
基于全局和局部特征的图像拼接方法
2022-05-12 07:01许向阳袁杉杉王军戴亚平
北京理工大学学报 2022年5期
许向阳,袁杉杉,王军,戴亚平
(1. 北京理工大学 自动化学院,北京 100081;2. 北京九如仪器有限公司,北京 100039)
随着图像传感器和图像处理技术的发展,越来越多的场合需要图像兼具大视场角和高分辨率,以提供对目标场景更加整体和清晰的描述,因此全景成像技术应运而生,其在监控[1−2]、虚拟现实[3−4]等领域都有着巨大的应用价值. 现阶段全景图像采集方法可分为鱼眼全景、折反射全景、拼接式全景3种[5],相比于前两者利用专用广角成像设备直接拍摄大视场图像,拼接式全景因其低造价和小失真逐渐成为主流全景图像采集方法.
BROWN 等[6]利用尺度不变特征变换(scale invariant feature transform,SIFT)[7]提取输入图像的点特征,然后使用随机抽样一致(random sample consensus,RANSAC)[8]剔除错误匹配点,进而对图像进行单应性对齐,最后采用多频段融合拼接算法形成一幅全景图像. 然而SIFT 和RANSAC 运算量均较大,较少关注实时性问题[9−10]. 此后RUBLEE 等[11]提出ORB(oriented FAST and rotated BRIEF)算法,其运行时间远远优于SIFT,但不具备尺度不变性. ZARAGOZA等[12−13]将图像划分成密集网格,每个网格使用一个单应性矩阵对齐,同时给出了一整套高效的计算方法Moving DLT 用于实现图像拼接.
然而上述算法在序列图像拼接时选定图1(a)为基准,提取图1(b)与图1(a)间的匹配点用于求解单应性矩阵,进而将图1(b)投影至图1(a)所在平面,融合两者的重叠区域获得拼接图像图1(f),然后以图1(f)为基准,重复上述步骤,完成后续图像拼接,获得全景图1(i). 然而图像配准和参数计算等过程中均存在一定程度的误差,多幅图像拼接时,前列图像的拼接误差逐渐累积,导致后续图像的拼接效果逐渐变差,出现明显畸变,如图1 所示.

图1 序列图像拼接误差累积Fig. 1 Stitching error accumulation of sequence images
此外如图2(a)所示,序列图像以1 为基准进行拼接时,图像N的匹配点主要分布在区域M内,然而M属于拼接区域,存在大量拼缝且拼缝处特征点容易出现畸变,进而导致图像配准过程中有效匹配点减少,匹配错误率增加,误差也将随着拼接的进行不断累加. 如图2 所示,图2(b)为待拼接图像图1(e)与已拼接图像图1(h)进行配准的结果图,图2(c)为待拼接图像图1(e)与相邻图像图1(d)进行配准的结果,明显可见现有拼接算法的误差累积问题严重影响后续图像的配准和拼接效果.
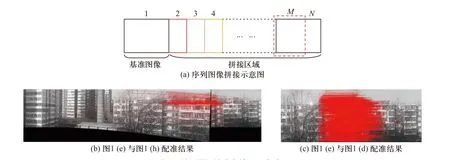
图2 误差累积导致有效匹配点减少Fig. 2 Reduction of effective matching points caused by the error accumulation
鉴于上述不足,本文提出一种基于全局和局部特征的图像拼接方法,首先同时拍摄大视场角、低分辨率全局图像和小视场角、高分辨率局部图像,然后利用SuperPoint[14]算法提取图像特征点及其特征描述子,利用SuperGlue[15]算法进行全局图像与局部图像间的特征配准,进而根据两者面积比等比例扩大全局图像的匹配点坐标,求解单应性矩阵将局部图像无缩放地投影至全局图像所在平面,最后融合投影后局部图像的重叠区域,拼接形成一幅大视场角、高分辨率全景图像.
1 基于深度学习的图像配准
在图像拼接过程中,首先对获取的输入图像进行滤波、灰度化、畸变矫正等预处理操作,其次提取图像特征点及其特征描述子,对取自不同时间、不同光照或不同拍摄视角的两幅或多幅图像进行特征匹配,使得图像对中对应于空间同一位置的点一一对应[16],然后根据匹配点计算图像对间的配准参数,求解单应性矩阵,并将图像投影至同一观察平面,算法流程如图3 所示.
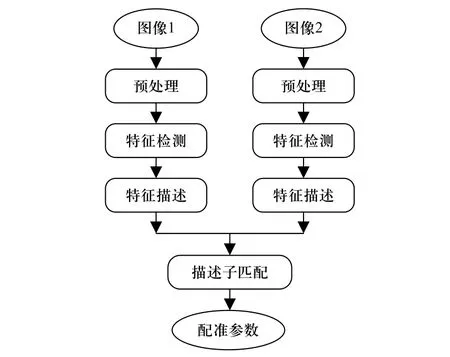
图3 基于特征的图像配准流程图Fig. 3 Flow chart of image registration based on features
1.1 基于深度学习特征提取
针对SIFT 运算量较大、实时性较差等问题,本文采用SuperPoint[14]提取特征点及其特征描述子,该算法并未公开其数据集且训练过程较为复杂,因此实验中仅加载其权重文件进行测试,不对模型结构、训练过程等进行修改,其流程主要包含特征点预训练、特征点自标定和联合训练3 个阶段,流程如图4所示.

