
基于SVM-IOA集成的动态风险识别模型研究
2022-05-10 00:03:04杨美芳
计算机技术与发展 2022年4期
杨 波,杨美芳
(江西财经大学 信息管理学院 信息系,江西 南昌 330000)
0 引 言
随着科技与信息的发展,经济全球化的不断深入,企业间关联越发紧密,客户需求的复杂多变以及竞争的加剧,使企业面临不确定因素增加,“互联网+”时代的到来,技术需求的提高以及互联网环境的多变,更加剧了这种不确定性,使企业动态风险进一步加大,若不能及时处理,可能导致企业日常经营活动无法正常开展,甚至产生严重的后果[1]。动态风险识别模型的核心思想是指通过已知的风险要素特征准确识别可能存在的风险[2],并确定风险等级,减少超高风险带来的经济损失,提高风险管理效率[3]。现有对动态风险识别的算法大致可分为经验统计特征算法、模式识别算法、机器学习算法、遗传进化算法和神经网络算法等[4]。传统的动态风险识别算法效果并不理想[5],如经典的模式识别算法需依赖于单个变量和预先设定阈值,而阈值的选取直接影响到算法的效率和效果,算法的可移植性较差[6]。神经网络算法虽然在风险识别方面具有一定的优势,但仍存在一些不足,如风险识别的动态性效果较差,对模型训练参数的依赖性较强,且模型的扩展能力有限[7]。因此,需寻求动态性能更好、检测率更高且移植性良好的动态风险识别算法。
支持向量机(support vector machine,SVM)是Corinna Cortes和Vapnik等于1995年首先提出的,是机器学习中最流行的非线性分类预测模型[8]。该模型是一种基于统计学习的结构风险最小化理论与VC维理论的普适模式识别模型[9]。它在解决高维、小样本及非线性模式识别问题中具有其他模型无法比拟的优势,且对于领域文本的复杂多变性不敏感,可以很好地进行模型训练与参数选取并具备良好的实践与扩展能力[10-11]。目前,支持向量机模型已成功应用于模式识别、数据分类和机器翻译等领域[12]。SVM的关键在于核函数技术的成功应用,进一步推动了支持向量机处理多维数据识别问题的研究[13-14]。支持向量机模型的选取是通过调节核函数的参数与惩罚因子来提高模型的识别性能,降低识别的错误率,因此SVM模型中参数的选取直接影响其识别性能[15]。目前,支持向量机参数选取缺乏理论与实践的指引,大多数核函数的参数选取仅仅依赖于先验知识[16]。
