
AMR 文本生成的数据扩充方法
2022-05-14 03:28:06付叶蔷李军辉
计算机工程 2022年5期
付叶蔷,李军辉
(苏州大学计算机科学与技术学院,江苏苏州 215006)
0 概述
抽象语义表示(Abstract Meaning Representation,AMR)[1]是一种新的语义表现形式,其将自然语言文本以句子为单位抽象成单根有向无环图。随着大规模标注语料的发布使用,AMR 技术受到广泛关注[2],在自然语言处理领域机器翻译[3]、问答系统[4]等多个任务中得到了成功应用。AMR 文本生成是指AMR 图到文本的转换。早期的AMR 文本生成研究多采用基于统计的方法。文献[5]使用两阶段方法,设计一个基于对齐树到字符串的规则,先将AMR 图拆分成多个树结构,再使用基于规则的方法将多个树转换器翻译为文本序列。文献[6]采用启发式学习的方式,使用提取算法学习图到字符串(graph-to-string)的转换规则,提高了AMR 图到文本任务的转换性能。近期研究更多的是将AMR图到文本的转换视为一个机器翻译任务,使用深度优先遍历算法获得AMR 图的线性化形式。文献[7]先将输入的AMR 图根据广度优先遍历将其线性化,再采用基于短语的机器翻译系统生成AMR 文本。文献[8]将Seq2Seq 框架应用在这项任务上,取得了较好的性能。为使生成的文本句法合理化,文献[9]又使用了额外的语法信息,提高了基于序列到序列方法的AMR 文本解析性能。
为解决AMR 图线性化后原图结构化信息丢失的问题,相关研究采用了图到序列(graph-to-sequence)的模型。例如,文献[10]提出了基于Transformer 模型对AMR 图结构的编码方法。文献[11]使用基于图结构的自编码方式,将编码后的图结构信息重新还原为序列形式的AMR 与三元组关系,以此减少AMR 图线性化后图结构信息的损失,从而提高AMR 文本生成的性能。文献[12]采用图注意力机制对输入的图信息进行编码,并通过节点间的语义关系和距离实现对图结构的重构。文献[13]使用最短路径算法,通过获得更多图结构的上下文信息提高了AMR 文本生成的性能。文献[14]借助预训练方法实现了跨语言的AMR 文本生成。文献[15-16]利用图神经网络对AMR 图进行编码。文献[17]从AMR 概念图与其关系图的角度进行图结构编码。
AMR 文本生成的性能在很大程度上受语料规模的影响,因此,可通过引入大规模自动标注语料来提高模型的性能。不同于简单地使用大规模自动标注语料,本文对现有标注语料进行动态数据扩充,以增强模型的健壮性。同时对AMR 文本生成的目标端,即自然语言句子进行动态扩充,在加载目标端句子时对单词做随机噪声化处理,增强目标端语言模型对句子的表达能力。在此基础上,使用ΟpenNMT框架作为Transformer 的基准模型[18],在仅使用人工标注语料和同时使用大规模自动标注语料这两个场景下,验证本文方法的有效性。
1 背景知识
1.1 AMR 文本生成
抽象语义表示是一种新的语义表现形式,其将自然语言文本以句子为单位抽象成单根有向无环图。以句子“The dog ate the bone that he found.”为例,其对应的AMR 图如图1 所示,其中,“eat-01”和“find-01”节点称作概念节点(concept),对应自然语言句子中的实词,两节点之间的边表示所连接的概念节点间的关系,例如“:ARG0”和“:ARG1”分别表示施事者和受事者。特别地,可以将AMR 文本生成视作一个序列到序列(Sequence-to-Sequence,Seq2Seq)的翻译任务,其中源端是AMR 图,目标端是文本。