图4 SuperPoint 算法流程图Fig. 4 Flow chart of SuperPoint
①特征点预训练(interest point pre-training).
创建一个主要由特征点位置明确的简单几何形状组成的合成数据集,例如线段、三角形、四边形等,进而利用合成数据集训练一个全卷积神经网络,并将训练好的检测器命名为MagicPiont,检测器在合成数据集上表现良好.
②特征点自标定(interest point self-labeling).
为提升MagicPoint 在真实数据集上的检测效果,实现跨域自适应,算法提出一种多尺度、多变换技术同态自适应(homographic adaptation),通过多次扭曲输入图像帮助特征点检测器从不同的视角和比例观察场景,标定真实数据集特征点.
③联合训练(joint training).
利用上述生成的特征点标签,训练一个全卷积神经网络,并命名为SuperPoint,实现真实数据集上图像特征点及其特征描述子的提取.
1.2 基于深度学习特征匹配
将上述SuperPoint 提取的特征点及其描述子作为输入,采用SuperGlue[15]进行图像间的特征匹配,实验中仅加载其权重文件进行测试,不对模型结构、训练过程等进行修改,算法主要包含注意力图神经网络和最佳匹配层两个模块,流程如图5 所示.
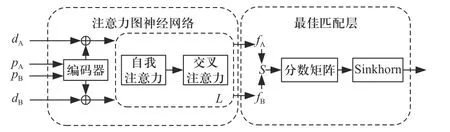
图5 SuperGlue 算法流程图Fig. 5 Flow chart of SuperGlue
①注意力图神经网络(attentional graph neural network).
利用特征点编码器将特征点位置p和特征描述子d映射到一个向量中,进而交替利用自我注意力层和交叉注意力层(重复L次)创建匹配描述符f.
②最佳匹配层(optimal matching layer).
求解匹配描述符内积用于创建一个M×N的分数矩阵,并对其进行扩展,进而利用Sinkhorn[17]算法找到最佳部分分配,实现图像间特征点配准,输出匹配点坐标对及其匹配度.
2 基于全局和局部特征的图像拼接
由于在图像配准和参数计算等过程中均存在一定程度的误差,当多幅序列图像拼接时,前列图像的拼接误差将逐渐累积,严重影响后续图像的拼接效果. 为解决上述问题,本文提出一种基于全局和局部特征的图像拼接方法. 利用所述的SuperPoint 和SuperGlue 算法进行大视场角、低分辨率全局图像与小视场角、高分辨率局部图像间的特征点配准,进而根据两者面积比等比例扩大全局图像的匹配点坐标用于计算单应性矩阵,将局部图像无缩放地投影至全局图像所在平面,最后融合投影后局部图像的重叠区域,拼接形成一幅大视场角、高分辨率全景图像,如图6 所示.

图6 基于全局和局部特征的图像拼接Fig. 6 Image stitching based on global and local features
2.1 单应性变换
用相机从不同位置拍摄所得的同一物体的图像之间存在单应性,单应性矩阵即是从一张图像到另一张图像映射关系的转化矩阵,例如假设 (xi,yi,1)为局部图像上一个特征点,对应于空间同一位置的全局图像上的匹配点为(x,y,1),利用单应性矩阵H可将局部图像特征点变换至全局图像所在平面,公式如下

