
改进YOLOv3的火灾检测①
2022-05-10 08:39王林,赵红
计算机系统应用 2022年4期
王 林,赵 红
(西安理工大学 自动化与信息工程学院,西安 710048)
火灾比其它自然灾害更为常见,一旦发生,不仅会造成严重的人员伤亡和财产损失,还会产生有毒气体污染环境[1].2019年3月四川凉山火灾事件导致31 人遇难,大面积的森林土地丢失.若能及时发现火情并报警,则能减少损失[2].随着科学技术的发展,基于传感器的设备被用于火灾检测,但探测范围有限,对场地空阔的林火等大空间来说安装成本高很难做到均匀覆盖,且对物理量的观测很容易受环境因素的干扰.随着计算机视觉和图像处理技术的发展及监控的普及,基于视频图像的火灾检测出现[3].李红娣等人[4]将图像特征金字塔的纹理特征和边缘特征组合,用机器学习方法支持向量机训练达到94%以上的检测率和3.0%以下的误报率.Kim 等人[5]通过火焰的RGB 颜色模型检测火灾但是检测的准确率不高.李巨虎等人[6]提出了基于颜色和纹理特征的森林火灾图像识别,通过提取不同空间的纹理特征,将得到的特征向量送入SVM 分类器,获得了94.55%的准确率.但传统的视频火灾检测大都基于人工提取火焰和烟雾的静态特征及运动区域的动态特征来研究的,人工提取特征容易造成检测的精度较低.
2012年,深度学习的出现促使人工智能飞速发展,为目标检测注入新的活力,Krizhevsky等人[7]提出Alexnet 并将它用在图片分类中,将错误率从25.8 %降到了16.4 %,2014年Girshick 等人[8]提出将具有CNN特征的区域(RCNN)用于目标检测,开启了目标检测的新时代.此后,目标检测在计算机视觉[9]语音识别[10,11]多个领域表现出了良好的效果.2015年,相关学者提出具有历史意义的一步检测YOLO(you only look once),可以达到每秒45 帧的速度,Redmon 等人[12,13]前后提出了将YOLO1、YOLO2 用于火灾检测,精度和速度逐渐提高.杜晨锡等人[14]提出了基于YOLOv2 网络的火焰检测方法,但模型可应用的场景简单.杨剑等人[15]提出了基于图像处理技术的烟雾检测在家庭火灾防范中应用,实验取得了较高的准确率,但对小区域烟雾存在漏检情况.针对以上问题.本文提出了一种改进YOLOv3[16]算法的火焰和烟雾检测,通过网络爬虫、视频截取等手段获得场景复杂,数量较多的火焰和烟雾的数据集,人工标注区域的位置信息和类别信息.针对YOLOv3 算法对小目标区域检测精度低的问题做出改进,实验表明,本文的改进相比原来的YOLOv3 算法准确率和误检率有了较大幅度的提升,能够在火灾初始阶段及时发现并报警.
1 YOLOv3 原理概述
为避免模型优化中网络加深出现退化的问题[17],YOLOv3的作者借鉴了残差块(Residual block)的思想形成了Darknet-53 网络结构[18].如图1所示,网络由3 部分组成,特征提取网络Darknet-53 和多尺度预测FPN 及检测网络YOLO Head.其中,Darknet-53 没有使用池化层,而是借鉴残差网络(residual network,ResNet)的结构形成跳跃连接对输入的图片特征提取,YOLOv3 算法的卷积块大多采用卷积层(convolution layers)后跟批标准化层(batch normalization,BN)和激活函数(leaky ReLU)的模式来加速收敛避免梯度消失.输入图像经过一个普通卷积模块(Conv2D+BN+Leaky_relu)后,使用步长为2 大小为3×3 卷积进行5次下采样,如图1 中(a)部分所示,保留每次卷积后的layer,且分别在每一次下采样后使用1×1 和3×3 大小的卷积核再次进行卷积操作.将此次连续卷积后的结果和保留的layer 相加.5 次下采样后图片的高和宽不断压缩变成13×13,通道数不断扩张变成1024×1024,这5 次下采样使用残差块的结构堆叠起来,残差块结构如图1 中的(b)所示,每个残差块的拼接次数依次是1、2、8、8、4.
