
配电网电力设备缺陷文本智能辨识运维综述
2022-05-09 03:01:40张磐郑悦李海龙刘航旭李国栋葛磊蛟
电力建设 2022年5期
张磐, 郑悦,李海龙,刘航旭,李国栋,葛磊蛟
(1.国网天津市电力公司电力科学研究院, 天津市 300384;2.国网天津市电力公司,天津市 300010;3.国网天津市电力公司滨海供电分公司,天津市 300450;4.天津大学电气自动化与信息工程学院,天津市 300072)
0 引 言
智能配电网电力设备具有种类繁杂、数量多、运维难等特点[1],随着电力系统的不断发展以及智能电网建设的深化推进,电网企业数据库中存储的电力数据随着智能电网的运维呈现爆发式增长[2]。这些数据通常以非机构化数据如图像、文本等形式存储[3],蕴含大量关于电网设备运行状态的信息[4]。通过对电力设备缺陷文本的深度挖掘,能够实现电网运行状态的实时监测、故障定位及设备维修,为电网的可靠运行提供指导[5]。
近年来,电力数据挖掘虽然已成为研究热点,但真正得到挖掘并利用的数据却很少[6],如何深度挖掘电力设备缺陷文本内部信息,是电力设备精细化管理未来发展面临的主要问题。我国在电力设备缺陷文本挖掘方面的成果较少,面临巨大挑战。首先,电力设备相关信息以文本形式表示,往往含义模糊、计算机难以辨别;其次,电力领域具有专业性,无法直接应用其他领域的文本挖掘方法;最后,随着智能电网的高速发展,电力设备相关文本会变得更加复杂,当前电力设备缺陷文本挖掘技术将不再适用。
本文基于现有研究成果,对该领域的发展方向以及主要方法进行分析,并指出面临的关键难题。首先,面向电力设备缺陷文本挖掘从4个方面进行剖析:1) 电力设备缺陷文本错误识别与质量提升;2) 电力设备缺陷严重等级自动分类;3) 电力设备缺陷细节提取;4) 电力设备健康状态自动评价。其次,结合相关文献中的算例结果,对不同方法实现的效果进行分析。最后,分析电力设备缺陷文本挖掘技术未来发展方向,以期为该领域的进一步研究提供参考与借鉴。
1 电力设备缺陷文本深度挖掘技术
电力设备缺陷文本深度挖掘技术包含缺陷文本错误识别与质量提升、缺陷严重等级自动分类、缺陷细节提取和健康状态自动评价4个方面,如图1所示。

图1 电力设备缺陷文本深度挖掘技术示意图Fig.1 Schematic diagram of text deep mining technology for power equipment defects
首先对缺陷文本进行错误识别与质量提升,剔除文本记录错误、混杂等数据,得到高质量的缺陷文本数据;进而对设备缺陷严重等级进行自动分类,并提取缺陷细节,进行电力设备的全面态势获取;最后进行健康状态自动评价,实现电力设备未来态势的预测。
2 缺陷文本错误识别与质量提升
