
面向电影评论的情感词典构建方法研究*
2022-05-10 07:28:20张再跃
计算机与数字工程 2022年4期
汪 韬 张再跃
(江苏科技大学 镇江 212003)
1 引言
电影评价文本信息是观影者接触较为广泛的网络文本信息形式,是观众了解电影动态、把握剧情梗概的重要手段之一。电影产品是我们生活中一种较为特殊的商品。在用户观看电影的过程中,观看用户在视听方面的亲身体验将影响其他用户对电影产品的消费,因此电影产品如果在用户中评价良好将会吸引很多潜在顾客。网络评论信息由于实时性非常强,如果对于负面评价不及时响应,往往对即将上映或者正在热映的电影造成负面影响,所以在电影宣发过程中十分重视电影网络评价的主动引导[1]。分析这些数量巨大的评论需要一种有效的方法,每一个观看电影的用户根据自己观看电影的感受对电影进行评论,电影宣传方针对这些评论去挖掘出用户真实的情感倾向,就可以帮助电影的宣传方找出电影宣传方向中存在的不足,及时采取相应的补救措施,从而可以提高潜在观影者的期待度,为企业产生有价值的信息,吸引观众观看[2]。
对于电影厂商与电影宣传单位,电影观众的观后评价数据一般在相应的互联网平台上展示出来。厂商可以通过分析这些评价数据来判断用户的电影喜好,从而避免花费大量的人力物力去做问卷调查。通过现代化的数据挖掘、情感提取分析来分析观影用户的评论、喜好和行为[3],能够帮助电影厂商确定电影的方向和提高电影的质量。例如,各大制片商通过在电影评论区的内容信息,采用相关技术分析数据中隐藏的价值信息,如用户在电影类型、电影剧情、演员阵容等方面的意见和建议,为制片商确定观影者类型与情节喜好,选择能取得更多观众喜爱的演员阵容,并根据分析得到的结果为以后的电影拍摄提供参考,真正把握市场动向,从而提高影片票房[4]。
对于普通观影者,当前经济社会飞速发展,每天都会有大量国内外各语种、各类型的电影大片发布,数量如此多的电影,让观众应接不暇。网络上其他观影者的评论信息成为潜在观众获取电影评价信息的重要渠道,同时这些用户的评价也是其他消费者选择影片时的参照,直接影响潜在观影者是否选择观看这部电影。越来越多的观影者在决定是否看某部电影前,会主动浏览关于此部电影的各方面评价,包括演员阵容、剧情、画面效果等[5]。评价不好的电影就没有花钱买罪受的必要,而口碑票房俱佳的电影必将成为茶余饭后的谈资,必须去刷,电影评论成为选择是否观看电影的重要依据。在纷繁复杂的评论信息中需要找到高质量的评价并非易事,使用情感分析技术可以减少消费者大量查询时间[6]。
2 构建电影评论情感词典
2.1 通用情感词词典
本文综合选取知网词典和台湾大学情感词典中的褒贬义词,将二者进行优化合并得到适用于通用语境下的通用情感词词典。通用情感词词典删去了两个词典中有歧义的词汇,整理使用二者中情感倾向度较为准确的正面和负面情感词,形成一个新的积极情感词词典,和一个新的消极情感词词典,最后由积极与消极情感词词典共同组成通用情感词词典。由于HowNet[7]和NTUSD[8]不像英文情感词典那样,不仅区分了词汇的情感极性,还描述了词汇的情感强度。这两个情感词典仅仅区分了情感词的正面与负面情感倾向性,因此将自主构建的通用情感词词典中的正向情感词语的权值设置为1,而负面的情感词语的权值设置为-1。
2.2 程度副词词典
