
基于NLP的中医医案文本快速结构化方法
2022-05-13 05:32:52肖晓霞刘明婷杨冯天赐刘鉴建县杨阳石月
大数据 2022年3期
肖晓霞,刘明婷,杨冯天赐,刘鉴建县,杨阳,石月
1. 湖南中医药大学信息科学与工程学院,湖南 长沙 410208;
2. 湖南大学信息科学与工程学院,湖南 长沙 410082;
3. 湘潭大学化学学院,湖南 湘潭 411105;
4. 湖南泽塔科技有限公司,湖南 长沙 410012;
5. 东北林业大学工程技术学院,黑龙江 哈尔滨 150040;
6. 北京瑞迪弘欣科贸有限公司,北京 100071
0 引言
中医医案是中医历代医家临床过程的记录,往往采用叙述的方式记录病人的症状、体征和理法方药,是历代医家综合运用中医理法方药解决临床问题的经验总结,是中医知识传承的载体。但医案浩如烟海,若能够将医案中的症状、体征、证、方提取出来,并结构化为独立可用的数据单元,才能利用现代数据科学技术构建“ 症状(体征)-证-方”的关系,才能更高效地总结海量医案中的诊疗经验,更有利于中医传承[1]。
目前,医案资料大多以书籍的形式存在,基本都有对应的电子书籍,但电子书籍也是以扫描版本为主,而非可计算机直接识别的文字。人工整理和结构化医案费时费力,直接采用自然语言处理结构化图片文字也不可能,但可以先采用光学字符识别技术将图片式医案转化为计算机文字,再用自然语言技术来处理。
1 医案结构化现状
医案的描述一般包括病人姓氏、年龄、性别、症状、体征、证名、治则或治法、病因、方剂名、汤药名、中草药名、西药品名等,这些都是采用自然语言形式描述的,要将医案结构化,就需要将这些信息提取出来作为一个独立的数据单元。这些信息提取中难度最大的就是症状、体征和现代医案中生化指标信息的提取,由于中文语句中没有词的间隔符,信息提取之前往往需要对文本进行词语的切分并将其识别为目标对象,对应的技术有中文分词和命名实体识别技术。 目前中文分词和命名实体识别主要有基于词典、基于规则、基于统计以及规则与统计相结合的方法[2]。
基于词典的方法要求词典涵盖所有需要抽取的实体,并且随着数据量的增大,匹配速度会大幅度降低,对未登录词(即自然语言处理中的未被词典收录的词)的补充较难实现[3-4],缺乏自学能力。由于人类语言的灵活性和多变性,基于规则的实体抽取也很难有一个通用的方法。基于统计的机器学习方法、深度学习方法是目前发展比较快、应用比较广的中文自然语言处理方法,如隐马尔可夫模型( hidden Markov model,HMM)、最大熵(maximum entropy,ME)模型、条件随机场( conditional random field,CRF)模型、长短期记忆(long short-time memory,LSTM)网络等[5]。由于基于统计的机器学习方法和深度学习方法需要对所处理的文本进行标注,短时间内无法完成,并且标注的方法及文本的领域特点也会使算法无法泛化到其他领域。除此之外,由于深度学习涉及大量的高维稀疏矩阵运算,需要特殊计算硬件来加速[6]。
医案结构化过程中最大的工作量就是对医案中症状、体征命名实体的识别,但目前并没有专门针对中医医案症状、体征命名实体识别的技术,也没有公开的用于中医医案症状、体征命名实体识别的词典和通用的语料库,因此涉及的中医药词典和语料都需要研究者自行构建。例如,张帆等人[7]构建了中医领域词典,对600份医案进行了人工标注,之后采用层叠隐马尔可夫模型结合中医词典的方法对600份医案进行处理,F1值为94.14%; 李明浩等人[8]在对492份医案中2 069条规范症状进行标注的基础上,采用LSTM-CRF对这些医案中的症状进行识别,F1值为78%。
中医临床命名实体识别研究随着技术的发展不断进步,但由于中医领域特点及研究起步较晚,症状命名实体识别要么需要大量人工语料标注,要么其F1值不高。为了找到合适的快速结构化医案文本的方法,本文在搜狗细胞词库中下载了与中医诊断、症状、中药等相关的词典近30部,共收集约17万个词条。尽管这些词典词条丰富,但要结构化的医案中的大量症状、体征未包含在其中,因此采用上述词典结合jieba库的分词效果不佳,长词基本无法识别,对未登录词的识别准确率也不高;尝试采用FuzzyWuzzy库进行模糊字符串匹配,准确率有所提高,但运行速率太低,整个实验从开始运行到完成花费将近7 h。鉴于此,本文采用无须人工标注语料的基于统计的N-gram模型结合词典来完成症状、体征命名实体的识别。
2 医案文本采集及预处理
2.1 医案来源
医案选择由董建华、王永炎两位院士主编的人民卫生出版社出版的《 中国现代名中医医案精粹》丛书第1至第6集(以下简称 名中医医案丛书)作为研究对象。整套丛书共收录了434位全国三批名老中医的医案,其中不少医案由名老中医自行整理,并分析其机理,探讨用方用药奥秘[9]。对这些医案进行结构化并深入研究对名老中医知识的传承是大有裨益的,并且此研究方法还可以推广到其他非结构化医案的研究。
2.2 医案编排特点
名中医医案丛书对医案编排的基本规范为:第一段以姓氏、性别、年龄独立成段,大部分医案有主诉及病史、诊查、辩证、治则或治法、处方、几诊等部分。同时也发现部分医案辩证和治法融合在一起;部分医案有辩证但缺失治则或治法;部分与针灸相关的医案用操作一词替代治法等。为了在医案图片识别过程中对医案进行初步结构化,针对上述问题,收集了医案中的同义词或者对应的结构词,见表1。