随着电力设备的日常运维,电力设备缺陷文本在电力设备文本系统中大量累积[7],但由于电力设备数量庞大,缺陷种类复杂,现有的规范[8]无法实现全面总结;此外,由于缺陷文本的人为记录特征,时常会出现由于记录人员经验不足导致的文本残缺甚至错误等现象[9],造成了缺陷文本挖掘的复杂性。因此,错误识别与质量提升是电力设备缺陷文本挖掘的关键技术之一。首先对电力设备缺陷文本进行错误识别,找到因录入不规范、语病等原因导致的文本错误,进而针对识别结果对其进行矫正,实现质量提升。
2.1 缺陷文本错误识别
通过对电力设备缺陷文本的挖掘,识别电力设备缺陷文本的错误,从而更加完整地记录电力设备相关缺陷,为电力设备缺陷文本的质量提升奠定基础。我国对于文本错误识别的研究开始于20世纪90年代,起步较晚,对于电力设备缺陷文本领域的错误识别相关研究较少。文献[10]面向卷宗文本错误识别构建了查错模块,对录入的文本进行搜索,找出语病、错别字等文本错误并记录位置。文中为了充分考虑语料库不能完全涵盖自然语言的局限性,将语料库中的词与识别文本进行比对,找出未登录的疑似语病的词字。进而将疑似错误与上下文的词串结合,利用Kenlm模块计算置信度值判断正误。然而针对电力设备缺陷记录领域,文献[10]所提方法并不适用。
现有针对电力设备缺陷文本的研究主要聚焦于电网公司中质量欠佳的历史缺陷文本,主要结合电力设备缺陷文本分类规范,研究电网中各设备的缺陷矫正方法,以改善设备缺陷。对于新录入信息管理系统中的缺陷文本,采用文本质量评价方法对其存在的问题进行分析,通过缺陷文本质量评价方法,对修正前后的缺陷文本记录数据进行打分,根据评分结果得到缺陷文本错误识别结果。
为对大规模文本信息进行深度分析,可借助知识图谱(knowledge graph,KG)显示知识之间相关联系的能力[11],构建电力设备缺陷文本知识图谱实现检索、查错等功能。知识图谱是一种新型的图型数据库,它通过“结点-关系-结点”的基本三元结构表示知识之间的关系[12]。知识图谱技术的发展有赖于人工智能的普及,它可以通过可视化的方式显示人工智能的决策过程。在知识图谱的分类中,纵向知识图谱指的是某一特定领域的知识图谱。电力知识图谱作为一种典型的纵向知识图谱,已在电力工业的数据分析与决策环节得到了应用。使用结构化数据形式的电力设备缺陷文本构造知识图谱,便可实现辅助录入系统所需要的数据检索与可视化功能[13]。针对电力设备缺陷文本错误识别,文献[14]采用基于知识图谱的缺陷文本错误识别方法,提出了一种基于图搜索的缺陷记录检索过程,通过深度优先搜索算法实现对知识图谱中完整树的搜索,从而构成完整的缺陷记录,大大简化了工作人员分析文本的过程。该文献最后以电网公司变压器缺陷文本为例,将所提方法与基于机器学习的模型进行对比,结合相关评价标准例如精确率、召回率等,证明了所提方法在提升缺陷文本错误识别效果方面的有效性和优越性。
