
机器学习预测叶片-网孔管线式高剪切混合器性能
2022-05-17 08:35王灵杰郭俊恒李文鹏程芹张金利
化学工业与工程 2022年2期
王灵杰郭俊恒李文鹏程 芹张金利∗
(1.天津大学化工学院,天津 300072;2.郑州大学化工学院,郑州 450000;3.安徽大学化学化工学院,合肥 230601)
高剪切混合器作为一种新型的过程强化装备,已广泛应用于化工、食品、制药以及农业领域。高剪切混合器核心部件为定转子,不同的生产过程与操作工况需要采用不同定转子构型及组合方式,这导致高剪切混合器的定转子结构及组合形式复杂多样[1]。高剪切混合器的结构参数、操作参数与物性参数对其流动、功耗、乳化和传质特性的影响错综复杂,至今仍未形成对上述特性清晰而系统的认识。目前,高剪切混合器的设计、选型、工业放大和操作参数调控仍然主要依赖于工程经验和反复实验,这导致其存在开发与使用成本偏高,放大困难等问题[2]。因此,急需建立高剪切混合器设计与优化模型。
近些年来,机器学习飞速发展,机器学习建模方法越来越多地应用于模型预测及系统优化。例如,在微波固化材料技术中,由于微波腔内不均匀的电磁场导致物体表面温度不均匀,严重阻碍了固化材料技术的发展;Zhou 等利用机器学习卷积神经网络(Neural Network,NN)实现了温度智能控制,使表面温度的均匀性有了明显地提高,解决了温度不均匀的痛点,满足了航空航天材料的高质量要求[3]。Wu 等利用机器学习的迁移学习方法,让计算机从高分子数据库中学习已有数据建立模型,并用实验数据微调机器学习模型,极大改善了因实验数据太少不能使用机器学习的缺点,设计了新型高导热聚酰亚胺,其导热系数比传统的提高了80%[4]。由于神经网络容易陷入局部极值,孙永利等使用机器学习神经网络和遗传算法结合的方法改善了神经网络容易陷入局部极值的缺点,精确预测了螺旋折流板换热器的壳程换热系数和压降[5]。李文鹏等使用反向传播神经网络机器学习算法对管线式高剪切反应器建模,减少了实验次数,获得了反应器的最优结构[6]。
可见基于人工智能和机器学习的建模和优化技术在化工方向发挥越来越重要的作用。然而高剪切混合器设计仅使用了一种机器学习算法,还有多种算法未尝试。因此本工作采用多种机器学习算法对叶片-网孔管线式高剪切混合器的结构参数、操作参数和物性参数对其功耗、液液传质和乳化性能进行建模,以期为叶片-网孔管线式高剪切混合器的设计与优化提供工具。从而减少实验次数,获得高剪切反应器的最优结构,降低成本,缩短开发周期。
1 机器学习算法
1.1 反向传播神经网络算法
反向传播(Back Propagation,BP)神经网络方法,在神经元足够多的情况下,可以在任意精度的情况下,逼近非线性的映射关系[7]。
BP 神经网络是多层的神经网络,含有输入层、隐含层和输出层。前面1 层神经元与后1 层神经元各个相连接,但是本层神经元互不相连。调整权重和阈值,使用梯度下降法的策略,使预测值与实际值的误差最小。
1.2 循环神经网络算法
循环神经网络(Recurrent Neural Network,RNN)是一种深度学习神经网络[8]。在神经网络中加入反馈连接层,能够对过去的数据留下印象并且建立不同时间段数据的关系。可认为是同一单元重复构成的链式结构网络,其输出不仅受当前数据的影响而且受以前所有数据的影响。伴随着时间和神经元数量增加,RNN 往往会出现梯度消失和爆炸的现象。
长短时记忆(Long Short Term Memory,LSTM)神经网络也是一种神经网络,它是RNN 的一种改进模型[9]。LSTM 利用记忆模块代替普通的神经元,一个记忆模块由输入门、遗忘门和输出门构成。由于遗忘门的存在,LSTM 可以忘记一些不重要的信息,有效防止梯度的消失和爆炸。
门控循环单元(Gated Recurrent Unit,GRU)神经网络是LSTM 的改进版本[10]。GRU 比LSTM 少一个门控单元,优化了LSTM 内部结构,由于参数的减少,从而大幅提高了训练速度。
1.3 基于树的机器学习算法
决策树(Decision Tree,DT)作为一种机器学习方法,可以进行数据分类和回归[11]。使用一个基于树的模型,以香农熵的大小为划分依据。因为它的方法非常简单、但却有非常明确的物理含义,可以轻松的变成“如果-那么”的规则,能够生成具有可解释的类似于流程图的树状结构的准确预测模型,从而使用户能够快速提取有用的信息。
极端随机树(Extremely Randomized Trees,ET)由Pierre Geurts 等于2006年提出[12]。通过对多个决策树进行打分,根据各个决策树预测值的平均值来预测。
极端梯度提升(Extreme Gradient Boosting,XGBOOST)由陈天齐博士提出[13]。内部是决策回归树,能处理大量的数据,自定义损失函数。采用弱分类器迭代计算,从而提高预测精确性。
梯度提升回归树(Gradient Boosting Regressor,GBR)每次迭代生成一个弱学习器用于拟合损失函数以前累积模型的梯度,之后将弱学习器加入累积模型,从而逐渐降低模型的损失[14]。
2 实验
2.1 PyCaret 程序
PyCaret 是一个开源的程序,它对计算硬件资源的要求不是很高,8 GB 的运行内存就可以运行[15];操作系统为Windows 10,程序语言为Python,在Jupyter Notebook 软件下运行。PyCaret 程序十分 方便机器学习初学者使用。
PyCaret 具有简洁的、可以方便设置的程序界面,内置25 种不同的机器学习算法,仅仅用几行代码就可以完成从数据预处理到实现模型部署的整个流程。它包含了如今很多流行的机器学习算法,如:决策树算法、随机森林算法、支持向量机算法和最近邻算法等。PyCaret 可以进行有监督和无监督模型的训练,能够实现分类、回归、异常检测、聚类、自然语言处理和关联规则挖掘6 大类功能。
2.2 数据预处理

