
命名数据网络中带宽时延感知的拥塞控制机制
2022-05-17 06:01曲大鹏张建坤吕国鑫高程希
计算机与生活 2022年5期
曲大鹏,张建坤,吕国鑫,高程希,宋 琪,3+
1.辽宁大学 信息学院,沈阳110036
2.中国科学院 深圳先进技术研究院,广东 深圳518055
3.辽宁大学 经济学院,沈阳110036
随着互联网的主要应用需求从早期的资源共享逐渐转变为当前的内容获取与分发,端到端通信模式的网络架构很难满足这种变化,信息中心网络(information centric networking,ICN)提出以内容为中心构建新型网络架构,通过对信息进行命名实现内容检索和数据传输,正逐渐成为一种主要的未来网络架构。命名数据网络(named data networking,NDN)作为ICN 的典型代表,吸引了研究者们的广泛关注。NDN 采用基于内容名称路由的无连接传输模式,内容请求者通过内容名称请求数据,同时路由节点依据内容名称进行数据转发。因此,NDN 具有节点缓存和无连接传输等特点。
在NDN 中,有两种分组:兴趣包和数据包,内容请求者发送兴趣包请求数据,内容提供者发送数据包响应兴趣包。通常情况下,内容请求者发送一个兴趣包以获取所需内容,内容提供者返回一个装有该内容的数据包给内容请求者。但是当请求内容比较大时,内容提供者需要将该内容分片,然后逐片装入数据包。这种情况或者需要内容请求者持续发送多个兴趣包才能获取完整内容,但会导致较大传输延时,或者内容提供者一次性返回所有数据包,但易导致数据包丢失,因此不适用于AR/VR 等大数据量延迟敏感型应用场景。
拥塞控制一直是计算机网络的重要研究问题之一,从传统的TCP/IP 网络结构到现在的NDN 结构,都涌现了很多相关研究。但一方面传统拥塞控制算法不适用于新型的NDN 结构,例如基于往返传输时间(round transmission time,RTT)的拥塞检测机制不能适应NDN 的多源多路径特性,而NDN 的无连接特性使得面向连接的基于确认ACK 的拥塞控制机制失效。另一方面,NDN 中的现有拥塞控制研究往往忽略了NDN 的内容缓存特性,没有考虑到中间节点缓存了部分请求内容的情况下,对于网络拥塞控制的影响。
基于上述分析,针对AR/VR 等大数据量延迟敏感型应用,基于One-Interest-Multiple-Data 传输模式,提出了一个新的拥塞控制机制,内容提供者基于兴趣包沿途收集的链路状态信息计算拥塞窗口和发送速率,内容请求者根据收到的数据包继续发送兴趣包,从而既避免一次发送大量数据包造成网络拥塞,又通过一个兴趣包与多个数据包之间的对应关系加速传输过程。同时考虑到大多数提出的NDN 拥塞控制算法没有考虑节点缓存对拥塞控制的影响,提出缓存标记的方法,标记链路中的缓存信息,让各节点缓存内容可以有序传输,充分地利用了节点缓存,减少传输所需时间,同时不会影响拥塞控制算法的准确性。
本文的贡献如下:
(1)针对NDN 的无连接传输特性,基于One-Interest-Multiple-Data 传输模式,提出了一种新的拥塞控制机制。该机制使用兴趣包收集从内容请求者到内容提供者的路径上的瓶颈链路带宽和时延信息,内容提供者据此信息计算出拥塞窗口和发送速率。内容提供者发送了拥塞窗口数量的数据包之后,内容请求者发送新的兴趣包反馈数据包的接收情况以及记录新的路径信息来更新拥塞窗口和发送速率。与相关研究相比,该机制不仅在拥塞窗口、队列长度和数据传输速率等方面取得更好性能,而且能够在更短的时间内完成大数据量内容的传输,更适用于AR/VR 等应用。
(2)针对NDN 的节点缓存特性,提出了缓存标记方法,在中间节点存在请求内容的部分缓存时,通过标记节点的缓存内容,一方面通告给后续节点,另一方面在节点尚未完成缓存内容的发送时,将后续节点传输过来的数据包缓存,留待后续发送。从而使得各节点缓存内容可以有序传输,充分地利用了节点缓存。