表1 分割关键词对应表示例
2.3 医案文本采集及初步结构化
本文的数据采集处理对象为网络下载的加密扫描版PDF书籍,加密的PDF一般无法直接进行文字转换,需先将PDF书籍切割成医案图片进行Base64编码后,再使用光学字符识别(optical character recognition,OCR)技术转化为计算机能够处理的文字,由于百度AI开放平台的OCR的准确率高达99%,本文采用百度的HTTP在线接口将图片转换为文字,校验无误后录入数据库。
在名中医医案丛书中,医案之后都有按语,医案文本长短不一,且本次研究只关注医案结构化不考虑按语,因此采用人工方式只对医案进行截图,确保每个医案图片可通过OCR获得正确的文本。为了方便后期处理,将每份医案截图保存到相应文件夹中,并对其编码。医案文件夹的编码规则为集号+该医案在书籍中的顺序,医案图片编码规则为集号+该医案在书籍中的顺序_该医案图片总数_目前该图片顺序。例如名中医医案丛书第2集中的第808个医案需要截图2张,则需要创建名为2808的文件夹,文件夹中将依次存放编号分别为2808_2_1和2808_2_2的两张图片。在识别过程中,这种编码可以按文件名从小到大的顺序识别并获得各个医案,并且能够很好地标识该医案的出处,方便后期对识别所得医案文本进行修订。
本文对4 902份医案截取了7 287张图片,并将医案图片用Base64转码,再将50份医案分为一组,采用OCR识别图片中的文字。在识别过程中,根据医案编排特点和分割关键字对应表对识别的字符串做切割,得到初步结构化的医案文本,并录入数据库。经人工核对,除去批量录入数据库时出错、信息不全的医案数据,最后整理出有效的医案数据共4 754例,结果如图1所示。

