
AI 文字识别技术在城市规划档案数字化中的运用
2022-05-10 09:10:02路燕
科学技术创新 2022年14期
路燕
(东华工程科技股份有限公司,安徽 合肥 230000)
城市规划档案是当地规划部门按照现行法律规定,实施规划审批、管理等有关工作的重要依据,还是衡量工程是否满足有关标准的主要证据。目前,城市规划档案信息不断增多,原本的查询检索方式对档案资料的应用,带来诸多不便,而应用AI 文字识别将档案进行数字化处理,能有效解决以上问题。
1 纸质档案数字化
数字化转变的基本程序涉及到文件扫描、图像处理及储存等。具体操作是把档案文件平整铺在固定位置,通过高拍仪实现快速翻页,照相机则同步拍照扫描,对得到的图像实施智能化纠偏,形成PDF 格式的附件文档。在现有的纸质档案中,使用的纸张尺寸可能达到A3,甚至更大,鉴于此类尺寸的档案并不多,因此在实践中,会选择使用数码相机处理,将得到的照片插入相应的PDF 文件里。在扫描工作结束后,会按照具体的类型,分别保存在不同的位置,依托于后台服务器,将档案信息和附件对应起来。
2 城市规划档案中运用AI文字识别技术的可行性
其一,准确性。在我国部分地区的城乡规划档案处理中,AI 文字识别基本上可以准确识别出至少70%的手写文字,如果是通用印刷体,识别精准度能超过90%。其二,数字化效率。根据当下既有的文字识别方法,平均每个字符耗用的时间大致在2ms 左右,每件档案一般会消耗3min 左右的时间。包括数据传输、格式调整、文字识别与人工校准多个环节。假设使用AI 文字识别,能进一步压缩数字化处理的时间。其三,稳定性。AI 文字识别可以把各类格式的图片与文字,在整理表格中,识别出图像包含的表格数量,同时完成准确切割,保障处理后的图像可以保障表格信息的完整性。其四,针对性。AI 文字识别运用到城市规划档案工作中,可提供自主模板设置,基于档案的实际样式,选择合适的模板,在大体上可以适应城市规划档案内容提取、补录的工作需要。
3 AI文字识别技术的有关讨论
3.1 Tesseract
Tesseract 来自谷歌,该项文字识别引擎应当是近年来,识别率与成效相对靠前的方法,其对文字的识别准确率较高,并且拥有良好的移植性。因为此项技术能够自建训练库,所以可以根据城市规划档案的处理需要,对文字识别引擎实施训练,并能准确识别出不同的字体和符号。其引擎功能优秀,基本上包含分析联通区域、确定块区域、确定文本行与单词、得到识别内容。(图1)
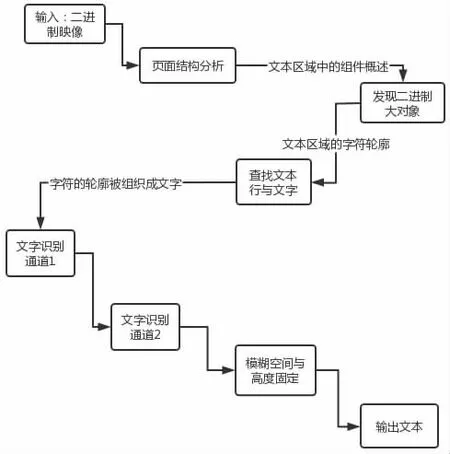
图1 Tesseract 框架图
3.2 百度OCR 文字识别
百度OCR 文字识别属于我国的老品牌,已经拥有庞大的用户群体,并借此得到训练集,依托于算法设计,在我国文字识别行业中排在前列。和上文的Tesseract 相较,百度OCR 可以提供更加准确的服务方案。由于Tesseract 在图像预处理中有较好的表现,因而使用百度OCR 进行API 中,还是把图像预处理部分交给Tesseract,由此保障整个处理过程的准确性。
3.3 图像预处理
首先,图像灰度化。计算机行业中,灰度数字图像代表一个像素就能对应一个采样颜色。拥有该特性的图像,通常是有亮度最小(黑色)至亮度最大(白色)的灰度,从理论角度来说,虽然该种情况可能是任何颜色的各个深浅程度,也能是各类亮度中的不同色彩。而灰度图像和黑白图像之间存在根本上的不同。对于计算机来说,黑白图像仅包含黑与白两个色彩,而灰度图像则包含黑和白之前的各种色彩深度。灰度化处理变化把一张包含多种颜色的图像,转化成仅具备灰度值的灰度信息。彩色图像的基本分量,包含R、G与B,各自对应红、绿、蓝,而灰度化处理过程,便是将颜色三个分量进行等量处理。灰度值更大的像素点,会更亮(白色是像素值最大的颜色,是255);灰度值低,就会相对更暗(黑色是最小的像素,是0)。完成灰度化处理的算法,具体选择如下:
其一,最大值法。把通过转换的三个分量,取得的值转化为前三个值里最大的一项,借此可得到亮度相对最高的灰度图像。用公式表示就是:

