
基于启发式Q 学习的FANET 可信路由算法
2022-05-14 03:28:22赵蓓英姬伟峰李映岐
计算机工程 2022年5期
赵蓓英,姬伟峰,翁 江,吴 玄,李映岐
(空军工程大学 信息与导航学院,西安 710177)
0 概述
近年来,无人机广泛应用于民用和军事领域:在民用领域,无人机用于航空摄影、智慧农业、电力巡检等方面;在军事领域,无人机用于情报侦查、军事打击、电子对抗等任务[1]。单架无人机的载荷与能量有限且覆盖范围小,无法完成大规模、高难度的任务,因此,无人机自主集群成为趋势[2]。无人机自组织网络(Flying Ad hoc Network,FANET)不依赖固定的基础设施,通过各无人机节点协同通信,是实现自主集群的关键技术[3]。但是,FANET 中节点的高机动性、网络开放性与拓扑变化频繁等特点,导致网络路由面临性能与安全方面的双重考验[4]。
本文提出一种基于启发式Q 学习的可信路由(Heuristic Q-learning based Trusted Routing,HQTR)算法。将FANET 中的路由选择问题映射为有限马尔科夫决策过程,并提出模糊动态信任奖励机制,针对路由层面的黑洞攻击与泛洪攻击,考虑节点的转发行为与路由请求发送速率,通过模糊推理计算节点的信任值,根据信任值与跳数计算节点的奖励值。结合单跳链路状况设计启发式函数,加速最优可信下一跳节点Q 值的更新,引导当前节点选择最优可信下一跳节点。同时在路由过程中,根据信任值检测并隔离恶意节点,从而实现安全可靠且高效的数据传输。
1 相关工作
在高动态的FANET 中,路由协议应该能够自适应地感知环境的变化,选择一个可靠的邻居节点来完成通信。强化学习是一种以环境反馈为输入的自适应机器学习算法,智能体可以根据环境反馈来不断调整行动策略,从而更好地适应动态的网络环境,因此,强化学习常被用于改进自组织网络的路由算法,以提高服务质量[5]。
在路由性能优化方面,强化学习算法主要用于优化不同的服务质量参数,如端到端延迟、吞吐量、数据包投递率、跳数、路由开销等[6]。文献[7]提出一种基于Q-learning 的无人机网络地理路由协议QGeo,该协议采用强化学习算法,根据数据包传输速度计算奖励值,同时根据邻居节点的距离调整折扣因子,选择Q 值最高的节点作为下一跳节点。文献[8]提出一种基于Q-learning 的多目标优化路由协议QMR,其考虑时延与剩余能量设计奖励函数,根据节点的邻居关系调整学习率与折扣因子,从而为FANET 提供低延迟、低能耗的通信服务质量。模糊数学能够很好地处理信息的不确定性与不完整性,同时可以融入人类专业知识,适用于自组织网络高度动态的网络环境[9]。