图1 医案文本初步结构化结果部分截图
医案中患者姓名、治则或治法、处方等的编排基本一致,在文本识别过程就做了结构化。为了保证采集的数据都能溯源,数据库中还保存了原文、原文出处及处理的图片信息等,由此获得的初步结构化内容包括患者的姓名、性别、年龄、主诉及病史、诊查、辩证、治法、处方、医生、医案来源、原文、对应图片信息等。主诉及病史、诊查的文本基本采用非结构化的自然语言描述, 其中包含大量症状、体征的描述,下一步的工作就是集中结构化此部分内容。
3 医案症状体征数据提取
3.1 N-gram模型
N-gram模型是一种基于统计的语言模型,可用于分词。给定一个句子w,w=ω1ω2ωm表示句子由m个有序的词组成,P(w)表示句子出现的概率,N-gram模型可用于计算句子概率。在现实中句子是多样的,即使将互联网上的文本作为语料库,也不能穷尽所有的句子形式,单个句子的出现频次多为1,句子重复出现的概率低而导致数据稀疏,因此直接计算P(w)是非常难的[10]。考虑到句子由词构成,词是有限的,P(w)可以由P(ω1,ω2,…,ωm)表示,假设词ωi的出现只与该词前面N-1个词相关,则P(w)的计算就可以转化为如下计算式:
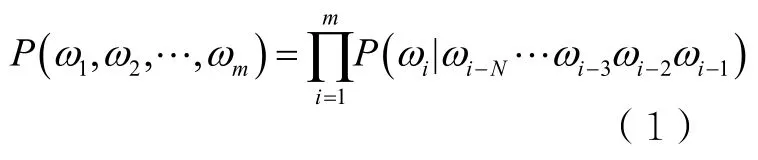
式(1)就是N-gram模型,当N很大时,模型的参数空间过大,会出现数据稀疏和词表维度过高的问题。N-gram模型中的ωi可以是词也可以是字,将ωi用于分词时,为了提高低频词分词效果,ωi的粒度为字。若ωiωi+1ωi+2是一个词,则其出现的概率和P(ωiωi+1)P(ωi+2)或P(ωi)P(ωi+1ωi+2)相似,一个词的凝固度可定义为该词出现概率与该词中其他组合概率比值的最小值,具体见式(2),本文根据词的凝固度对医案进行分词并识别新词。

定义预处理后的语料库为corpus,语料中的字用ωi表示,n表示切分词的最大长度,模型识别出的词都被保存在词库VG中。本文采用的N-gram模型的具体步骤如下。
(1)对corpus中的字按1到n的顺序切分,并统计各个片段的频次,根据式(2)计算切分片段的内部凝固度。多次实验选取合适的阈值,将凝固度高于阈值且字数大于2的切分片段加入VG中。
(2)根据步骤(1)中的凝固度对句子进行切分并统计频次。切分方法是若存在两个片段的凝固度低于某个片段,则从此处切分。如 存 在则从ω处 切i+1分。其中,a为一个给定的阈值,通过实验确定。
(3)对步骤(2)中的切分片段进行检测,若切分的片段在VG中或部分在VG中,则保留切分片段,筛选出高频片段并加入VG。
3.2 正向最大匹配法
正向最大匹配法是最基础的基于词典的中文分词算法,其算法流程如图2所示,MaxLen为分词词典中最长词条所包含的汉字个数。应用此算法之前需要先确定一个分词词典。
例如,待分词文本为s1= {“舌”,“ 脉 ”“ 为 ”,“ 舌 ”,“红 ”,“ 苔 ”,“黄”,“腻”,“脉”,“弦”},对应分词词典为dict[]={“舌红”,“舌 红苔黄腻”,“脉弦”}。根据图2进行分词,从s1[1]开始,取长度为5的字符串w为“舌脉为舌红”,扫描dict[],发现w不在dict[]中,因此去掉“红”,继续扫描“舌脉为舌”是否在词典中,如此重复上述过程直到剩下的部分是dict[]中的词或单字,并加入s2中。最终s2的结果为“舌/脉/为/舌红苔黄腻/脉弦”。

