
基于改进蚁群算法的社交网络好友推荐算法
2022-05-20 08:09高良诚
滁州学院学报 2022年2期
高良诚
随着互联网技术的飞速发展,与现实社会相比,社交网络以其时空方面的优越性,在人们的工作和生活中发挥着越来越重要的作用。社交网络用户众多,数据庞大,高效地让用户找到可能成为好友的其他用户显得十分重要,但用户普遍对周边信息缺乏有效过滤,在好友推荐方面存在信息投送不精准和信息利用率低等问题,如何设计出高效的好友推荐算法已成为当前重要研究课题[1-2]。
经典的好友推荐算法主要有基于用户属性特征相似度和基于用户间的拓扑结构两种,但存在推荐结果不准确或推荐范围过窄等问题。链路预测算法在好友推荐算法中得到广泛应用[3-4],其基本思想是将社交网络中的用户作为网络中的节点,利用好友属性,计算节点之间的相似度,据此形成新链路来进行好友推荐,但在链路预测时,只考虑单一的网络结构,导致推荐准确度不高。目前好友推荐算法普遍综合多元化的用户属性,如用户基本信息、社交关系、地理位置等,解决推荐精度低、信息过载等问题[5-9]。文献[10]利用聚类算法对用户进行聚类,通过根节点到叶节点的加权求和进行推荐,文献[11]提出了一种基于图聚类与蚁群算法的社交网络聚类算法,有效地缓解稀疏性问题与冷启动问题,但均未充分考虑用户位置信息。本文提出一种社交网络中基于用户属性和改进蚁群算法的好友推荐算法(Friend recommendation algorithm based on user attributes and ant colony optimization algorithm,UA-ACO),综合考虑用户基本信息、社交关系、地理位置等用户属性和交互信息,计算用户相似度,将其作为链路预测的依据,并通过改进蚁群算法搜索好友用户,增加好友推荐算法的精准度。
1 系统模型及问题描述
本文设计了基于用户属性与用户交互的相似性二维图模型,综合考虑用户属性和用户交互,计算用户间的相似度来进行链路预测,建立用户之间连接。系统模型用G=(V,E,W)表示,其中V(G)={v1,v2,…vn}表示网络节点集合,对应为社交网络的用户;E(G)={e1,e2,…,en}表示网络中边的集合;W(G)={w1,w2,…,wn},对应边的权值,对于任意一个边e∈E(G),对应用户相似性值。
根据用户属性和交互信息计算各个用户与目标用户之间的相似性值,基于用户属性和交互信息的相似性计算公式为:
(1)
其中:Au,v为用户u和v间的用户属性关系值,计算式为
(2)
其中:GF为用户u和v共同好友数,PR为用户u和v共同居住地数,w1和w2为比例系数,Du,v为用户u和v之间的距离,Davg为用户间平均距离。根据用户对评分项目的评论信息计算各个用户与目标用户之间的相似性值,基于皮尔逊相关系数(Pearson correlation coefficient, PCC)的相似性计算公式为:
simu,v=
(3)

2 基于Q学习和蚁群算法的好友推荐算法
2.1 Q-Learning算法
Q-Learning是一种强化学习算法[12],通过与环境交互,构建(状态,行动)函数值,根据函数值选择下一动作。在状态s下,赋予动作a奖励和惩罚信息,进而能够选择最优动作。用Q(s,a)表示动作a获得收益的期望,在时刻t根据状态s选择动作a,并获得报酬rt,Q值计算公式如下:
Qt+1(s,a)=(1-δ)Qt(s,a)+δ(rt+1+γmaxQ(st+1,a))
(4)
其中,δ为学习因子,δ∈(0,1),γ为折扣因子,γ∈(0,1)。
通过公式(4)看出,Q-Learning算法的Q值可以作为蚁群算法中的信息素,从而加快蚁群算法初期的收敛速度。
2.2 改进蚁群算法
蚁群算法模拟蚂蚁群体觅食过程,在解决离散优化问题方面,具有收敛速度快和求解精度高等特点[13]。其核心思想是在一个加权图中,蚂蚁释放信息素,根据路径转移概率选择下一节点,并通过信息素更新驱动蚂蚁选择最优路径,实现蚂蚁间信息交换,最终在图中找出最优路径。
2.2.1 路径转移概率
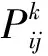
(5)
其中:μj为节点j的信息素浓度,初始值为Q学习算法的Q值;α为路径上信息素影响因子;ηij为路径选择函数,ηij=simi,j;β为路径选择影响因子;Tabuk存放蚂蚁k目前访问过的节点。
2.2.2 信息素更新
当蚂蚁经过某节点时,需要更新该节点上的信息素。节点上路过蚂蚁数量越多,信息素浓度越大,该节点被选择为下一节点的概率越大。
μj为节点j的信息素浓度,信息素更新规则如下:
(6)
其中,δ为信息素挥发因子,γ为折扣因子,Δμj为信息素的增量,由式(7)计算。
(7)
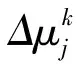
(8)
其中:Q为Q-Learning算法生成的初始信息素,Cost(i,j)为蚂蚁k从节点i到当前节点j的费用函数,由式(9)计算。
(9)
其中:tu为目标用户,hosps(tu,j)为图中从目标用户节点到用户j对应节点的路径长度。
式(8)表明,蚂蚁到节点j所经过路径费用越小,则节点j的信息素增量越大,蚂蚁选择节点j的概率越大,因此,费用低的路径被选择的概率变大。
每次迭代结束后,更新所有节点的信息素,公式如下:
μj′=(1-ρ)μj
(10)
其中:ρ为信息系挥发因子。
2.2.3 信息素扩散

