
多尺度特征自适应融合的图像语义分割算法
2022-05-09 10:59:52邓佳莉谢鸿慧
小型微型计算机系统 2022年4期
王 振,杨 珺,邓佳莉,谢鸿慧,黄 聪
1(江西农业大学 计算机与信息工程学院,南昌 330045)
2(江西农业大学 软件学院,南昌 330045)
1 引 言
图像语义分割[1,2]可以理解成为图像中的每个像素点分配一个预先定义好的类别标签,实现图像的按区域划分,将图像中的不同类别用不同的颜色进行标识,在实现像素点分类的同时,还保留了不同类别像素点在图像中的位置信息.Long等人[3]最早提出了使用全卷积的神经网络(FCN)实现端到端的图像语义分割,FCN使用卷积层替换VGG16[4]等分类网络的全连接层,通过反卷积实现图像的上采样.基于FCN提出的这种编码-解码机制,RefineNet[5]、SegNet[6]和EncNet[7]等改进的编码-解码网络模型被陆续提出,Simon等人[8]还提出了一种具有上百层的DenseNets网络结构.但是这种结构都存在以下两个方面的问题:在编码过程中,频繁的使用最大池化操作会丢失大量的像素位置信息,而且普通卷积的感受域是固定的,无法获取特征图中的多尺度信息;在解码过程中,采用简单的线性插值算法,会丢失很多的细节信息[9],也没有很好的利用编码过程中多尺度浅层特征的位置信息,从而导致预测结果过于粗糙.Lu Yi等人[10]试图用图网络解决这种问题,提出了Graph-FCN,但也没有取得很好的实验效果.
由Chen等人和谷歌团队提出的Deeplab系列算法在目前的语义分割中具有不错的效果.Deeplab v1[11]中提出了使用空洞卷积来增加输出特征的感受域并替换传统的池化操作;Deeplab v2[12]中提出了空洞空间金字塔池化(ASPP)结构,通过使用多个并行的空洞卷积从不同尺度的输入图像中进行多尺度信息的提取;Deeplab v3[13]和Deeplab v3+[14]则通过改进上述的ASPP结构,在编码过程的最后阶段并行多个不同膨胀率的空洞卷积实现多尺度特征的提取,得到高层语义特征.在解码过程中,Deeplab v3直接将编码得到的语义特征进行线性插值上采样,得到最终预测结果;Deeplab v3+则先将语义特征进行线性插值上采样,与编码过程中的某一层低阶特征进行融合,再次线性插值上采样得到最终的预测结果.这两种解码方式都过于简单,没能有效利用编码过程中的多尺度信息.
针对Deeplab v3+网络解码阶段缺乏对编码阶段多尺度特征信息的利用问题,同时考虑到编码阶段多尺度特征对解码的重要作用,根据Liu等人[15]提出的自适应空间特征融合思想,本文提出了一种多尺度特征自适应融合的图像语义分割算法(ASFF-Net),该算法将编码阶段产生的不同尺度特征按照自适应的比例进行融合,使高层语义信息在解码过程中能够利用多个尺度的低阶信息进行上采样,以期达到更好的语义分割效果.
2 相关研究
2.1 编码-解码模型
图像语义分割一般采用编码-解码结构实现原图像端到端的像素级别的分类任务,编码过程通常采用图像分类网络作为下采样的骨干网络,提取图像的高级语义信息;解码过程则通过对编码结果进行线性插值、转置卷积或反池化等操作进行上采样,通过解码过程能够得到与输入图像相同大小的像素分类结果.解码过程可融合编码过程中相应的编码特征,实现对编码过程中低级语义特征空间位置信息的利用,从而达到更为精准的图像语义分割效果.如图1所示为一种对称的编码-解码模型结构,其解码结构与编码结构相同,且融合了对应层的编码特征.
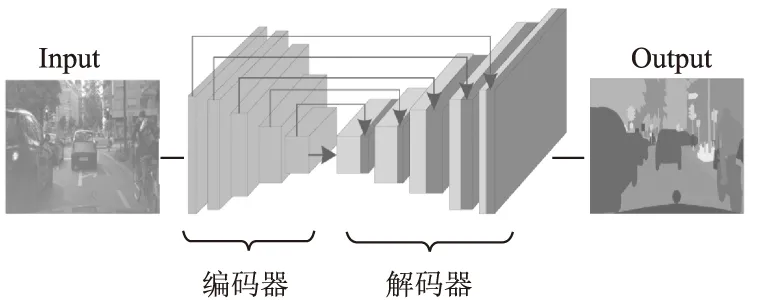
图1 对称的编码-解码模型结构Fig.1 Symmetric encoding-decoding model
2.2 空洞卷积与空洞空间金字塔池化(ASPP)结构
在FCN、RefineNet、SegNet等语义分割网络中,为了扩大输出特征的感受野,一般通过卷积层和池化层缩小特征图的尺寸来实现,由于图像语义分割网络通常是基于编码-解码结构,在解码过程中利用缩小的特征图还原至原图大小时,通常会造成很大的精度损失.空洞卷积[11]的提出能够很好的弥补这种缺陷,空洞卷积可以通过膨胀率控制卷积核以及感受野的大小,以便获取图像中的多个尺度信息.当膨胀率为r时,表示在普通卷积核的每两个元素之间插入r-1个0,当r=1时,则为普通卷积核.空洞卷积的优势在于在不增加参数数量的条件下,扩大了输出特征的感受野,能够获取更大尺度的特征.
图像语义分割要完成对图像中每个像素点的密集预测,通常需要获取图像的多尺度特征,在卷积神经网络中,神经元的感受野越大,意味着其能够捕获原图像中更大尺度的特征信息,神经元的感受野较小,其捕获的一般是局部和细节信息.为了获取某一特征图中的多尺度特征,通过使用不同膨胀率的空洞卷积,并行进行多尺度特征的提取,构建空洞空间金字塔池化(ASPP)[13]结构,最终通过级联多个相同尺寸大小的输出特征图,融合多尺度特征.如图2所示为ASPP结构对编码骨干网络最终的输出特征图进行多尺度特征提取并融合的过程.