除PyCaret 以外,本研究所有机器学习模型的输入数据均采用归一化的方法[式(1)],将输入数据变为-1~1 的值,将有量纲的数据变为无量纲的数据,变成纯量数据后,更有利于机器学习的训练。输出数据采用对数的方法[式(2)]平滑输出数据,使其更符合高斯分布,也更方便机器学习的训练。最后使用式(3)将式(2)的输出数据变为最终的拟合数据。
式(1)中:xmax为每个特征的最大值,xmin为每个特征的最小值。

2.3 数据描述
2.3.1 流体净功耗(Pfluid)数据
流体净功耗数据来自程芹和秦宏云的实验,共有141 组数据[16,17]。输入参数为转子叶片弯曲角度、定转子剪切间隙、转子叶片个数、转子转速、流体流量、流体密度、连续相黏度、分散相黏度、外层直径和层数,输出参数为Pfluid,总计10 个输入变量,1 个输出变量。表1为部分流体净功耗数据。

表1 部分流体净功耗数据Table 1 Part of Pfluid data
2.3.2 液液总体积传质系数(KLa)数据
液液总体积传质系数KLa数据来自秦宏云的实验,共有35 组数据[17]。输入参数为定转子剪切间隙、层数、转子叶片个数、转子叶片弯曲角度、转子转速,输出参数为KLa,总计5 个输入变量,1 个输出变量。表2为部分液液KLa数据。

表2 部分液液KL a 数据Table 2 Part of liquid-liquid KL a data
2.3.3 液液乳化Sauter 平均直径(d32)数据

表3 部分液液乳化液滴d32 数据Table 3 Part of liquid-liquid emulsification droplet d32 data
3 结果与讨论
3.1 流体净功耗模型
3.1.1 流体净功耗GRU-BP 模型
GRU-BP 神经网络是在算法层面对2 个网络的结合。将GRU 层的输出作为BP 神经网络的输入层,接着是BPNN 的隐含层,最后是输出层。