文献[10]提出一种改进的AΟDV 协议PFQ-AΟDV,其利用链路带宽、链路质量以及车辆方向、速度变化的模糊推理结果修正Q 值更新函数,在路由发现过程中选择Q 值最大的邻居节点作为下一跳节点。文献[11]提出一种基于模糊Q-learning 的路由算法FQ-AGΟ,该算法考虑可用带宽、链路质量、节点传输功率和距离,利用模糊逻辑来评估无线链路,采用Q-learning 算法选择最优的下一跳节点。针对Q-learning 算法效率低的问题,文献[12-13]引入启发式函数指导动作的选取,提出启发式Q-learning。文献[14]结合节点间的延迟信息来指导节点的转发行为,设计启发式函数和评价函数,加快当前最优动作Q 值的更新,减少不必要的探索,从而提高Q-learning 过程的收敛速度以及学习效率。
采用信任模型是确保自组织网络路由安全性与可靠性的有效措施之一[15]。文献[16]抽象出一种分布式信任推理模型,采用直接信任度、间接信任度、历史信任度、链路质量等作为信任评估因子,通过模糊层次分析法来确定权重,提出一种轻量级信任增强路由协议TEAΟMDV。文献[17]将信任机制与Q-learning 算法相结合,根据节点转发行为确定节点的可信度,并将其作为奖励值,选择满足剩余能量要求的最大Q 值节点,以有效应对槽洞攻击与黑洞攻击。文献[18]针对VANET中的窃听、干扰和欺骗攻击,通过信任模型评估节点对VANET 的威胁级别,采用区块链技术防止信息篡改,基于Q-learning 决定是否响应源节点的请求或选择可靠的中继节点。针对SDN架构的VANET,文献[19-20]采用信任模型评估邻居转发数据包的行为,以应对恶意节点的丢包攻击,SDN 控制器作为Agent,通过深度强化学习确定VANET 中最可信的路由路径。
随着FANET 的发展,其承载的业务更加复杂繁重,安全威胁层出不穷,对路由算法的性能与安全性都提出了更高的要求。然而,目前大多数算法仅关注性能优化或安全防护,为了有效应对潜在的恶意攻击,同时优化算法性能并提高服务质量,需要设计实现一种安全、高效且可靠的路由算法。
2 系统模型
2.1 多跳FANET 模型
本文考虑一种多无人机协同作业场景,无人机之间形成自组织网络,不依赖地面站即可完成机间通信,从而摆脱地面站对无人机群活动范围的限制,扩大网络覆盖区域[21]。如图1 所示,无人机节点同时充当终端与路由器,邻居节点直接通信,非邻居节点可通过其他节点作为中继节点进行多跳通信。多跳FANET 模型的关键在于找到一条最优路径,能够在低延迟、低开销的情况下安全传输数据。
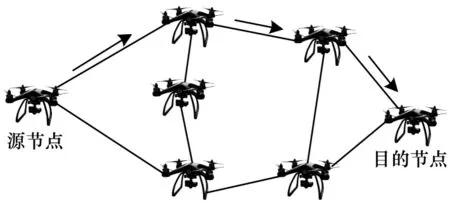
