
基于Logistic快速最小误差熵算法的配电变压器停电预测
2022-05-11 05:21:46许中栾乐莫文雄罗思敏叶宗林陈超赖轩达解明辉
发电技术 2022年2期
许中,栾乐,莫文雄,罗思敏*,叶宗林,陈超,赖轩达,解明辉
(1.广东电网有限责任公司广州供电局,广东省 广州市 510000;2.西安交通大学电气工程学院,陕西省 西安市 710049)
0 引言
配电网是指从输电网或地区发电厂接受电能,通过配电设施就地分配或按电压逐级分配给各类用户的电力网[1]。近年来,随着我国经济的快速发展,电力负荷的增长明显加快,对城市配电网的供电能力、电能质量、供电可靠性都有了更高的要求[2-5]。配电网作为与用户直接相连的电力网,不仅规模庞大、设备繁多,且供电环境复杂,据统计,80%以上的停电事故由配电网故障引起[6]。因此,研究一种精确、高效的配电变压器停电预测方法具有重要的实际意义。
目前配电网停电预测方法的研究主要集中在配电网可靠性评估[7-12]和基于大数据技术的配电网停电预测方面。文献[13]分析了配电网故障数据之间的关联性,并基于Logistic分类算法建立故障识别模型进行停电预测。文献[14]针对极端天气下配电网停电问题,利用历史灾损记录和灾害数值模拟数据,构建灾害时间贝叶斯网络模型进行停电预测。文献[15]针对台风灾害,综合考虑气象、电网及地理因素,提出一种基于随机森林算法的用户停电区域预测评估方法。文献[16]针对超高温、暴雨等恶劣天气条件,采用XGBoost 算法建立了线路停电数量预测模型。文献[17]提出建立贝叶斯网络预测飓风情况下的配电网停电概率。文献[18]考虑配电网下面的植被情况和雷达检测数据,通过建立随机森林模型来提高停电预测结果的准确性。
本文将基于配变运行数据得到的停电预测特征之外的因素作为误差因素,采用最小误差熵估计[19]。针对基本的最小熵回归算法运行时间较长的问题,提出了快速最小误差熵算法;然后针对停电预测适用Logistic 回归的情况,提出了基于Logistic 的快速最小误差熵回归算法,建立了配电网变压器特征变量数据的配网停电预测模型,以实际数据为例验证了所提方法的有效性。
1 传统最小误差熵算法
最小误差熵算法通过最小化回归算法中误差所包含的信息量从而使得回归模型所包含的信息量最大化。最小误差熵算法采用二阶Renyi熵[20]来表示模型误差中所包含的信息量:
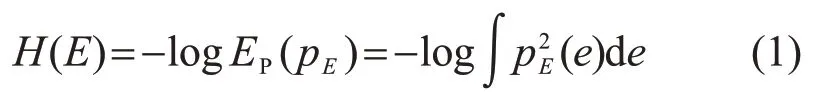
