图网络的姓名消歧方法Fig.1 Name disambiguation on encoding attributes and graph topology
1 问题形式化定义
在姓名消歧任务中,i代表一个作者姓名。消歧任务就是找到合适的函数将与这个姓名相关的文档划分到不同的类别中,使得每个类别中仅包含同一作者的文档。给定一个文档集合i,任务是将文档划分为K个不相交的簇其中,表示第k个作者。对于不同待消歧的作者姓名,这里K是不同的。用函数表示为
Φ(i)→i.
(1)
2 基于特征编码和图嵌入的姓名消歧
2.1 文档向量表征
Word2vec模型被广泛用于单词表示学习中。本文利用word2vec的模型之一CBOW[17]用于学习文档的向量表示。
假设有一系列训练词w1,w2,…,wT,CBOW模型通过某单词周围其他单词的出现频率预测这个单词的出现频率。该模型根据训练语料库中预定义上下文窗口内词的出现频率来学习单词向量。目标是最大化出现在预定义上下文窗口中的单词的共现概率,概率函数表示为
(2)
其中c代表预定义窗口大小。

(3)
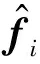
2.2 变分图自动编码器
对于每一个待消歧的作者姓名i,表示其对应的待消歧的文献集合。首先构建i对应的文档图网络=(,ε),文档d∈可以表示网络节点,利用2.1节中的文档向量表征构建,ε用于表示节点之间是否存在边,本文用邻接矩阵A表示。


(4)
其中

图2 变分图自动编码器Fig.2 Variational graph auto-encoder

(5)
μ=[μ1,μ2,…]=GCNμ(X,A)是图卷积网络输出各个向量的平均值构成的矩阵,σ=[logσ1,logσ2,…]=GCNσ(X,A)代表标准差矩阵。2层卷积神经网络可以表示为
(6)

(7)
其中
(8)


KL[q(Z|X,A)‖p(Z)].
(9)
2.3 图网络嵌入
如果仅利用图自动编码器,在引入节点关系的时候只考虑到文档特征之间的相关性。当出现表1所示情况时,无法判断文档1和文档2是否由同一作者所撰写。引入文档3和前2个文档之间的关系后,因为2篇文章的所有合作者都是文档3的作者,所以可以判断出2篇文章属于同一作者。
本文研究希望通过利用合作者关系进一步推断文档相似性,并将合作者关系网络信息嵌入文档表征向量Z中。提取网络结构信息的方法有Deepwalk[18]、GCN[19]等。本文通过构建作者-作者网络、文档-作者网络和文档-文档网络,聚集有关系的作者和文档向量。

表1 合作者相关联的文档Table 1 Related documents refer to one-hop co-author

(10)
p(
(11)
对于文档-文档网络,希望这个概率更大,所以需要最大化这个概率
(12)
类似地,对于作者-作者网络和作者-文档网络:
(13)
(14)
目标是将3个网络的拓扑结构信息嵌入文档表征向量中,优化函数为
(15)
其中:A为合作者构成的矩阵,Z代表微调后的待消歧文档矩阵。通过训练图嵌入模型,文档表征向量中包含了文献属性特征及3个图网络的拓扑信息。
2.4 聚类
对图网络嵌入模型训练后的文档表征向量应用层次聚类算法[20]。该算法将训练样本中的每一个数据点都当作一个簇,然后计算每2个样本点之间的距离并合并距离最近的簇,直到满足终止条件。本文将终止条件设置为簇个数等于真实聚类个数。
3 仿真实验
3.1 仿真设置
本文使用在线学术搜索和数据挖掘系统AMiner[21]上采样的100个作者姓名数据集,每个姓名都对应着与这个姓名相关联的文档,采样数据集共包含27 128篇文献和1 066个真实作者。
超参数设置上,CBOW模型中,文档表征向量维度设置为100,预定义上下文窗口为5。变分图自编码器中,逆文档频率的阈值为25,第1层图卷积网络输出维数为200,第2层图卷积网络输出维度设置为100,学习率为0.01,迭代200次。图网络嵌入模型中,学习率为0.05,正则化参数为0.01。
3.2 性能比较
在仿真实验中,对比本文方法与其他几个基于图网络的姓名消歧方法。Zhang等[12]提出一种合并全局表示学习和局部嵌入学习的方法(Aminer)。在全局表示学习中,需要引入标签信息构建正负样本。在局部嵌入学习方法中使用图自动编码器。Zhang和Hasan[13]将作者-作者、作者-文档、文档-文档网络信息压缩至低维空间。GHOST模型[14]只考虑作者合著关系,在每个合作者间建立网络,通过选择有效路径计算作者节点之间的相关性划分作者聚类。并查集方法通过合作者和隶属机构的严格匹配在文档间建立图连接,将所有有连接关系的文档节点构成一个集群。
本文使用pairwise Precision、Recall和F1值[22]对模型进行性能比较。对100个消歧作者数据集计算每个指标的平均值。表2显示不同的消歧方法在AMiner数据集上的仿真结果。可以看到,本文提出的方法在表中15个姓名中有11个都表现最佳,平均F1值比Aminer 算法[12]提高3.87%,比Zhang和Hasan[13]的算法高25%,比GHOST模型[14]高33.85%。
图3是一个待消歧文档数据集通过本文方法与Aminer学习后的文档表征向量的2维空间可视化,图3(a)、3(b)中不同的颜色表示不同的真实集群。图3(c)、3(d)为预测集群分布。在此数据集上,本文提出的方法的F1值为0.633 8,Aminer方法仅为0.538 2。从图3(d) 虚线内的样本可以看出,Aminer方法学习后的文档表征向量在向量空间中距离较远,样本并没有被正确归类。而本文提出的方法通过将相似的表征向量聚集在一起,如图3(a)的橙色散点表示,输出的文档表征向量更加接近,图3(c)中并没有将这些散点划分错误,从而实现了更好的聚类效果。

