
基于多模态与多尺度融合的抗欺骗人脸检测算法研究
2022-05-09 13:02:50刘龙庚
信息安全研究 2022年5期
刘龙庚 任 宇 王 莉
1(中国软件评测中心 北京 100048) 2(四川大学计算机学院 成都 610065)
近年来,人脸识别技术由于简单、无接触和高判别性等特点成为智能设备解锁、安全支付、考勤和安检等身份认证应用的主要手段之一[1].由于人脸识别技术被广泛应用于各个领域,高识别精度的人脸识别技术在恶意伪造身份攻击下存在明显安全漏洞[2].人脸识别系统一旦被演示攻击攻破,将会造成不必要的损失[3].人脸活体检测技术可通过检测并过滤伪造的攻击图像,以达到抵御攻击的目的.然而,现有的人脸活体检测技术还存在数据模态单一化、图像分辨率不高、采集方式和攻击方式单一化等诸多问题.
现有的公开数据集不能兼顾多模态、多姿态、多攻击方式等条件.在人脸活体检测任务中,多模态数据通常包括可见光(visible light, VIS)图像、近红外(near-infred, NIR)图像和深度(depth)图像.VIS图像拥有其他模态数据不具备的颜色与纹理信息,但难以抵御数码设备回放;NIR图像对回放攻击有极高的辨别能力;depth图像对各种平面类的攻击方式都有良好的防御能力,并且对光照和环境变化不敏感,能有效提高泛化性能.CASIA-SURF数据集[4]是首个包含3种模态数据的人脸活体检测数据集,其不足之处有3点:一是分辨率较低;二是其近红外摄像头没有配备滤光片;三是数据集中不包含回放攻击样本.
近年来,多模态融合方法逐渐成为提升人脸识别检测准确率的新思路[5-6];文献[4]在提出CASIA-SURF数据集的同时,也提出一种基于ResNet18网络的多模态融合的方式;文献[7]在CASIA-SURF的基础上提出了一种轻量级的人脸活体检测网络和一种决策层融合方法;文献[8]提出一种基于ResNext[9]的多模态融合方法,该方法提出的MFE(modal feature erasing)模块可以有效降低网络过拟合风险;文献[10]提出了一种多层级数据融合的方法,该方法使用 ResNet34 作为基础网络并将各个模态res1,res2,res3部分输出进行合并.现有的多模态融合方法大致分为2种:早融合(early fusion)方法和晚融合(late fusion)方法.早融合方法需要使用多分支输入分别提取多模态特征;晚融合方法的最终决策结果可以根据实际需求调整,相比早融合方法更加灵活.
在实际应用场景中,算法通常依附于人脸识别应用部署在嵌入式或者移动设备中,这就要求算法需要足够轻量化,而现有多模态融合算法对算法复杂度和参数量等问题还鲜有研究.在现有的晚融合基础上,本文提出了一种基于多模态与多尺度融合的人脸活体检测算法.在可见光人脸检测后,首先经近红外人脸第1层检测以过滤回放攻击,然后经过深度判别网络第2层检测过滤平面攻击,对于前2层检测难分类的样本进行3种模态融合加权判断得到最终分类.为了兼顾实时性能,本文对其中的判别网络进行了轻量级设计,利用多尺度图像的信息互补性进行多尺度特征提取与融合,并使用全局深度卷积代替全局平均池化提高了网络对于人脸特征的表征能力,选择Focal Loss[11]替代交叉熵损失函数解决了样本不均衡问题.在构建的多模态高分辨率人脸数据集上的对比实验证明,多模态方法在准确率指标上明显优于单模态算法,推理时间远低于其他常见融合方式.
1 多模态人脸活体检测数据集构建
本文在现有数据集采集方案的基础上,构建了一种多模态人脸活体检测(multi-modal face anti-spoofing, MMFAS)数据集.
1.1 数据集采集系统
MMFAS数据集采集系统由上下堆叠的双目摄像机和RealSense D415构成,如图1所示.其中RealSense D415由2个红外摄像头、1个可见光摄像头和1个红外结构光发射器组成,负责depth图像的获取.双目摄像机由1个可见光摄像头、1个加装850 nm窄带滤光片的红外摄像头和1个红外发射器组成,负责VIS图像和NIR图像的获取.摄像头与目标之间相距0.3~1 m,被采集目标如果是人物,需要按指示进行头部旋转操作;如果被采集目标是伪造介质,操作者需要持伪造介质按指示进行相应攻击操作.