上述图搜索算法对于错误识别具有良好的效果,但是容易因为临近搜索而陷入死循环。树搜索算法在搜索问题复杂度不高的情况下可以在不明显牺牲搜索灵活度的前提下解决陷入死循环的问题。因此树搜索算法也可以用于解决缺陷文本错误识别的难题。文献[15]为提高缺陷分类等级的准确度,对缺陷文本中的错误识别进行了研究。首先输入历史记录的设备缺陷文本,并根据国家电网有限公司给出的缺陷分类标准构建了树路径匹配框架。进而按照树路径匹配算法找到对应的最相似路径,从而识别到文本错误并给出错误程度。这种基于树搜索的识别模式与图搜索类似,但是区别在于前者允许经过重复的节点而后者不允许。
由于关系提取的准确性将直接影响知识图谱[14]和树结构的准确性和完整性,且现有的知识图谱与树结构的表示主要是依赖电网公司的分类标准,随着设备的多样化以及运行场景的复杂化,缺陷文本的错误可能会被误识别[15]。如果使用更多的语法解析等自然语言处理技术提取更多的语义特征,缺陷文本的错误识别效果可进一步提高。这也是未来缺陷文本错误识别研究的一个可能方向。
2.2 缺陷文本质量评价与提升
缺陷文本的质量会影响深度挖掘的效果,因此高质量的缺陷文本库是对其深度挖掘的基础。设备缺陷文本很大一部分由人工录入,存在录入不规范、语病等问题,对缺陷文本进行错误识别后需要对其进行质量评价和提升。
机器学习与自然语言处理技术可以实现缺陷文本质量的智能评价与提升[16]。文献[17]将文本错误的纠正问题看作输入数据的规范化翻译过程,改变了传统的文本错误识别-质量提升的二阶段策略,运用带注意力机制的序列到序列学习模型对常规中文文本进行了错误纠正。这种文本提升方法需要大量的带标签数据对深度学习模型进行训练,对于电力设备缺陷文本专业领域的适用性不足,目前对电力设备缺陷文本质量提升方面的研究较少。文献[18]提出了一种缺陷文本质量评价和提升方法,以电网中不同设备产生的25 000多条历史缺陷文本为例,通过缺陷文本质量评价方法,对修正前后的缺陷文本记录数据进行打分,根据打分评价结果,准确识别新录入文本存在的问题并给出修改建议,完成新录入缺陷文本质量的提升,从而验证了所提方法在同时实现历史缺陷文本与新录入文本质量评价与提升方面的有效性。
电力设备缺陷文本质量提升过程主要有以下几个步骤:首先,以电网公司缺陷文本为样本,分析获知电网公司缺陷文本存在的问题,如格式残缺、语义模糊、冗杂等问题;然后,针对这些问题,提出缺陷文本质量评价指标,并以此构建相关评分体系对缺陷文本进行评价;基于文本质量评价结果,聚焦于电网公司中质量欠佳的历史缺陷文本,采用潜在多元Beta分布等方法,结合电力设备缺陷文本分类规范,对文本内容予以矫正;最后,针对新录入信息管理系统中的缺陷文本,采用上述文本质量评价方法对其存在的问题进行分析,从而给出修正建议。
然而,目前的缺陷文本质量评价方法存在很强的主观性[18],随着缺陷文本数据量的增加可能出现评价与实际质量偏差过大的情况影响质量提升效果。因此,基于客观评价结果建立缺陷文本质量量化模型是未来缺陷文本质量提升的重要方向。
3 缺陷文本缺陷严重等级自动分类