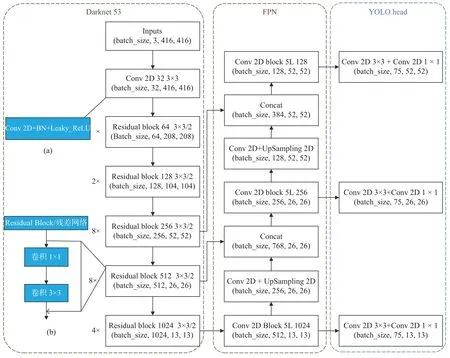
图1 YOLOv3 网络结构
为了检测出不同尺寸的物体,YOLOv3 借鉴SSD的特征金字塔(feature pyramid network,FPN)结构进行多尺度检测,选取后面3 个32 倍、16 倍、8 倍(13×13、26×26、52×52)的特征层预测物体,为了更好的利用深层语义特征信息,将最后一个特征尺度(13×13)用线性插值的方式上采样与前面一个特征层进行拼接,这样可以在较低层特征上获得深层特征的信息检测尺寸较小的物体,保证检测的效果.依次如此,直到和52×52大小的特征层拼接.
尽管YOLOv3 是一个经典、高效的网络,在目标检测领域有良好的表现力,但火灾检测的公开数据集较少,且相对形状固定的目标来说火焰和烟雾具有运动性、复杂性,特别是针对小火焰区域和复杂背景下的火焰和烟雾,YOLOv3 容易发生漏检的情况,失去了火灾预警的意义.本文针对这一问题对YOLOv3 算法进行改进,并将改进后的算法与YOLOv3 原算法进行比较,通过对比验证了本文算法在火灾检测方面的可行性.
2 YOLOv3 改进相关工作
2.1 主干网络Darknet-53 的改进
YOLOv3 网络通过基本的卷积组件和一系列残差块对火焰和烟雾的图片特征提取,使用8 倍、16 倍、32 倍后输出的3 种特征图进行多尺度预测,13×13 的尺度提取深层语义信息,用来预测尺寸较大的物体,26×26 尺度的特征图预测尺寸相当的物体,同理,52×52 的特征尺度因网格划分较细提取浅层位置信息,用来对较小尺度目标预测.但经8 倍下采样得到的特征图和原始416×416 的输入图像来说依然不够精细,当对更小尺度目标检测时会出现效果不佳的问题.除非13×13 尺度的特征图能够给它提供更多的深层特征信息以供它检测小目标.但YOLOv3 网络对输入图像经过5 次下采样后并没有其它操作.
本文决定改进YOLOv3 网络的Darknet-53 结构,在其后添加一个SPP(spatial pyramid pooling)模块来加大网络的特征接受范围,以充分利用上下文特征信息,增大感受野(receptive field),提升对小尺度目标的检测效果.SPP 由He 等[19]提出,解决了卷积神经网络(CNNs)输入图像尺寸限制的问题.对图像进行一次特征映射来避免特征重复提取,加快目标检测速度.如图2所示.对13×13 尺度特征图继续处理,首先对此特征图做3 次卷积(Conv2D+BN+Leaky_relu),分别是512×1×1、1024×3×3、512×1×1.然后将得到的结果用1×1、5×5、9×9、13×13 四个不同尺寸的池化核进行最大池化操作(max-pooling),且并联一个输入到输出的直连操作.最后将得到的特征图堆叠(concat),将不同尺度下提取的特征汇聚在一起.最大池化核的尺寸和特征图尺寸一样,保证融合了图片的局部特征信息和全局特征信息.