图1是GRU 单元内部结构,式(4)是sigmoid 激活函数。式(5)中zt为更新门,σ为sigmoid 激活函数,xt表示t时刻输入,ht-1表示上一隐藏节点输出;
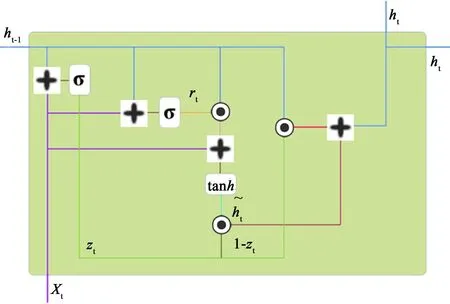
图1 GRU 单元结构Fig.1 The structure of GRU unit
式(6)中rt为重置门;式(7)中为隐藏节点待选值,tanh 为双曲正切函数;式(8)中ht为t时刻隐藏节点的输出,Wz、Wr、Wh、Uz、Ur和Uh为需要更新的参数。
将叶片-网孔管线式高剪切混合器流体净功耗的141 组数据中的119 组数据为训练集,22 组数据为测试集。训练时使用式(2)和式(3)对输出数据进行数据变换。使用GRU-BP 模型Adam 算法训练数据,得到输入层10 个神经元,1 层深度为2 的GRU 单元后接3 个神经元的全连接层,全连接层使用sigmoid 函数激活,输出层为1 个神经元的GRUBP 模型(图2)。式(9)~式(11)为评价模型平均绝对误差(MAE)、平均相对误差(MRE)和决定系数(R2)。模型训练后的MAE、MRE、R2如表4所示。图3为GRU-BP 模型预测值与实验值的对比,最大相对误差为24.94%。

图2 经过优化的GRU-BP 结构Fig.2 Optimized structure of the GRU-BP model

图3 GRU-BP 模型预测Pfluid 值和实验结果对比Fig.3 Comparison of predicted Pfluid value and experimental value with GRU-BP model

表4 叶片网孔型流体净功耗GRU-BP 模型表现Table 4 The performance of blade screen Pfluid GRU-BP model

式(9)~式(11)中:Ysim为预测值,Yrea为实验值。
3.1.2 流体净功耗树模型
①公路桥梁养护及加固是其施工管理的重要组成部分,确保较高质量的公路养护和加固技术应用,对于工程建设质量提升,和道路运行安全具有重大影响,其能确保公路桥梁社会服务职能的充分发挥。②对于建设企业而言,公路桥梁养护和加固技术的应用,有助于其施工工艺的不断成熟,从而在提升自身技术竞争优势的同时,实现工程质量效益、经济效益和社会效益的有效获得。③从社会发展的角度来看,公路桥梁工程服务于区域的社会生产实践,通过养护及加固技术应用,确保其建设的质量化,对于区域经济发展和社会进步具有重大影响。由此可见,在公路桥梁工程建设中,确保养护及加固技术的深层次应用势在必行。
使用PyCaret 程序默认设置对流体净功耗数据进行拟合,在141 组数据中119 组数据为训练集,22组数据为测试集。输入数据和输出数据均不作任何数据变换。在PyCaret 程序创建的25 种常用的机器学习模型中,选出MAE 较小的3 个模型,按照MAE 从小到大排列与GRU-BP 模型比较,模型的MAE、MRE 和R2如表5所示。从表5可以看到,经过PyCaret 优化的ET 模型不仅其MRE 为1.48%小于GRU-BP 模型的2.96%,而且其MAE 为1.111 9也小于GRU-BP 模型的2.375 8。由此可见,自动机器学习模型对于仅有少数机器学习背景的科研人员和工程师还是非常有用的,可以用于大数据量的建模与预测。

表5 4 种不同Pfluid 模型比较Table 5 Comparison of 4 different Pfluid models
3.2 液液总体积传质系数KLa 模型
3.2.1 KLa 的RNN、BP 模型
将叶片-网孔管线式高剪切混合器的液液总体积传质系数KLa共计35 组数据,分为28 组训练数据和7 组测试数据;使用BP 算法,激活函数为sigmoid 函数,在输入层、隐含层和输出层之间进行数据传输。最终得到了输入层5 个神经元、隐含层3个神经元、输出层1 个神经元的5-3-1 网络结构的BP1模型。模型训练后的MAE、MRE、R2如表6所示,模型在所有数据集上的最大相对误差为19.74%。

