
苎麻种质资源信息平台的构建
2022-05-11 06:49罗诗洁曹晓兰
中国麻业科学 2022年2期
罗诗洁,曹晓兰
(湖南农业大学信息与智能科学技术学院,湖南 长沙 410128)
随着科学技术的与时俱进,人们日渐习惯于依赖互联网获取知识和信息,而如何在海量的信息中高效准确地找到目的信息成为信息获取的难点[1]。知识图谱用关系网络覆盖知识,使信息变得富有条理性与直观性,提供了全新的信息搜索方式[2]。因此,构建领域知识图谱,以可视化方式展示领域知识,并将其应用于领域知识管理与查询平台中,已成为当前研究与应用的热点。叶帅、张娜、任玉琦分别构建了煤矿领域、文物领域和CNKI中文医学文献领域的知识图谱,并开发了相应的领域知识图谱系统,实现该领域知识的管理、展示、查询等功能[3-5];在农林领域,王丹丹[6]构建了宁夏水稻知识图谱,并开发了宁夏水稻知识查询实验系统,通过该系统进行水稻知识图谱的可视化展示以及知识的查询;檀稳[7]构建了植物知识图谱,并开发了基于植物知识图谱的语义检索系统,实现了基于植物知识图谱的语义检索,接受用户输入的问句来提供准确的答案;在井福荣[8]设计的作物种质资源大数据体系中,知识图谱被视为一项重要的大数据处理技术,其构建了作物种质资源知识图谱的模型层和数据层,实现了基于图结构的知识图谱可视化界面,以方便用户查询数据。
苎麻原产中国,栽培历史悠久,遗传资源非常丰富,这些宝贵的苎麻资源是发展苎麻生产、选育良种和进行科学研究的物质基础[9]。作为中国特产的纤维作物,苎麻功用众多,被冠以“中国草”的美名[10]。然而当前互联网上可查询的苎麻种质资源信息存在数据少、信息不完整且不准确的问题。为改善这种现状,本文采用知识图谱技术,以《中国苎麻品种志》[9]《中国麻类作物种质资源及其主要性状》[11]两本专著作为数据源,整合苎麻种质资源信息,设计并开发了基于知识图谱的苎麻种质资源信息查询平台,旨在为苎麻信息的高效利用打下基础。
1 苎麻种质资源信息框架概念模型
为了确保数据的真实有效性,本文选用中国农业科学院麻类研究所组织编纂的两本专著《中国苎麻品种志》与《中国麻类作物种质资源及其主要性状》作为数据来源,对其中记载的共2000余种苎麻种质资源数据进行分析,整理出常用词汇和专业术语,对有歧义的概念予以统一修正,对重复的概念进行唯一性保留,确定了苎麻的31个属性,并将这些属性归为6个大类,最终形成了苎麻种质资源信息知识框架(表1)。

表1 苎麻种质资源信息知识框架Table 1 Information knowledge framework of ramie germplasm resources
2 构建知识库
依据定义的概念类型进行实体属性和实体关系的定义,以便后续知识图谱的构建。实体属性如表2所示:

表2 苎麻领域知识图谱的实体属性Table 2 Entity attributes of ramie knowledge graph
实体关系是苎麻品种与此种苎麻的各类数据之间的关系,以表3中所示的黄皮苎为例:

表3 苎麻种质资源数据表(示例)Table 3 Data table of ramie germplasm resources(example)
黄皮苎与ZM0001之间的关系为种质库编号,即黄皮苎-种质库编号->ZM0001,以此类推,由于概念模型中包含62种属性,除去属性“中文名称”外还余61种,即苎麻的中文名称对应着61种不同的值,因此苎麻领域的知识关系共分为61种类型。
3 知识抽取
知识抽取包括实体抽取和关系抽取[12],本文利用Python进行知识抽取,具体操作如下:
实体抽取:通过append方法在代码中规定各个节点属性名称,在数据表中抽取对应数据,将主节点对应的数据保存至node_list_key中,将其他节点对应的数据保存至node_list_value中,再通过list(set())方法对两个 list列表进行去重操作。
关系抽取:首先将实体抽取到的数据列表一一对应,使用py2neo包下的relationship找到两两节点之间的关系,再通过gragh中create(relationship)方法创建两个节点之间的关系,再将两个节点与其关系以三元组的形式存入一个dict中。
4 知识图谱存储
4.1 存储策略
本文采用Neo4j存储节点和关系,存储策略如表4所示。Neo4j使用属性图模式将实体存储为节点,节点标签标示此节点所属的实体类,一个节点可以具有多个标签,为了便于展示各苎麻与其属性之间的关联,本文节点标签包括中文名称和值两类;节点属性包含名称、详细内容、可扩展性、类别、半径和颜色;节点关系类型分为61类,关系属性包括关系名、开始节点ID和结束节点ID。

