
基于注意力机制的LSTM 长江汛期水位预测方法研究
2022-05-09 02:14王迎飞黄应平周爽爽
三峡大学学报(自然科学版) 2022年3期
王迎飞 黄应平 肖 敏,4 熊 彪 周爽爽 靳 专
(1.三峡大学 计算机与信息学院,湖北 宜昌 443002;2.湖北省农田环境监测工程技术研究中心(三峡大学),湖北 宜昌 443002;3.三峡大学 水利与环境学院,湖北 宜昌 443002;4.三峡库区生态环境教育部工程研究中心(三峡大学),湖北 宜昌 443002)
人们在开发利用水资源的过程中,不可避免地要面对由此产生的灾害.根据联合国政府间气候变化专门委员会(IPCC)和联合国减少灾害风险办公室(UNISDR)报告称,洪水是世界上大多数城市所遭受的最严重的灾害之一.因此有必要对内陆河流及其主要城市进行汛期水位监测,以便提前感知洪水的形成.伴随着社会发展,人类活动加剧了径流序列的非线性化程度并降低了平稳性[1],多元的径流序列给水位预报精度带来了挑战,是目前急需解决的问题之一.
河流水位数据通常是非线性、非平稳的时间序列[2],受到多方面因素的影响,预测难度较高.神经网络模型的出现,尤其是循环神经网络[3-4](Recurrent Neural Network,RNN)模型极大促进了水文时序预报的发展.随着网络的发展,RNN 面临着梯度消失的问题[5],即RNN 无法应对长时间依赖的情况.为解决这一问题,Schmidhube等[6]提出了长短期记忆网络(Long Short-Term Memory,LSTM),并成功应用于洪水预测[7-9]中,取得了不错的结果.但河流水位不仅受过去历史水位的影响,还受上游水位的影响,即河流水位数据具有时空关联性[10].目前,基于时间域卷积的神经网络(Temporal Convolutional Neural network,TCN)在处理时序任务上甚至可以超过循环神经网络,但是卷积神经网络与RNN 同样无法应对长时间依赖问题[11].因此,如何从大量的时间、空间数据中提取出有利于预测的信息,是河流水位时空预测的重点与难点,注意力机制是一种从海量的信息中快速选择高价值信息的方式,胡鹤轩等[12]建立了基于双阶注意力机制的径流预报模型,并对流域径流量进行预测,结果表明此改进方法能有效提高径流预报精度.
针对LSTM 存在空间信息应对能力不足的问题,在兼顾模型预测性能的情况下,本文提出一套具有自适应性时空注意力机制的LSTM 水位预测模型(简称AT-LSTM),输入数据先经过注意力模块自主地生成时间、空间注意力权重矩阵并赋予输入序列注意力权重值,再将带有权重信息的序列作为LSTM的输入,由LSTM 输出预测水位.将其用于预测长江流域水位,通过武汉上游的汛期水位预测武汉未来一段时间的水位,实验对比分析原始LSTM、TCN、仅应用时间注意力的LSTM(TA-LSTM)、仅应用空间注意力的LSTM(SA-LSTM)和同时应用时间注意力的LSTM(AT-LSTM).
1 研究区域与数据来源
1.1 研究区域概述
选取长江从宜昌至武汉的河段作为研究区域,如图1所示.从历史资料看,武汉经历了多次重大洪水灾害;从地理位置看,长江上游水位暴涨是引发下游洪水的重要因素.因此,十分有必要对武汉上游水位进行监测,以便决策部门提前做好应对措施,降低洪水的损害.
1.2 研究数据
1.2.1 数据来源
三峡大坝作为世界最大的水电枢纽,对其下游的水文特征影响较大,大坝上下游的水位连续性也较差.因此,本文基于三峡大坝下游流域展开研究,通过宜昌、枝城、沙市、监利和螺山5个水文站过去一段时间的每小时水位,预测武汉未来一段时间的水位.实验选取了2012 至2018 年汛期(5~9 月)每小时水位,如图2所示.数据来源于湖北省水文水资源中心官网(http://113.57.190.228:8001/#!/web/Report/River Report).水位数据包含了时间维度和空间维度,即水位数据在时间和空间上都是连续的.