在电力系统巡检过程中,往往会累积大量缺陷文本,这些缺陷文本中记录着大量关于设备缺陷严重等级的相关信息,对设备缺陷等级的分类至关重要。通过分类设备缺陷严重等级,工作人员可以更好地实现对电力系统中缺陷设备的管理。然而传统的设备缺陷严重等级分类方法往往需要人工完成,其分类效率低下;且针对模糊性较强的亚健康缺陷,往往会出现由于巡检人员经验不足而分类不精确的情况,对电力设备运行状态的评估产生不利影响。
随着人工智能及模式识别的深度开发,多种机器学习模型与电力设备缺陷严重等级分类相结合[19],既能够提高电力设备缺陷严重等级分类的效率[20],又能够避免因信息模糊造成的分类精确率降低。文献[21]针对缺陷文本分类,首先通过one-hot词袋模型对缺陷文本进行预处理,实现了向量空间的构建及缺陷严重等级的分类与量化;接着采用K最近邻算法对电力设备缺陷记录数据完成类别辨识。仿真部分以断路器缺陷文本为例,对缺陷文本进行重新分类,与初始结果进行对比可得,该方法准确率更高,验证了所提方法的可行性。
机器学习与智能识别的应用,使得分类效率大大提高。但这类分类方法往往需要依靠特征函数,从而导致特征项模糊甚至丢失[22];此外,传统机器学习分类方法的泛化能力以及数据挖掘能力有限,从而大大限制了缺陷文本的分类效果。
为解决上述问题,基于卷积神经网络(convolutional neural network,CNN)的电力设备缺陷文本挖掘算法被提出,通过卷积运算实现特征压缩降维、减小运算量[23]。文献[19]通过与多种传统机器学习分类模型对比得出:基于CNN的缺陷文本分类模型在耗费一定时间的前提下,显著降低了缺陷文本分类的错误率;此外,与以往的机器学习分类法相比,基于CNN的缺陷文本分类模型分类时间较短,提高了分类效率。但是该方法仅对文本进行了一次串行浅层特征提取,不能很好地挖掘长文本深层语义信息。针对CNN无法对长序列信息建模的问题,应用循环卷积神经网络(recurrent convolutional neural network,RCNN)是解决该问题的可行思路。RCNN是基于循环神经网络(recurrent neural network,RNN)的改进算法,克服了传统RNN长期依赖、梯度爆炸的问题[24]。文献[25]以变压器为研究对象,运用RCNN模型完成对缺陷文本的自动分类。仿真部分基于变压器运维文本,将RCNN方法分别与传统文本分类模型、RNN以及CNN方法进行对比。与传统中文文本分类方法相比,RCNN同时实现了特征提取与分类评估,可直接面向底层进行语义分析,分类性能提升了3.49%~21.0%;相比于CNN、RNN,RCNN 模型网络框架更加优秀,可更好地融合上下文信息并最大可能保留关键语义。