1 相关工作
由于拥塞控制一直是计算机网络的重要研究问题之一,近年来,也涌现了很多针对NDN 的拥塞控制研究。基于不同研究角度,这些拥塞控制算法可以有不同的分类方法。从拥塞控制执行者的角度出发,将这些拥塞控制算法分为三类:
(1)基于内容请求者的拥塞控制算法
兴趣控制协议(interest control protocol,ICP)和信息中心传输协议(information centric transmission protocol,ICTP)都是基于内容请求者的控制算法,即它们发送的兴趣包内含窗口大小限制。通过RTT控制并以加法增加乘法递减(additive increase multiplicative decrease,AIMD)机制改变拥塞窗口的大小,并且仅通过超时检测拥塞。由于NDN 多源多路径的传输特性,不同的路径以及不同的内容提供者具有不同的RTT,基于单一内容源的算法通过设置单一RTT 值在检测拥塞方面存在一些问题。
内容中心TCP(content centric TCP,CCTCP)和远程自适应主动队列管理(remote adaptive active queue management,RAAQM)通过标签识别每个内容源或每个传输路径来实现多源传输拥塞控制。其中,CCTCP 为每个数据源维护一个RTO 值和拥塞窗口。RAAQM 为每个传输路径维护一个RTO 值和拥塞窗口,这样的拥塞控制方案需要内容请求者为每个流维护多个源或路径的大量信息,因此它们的开销很大。
在兴趣包速率的自调节控制(self-regulating interest rate control,SIRC)中,内容请求者监视数据包的到达间隔时间并将兴趣包发送速率调整为数据包接收速率。SIRC 还考虑了多个内容提供者在重传超时后相互转换,但没有考虑同时使用多个内容提供者进行传输。同样在NDN 中数据可能来自不同路径的不同源,因此数据包的到达间隔并不能正确反映网络链路的真实情况,进而导致SIRC 可能计算出错误的发送速率。
显式控制协议(explicit control protocol,ECP)将网络拥塞程度划分为三个级别,通过检测中间节点中传输队列的平均长度判断网络的拥塞程度,并将具体的拥塞级别信息通过NACK(negative acknowledgment)分组反馈给内容请求者,然后内容请求者通过乘法增加加法增加乘法递减(multiplicative increase additive increase multiplicative decrease,MIAIMD)算法相应地调整其兴趣发送速率。但是在节点检测到拥塞后,数据包会重复反馈拥塞信息造成拥塞控制算法的过度反应。
PCON 算法提出各个节点监测自身出站链路上每个数据包的排队延迟来检测拥塞。检测到拥塞后通过数据包反馈拥塞信号给内容请求者,内容请求者接收到拥塞标记后调整拥塞窗口大小。拥塞窗口在接收到未标记的数据包时增加,接收到有标记的数据包、NACK 和超时时减少,并且内容请求者每RTT 最多执行一次窗口减少,PCON 算法的问题是当在一个RTT 中已执行了一次窗口减少,如果后续数据包反馈更严重的拥塞,此时算法无法进一步减少窗口,因此不能对拥塞进行更有效的控制,降低了拥塞控制算法的效率。
基于内容请求者的拥塞控制算法可以利用NDN内容请求者驱动的传输特性,通过控制兴趣包的发送数量或发送速率进行拥塞控制,易于实现,但是在内容请求者处进行拥塞控制存在内容来源不确定的问题,进而影响拥塞检测的准确性。
(2)逐跳拥塞控制算法
逐跳兴趣包整形机制(hop-by-hop interest shaping mechanism,HoBHIS)通过监视块队列长度来检测拥塞,并根据队列长度和节点可用资源调整兴趣转发率。路由器独立决定允许的最大兴趣发送速率,并相应地形成兴趣包。还向内容请求者报告最大允许发送速率,内容请求者根据反馈信息来控制兴趣包的发送。