图2 原始数据图
1.2.2 水位序列分析
目前针对神经网络输入变量的分析方法有:最小二乘法、主成分分析法和相关系数法等.但上述方法都存在一定的缺陷,如最小二乘法可以计算输入变量对输出变量的重要程度,但针对的主要是线性问题,有一定的局限性.主成分分析法和相关系数法虽然计算过程简单,但同样难以反应非线性、复杂多元的水位序列不同特征之间的关系.
互信息(Mutal Information,MI)以信息熵为理论基础,既能反映输入变量与输出变量间的线性和非线性关系,它的大小又能表示一个变量包含另一个变量信息的强弱[13],计算过程为:

其中:X表示输入变量;Y表示输出变量;p[x(i),y(j)]表示他们的联合密度概率;p[x(i)]和p[y(j)]为变量X和Y的边界密度概率函数;I(X;Y)是计算联合分布p[x(i),y(j)]和p[x(i)]·p[y(j)]之间的相对熵.宜昌至螺山的5个输入序列与武汉的互信息见表1.

表1 输入变量与输出变量的互信息值
由于输入变量与输出的互信息值均大于0.49,则认为可通过输入的每个水文站预测汉口站的水位.
2 基于改进时空注意力机制的水位预测模型
2.1 长短期记忆网络
长短期记忆网络(LSTM)是由RNN 演化来的,目的是解决RNN 梯度消失的问题.LSTM 通过一个状态存储单元和门结构对网络中的信息流进行选择性控制,图3展示了LSTM 的cell单元结构.单元由3个门组成:输入门、遗忘门和输出门,一个cell单元的状态更新过程如下:

图3 LSTM 记忆单元结构

其中:假定时刻t的输入为Xt,则ct表示时刻t的cell状态;ft表示遗忘门决定了ct-1有多少需要被保留;it表示记忆门决定了Xt有多少信息被用于计算ct;ot表示输出门决定了要输出cell状态的哪些部分;ht表示隐含层状态.
2.2 注意力机制
并不是所有的输入特征都与洪水预报结果呈正相关,不相关的输入往往会带来大量噪音,导致预测精度下降.然而,长江流域的水域性质复杂,在缺乏专业知识的情况下难以确定最佳输入.因此,使用注意力机制可以克服这种挑战.注意力机制有助于让模型缩小对重要数据的关注范围,可以让模型从所有输入中获取关键信息.注意力有两种类型:硬注意力和软注意力[14].硬注意力即注意力权重值的选择为0或1.软注意力的注意力权重值分布在[0,1]之间,与硬注意力相比,注意力权重的分配将更加灵活.本研究就是基于软注意力展开的,注意力模块是根据Softmax()函数设计的,输入序列经过注意力模块后,被映射为序列中每个位置元素占总体序列的比重,用重要程度表示元素的注意力权重值.运算过程如下:
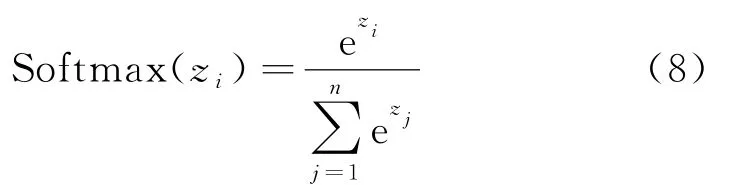
其中:zi表示输入序列中的第i位的值;n为序列包含的类别个数,通过上述运算,Softmax()函数可将输出映射在[0,1]区间内,并且输出序列元素之和为1.
2.3 模型构建
深度学习中的注意力机制主要是让模型有选择地注意特定部分的信息,本文在LSTM 数据的输入前应用注意力模块,输入序列经过注意力模块被自动赋予相应的时间或空间注意力权重信息,从而实现模型的选择性学习.根据注意力模块与LSTM 模型的组合情况,可分为仅在时间尺度上应用注意力模块(TA-LSTM)、仅在空间尺度上应用注意力模块(SA-LSTM)和同时在时间和空间尺度上应用注意力模块(AT-LSTM).重点讨论第3 种情况,即同时应用时间注意模块和空间注意模块的LSTM,所构建的AT-LSTM 模型结构如图4所示.