图2 正向最大匹配算法流程
该算法的一个弊端是在算法开始前需预设一个匹配词长的初始值,初始值一般是词库中最长词的长度,如果这个词长 初始值过大,在查找短词时,就会导致很多无效匹配;如果词长初始值过小,就不能进行有效的切分,这就会导致算法的效率降低[11]。
3.3 词典构建
结构化医案过程中需要尽可能保留其原始样貌,保证数据的真实和完整,因此提取临床症状、体征时不会对其做任何规范化处理。中医临床中采用自然语言描述的医案症状描述多样,如发 烧就有大热、壮热、微热等描述,口渴有口渴欲饮、口渴不欲饮等描述,为了满足后期智能诊断需求,这些症状都需作为命名 实体提取。
根据《中医诊断学(新世纪第4版)》[12]及《诊断学基础(第2版)》[13]中对症状术语最小粒度的界定,以及尽可能保持数据的真实和完整的原则,整理出待处理的语料、停用词表、高频症状短语词库、西医临床诊断关键词库、中医关键词库、中医布尔类型关键词库。词库构成简述如下。
● 停用词表:由语料中非症状体征的字词构成,如患者、入院后、家属、出示、来诊时等。
● 高频症状短语词库:根据医案的结构特点,使用正则表达式将“诊查”字段与“辩证”字段之间的症状信息提取出来,并统计词频。将人工核验后为最小症状提取单元且词频大于或等于5的症状短语收录到高频症状短语库中,如烦躁不安、恶心呕吐、不思饮食、心悸气短、形体瘦削等。
● 西医临床诊断关键词库:医案中含有一部分西医诊断信息,考虑到直接删除该部分信息会导致疾病的诊断依据不完整、偏离专业诊断方向,故建立西医临床诊断关键词库,用于提取体温、尿糖、血压、黄疸指数、血清胆红素、血小板计数、白细胞计数、麝香草酸/草酚浊度试验、孕二醇测定等信息。
● 中医关键词库:医案中存在大量名词-形容词的搭配,对于同一名词,可能会出现多个形容词与之构成不同的症状短语,可将这些名词收录整理为提取语料中的症状信息的辅助工具。这些关键字有舌苔、舌质、形体、面色、二便、口、四肢等。
● 中医布尔类型关键词库:中医布尔类型关键词是指不可拆分的、在疾病描述中只有出现与否两种状态的症状短语,它在本研究医案中出现的频率低。若中医布尔类型关键词出现在语料中,则可直接提取。手足心热、午后潮热、头晕目眩、角弓反张、张口抬肩、少气懒言、潮热盗汗、形寒肢冷等都属于布尔类型关键词,对于某一患者来讲,只有是否出现该症状两种情况。
在训练模型的过程中,为了提高提取的准确度,除上述词典外,还补充了前缀修饰词库以及西医需特殊处理的关键词库,分别见表2与表3。

表2 前缀修饰词库示例
3.4 症状体征提取
医案结构化的一个重要工作就是将医案中的症状短语提取出来,对于一个没有足够大的短语词典以及没有人工标注的医案文本数据集,采用的提取方式是非常受限的。本文采用结合规则、词典和N-gram新词发现的算法提取医案中的症状、体征命名实体。定义整个医案文本为S,算法具体步骤如下。
第一部分:语料预处理及高频短语提取
(1)准备语料:将第2.3节中获得的每个医案的诊查文本以标点符号为分隔符,分行存储在按文献顺序编号的单独的TXT类型的文件中。将图1所示文件中的主诉及病史中的文本汇总为一个TXT文件,命名为TXTcorpus。
(2)使用N-gram模型处理TXTcorpus:用第3.1中介绍的N-gram模型处理TXTcorpus,并将高频词加入对应的词典。
第二部分:对每个医案文本文件中的文本行进行处理
(3)去掉停用词:采用过滤停用词的方式过滤语料中的非症状词。
(4)识别已登录词:先用高频症状短语词库和预先准备的西医临床诊断关键词等词典提取语料中的症状单元,将其输出到相应文件中,并将其从语料中删除;若语料剩余长度为0,则读取下一个文件并进行处理。
(5)清洗剩余语料:对剩余语料再次进行停用词处理, 若处理后的语料长度为0,则读取下一个文件并进行处理。
(6)识别未登录词:采用N-gram模型识别未登录词, 将其输出到对应文件中,并将其更新到症状词典中后删除该词。若语料剩余长度不为0,则进行人工处理。
(7)人工处理:手动处理剩余语料,若剩余的语料为无意义的字词,则将其加入停用词表;若为症状短语,则将其手动输出到对应的文件中,并分析该词未被识别的原因,将其收录到对应的词典。
重复(3)~(7),直至所有语料处理完毕,算法结束。
3.5 实验结果及分析
本文采集到的、需要处理的名中医医案丛书的文本字数见表4。实验采用词典、N-gram模型、词典+N-gram模型3种方式提取医案中的症状、体征命名实体,3种方式的提取结果与医案数成比例增长,结果如图3所示。由于本次医案结构化的目的是为后期数据挖掘和术语规范化提供真实数据,提取对象多为包含症状描述的症状短语,其中有的短语有症状程度的描述,如口渴欲饮、口渴不欲饮;有的是多个症状同时出现时的常用描述,如寒热往来、眩晕目糊、失眠惊惕。因此,随着医案数的增加,症状短语数不断增加,而且数量可观。
为了能客观准确地描述3种方案的优劣,从4 754份医案中随机抽取666份医案组成最终的测试样本空间,剩下的4 088份医案则进行模型训练及相关处理。随机抽取的666份医案经人工处理得到5 439个症状、体征命名实体,将其作为实验评价的参考标准。不同方案提取的结果采用准确率P、召回率R、F1值3个指标进行评测,计算式如下[14]。
3种方案的实验结果见表5,其中正确症状总数为实验结果中与标准输出完全一致的症状短语个数,分词总数为实验提取的症状、体征命名实体总数,有效医案总数为提取命名实体数不为0的医案数,随机抽取的666份医案中都包含有症状或症状短语,因此人工处理的有效医案总数为666份,分词总数为5 439个。从表5可以看出,单独采用N-gram模型提取症状的结果最差,有28份医案无法识别。