基于窗口的逐跳拥塞控制(hop-by-hop windowbased congestion control,HWCC)提出在每个数据流中的每一跳确定一个兴趣窗口大小,HWCC 引入逐跳确认(H-ACK)分组和在窗口关闭时存储兴趣分组的队列(兴趣队列)。H-ACK 分组报告连续传送的兴趣包的接收。为了请求H-ACK 分组,将H-ACK 请求标志添加到兴趣分组。路由器在窗口中的最后一个兴趣数据包上设置此标志。对于超过拥塞窗口的兴趣包,路由器将它们存储在兴趣队列中,等待下一次窗口再发送。
逐跳控制可以细粒度地调节链路数据的传输,这样可以更准确地检测拥塞,并进行适当的调节以缓解拥塞,但是在节点处进行复杂的拥塞监控及速率调整会增加算法设计难度,开销巨大且会受到节点资源的限制。
(3)基于内容请求者和逐跳控制的混合方案
联合逐跳和接收器驱动的兴趣包控制协议(hopby-hop and receiver-driven interest control protocol,HR-ICP)在ICP 的基础上增加了逐跳拥塞控制机制。在内容请求者处,使用ICP 的兴趣控制算法,在中间节点处,采用基于配额的方案来转发兴趣包,以实现更快速地检测并响应拥塞,从而提高了网络的吞吐量和鲁棒性。但在HR-ICP 中,基于内容请求者的机制和逐跳控制机制是相互独立的,在中间节点采取的转发控制会直接影响内容请求者处隐式拥塞检测的准确性。
块交换跳跃拉控制协议(chunk-switched hop pull control protocol,CHoPCoP)使用基于内容请求者的控制作为主控制,并使用逐跳控制作为辅助控制手段。当中间节点的队列长度超过设定阈值时,CHoPCoP 启动逐跳控制机制,并且内容请求者使用AIMD 机制调整窗口大小,中间节点采用REM(随机早期标记)机制,即通过监视输出数据队列的大小来检测拥塞,并在发生拥塞时标记数据包将拥塞信息反馈给内容请求者。
基于内容请求者和逐跳控制的混合方案有效避免了单类型算法的缺点,并可以实现更多样性的拥塞控制机制,但两种机制的组合如果不能协调得当,就会出现重复或者过度的拥塞控制,造成传输性能下降。
通过上述分析讨论,本文首先提出了采用One-Interest-Multiple-Data 的传输模式,并在内容提供者处通过控制数据包的发送来进行拥塞控制。一方面降低传输时延,另一方面通过兴趣包的路径信息收集实现合理传输和避免拥塞。最后,在此基础上,针对现有拥塞控制算法大多忽略了节点缓存对拥塞控制影响的问题,充分考虑了内容缓存对拥塞控制的影响,通过缓存标记,有序传输缓存内容,加速内容获取,避免拥塞。
2 拥塞控制机制
2.1 机制概述
为实现本文提出的拥塞控制机制,对NDN 中的兴趣包、数据包和PIT(pending information table)结构做了适当必要修改,具体结构如图1 所示,其中灰色部分表示新增字段。

图1 数据结构图Fig.1 System data structure
兴趣包中的Bandwidth 字段记录内容提供者到内容请求者之间路径的瓶颈带宽;Delay 字段记录内容提供者到内容请求者之间的单向时延;Sent字段记录传输路径中存在的节点缓存内容;Lost字段记录传输过程中丢失的数据包。
数据包中的Inventory 字段记录内容提供者针对当前收到的兴趣包发送的数据包的清单;PacingRate字段记录当前数据包的发送速率,表示数据流的实际占用带宽。
PIT 表中的Rate 字段记录各个流的预估占用带宽/实际占用带宽。当兴趣包经过节点时,Rate 值等于兴趣包的Bandwidth 字段值,即预估占用带宽,当数据包经过节点时,Rate 值等于PacingRate 字段值,即实际占用带宽。Caching 字段用来标记当前节点是否存在待发送的缓存内容。
算法流程如图2 所示。
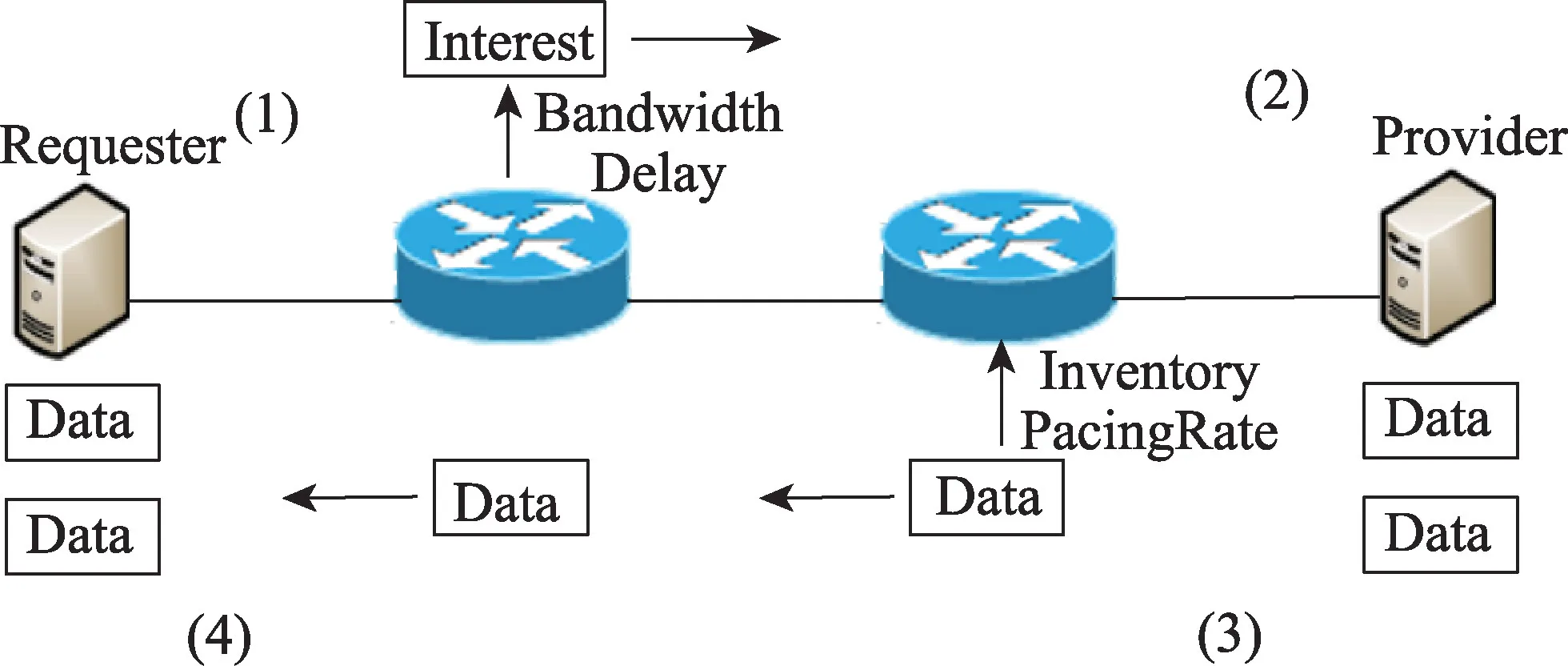