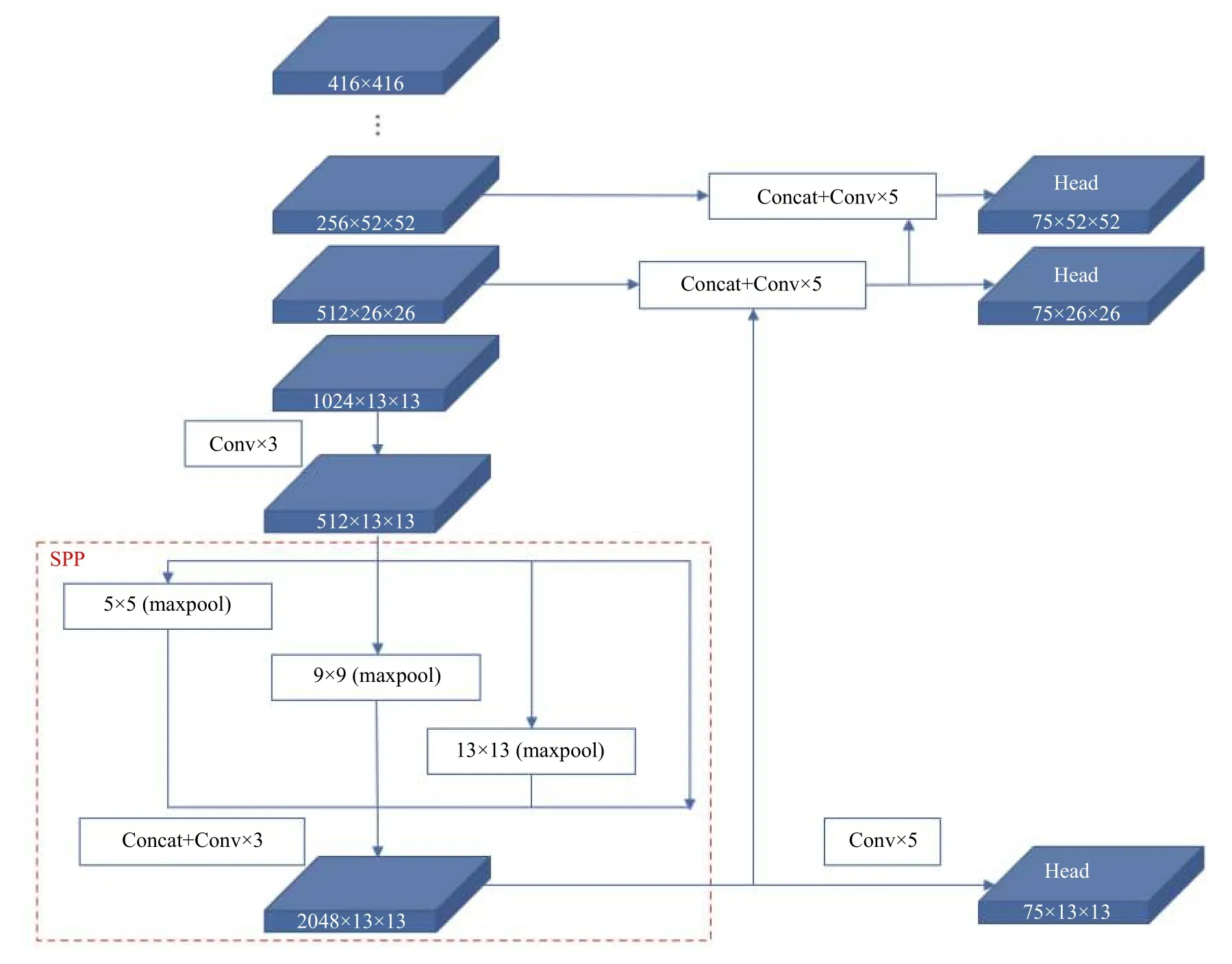
图2 加了SPP 模块的网络结构
2.2 先验框的改进
相比基于区域的两阶段(two stage)目标检测算法,YOLOv3 网络将输入图像直接送入一个深度卷积神经网络,一次性的进行目标的类别和位置的判断.将原始图片划分为大小一样、互不重复的小网格,通过Darknet-53 网络得到3 个不同尺度的特征图.每个特征点代表原始图片的一小块元素,当真实目标物体的中心落在这个网格内时,则由这个网格负责检测该物体,如图3所示.

图3 网格预测示意图
YOLOv3 网络沿用YOLOv2 采用anchor boxes 机制,给每个特征点预设一组面积不同,宽高比大小不同的初始先验框,这些先验框是通过K-means 聚类算法得到的框.对于目标检测算法来说,一组合适的先验框将减少网络的调整使之更快的获得预测框.为了实现快速、准确的火焰和烟雾检测,需要对YOLOv3 本身的先验框优化使之适合自己的数据集.本文决定通过改进的K-means 聚类算法对标注火焰和烟雾的真实框(true box)分析,使先验框的尺寸更符合本文火焰和烟雾数据集的尺寸.聚类的个数K即为要选取的先验框的个数,聚类中心框的宽和高即为先验框的宽和高.