表2 几种基于图网络的姓名消歧方法的聚类结果Table 2 Clustering results of different graph-based name disambiguation methods

图3 不同姓名消歧方法聚类结果的可视化Fig.3 Visualization of clustering results of different name disambiguation methods
从表2中可以看到对于其中的4个姓名Aminer方法更好,为进一步分析其中的原因,本文选取作者姓名为“Rong Yu”的文档集合并对本文方法与Aminer模型的聚类结果进行比较。
图4为在这个文档数据集上2种方法聚类结果的可视化对比。从图4(b)中的蓝色散点可以看出,通过Aminer方法学习文档向量表征后,属于这个作者的文档向量主要集中在2个区域,而本文的方法将更多的点集中到左侧椭圆虚线框内,如图4(a)所示,这意味着本文方法将更多的文档划分到了正确的类中。但是因为本文方法将很多文档向量从右侧虚线框内移出,导致其余的文档向量在向量空间中太过分散,从图4(c)中可以看出,这些文档向量被划分为3个不同的类。在图4(d)中,这些文档向量虽然也被划分到另一个类别中,但是根据聚类方法中pairwiseF1值的计算方法可知,这些文档向量组成的两两文档对在预测集和真实集中仍然都属于同一个类别,仍算作True-Positive文档对。因此在作者姓名为“Rong Yu”的文档数据集上,Aminer的F1值高于本文提出的方法。
图5为使用word2vec构建文档向量表征后直接对该文档集合中的文档向量进行聚类的结果可视化。从蓝色散点可以看出,进行文档向量表征后属于同一作者的文档向量就被划分到了向量空间中不相连的2个区域中,从文档属性特征分析,代表这个作者的文章有2个强属性特征,他的大部分文章都与其中一个属性相关,例如他可能有2个不同的研究方向,这2部分文章的特征词并不相关,所以在特征编码后与他相关的文档向量分布在2个区域。而本文方法在引入关系信息后使得模型能够区分出其中一部分文档。但是由于并不能覆盖到所有的文档,在属性特征关系弱的数据集中,文档向量分布较为分散,本文的方法会导致一部分文章被划分到多个不同的类别中,而Aminer方法虽然也没有将这些文档划分到正确的类别中,但是保留了它们彼此之间的联系,使得这些文档被划分为同一个类别,所以本文方法的聚类结果的F1值相对较低。

图4 Rong Yu文档集合上的聚类结果对比Fig.4 Comparison of clustering results on the document set of Rong Yu