程度副词一般位于要修饰的副词或者形容词前,其主要作用就是限定这些词的情感程度[9]。程度副词通过与情感词结合影响整个语句的情感程度,可以强化情感词的情感倾向性,也可以产生减弱的作用。比如说:“电影很好看,剧情非常感人”,这句话中出现了两个程度副词“很”和“非常”,观影者在想要表达电影“好看”的同时加上了程度副词“很”来加强“好看”的情感程度。但是在基础情感词典中,“很”既不属于正向情感词汇也不属于负面情感词汇,若不考虑程度副词对情感倾向性的影响,会导致在实际计算情感值时使整个句子丢失一定的情感得分。因此在对整个句子进行情感倾向性判断时,本文将程度副词所带来的影响纳入考虑范围。在整理过程中,发现不同的程度副词对情感倾向性的影响是不同的。例如:“人物塑造令人很失望,剧情有点拖沓”,“很”加强了“失望”表达的情感“有点”削弱了“拖沓”表达的情感。本文考虑到程度副词对情感词的修饰程度的不同,根据修饰程度强弱进行分级,共有极、高、中、低四个等级也对应着2、1.7、1.2、0.8四个权值,如表1所示。

表1 程度副词
2.3 否定词词典
单独使用的否定词是不存在感情色彩的,它的实际作用是修饰情感一类的词,它与程度副词有一定的区别,程度副词的有两方面作用,一方面可以加强情感词的情感强度,也可以削弱情感词的情感强度。否定词的作用只有一个,它与情感词结合使用会使原本的情感词语义发生反转[10]。若否定词修饰的是个正面积极的情感词,那么就会使整个句子的情感表达倾向性变为消极。若否定词修饰的是个负面消极的情感词,那么在加入否定词后整个句子的情感表达倾向性就成积极的[11]。中文文本中否定词的数量也是灵活多变的,可以含有两个否定词甚至多个。含有偶数个否定词的句子,句子的整体情感倾向不会发生改变。含有奇数个否定词的句子,句子的整体情感倾向发生逆转。当一个句子中出现的否定词加上程度副词时,句子的情感倾向性不会发生改变,只会影响情感强度。结合电影评论文本语料和中文日常表达方式,本文直接采用人工收集的方法构建了包含45个否定词的否定词词典,如表2所示。

表2 否定词
2.4 使用SO-LPMI算法扩建电影领域情感词典
一般来说,任何一个基础的情感词典都不会完全适用于某一个特定领域,其对于含有领域专业词汇句子的情感分析会大打折扣[12]。例如:“这剧情真狗血”。“狗血”在实际生活中只是一个名词,表示狗这个动物的血液,但是在电影评论中就表示剧情太过夸张、近乎胡扯,表达了观众的不满情绪。为了使情感词典能在电影评论领域有一个比较全面的文本倾向性分析能力。采用计算词汇间点互信息的方法可以很大程度地扩展基情感词典,而且可以有效地提高情感分析的效率。
在信息论中,如果要计算两个词语x1与x2的PMI值[13],计算方法如式(1)所示。
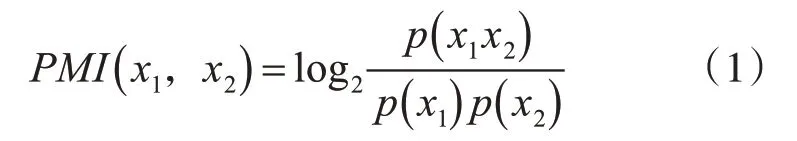
其中,p(x1)表示文本里词语x1出现的概率,p(x2)表示文本里词语x2出现的概率。p(x1x2)表示词语x1和词语x2一起出现的概率。在信息论的点互信息算法中,使用情感词典中正向和负向的种子词与待定情感词的关系来判定一个词语的情感极性,计算方法如式(2)所示。
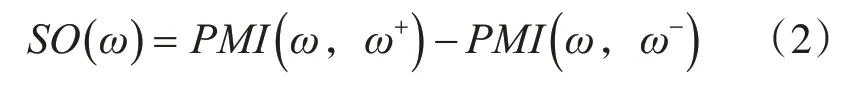
其中,ω是指等待确定情感倾向的词语,ω+是指具有正向情感的种子词语,ω-是指具有负向情感的种子词语。
建立在点互信息基础上的SO-PMI算法描述为:选择具有代表性的正向情感词语和负向情感词语分别作为正向和负向的种子词语集合,分别记为集合P={p1,p2,p3,…,pn},和集合N={n1,n2,n3,…,nn},词语x为我们需要判断情感倾向的词语,式(3)如下。
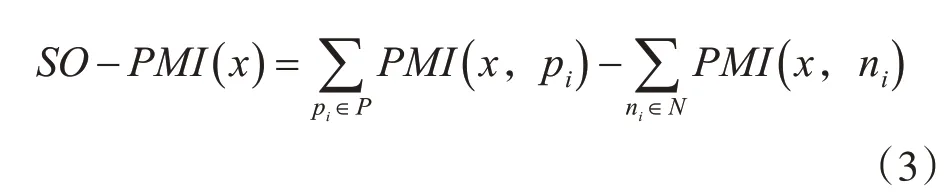