图2 ASPP的结构图Fig.2 Structure of ASPP
2.3 深度可分离卷积与Aligned Xception网络
在深度神经网络中,频繁的使用卷积层提取图像特征,会导致网络模型的训练参数过多,增加网络模型的结构复杂性,从而会导致网络的训练速度过慢.深度可分离卷积[16]在深度神经网络中也能够提取图像特征,达到与正常卷积几乎等效的特征提取能力,且具有参数量少的优势.对于一张a*a大小,通道数量为n的特征图,使用3*3大小的卷积核提取图像的m个属性,得到最终的b*b大小,通道数为m的特征图,需要定义的参数数量为3*3*n*m,如图3所示为正常卷积提取图像特征的执行过程.深度可分离卷积的运行过程按两个步骤执行:首先使用3*3大小,通道数量为n的卷积核对输入特征图的n个通道分别进行卷积,但是对于同一位置上的像素点不进行所有通道上数值的求和运算,得到b*b大小,通道数依然为n的特征图;再根据需要获取属性的数量m,对前面得到的b*b大小,通道数为n的特征图进行m次简单的1*1卷积,从而得到最终的b*b大小,通道数为m的特征图,其需要定义3*3*n+1*1*n*m个参数,如图 4所示为深度可分离卷积对应的卷积过程.由此过程可知,当需要提取的属性数量m越大时,深度可分离卷积相对于正常卷积可大量减少需要训练的参数数量.
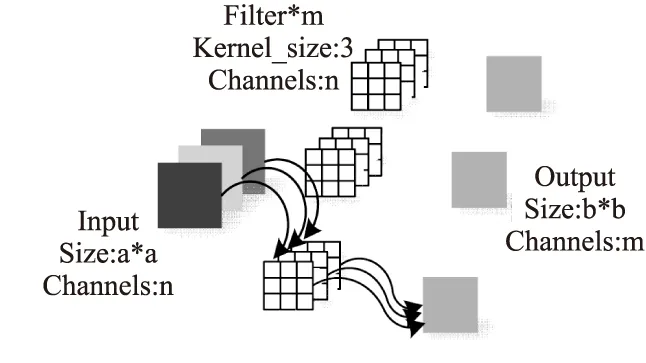
图3 一般卷积过程Fig.3 General convolution

图4 深度可分离卷积过程Fig.4 Depthwise separable convolution
由于Xception[16]网络模型在图像分类中表现出优越的性能,因此将其作为语义分割模型编码部分的骨干网络.在Aligned Xception网络的基础上,使用深度可分离卷积(Depthwise separable convolution)替换普通的卷积层以及最大池化层,增加网络的层数,且在每个3*3卷积之后都进行归一化和relu激活,加快模型的收敛速度.这种优化的模型相比于传统的编码网络,大量地减少了卷积核的参数,深层的网络结构也增强了模型的表达能力.改进的Aligned Xception网络结构如图5所示.