图2 算法流程图Fig.2 Algorithm flow chart
(1)来自内容请求者的兴趣包在经过中间节点时,每个节点根据沿途每段链路信息动态计算出瓶颈带宽和时延,并将其分别放入兴趣包中相应的字段。
(2)内容提供者收到兴趣包后,根据包中的瓶颈带宽和时延等信息计算出拥塞窗口和数据包的发送速率,然后生成数据包原路返回。
(3)数据包在经过中间节点时,每个节点根据数据包中Inventory 字段和PacingRate 字段的信息更新PIT 表中的记录。
(4)内容请求者收到数据包后,根据兴趣包中的Inventory 字段判断数据包的接收情况,从而判断后继操作,即发送新的兴趣包请求后续内容或重传丢失的数据包。
2.2 拥塞控制算法
中间节点在收到来自内容请求者的兴趣包后,如果该节点的PIT 表中待定兴趣包的数量超过阈值,则将该兴趣包返还给上一节点,寻找新的可用路径;否则将该兴趣包记录在PIT 表中,然后节点根据当前链路状态,动态计算这个新加入的数据流在该节点可分配到的带宽,即这个兴趣包所请求的数据包在该节点出接口(从内容提供者到内容请求者方向的接口)的可用带宽,计算如下:
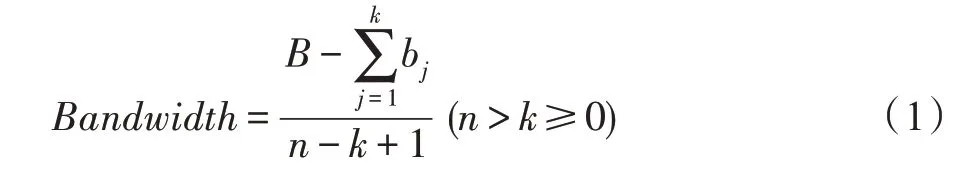
其中,表示兴趣包对应的数据包在节点出接口的总带宽,是当前出接口已经存在的数据流的个数,是当前节点已存在的个数据流中,已占用带宽小于带宽的分之一的数据流的个数,b是这个数据流中第个数据流的实际带宽,数值为该数据流在PIT 表记录中的Rate字段的值。
兴趣包在从内容请求者出发的路径上,沿途将逐段链路瓶颈带宽的数值记录在Bandwidth 字段,并实时更新,同时计算每段链路的时延,并将从内容请求者到当前节点的时延和记录在Delay 字段。当兴趣包到达内容提供者时,此时兴趣包的Bandwidth 字段中记录着经过的整个路径中所有节点可以提供的带宽最小值,Delay 字段记录着从内容请求者到内容提供者之间的单向时延和。内容提供者据此计算出拥塞窗口,如下所示:

其中,表示数据包大小,拥塞窗口值就是受瓶颈链路影响的整条路径中可以容纳的数据包数量。内容提供者计算出拥塞窗口后,将相应数据包按照Bandwidth大小的速率发送出去。数据包中的Inventory字段中记录着此次数据包清单。PacingRate字段中记录数据包的发送速率。
中间节点在收到来自内容提供者的数据包后,将PIT 表中Rate 字段中的值更新为PacingRate 字段中的值,即实际占用带宽。从而保证在新的数据流加入后,带宽能够重新分配。同时,节点应用Inventory字段来更新PIT 表条目状态,即判断当前数据包是否为请求内容的最后一个数据包,如果不是的话,则延长该数据流在PIT 表中条目的生存时间。
内容请求者在收到数据包后,按照Inventory 字段上的内容对比收到的数据包,如果某个数据包未收到,但后续数据包已经收到,则判定该数据包丢失;如果收到某一数据包之后,超过RTO 值(即从内容请求者发送兴趣包的时刻到收到第一个数据包的间隔或者更小的值)未收到后续数据包,则判定该后续数据包丢失。内容请求者发送新的兴趣包(相当于ACK),将丢失的数据包清单记录在兴趣包的Lost字段。内容提供者收到新的兴趣包后,提取新的Bandwidth 和Delay 字段,计算新的和数据包的发送速率,重传Lost 字段中记录的数据包或者发送新的数据包。
2.3 缓存内容标记策略
为充分利用NDN 的内容缓存特性,应用缓存标记策略来直接传输节点的缓存内容,同时传输后续节点的内容。具体流程为:中间某个节点在收到兴趣包后,发现自己有该请求内容的部分缓存时,就将自己的缓存内容记录在兴趣包中的Sent 字段中,然后节点根据兴趣包中Bandwidth 字段和Delay 字段中的信息计算出拥塞窗口以及发送速率,并将缓存内容发送给内容请求者。接着继续应用FIB 转发该兴趣包,直至到达最终的内容提供者或该兴趣包对应的所有分片内容都已放入sent字段,即中间缓存节点满足了内容请求者的需求,返回了该内容对应的所有分片。