通常情况下,采用0作为临界值,从而能够得到三种结果:S O-P MI(x)>0,则表示这个词语具有正向情感,称之为褒义词语;S O-P M I(x)=0,则表示这个词语具有中性情感,称之为中性词语;SO-PMI(x)<0,则表示这个词语具有负向情感,称之为负向词语[14]。
采用SO-PMI算法来计算词语情感值的时候,要人为地从情感语料中选取一定数量高质量的基准词,从而确定一组具有正向情感的词语和一组具有负向情感的词语来作为基准词集合。最终计算需要判断的情感词与种子词语之间的点互信息差值,与阈值进行比较后将词语添加到相应的情感词典里面,从而实现对情感词典的扩充[15]。
本文在原先PMI计算点互信息时引入共现词语间的距离关系,更细致地计算点互信息:若两个词之间的距离较短,那么它们的关联性越大;若两个词之间的共现距离越长,那么它们的关联性越小。实际运用到情感分析中就是在一段文本中两个词语离得越近,这两个词的情感倾向性就越趋同。共现距离按照两词之间相隔的字符的数量来进行计算。如式(4)所示。

其中Lw1表示在一条评论中从评论开始字符到两个词排序较为靠前的词语的最后一个字符的字符数量,Lw2表示在一条评论中从评论开始字符到两个词排序较为靠后的词语的第一个字符的字符数量。
引入词间距的PMI计算公式改进为LPMI,如式(5)所示。
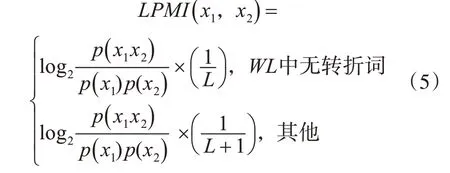
WL为x1与x2之间的字符组成的字符串,转折词如表3所示。

表3 转折词表
SO-PMI也相应地改进为SO-LPMI算法,如式(6)所示。

本文从电影评论数据集中人工筛选出电影剧情、电影画面、演员阵容、演技等多个方面词频较高且情感色彩鲜明的基准情感词汇,并将这些词按照消极与积极的词性划分为正向种子集与负向种子集。使用引入词间距的SO-LPMI算法计算待定词和基准词的SO-LPMI值,以SO-LPMI值的正负性为依据,把待定词录入电影领域情感词典中,其中选取的基准词部分如表4所示。
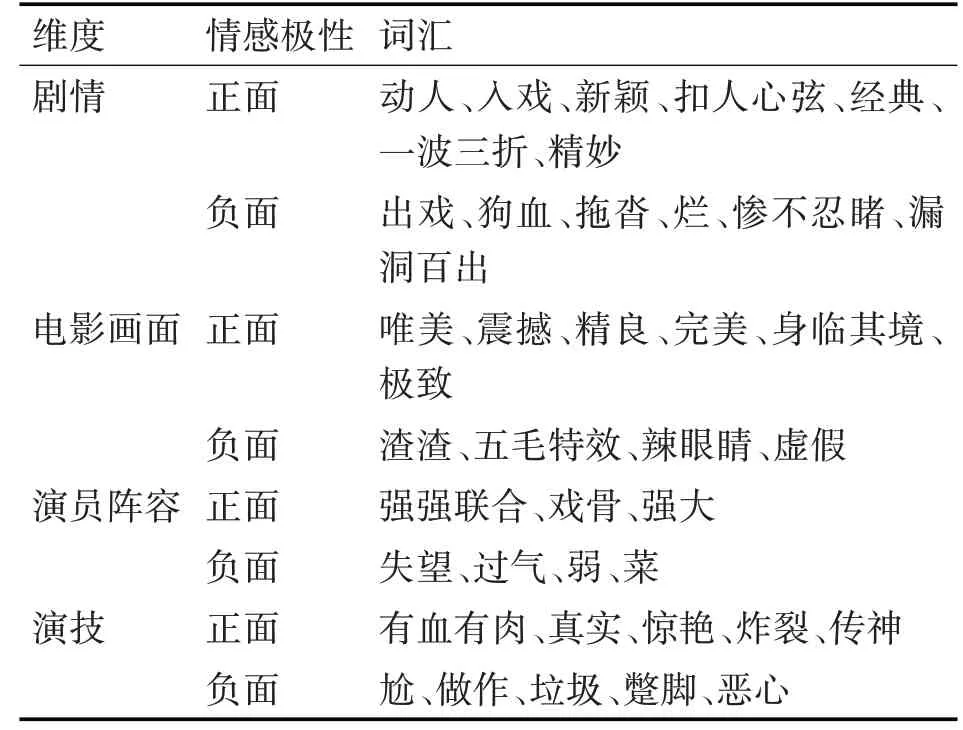
表4 基准词
SO-LPMI算法扩充电影领域情感词典,具体方法步骤如下。
第一步:通过八爪鱼网络爬虫软件爬取豆瓣电影网上的电影短评,把这些原始数据中无用的数据与噪声去除,再利用中文分词技术将实词切分出来并存放在一起。
第二步:用通用情感词词典匹配上一步中搜集到的词汇。将匹配结果分为三类,第一类是匹配到的褒义词,第二类是匹配到的贬义词,第三类是不存在于通用情感词典中的词汇,把这三类词分别存储在三个集合中。
第三步:辅以人工的方式,分别在褒义词集合和贬义词集合中,挑选出在评论文本中出现次数较高并且保证个数相同的褒义词与贬义词作为基准词。
第四步:根据SO-LPMI算法来计算基准词与在通用情感词典不匹配的词汇间的SO-LPMI值。
第五步:使用第四步中得到的SO-LPMI值将不匹配词汇分为褒义词与贬义词,分别存于电影领域褒义词词典和电影领域贬义词词典中,二者共同构成电影领域情感词典。
情感词典总体构成如图1所示。
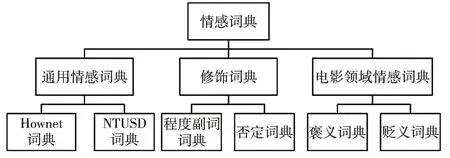
图1 情感词典构成
3 实验过程
本文实验语料使用网络爬虫爬取的电影评论语料集,囊括正向、负向的评论各3000条。通过比较不同的情感词典在电影评论数据集中的分类效果完成对比实验。查询语料中所有情感词汇与否定词和程度副词的搭配情况,按照提出的情感词与否定词、程度副词权值计算方式,综合计算每条电影评论的整体情感值。以情感值的大小作为分类的依据,当情感值大于0时认为文本为正面情感倾向性情感,当情感值小于0时认定文本为负面倾向性情感。