传统的K-means 聚类算法采用欧式距离计算,但当聚类不是用于点的聚类而是用于边框的聚类时会产生误差.边框的尺寸越大产生的误差也会越大,因此本文决定用改进的交并比(intersection over union,IoU)[20]来进行K-means 聚类.聚类开始时随机选取k个真实框(bounding box)作为初始锚框(anchor box),计算每个bounding box 与每个anchor box 的IoU,IoU 越大时误差越小.依次将每个bounding box 分配给误差最小的那个anchor box.最后,将每个anchor box 中所有的bounding box 求宽高中值大小作为新的anchor box.重复迭代更新,直至所有的真实框所属的anchor box 和上一次分配的一样,停止更新.保存最后得到的anchor box 作为聚类后的先验框.计算样本中bounding box与k个anchor box 的平均IoU(AvgIoU),得到的结果如图4所示.当 值越来越大时,AvgIoU 的值先快速增加后平缓增加.考虑到检测模型的计算精度和速度,选取聚类个数k=9.
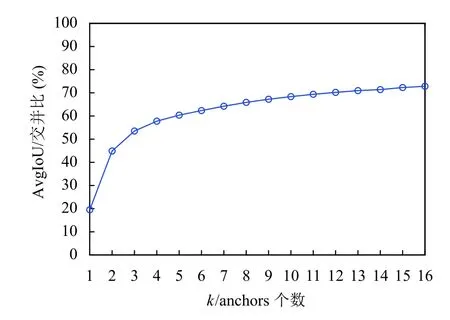
图4 先验框个数k 与AvgIoU 关系图
聚类后的聚类中心坐标和先验框尺寸如表1所示,其中坐标是相对于图像大小的比例,将其与输入尺寸相乘得到先验框尺寸.
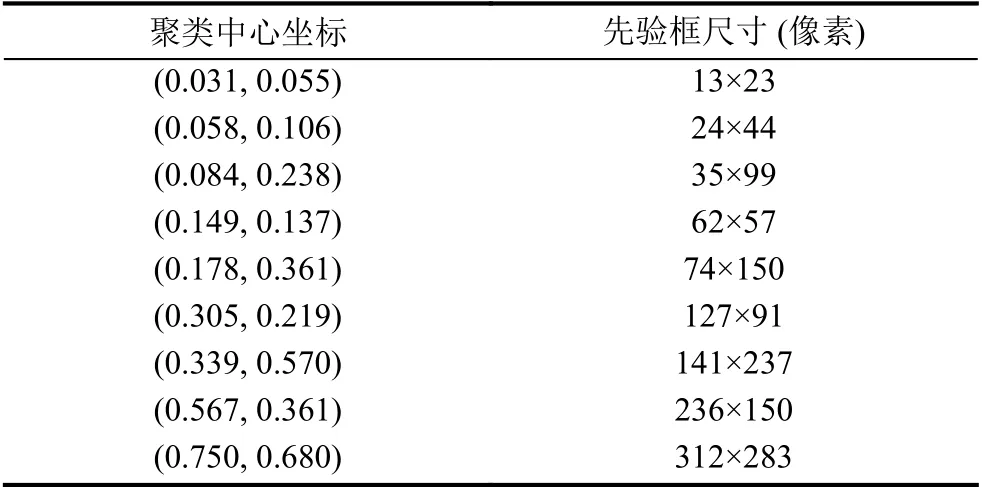
表1 改进K-means 聚类得到中心坐标和先验框尺寸
沿用YOLOv3的做法,将9 种宽高比不同的先验框平均分配到3 种不同尺度的特征图上,经32 倍下采样后的13×13 特征图感受野最大,用来检测尺寸最大的火焰和烟雾,将141×237,236×150,312×283 分配给它;26×26 特征图感受野一般,将62×57,74×150,127×91 分配给它;然后将剩余的13×23,24×44,35×99 分配给感受野最小的52×52 特征图,用来检测小火焰烟雾目标.
2.3 损失函数的改进
损失函数衡量的是真实值和预测值的误差.神经网络反向传播的训练是通过计算损失函数对梯度的偏导来更新权重和参数,因此损失函数的定义直接影响到模型训练的好坏.YOLOv3 算法的损失函数[21]由3 部分组成:坐标损失(coord loss)、类别损失(class loss)和置信度损失(confidence loss),损失函数表达式如下:

其中,网格中存在物体 为1,否则是0,r为物体的种类,如火焰或烟雾,其中x,y为物体的中心坐标,w,h为物体的宽高.