文献[26]采用基于双向长短期记忆网络(bi-long short term memory, BiLSTM)的分类模型实现对缺陷文本缺陷严重等级高效自动分类。选取经过人工分类的某电网公司2010—2015年的529个故障文本中的900条句子作为输入数据,输出为设备故障严重等级。仿真部分通过分类准确率、召回率以及F1值3个指标对BiLSTM方法与LSTM及CNN方法进行比较,验证了BiLSTM方法的优越性。文献[27]在BiLSTM的基础上引入了注意力机制,提出了基于注意力机制的双向长短期记忆神经网络(BiLSTM based on attention mechanism, BiLSTM-Attention)缺陷文本分类方法。相比于传统文本分类模型、BiLSTM模型以及CNN模型,BiLSTM-Attention模型在电力设备缺陷文本分类中具有更好的分类性能,提高了对含有混淆信息长文本的特征提取能力和分类能力。关于电力设备缺陷文本缺陷严重等级自动分类的方法如图2和表1所示。
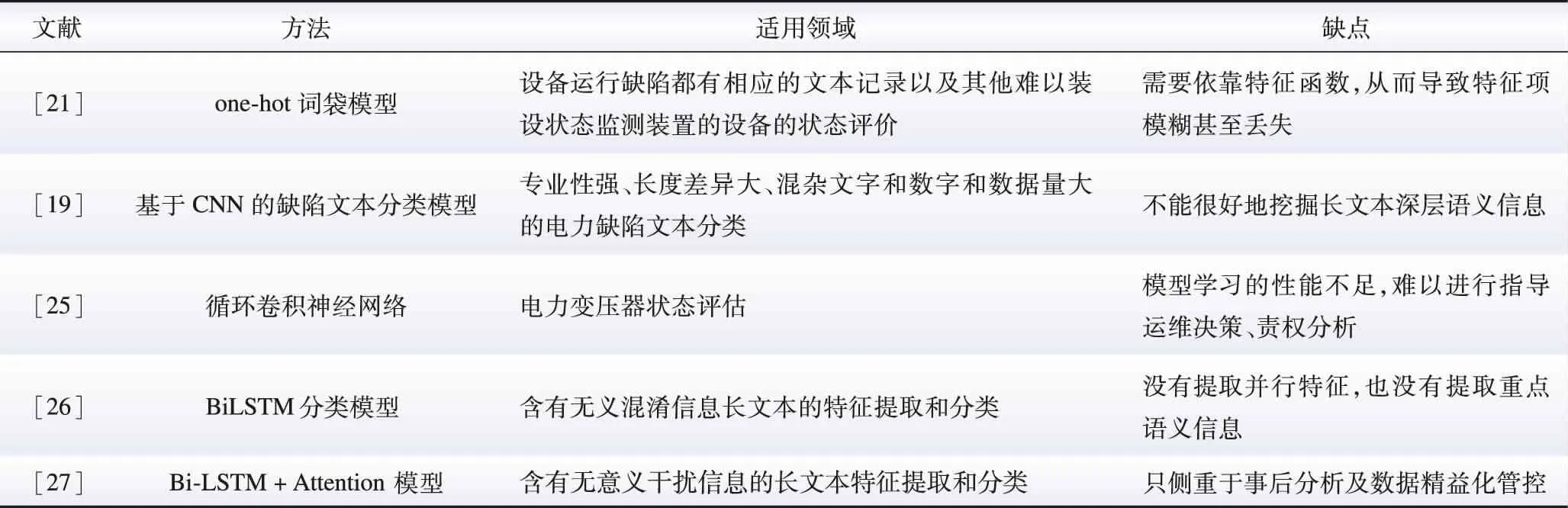
表1 现有缺陷文本缺陷严重等级自动分类方法特点对比Table 1 Comparison of characteristics of existing automatic classification methods for defect severity level of defect text
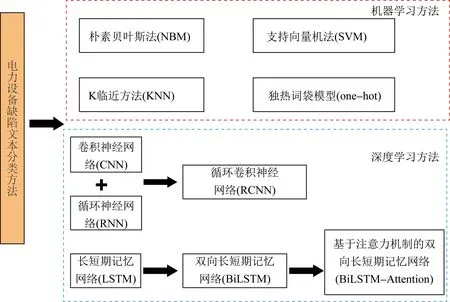
图2 缺陷文本缺陷严重等级自动分类方法Fig.2 Automatic classification method for defect severity level in defect text
4 缺陷文本缺陷细节提取
电力公司在电力设备的日常运营巡检中,通常以非结构化数据形式将电力设备的异常和维护等信息录入管理系统,数据形式以文本形式为主。这些信息中存在着大量的设备相关运行状态信息,同时还表征了其他同类设备的运行可靠性信息[28]。然而通过对大量缺陷文本信息的研究能够发现,同一设备多个零件的缺陷情况经常存在于一条缺陷文本信息中,过度且复杂的描述导致信息记录错乱无序。通过对缺陷记录中缺陷细节的提取,可以实现缺陷情况的精确统计、高效分析与有效评价。因此,缺陷文本中缺陷细节的提取是确保电力系统安全运行的关键环节[29]。自然语言处理(nature language processing, NLP)技术是一门融合语言学、计算机科学、数学于一体的科学,可以实现人与计算机之间用自然语言进行有效通信,在一定程度实现人机交互。为此,基于NLP领域中的多种方法被广泛应用到中文电力设备缺陷文本细节提取中。目前电力设备缺陷文本细节提取按自然语言不同主要可分为英文电力设备缺陷文本细节提取和中文电力设备缺陷文本细节提取2个方向。