上式可变换为

进一步变换为

由上可得一组匹配点 (xi,yi,1) 、 (x,y,1)可获得2组方程,进而添加约束h33=1,因此单应性矩阵具有8 个自由度,可由4 组匹配点确定. 同时,为减少计算量,本文将局部图像平均划分成为4 个区域,取各区域内匹配度最高的特征点用于求解单应性矩阵,如图7 所示.
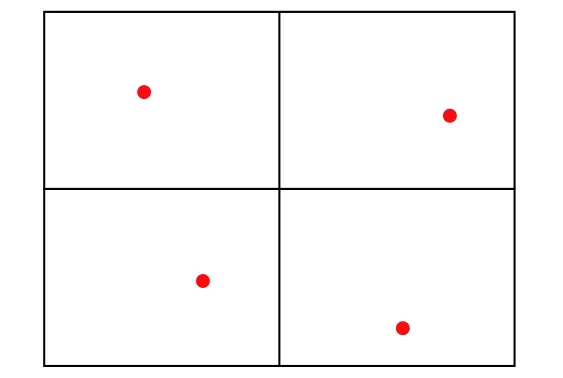
图7 求解单应性矩阵的4 组匹配点Fig. 7 Four sets of matching points for calculating the homography matrix
2.2 基于全局和局部特征的图像变换
由于拍摄过程中全局图像与局部图像分辨率相同,根据局部图像在全局图像中所占面积比,即图8全局图像中菱形区域和矩形区域面积比,同比例扩大全局图像匹配点坐标值,避免单应性变换过程中局部图像缩小导致像素损失. 进而利用4 组匹配点求解单应性矩阵,将局部图像无缩放地投影至全局图像所在平面.

图8 基于全局和局部特征的图像变换Fig. 8 Image transformation based on global and local features
图8 所示投影过程有效保留了局部图像的像素信息及其在全局图像中的位置信息,且局部图像间相互独立,使得算法不受图像行数、列数、拼接顺序及相邻图像重叠区域面积大小等因素影响,进而融合所有投影图像重叠区域形成全景图像,避免序列图像拼接过程中前列图像的拼接误差对后续图像的拼接造成严重影响.
3 实验结果
为验证上述方法的合理性和有效性,本文采用手机摄像头拍摄不同场景下的单张全局图像和多张局部图像,分别对单行和多行序列图像进行拼接测试,并与利用尺度不变特征变换(SIFT)和随机抽样一致(RANSAC)实现序列局部图像拼接,以及利用SuperPoint 和SuperGlue 实现序列图像拼接的方法进行结果对比.
3.1 单行序列图像拼接效果
同时拍摄单张大视场角全局图像和多张小视场角局部图像,设置所有图像分辨率为1 920×1 440,如图9 所示,利用本文方法对预处理后的局部图像与全局图像进行特征点配准,进而根据两者面积比,约为3,等比例扩大全局图像的匹配点坐标用于计算单应性矩阵,将局部图像投影至全局图像所在平面,最后融合单应性变换后局部图像的重叠区域,拼接形成一幅大视场角、高分辨率全景图像. 同时针对该组局部图像,分别利用SuperPoint 加SuperGlue 算法以及SIFT 加RANSAC 算法完成全景图像拼接,进行效果对比. 效果如图10~图15 所示.

图 9 全局图像及单行局部图像(1920×1 440)Fig. 9 The global image and single-line local images (1920×1 440)

图 10 基于局部和全局特征的图像配准结果Fig. 10 Image registration results based on global and local features
图11 和图12 为传统拼接方式中以前列图像的拼接结果为基准完成后续图像拼接时的配准结果,实验结果表明,该方法中拼接误差的累积严重影响后续图像的匹配效果,有效匹配点逐渐减少,然而本文方法中局部图像间相互独立,有效避免了误差累计问题,进而利用配准结果进行图像拼接时,如图13所示,除黑色背景区域外,有效图像像素约为5 551×1 455,保证了大视场角和高分辨率. 然而基于传统拼接方式的图14 总像素8 426×2 192 和图15 总像素11 357×2 685,其像素扩增是因误差累积导致图像畸变,进而引起图像纵向和横向拉伸,若去除黑色区域和畸变拉伸,其有效面积与本文方法结果接近,具有可比较性且本文方法表现良好,没有图像畸变问题.

图11 基于SuperPoint 和SuperGlue 的局部图像配准结果Fig. 11 Local image registration results based on SuperPoint and SuperGlue

图12 基于SIFT 和RANSAC 的局部图配准结果Fig. 12 Local image registration results based on SIFT and RANSAC

图13 基于全局和局部特征的图像拼接结果(有效区域约为5 551×1 455)Fig. 13 Image stitching result based on global and local features (effective area is about 5 551×1 455)

图14 基于SuperPoint 和SuperGlue 的局部图像拼接结果(8 426×2 192 包含黑色背景和畸变引起的拉伸)Fig. 14 Local image stitching result based on SuperPoint and SuperGlue (8 426×2 192 includes the black background and the stretch caused by distortion)