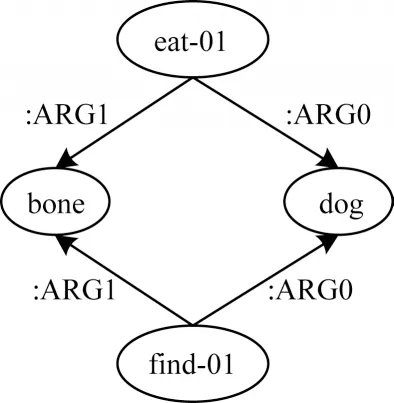
图1 AMR 图示例Fig.1 Example of AMR graph
1.2 数据扩充
数据扩充的目的是为了在有限的数据基础上产生更多可使用的数据,以此增加训练样例的多样性,提高模型的健壮性。目前,数据扩充技术在自然语言处理领域已得到广泛应用。
数据扩充方法可概括为两大类:一类是以句子为单位,从句子级别出发从而得到更多可靠的、高质量的训练样例,从而提高模型的泛化能力;另一类是以单词为单位,从单词角度出发,对句子中的单词进行随机交换、替换等,采用此方法可得到带有噪声的数据,从而提高模型的健壮性。
反向翻译[19]是一种句子级别的数据扩充方法,其在无监督机器翻译上得到广泛应用,有效提高了无监督机器翻译的性能。本文在实验中使用的大规模自动标注AMR 语料即采用反向翻译策略生成。具体地,先在已标注的AMR 平行语料上训练出一个与AMR 文本生成任务相反的模型,再通过该模型输入已处理的序列化英文文本句子得到AMR 图序列化形式,最终得到一份自动标注的AMR 伪平行语料。
与句子级别的方式相比,单词级别的扩充方式获得了更多的研究与应用。文献[20]设定窗口,并固定其长度,在窗口内将单词随机和相邻的单词进行替换。文献[21]先在大规模单语语料上训练得到语言模型,再通过该语言模型找到可以被低频词汇替换的高频词汇,有效地缓解了数据稀疏问题。文献[22]提出一种融合多个单词信息的方法,首先训练一个语言模型,然后把语言模型预测出的下一个单词概率分布作为每个候选单词嵌入表示的权重,最后线性组合词表中每个单词的嵌入表示作为要替换的单词。
借鉴BERT[23]设计思想,本文将AMR 文本生成模型解码端看作为一个语言模型,使用单词级别的扩充方法,通过动态地对目标端单词进行随机替换,得到带噪声的数据,从而增强模型的泛化能力,提高AMR 文本生成的性能。
2 基于Transformer 的AMR 文本生成
本文使用Seq2Seq 的Transformer 模型作为AMR 图到文本转换的基准模型。Transformer 模型由编码器和解码器两部分组成,解码器和编码器又分别由多个相同结构的层次堆叠而成。编码器层由自注意力层和前馈神经网络组成。同样,解码器中也有自注意力层和前馈层。除此之外,在上述两个层之间还有一个注意力层,该层主要用来关注输入句子的相关部分,同其他Seq2Seq 模型的注意力机制作用相似。
为使AMR文本生成任务更好地应用在Transformer模型,需要对AMR 图进行线性化处理。同时,为了解决数据稀疏问题,本文通过子词化处理,将低频词汇单元拆分成更小粒度的高频子词单元[24]。由于该任务的源端和目标端存在大量的共同词汇,因此本文使源端和目标端共享词汇表。
2.1 线性化预处理
本文采用文献[25]中实验所使用的AMR 图线性化处理方法。该方法先对AMR 图作简化处理,即删除变量、wiki 链接、谓词意义后缀等得到AMR树。由于AMR 图中的变量不携带语义信息且仅用于指示共同节点,因此移除变量、删除wiki 链接等不会损失AMR 图中原有的主要信息,故可采用此方法将AMR 图转化为AMR 树。最后,使用空格替换AMR 树中的换行符,从而得到序列化的AMR图。图2 给出了一个AMR 图和线性化后AMR 序列的示例。