2.3 UA-ACO算法实现步骤
初始阶段,每个节点的信息素为Q-Learning算法的Q值,蚂蚁随机地分布在图中节点上。蚂蚁根据路径转移概率选择下一节点,并进行信息素更新和扩散。重复迭代,直到符合结束条件。将节点按信息素降序排列,选择信息素高的节点。
算法步骤如下:
1.使用公式(1)计算用户之间的相似性。
2.初始化并精简网络。根据给定相似度阈值,删除不满足要求的用户和独立节点集。
3.将蚁群算法的初始信息素设置为Q-Learning算法迭代产生的Q值。
4.初始化蚁群算法的迭代次数NC。
5.将源节点放到蚂蚁禁忌表tabu中,将k只蚂蚁随机放置到图中节点上。
6.蚂蚁根据公式(5)计算路径转移概率,选择概率值大的邻居节点作为下一节点。
7.按公式(6)对蚂蚁选择的节点进行信息素更新,并将该节点放到禁忌表tabu中。
8.重复步骤6 和步骤7 直到路径长度超过5。
9.按照公式(10)全局更新信息素。
10.按2.2.3方法进行信息素扩散。
11.重复步骤5~步骤10直到迭代次数超过NC,将节点信息素降序排列,选择信息素浓度高的节点。
3 实验与结果分析
本文采用人人网作为数据来源,实验环境为PC机,PC机的配置为8GB内存,i7 8550处理器,使用Matlab进行仿真。设置参数w1=0.8,w2=0.9,δ=0.8,γ=1.1,α=1,β=1.2,θ=0.1,信息系挥发因子ρ=0.2,蚂蚁数量150,迭代次数NC为100。
准确率、召回率以及F1-measure 是好友推荐算法的重要指标。准确率是指推荐好友为真实好友数量与推荐好友数量的比例,召回率是推荐的真实好友数量与数据集中实际好友数量的比例,F1-measure是综合衡量指标。本文对UA-ACO算法、基于用户的协同过滤算法(User-CF)[14]以及基于近邻的协同过滤算法(NBCF)[15],在准确率、召回率以及 F1-measure指标方面进行比较与分析。
准确率的计算公式如下:
(11)
召回率的计算公式如下:
(12)
F1-measure的计算公式如下:
(13)
图1为不同算法的准确率对比。由图1可见,随着推荐好友数的增加,几种算法的准确率均出现下降,但UA-ACO融合Q-Learning和改进蚁群算法,加快了算法收敛速度,算法能更快地实现较高的准确率,且准确率下降幅度较小。

图1 不同算法的准确率对比
图2为不同算法的召回率对比。由图2可见,随着推荐好友数的增加,几种算法召回率均增大,UA-ACO采用改进蚁群算法,把Q-Learning算法的Q值作为蚁群算法的初始信息素,算法收敛速度快,召回率增加更明显。

图2 不同算法的召回率对比
图3为不同算法的F1-measure对比。由图3可见,本文算法的F1-measure值指标较好。

图3 不同算法的F1-measure值对比
4 结语
文章提出了一种基于改进蚁群算法的社交网络好友推荐算法,综合考虑用户基本信息、社交关系、地理位置等用户属性,结合用户交互关系,计算用户间的相似度进行链路预测,建立社交网络二维图,设定相似度阈值,去除不符合要求的用户节点,减小好友推荐算法时间代价,在此基础上,采用改进蚁群算法,相似性值高的用户被推荐的可能性增大。仿真实验表明,该算法准确率和召回率性能较好。下一步将充分研究用户对地理位置敏感的好友推荐需求。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
小雪花·初中高分作文(2019年10期)2019-02-12
中国交通信息化(2018年5期)2018-08-21
杂文月刊(2017年20期)2017-11-13
少儿科学周刊·儿童版(2017年5期)2017-06-29
学苑创造·A版(2017年3期)2017-04-27
学苑创造·A版(2014年6期)2014-08-04
小雪花·成长指南(2009年10期)2009-12-04