式中,ωR、ωG、ωB各自对应R、G与B的权值,在选定不同值的情况下,能得到差异化的灰度图像。因为人类肉眼对红、绿与蓝的敏感度排列是:绿大于红大于蓝,所以,在设置权值中,会根据上述大小情况,进行调整,这样能获得识别难度更低的灰度图像。在档案管理中,三者一般设置的权值分别是:ωR=0.2999、ωG=0.587、ωB=0.114。对于城市规划档案,其中有大量白底黑字的文件,使用高拍仪提取图像中,可能会受到光线等条件的干扰,出现明显色差,不利于信息识别,所以,要实施灰度化处理。
其次,图像降噪。扫描件因为硬件自身的问题,图像上会带有诸多噪声点,对于该种情况,Tesseract 是借助高斯低通滤波加以处理,提高图像质量。高斯低通滤波装置是基于高斯函数的线性平滑装置,而所谓的高斯函数属于密度函数,为正态分布。因此,该装置面对服从正态分布的噪声,有着姣好的处理效果。一维与二维的高斯函数如下:
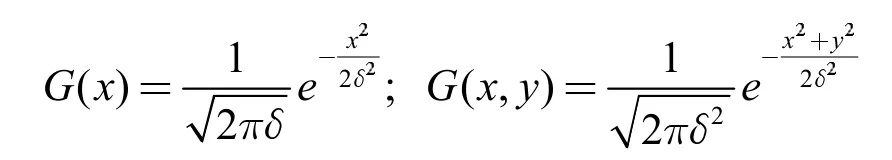
式中,δ 是标准差。因为档案图像一般是二维内容,所以图像去噪一般应用二维高斯函数。鉴于高斯函数存在可分离性,因而需对行实施高斯滤波,而后处理列的部分,利用该种处理方式,把二维高斯函数调整成一维的高斯滤波。在此函数中,标准差提高,整条曲线会更加平滑;降噪处理程度更高,图像会更加模糊。
最后,二值化。图像二值化过程,是把像素点灰度值处理成0 及255,让最后保存的图像仅包含黑白两个颜色。根据自适应阈值的算法,按照像素灰度值,把图像分成前景与背景,经过计算确定二者方差,以此得出差异的显著性,最终通过筛选对应方差实现最佳类别划分的界限,将此视为最佳预制。将灰度图像大小设成w*h,这与像素数量对应。类别划分的阈值是threshold,将小于此阈值的全部像素,当成前景,超过的部分则是背景。图像总体平均灰度的表达式是:

式中,μ 是图像总体平均灰度;ω0是前景像素数目的比例,对应的平均灰度是μ0;ω1是背景像素数目的比例,对应平均灰度是μ1。在系统分析中,会对比图像所有灰度值,得出相应的方差,继而确定出最佳阈值,由于方差在整个处理环节中,仅是用于对比,因此,直接将其用像素数量代替。通过二值化处理后的扫描件,能得到黑白分明的表格如下:

表1 二值化处理后的表格
4 城市规划档案数字化识别系统分析
4.1 系统概述
针对某城市规划中的建筑项目进行整合,既有纸质档案中仅有界址点。倘若在转化成电子档案中,只利用人工录入,显然是不够高效的,对此依托于OCR 技术与其他有关手段,设计识别系统。硬件上,为准确识别出纸质资料里的界址点,配置扫描仪等设备。开发及运行平台选择戴尔z230,而高拍仪选择宝 碁·点易拍E1200DS,此款仪器的主摄像头与副摄像头,像素分别是1000 万与200 万,能运用自然光线与LED等。根据基本参数来说,能适应档案成像需要。系统软件方面的配置,见表2。

表2 软件配置
城市规划档案的数字化处理过程是:利用文字识别手段,提取界址点内容,由此得到地图。使用高拍仪把纸质档案文件中所有包括界址点内容的页面,经过扫描保存,而后读取图像内容,根据档案基础版面,确定X与Y的数据。通过文本进行切割,提取X和Y。基于特征分析与神经网络,把X和Y转化相应的坐标,保存在Excel 表格。而后利用图像生成软件,读取表格内容,最终取得图像。

图2 系统运行流程图
4.2 系统功能
基于前文对档案文字识别系统的概述,整体可分出几个模块,即图像裁剪、版面分析、字符处理、生成表格等模块。
4.2.1 图像裁剪
由于档案图像中的多余内容,会对提取坐标信息的准确度有干扰,所以在分析版面以前,需全面处理,确保图像里仅包含界址点的内容。高拍仪最初拍到的图像信息见表3。经过图像识别,把图像进行分割。在纸质版档案中,序号位置通常是有装订孔,而边长对地图没有价值,因而,可直接把二者切掉,最终得到图像信息。