图15 基于SIFT 和RANSAC 的局部图像拼接结果(11 357×2 685 包含黑色背景和畸变引起的拉伸)Fig. 15 Local image stitching result based on SIFT and RANSAC (11 357×2 685 includes the black background and the stretch caused by distortion)
此外,针对图9 输入图像,传统拼接方式及本文方法在中央处理器(CPU)及图形处理器(GPU)上的运行时间对比如表1 所示. 其中实验中仅加载Super-Point 和SuperGlue 权重文件用于特征提取和图像配准,因此其运行时间仅包含网络测试时间,不包含网络训练时间. 结果表明,仅包含局部特征时,后续图像的拼接需要与前列图像的拼接结果做配准,因其拼接结果包含更多的图像像素信息,导致运算时间大幅上升,因此本文方法中基于深度学习的图像配准和基于全局和局部特征的图像拼接极大提升了运行速率.

表1 传统拼接方式与本文方法运行时间对比Tab. 1 Comparison of running time between the traditional algorithm and the method in this paper
3.2 多行序列图像拼接效果
参照上述步骤,更换实验场景,同时拍摄单张大视场角全局图像和多行小视场角局部图像,设置所有图像分辨率为1920×1 440,如图16 所示,本文方法根据匹配点的坐标信息确定局部图像在全局图像中的位置信息,根据全局图像和局部图像的面积比,约为3,等比例扩大全局图像的匹配点坐标,用于计算单应性矩阵,将局部图像无缩放地投影至全局图像所在平面,如图17 所示,拼接过程有效地融合投影变换后局部图像的像素信息和位置信息,局部图像间相互独立,有效削弱了前列图像的拼接结果对后续图像拼接的影响,其拼接结果如图18 所示.

图16 全局图像及多行局部图像(1 920×1 440)Fig. 16 The global image and multi-line local images (1 920×1 440)

图17 局部图像投影结果(5 760×4 320)Fig. 17 The projection results of local images (5 760×4 320)

图18 基于全局和局部特征的多行图像拼接结果(5 760×4 320)Fig. 18 The stitching result of multi-line images based on global and local features (5 760×4 320)
此外,当仅针对图16(b)及图16(d)单独进行图像拼接时,由于重叠面积过小,导致传统拼接方式没有匹配点,或匹配点明显减少,匹配错误率明显上升,如图19(a)和19(b)所示,无法实现图像拼接,然而本文方法相对于传统拼接方式加入了全局特征,对重叠面积等不做要求,拼接结果如图19(c)所示,可见本文方法中局部图像间相互独立,不受图像行数、列数、拼接顺序及相邻图像重叠区域面积大小等因素影响.

图19 局部图像重叠面积过小时的结果对比Fig. 19 Comparison of results with small overlapping areas of local images
同时,针对图16 输入图像,本文方法在中央处理器(CPU)及图形处理器(GPU)上的运行时间对比如表2 所示. 同上所述,本文方法运行时间仅包含网络测试时间,不包含网络训练时间. 结果表明,利用GPU 加速极大地提升了拼接速率,使得算法容易推广应用至视频图像的实时拼接中.

表2 本文方法在CPU 和GPU 上的运行时间对比Tab. 2 Comparison of running time on CPU and GPU using the method in this paper
针对上述讨论情况,对比基于全局和局部特征的本文方法和以前列图像拼接结果为基准完成后续图像拼接的传统方式,两者特点归纳如表3.

表3 本文方法与传统拼接方法对比Tab. 3 Comparison between the method in this paper and the traditional stitching method
4 结 论
针对序列图像拼接误差累积问题,本文提出了一种基于全局和局部特征的图像拼接方法. 同时拍摄单张大视场角、低分辨率全局图像和多张小视场角、高分辨率局部图像,利用深度学习替代传统算法实现局部图像和全局图像的特征点配准,进而根据两者面积比等比例扩大全局图像的匹配点坐标用于求解单应性矩阵,将局部图像无缩放地投影至全局图像所在平面,最后融合投影后局部图像的重叠区域,拼接形成一幅大视场角、高分辨率全景图像. 本文方法不受图像行数、列数、拼接顺序及相邻图像重叠区域面积大小等因素影响,拼接速率较快,且局部图像间相互独立,有效解决了拼接误差累积的问题.
猜你喜欢
现代电子技术(2022年18期)2022-09-17
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
航天返回与遥感(2022年3期)2022-07-07
考试与评价·高二版(2020年6期)2020-09-10
科学与财富(2018年28期)2018-11-16
金桥(2018年4期)2018-09-26
数码影像时代(2018年1期)2018-09-25
英美文学研究论丛(2018年1期)2018-08-16
航空知识(2017年4期)2017-06-30