图1 多跳FANET 模型Fig.1 Multi-hop FANET model
2.2 攻击模型
针对FANET 路由层面存在的攻击,根据其特征的不同可分为以下3 类:
1)以丢包为特征的攻击,如黑洞、灰洞、选择性转发攻击。
2)以篡改、伪造报文为特征的攻击,如槽洞、黑洞、灰洞、虫洞攻击。
3)以泛洪为特征的攻击,如Hello 消息泛洪攻击、RREQ 消息泛洪攻击。
本文假设攻击者具有以下破坏能力:
1)外部攻击者可以捕获网络内部节点,将其转化为一个恶意节点。
2)内部攻击者或被转化的恶意节点可以篡改路由信息,如篡改路由回复报文、欺骗邻居节点其距离目的节点最近,从而加入转发路径,继而发动黑洞、灰洞等攻击,丢弃接收到的数据包。
3)内部攻击者或被转化的恶意节点不受路由请求发送速率的限制,利用RREQ 泛洪特性不断广播虚假的请求报文,淹没正常请求,占用网络资源,造成网络拥塞。
2.3 安全目标
为保证多跳FANET 中无人机节点间的通信安全并协同完成通信任务,本文考虑以下安全目标:
1)检测与防范黑洞、灰洞等丢包类攻击与路由请求RREQ 消息泛洪攻击。
2)通过验证节点之间的可信度,隔离内部恶意节点。
3)提供从源节点到目的节点的安全数据传输,实现高吞吐量和高数据包投递率,控制网络开销,优化平均端到端时延。
3 基于启发式Q-learning 的可信路由算法
3.1 FANET Q-learning 模型
Q-learning 是基于有限马尔科夫决策过程的强化学习算法,主要由智能体(Agent)、环境(Environment)、状态(State)、动作(Action)组成,如图2 所示[22]。智能体在执行某个动作后,环境将转换到一个新的状态并给出奖励(Reward)信号,随后智能体根据新的状态和环境反馈的奖励,按照一定的策略执行新动作。
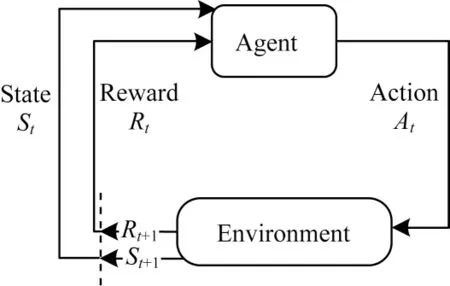
图2 马尔科夫决策过程Fig.2 Markov decision process
本文将FANET 中的路由选择问题描述为一个马尔科夫决策过程,给出如下定义:
1)基本组件。
(1)学习环境:整个FANET 网络环境,包括无人机节点、通信链路等。
(2)智能体:FANET 中每个无人机节点作为学习主体Agent。
(3)状态空间:本节点以外其余节点构成该节点的状态空间。
(4)动作空间:动作表示节点在数据传输时对下一跳节点的选择,动作空间为其邻居节点。
2)奖励。
将节点对下一跳节点的可信度评估作为奖励信号,表示节点动作选择的可靠性。奖励值函数定义如式(1)所示:
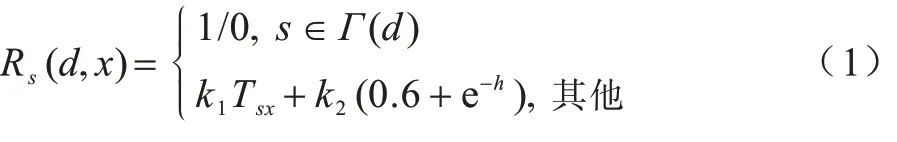