图2 AMR 图线性化示例Fig.2 Example of AMR graph linearization
2.2 子词化处理
为了解决低频词翻译数据稀疏的问题,文献[9]使用了匿名机制,但由于需要人工制定匿名化规则,因此极大地增加了成本。受机器翻译领域解决低频词翻译问题的启示,本文采用有效可行的字节对编码(Byte Pair Encoding,BPE)[24]方法。BPE 方法的基本思想是将原低频词汇单元拆分成更小粒度的高频子词单元。BPE方法在机器翻译领域的使用,极大地提高了翻译质量。同时,BPE 方法操作简单,仅在翻译前使用脚本对语料做BPE 处理,翻译后去掉翻译文件中的“@”标识符即可,不需要对模型做任何修改。
由于AMR 生成任务的源端和目标端存在相同的单词,如图2 所示,Academy、Sciences 等单词在序列化的AMR 图和文本句子中同时出现,因此本文对源端和目标端同步进行子词化处理。同时,为了将源端和目标端之间建立联系,本文采用源端和目标端共享词表的策略。
3 AMR 文本生成的动态数据扩充方法
目前,由于可使用的已标注AMR数据集规模较小,影响了AMR 文本生成性能的提升。本文提出一种简单而有效的动态数据扩充方法,在不引入外部语料的情况下,有效提升AMR 文本生成的性能。该方法对原始平行数据的目标端进行动态扩充,即在每次加载目标端句子时按照一定策略对句子中单词做随机噪声化处理,然后编码器预测出被引入噪声的单词,从而提高编码器对句子中单词的预测能力,使得AMR 文本生成的性能获得提升。
3.1 动态数据扩充
本文提出的动态数据扩充方法,是一种引入噪声的方法。类似于降噪自编码器[26],假设输入的目标端序列为y=,对该序列加入噪声生成y′=。参考预训练模型BERT[23]的方法,本文采用的加噪声方式,是对每个序列15%的单词进行随机覆盖,并限制每个序列中随机覆盖单词数不超过20 个。对于一个句子序列,本文采用以下3 种方式对其进行噪声化处理:1)设定10%的概率使选中的单词不发生任何改变;2)设定10%的概率使选中的单词被词表中的任意一个单词替换;3)设定80%的概率使选中的单词用[MASK]随机替换。
假设给定目标端序列“they are displeased to find someone unexpected when they arrive,even though they are in need of assistance.”,在对该句子序列进行噪声处理时,分别随机选中第1 个单词“they”、第3 个单词“displeased”和第10 个单词“arrive”,经过上述3 种不同的策略对其进行处理将得到噪声序列:“they are need to find someone unexpected when they[MASK],even though they are in need of assistance.”,具体过程如表1所示。

表1 目标端序列引入噪声示例Table 1 Examples of introducting noise into target-side sequence