YOLOv3 在计算坐标误差时将中心和宽高坐标作为单独的变量去计算,忽视了两者的相关性.考虑用真实框和预测框的重合程度 去计算坐标损失,但当两个框之间没有重合或尺寸相差较大时无法计算,为加快损失函数的收敛,采用CIoU(Complete-IoU)[22]作为位置坐标的损失函数.计算公式如下:
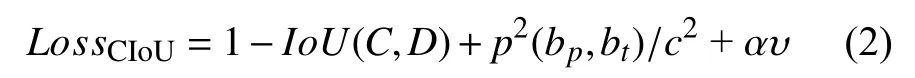
3 实验结果及分析
3.1 实验环境
本文所用的深度学习框架为PyTorch 1.2.0 版本,实验基于Anaconda 虚拟环境,编辑器为VScode,编程语言为Python 3.5.2,操作系统是Windows 10,GPU 为GTX1080Ti,CPU 是Inter i7-6700,电脑内存为128 GB,GPU 加速库cuDNN 的版本是7.4.1.5,配套的CUDA的版本是10.0.实验程序将原始输入图像尺寸统一调整为416×416.
3.2 实验数据集
目前基于深度学习的火灾检测公开的数据集较少且场景单一,本文所用的实验数据集是通过网络爬虫和数据截取方式获得的,选取了10 825 张不同场景下的火焰和烟雾图像,其中有山地、田野、森林、室内等场景,也有白天和夜晚情景下的图像,有3 123 张火焰图像,有2 987 张烟雾图像,4 715 张火焰和烟雾混合图像.本文将数据集按照8:1:1 比例分别用作训练、验证和测试.数据集的部分展示如图5所示.

图5 火灾数据集部分图像
本文使用LabelImg 软件来对数据集进行标注,标注的种类为火焰fire 和烟雾smoke 两类.注意标注时要完全框柱目标物体,不能缺少或超过以影响火灾检测的准确率.将图像中标注物体的种类信息和位置信息保存至XML 格式文件中,然后通过程序将这些信息转换为VOC 格式进行训练.
为了提升模型的鲁棒性,本文对训练的数据集使用Mosaic 在线数据增强[23].此方法将4 张图片进行拼接,它的一个巨大优点是丰富待检测物体的背景,且批量标准化计算的时一次性计算出4 张图片的数据.过程如图6所示.

图6 Mosaic 数据增强示例
3.3 模型训练
实验采用小批量梯度下降方法优化模型,批尺寸(batch size)设置为20,动量因子(momentum)设置为0.9,使用Mosaic 进行在线数据增强.整个训练过程有100 轮(epoch),前50 次epoch 是初始学习率为0.001的冻结训练,后50 次epoch 在冻结训练的基础上进行初始学习率为0.000 1 的训练.模型所有的迭代次数为39 000 次.每次迭代训练结束后将得到的训练权重以及整体loss 和验证集loss 值保存在日志中,模型训练初期根据loss 值收敛程度调整参数,最终将网络参数调整至合适大小,并将loss 值收敛效果最好的一次的权重作为最终权重进行预测.损失函数随着迭代次数的变化如图7所示,为了更加准确的观察loss 的变化趋势,将第300 次到第20 000 次的迭代放大并置于图中,可以看到模型的收敛速度和收敛效果均较好,可以看出,在第15 000 次迭代后,模型的loss 值趋于稳定.
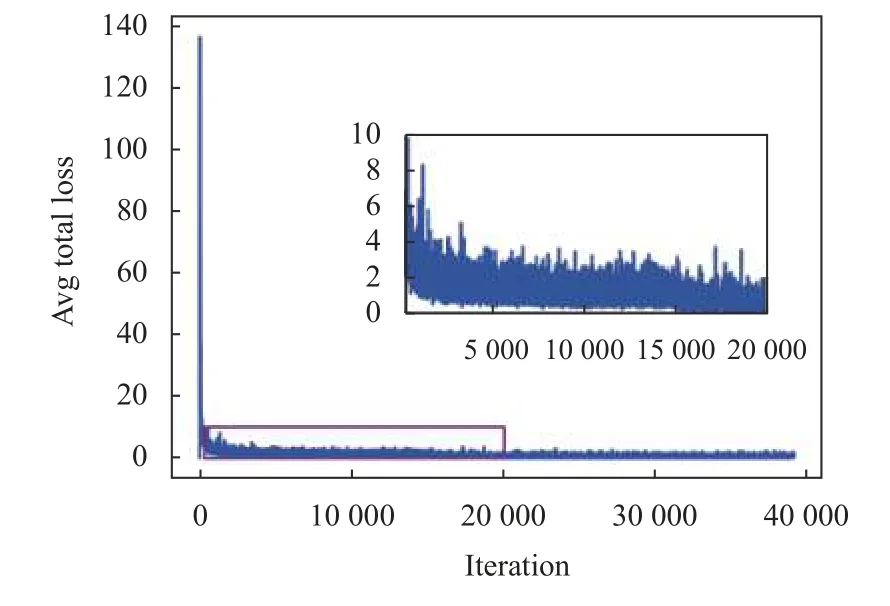
图7 训练模型损失函数曲线图
每次迭代预测框与真实框的平均IoU 如图8所示,可以看到,随着迭代次数的增加,IoU 值上升并趋于稳定.