式中:E为回归误差的随机变量;H(E)为E的熵;pE(e)为E的概率密度函数;e为设定的概率密度函数自变量取值;EP(·)为对应随机变量的期望。利用Parzen 窗方法[21],E的概率密度函数p^E(e)可以表示为
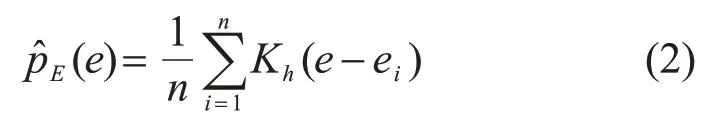
式中:n为随机变量E的采样样本数;K为核函数;ei为样本值;h为带宽。一般情况下,选择高斯核函数作为核函数,即则随机变量的信息熵的估计量为
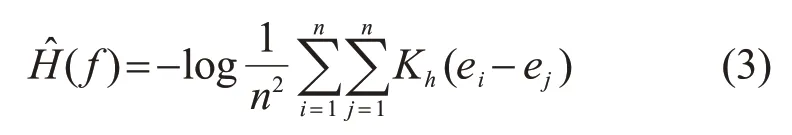
由于对数函数单调递增,实际应用中,最小化时可以将其移除而不影响最小化的结果。故变换后的随机变量对应的信息熵的估计量为
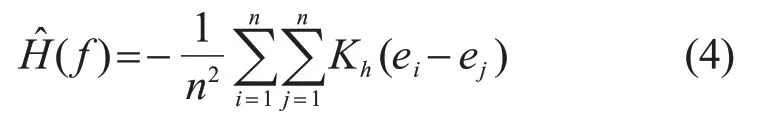
对于线性回归模型,y=wTx+e需要从数据样本中估计出w。由于ei=yi-wTxi,则对应的变换后的误差信息熵的估计量为关于w的函数:
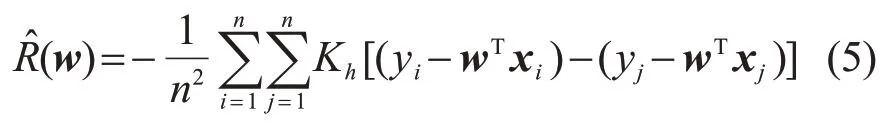
估计量R^(w)可以通过用梯度下降法极小化式(5)来求解。由于式(5)中含有二重求和运算,最小误差熵算法的时间复杂度为O(n2),这就使得随着样本数目的增大,最小误差熵算法所需要的时间会快速增加。
2 Logistic快速最小误差熵算法
在对配电网变压器的停电状况进行预测时,由于在训练样本中,配变的预测结果为“停电”与“不停电”2种情况,即预测结果为布尔变量,而一般的回归模型的预测结果是连续变量,因此需要建立起这2 种不同变量类型间的联系,将区间(-∞,+∞)的结果映射到[0,1]。Sigmod 函数非常适合实现这一点,对应的算法即为Logistic回归。
Logistic 回归通过Sigmod 函数,在线性回归的基础上,将线性模型在区间(-∞,+∞)的预测结果映射到[0,1]。由于一个事件的概率值恰好在[0,1],故Sigmod 函数的预测结果具有概率上的意义,预测值可以代表一个事件发生的概率,当预测概率小于0.5时,分类结果为负类,即表示不停电;当预测概率大于0.5时,分类结果为正类,表示停电。因此,在配变停电故障的预测过程中,Logistic回归可以建立配电网变压器的各种特征参数与其停电概率之间的关系。
2.1 Logistic回归
常用的二项Logistic回归模型为以下条件概率分布:
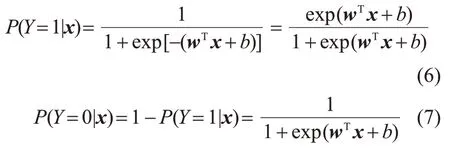