其中:Γ(d)表示目的节点的邻居节点集,目的节点为当前节点的可信邻居节点时,奖励值为1,否则奖励值为0;Tsx表示当前节点s通过邻居节点x作为中继节点传输数据的可信程度;h为节点x距离目的节点的跳数。可信度越高,跳数越少,奖励值越高。
3)Q 值更新函数。
Q-learning 的动作值函数更新如式(2)所示:
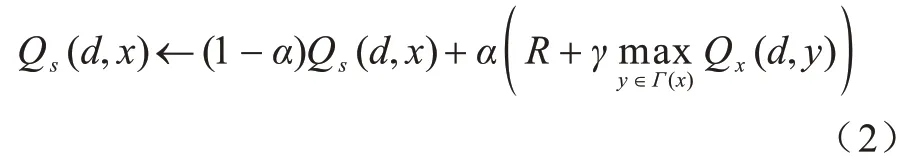
其中:Qs(d,x)表示当前节点s选择x作为下一跳到达目的地d的Q 值表示节点x选择y作为下一跳到达目的地d的Q 值;y为x邻居节点中Q 值最大的点;α为学习率;γ为折扣因子。每个节点维护一个Q 表,节点将最大Q 值添加到Hello 消息中,通过定期交换Hello 消息来更新Q 值。学习任务分配到每个节点,使算法能够快速收敛到最优路径,并依据网络拓扑的变化进行及时调整。
3.2 模糊动态信任奖励机制
针对FANET 中的黑洞攻击与RREQ 泛洪攻击,本文提出一种模糊动态信任奖励机制,该机制包括模糊化处理、模糊推理和去模糊化3 个步骤,实时监测节点的数据包转发率、RREQ 发送速率,周期性地计算节点可信度,并将其作为节点的奖励值。该机制的具体流程如图3 所示,其中,数据包转发率、RREQ 发送速率计算公式如式(3)、式(4)所示,NRDP为节点接收到的数据包个数,NFDP为转发的数据包个数,τ为信任计算周期,NRREQ为一个周期内节点发送的路由请求报文个数。

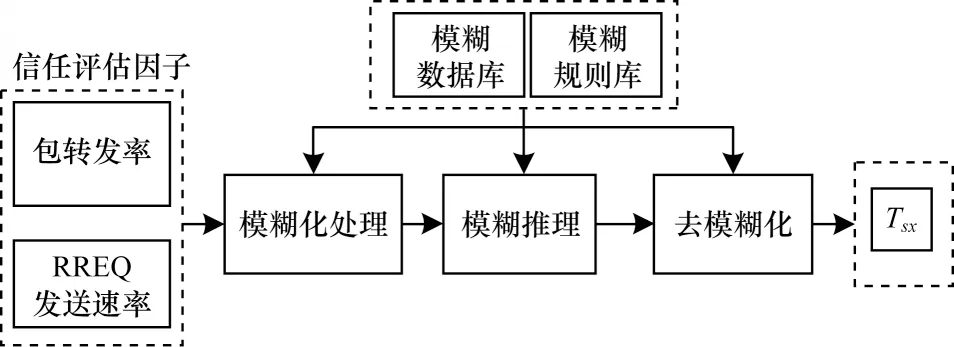
图3 模糊动态信任奖励机制流程Fig.3 Procedure of fuzzy dynamic trust reward mechanism
本文模糊动态信任奖励机制各步骤具体如下:
1)模糊化处理。定义数据包转发率与RREQ 发送速率的模糊隶属函数如图4(a)、图4(b)所示,参考文献[23],将数据包转发率分为3 个等级,RREQ 发送速率分为2 个等级,利用隶属函数将其转换成模糊值。
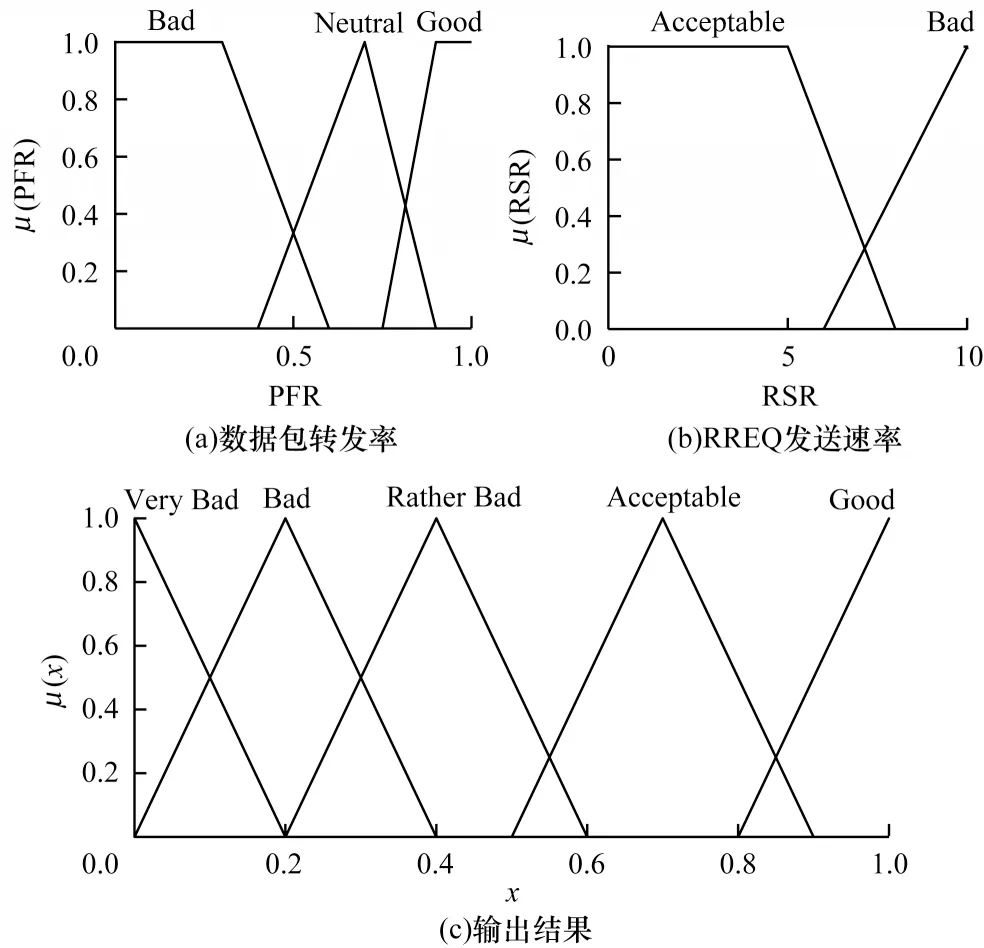
图4 模糊隶属函数Fig.4 Fuzzy membership function
2)模糊推理。定义模糊规则库如表1 所示,根据模糊规则库进行模糊推理,输出信任值对应的模糊等级与隶属度。
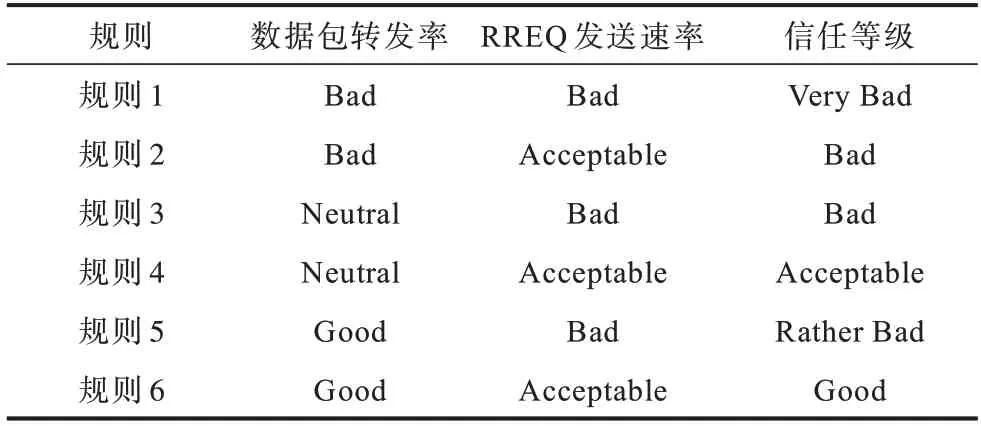
表1 模糊规则库Table 1 Fuzzy rule base