表6 叶片网孔型KL a 模型表现Table 6 The performance of blade screen KL a model
使用和BP1模型同样的训练集和测试集,采用RNN 模型Adam 算法训练数据,得到输入层5 个神经元,1 层RNN 单元,RNN 单元的深度为3,输出层1 个神经元的RNN1模型。模型训练后的MAE、MRE、R2如表6所示,模型在所有数据集上的最大相对误差为19.70%。
使用模型融合方法,将不同模型的输出乘以权重值加和后作为融合模型的输出,可以减轻神经网络容易过拟合,泛化能力差的问题。不同融合模型的预测精度如图4所示。图4中除BP1、RNN1外,其余模型名称的命名规则与MK55 相同;MK55 中的M 是Model 的简写,K 是KLa的简写,第1 个5 表示BP1模型的权重为0.5、第2 个5 表示RNN1模型的权重为0.5。从图4中可以看出,MK55 模型有最小的平均相对误差,其平均相对误差为6.36%;因此,选取MK55 作为叶片-网孔管线式高剪切混合器KLa的最终预测模型[式(12)]。图5为MK55 模型预测不同结构参数和操作参数对KLa的影响,图5中的圆球形表示的是实验数据。由图5知,KLa随着转子叶片个数先增大后减小;随着转子叶片弯曲角度增大而减小;低转速下,层数增加,KLa增加。改变高剪切混合器的结构参数和操作参数,可以形成107 632 个组合,在此范围内利用MK55 模型进行参数寻优,发现:定转子剪切间隙为0.000 5 m、转子层数为2 层、转子有6 个叶片、转子叶片弯曲角度为-15°、转子转速为3 000 r·min-1时,可以获得最高的KLa值;此条件下,经GRU-BP 模型预测的流体净功耗为35.02 W。

图4 不同KL a 模型表现Fig.4 The performance of different KL a models
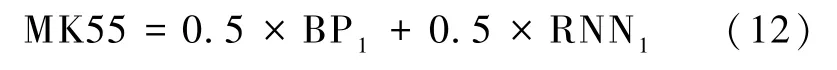

图5 MK55 模型估算不同结构参数和转速时叶片网孔KL a 的值Fig.5 The blade screen KL a MK55 model to estimate values of different configuration parameters and speeds
3.2.2 KLa 的树模型
使用PyCaret 程序默认设置对总体积传质系数35 组数据进行拟合,在35 组数据中28 组数据为训练集,7 组数据为测试集。输入数据和输出数据均不作任何数据变换。在PyCaret 程序创建的25 种常用的机器学习模型中,选取2 个MAE 较小的模型与MK55 模型比较,模型的MAE、MRE 和R2如表7所示。表7的DT 模型和ET 模型对高剪切混合器性能的拟合均优于MK55 模型。
图6是表7决策树模型DT 估算不同剪切间隙和转速时KLa值的变化情况。通过图5与图6比较,MK55 模型输出值是平滑的,决策树模型输出值是阶跃的。因此,虽然决策树的MRE 和MAE 都优于MK55 模型,但在数据量较小的情况下,决策树模型由于其输出不能平滑变化,不能对高剪切混合器进行较好地优化。