人工免疫优化算法是一种有效的全局函数优化算法[17]。人工免疫优化算法模拟生物免疫系统自然选择过程中发生的繁殖、交叉、变异和优选现象,在每次迭代过程中都保留一组候选解,并按某种标准从解群中选取更优的个体,利用免疫优化算子对个体进行组合,产生新的子代候选解,重复此过程,直到满足预先设定的收敛标准为止[18]。因此,该文首先将SVM的参数选取过程类比为函数最优化求解过程,然后通过IOA算法来求解目标函数的最优值,最后找到核函数参数和惩罚因子C的最优值。在此基础上,选取Heart-Disease数据集对SVM-IOA集成的动态风险识别模型进行仿真实验。实验结果表明,该模型能够选取出较好的核函数参数,同时在进行动态风险识别模拟实验中表现出较好的识别效果。
1 方法概述
1.1 支持向量机方法
支持向量机(support vector machine, SVM)主要是针对高维、小样本与非线数据样本情境,分析学习与训练已知的样本数据寻求问题的全局最优解,而不只是样本数据趋近于无穷大时的局部最优解。SVM算法的基本思想是选择一个非线性变换的核函数ψ(x),将N维输入的样本特征向量
k为训练样本的个数,从原空间映射到高维特征空间F,并在该高维特征空间构造最优线性回归函数:
F(x)=aψ(x)+b
(1)
其中,a为权值向量,b为偏差。一方面,SVM就是寻求一个平面aψ(x)+b=0,使得训练数据点距离分类平面尽可能远。根据结构风险最小化原则,参数a和b可通过最小化G函数确定。
(2)
其中,Gsv为控制经验误差函数,‖a‖2为控制模型分类能力,C为控制对错分样本惩罚的程度。另一方面,SVM通过核空间理论与方法,并运用非线性函数将原始特征空间映射到更高维的希尔伯特空间,从而将分类问题转化到低维空间中线性可分问题。不同的核函数ψ(x)可以构造不同类型的非线性分类平面学习机,从而产生不同的支持向量识别模型。目前,支持向量机常用的核函数及其参数如表1所示。

表1 支持向量机常用的核函数及其参数
针对支持向量机核函数参数的选取,国内外学者提出了大量方法。通常使用的方法是对核函数的参数进行随机组合,然后进行全局搜索,最后确定识别率最高的参数组合[19]。这些方法虽然简单,但是精确度不高,而且搜索过程非常耗时,效率低下[20]。也有学者提出基于梯度的核函数参数选取方法,虽然可以有效地进行参数选择,但对核函数的求导较困难,通用性较差。而人工免疫算法是借鉴生物免疫系统中自然选择与免疫应答过程的高度并行与自适应的全局优化算法。因此,该文运用免疫优化算法来解决支持向量机核函数参数选取的问题。
1.2 免疫优化算法(Immune Optimization Algorithm)
人工免疫算法是借鉴自然界中生物免疫系统的理论与方法,并结合工程或社会领域应用而人工模拟的一种计算模型[21]。它模仿生物的免疫识别与应答过程,具备较好的全局搜索能力和记忆功能[22]。免疫算法是在生物免疫系统的基础上,保留遗传算法优良特性的前提下,通过利用待求解问题的特征抑制其优化过程而形成的一种新型智能搜索算法[23],其基本要素和流程可描述如下:
IA(S,Rs,Ab,Ag,Aff,Sim,M,IM,Sp,Tc)
(3)
其中,S为搜索空间,Rs为抗体与抗原的表示空间,Ab为抗体空间集合,Ag为抗原空间集合,Aff为亲和力函数,Sim为相似度函数,M为记忆库更新机制,IM为免疫方法,Sp为选择百分比,Tc为终止条件。
人工免疫算法解决问题各步骤的对应关系为(以解决动态风险识别问题为例):抗原对应待识别的动态风险;抗体对应动态风险识别器;抗原与抗体的亲和力对应动态风险识别器性能的评估值;记忆细胞对应保留下的动态风险识别器;抗体促进对应动态风险识别器的促进,抗体的抑制对应动态风险识别器的删除;优秀抗体的生成对应较优的动态风险识别器的产生。人工免疫算法分为以下几个步骤:
(1)进行抗原识别,即理解待优化的动态风险识别问题,对问题进行可行性分析,提取已知的动态风险识别案例库,并建立合适的亲和度函数,同时设置动态风险识别问题的规则与约束。
(2)随机生成初始抗体群(即初始的动态风险识别器)。具体地,通过编码将动态风险识别问题的可行解表示成解空间中的识别器,在解空间内随机生成一个初始种群。
(3)计算所有种群的亲和度。
(4)判断是否满足算法预先设定的终止条件:如果满足条件,则终止算法寻优过程,输出计算结果;否则,继续寻优运算。
(5)计算抗体浓度和激活度。
(6)进行免疫应答过程的处理,包括免疫选择、克隆、变异和克隆抑制。免疫选择是指根据种群中抗体的亲和度和浓度计算结果选择优质抗体,使其活化。克隆是指对活化的抗体进行复制,增加样本的多样性。变异是指对克隆得到的抗体进行突变操作,使其发生亲和度变化。克隆抑制是指对变异结果进行再选择,抑制亲和度低的抗体,保留亲和度高的变异结果。
(7)种群刷新,以随机生成的新抗体更新种群中激活度较低的抗体,形成新的抗体种群,转步骤(3)。
为方便算法描述,该文定义Ag为输入的抗原集,Ab为抗体集,M为记忆细胞集,Aff为抗原和抗体亲和力函数,S为抗体间相似度矩阵。人工免疫算法的一般流程如图1所示。
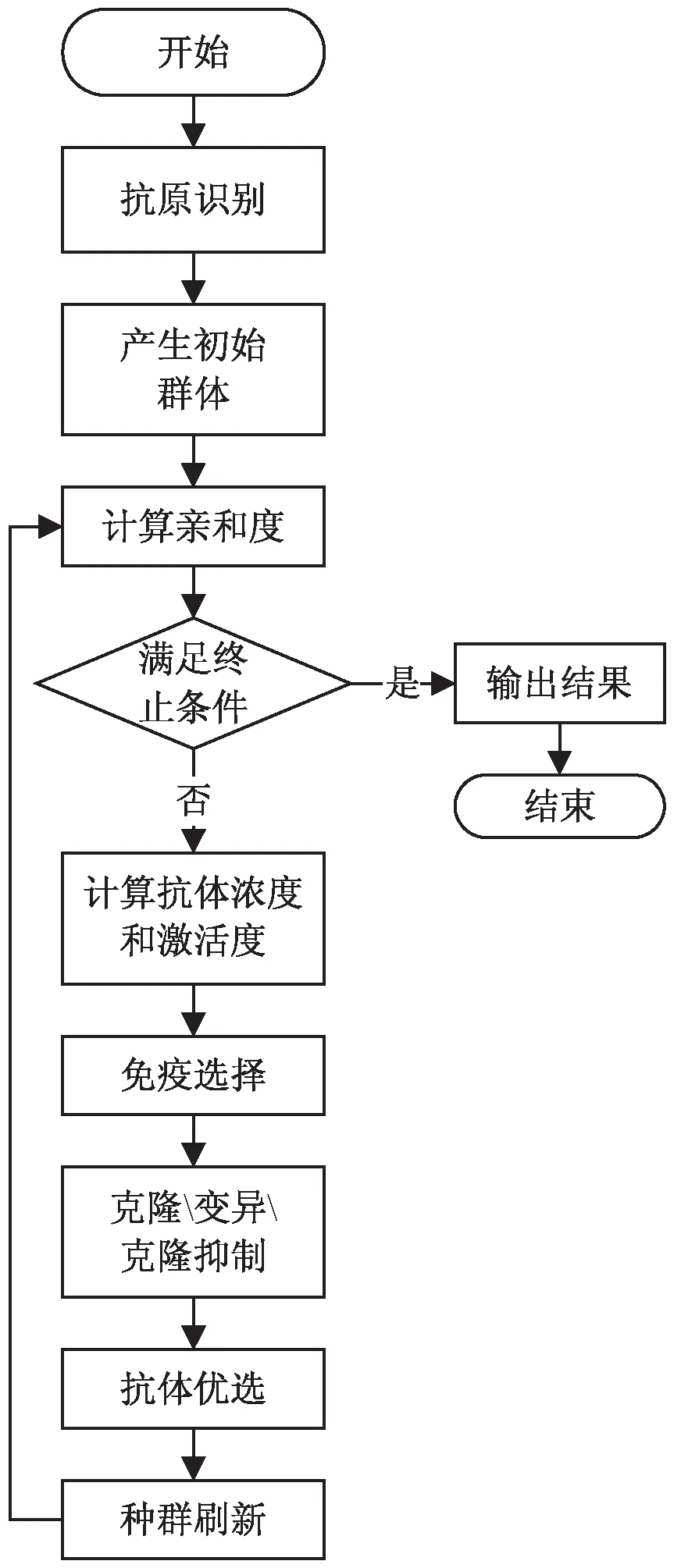
图1 人工免疫算法一般流程
人工免疫算法的一般流程中涉及到的关键机制主要包括亲和力计算、抗体记忆库更新、抗体分裂变异机制和抗体优选机制。具体免疫机制核心思想如下:
(1)计算亲和力。
假设抗原(Ag)和抗体(Ab)结构相似,均为长度为n的十进制位串组合。抗原抗体的亲和度与它们之间的距离相关。因此,抗原Ag和抗体Ab的亲和度采用欧几里得距离计算。Ag和Ab亲和度Aff(Ag/Ab)计算公式如下:
(4)
任一抗原Agi在机体抗原群体G中的抗原浓度(C)计算公式如下:

(5)
其中,0<α<1,d(g,Agi)为g与Agi的欧几里得距离。
高校图书馆信息素养教育的改进措施主要分为两大部分,第一是举办课外学习素养教育活动,第二是信息素养教育课程的优化。
(2)抗体记忆库更新。
更新抗体记忆库选择与抗原亲和力更高的抗体加入到记忆细胞集中。由于抗体记忆库数目有限,动态清除与抗原亲和力低于σ的抗体,即抗体的自然死亡。抗体记忆库更新机制可用如下公式描述:
Rupdate(t)=

(6)
其中,R(t-1)为t-1时刻组织内本身还存在的抗体识别器,Rdead(t)为t时刻组织内消失的识别器,Rchoice(t)为t时刻组织内通过分裂变异优选产生的识别器,Nnew(t)为免疫系统在t时刻新增的识别器。Rchoice(Agi)分裂变异优选机制如下。
(3)抗体分裂变异机制。
抗体分裂机制:当抗体激活度达到了预定的阈值,当前抗体开始分裂增殖[24]。具体分裂机制如下:①若抗体激活度Ad大于等于激活阈值,则抗体分裂出两个子代抗体;②对子代抗体进行变异操作。定义抗体的激活度公式为:
Abad=Aff(Agi,Abi)*eεC(Agi)
(7)
其中,Aff(Agi,Abi)为抗原和抗体的亲和度,C(Agi)为抗原的浓度,ε为调节系数。从公式(7)可得知,抗体的激活度主要由抗体抗原间的亲和度与抗体的浓度决定。若某类抗原的频度和强度越大,抗体的活化度越大,抗体对此类抗原识别能力也就越好。
根据子代变异抗体的亲和度大于父代抗体亲和度的原则,以确保免疫识别的准确性[24]。如果变异后的两个子代抗体亲和度都低于父代抗体亲和度,则删除这两个子代抗体,保留父代抗体;如果变异后的两个子代抗体亲和度都高于父代抗体亲和度,则删除父代抗体,保留子代抗体,并根据公式赋予子代抗体对应的抗原浓度;如果变异后的有一个子代抗体亲和度高于父代抗体亲和度,则保留父代抗体和该子代抗体,并设定该子代抗体对应的初始抗原浓度等于父代抗体对应的抗原浓度。
(8)
(9)
其中,Aff(Abchildren,Abparenti)为子代和父代抗体的相似度,该文使用欧几里得距离计算抗原抗体的相似度。
2 SVM-IOA动态风险识别模型
2.1 问题的定义
所谓动态风险识别问题,是指在含有风险抗原实例的复杂系统中定位出具体风险抗原实例的过程。由于风险随时间和外部环境而动态变化,已知的风险预控方案与未知的风险抗原并不能完全匹配,而需进行变异优选以适应动态风险的变化。
该文将动态风险抗原作为支持向量机SVM的目标函数,接着通过随机函数生成与之对应的抗体作为目标函数的解,再计算抗原和抗体间的欧几里得距离(即亲和度),并将亲和度无限逼近可行解与最优解。最后根据抗体分裂变异机制对抗体进行分裂与高频变异产生更多的子代抗体集进行优化,直到满足目标函数的终止条件。