图5 文档向量表征后的聚类结果Fig.5 Clustering results after document representation
3.3 组件性能分析
为了展示本文方法中文档向量表征、变分图自编码器、图嵌入模型各自的作用与聚类效果,本节将每个组件分开评估。图自动编码器和图网络嵌入模型建立于构建了文档向量表征之后。如表3所示,图自编码器和图网络嵌入分别将模型的F1值提高了0.064 1和0.048 3。而本文提出的综合方法取得了最高的准确率和召回率。图6为每个子模型训练后学习的文档向量的低维可视化,这里使用真实标签在文档表征空间的分布,不同颜色代表不同作者所撰写的文档向量。由图6可以看出,图自编码器将绿色点和蓝色点聚集在了一起,而图网络嵌入使这些点更加接近使得模型可以更准确地聚类。同时,图网络嵌入模型将离群的黄色点移动到了正确的区域,所以本文的模型对异常值有一定效果。
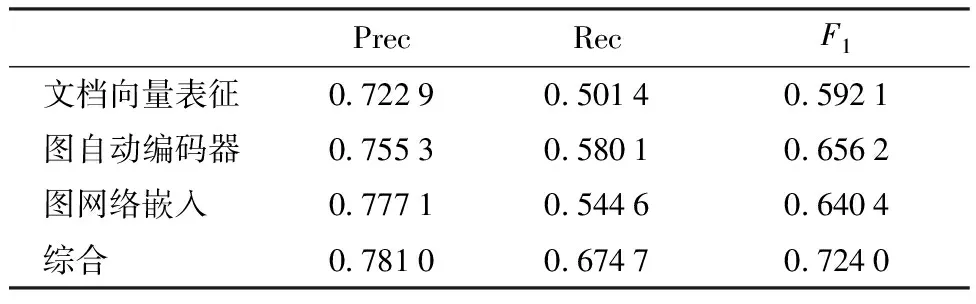
表3 组件性能分析Table 3 Clustering results of each component
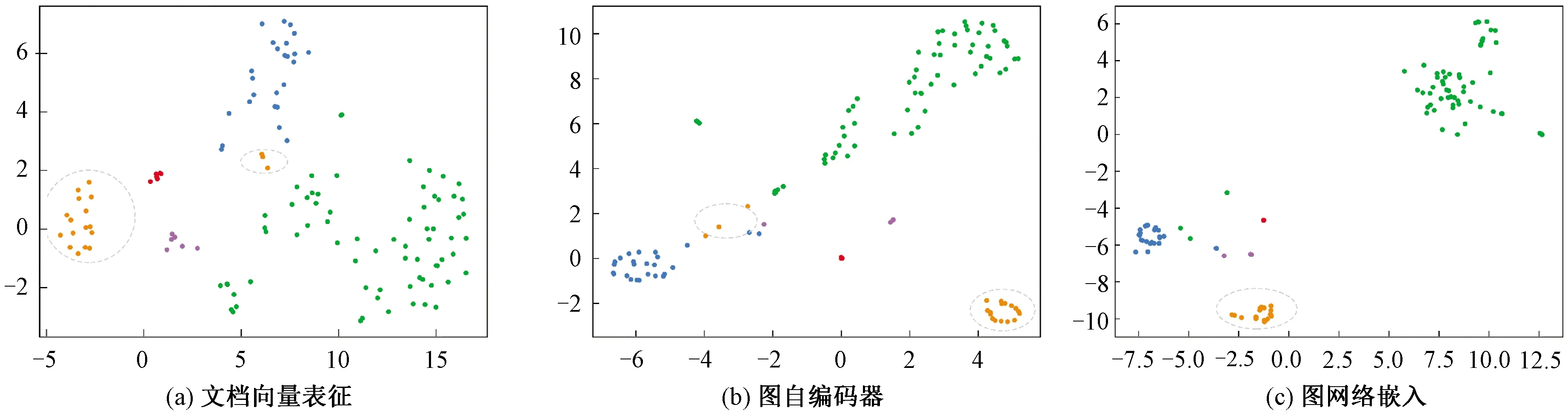
图6 各组件聚类结果可视化Fig.6 Visualization of clustering results of each component
4 结论
本文基于图网络提出一种新的作者姓名消歧方法,该方法通过文档表征、图自动编码器和图嵌入模型来编码所有论文的属性特征和作者及论文的关系图拓扑结构。采样于数据挖掘系统AMiner的数据集被用于验证本文提出的图网络姓名消歧方法,仿真结果证明本文提出的模型优于目前其他几种基于图网络的姓名消歧方法。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
客联(2022年3期)2022-05-31
汽车实用技术(2022年4期)2022-03-07
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
电脑爱好者(2017年7期)2017-05-06
漫画月刊·哈版(2015年3期)2015-05-28
小天使·一年级语数英综合(2015年2期)2015-01-14
小天使·三年级语数英综合(2014年9期)2014-09-12