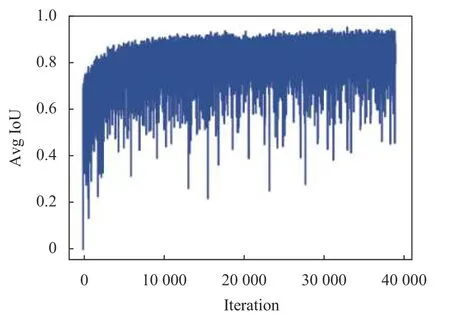
图8 训练模型IoU 曲线图
3.4 评估指标
本文使用mAP 作为模型的评价指标,下面是计算过程.TP是被模型分到正样本且分对了的个数,TN是被模型分到负样本且分对了的个数,FP是被模型分到正样本且分错了的个数,FN是被模型分到负样本且分错了的个数.那么模型的准确率(precision,P)计算公式为:

模型的召回率(recall,R)计算公式为:

当取不同的置信度时可以得到不同的P和R,由此,得到平均准确率AP的计算公式为:
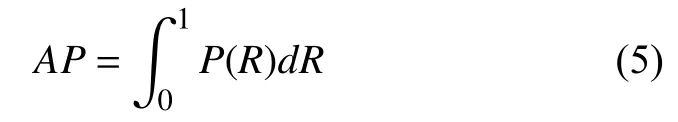
检测目标火焰和烟雾对应的P-R(Precision-Recall)曲线如图9所示.其中火焰的AP为97.71%,烟雾的AP为94.32%,当分类个数超过一个时,便引入了mAP,mAP的计算公式为:
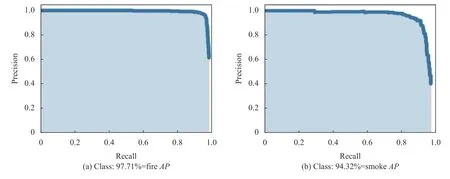
图9 火焰和烟雾P-R 曲线图
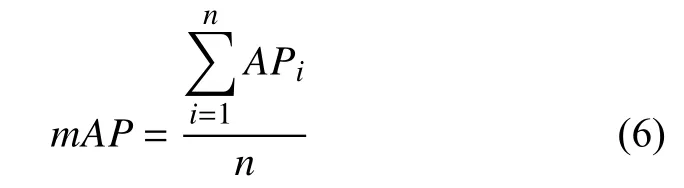
其中,n为分类的种类数,本文中有火焰和烟雾,因此n= 2,则本文改进后模型的mAP为96.02%.
3.5 模型对比分析
3.5.1 训练loss 图对比
两个模型的损失函数如图10所示,可以看到,由于迁移学习YOLOv3 初始权重,模型一开始的整体损失较少,随着迭代次数的增多,改进后模型loss 的收敛速度和最终收敛效果均比YOLOv3 模型要好.