本文提出的加噪动态数据扩充方法仅对目标端文本加入噪声,因此也可以应用到其他文本生成模型中。如图3所示,本文中所使用的模型仅在基准Transformer模型中添加了一个噪声模块。其中,假设模型输入端的AMR 序列为“tolerate:arg0 we:arg1(country:name(name:op1 japan)):duration amr-unknown”,输出端的句子序列为“how long are we going to tolerate japan?”,该句子序列经过噪声模块随机噪声化后可能变为“how long are we going to[MASK]japan?”,噪声化后的句子序列经过模型的Decoder模块时,结合Encoder 模块输出的信息可以将其恢复。
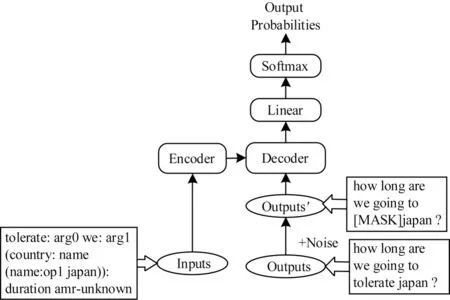
图3 本文模型框架Fig.3 Framework of the proposed model
3.2 基于大规模自动标注语料的数据扩充
为了更充分地证明本文方法的有效性,进一步在大规模自动标注语料的基础上,使用本文提出的动态数据扩充方法。本文参考文献[27]使用自动标注语料提升AMR 文本生成性能的方法,先使用一定规模的外部语料得到自动标注语料,再利用该自动标注语料预训练模型,最后使用人工已标注的语料对预训练模型进行微调。
针对本文提出的AMR 文本生成的数据扩充方法,本文同时提出了一种加噪声的预训练方式。首先,使用自动标注的AMR 语料对模型进行预先训练,在预训练时,先对自动标注语料目标端的句子按照一定方式进行随机噪声化,再利用编码器将引入了噪声的句子恢复,以此得到预训练模型。然后,使用人工标注的AMR 标准数据集对得到的预训练模型参数进行微调优化。最后,获取AMR 文本生成模型。该微调方法在使用时会对模型的共享参数进行调整,例如,使用较低的学习率可以保留预训练时模型所捕获的一些语言特征信息,在对预训练模型参数进行微调时,仍采用本文提出的动态数据扩充方法对使用的AMR 标准数据集引入噪声。
4 实验与结果分析
实验将对训练数据的源端和目标端分别使用本文提出的动态数据扩充方法引入噪声。具体地,动态数据扩充是指对同样一批数据每次加载都采用不同的加噪声方式。为了更好地评估文本生成性能,本文分别使用BLEU[28]、Meteor[29]和chrF++[30]3 种评测指标。
4.1 实验数据集
实验中使用的人工标注AMR 标准数据集如表2所示。该数据集分别为LDC2017T10 和LDC2020T02,即AMR2.0 和AMR3.0。在LDC2020T02 的训练数据集、开发数据集和测试数据集中,分别包含了LDC2017T10的对应数据集合,并且在此基础上又增加了新的数据。本文使用斯坦福分词工具对数据集进行分词,同时按照2.1 节和2.2 节提到的AMR 图线性化和子词化方法,分别对语料进行相应处理。针对本文使用大规模自动标注语料时先预训练再微调的任务特点,用预训练数据集的子词词表对线性化后的AMR 图和进行分词处理后的文本进行子词化。

表2 AMR 数据集信息Table 2 Information of AMR datasets