融合支持向量机识别技术与免疫优化技术(SVM-IOA)的动态风险识别方法中,抗体的定义如下:支持向量机中的参数作为抗体。以RBF核函数为例,核函数有一个参数,则抗体中存放核函数参数σ和SVM模型中的惩罚参数C,若核函数中有两个参数,则抗体中存放核函数的两个参数和SVM模型中的惩罚参数C。
2.2 模型算法
基于SVM-IOA的动态风险识别算法的步骤如图2所示。
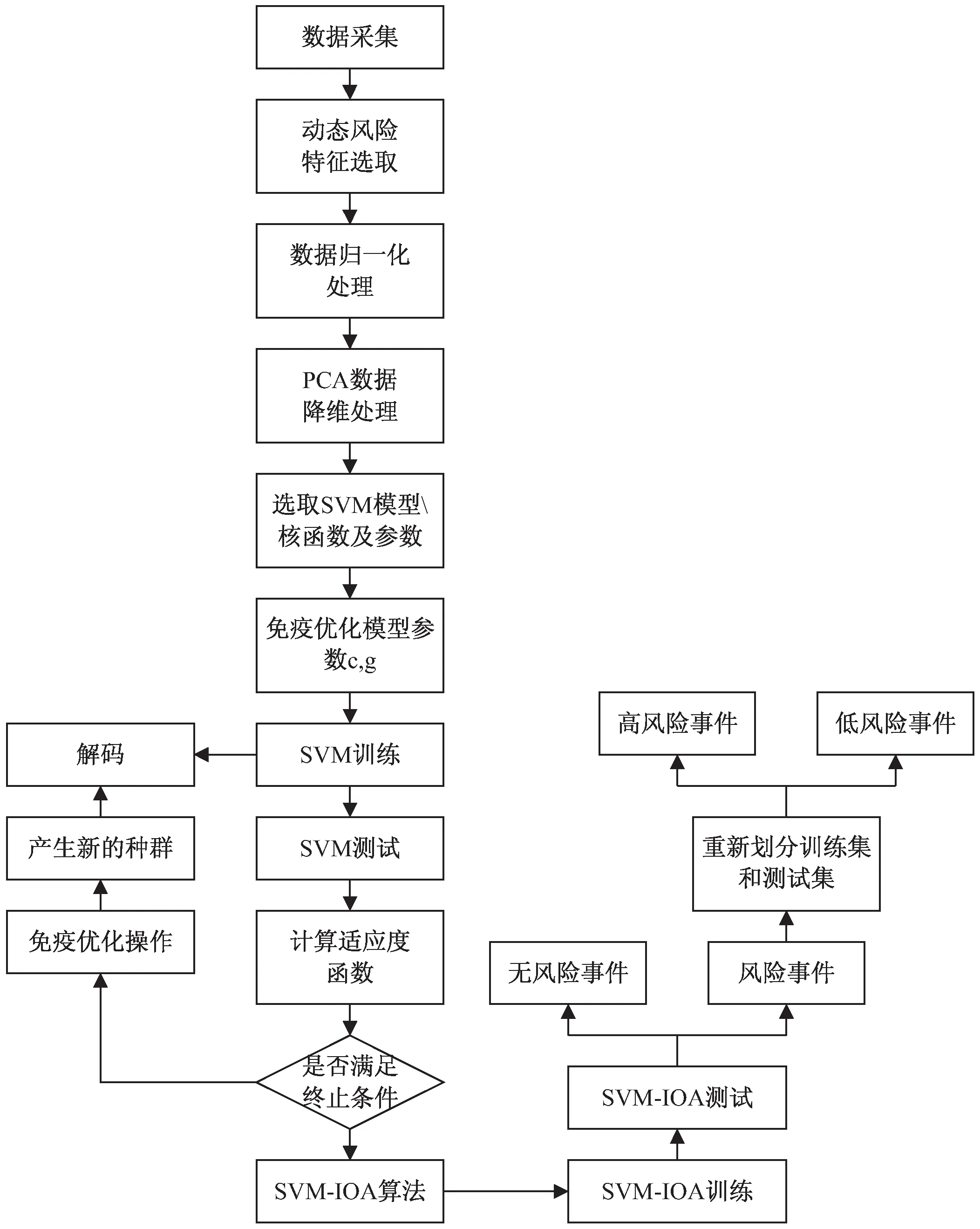
图2 基于SVM-IOA的动态风险识别算法流程
该算法的具体描述如下:
Step1:初始化实验数据,主要是动态风险特征数据的选取,并对其进行归一化和降维处理,得到用于SVM-IOA训练和测试的样本数据。
Step2:将支持向量机目标函数设置为抗原,SVM及其核函数的参数作为抗体。
Step3:初始化SVM-IOA模型参数,运用Step1中的训练样本数据训练模型,通过多次迭代优化的参数,建立SVM-IOA测试模型。
Step4:运用Step3得到的测试模型对测试样本集进行识别。
Step5:根据适应度函数,计算模型的精度,若不符合精度要求,重新设定SVM-IOA模型参数,并对参数进行免疫优化操作,产生新的种群数据,返回Step3,重新训练,直至满足终止条件;若符合精度要求,转入Step6。
Step6:采用SVM-IOA算法,运用Step1中的训练样本数据训练模型通过多次迭代优化的参数,建立SVM-IOA测试模型,并运用该模型对风险事件进行第一次识别,判断出是否为风险事件。
Step7:根据第一次识别结果,重新划分训练集和测试集,再次运用SVM-IOA模型对风险事件进行识别,判断该事件是高风险或低风险。
2.3 模型参数选取
大多数文献在选择支持向量机核函数参数时基于经验,缺乏严谨的理论支持,难以训练得到最优的参数值。该文选用径向基(RBF)核函数的支持向量机模型,将RBF核函数的公式带入F(x)超平面函数中。利用免疫优化算法对惩罚参数和径向基核函数的参数进行优选。将如下公式作为适应度函数,其中分类精度是指优选过程中模型对测试集的分类正确率,它反映模型对动态风险问题的分类识别能力,即可用公式(10)计算。

(10)
其中,TP(true positive)表示SVM-IOA模型识别出风险抗原的个数,FP(false positive)表示SVM-IOA模型未能识别出风险抗原的个数。
