
基于大数据匹配的大学生心理健康因素分析算法研究
2022-05-10 10:25王佳齐杨思宇
电子设计工程 2022年9期
王佳齐,杨思宇
(成都理工大学工程技术学院,四川乐山 614000)
随着高校大学生数量的增加,同时毕业、就业和家庭矛盾等社会问题的激增,使得大学生心理健康问题逐渐凸显[1-2]。如何发现影响大学生心理健康问题的因素并及时解决,已成为一个新的研究热点[3-4]。针对大学生心理健康复杂的环境因素,如何切实有效地分析各个因素和大学生心理健康的关系则是其难点问题[5]。
利用大数据技术,为心理健康领域研究开辟了新的方向[6-7]。文献[8]提出在大数据背景下重构心理学体系特征。文献[9]提出基于改进Ising 模型的心理量表大数据分析。此外,文献[10]提出利用大数据技术开发心理疾病预测系统。大数据技术在心理健康领域的广泛应用说明了其在数据挖掘和分析方法领域所具有的优势,可在海量数据中发现数据的相关趋势。
在大数据广泛应用于心理健康领域的基础上,利用大数据技术研究关于心理健康危机预警新途径已成为一个新的研究方向。文献[11-12]提出利用大数据技术预警心理危机与孤独系数,在一定层面上可侧面反应大学生心理健康水平。基于高校大学生幸福感与心理弹性的相关研究也取得了一定的成果。在心理大数据分析方面,数据挖掘和关联规则特征提取算法发挥了一定的作用,但对于复杂的外部环境因素,如何确定主要因素仍存在一定的不足[13-16]。
中文针对大学生心理健康问题分析需求和现有算法的不足,研究了基于大数据匹配的大学生心理健康因素分析算法。为了更优地分析影响大学生心理健康的因素,文中提出模型融合方法,将社交模型、情感模型和兴趣模型相融合,实现数据预处理。在此基础上,文中提出利用剪枝决策树算法,根据信息熵与增益率大小生成根节点,并进行后向剪枝去除不必要的节点。通过多个学校的数据分析对比可知,文中所提算法具有一定的普适性,且相对于现有算法实用性更高。
1 系统模型
为了分析影响大学生心理健康的各类因素,文中提出基于大数据决策树匹配的健康因素分析算法,可有效发掘和分析影响大学生心理健康的因素,为心理健康干预提供支持。算法架构如图1 所示。
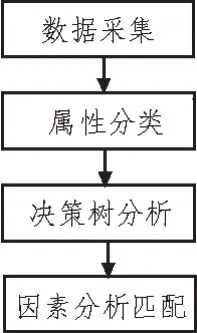
图1 大数据心理健康因素分析匹配算法架构
文中所提算法架构主要分为4 个部分,包括数据采集、属性分类、决策树分析和因素分析匹配。
1)数据采集主要是大数据信息提取,根据信息多样性和准确性原则采集数据,为算法提供数据支持;
2)属性分类是对第一步收集的大数据进行预处理,进行分类别、分属性归一化处理,生成属性集合;
3)决策树分析主要是判别各因素属性和大学生心理健康结果的相关性,保留相关性较大的因素,将相关性较小的因素剔除,使分析结果更加合理;
4)因素分析匹配是对经过决策树分析后的相关因素进行匹配分析,从而得到更精确的分析结果。
2 数据预处理
利用大数据匹配算法进行大学生心理健康因素分析需要大量的数据支持,数据的多样性和准确性直接影响算法分析的精确性。为了保证数据的完整性,文中采集的数据主要分为两种大的属性类型,其主要包括学生属性与家庭属性,心理健康因素学生属性数据和家庭属性数据如表1、表2 所示。