图1 MMFAS数据集图像采集设备及拍摄对象示意图
1.2 MMFAS数据集统计信息
MMFAS数据集共包含19 938组图片,每组图片又包含3个模态数据,共计59 814张图片,其中训练数据、验证数据和测试数据的样本数量比约为7∶1∶2.MMFAS数据集包含69个目标人脸,其中31个目标为实际采集目标,包含真实数据与攻击数据,剩余38个为来自SiW数据集[12]和网络的扩展目标,由于其真实数据源不同于MMFAS,所以只包含攻击数据.MMFAS数据集中涵盖了各个年龄段、不同人种、不同性别、是/否佩戴眼镜的人群,包括6种打印攻击子类、3种回放攻击子类以及5种面部姿态子类,MMFAS数据集的详细数据分布情况如图2所示.
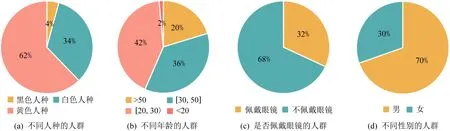
图2 MMFAS数据集的数据分布情况
表1综合统计了本文构建的MMFAS数据集和公开数据集多种属性差异.
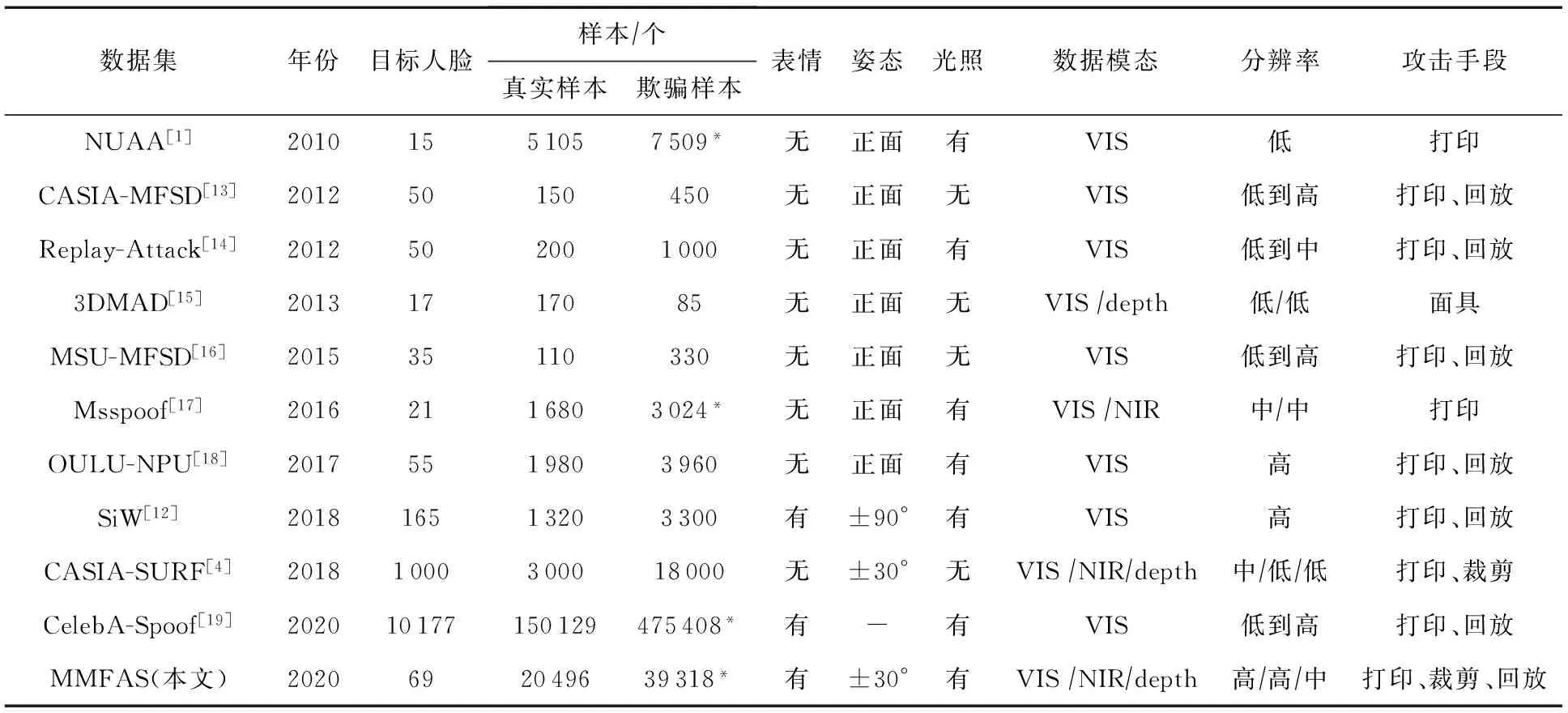
表1 MMFAS 数据集与公开数据集的对比
2 算法描述
2.1 算法总体流程设计
本文所提出的基于多模态融合的抗欺骗人脸检测(face anti-spoofing based on multi-modal fusion, FAS-MMF)算法充分利用可见光、近红外、深度模态的互补特性进行逐级过滤,避免了全部样本都经过多个网络判别.主要包含3个步骤,其总体流程图如图3所示:

图3 基于多模态与多尺度融合的人脸活体检测算法框架
步骤1.数码设备判别(NIRD).