式中:x∈Rn是模型输入;n为模型输入的维数;Y=1 和Y=0 是Y的2 个可能取值;P(Y=1|x)和P(Y=0|x)分别为Y取得这2 个可能取值的概率;w∈Rn和b∈Rn是参数,w为权值向量,b为偏置。为了表达方便,可以将权值向量和输入向量进行扩充,即w=(w(1),w(2),…,w(n),b)T,x=(x(1),x(2),…,x(n),1)T。
2.2 快速最小误差熵
一个随机变量X的微分熵[22]如式(8)所示:
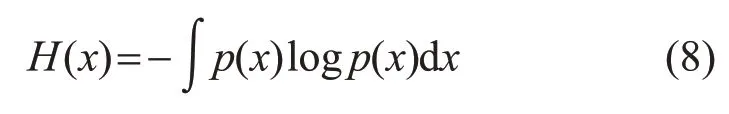
假设一个随机变量x接近与其均值和方差相同的高斯分布,将其概率密度函数GramCharlier展开式[23]代入式(8),化简后可得:
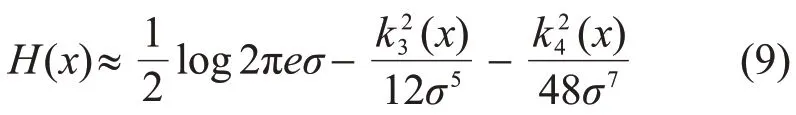
式中:σ为随机变量x的方差;k3(x)和k4(x)分别为x的三阶和四阶累积量,即偏度和峭度。
对于线性回归模型,其误差的熵为
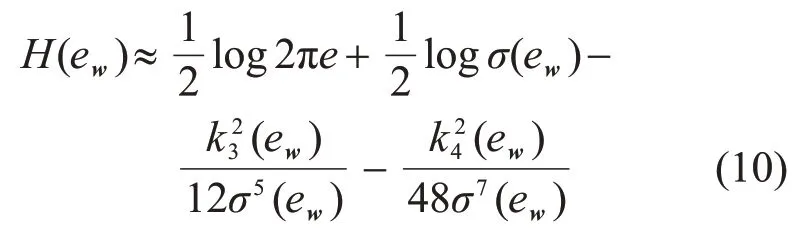
2.3 Logistic快速最小误差熵回归算法
参考线性回归与Logistic 回归的转换,快速最小误差熵回归的配电网变压器停电概率预测结果也为连续变量,因此也需要叠加一个Sigmod函数,将配电变压器的各种特征参数映射到[0, 1],称为Logistic 快速最小误差熵算法。则对于模型:
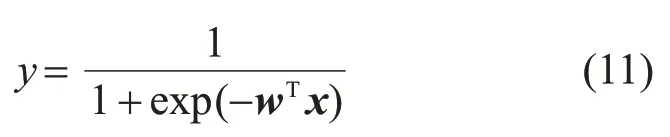
Logistic快速最小误差熵算法的误差可以表示为
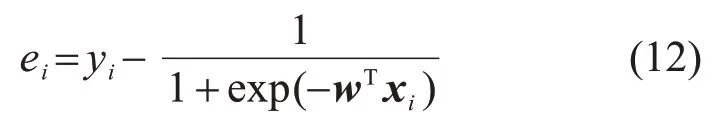
在得到式(10)的过程中,线性回归的误差被作为一个随机变量进行推导,并没有使用关于线性回归的信息。因此,式(10)的表达式与回归算法的形式没有关系。故Logistic快速最小误差熵算法误差的熵与线性回归误差的熵的表达式(10)相同。
为了求出H(ew)的最小值,H(ew)关于w的导数为
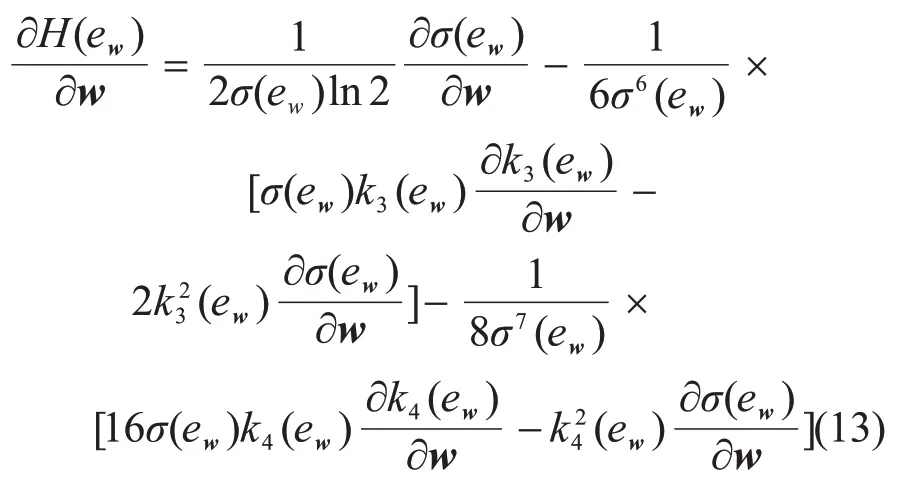
其中:

为了获得能够最小化H(ew)的w,使用如下所示的梯度下降迭代格式:
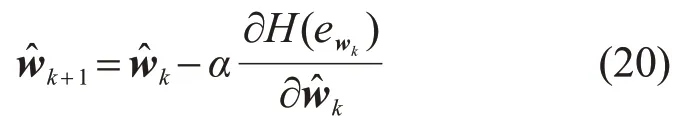
式中:和分别表示第k次和k+1次迭代得到的线性回归系数向量;α表示迭代步长,由Arimijo准则确定。
由于这些式子的计算复杂度均为O(n),故快速最小误差熵算法的计算复杂度也为O(n)。因此理论上可以认为快速最小误差熵算法的运算速度快于传统的最小误差熵算法。