3)去模糊化。定义输出信任值的隶属函数如图4(c)所示,采用隶属度加权平均法对模糊推理结果进行去模糊化处理,计算方式如式(5)所示。模糊推理输出一个信任等级,根据该等级的隶属度函数及隶属度得到对应的信任值,有2 个点则取平均值。若对应多个信任等级,则分别求出其对应的信任值,再以归一化后的隶属度作为权重系数,加权平均得到最终信任值。
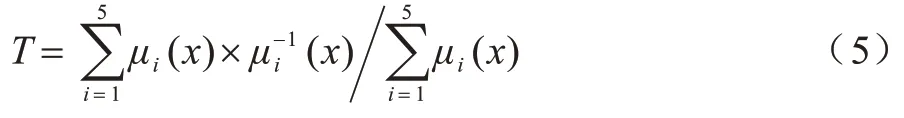
3.3 启发式路由选择算法
在FANET 环境下,Q 值的更新速度受到Hello 消息发送间隔的限制,间隔过小将加重网络负载,间隔过大将无法及时感知拓扑变化,导致算法收敛速度变慢。同时,大多数算法根据Q 值采用贪婪策略选择下一跳,然而高可信度节点可能链路状况较差,并非最佳下一跳节点,这也会增加高可信度节点的负担。因此,本文提出一种基于启发式Q 学习的路由选择算法,通过利用-探索平衡策略,根据单跳延迟与链路质量来确定当前最优的可信下一跳节点。启发式评价函数用于更新当前最优动作的Q 值,若节点x为最优可信下一跳,为其赋予一个适当的启发值,引导当前节点选择该节点作为下一跳,以加快收敛速度,提高路由算法的效率。
3.3.1 利用-探索平衡策略
当选择转发数据包的邻居节点时,HQTR 算法不直接选择Q 值最大的下一跳节点,而采用改进的标准贪婪策略选择动作,如式(6)所示:
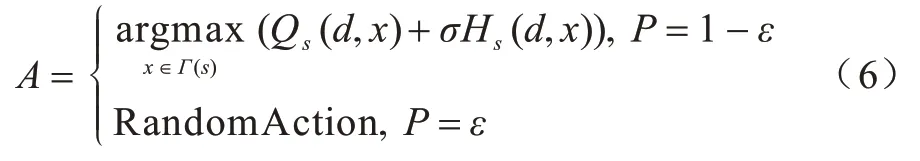
其中:A表示选取的动作,即下一跳节点;Hs(d,x)表示当前最优动作的启发式函数值;σ∈[0,1]是度量启发式函数影响程度的实数,本文中取σ=1;P=ε表示算法以一定的概率ε随机选择下一跳节点,即智能体在环境中“探索”;P=1-ε表示算法以1-ε概率选择价值最大的邻居节点作为下一跳节点,即智能体直接“利用”已经探索得到的信息。
3.3.2 最优动作确定
多跳路由的效率取决于构成该路由的所有直接无线链路(即单跳链路),因此,为提高通信服务质量,本文考虑单跳节点间的链路状况,包括单跳延迟与链路质量,通过衡量单位时间内接收Hello 消息的平均单跳延迟与数量,确定最优可信下一跳。最优可信下一跳定义如式(7)所示,其中:AADelay为平均单跳延迟,计算方式如式(8)、式(9)所示;HHRR为Hello包接收率,计算方式如式(10)所示;TA*为当前节点对下一跳节点的信任值;θ为可信阈值。平均单跳延迟越小,Hello 包接收率越高,表明其与该节点之间的链路状况越好,此节点将被确定为最优可信下一跳。
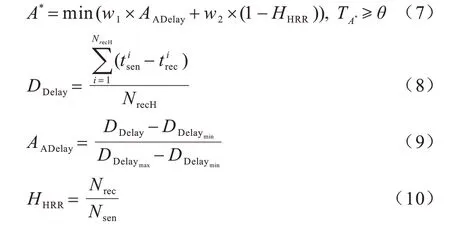
3.3.3 启发式函数
当确定最优可信下一跳节点后,启发式函数Hs(d,x)引导当前节点选择该节点并更新相应的Q值。启发式函数定义如式(11)所示,其中,η取0.01。若节点x为最优可信下一跳,为其赋予一个适当的启发值,否则启发值为0。Hs(d,x) 的值必须大于Qs(d,x)值之间的变化,以便其可以影响动作选择,同时为了最小化误差,Hs(d,x)必须尽可能小。