在数据包的返回过程中,如果数据包被转发到之前存在缓存的节点时,PIT 表中该内容条目的Caching 字段显示为true 时,则表示该节点还未将缓存内容发送完毕,则此节点先将接受到的数据包缓存到CS 中,之后让该节点统一发送。
2.4 算法描述
由于NDN 中只有兴趣包和数据包传输,本文提供两种包的传输过程,分别如算法1 和算法2 所示。
1 兴趣包在NDN 中的传输过程

其中,步骤2、3 表示如果当前节点中的未决表项数量超过阈值,即已经处于拥塞状态,则该中间节点将这个兴趣包返回给上一跳节点;否则,步骤5~9 表示该中间节点在PIT 中加入一条新的表项,并更新这个兴趣包中的Bandwidth 和Delay 字段。如果此中间节点有这个兴趣包需求的内容,则步骤12~15 表示计算拥塞窗口,返回缓存的请求内容等,否则继续转发这个兴趣包。
2 数据包在NDN 中的传输过程


其中,步骤2~5 表示内容请求者收到数据包后,检查相应内容,如果收到的数据包不能组成全部内容,则需要继续发送兴趣包以获取缺乏的内容,步骤7~14 表示中间节点在收到数据包后,更新相关内容,然后如果自己的缓存内容还没有发送完,则先缓存收到的数据包,以避免拥塞,否则直接转发。
3 实验与性能评估
使用开源仿真平台ndnSIM 实现了提出的拥塞控制机制,ndnSIM 基于网络模拟器NS3 实现了NDN协议栈。
3.1 实验设置
采用NDN 中常用拓扑DFN,如图3 所示。共设置3 个内容请求者1、2 和3,3 个内容提供者1、2 和3 以及8 个路由节点,分别为1~8。根据VR 的初级沉浸(entry-level immersion,EI)应用性能要求,将4-5、4-8、8-5 设置为瓶颈链路,带宽均为50 Mbit/s,将1-4、2-4、3-4链路带宽均设置为80 Mbit/s,其余链路带宽均为100 Mbit/s,所有链路时延均为10 ms。通过模拟VR初级沉浸场景下的数据传输来评估各个算法的性能。兴趣包大小为125 Byte,数据包大小为1 124 Byte,默认下,每个兴趣包请求的内容大小为100 MB。

图3 DFN 拓扑Fig.3 DFN topology
选择当前NDN 中的一个主要拥塞控制算法CHoPCoP 作为基准算法进行性能比较。同时,考虑到CHoPCoP 算法基于One-Interest-One-Data 传输模式,为保证公平性,对CHoPCoP 算法进行了改进(CHoPCoP-impro),即通过内容提供者改变发送数据包的数量来进行拥塞控制,并保留了中间节点记录队列长度反馈拥塞的机制,兴趣包和数据包的结构也进行了类似修改以记录相关信息。
3.2 结果分析
主要从拥塞控制机制的效率、稳定性以及存在节点缓存时的传输三方面评估性能。
首先设定从1 向1 请求100 MB 的数据,分别观察1 向1 请求数据时的拥塞窗口、队列长度和数据传输速率随时间发展的变化情况。
图4 显示内容提供者1 的拥塞窗口随时间发展的变化情况。可以看出,本文提出机制的拥塞窗口一直稳定在一个最高的数值,CHoPCoP 和CHoPCoPimpro 都随着时间而波动,但后者波动的范围略小,而且数值较高。这是因为该机制可以准确探测链路的信息并计算出可以容纳的数据包数量,因此当链路情况保持不变时性能最优。而CHoPCoP和CHoPCoPimpro 都采用线性增长指数下降和中间节点反馈队列长度的策略进行拥塞控制,持续增加拥塞窗口会导致节点处出现较长队列,进而通过反馈减少拥塞窗口,如此往复造成拥塞窗口出现持续的振荡。CHoPCoP 算法一次性发送拥塞窗口数量的兴趣包,导致队列长度过长,进而超过阈值时减少拥塞窗口,因此CHoPCoP 的性能最低。CHoPCoP-impro 可以根据路径反馈的队列长度调整数据包发送速率,避免了集中发送数据包,在中间节点处出现长队列的情况,因此可以达到比CHoPCoP 更高的拥塞窗口值。