图5 Aligned Xception网络结构Fig.5 Aligned Xception
2.4 自适应空间特征融合(ASFF)结构
神经网络结构中的不同尺度特征图都包含了不同级别的语义信息和细节信息,通过融合编码过程中的多尺度特征图,能够使语义分割解码过程得到更准确的预测结果.自适应空间特征融合(ASFF)[15]结构能够给不同尺度特征分配自适应的权重参数,实现不同尺度特征的高效融合,其实现的具体步骤主要分为两步:首先对不同尺度的特征图进行统一尺寸的卷积处理,选定某层特征图的尺寸作为标准,对于尺寸大于给定标准的特征图进行下采样(步长为2的卷积或池化操作),对于尺寸小于给定标准的特征图进行上采样(线性插值法),最终实现不同尺度特征图大小、通道数的统一;然后给每个标准化后的特征图分配一个自适应的权重参数矩阵,每个特征图都与其对应的权重参数矩阵相乘,最后将每个特征图相同位置的元素值相加,从而得到最终的融合结果.
3 网络结构与算法实现
3.1 网络结构
Deeplab v3+网络是图像语义分割领域内一种较为高效的网络模型,它在Deeplab系列中具有最好的分割效果,但是其解码结构不够完善,在输出步长output_stride=16的网络解码结构中,直接将编码过程产生的特征图进行4倍上采样,然后与编码过程中1/4大小的特征图进行concat融合,将融合后的特征图继续进行4倍上采样,得到最终的预测结果.这种解码方式会导致编码过程中产生的多尺度特征上下文信息的丢失,因此本文提出改进Deeplab v3+网络的解码结构,将编码阶段中的多尺度特征进行融合,有效利用编码阶段的多尺度上下文信息,以期达到更好的语义分割效果.改进后的Deeplab v3+网络模型ASFF-Net的网络模型结构如图6所示,网络的执行步骤如下:
观察组的男女比例为9:11,年龄跨度范围30-62岁,平均(43.3±17.9)岁,其中的最短患病时间1个月,最长12个月,平均(8.4±3.2)个月;对照组的男女比例为19:21,年龄跨度范围29-60岁,平均(45.9±16.2)岁,其中的最短患病时间2个月,最长14个月,平均(9.7±4.3)个月。两组患者一般资料无统计学意义,P>0.05。