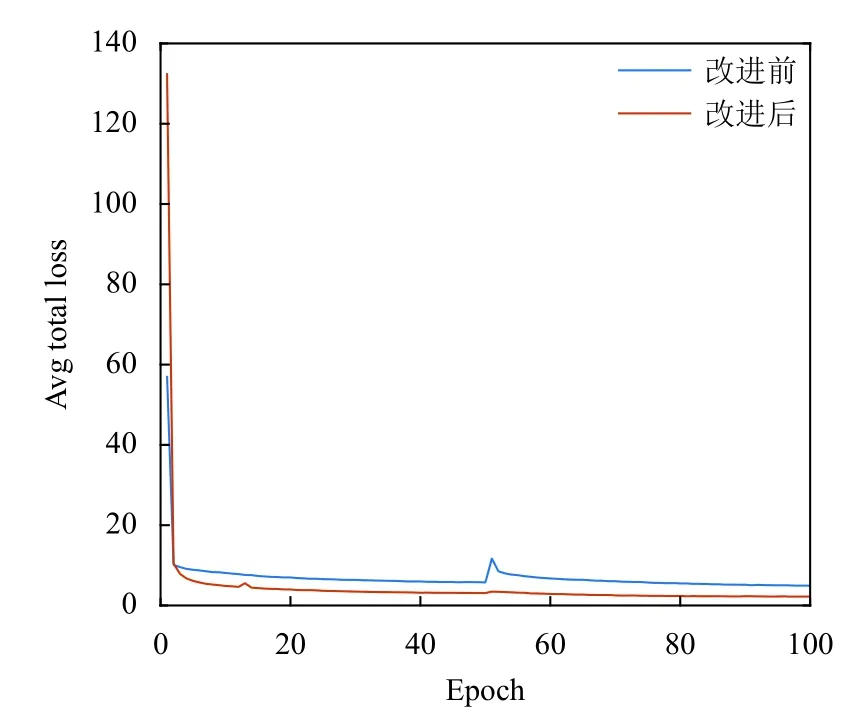
图10 模型训练Loss 收敛对比图
3.5.2mAP对比
两个模型的准确率(precision)、召回率(recall)、精度(AP)、平均精度(mAP)对比如表2所示.
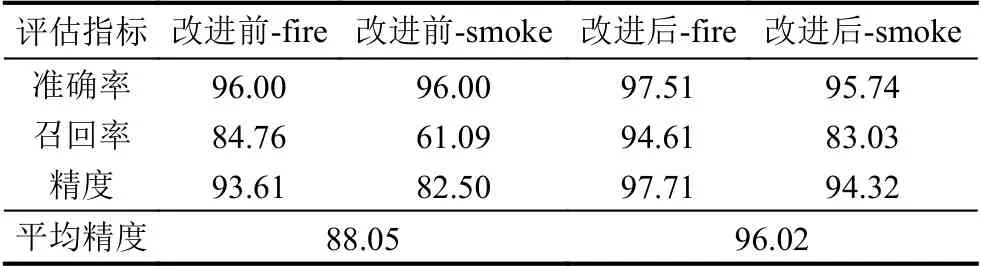
表2 模型训练结果参数对比(%)
YOLOv3的mAP为88.05%,改进后模型的mAP为96.02%.可见改进后模型的AP和mAP表现均较好.
3.5.3 测试集检测结果对比
为了测试两个模型对复杂背景的检测效果以及小目标的检测效果,选取了测试集中几种有代表性的图像进行对比,检测结果如图11所示.
从图11 的检测结果可以看到,改进后的模型在小目标检测方面比YOLOv3 有更大的优势,对于图11(a)中未检测出来的小火焰区域,改进后的模型均能极好的检测出来,且对复杂背景下的烟雾来说因其运动不规律易受背景影响,从图11(c)、图11(e)、图11(g)可以看出,YOLOv3 存在多次漏检现象,但改进后的模型能很好的检测出复杂背景下的大小烟雾区域.因此,本文的改进是效果显著的,对小目标的查全率及复杂背景下目标的检测精度均比YOLOv3 要好.

图11 实际检测效果对比图
3.5.4 公开数据集检测结果对比
为了检验改进后算法的鲁棒性,本文在公开的火灾数据集上与其它算法进行对比检测.公开数据集来自于Research Webpage about Smoke Detection for Fire Alarm(http://signal.ee.bilkent.edu.tr/VisiFire/Demo/SampleClips.html),本文对其中的视频进行截图后得到不同状态下的火焰和烟雾图片,部分图片如图12所示.

图12 公开数据集部分图片
分别使用算法Faster RCNN、SDD、文献[24]、YOLOv3 及本文算法对公开数据集进行检测,并计算检测结果,算法的检测结果对比见表3.