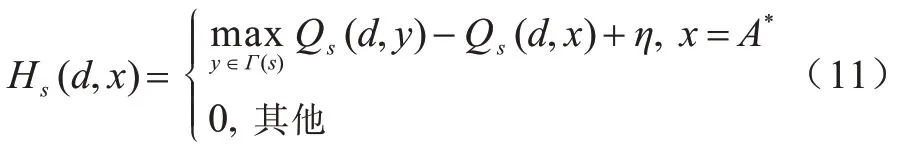
综上,将启发式路由算法主要分为Hello 消息维护、数据传输、路由发现、恶意节点隔离4 个部分,描述如算法1 所示,将该算法应用于AΟMDV 协议中,建立多条可信路径,便于在链路中断、恶意节点破坏时进行路径切换。
算法1HQTR 算法

本文HQTR 算法的复杂度主要与信任值、Q 值和启发式函数值的更新相关,三者的时间复杂度与空间复杂度相同,分别为Ο(N)、Ο(N2)、Ο(N2),因此,算法1 的时间复杂度与空间复杂度均为Ο(N2)。
4 仿真结果与分析
本文采用NS2 模拟器进行仿真实验,具体参数设置如表2 所示,基于包投递率、吞吐量、路由开销、平均端到端时延这4 个性能评价指标,对AΟMDV、TEAΟMDV[16]、ESRQ[17]与HQTR 进行仿真对比,分析恶意攻击、节点移动速度与网络规模对算法性能的影响,比较结果如表3 所示。
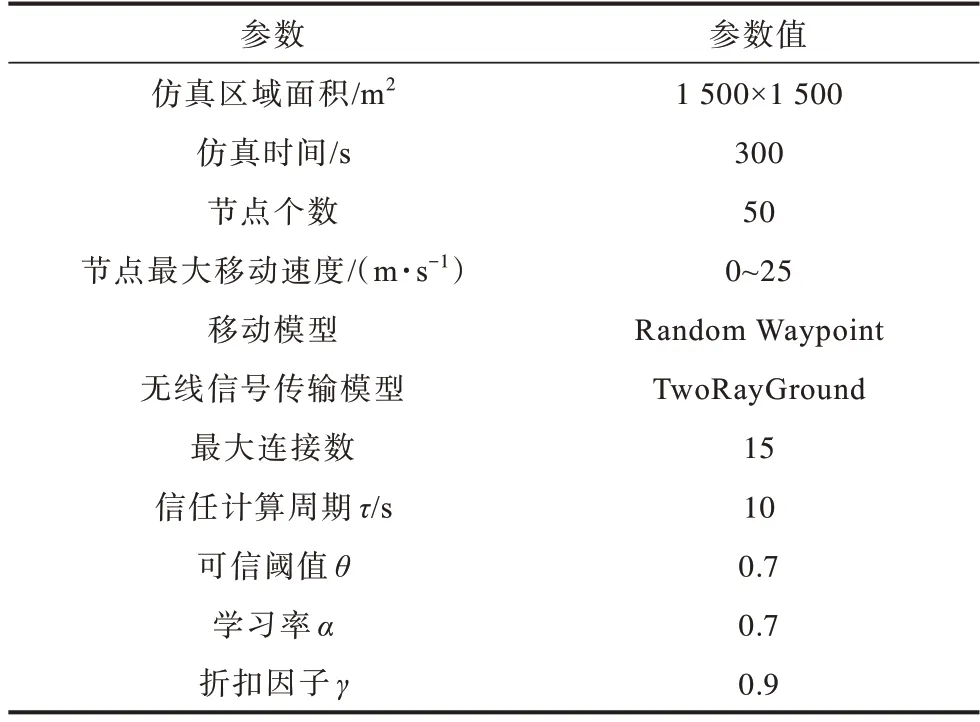
表2 仿真参数设置Table 2 Simulation parameters setting
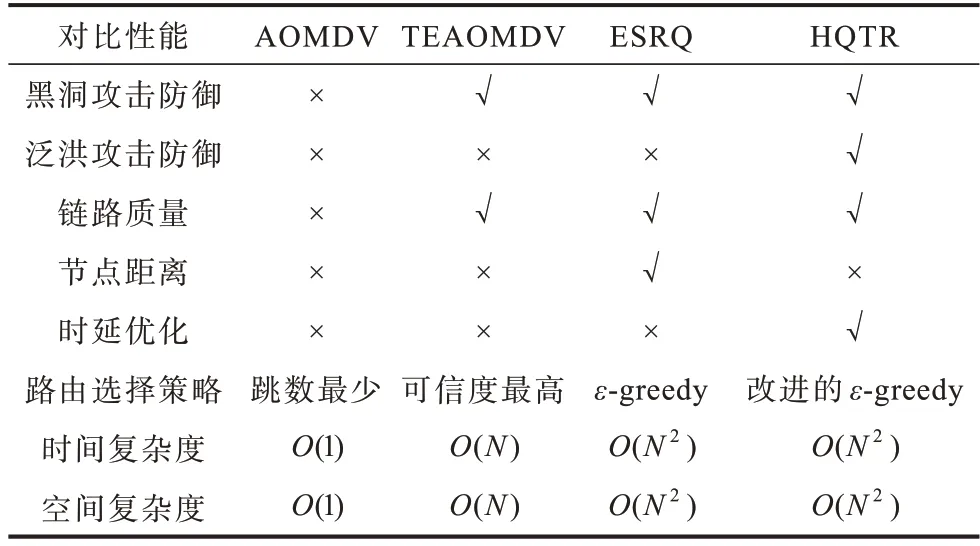
表3 算法性能比较结果Table 3 Algorithms performance comparison results
4.1 恶意攻击下的算法性能评估
设置节点最大移动速度为10 m/s,黑洞攻击中设置6 个恶意节点,泛洪攻击中设置1 个恶意节点,2 种攻击并存时设置3 个恶意节点,仿真结果如图5所示。
由图5(a)可知,在未受到攻击时,包投递率都保持在90%以上,TEAΟMDV 与HQTR 选择了链路质量较高的下一跳节点,ESRQ 考虑距离因素,包投递率略高于AΟMDV。当受到黑洞攻击时,AΟMDV 包投递率有所下降,而TEAΟMDV、ESRQ 与HQTR 隔离了恶意节点,包投递率下降幅度较小。当存在泛洪攻击节点时,大量的RREQ 消息被不断地转发,占用了有效带宽,导致数据包得不到及时处理而被丢弃,AΟMDV、TEAΟMDV 与ESRQ 包投递率下降,而HQTR 丢弃了来自恶意节点的路由请求,包投递率下降幅度较小,降低了泛洪攻击对网络的影响。当恶意节点同时发动2种攻击时,TEAΟMDV 与ESRQ 虽然能够检测出黑洞攻击,但恶意节点的请求仍然能够被发送与转发,而HQTR可以同时应对2 种攻击,包投递率更高。