表1 心理健康因素学生属性数据

表2 心理健康因素家庭属性数据
除了表1 和表2 以外,为了分析大学生心理健康因素,仍需采集大学生的兴趣爱好、交友情况与相应的情感状态,然后参照表1 和表2 进行相应的赋值和数据处理。
为了更准确地分析大学生心理健康因素,文中采用数据模型融合方法进行预处理。如图2 所示,将采集的数据细化为情感模型、兴趣模型和社交模型3 类,并计算3 类模型参数与大学生心理健康的相关系数。选择相关系数最大的一类作为基础模型,其余两类作为待选模型,并依次计算待选模型中的数据参数加入模型后整体的数据相关性。若数据相关系数增大,则将该数据属性加入模型;否则将进行抛弃。通过数据预处理融合,可在一定程度筛选不相关数据,实现数据的预处理。
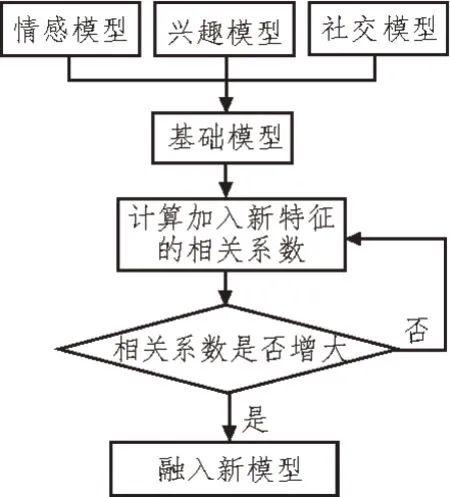
图2 心理健康因素数据预处理架构
3 大数据匹配因素分析
在完成数据预处理后,可利用文中所提的基于大数据匹配算法对大学生心理健康因素进行分析。为了保证算法分析的正确率,利用大数据匹配算法首先将数据分为训练集和测试集,然后验证算法的有效性,并淘汰奇异值。
设训练样本集合为S,其数据样本分为m类,定义为Mi,i=1,2,…,m,设Mi中的样本数为mi,则训练样本集合的信息熵为:

其中pi表示任意样本属于Mi的概率。
设属性A有n个不同的值,可以用属性A将整个训练集合分为n个子集。假设其中一个子集Sj包含S在属性A上具有相同值的所有样本,用Sij表示子集Sj中属于Mi的样本个数,则由属性A划分的子集的条件信息熵为:
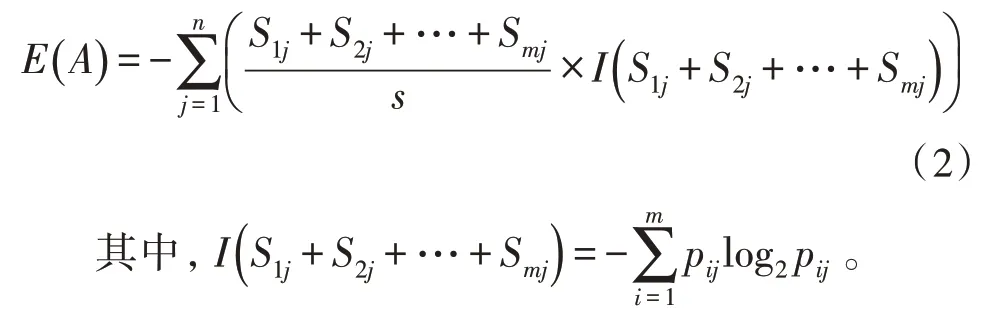
pij表示子集Sj中属于Mi的概率,如式(3)所示:

由式(1)和式(2)可计算在属性A上获得的信息增益:
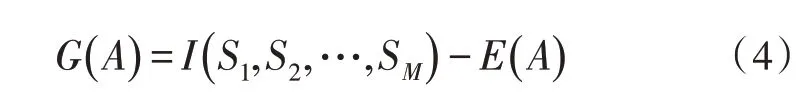
以属性A为整个样本进行分类,可以获得分类信息熵为:

其中,pj表示数据样本集合S中,属于属性A的第j个子集的概率:

根据式(4)和式(5)可以计算属性A的信息增益率:

文中所提基于大数据匹配的大学生心理健康因素分析算法利用C4.5 算法生成决策树,依次发现影响大学生心理健康的主要因素。C4.5 算法是选择信息增益率最大的属性生成决策树的算法。该算法流程如图3 所示,主要包括计算各属性信息熵、计算信息增益率、新建根节点和剪枝4 部分。