图4 应用了时空注意力机制的LSTM 模型结构
2.3.1 空间注意力模块
假定输入为m行n列的二维矩阵X∈Rm×n,其中m表示每个空间序列包含的水文站数量;n表示每个时间序列包含时间节点的个数.将每个时间步输入的二维序列拆分为一维的时间、空间序列,即输入矩阵的每一行表示某一个水文站的逐小时水位,输入矩阵的每一列表示某一时刻所有水文站的水位.设第t个时间步的空间序列为则t时刻空间序列的注意力权重计算过程如下所示:


2.3.2 时间注意力模块


2.3.3 时间注意力与空间注意力融合模块
将通过上述得到的空间注意力权重矩阵A和时间注意力权重矩阵B通过Hadamard积,即矩阵对应位置元素相乘的方式,得到一个与输入矩阵大小相同的矩阵,称为时空注意力权重矩阵AT,运算过程如下:

3 实验过程及分析
3.1 评价指标
为了评价模型的预测精度,本文选取了4个指标进行评估:平均绝对误差(EMAE)、均方根误差(ERMSE)、平均绝对百分误差(EMAPE)和决定系数(R2).这些评价指标的运算过程如下:

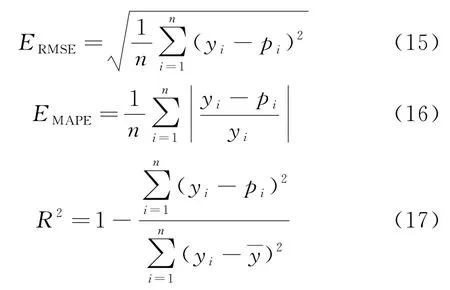
其中:n是测试样本的总数量;yi代表水位的实际值;pi表示预测水位是实际数据的平均值.EMAE、ERMSE和EMAPE用于描述样本实际值与预测值之间的差异程度,这些评价指标的度量数越小,模型的平均预测精度越高.R2用于量化预测值与实际值的接近程度,R2越接近1模型性能越好.
3.2 实验环境设置
所有实验均在Windows系统上(CPU:Intel(R)Core(TM)i7-10700KF CPU@3.8GHz,GPU:NVIDIA GeForce RTX3070,8 G),基于Python和Keras框架实现.对数据集进行划分,将2012~2016年的数据作为训练集共计18 360条数据,2017年的数据作为验证集共计3 672 条数据,2018 年的数据作为测试集3 672条数据.
为验证所提出模型的有效性,对比分析了原始LSTM、TCN、TA-LSTM、SA-LSTM 和AT-LSTM在相同数据集下的水位预测表现.所有网络模型都采用单层网络结构,并在相同的超参数下进行训练,通过预实验获得实验参数,隐含层神经元个数为128,每个批次大小为64,选择Adam 算法作为优化器,以均方误差(EMSE)作为预测模型的损失函数,设置学习率为0.01,当验证误差变化率小于0.005时训练终止.
3.3 模型的预测性能验证
表2展示了LSTM、TCN、SA-LSTM、TA-LSTM和AT-LSTM 在长江水位数据集上的平均预测表现.
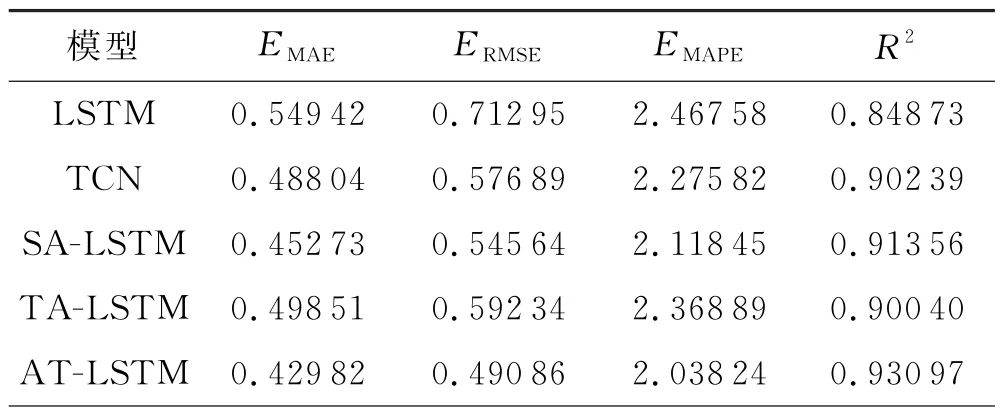
表2 预测模型的平均性能
从评价指标可以看出,AT-LSTM 的预测性能是5种模型中最好的,并且SA-LSTM 和TA-LSTM 的预测表现均好于原始LSTM,这表明时间注意力模块和空间注意力模块都对LSTM 的预测性能有积极作用.此外,TA-LSTM 的预测性能与TCN 的预测性能较为接近,而SA-LSTM 的预测性能明显大于TALSTM,这表明空间注意力模块对模型预测性能的提升程度大于注意力模块.应用了注意力机制后,ATLSTM 比原始LSTM 的平均预测性能有所提高,EMAE、ERMSE、EMAPE分别降低了21.77%、31.15%、3.54%,R2提高了9.69%.
图5显示了预测模型在不同时间步长情况下每种评价指标的变化,验证了在预测周期为[3,5,7,9,11,13,15]天时的评价指标变化情况,对应的时间步为[72,120,168,216,264,312,360].为了进一步验证所提出模型的预报性能,对比了5种预测模型在时间步为[72,168,264,360]时的水位预报结果,其预报表现如图6所示.