由图5(b)可知,AΟMDV 由于受到恶意节点的攻击,丢包状况严重,网络吞吐量下降,TEAΟMDV与ESRQ 在一定程度上防御了黑洞攻击,提升了吞吐量,但无法应对泛洪攻击,当存在泛洪攻击时,两者的吞吐量较低,HQTR 能够有效应对黑洞攻击与泛洪攻击,吞吐量始终保持较高水平。
由图5(c)可知,在未受到攻击时,HQTR 与AΟMDV、ESRQ 路由开销相近,而TEAΟMDV 略高,表明在正常情况下HQTR 未引入冗余开销。当受到黑洞攻击时,隔离恶意节点需要路径切换或重新建立新路径,HQTR 的路由开销相比TEAΟMDV 与ESRQ 更低,选择的路径更加安全可靠。当受到泛洪攻击时,恶意节点不断发送请求报文,同时这些报文也被其他节点转发,导致路由开销大幅上升。HQTR 将不再接受恶意节点的请求,抑制了RREQ的传播,控制了路由开销,但不能阻止恶意节点发送RREQ,因此,其路由开销相比正常情况高。当恶意节点同时发动2 种攻击时,TEAΟMDV 与ESRQ 中部分节点由于检测出黑洞攻击而隔离了恶意节点,降低了路由开销,但恶意节点的请求仍能被其他节点接收并转发,因此,TEAΟMDV 与ESRQ 的路由开销高于HQTR。同时,TEAΟMDV 需要发送额外的控制包用于信任推荐,其路由开销较ESRQ 更高。
由图5(d)可知,在未受到攻击时,HQTR 平均端到端时延较低,当受到黑洞攻击时,平均端到端时延均有所上升,TEAΟMDV 略高,TEAΟMDV 将恶意节点从路径中剔除后,需重新选择可信路由路径,可能会增加跳数,从而导致时延增大。ESRQ 优先选取距离较近的下一跳,平均端到端时延低于TEAΟMDV。HQTR在选择下一跳时考虑跳数、单跳延迟与链路质量,优化了时延。当存在泛洪攻击时,由于网络中充斥大量请求报文,产生拥塞,时延明显上升,HQTR缓解了网络拥塞,其时延相比TEAΟMDV 与ESRQ更低。

图5 恶意攻击下的算法性能比较Fig.5 Performance comparison of algorithms under malicious attacks
4.2 不同节点移动速度下的算法性能评估
设置3 个恶意节点,同时进行黑洞攻击与泛洪攻击,仿真结果如图6 所示。由图6 可知,随着节点移动速度的提升,链路中断频繁,丢包状况严重,包投递率与吞吐量均不断下降,同时需要发送更多的控制包用于路由发现与维护,路由开销与平均端到端时延有所上升。ESRQ 仅考虑了距离因素,而节点移动速度过大时,链路质量不稳定,因此,其包投递率与吞吐量较低,路由开销与平均端到端时延也逼近TEAΟMDV。HQTR 避免了存在恶意节点以及丢包严重节点的路径,通信链路较为稳定,相比TEAΟMDV 与ESRQ,其包投递率与吞吐量下降缓慢,始终保持较高水平,同时降低了路由开销与平均端到端时延。