分辨并过滤数码设备攻击(回放攻击).由于数码设备屏幕在 NIR 模态下不会成像,因此在NIR裁剪图中没有检测到人脸可以直接判断该样本为回放攻击样本,否则该样本为非回放攻击样本,可能是真实样本或打印攻击样本,需要进入步骤3进一步进行判断.
步骤2.深度模态判别.
对步骤1数码设备判别模块判别为非数码设备的样本进行判断.将其对应的depth图像输入depth判别网络进行人脸活体检测,并根据深度图的输出分数高低将样本分为真人、攻击和不易辨别3个类别.深度判别模块设置高分阈值0.7和低分阈值0.3,当分数大于0.7时直接判断该样本为真实样本,如果分数小于0.3则直接判断该样本为攻击样本,当分数在0.3~0.7之间时,则认为该样本的类别不确定,需要进入步骤3继续进行多模态加权判别.
步骤3.多模态加权判别.
对步骤1和步骤2难辨别的样本进行融合加权获得最终分类.首先将VIS图像和NIR图像分别输入对应的判别网络,得到VIS分数和NIR分数,然后再与depth分数加权求和得到最终分数,加权公式见式(1),根据各模态数据对人脸活体检测任务的重要程度进行分析,将depth图像、NIR图像和VIS图像的权重α,β,γ分别设置为0.5,0.3,0.2,最后加权分数大于等于0.5的划分为真,小于0.5的划分为假.加权求和公式如式(1):
score=α×scoredepth+β×scoreNIR+γ×scoreVIS,
(1)
其中α为depth模态权重;scoredepth为depth模态分数;β为NIR模态权重;scoreNIR为NIR模态分数;γ为VIS模态权重;scoreVIS为VIS模态分数.
2.2 单模态多尺度判别网络设计
为了进一步降低算法复杂度,图3中depth网络、NIR网络、VIS网络均采用多尺度轻量级判别网络(light-weight networks based on multi-scale fusion, LWDN-MS)作为主干网络,其网络架构如图3中虚线框内所示.主要包括如下3个步骤:
1)数据预处理.
对原始图像进行预处理得到多尺度人脸样本.首先使用RetinaFace[20]对VIS图像进行人脸检测得到人脸框坐标,接着根据人脸框坐标位置裁剪出包含面部细节的1倍缩放图和包含人脸主体、背景信息或攻击介质边框的2倍缩放人脸图.将经过增强的图像在通道维度上进行拼接,得到6×224×224的特征图并送入特征提取子网络.
2)多尺度特征提取子网络.
对多尺度输入进行特征提取.首先将步骤1)输出的特征图在通道维度拆分为2个3×224×224的张量,分别输入各自的特征提取网络,2路分别对应1倍和2倍缩放人脸图像.特征提取网络对应MobieNetV2[21]的前5层,第1层是图像下采样和通道扩张的标准卷积层,第2~5层依次为重复1次、2次、3次、4次的堆叠的倒置残差块,从第3层开始逐层下采样操作,即特征图尺寸依次减半.第5层输出2个8×14×14的特征图,作为多尺度特征融合子网络的输入.
3)多尺度特征融合子网络.
将步骤2)输出的特征图进行融合并得到精确分类.第6层首先将步骤2)中2个8×14×14的特征图在通道维度进行特征连接,得到16×14×14的堆叠特征图.网络的第7层和第8层为倒置残差块,第9层使用1×1卷积进行通道融合,第10层用全局深度卷积(GDC)替换全局平均池化层以获得自适应的权重.网络最后一层将逐点卷积替换为全连接层进行最终分类,得到通道数为2的输出,最后经过Softmax计算得到正负样本概率.