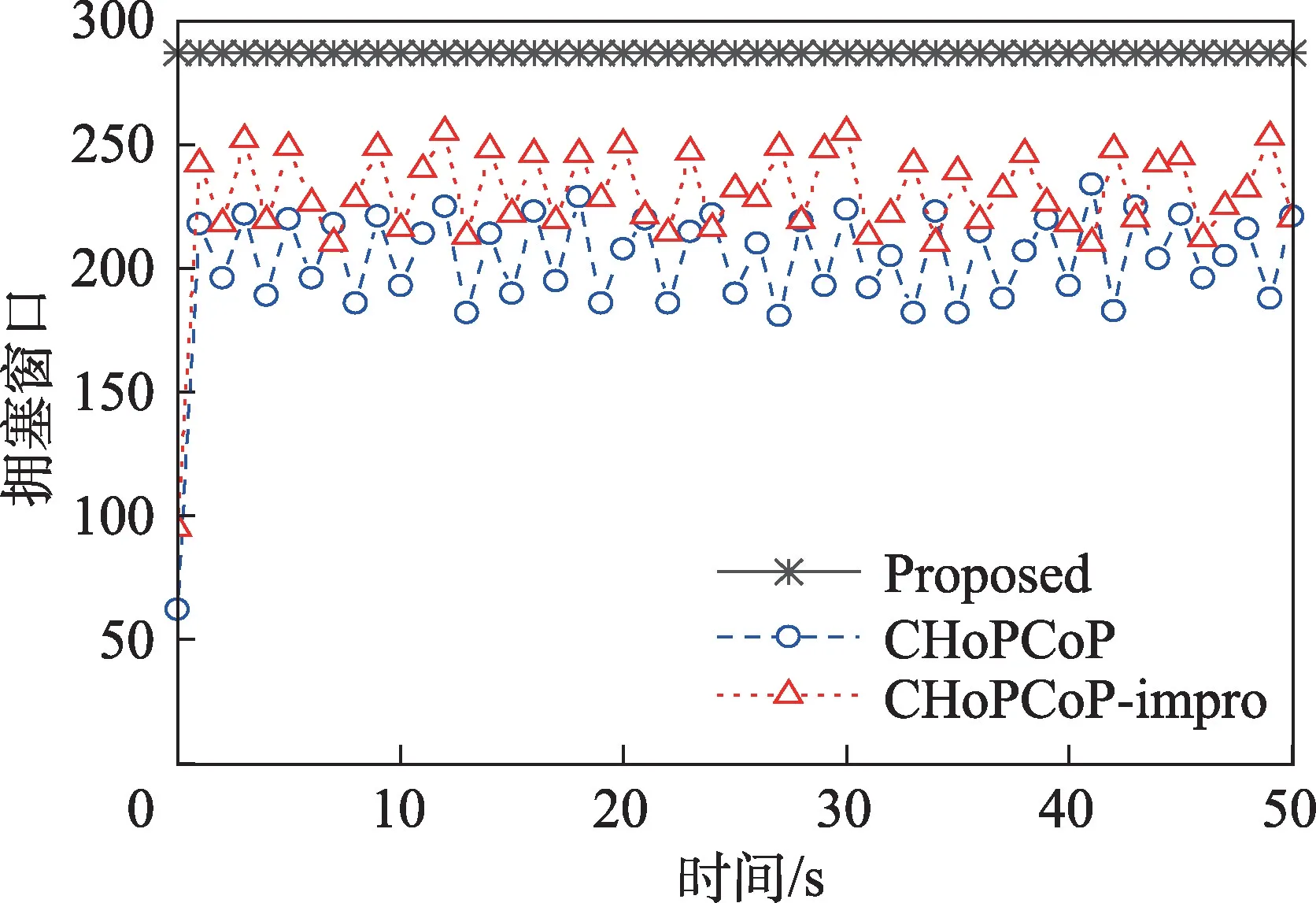
图4 拥塞窗口随时间发展的变化情况Fig.4 Changes in congestion window over time
图5 显示所有中间节点(1、4、5 和6)的队列长度平均值随时间发展的变化情况。提出的算法能够将数据包发送速率控制在整条传输路径的瓶颈带宽范围内,因此在各个中间节点几乎都没有出现排队队列。CHoPCoP-impro 根据路径状况调整数据包发送速率,从而降低了在各个中间节点处数据包的排队长度,因此队列长度整体较小,波动范围也较小。CHoPCoP 的数据包突发会造成数据包在中间节点处出现排队较长的现象,因此性能最差。
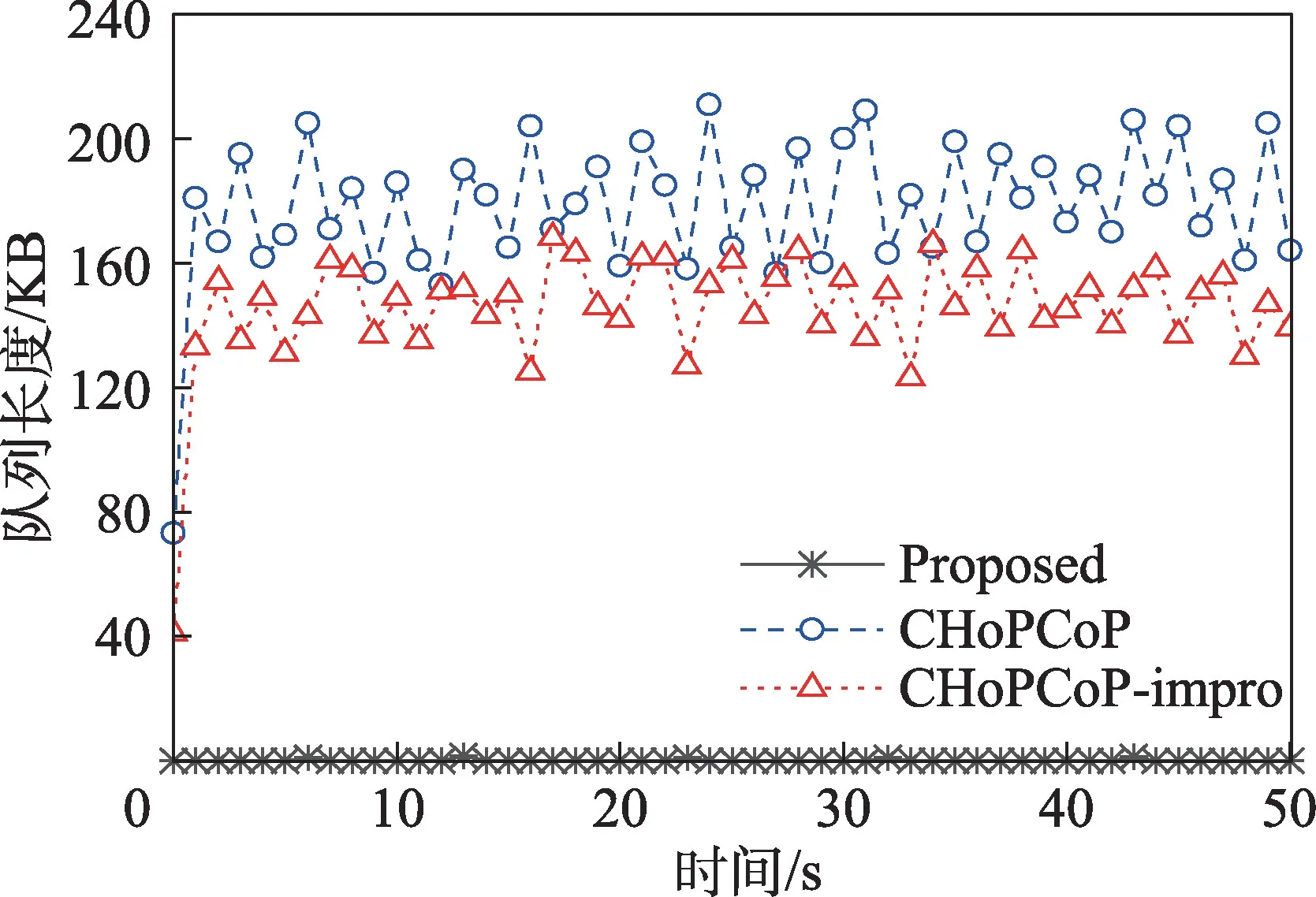
图5 队列长度随时间发展的变化情况Fig.5 Changes in queue length over time
图6 显示的是数据传输速率随时间发展的变化情况,即内容请求者1 接收数据包的情况。提出的算法按照链路瓶颈发送数据包,可以将数据传输速率稳定维持在接近瓶颈链路带宽的速度,因此取得了最好性能。CHoPCoP-impro 算法可以动态调整数据包的发送速率,避免了数据包突发造成的排队问题,因此平均传输速率要高于CHoPCoP,而CHoPCoP算法容易在节点处造成长队列,进而频繁地减少拥塞窗口,使得整体传输速率小于其余两种算法,因此性能最差。

图6 数据传输速率随时间发展的变化情况Fig.6 Changes in data transmission rate over time
进一步测试内容请求者需求不同大小内容时,传输时间长度的情况。即从内容请求者生成第一个兴趣包到它收到所有内容的时间差。结果如图7 所示,提出的机制在不同内容大小下都耗费了最短的时间。而且随着内容大小的增长,传输时间比另外两种算法的传输时间优势也随之增长,最多可分别达到约36.2%(CHoPCoP)和25.6%(CHoPCoP-impro)。
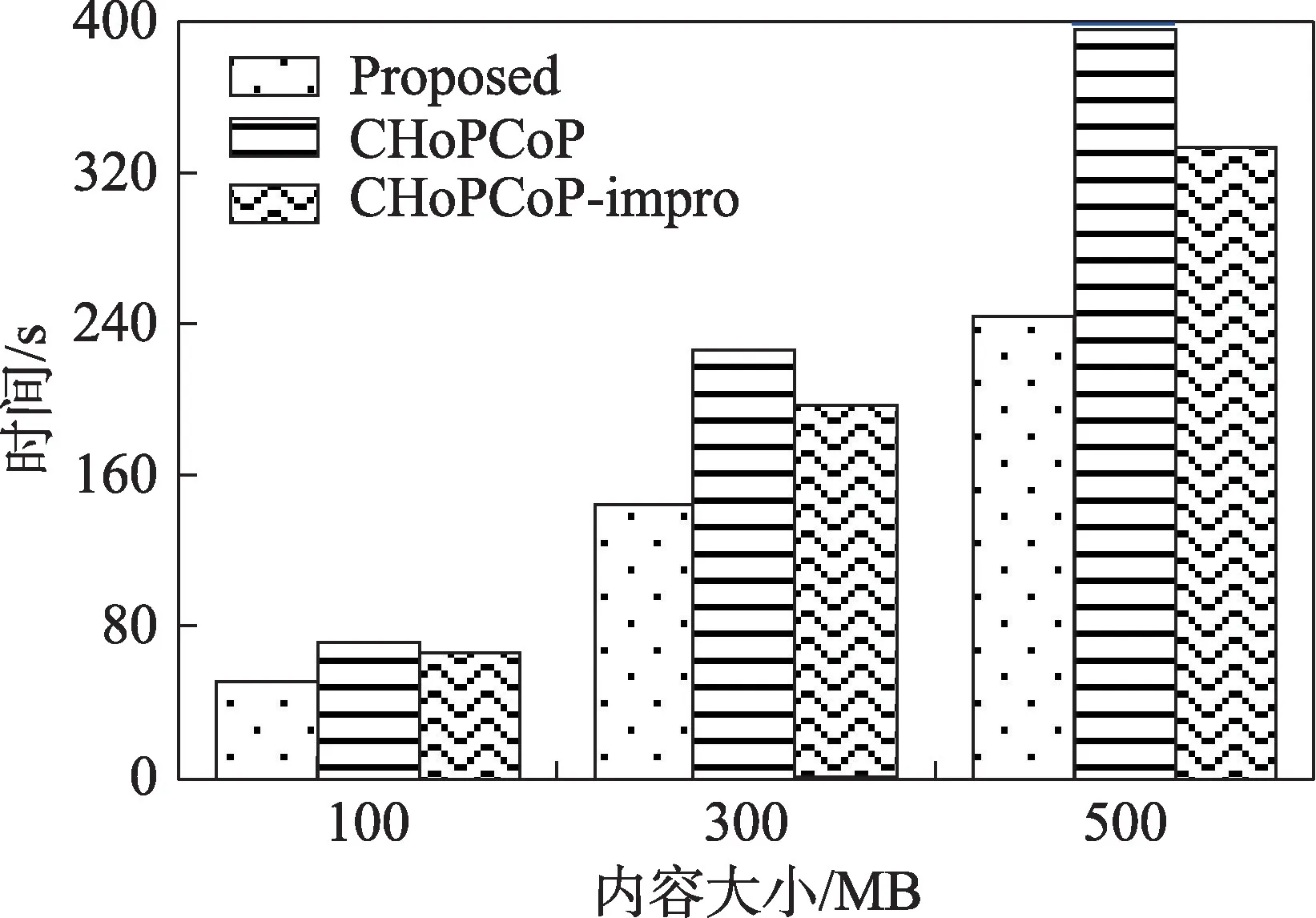
图7 传输时间比较Fig.7 Comparison of transmission time
接着测试新增数据流情况下的机制稳定性。即在0 s 时,1 开始向1 请求数据,在10 s 时2 开始向2 请求数据,测量1 和2 的数据流传输状态达到平衡所需时间。运行30 次实验,测量两个流达到动态平衡所需时间,统计这30 个实验结果的概率分布函数,如图8 所示。可以看出,本文提出的机制达到平衡所需时间以90%概率小于163 ms,CHoPCoP算法达到平衡所需时间以90%概率小于237 ms,CHoPCoP-impro 算法达到平衡所需时间以90%概率小于253 ms。因为CHoPCoP-impro 算法每个周期内只调整一次拥塞窗口和发送速率的变化,滞后了达到平衡时间,整体恢复平衡时间要大于CHoPCoP算法。

图8 数据流达到平衡所需时间的累计分布函数Fig.8 Cumulative distribution function of time required for data flow to reach equilibrium
进一步测试多个数据流共享瓶颈带宽时,各个算法的性能。考虑到AR/VR 应用对带宽和时延有严格要求,以保证应用的服务质量,因此适用于AR/VR场景的拥塞控制算法应能检测链路带宽是否能满足传输性能要求,并进行链路选择。逐渐增加内容请求者和内容提供者的数量,最开始只有1 请求数据,每5 s 后增加一个数据请求者,直到三个内容请求者都请求数据。