文献[30]以纽约市电力系统相关信息作为参考,提出了一种基于机器学习的海量缺陷历史数据挖掘方法,电力公司通过该模型可以确定维护和维修工作的优先级,例如:1)对馈线故障维修的优先等级;2)对电缆、接头、终端以及变压器等故障维修的优先等级。该方法为电网公司提供了电力设备故障预测以及预防性维修的依据,从而实现对电网更好的维护。国外的缺陷文本细节提取研究主要聚焦于英文文本,然而与之相比,中文文本在构词、词性等方面存在着较大差异,因此英文文本挖掘的相关算法研究在中文文本中是不适用的。文献[31]提出一种基于语义框架的电力设备缺陷文本缺陷细节提取方法,为电力设备缺陷的进一步记录、管理奠定了基础。首先,建立本体字典库;接着通过对电力设备缺陷记录数据的总结分析,结合其固有特点实现了电力语义框架与语义槽的建立;采用槽填充并构建语义框架,构建流程如图3所示。通过对大量变压器缺陷文本的处理,验证了该方法能够精确提取电力设备缺陷文本中的缺陷信息,因此也能够应用于电力设备缺陷统计与分类中。文献[32]结合依存句法分析技术对电力设备缺陷文本信息的精确辨识方法进行了改进。首先,基于依存句法分析技术,构建了电力设备缺陷文本与电力设备标准文本的依存句法树,依存句法树生成流程如图4所示。接着运用依存句法的树匹配算法实现了电力设备缺陷细节数据的准确分析与分类。最后以主变压器为研究对象,通过分析其历史缺陷文本记录,证明了该方法的优越性和实用性,相比于其他方法,该方法的计算速度与精确度更具有优越性。
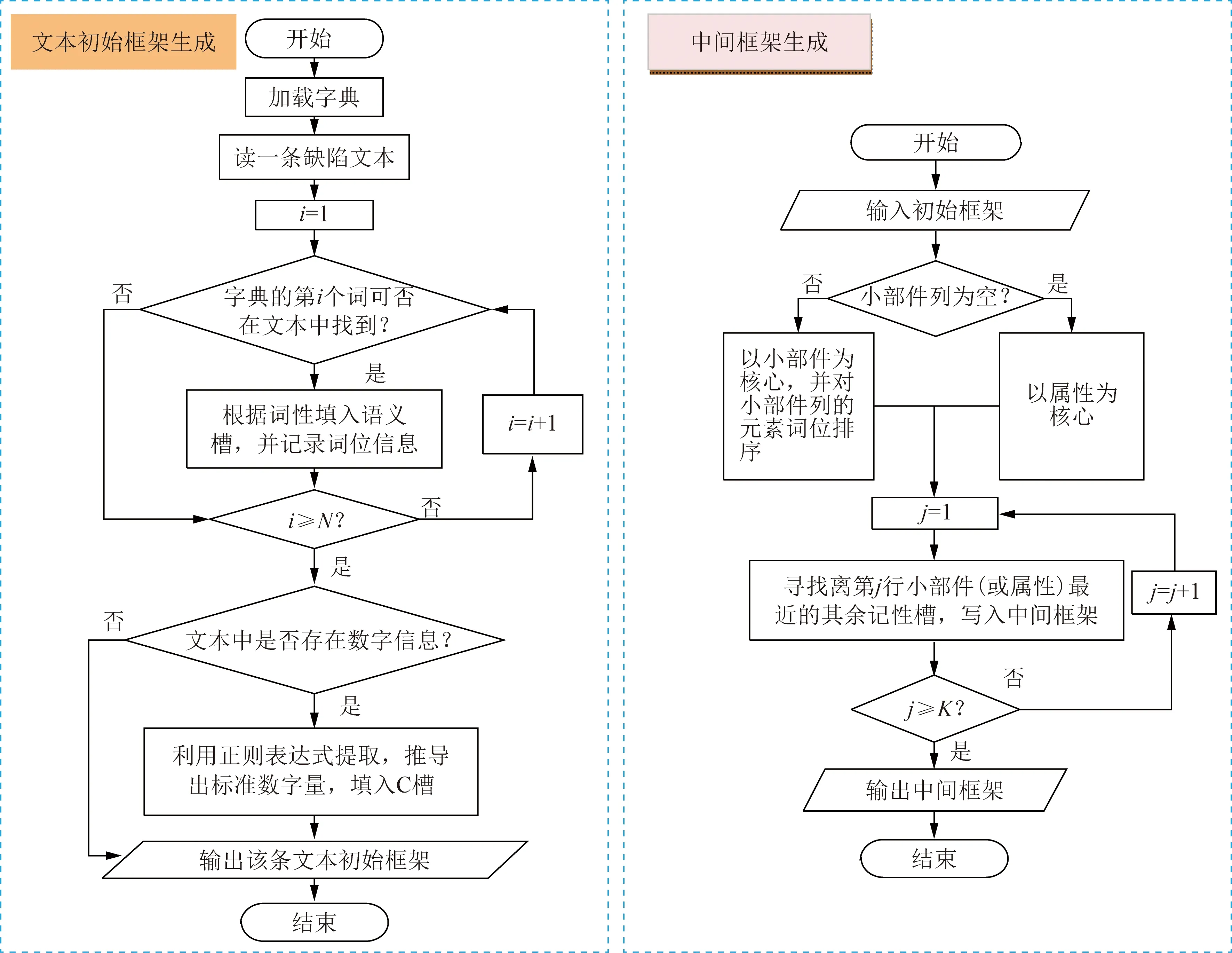
图3 构建语义框架流程Fig.3 Semantic for framework construction

图4 电力设备文本依存句法树生成流程Fig.4 Flowchart of constructing dependency syntax tree based on equipment defect text
5 缺陷文本健康状态自动评价
在电力设备日常运行巡检中,产生的缺陷文本除了包含电力设备当前的缺陷情况外,还蕴藏着丰富的电力设备健康状态历史记录,通过对健康状态的历史记录进行分析,能够更好地评价设备运行状态,从而实现对电力设备未来态势的预测。
当前健康状态主要评价方法如下所述:1) 基于评价导则与专家系统的方法,这种方法成本高、耗时长,当面对大量设备健康状态评价时,难以满足需求[33];2) 基于人工智能技术构建神经网络等模型的方法,这种方法是目前的主流方法,能够实现大量设备健康状态的评价[34-37]。
文献[34]提出了一种比率型断路器全寿命周期运行状况评价模型。首先,根据断路器缺陷等级,结合文本挖掘技术和相关评价规范[35]得到缺陷等级评价结果,将评价结果量化为健康状态指数;接着运用比率型状态信息融合模型得到单位健康周期健康状态指数,将其与之前得到的健康状态指数结合,得到了全寿命周期数据流,从而得到断路器全寿命周期运行状况评价模型。