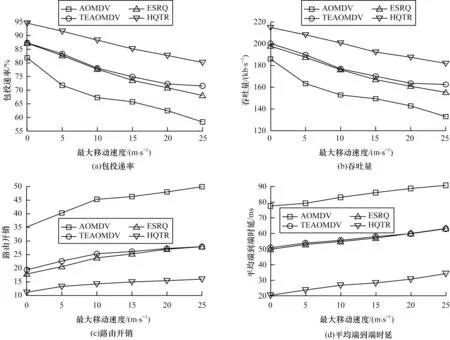
图6 不同节点移动速度下的算法性能比较Fig.6 Performance comparison of algorithms under different node moving speeds
4.3 不同网络规模下的算法性能评估
设置节点最大移动速度为10 m/s,3个恶意节点同时进行黑洞攻击与泛洪攻击,仿真结果如图7所示。由图7可知,在相同的飞行范围内,当网络中节点数量较少时,数据包转发跳数较多,由于无线链路的不稳定性,导致数据包投递率与吞吐量略低。随着网络规模的扩大,恶意节点造成的破坏更加严重,导致数据包投递率与吞吐量不断下降,路由开销与平均端到端时延不断上升。HQTR能够有效抵御恶意节点的黑洞攻击与泛洪攻击,其相比AΟMDV、TEAΟMDV与ESRQ性能更优且稳定。

图7 不同网络规模下的算法性能比较Fig.7 Performance comparison of algorithms under different network sizes
5 结束语
本文提出一种基于启发式Q 学习的可信路由算法HQTR,该算法考虑黑洞攻击、RREQ 泛洪攻击的主要攻击特征,检测与隔离恶意节点,建立多条可信路径,采用启发式Q 学习引导当前节点选择链路状况最佳的可信下一跳节点。仿真结果表明,HQTR 能够有效应对黑洞攻击与RREQ 泛洪攻击,在不增加路由开销的情况下可以降低网络拓扑频繁变更与网络规模变化所带来的影响,提高数据包投递率与吞吐量,优化平均端到端时延。下一步将运用深度学习方法对FANET 中存在的多种路由攻击进行入侵检测,同时在路由选择时结合强化学习方法来实现安全且智能的路由。
猜你喜欢
工业设计(2023年1期)2023-03-02 10:08:12
中外文摘(2022年13期)2022-08-02 13:46:16
现代装饰(2021年6期)2021-12-31 05:28:36
意林·全彩Color(2019年6期)2019-07-24 08:13:56
环球时报(2019-04-11)2019-04-11 11:46:25
网络安全和信息化(2018年4期)2018-11-09 12:01:54
红领巾·萌芽(2015年5期)2015-06-16 02:35:40
中国新通信(2014年11期)2014-09-11 19:27:52
延河(下半月)(2014年2期)2014-02-28 21:06:10
深圳信息职业技术学院学报(2013年3期)2013-08-22 11:42:30