图6 ASFF-Net网络模型结构Fig.6 ASFF-Net network model structure
1)该网络模型的编码结构为Aligned Xception网络,其结构如图5所示,该网络均采用深度可分离卷积提取图像特征,并取代了普通网络中的最大池化操作,在每个3*3卷积之后都会进行归一化和relu激活,加快了模型的收敛速度.模型由Entry flow、Middle flow和Exit flow共3个部分组成,设定输出步长output_stride=16,在特征提取过程中会产生1/2、1/4、1/8和1/16大小的特征图,不同大小的特征图包含了不同尺度的上下文信息,1/16大小的特征图为Aligned Xception网络特征提取的最终结果.
2)为进一步提取Aligned Xception网络最终结果中的不同尺度信息,通过调节空洞卷积的膨胀率r获取不同感受野的上下文信息,使用空洞空间金字塔池化(ASPP)结构来实现多尺度特征的提取.该结构中5个卷积操作并行进行特征提取,第一个为1*1卷积,第5个为平均池化卷积,其余3个为3*3的空洞卷积,其对应的膨胀率分别为r1=6,r2=12,r3=18,其中padding与dilation的值相同,因此该结构会生成5个尺寸和通道数都相同的特征图,然后使用concat将5个特征图进行融合,最终通过1*1卷积改变通道数,得到编码阶段的最终结果.
3)为有效利用编码过程中不同尺度特征图包含的语义信息,利用自适应空间特征融合(ASFF)算法,将1/2、1/4和1/8大小的特征图进行特征融合.选取1/4大小特征图的尺寸和通道数作为融合标准,对于1/2大小的特征图,首先进行1*1卷积,将其通道数转换为与1/4大小特征图相同的通道数,然后进行步长为2的3*3卷积,将特征图进行2倍的下采样;对于1/8大小的特征图,也先进行1*1卷积,将其通道数转换为与1/4大小特征图相同的通道数,然后进行2倍的线性插值上采样,最终得到了3个尺寸和通道数都相同的1/4大小的特征图,最终根据自适应空间特征融合(ASFF)算法进行融合,得到最终的融合结果.
4)将第2步中的编码结果进行4倍的上采样,然后与第3步中的特征融合结果进行concat融合,再次使用3*3卷积对特征图进行处理,最后通过4倍上采样完成解码过程,从而得到最终的预测结果.
3.2 自适应空间特征融合(ASFF)算法
Deeplab v3+是一种编码-解码模型,本文采用的是output_stride为16的网络结构,即编码阶段输出的最小特征图为原图的1/16,编码阶段下采样均使用stride=2的卷积操作,因此编码阶段会产生4种不同大小的特征图.为了利用编码阶段产生的4种不同尺度大小的特征图,本文提出使用自适应空间特征融合(ASFF)算法,在解码阶段按不同比例融合多尺度特征,能够合理利用编码产生的多尺度信息实现更精准的图像语义分割效果.
首先获取编码阶段中分别为原图1/2、1/4、1/8大小的特征图作为自适应空间特征融合算法的输入,考虑到需要融合的特征图大小和通道数不一致性等问题,选取1/4大小特征图的尺寸和通道数作为融合标准.对于1/2大小的特征图,首先使用1*1卷积将其通道数转换为与1/4大小特征图相同的通道数,然后执行步长stride=2的卷积过程,实现2倍的下采样;对于1/8大小的特征图,首先也要使用1*1卷积将其通道数转换为与1/4大小特征图相同的通道数,然后通过线性插值,实现2倍的上采样.最终实现了3种不同尺度特征图的统一尺寸和通道数的处理,得到了3个尺寸、通道数都相同的特征图X1i,j、X2i,j、X3i,j.
X1i,j、X2i,j、X3i,j特征图分别来自编码阶段的不同深度,因此其包含了不同的细节信息,多尺度特征融合就是要实现这3个特征图的按比例融合,针对3个特征图中同一位置的像素点,定义ai,j、bi,j、ci,j为融合比例,确定来自不同特征图像素点的权重参数,因此特征融合策略定义为:
ai,jX1i,j+bi,jX2i,j+ci,jX3i,j=Yi,j
(1)
Yi,j为融合后的特征图,其中的融合比例ai,j、bi,j、ci,j∈[0,1],且满足:
ai,j+bi,j+ci,j=1
(2)
(3)
(4)
(5)
4 实验研究过程与结果对比分析
4.1 实验环境配置
为验证本文提出算法的优越性和建立对照实验,本文所有实验的软硬件环境配置情况如表 1所示.
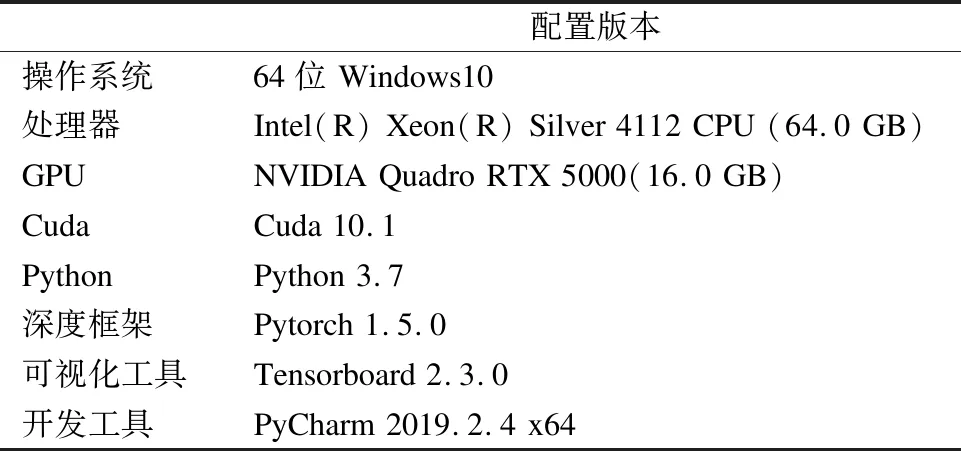
表1 实验的软硬件环境配置Table 1 Configuration of the experiment
4.2 实验数据集
Cityscapes数据集是图像语义分割领域内较为常用的一个数据集,该数据集通过使用车载摄像头采集了欧洲50个城市在不同环境、不同季节条件下的5000张街道场景图像,并包含了图像对应的像素级标签图像,图像分辨率为2048×1024.该数据集的训练集有2975张图像,验证集包含了500张图像,测试集为1525张图像,通常使用其中19个人工标注类别进行语义分割的实验.
Vaihingen数据集是由国际摄影测量与遥感学会ISPRS提供的遥感图像语义分割的数据集,其中的遥感图像来自 Vaihingen市的某个小村庄,语义类别主要有建筑物、低矮植被、树木等.该数据集中包含了33张尺寸不一的高分辨率图像及其对应的标签图像,本次实验随机选用20张原图作为训练集,7张原图作为验证集,6张原图作为测试集;根据实验要求,设定513×513的滑动窗口,按照移动步长为256的裁剪策略进行图像裁剪切割,处理之后得到的训练集、验证集和测试集图像数量分别为1018张、434张和276张.
4.3 实验评价指标
在图像语义分割领域中,为评估模型的性能和预测结果的准确度,建立预测结果与真实标签的混淆矩阵,将像素准确度(PA)、类的平均像素准确度(MPA)、平均交并率(MIoU)和带权交并率(FWIoU)等作为评价指标[17],其计算公式如表2所示,其中K为像素类别总数,Pi为第i类的像素点总数,Xji表示真实类别为j,预测类别为i的像素点,Xii表示真实类别为i,预测类别也为i的像素点.