3 实验及结果分析
为了进一步验证本文算法的检测性能和鲁棒性,设置了如下2组实验:
1)检测精度对比实验.3.3节对不同的融合方式、不同的模态组合方式进行对比.
2)单模态算法与多模态算法对比实验.3.4节从检测性能和算法轻量化程度进行算法对比.
网络的深度学习框架使用Pytorch 1.7.0,python3.7进行编码.算法在Intel Core i7-8700 CPU @ 3.2 GHz,16 G-RAM,NVIDIA GeForce GTX 1080Ti的Ubuntu18.04的环境下运行.
3.1 算法评估方法
3.1.1 人脸活体检测性能指标
本文采用TPR@FPR[4,19]指标对人脸活体检测算法进行性能评估,将真实人脸定义为正类,攻击人脸定义为负类.TPR@FPR表示在当前FPR取值情况下TPR的值,该指标能在一定程度上反映分类器对正负样本的划分质量.其中TPR表示TP占总正样本数的比例,FPR表示FP占总负样本数的比例.同时,依据生物活体检测标准文件[22],本文采用攻击样本分类错误率(attack presentation classification error rate, APCER)计算攻击样本的分类错误率,采用真实样本分类错误率(bona fide presentation classification error rate, BPCER)计算真实样本的分类错误率,采用平均分类错误率(average classification error rate, ACER)计算攻击样本与真实样本的整体分类错误率,作为最终的评价指标.
3.1.2 网络轻量级指标
本文采用网络的参数量(params)表示网络模型的参数总量,采用浮点运算数(floating point operations, FLOPs)衡量网络的总体计算规模.
3.2 训练测试过程及参数
在深度学习训练过程中涉及到的参数设置如下:批处理尺寸(batch size)统一设置为128,部分网络模型显存占用较大,1次读取无法容纳所有数据,此时批处理尺寸依次减半;初始学习率为0.01;权重衰减设置为0.000 1;优化算法采用随机梯度下降算法;网络输入设置图片大小为224×224;最大训练次数(epoch)为200 轮.
采用Focal Loss[11]作为损失函数解决样本不均衡问题,α设为0.2,γ设为2;深度判别网络和近红外网络的输入为单通道,可见光判别网络的输入为3通道.
3.3 算法检测性能分析
本节设置了2个实验,表2列出了不同融合算法与本文的融合算法之间的对比效果,表3列出了单模态、双模态不同组合、3模态不同组合以及本文算法的检测效果对比.值得注意的是,在VIS和NIR模态融合时,由于没有depth分数,所以权重参数α,β,γ分别设置为0,0.6,0.4.由于TPR@FPR指标的计算需要使用分类器输出的分数,而NIRD模块不会输出分数,所以对NIRD模块的输出进行修改,将所有被NIRD模块判断为回放攻击的样本记为0分,其余样本由后续判别网络输出分数.

表2 不同融合方式的对比
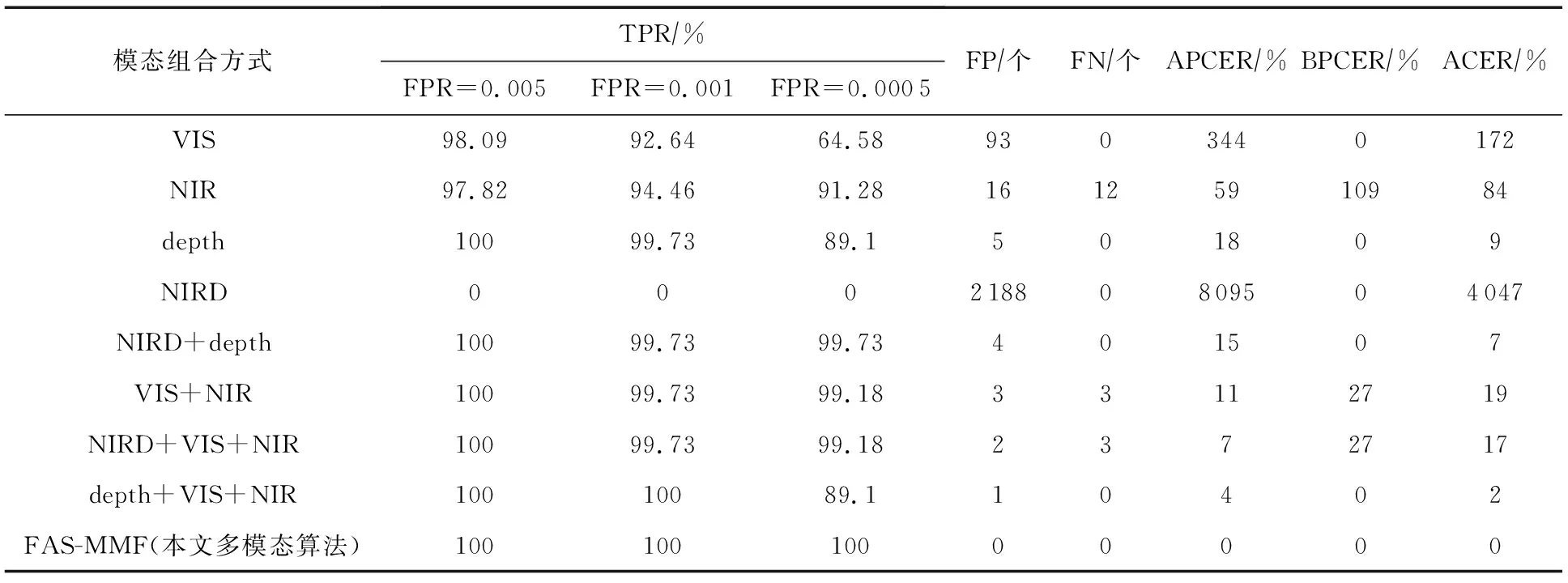
表3 不同模态组合方式的对比