文献[36]表明,结合全寿命状态评价模型,可从电力设备缺陷文本中的语句结构和语义对电力设备缺陷文本进行深层次挖掘,通过对比缺陷文本与电力设备缺陷评价规范,给出当时情景下的电力设备健康评价结果,从而极大改善了电力设备健康状态评估的客观性与准确性。文献[37]以电力系统故障的告警信号为研究对象,提出了一种电力调度故障自动判断模型。首先,结合隐马尔可夫模型及向量空间模型对调度故障信息进行预处理;接着基于对故障信息文本的辨识结果,实现对故障情况的精确诊断,并通过k-means聚类法获取高概率故障为运维人员提供运维检修依据。
现有的基于缺陷词库的电力设备健康状态评估方法[30],普遍存在以下缺陷:由于样本较少,经过模型训练所得到的结果往往并不精确,难以覆盖所有缺陷,缺陷文本录入不规范也会限制电力设备健康状态评估方法的准确性。因此,通过对电力设备缺陷文本深度挖掘来提高缺陷类型评估准确性的方法[36]存在固有局限性,需要先对缺陷文本进行质量提升。此外,基于机器学习的健康状态评估方法的核心是实际需要故障类型对训练的故障样本具有高度依赖性,对于故障样本未包含的故障类型,难以进行精准识别,通过生成对抗网络来生成原本故障样本未包含的数据是一种数据增强的有效手段。此外,深度学习等机器学习算法需要大量的有标签数据作为数据支撑,当训练数据匮乏时,训练出的模型极易出现过拟合的现象,这种现象在小规模数据集上尤为明显。未来,通过人工智能技术提高训练样本集完备性以加强故障类型识别精度值得深入研究。
6 电力设备缺陷文本信息挖掘前景展望
目前电力设备缺陷文本挖掘领域仍然处于初级阶段,对文本挖掘技术有待进一步研究。本文基于目前的研究成果,对电力设备缺陷文本挖掘技术进行了总结,其未来关键技术发展前景展望如下:
1) 高质量电力本体词典的构建。电力本体词典是电力设备缺陷文本挖掘技术的基础[36],其质量决定了电力设备缺陷文本挖掘的效果。受制于电力领域方向众多、词汇复杂等因素,构建高质量电力本体词典困难,如何通过相关方法构建高质量电力本体词典,是今后研究的关键问题。目前电力本体词典的构建主要针对非结构化的文本数据,如果能与结构化的多源数据进行融合,结合专家系统对电力本体词典进行实时在线扩充,将会极大消除电力设备缺陷文本挖掘对于未知缺陷的特征文本提取困难的现状。
2) 知识图谱在电力设备缺陷文本信息提取中的深层次应用。当前电力知识图谱的研究不够深入,在其内部架构设计方面有待进一步研究[38]。文献[39]所提出的电力知识图谱主要采用三元组的形式进行表示,难以表示更加复杂的电力设备缺陷文本信息。因此,如何进一步开发知识图谱,使其能够更加详细地表达复杂信息,是电力知识图谱在电力设备缺陷文本挖掘中的重要研究方向;此外,电力知识图谱构建过程中,如何更加准确地获取大量有效知识以及如何更好对知识进行有效融合,是电力知识图谱应用的另一关键问题。知识图谱具有良好的解释性,而基于深度学习的特征提取方法具有精准度高解释性差的特点,因此可以将二者结合,构建基于深度学习的新型知识图谱,将深度学习的输出结果转化为知识图谱可以理解的三元组进行推理,在保证缺陷文本提取合理性的基础上提高提取精度与效率。