表2 语义分割的评价指标Table 2 Evaluation index of semantic segmentation
4.4 实验过程与结果分析
为验证多尺度特征自适应融合的有效性,首先在deeplab v3+网络模型基础上将3个不同尺度的编码特征图按照1∶1∶1的比例进行融合,构建SFF-Net模型结构,作为对照实验;然后按照自适应空间特征融合(ASFF)算法将不同尺度特征图进行融合,构建ASFF-Net模型.
4.4.1 Cityscapes数据集的实验过程
本实验通过使用Xception网络的预训练模型参数,以迁移学习的方式初始化图像语义分割网络结构的编码部分,加快模型的收敛速度;对训练集数据采用左右随机翻转、随机缩放裁剪等方式进行数据增强;使用poly算法调整训练过程中的学习率;采用随机梯度下降法,通过计算交叉熵损失[18]进行梯度的反向传播;其它超参数的设置如表 3所示.
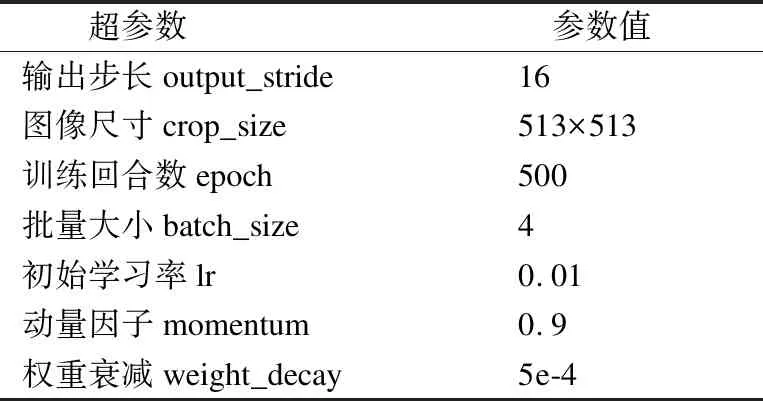
表3 超参数的设置Table 3 Setting of super parameters
4.4.2 Cityscapes数据集的实验结果分析
如表4所示为不同网络模型的语义分割精度对比结果,通过对比分析可以发现,在Deeplab v3+网络模型基础上将3个不同尺度的编码特征图按照1∶1∶1的比例进行融合的SFF-Net网络模型,其分割效果在4个评价指标上均低于Deeplab v3+网络本身的分割精度,由此说明直接将不同尺度特征进行相加融合不仅不能提高反而可能会降低预测准确率;但本文提出的多尺度特征自适应融合网络ASFF-Net在4项评价指标上均优于Deeplab v3+网络,正是由于ASFF-Net在特征融合时能够自适应调整不同尺度特征图在每个像素点的权重大小,自适应选择有效特征,实现不同尺度特征图高效的自适应融合,从而达到更加精准的语义分割效果.通过表5可以发现,本文提出的ASFF-Net网络模型在Cityscapes数据集的19个语义类别中,有11个类别的分割效果得到了提升,且对小尺度目标物体有了更为精准的分割效果.