表5 3种方案实验结果
根据表5计算P、R和F1值,结果见表6。其中,词典+N-gram模型的F1值为82.99%,词典方案的F1值为79.91%。本次实验中N-gram模型中的N取值为5,但通过回溯仍可提取字数超过5的长短语。实验中采用的词典除少数是人工添加的外, 大量的短语来源于非人工处理:一部分采用正则表达式提取得到,一部分是训练N-gram模型时获得的未登录高频词。

表6 3种提取方案的效果
本文采用的N-gram模型仅使用词的凝固度来分词,不需要对语料进行标注,节省了人力。由于提取的命名实体包含症状短语,需要保留症状的常用描述方式及非数值描述的程度描述部分,因此没有考虑词的自由度,进而“口渴”“口渴欲饮”“口渴不欲饮”等词都能被提取。使用N-gram模型训练时,采用的语料由所有医案组成,这些医案按照书籍编辑顺序保存为一个文档,并且只保留中文字符,这种做法简化了算法,但在语料不充足的情况下,很容易造成数据稀疏问题。本文采用的N-gram模型还需从数据结构、数据稀疏问题的平滑技术等方面进行优化,才能获得更高性能。
4 医案数据结构化
完成症状、体征信息的提取后,可以根据所建词典对医案进行结构化。根据临床信息分析需求、文献来源需求统计分析医案结构,医案结构化数据由医案ID、姓名、年龄、性别、是否婚配、初诊时间、主诉及病史、诊查、辩证、治法、处方、其他诊次、医生、医案来源、原文和图片ID等字段组成,其中诊查部分完全结构化为症状、体征 数据,数据之间用逗号分隔,结构化后的医案如图4和图5所示。本次医案采集数据总计4 754条,每页存储15条,共317页。在医案结构化过程中,应尽量保持医案数据原貌,不对医案中的术语进行标准化处理,其目的是为后续医案数据挖掘、临床信息标准化等相关工作提供原始数据。

图4 医案文本结构化结果部分截图1

图5 医案文本结构化结果部分截图2
5 结束语
中医医案是中医临床经验的总结,为中医治学提供了关键的第一手实践资料,对于深化、传承和发展中医药具有非常积极的作用。系统地对中医医案进行结构化整理和研究,有助于中医传承和发展。本文提出的基于自然语言处理的中医医案文本快速结构化方法,可以迅速地对图片医案或文本医案进行结构化,在结构化过程中还能动态完善中医词库,尽可能最大限度地收集中医临床术语,并保持症状描述的完整性,为后期其他医案结构化、医案数据挖掘、医学知识总结、医学知识库构建、中医术语标准化等提供信息完整的数据支持。
从实验结果来看,所提方法还有很多改进空间,后期还可以以此为基础对医案进行标注,并采用神经网络进行新词发现研究,进一步提高医案结构化效率及自动化处理能力。数据采集过程中也需要提高自动化处理程度,对现有语言模型进行补充。
猜你喜欢
河北理科教学研究(2021年4期)2021-04-19 13:34:44
计算机教育(2020年5期)2020-07-24 08:53:00
智富时代(2019年6期)2019-07-24 10:33:16
基层中医药(2018年4期)2018-08-29 01:25:46
基层中医药(2018年3期)2018-05-31 08:52:03
高中生·天天向上(2016年9期)2016-11-22 09:10:34
计算机工程(2015年8期)2015-07-03 12:20:35
中国中医药现代远程教育(2014年23期)2014-03-01 04:33:52
中国中医药现代远程教育(2014年17期)2014-03-01 04:29:11
华东理工大学学报(自然科学版)(2014年5期)2014-02-27 13:49:32