图9 显示了多个数据流传输速率到达平衡时的带宽占用情况。可以看到,由于提出算法在数据流加入时会将带宽进行重新分配,在流达到平衡时,数据流1(1-1)和2(2-2)占用带宽比例相同,即均分可用带宽。当内容请求者3 开始请求数据时,此时瓶颈链路4-5 已经存在两个数据流,如果3请求数据仍从4-5 链路进行传输的话,可分配带宽无法满足AR/VR 初级沉浸场景下的传输带宽要求(20~50 Mbit/s),因此4 节点会把3 发送的兴趣包从另外的接口转发到其他带宽满足需求的路径中,数据流3 使用4-8-5 路径以满足应用需求。因为新加入流难以抢占带宽,CHoPCoP 算法中数据流1 和2 占据更多带宽,数据流3 占据带宽较小。CHoPCoP-impro 算法中,由于减少拥塞窗口时也会减少传输速率,降低队列长度,后续的流可以在刚开始传输时获得一个较大的拥塞窗口,因此虽然同样是最开始的数据流占据最大带宽,但各个数据流占据带宽的差值要小于CHoPCoP 算法。

图9 多流传输时各数据流占用带宽情况Fig.9 Bandwidth occupied by each data stream during multi-stream transmission
图10 显示了多数据流传输时,各个流完成传输所需时间的情况。可以看出,与图9 相对应,本文提出的算法,数据流1 和2 占用带宽相同的情况下,完成传输时间基本相同,数据流3 使用其他带宽更高的路径进行传输,因此完成传输所需时间最小。CHoPCoP 算法中,数据流1 占据带宽最多,因此完成传输所需时间也最小,其次是数据流2,最后是数据流3。CHoPCoP-impro 算法中,结果相似,而数据流2 和3 完成传输时间均小于CHoPCoP 算法中的数据流2 和3,一方面是因为占用带宽大小不同,另一方面则是CHoPCoP 在传输过程中的传输速率波动较大,会造成传输效率的下降。
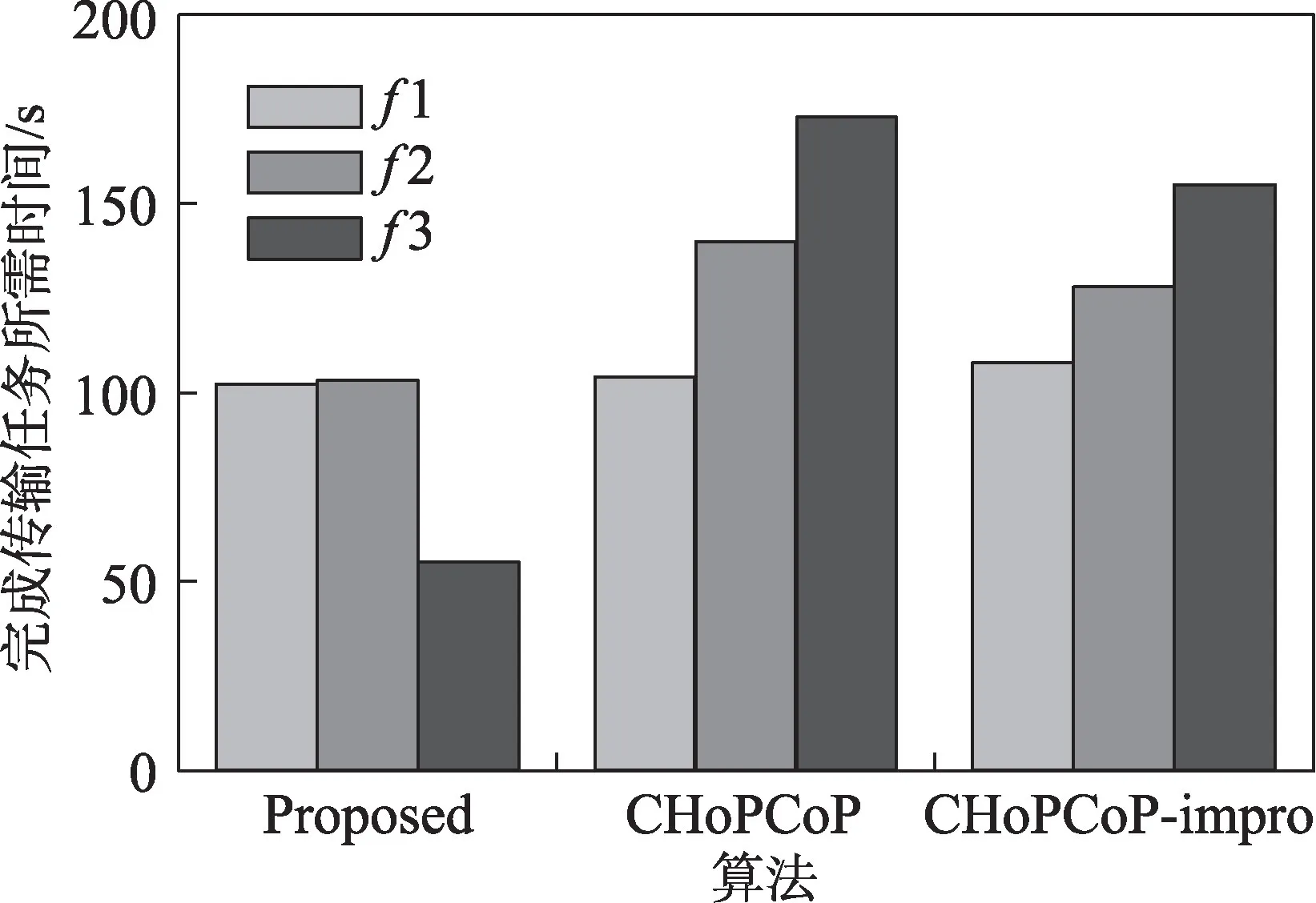
图10 各个数据流完成传输所需时间Fig.10 Time required for each data stream to complete transmission
然后进行了随机丢包测试,即在1 向1 传输数据时,通过在节点设置丢包率,并20 s 触发一次,随机丢弃一定数量的数据包,测试各个算法的传输速率随时间的变化情况以及流完成时间。
图11 显示在网络存在丢包的情况下,三种机制的数据传输速率随时间发展的变化情况。可以看出,本文提出机制的数据传输速率不受丢包因素的影响,这是因为内容请求者根据数据包的Inventory字段,判断是否发生丢包,如果发生丢包的话,内容请求者将丢失的数据包记录在兴趣包的Lost 字段中,内容提供者接收到兴趣包后直接重发丢失的数据包,因此不用减少拥塞窗口和发送速率。CHoPCoP在检测到丢包后会将拥塞窗口减为1,传输速率急剧减少,当发生多个丢包时,算法会持续进入慢启动阶段,因此数据传输速率就会维持在极低的水平。而CHoPCoP-impro 设置为丢包后,不会在兴趣包Lost字段记录丢失数据包清单,只是在Lost 字段标记发生丢包,因此内容提供者会将上一轮传输的数据包进行重传,并不会减少发送速率。
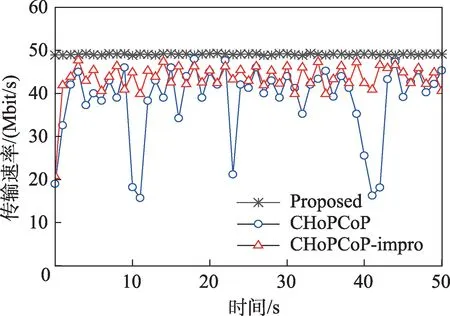
图11 网络存在丢包时数据传输速率的变化Fig.11 Changes in data transmission rate under packet loss on network
图12 表示在网络中存在丢包时,传输时间的比较。可以看出,本文提出的算法只需要按照正常的传输速率将丢失的数据包重传,因此流完成时间并没有发生明显的增加。而CHoPCoP 算法因为丢包触发的持续进入慢启动阶段造成传输速度大幅度下降,额外增加了传输时间,因此流完成时间最大增加了41.6%。CHoPCoP-impro 的传输速率虽然没有变化,但是由于一次丢包要重传上一轮的所有数据包,也会造成传输时间的增加,流完成时间最大增加28.2%。