3 案例分析
3.1 算法时间复杂度验证
本文通过实验比较快速最小误差熵算法与最小误差熵算法的程序运行时间消耗。设线性回归模型y=w*Tx+e,其中模型参数取x~N(0,I10),w*=[1 -1 1 -1 1 -1 1 -1 1 -1]T。其中,噪声信号采用高斯噪声e~N(0,1),快速最小误差熵算法的迭代歩长取最小误差熵算法高斯核的核函数参数取h=10[24]。实验中采用从100 到500的样本数量。算法时间复杂度验证时,取90%的样本作为训练集,10%的样本作为验证集。实验结果如表1所示。
从表1 中可以看到,在算法平均运行时间和最快运行时间2 方面,快速最小误差熵算法均比最小误差熵算法耗时少。

表1 2种算法对于高斯误差的运行时间Tab.1 Running time of two algorithms for Gaussian error
3.2 配电网停电预测算法验证
考虑配网中与停电相关的因素以及实际可获取运行数据,本文选取重过载时长、最大有功负载率、平均有功负载率、重三相不平衡时长、最大三相不平衡度以及平均三相不平衡度作为停电特征向量,利用Embedded 特征选择方法进行配变最优停电特征的选择,选用Logistics回归作为基分类器,惩罚项选用L1 范数,惩罚项权重取0.45,得到配电变压器最优停电特征子集。
选取某地区供电公司实际1 265条数据作为样本数据,对本文提出的快速Logistic最小误差熵模型进行验证。将数据随机分为训练集和验证集2 个部分,其中训练集占80%,验证集占20%。表2中给出特征变量的样例。

表2 训练集中的特征变量数据样例Tab.2 Sample of feature variable data in training set
在训练集上运行Logistic快速最小熵算法,得到预测模型的参数:
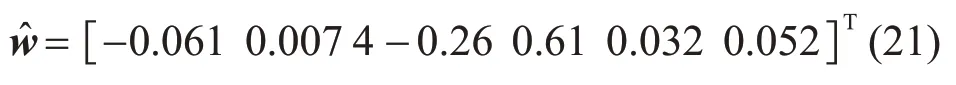
然后利用测试集对配电变压器的停电概率进行预测,测试集的部分输出结果如表3所示。
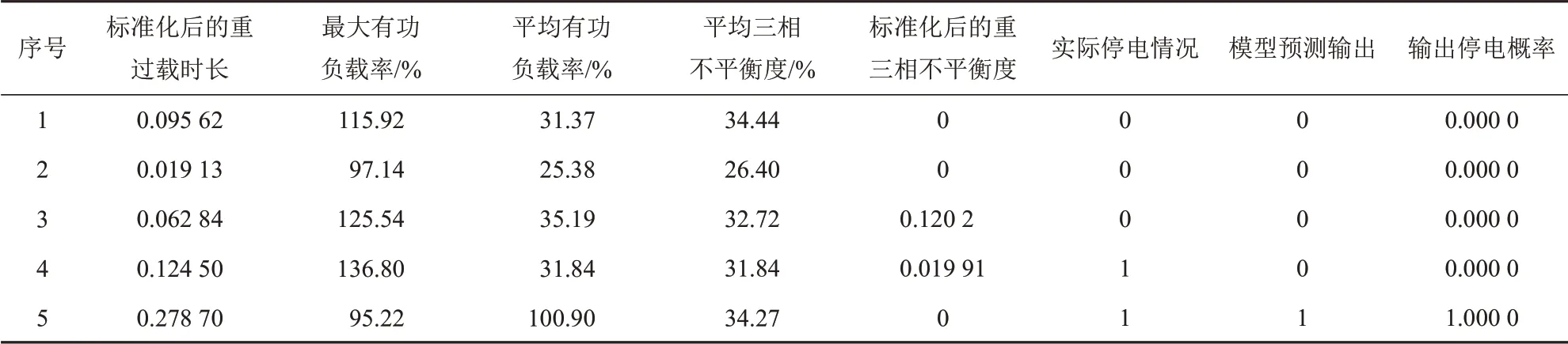
表3 测试集中的部分预测结果Tab.3 Partial prediction results in test set
使用错误率和F测量2种评价标准对模型的预测结果进行评价。Logistic快速最小熵算法的停电预测结果见表4,可以看出,算法预测的准确率在88%左右,表明配电变压器的停电预测模型较为稳定,可以对是否停电进行区分,能够辅助运维人员预测设备的停电情况,并根据设备停电情况对有停电隐患的设备进行有针对性的关注和管理,减少停电的发生。