表4 Cityscapes数据集上模型预测精度对比Table 4 Comparison of prediction accuracy of different models on Cityscapes

表5 Cityscapes数据集上不同语义类别IoU值对比Table 5 Comparison of IoU of different semantic categories on Cityscapes
为了更加直观看出本文提出的多尺度特征自适应融合算法(ASFF-Net)的优越性,将Deeplab v3+网络的预测结果与ASFF-Net的预测结果进行可视化对比分析.如图7所示,第1列结果中Deeplab v3+网络未能正确分割出少部分的天空像素点,ASFF-Net能够进行更精细的分割,将其识别出来;第2列结果中,ASFF-Net相对于Deeplab v3+网络对骑自行车的人有了更为精确的分割效果;第3列结果中,Deeplab v3+将小尺度目标车辆误分为人,但ASFF-Net能够准确识别小尺度目标物体;第4列结果中ASFF-Net对大树的分割明显达到了比Deeplab v3+更加准确的分割效果;第5列结果中Deeplab v3+网络未能识别出花坛中的绿植,但是ASFF-Net达到了和标签图像几乎一样的预测效果.由此可以证明本文提出的多尺度特征自适应融合算法(ASFF-Net)在小尺度目标物体的分割上相比于Deeplab v3+网络更为精确,且对大部分语义类别的预测准确度有了提高.

图7 不同模型在Cityscapes数据集上的预测结果Fig.7 Prediction results of different models on Cityscapes
4.4.3 Vaihingen数据集的实验结果分析
为进一步验证本文提出算法的泛化性和有效性,在Vaihingen遥感图像数据集上进一步实验.此实验仅将Cityscapes数据集训练超参数中的训练回合数epoch改为100次,输出步长、批量大小、初始学习率等参数的设置均保持不变,Deeplab v3+、SFF-Net和ASFF-Net这3个网络在设定的epoch次数内均达到收敛状态.通过训练得到的模型在Vaihingen测试集上的预测精度以及各个语义类别的IoU值对比结果如表6和表7所示,通过对比发现改进后的网络在像素准确度、平均交并率、带权交并率等指标上的结果都优于Deeplab v3+网络;在3种模型结构中,本文提出的多尺度特征自适应融合网络(ASFF-Net)在5个语义类别上的预测效果均达到最优.

表6 Vaihingen数据集上模型预测精度对比Table 6 Comparison of prediction accuracy of different models on Vaihingen

表7 Vaihingen数据集上不同语义类别IoU值对比Table 7 Comparison of IoU of different semantic categories on Vaihingen
如图8所示为本文提出的多尺度特征自适应融合网络模型ASFF-Net与Deeplab v3+网络模型在Vaihingen测试集上预测结果的对比,通过第2列、第3列和第4列可以看出,本文提出的ASFF-Net网络模型的语义分割效果比Deeplab v3+网络的分割结果更为精细,通过第1列和第5列可以看出ASFF-Net能够识别出遥感图像中Deeplab v3+网络未能识别出的小尺度目标物体.综上,由于ASFF-Net能够按照自适应比例融合网络编码过程中的多尺度特征图进行上采样,因此其具有更强的特征捕获能力和更精细的语义分割能力.

图8 不同模型在Vaihingen数据集上的预测结果Fig.8 Prediction results of different models on Vaihingen
5 结束语
本文提出了一种基于Deeplab v3+网络改进的多尺度特征自适应融合的图像语义分割算法,该算法也是通过编码-解码模型来完成图像的语义分割任务.针对Deeplab v3+解码结构过于简单,仅融合编码过程中某一尺度特征图而造成最终语义分割结果较为粗糙的问题,本文提出的算法能够给编码过程中的多尺度低阶语义特征图分配自适应的融合权重,实现解码过程对编码过程中多尺度信息合理且高效的利用,从而提高网络的语义分割性能.从实验结果来看,本文提出的算法在像素准确度、平均像素准确度、平均交并率和带权交并率4项指标上都优于Deeplab v3+网络,且对图像中大部分小尺度目标物体有了更为精确的分割效果.尽管本文提出的算法有了些许改进,但仍存在预测图像边界不清晰等问题,下一步的工作需要结合图像的边缘检测[19-21],有效提高物体边界的分割效果,且尽可能减少网络参数,提高网络的分割效率.
猜你喜欢
中国石油石化(2022年12期)2022-07-16 08:28:28
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
开放教育研究(2020年2期)2020-03-31 01:54:14
中国外汇(2019年19期)2019-11-26 00:57:32
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
太空探索(2016年5期)2016-07-12 15:17:55
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
时代英语·高三(2014年5期)2014-08-26 17:01:17