本文使用的大规模自动标注AMR 数据集,文本端是WMT14 英语到德语翻译的news-commentray-v11 数据集中的英语部分,包含3 994 035 句英语句子,将该英语句子文本分别在基于LDC2017T10 数据集和LDC2020T02 数据集训练得到的序列化AMR 解析模型上进行解析,得到对应的自动AMR 序列图。在进行子词化步骤时,首先将AMR 人工标注数据与获得的自动标注数据集混合,然后使用子词化工具对合并后的数据集设置20 000 操作数获取词表,最后根据此词表分别对自动标注的AMR 语料和已标注的人工AMR 语料进行子词化处理。
4.2 实验设置
本文使用ΟpenNMT 的开源框架Transformer 作为基准模型。该基准模型编码器和解码器的层数都使用默认层数6 层,多头注意力(Multi-head attention)机制的头数为8,隐藏层大小和词向量维度为512 维。本文模型将交叉熵作为损失函数,使用Adam 优化器[31],其中,beta1 值的大小设置为0.9,beta2 值设置为0.98。根据news-commentray-v11 数据集的开发集选择预训练模型,并且预训练和微调使用的模型参数保持一致。
4.3 实验结果
上文提出的目标端的数据扩充方法同时也适合于对源端的数据扩充。因此,分别对AMR 标准数据集的源端(+src_noise)、目标端(+tgt_noise)、源端+目标端(+src_tgt_noise)进行动态数据扩充。动态数据扩充每次在加载同样一批句子时均采用不同的方式对句中的单词随机进行噪声化处理。不使用大规模自动标注语料场景时的AMR 文本生成性能如表3 所示,其中,Transformer 表示没有添加噪声模块的基准模型,加粗表示最优值。
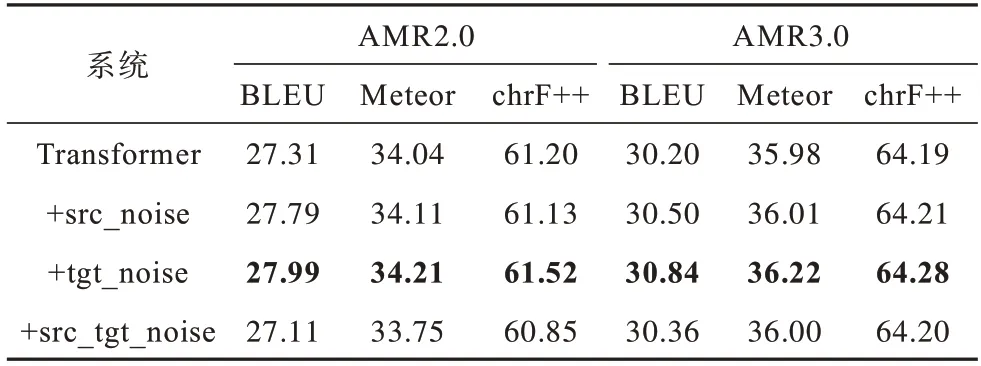
表3 不使用大规模自动标注语料场景时的AMR 文本生成性能Table 3 AMR-to-text performance when not use large-scale automatic labeled dataset
由表3 可以看出,与只使用基准Transformer 模型的系统相比,对目标端进行动态数据扩充,使得AMR 文本生成性能在AMR2.0 和AMR3.0 标准数据集上BLEU 指 标分别提 升0.68 和0.64,Meteor 指标分别提升0.17 和0.24,chrF++指标分别提升0.32 和0.09。同样,该数据扩充方法同时也适用于源端,BLEU 指标分别提升0.48 和0.30,Meteor 指标分别提升0.07 和0.03,chrF++指标分别提升0.07 和0.02。但是,当源端和目标端同时进行噪声化时,噪声化带来的模型健壮性这一优势丢失了,性能与不使用噪声化(即Transformer)相当。这说明,如果对输入过度噪声化,会引起适得其反的效果。通过分析可知,该数据扩充方法随机对语料引入噪声时,在其中一端(源端或目标端)进行噪声化操作,可提高模型的健壮性和稳定性,提高文本生成效果,但对两端同时进行噪声化操作时,该随机性可能会降低模型的健壮性,使得模型性能不仅没有明显提升,甚至造成结果下降。
为了进一步验证本文方法的有效性,使用3.9M大规模自动标注语料进行预训练,并在预训练时对语料进行动态数据扩充引入噪声,实验结果如表4所示,其中,加粗表示最优值。
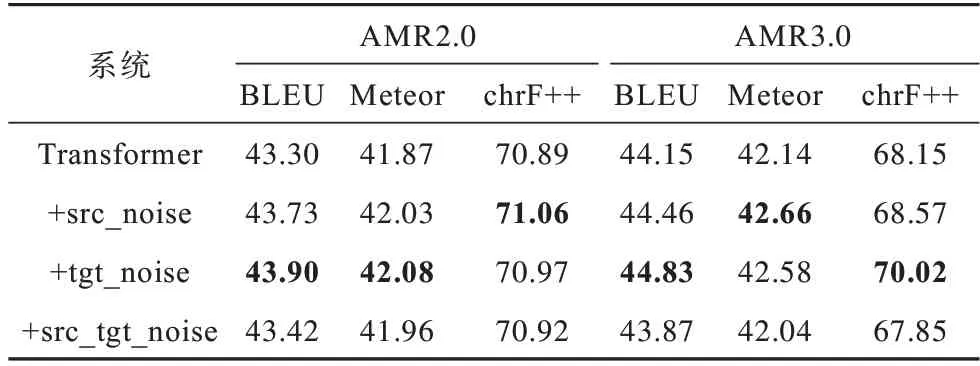
表4 使用大规模自动标注语料场景时的AMR 文本生成性能Table 4 AMR-to-text performance when use large-scale automatic labeled dataset