表4 知识存储策略Table 4 Knowledge storage strategy
4.2 数据的输入
利用Python开发工具结合Cypher语言将处理好的表格数据输入Neo4j进行存储,实例如下:
(1)获取主节点
(2)获取相关节点关系
(3)获取所有节点关系
MATCH()-[r]->()RETURN r
4.3 数据的管理
数据管理包括苎麻实体节点和实体关系的创建、更新、删除和查询。查询采用最短路径算法,利用Cypher中shortesPath函数实现,语句如下:
MATCH p=shortestpath((:中文名称{name:黑皮蔸})-[*..10]-(:中文名称{name:黄皮麻}))return p
4.4 数据的查询与展示
Neo4j图数据库基于匹配模式来进行查询,即使用MATCH来描述用户想查询的对象,语句执行之后返回匹配节点,例如查询含有“三麻工艺成熟天数”关系的任意25种苎麻,查询语句如下:
MATCH p=()-[r:`三麻工艺成熟天数`]->()RETURN p LIMIT 25
查询结果如图1所示。
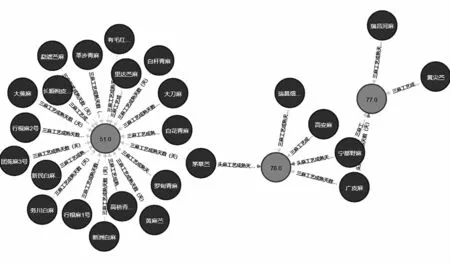
图1 Neo4j查询展示Fig.1 Neo4j query display
5 苎麻种质资源信息查询平台
5.1 平台设计
苎麻种质资源查询平台的功能分为四个功能模块:
用户权限管理:用户分为普通用户、专家学者和管理员,具有不同权限。
知识管理:包括实体与关系信息的添加、删除和修改。
知识查询:设计两种查询方式,关键词查询(包括精准查询与模糊查询)和Cypher语言查询。
知识展示:默认以力导向图的形式展示知识查询结果,用户可以手动转换为表格形式,潜在关系扩展表现为用户双击某一节点,将以此节点为中心展开相关知识图谱。

图2 平台功能图Fig.2 Platform function diagram
5.2 整体架构
本系统将采用MVC设计模式,主要包括数据层、业务层、展示层等。数据层用于创建基础属性,通过与数据库的交互,在业务层中进行数据处理,再通过业务层与展示层进行数据交互与传输。具体系统架构如图3所示。

图3 整体架构设计Fig.3 Overall architecture design
5.3 平台实现
苎麻知识图谱信息查询平台能对苎麻的属性信息进行展示,使用户一目了然地获取信息之间的关联,知识展示分为两种,一是苎麻数据表展示,主要显示苎麻的基本信息,页面展示信息条数可在100以内自主选择,通过对任一表头的点击可以实现所选属性的升降序,双击具体苎麻会跳转到该苎麻详情页,通过表头上方的输入栏可以进行查询。如图4所示。
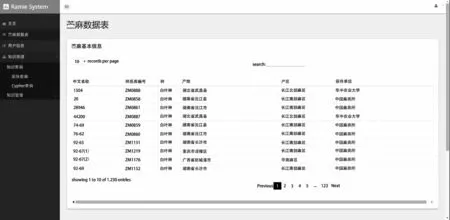
图4 苎麻数据表Fig.4 Ramie data sheet
二是力导向图展示,在力导向图中,以节点-线-节点来展示实体-关系-属性,不同的实体间可存在相同的属性,如图5所示。单击节点可进行任意拖动,当鼠标悬停于中文名称类节点上时该节点会大幅增大,悬停于其他类节点时该节点会小幅增大,便于用户进行苎麻属性信息查看和系统操作。

图5 苎麻属性信息展示Fig.5 Ramie property information display
在用户使用关键词查询时,根据用户输入的关键字进行结果匹配,如果用户能够准确地输入苎麻实体名称,查询返回的结果即为目标节点及其直接关系节点图,否则进行模糊查询,对近似实体名称进行匹配并反馈给用户,通过用户的下一步选择再返回相应结果。除了用名称进行查询之外,也支持用苎麻属性进行查询,例如输入“蔸型”(属性类别名)得到蔸型的具体种类,输入“浅红”得到某一属性为浅红的所有苎麻名。此外,平台也支持使用图查询语言进行查询,专业用户可以实现基于Cypher语言的路径查询、关联度分析等功能。
除了知识查询外平台还有知识管理功能,主要分为节点管理和关系管理,都包括新增、更改和移除功能。新增节点时,只需打开属性框在其中记录节点信息即可完成,通过对已有的信息进行修改就是更新节点数据,右键点击节点即可弹出属性框,如图6所示。

图6 修改节点Fig.6 Modify nodes
6 结语
本文构建了苎麻种质资源的知识框架,完成了苎麻实体与关系的类型划分,制定了知识存储策略并运用到实践之中,最终完成了苎麻领域知识图谱的构建,并在此基础上,设计开发了基于知识图谱的苎麻种质资源信息查询平台,平台以查询功能为主,还能对已存知识进行新增、更新等操作,用户查询的结果以力导向图形式返回,能够清晰地展示苎麻种质资源知识图谱的相关内容,对提高苎麻种质资源信息利用率具有一定的现实意义。