表4 Logistic 快速最小熵算法预测结果评价Tab.4 Evaluation of prediction results of Logistic fast minimum entropy algorithm
3.3 配电网停电预测方法的对比分析
本文对Logistic 快速最小误差熵算法以及Logistic 回归算法的预测效果进行对比分析,并采用与Logistic 最小误差熵预测模型相同的数据集。
对2种算法分别进行30次预测,图1是2种算法预测结果的F 测量评价。从图1 中可以看出,2种算法的F测量值都在0.80以上,但Logistic快速最小误差熵的预测效果要明显好于Logistic回归的效果。
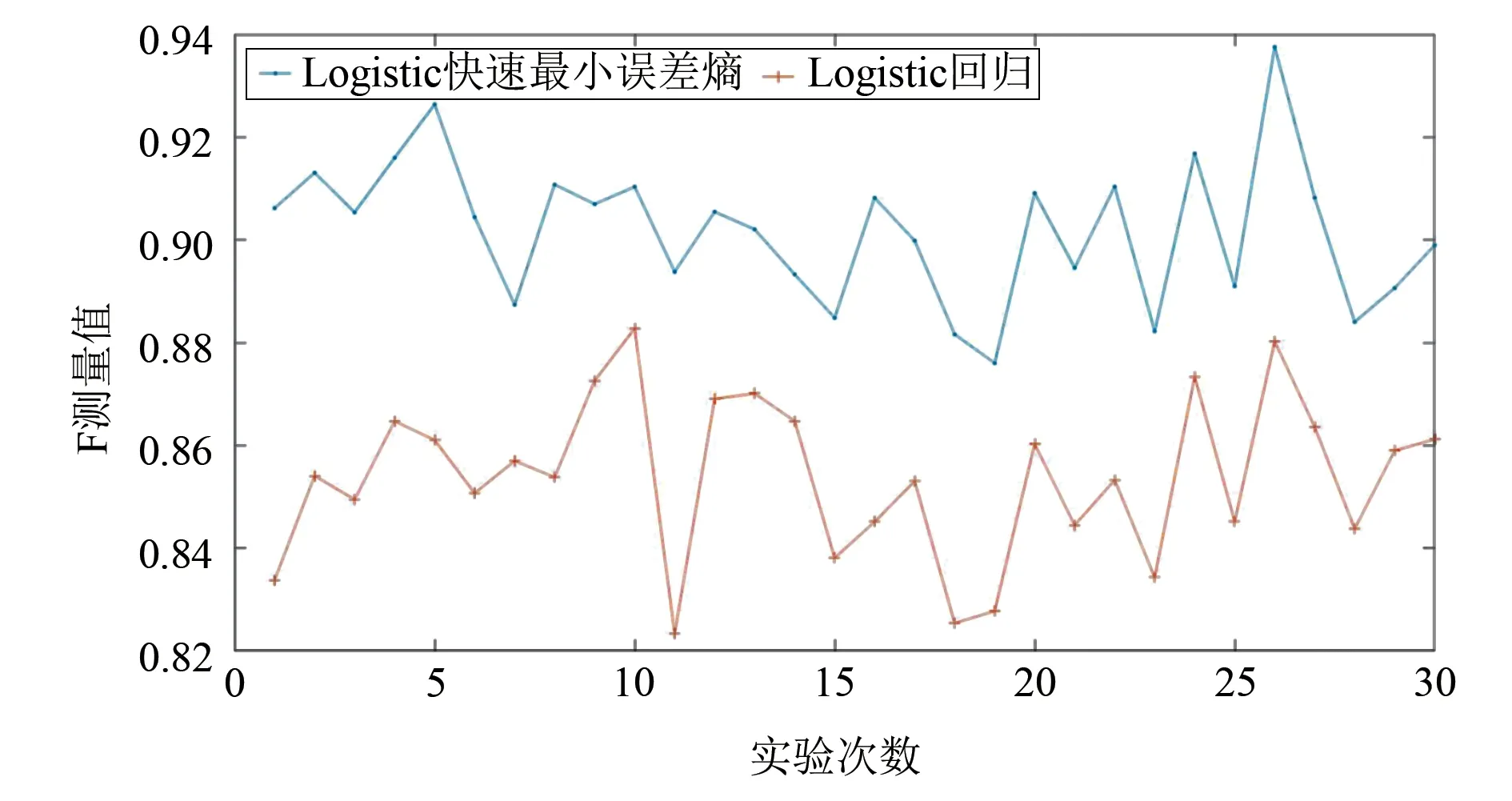
图1 2种算法停电预测结果的F测量Fig.1 F-measurement of outage prediction results based on two algorithms
4 结论
在最小熵回归算法的基础上,提出了快速最小误差熵算法,基本保持了最小熵回归的回归效果,并且显著地减少了算法的运行时间;针对配变停电预测适用Logistic回归的情况,提出了基于Logistic的快速最小误差熵回归算法,根据供电公司实际数据进行算法验证,预测效果要明显好于Logistic回归的效果。
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:08:00
中学生数理化·高一版(2021年2期)2021-03-19 08:32:06
经济技术协作信息(2018年7期)2019-01-14 03:05:40
经济技术协作信息(2018年32期)2018-11-30 01:43:16
电子制作(2018年18期)2018-11-14 01:48:20
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:34
通信电源技术(2018年5期)2018-08-23 01:16:20
电测与仪表(2016年5期)2016-04-22 01:14:14
河南电力(2016年5期)2016-02-06 02:11:24
电测与仪表(2014年17期)2014-04-04 11:56:34