图3 大数据决策树匹配分析算法流程
图3 中,计算属性信息熵和信息增益率可分别根据式(1)、式(2)与式(7)进行计算。生成根节点是根据属性集合信息增益率的大小,选择最大的生成根节点。假设情感特征属性集合的信息增益率最大,则会生成关于情感属性的决策树,为了方便分析,化简的情感属性决策树示例如图4 所示。
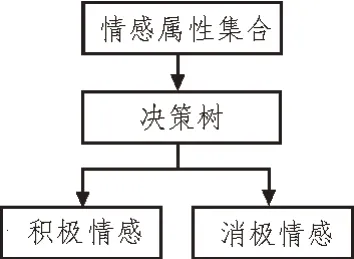
图4 化简的情感属性决策树示例
在生成若干个根节点后即会生成决策树,此时需要利用剪枝算法,搜索相关系数较大的因素。筛选掉相关系数较小的根节点,得到最终的决策树。
文中所提的大数据匹配心理健康因素分析算法步骤如下:
输入:数据集合S、类别集合Mi、属性子集Sj;
1)根据式(1)计算样本集合的信息熵;
2)根据式(2)计算属性的条件信息熵;
3)根据式(4)计算信息熵增益;
4)根据式(5)计算分类信息熵;
5)根据式(7)计算信息增益率;
6)根据信息增益率大小生成决策树;
7)判断去除第j个叶子节点是否减小数据相关系数,若是则转向9),否则转向8);
8)将元素j从数据集合g中剔除;
9)j=j+1;
10)根据决策树生成因素集合{Ri} ;
输出:因素类别集合{Ri} 。
为了验证算法的有效性,需要验证其性能指标。文中利用分类算法进行预测时,可得到的结果共有4 种情况,如表3 所示。

表3 不训练集预测结果
表3 中,TP表示预测为积极因素,且与实际情况相符;FN表示预测为消极因素但是与实际情景相反;FP表示预测为积极因素但是实际情况为消极因素;TN表示预测为消极因素且与实际情况相符。
为了显示数据的有效性,可以计算样本分类的有效性,即预测正确率,计算公式为:

召回率表示分类正确的样本数占该类真实样本总数的比例:

可以根据正确率和召回率综合验证所提算法的性能。
4 仿真验证及数据分析
为了验证文中所提基于大数据匹配的大学生心理健康因素分析算法的有效性和适用性,文中对比了不同学校大学生的心理健康分析结果。同时通过对比文中算法与其他现有算法的性能,验证文中所提算法的优越性。
如表4 所示,文中使用不同类型学校的大学生心理健康数据进行对比,涉及不同层次、不同学科的学校。可以发现文中所提基于大数据匹配的大学生心理健康因素分析算法,对于不同学校指标趋于一致,则说明算法具有优良的适用性。且可发现算法性能和学科有关,理工科学校更趋于一致,表明大学生心理健康水平与学业有一定关系。

表4 不同学校大学生心理健康因素匹配算法性能
如表5 所示,在使用同一数据集的情况下,文中算法的匹配正确率要远高于其他两种现有算法。ID3 算法存在欠拟合现象,因此性能较差。CART 算法由于剪枝不当,无法实现全局最优匹配,因此性能也略逊于文中算法。文中所提算法由于采用后向剪枝方法,避免了其他算法的缺点,因此具有一定的优越性。

表5 不同算法匹配性能对比
5 结束语
针对关注大学生心理健康问题的需求,文中提出了一种基于大数据匹配的大学生心理健康因素分析算法。与现有研究不同,文中使用综合模型考虑了更多的因素。并利用大数据信息,计算不同因素数据的信息熵,采用剪枝决策树算法实现因素分析。相对于现有算法,文中算法在不同指标上均有一定提高,并避免了奇异值对数据分析造成的影响。同时,经过对多个高校学生数据的分析验证,说明文中所提的大数据匹配算法具有较优的实用价值。
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
世界科学技术-中医药现代化(2021年8期)2021-12-21
世界科学技术-中医药现代化(2021年8期)2021-12-21
北京航空航天大学学报(2021年6期)2021-07-20
电子制作(2019年19期)2019-11-23
电子制作(2018年19期)2018-11-14
电子制作(2018年16期)2018-09-26
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
雷达学报(2017年6期)2017-03-26
电子制作(2017年24期)2017-02-02