最大进化代数取值为200,一般取值范围为[100,500],种群最大数量取值为100,一般取值范围为[20,100],参数c的变化范围默认为[0,100],参数g的变化范围默认为(0,1 000),经过免疫优化算法迭代后,得到惩罚参数c,径向基核函数的参数g。免疫优化算法优选后的参数结果如图3所示。此时,SVM-IOA模型算法对训练集和测试集的平均分类精度达到了95.5%,适应度变化如图4所示。
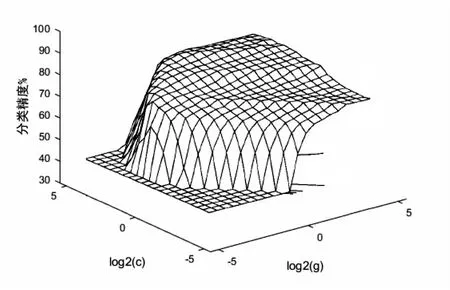
图3 参数优化后分类精度结果

图4 SVM-IOA算法适应度变化
3 实验结果与分析
3.1 模型算法
该文运用Heart-Disease数据集作为实验数据,Heart-Disease数据集包含14个属性,其中固定属性13个,预测属性1个,预测属性分为两种状态,分别为健康状态和疾病状态[24]。该文将实验数据中的预测属性健康数据称为正常数据,疾病数据称为风险数据。根据集成算法和风险识别率公式,仿真分析SVM-IOA模型的准确性和执行效率。
3.2 评估方法
基于SVM-IOA的动态风险识别过程中,通常使用识别率作为衡量识别器设计效果的指标。风险抗原识别率IPR(identify positive rate)表示识别器能够正确识别出风险抗原的比例,即可用公式(10)计算。
非风险抗原识别率INR(identify negative rate)表示识别器对于非风险抗原正确识别的比例,即可用如下公式计算:
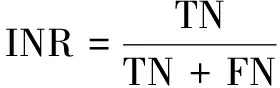
(11)
其中,TN(true negative)表示识别器识别出非风险抗原的个数,FN(false negative)表示识别器未能识别出非风险抗原的个数。
综上所述,得出计算识别率的公式如下:
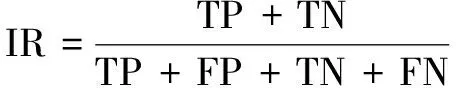
(12)
3.3 实验结果对比分析
该文将SVM-IOA模型的仿真结果与传统的“自体-非体”免疫算法(self-non-self algorithm,SNSA)、已知的树突状细胞算法(dendritic cell algorithm,DCA)和克隆选择算法(clonal selection algorithm,CSA)进行实验对比分析,对比结果如表2所示。

表2 各免疫算法识别率对比 %
从表中各免疫算法的识别率可得出,SVM-IOA和CSA的抗原识别准确率均高达90%以上,其中:SVM-IOA抗原识别准确率为96.21%,SVM-IOA的风险抗原与非风险抗原的识别率分别为95.82%和96.01%,均高于SNSA、CSA和DCA的识别准确率。可见SVM-IOA的抗原识别效果很好。
4 结束语