图5 预测模型在不同时间步长时评价指标变化

图6 模型在2018年不同时间步的预测值与实际值对比
通过实验可以发现,随着预测周期的增加,上述5种预测模型的预测误差逐渐增加.整体上,ATLSTM 的预测值与真实值最为接近,说明所提出的模块不仅提升了模型的学习泛化能力,还对长江汛期的水位预报精度有了显著提升.
3.4 注意力权重的分布分析
在上一小节的实验中,验证了所提出模型对于长江汛期水位预测精度,得到了不错的预测结果.为了进一步分析注意力模块产生的注意力权重在模型中是如何变化的,从训练好的AT-LSTM 模型中分别提取出时间注意力权重和空间注意力权重序列.由于时间注意力是运用在每一个输入的所有时间步上的,例如预测期为72 h,则72个时间步都会产生一个时间注意力权重值.为了简化时间注意力的展示方式,仅展示每个预测周期中时间注意力最大的前10个时间步,结果见表3.

表3 每个预测周期中时间注意力权重值由大到小排名前10的权重所出现的时间步
通过统计可以初步得出结论,经过时间注意力模块后,模型的注意力主要集中在小于当前时间步长约50%的部分,也就是说在预测期中,越靠近预测时刻的时间步,对准确预报的贡献越大.还对比了上一小节中4个预测期(3、7、11和15 d)的空间注意力的分布情况,结果如图7所示.

图7 空间权重值的分布情况
可以发现,距离武汉站最近的水文站的空间权重值远高于其他位置的权重值,导致这一现象的原因主要是螺山站空间位置上与武汉站较为接近,直线距离约135 km,两地的水位高度也较为接近.再次说明空间注意力模块对于提高模型预测性能贡献更大.
4 结论
本文利用时空注意力模块和长短期记忆网络解决了水位预测任务中存在的空间信息利用不足及时间跨度过长导致的预测精度下降的问题.在LSTM模型输入前应用时空注意力模块,有效提升了LSTM对时间序列任务的处理能力,并且使LSTM 能够考虑到空间信息.所提出的AT-LSTM 模型,做到了同时捕获数据的时间依赖性和空间依赖性两个维度的信息,并自主地生成相应的时间或空间注意力权重矩阵,为模型筛选输入信息中重要的部分.以长江汛期的水位作为研究对象,预测武汉的水位,在真实数据集上进行了验证,通过与多种预测模型进行对比,验证了所提出的时空注意力模型对水位预测的准确度有显著提升.
猜你喜欢
心理学报(2022年5期)2022-05-16
小雪花·成长指南(2022年1期)2022-04-09
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
第二课堂(课外活动版)(2016年2期)2016-10-21
中学英语之友·高一版(2008年10期)2008-12-11
中学生数理化·七年级数学人教版(2008年10期)2008-01-21