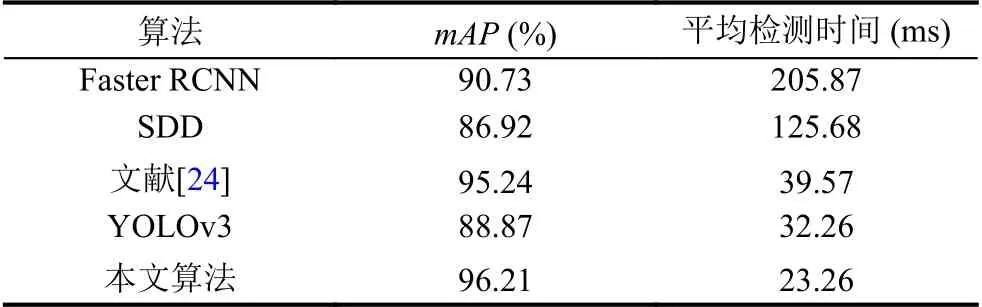
表3 公开数据集检测结果对比
通过对比可知,本文算法在精度和速度方面均表现更好,可以更好的应用于火灾检测.其中,Faster RCNN 的mAP 比YOLOv3 好,但由于其在候选区处理时需要很大时间,所以检测时间较长.而火灾检测对实时性的要求比对精度的要求优先级更高,因此,改进后的本文算法更适用于火灾检测.
3.5.5 消融实验对比
本文的算法改进有:在主干特征提取网络中加入SPP模块、使用CIoU 计算新的损失函数、使用Mosaic 进行数据增强.为深入了解这些改进对于算法性能提升的程度,将本文算法拆分为4 组实验,实验结果如表4所示.
从表4 可以看出,在只加入SPP 模块的模型2 中,由于提升了网络的感受野,融合了图片的局部特征信息和全局特征信息,使得mAP提升了2.84 个百分点.在加入了SPP 模块和CIoU 改进损失函数的模型3 中,由于计算坐标误差时考虑了中心和宽高坐标两者的相关性,加快了损失函数的收敛,使得mAP提升了3.67个百分点.在模型4 中,增加了Mosaic 数据增强,丰富待检测物体的背景,使得mAP提升了1.46 个百分点.因此,本文的改进方法均可以提升火灾检测效果,其中,引入CIoU 改进损失函数的改进效果最显著.
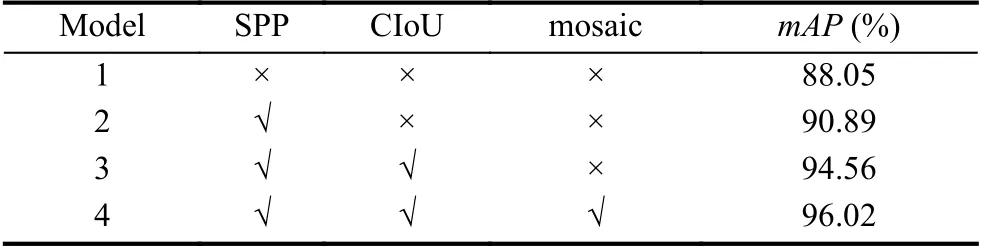
表4 消融实验对比结果
4 总结与展望
针对深度学习方法在火灾检测应用上的不足,本文提出了改进YOLOv3的视频图像火灾检测算法,通过特征提取网络的改进、先验框的优化、损失函数的改进和数据增强等一系列措施提升了火灾检测的精度和速度.
在自行标注的Fire-Smoke-Detection-Dataset 上进行了实验.实验结果显示,本文改进的模型在火灾检测方面有更好的鲁棒性、更高的准确率,尤其是在复杂背景下的检测和对小目标的检测效果更优异.其中,对火焰的检测率从94%提升至98%,对烟雾的检测率从82%提升至94%,mAP从88.05%提升至96.02%,平均检测速度从31 fps 加快到43 fps.之后的工作里,将继续对网络进行优化改进,进一步改善检测效果和算法优化效果,增加对烟雾这一复杂对象的详细分析.
猜你喜欢
中国音乐学(2022年1期)2022-05-05
汽车实用技术(2022年4期)2022-03-07
客联(2021年9期)2021-11-07
小学阅读指南·低年级版(2021年3期)2021-03-19
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
学苑创造·C版(2018年7期)2018-08-08
成都理工大学学报·社会科学版(2017年4期)2017-09-08
电子技术与软件工程(2016年23期)2017-03-06
岁月(2016年5期)2016-08-13
科学启蒙(2014年12期)2014-12-09