3) 电力设备缺陷文本细节提取方法的深度开发[40]。当前电力设备缺陷文本细节提取方法仍较为简单,可以通过筛选进一步完善。如利用神经网络的分类功能对不同数据进行筛选,有效降低非强关联数据对提取结果的影响,改善细节提取原始数据集的质量。
4)多源数据融合在电力设备缺陷文本挖掘方法中的应用。当前依靠缺陷文本挖掘与自动诊断技术的应用对电力设备健康状态自动评价的方法只是基于历史缺陷记录数据对设备当前运行态势进行评价,如何将设备运行实时监测数据与健康状态评价模型相结合,实现电力设备健康状态完整评价,仍需要进一步研究。例如针对多源数据融合接入进行综合分析处理,实时融合机器人等站端各类智能装备在线数据和离线监测数据等信息;进而依托设备健康状态评价算法模型进行设备运行状态评估;最后结合专家系统中的知识库、规则库实现智能预警,并与智能装备调度平台进行联动控制,实现一体化、全方位的数字化和智能化设备健康状态评估。
7 结 论
本文主要从技术角度探讨了电力设备缺陷文本错误识别与质量提升、严重等级自动分类、缺陷细节提取、健康状态自动评价等关键技术。本文研究的内容,是基于该领域已有科研成果所作的总结和展望,以期对电力设备缺陷文本挖掘技术的进一步发展及应用提供一些思路和借鉴。然而配电网作为输电端与负荷端连接的关键系统,具有设备复杂、传感器种类多样、新旧程度不一等特点。在应用层面,由于运行环境恶劣、电磁干扰,许多设备状态监测装置现场应用性能不稳定,监测装置本身存在故障率、误报率高及数据可信度存疑等问题,电力设备缺陷文本智能辨识技术在配电设备智能高效运维的实际工程应用面临严峻挑战。通过建立基于人工智能的电力设备缺陷文本分类模型,对现场巡视人员录入的缺陷文本数据进行等级分类并给出相关分类依据可有效提升电力设备运维效率。此外,电力设备缺陷文本挖掘技术的发展仍然需要相当长的过程,在当前研究的基础上,应融合多种方法实现电力设备缺陷文本挖掘,以期实现更加智能的效果。
猜你喜欢
小天使·一年级语数英综合(2022年2期)2022-03-30 16:18:14
少先队活动(2020年12期)2021-01-14 01:47:40
江苏安全生产(2020年7期)2020-09-04 09:34:58
中成药(2017年3期)2017-05-17 06:09:01
现代工业经济和信息化(2016年22期)2016-08-23 11:55:50
领导科学论坛(2016年9期)2016-06-05 14:59:58
电测与仪表(2016年18期)2016-04-11 11:29:34
人生十六七(2015年29期)2015-02-28 13:09:01
电测与仪表(2014年10期)2014-04-04 12:01:56
短篇小说(2014年11期)2014-02-27 08:32:41