表7 3 种不同KL a 模型比较Table 7 Comparison of 3 different KL a models

图6 决策树模型估算不同剪切间隙和转速时叶片网孔KL a 的值Fig.6 The blade screen KL a decision tree model to estimate values of different shear gaps and speeds
3.3 乳化液滴d32 模型
将叶片-网孔管线式高剪切混合器的乳化液滴d32共计28 组数据分为23 组训练数据和5 组测试数据,使用BP 模型Adam 算法训练数据,得到5-2-1网络结构的BP2模型。模型训练后的MAE、MRE、R2如表8所示,模型在所有数据集上的最大相对误差为10.34%。
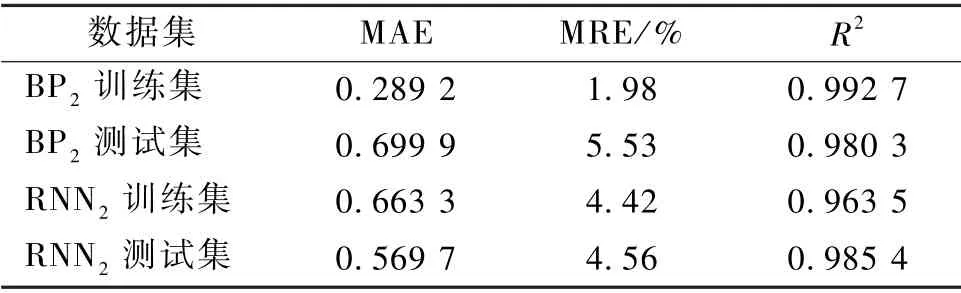
表8 叶片网孔型d32 模型表现Table 8 The performance of blade screen d32 model
使用和BP2模型同样的训练集和测试集,使用RNN 模型Adam 算法训练数据,得到输入层5 个神经元,1 层RNN 单元,RNN 单元的深度为1,输出层1 个神经元的RNN2模型。模型训练后的MAE、MRE、R2如表8所示,模型在所有数据集上的最大相对误差为12.10%。
图7是不同乳化液滴d32模型的比较,除BP2、RNN2外,其余模型的命名规则与MD91 相同;MD91模型名称的命名规则为:M 代表Model、D 代表d32,9表示BP2模型的权重为0.9,1 表示 RNN2模型的权重为0.1。

图7 不同叶片网孔d32 模型表现Fig.7 The performance of different blade screen d32 models
从图7中可以看出,各个模型MRE 变化相对于其最大相对误差变化比较小,MD91 模型有最小的平均相对误差,其平均相对误差为2.69%;因此,选取MD91 作为乳化液滴d32的最终预测模型(式13)。改变高剪切混合器的结构参数和操作参数,可以形成55 552 个组合,在此范围内利用MD91 模型进行参数寻优,发现:定转子剪切间隙为0.000 5 m,转子层数为3 层,转子有9 个叶片,转子叶片弯曲角度为15°,在转速3 500 r·min-1下,可以获得最小的d32。在此条件下,经GRU-BP 模型预测的流体净功耗为57.26 W。

4 结论
1)BPNN、RNN、GRU-BP 算法可以准确预测高剪切混合器的功耗、液液传质和乳化性能,通过对不同机器学习模型进行融合,可以使预测模型的最大相对误差继续下降,模型精度进一步提升。经过模型融合液液KLa模型最大相对误差由19.74%下降至19.53%,平均相对误差由 7.11% 下降至6.36%。乳化液滴d32模型最大相对误差由12.10%下降至10.00%,平均相对误差由4.44%下降至2.69%。从而为高剪切混合器的结构与操作参数设计提供工具。
2)为了获得最适宜的液液传质和乳化性能,利用机器学习模型对高剪切混合器的操作与结构参数进行了优化设计。最适宜参数组合为:定转子剪切间隙为0.000 5 m,转子层数为2 层,转子叶片数为6 个,转子叶片弯曲角度为-15°,转子转速为3 000 r·min-1时,可以获得最高的KLa值;定转子剪切间隙为0.000 5 m,转子层数为3 层,转子叶片数为9 个,转子叶片弯曲角度为15°,转子转速为3 500 r·min-1时,可以获得最小的乳化液滴d32。
3)基于自动机器学习的PyCaret 程序能够准确拟合数据,但在数据量较小的情况下,其优化能力较差。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
柴油机设计与制造(2022年2期)2022-08-16
环球时报(2022-07-13)2022-07-13
内燃机与动力装置(2022年3期)2022-07-12
现代电力(2022年2期)2022-05-23
环球时报(2022-03-14)2022-03-14
武汉科技大学学报(2021年3期)2021-04-21
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
电影(2018年8期)2018-09-21