整个实验中使用了本文构建的电影领域情感词典、NTUSD词典和知网词典。在保持数据集不变的情况下,分别使用上述三种情感词典进行情感分析,由此可以分析对比实验效果。
对比实验按照以下方式进行:
1)针对电影评论语料集完成文本预处理操作。
2)使用情感词典来分析电影评论语料的情感值。主要考察语句中的情感词和否定词以及程度副词如何搭配的,根据不同的搭配情况,使用不同的权值计算方式带入其中,计算各个词语搭配的情感值权重。
3)把步骤2)中得到的情感值权重进行求和计算,得到一整条评论的整体情感值。在情感总值大于零的情况下,由此得出该评论文本为具有积极情感的文本;在情感总值小于零的情况下,由此得出该评论文本为具有消极情感的文本。
4)利用分类指标对分类结果进行评测。对比三个词典在电影评论的不同表现,以比较出三种词典在电影评论领域情感分析的有效性。
4 实验结果分析
使用三种不同词典对电影评论进行情感分析,得到了不同的精确率、召回率和F1值的数据,如表5所示。

表5 三种词典实验结果
在使用完全相同的电影评论语料集时,由于本文所构建的电影领域词典涵盖的情感词能合理匹配电影评论中的情感词,使用本文所构建的词典进行情感分类的效果明显优于其他两种词典。但是三个词典在负面评价的电影评论文本中的判别效果均高于正面评价文本。导致这种现象发生的原因可能是中文文本中的含蓄表达方式。中文表达中,有时不会直接用负面词汇表达某方面的不好,而是会对正面词汇加以修饰来含蓄表达出自己的负面情感,这就导致文本表面上是正面情感,但其真实内涵是负面情感,机器不能进行有效识别。负面文本中,一般不会出现这种情况,所以负面文本分类效果相比于正面文本会好一点。
5 结语
本文重点介绍了如何构建电影领域情感词典的全部过程,再与常用中文情感词典进行对比实验分析结果。首先是通用词典的构建,其由Hownet词典和NTUSD词典中的情感词汇通过筛选得到。然后构建了程度副词词典和否定词词典,这两者都是根据现有词典经过人工选取得到的。接着构建电影领域专用词典,若用传统的SO-PMI算法进行领域词典的扩充仅考察词语间的共现概率,没考虑语义表达中的词间距关系,基于此,通过引入词共现距离来改进SO-PMI算法。使用改进后的SO-LPMI对电影领域情感词典进行扩充,将扩展后的电影领域情感词典与通用词典、程度副词词典和否定词词典结合为电影评论情感词典。实验证明,通过适用于电影领域的情感词典进行电影评论的情感分析相较于用通用的情感词典分析电影评论有更好的分类效果。
猜你喜欢
阅读(快乐英语中年级)(2023年6期)2023-05-24 22:53:36
有色金属(矿山部分)(2021年4期)2021-08-30 06:10:42
三门峡职业技术学院学报(2021年4期)2021-04-19 09:00:38
文苑(2019年24期)2020-01-06 12:06:50
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
新闻研究导刊(2015年17期)2015-12-25 12:36:42
语言与翻译(2015年4期)2015-07-18 11:07:43
中央民族大学学报(自然科学版)(2014年3期)2014-06-09 08:54:32
高中生学习·高三版(2014年3期)2014-04-29 06:09:37