图12 网络存在丢包时传输时间比较Fig.12 Comparison of transmission time under packet loss on network
最后考虑NDN 的内容缓存特性,即测试中间节点存在缓存时,不同拥塞控制算法的性能。1 向1发送兴趣包请求内容,在中间节点4 处放置1/4的缓存内容,使得部分请求内容可以在4 节点返回给1。
从图13 可以看出,本文提出的机制在4 获取缓存内容时,可以根据1-4 的瓶颈带宽发送数据包,当从内容提供者1 发送的数据包到达4,而4 尚有数据包等待返回时,可以先将数据包缓存在4中,避免队列缓冲区溢出。CHoPCoP算法因为节点缓存的存在,导致从节点缓存返回的数据包不能反馈完整的链路信息,造成拥塞窗口增加过快,导致算法多次进入慢启动阶段,降低数据传输速率。CHoPCoPimpro 在4 尚有缓存内容等待返回时,没有将数据包缓存在4 的CS 中,可能会造成4 处的数据包队列长度超过阈值,甚至发生拥塞,因此会造成拥塞窗口的减少乃至进入慢启动阶段,也会降低数据传输速率。

图13 存在节点缓存时数据传输速率的变化Fig.13 Changes in data transmission rate with node caches
从图14 可以看出,在中间节点存在缓存时,本文提出的机制与CHoPCoP-impro 算法完成所有内容传输所需的时间比没有缓存时的时间更短。本文提出的机制所需时间最短,能减少大约21.6%的传输时间;CHoPCoP-impro 大约减少11.3%的传输时间;而CHoPCoP 在有缓存内容的情况下,内容提供者接收数据包反馈的队列长度存在误差,导致频繁进入慢启动阶段,传输时间反而增加了大约37.5%。
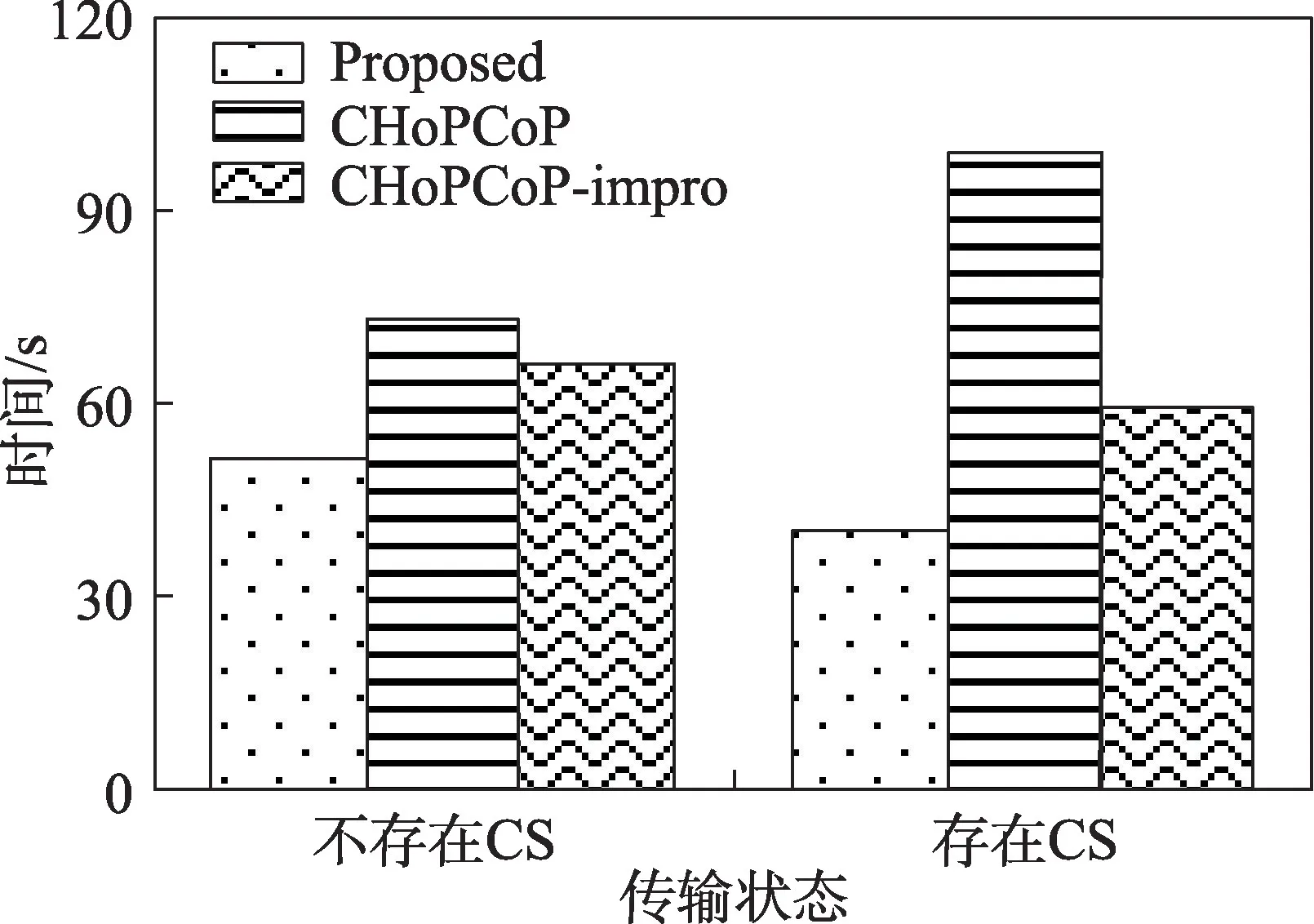
图14 存在节点缓存时传输时间比较Fig.14 Comparison of transmission time with node caches
4 结论与展望
针对NDN 的传输模式在内容较大时需要内容请求者持续发送多个兴趣包才能获取完整内容,传输延时增加,或大量数据包同时返回易造成网络丢包,不适用于AR/VR 等大数据量延迟敏感型应用,以及现有拥塞控制研究忽略内容缓存特性的问题,本文在One-Interest-Multiple-Data 传输模式基础上提出了一种新的链路带宽时延感知的拥塞控制机制。使得内容提供者通过兴趣包收集的路径瓶颈带宽和时延信息计算拥塞窗口和数据发送速率,从而合理地发送数据包,降低传输时延,避免网络拥塞,并且提出了一种缓存标记策略以充分地利用节点缓存,减少传输所需时间。最后,基于ndnSIM 的实验结果表明,本文提出的机制在拥塞窗口、队列长度和数据传输速率等方面取得更好的性能,同时能够以更短的时间完成请求内容的传输。而且在网络中存在丢包和中间节点存在缓存内容时,本文提出的机制达到了更好的性能优势。
在未来的工作中,一方面将设计有效的合作缓存机制,以提高节点之间的合作,使得该拥塞控制机制能更有效地利用中间节点的缓存内容;另一方面将部署原型系统,并在更复杂和实用化的网络拓扑中测试该拥塞控制机制。
猜你喜欢
航空学报(2022年7期)2022-09-05
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
计算机技术与发展(2020年5期)2020-05-22
中国计算机报(2020年15期)2020-05-13
法制博览(2020年2期)2020-04-29
法制与社会(2017年9期)2017-04-18
绿色科技(2017年2期)2017-03-23
法制与社会(2017年5期)2017-03-14
CHIP新电脑(2016年9期)2016-09-21