由表4 可以看出,即使通过引入大规模自动标注语料大幅度提高了AMR 文本生成的性能,本文方法仍然进一步使BLEU 指标提高了0.60 和0.68,这说明本文方法的有效性并没有随着模型性能的提高而变少。其中,当显著性测试p=0.01 时,本文方法在AMR 文本生成中具有显著的性能提升效果。
4.4 与高斯噪声法的比较
目前,引入噪声以提高模型鲁棒性的方法在机器翻译领域得到了广泛应用,然而该方法在AMR 文本生成领域中应用较少。为了更进一步验证本文提出的方法能够显著提高AMR 文本生成的性能,本文基于大规模自动标注语料的场景,将文献[32]提出的引入噪声以提高模型鲁棒性的方法应用到本文使用的基准模型Transformer 中。该方法将给定句子中的每个单词的词向量加入高斯噪声(Gaussian noise),如式(1)所示:
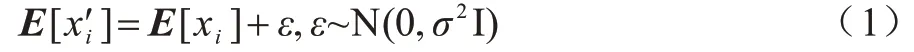
其中,E[xi]表示一个输入句子x的第i个单词对应的词向量;ε服从方差为σ2的高斯分布,σ是一个超参数,设置为0.01。该方法对句子中的每个词向量都引入了高斯噪声。
在大规模自动标注语料的基础上,比较使用本文方法与文献[32]提出的高斯噪声方法的AMR 文本生成性能,如表5 所示。其中,+Gaussian noise 表示使用3.9M 自动标注语料进行预训练和使用人工标注的AMR 标准数据集进行微调时引入高斯噪声,加粗表示最优值。
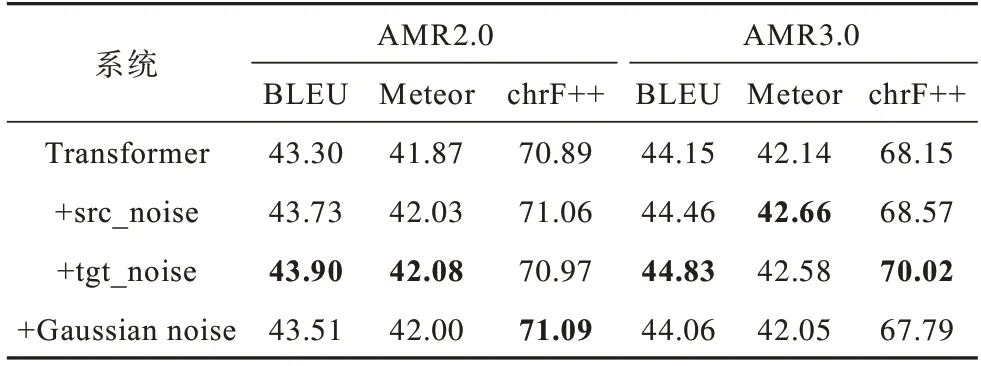
表5 本文方法与高斯噪声法的性能比较Table 5 Performance comparison of the proposed method and Gaussian noise method
由表5 可以看出,使用高斯噪声法在AMR2.0 数据集上BLEU 指标仅提高0.21,在AMR3.0 数据集上性能指标甚至有所下降,而本文方法可使AMR文本生成性能得到显著提升。
5 结束语
目前,AMR 文本生成可使用的已标注数据规模较小,使其性能受限。针对这一问题,本文提出一种动态数据扩充方法。该方法每次在加载一批训练集时均采用不同的操作随机修改句子中的单词,从而引入噪声得到新的目标句子,该句子和源端语句构成新的平行数据,在训练时,解码器端将重构原始目标语句。实验结果表明,本文提出的数据扩充方法可有效提升AMR文本生成性能,在使用大规模自动标注语料的情况下也同样能获得性能提升效果。后续将考虑在数据扩充时加入文本句子的句法信息,进一步提高AMR 文本生成的性能。
猜你喜欢
数学年刊A辑(中文版)(2020年3期)2020-10-27 02:44:16
阅读(快乐英语高年级)(2020年8期)2020-01-08 02:21:16
智慧少年·故事叮当(2018年11期)2018-05-14 11:48:18
中学生数理化·八年级物理人教版(2017年9期)2017-12-20 08:11:30
意林(绘英语)(2017年5期)2017-05-15 02:17:23
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
噪声与振动控制(2015年4期)2015-01-01 07:08:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