针对当前动态风险识别模型中支持向量机核函数的参数选取对识别模型性能的影响问题,提出了一种基于支持向量机与免疫算法的组合来建立动态风险识别模型的方法,为复杂多变的动态风险识别问题的处理提供更加高效、可靠的决策支持。首先对原始数据进行特征选取及降维处理,然后通过人工免疫算法对支持向量机的惩罚参数和核函数的参数进行择优,建立基于支持向量机与人工免疫集成的动态风险识别模型,最后运用Heart-Disease数据集进行实验,实验结果表明该模型具有很好的识别效果。
该文的理论贡献主要体现在以下两方面:(1)与现有动态风险识别理论相比,尝试从支持向量机与免疫优化算法集成视角进行动态风险识别模型研究是该文在研究视角上的创新。借鉴支持向量机方法在解决小样本、非线性及高维模式识别中的优势,动态风险识别逐渐转向机器学习视角,但传统的支持向量机核函数的参数选取仅凭先验知识,缺乏实践指引,难以解决复杂多变的动态风险问题。该文采用人工免疫算法求解支持向量机核函数参数和惩罚因子C的最优值,从而理论上为支持向量机解决动态风险识别问题选取较好的参数。(2)从机器学习视角研究动态风险识别推动了企业风险管理应用与实践,目前很少有人主动采用这种方法。究其原因,主要在于方法的可操作性以及缺少具体的实验指导。为了弥补这一缺陷,该文不仅介绍了支持向量机与人工免疫集成的动态风险识别模型,还借助仿真工具对该方法进行具体的模拟仿真实验。
支持向量机与人工免疫集成的动态风险识别方法仍有待深入研究,主要表现在与互联网、企业与工程等领域风险识别的紧密衔接。支持向量机与人工免疫集成DRI方法的应用所面临的挑战在于企业风险指标体系的构建、各类风险指标的量化,以及该方法在各个领域普适性问题。未来可以从以下两方面进行深入探究:一是系统分析企业内外部风险的形成和演化机理,构建出相关的风险指标体系,运用支持向量机与人工免疫集成方法对企业动态风险识别进行实证分析。二是探讨不同领域风险识别过程,从而进一步深化和拓展支持向量机与人工免疫集成方法,并进一步增强方法的普适性。
猜你喜欢
卫星应用(2022年7期)2022-09-05 02:36:02
卫星应用(2022年3期)2022-05-23 13:44:30
新高考·高一数学(2022年3期)2022-04-28 07:02:46
卫星应用(2022年1期)2022-03-09 06:22:20
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
环球慈善(2019年6期)2019-09-25 09:06:24
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
西南医科大学学报(2015年1期)2015-08-22 13:01:46
医学研究杂志(2015年6期)2015-07-01 17:41:11