表3 包含界址点的图像内容
4.2.2 版面分析
保存于Excel 表格中的版面结构,使用几何结构与逻辑结构表示。其中,前者是对各个单元格位置实现定位与切分。而版面分析便是对扫描件实施分割,进一步识别X与Y坐标。本文此处以top-down 为例,基于对图像所有数据实施分析,根据得到的结果对文件实行切分。此种处理方式比较简便,主要用在只包括界址点内容的档案。
4.2.3 字符处理
字符切分环节视为把扫描件所示的所有数字均提取出来,得到若干数字图像,假设不能正确切分,在后续环节中就无法确定数字特征,这会影响文字识别的准确度。档案数字化处理中,会由于某些问题干燥,导致切分处理更加复杂,比如手写字体差异、大小不同等。目前可用在字符切分中的算法角度,此处以按照连通域进行切分的方法为例。简言之,一个数字可以形成相应的连通图像域,在确定各自行、列的起止位置,便能提取出一个矩形,实现字符切分。此处采用CFS分割法,整个运行流程为:把经过二值化处理的图像,由左至右,由上到下全面扫描遍历,假设存在黑色像素,而且从未被访问过,可直接将其标记成“已访问”;假设栈不为空,需要向周围据需探测其他像素,重复以上步骤,但如果栈可以是空的,说明当前已经探测好一个字符块;探测任务完成后,便能得到相应数量的字符。目前,AI 发展迅猛,该领域内的诸多厂商,都已经推出比较完善的文字识别计划,此处以百度OCR 为例,分析其识别的过程,针对数字部分,运用表格文字识别的方法。
4.2.4 生成表格
提取到的界址点坐标数据要借助Python 保存,支持生成地图。此处选用该项技术中的xlwt(xls 文件,write 库)保存表格。整个处理流程为:导入界址点坐标数据;创建工作表;填写数据;保存。(图3)

图3 生成表格流程图
4.2.5 生成地图
在城市规划档案管理机构中,计算机配置相近,既有软件也基本相同,如果原本的ArcGIS Desktop 均是10.0,使用C#比较合适,再加上操作页面具有可视化的特点,能支持大部分工作者使用。在城市规划档案的处理中,此文所述系统主要涉及到两个类库:Geometry类库与System 类库。前者可以处理保存于特征类以及其他图像要素里的geometry与shape。大部分用户涉及到的几何对象包含Point、Polygon等。在此类顶层实体意外,还存在各类几何体。GIS采集到的的实体均具备现实存在的特点,其方位是按照所在空间参照的几何体进行定义。在Geometry 库内,含有投影与地理系统的相应参考对象。在研究系统中,可以选择从空间参考方向入手,逐渐拓展空间参考的范围,由此保障储存内容的完整性与全面性。而后者属于ArcGIS系统,并未与最底层。该类库可提供所在系统内其他类库服务功能的相应组件,在此类库下,定义出大多数开发人员能实现的接口,例如,AoInitializer 对象,开发者应运用此对象,实现初始化。但开发者不可将该类库进行拓展,可以选择利用此类库内包括的接口,把ArcGIS系统进行有效拓展。在系统运行后,读取经过OCR 识别的全部表格文件,提取其中的界址点内容。建立SHAPE 图层,根据地号设置名称。因为通过OCR识别得到的表格已经用地号命名,所以此处无需更改。而后定义坐标系、创建图层,呈现出经纬度。在点绘制成线后,利用ring函数,得到Polygon,保存在相应的文件夹内。
综上所述,AI 文字识别能为档案工作提供技术帮助,将纸质档案快速转化成电子文件。实践中,在保障档案文字识别、纠错准确的技术上,还需保证档案资料安全,针对数字化内容开展全面保密检查,为城市规划档案管理夯实基础。
猜你喜欢
小学生学习指导·高年级(2024年4期)2024-05-22 21:51:59
数学小灵通(1-2年级)(2024年4期)2024-05-14 09:30:52
小学生学习指导(高年级)(2024年4期)2024-05-07 03:28:36
现代临床医学(2022年1期)2022-02-12 02:04:26
资源信息与工程(2020年3期)2020-07-09 09:55:20
文化创新比较研究(2020年14期)2020-01-02 19:25:56
文化创新比较研究(2020年10期)2020-01-02 02:10:07
文化创新比较研究(2020年13期)2020-01-01 06:17:02
小学生学习指导(低年级)(2019年6期)2019-07-22 03:33:10
四川师范大学学报(自然科学版)(2015年2期)2015-02-28 14:07:36