表2的结果表明,本文提出的融合算法与另外2种融合算法的性能相当,其平均分类错误率都非常低,其中SE fusion算法与本文算法对所有样本都能正确分类.各种算法在检测性能方面都取得较好结果的原因可能在于多种模态数据具有较强的互补性,同时采集的数据能充分发挥各自模态的优势[23-26],具有较强的判别性.
从表3可以看出,只使用单模块进行检测,效果远差于多种模块组合的方法,和depth模块进行组合能取得更好的效果,比如NIRD+depth组合、VIS+NIR与depth组合的效果要优于其他2种组合方式;值得注意的是,VIS+NIR与depth组合时存在FP样本,在加上NIRD模块之后,FP样本被正确检测,说明NIRD模块和depth模态具有互补作用.本文提出的融合方法融合了depth模态、VIS模态、NIR模态和NIRD输出信息,在各项指标上都取得了最优结果,是所有模态组合方式中最好的.
3.4 单模态与多模态算法的检测效率对比
本实验从网络轻量化程度和准确率2方面对2.2节描述的单模态多尺度判别网络(LWDN-MS)和多种多模态算法进行对比,本节实验的推理时间的计算在i7 8700上进行,并且不使用推理框架,FAS-MMF的参数量为depth判别网络、NIR判别网络和VIS判别网络参数量的总和.
从表4可知,相比于其他常见网络,本文提出的判决网络结构具有最少的参数数量,只包含19万个网络参数和8.07 s的推理时间.多模态融合准确率指标上明显优于单模态算法.但是单模态算法在参数量和推理时间上更具优势.本文提出的FAS-MMF方法在现阶段适合在不限制成本并且对精度要求非常高的场景下使用.

表4 单模态算法与多模态算法的检测效率对比
4 结 论
针对现有的人脸活体检测模态单一、攻击方式单一、数据集质量不高等问题,本文利用多模态数据之间的互补特性,设计了基于多模态融合的人脸活体检测算法,大多数攻击样本仅需前2步判别就能被正确分类,避免了全部样本都经多个网络判别.本文对各判别网络进行了轻量级设计,进一步降低了算法的复杂度.在构建的多模态高分辨率人脸活体数据集上进行的对比实验证明了本文算法在检测性能和推理时间2方面的优越性.本文构建的数据集均为二分类样本,后续研究可丰富样本采集环境如人脸属性、攻击子类型、攻击设备、光照、姿态等,进一步提高算法的泛化性和鲁棒性.
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
肝博士(2021年1期)2021-03-29 02:32:08
华人时刊(2020年21期)2021-01-14 01:33:36
保健医苑(2020年1期)2020-07-27 01:58:26
动漫星空(2018年9期)2018-10-26 01:17:14
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
百科探秘·航空航天(2015年10期)2015-11-07 07:05:17
上海电机学院学报(2015年4期)2015-02-28 14:30:00
发明与创新(2015年33期)2015-02-27 10:40:09
奇闻怪事(2014年5期)2014-05-13 21:43:01
