
基于用户评论文本情感分类的推荐算法ABFR
2022-05-08 03:51:18朱千谦蓝雯飞孙惠张雨绮田鹏
中南民族大学学报(自然科学版) 2022年3期
朱千谦,蓝雯飞,孙惠,张雨绮,田鹏
(中南民族大学 计算机科学学院,武汉 430074)
1 文献综述
随着互联网的崛起与发展,人们的生活发生了翻天覆地的变化.生活中的各个领域,如医疗、交通、购物、娱乐等都充斥着大量的数据,虽然网络中的数据呈现指数级的增长给人们带来了便利,但是海量数据又增加了人们获取有效数据的难度.数据过载使得从海量数据中挖掘有效信息成为一个难以解决的问题.近年来,推荐算法被证明在实际场景中能够有效地解决数据过载的问题,因此推荐算法成为国内外专家学者研究的热点领域.
协同过滤推荐算法和基于内容的推荐算法是传统推荐算法的代表.其中,协同过滤推荐算法通过用户与系统的交互行为来分析其兴趣偏好,为兴趣相似的用户推荐类似的物品;基于内容的推荐算法则是根据物品的元数据,挖掘物品之间的相关性,然后基于用户的历史偏好为用户推荐相似的物品.
当系统中数据量过大的时候,用户难以获取稀疏分布在系统中的有效数据.为了解决这个问题,系统需要多维度分析用户交互行为的特征,通过特征来获取更多关联性的数据,继而解决数据稀疏性的问题.因为用户的评论信息是反映用户兴趣偏好的重要载体,所以国内外研究人员致力于从用户评论信息中提取更多的有效数据.
GUANG等[1]和CATALDO等[2]率先利用了非负矩阵分解和狄利克雷分布的方式提取了评论的主题分布和主题中每一个词的分布,实现了一种比单一评分数据的模型更加精确的推荐方式.但是,这两种方式没有考虑到评论文本中词与词之间的依赖关系.BAO等[3]提出一种TopicMF模型,该模型利用矩阵分解的方式将用户-物品评分矩阵进行分解来提取用户和物品的潜在因子,同时使用非负矩阵分解的方法从评论中提取主题,并将主题因子与用户物品潜在因子进行关联,但当主题因子和用户物品潜在因子稀疏时,相关联的因子缺失会降低推荐质量.WU等[4]设计了一种基于上下文感知的用户-物品表示学习模型,该模型通过两个独立的学习组件,分别利用用户的评论数据和评分交互数据,动态地学习用户的交互特征.由于该模型训练量较大,当两种交互特征的耦合度较高时,特征数据较少,导致无法根据用户的交互特征进行精确推荐.不同的评论信息对于某一个具体目标的重要性是不一样的,MPCN[5]模型利用评论级别的共注意力机制,挑选出最重要的评论,然后利用词级别的注意力机制来提取重要评论的特征信息,但该模型会忽略低级别的评论信息,导致评论特征信息提取不全面而降低推荐的准确率.
上述方法虽然致力于不断提升推荐算法的质量,但只能提取文本的浅层信息,无法获取文本中上下文的依赖关系.由于BiLSTM能够双向捕获上下文的语义依赖关系,为了全面提取用户评论短文本中的特征信息,在可获取用户评论数据的场景下,本文提出了一种基于ALBERT-BiLSTM模型的协同过滤推荐算法(ALBERT-BiLSTM Model Based Collaborative Filtering Recommendation Algorithm)ABFR算法,ABFR算法先利用ALBERT模型对用户评论信息进行预处理,将普通文本转化为词向量,继而使用BiLSTM网络分析词向量间的情感倾向.将用户评论短文本中的情感倾向转化为评分数据填充到用户评分矩阵中,再结合矩阵中情感分析的评分数据和用户对物品的评分数据来为用户提供个性化推荐,最后通过对比实验证明算法的有效性.
2 模型介绍
2.1 ALBERT预训练模型
BERT模型参数量大,使用BERT模型进行预训练需要更高的计算能力和更多的时间开销,为了解决这个问题,LAN等[6]提出了ALBERT模型,模型结构如图1所示.

图1 ALBERT模型结构Fig.1 Structure of ALBERT model
图1中[E1,E2,…,En-1,En]是原始文本向量,trm是Transformer模型[7],模型的输出包含了表示全部文本上下文信息的向量,每个向量[T1,T2,…,Tn-1,Tn]包含了一条完整序列的文本信息.
2.2 BiLSTM神经网络
BiLSTM神经网络通过拼接前后向隐藏层向量,提取词向量之间的语义依赖关系,这样就能够充分考虑上下文信息,挖掘语料中的情感倾向.BiLSTM的结构如图2所示.
图2中,LSTML和LSTMR分别是前向传递模块和后向传递模块,XN表示N位置上的词向量输入,hLN和hRN分别是N位置的前向传递隐层输出和后向传递隐层输出.最后BiLSTM模型的输出结果是前向和后向输出结果的均值[hLN,hRN].
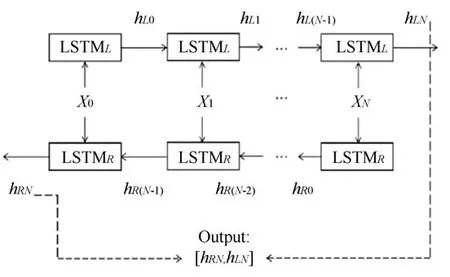
图2 BiLSTM结构图Fig.2 BiLSTM structure diagram
3 基于ALBERT-BiLSTM模型的协同过滤推荐算法ABFR
3.1 基于ALBERT-BiLSTM评论短文本情感分类的推荐模型
为了佐证评论文本中的情感倾向信息是否对推荐算法的精确度有正向影响,本文提出基于ALBERT-BiLSTM的情感分析模型来挖掘用户评论数据中的情感倾向并根据情感倾向进行个性化推荐.首先评论语料信息进入ALBERT层进行预训练,ALBERT层将一条评论语句转化为多个词向量.词向量传入BiLSTM层中,BiLSTM通过前向LSTM和后向LSTM来捕获词向量间双向的语义依赖信息分析用户评论文本中的情感倾向;然后将情感倾向进行二分类,分为积极情感和消极情感传入情感数值化层.情感数值化层将情感倾向进行数值化处理,数值化处理方式可以表示为:

将情感数值化评分代入到用户评分矩阵,此时用户评分矩阵中的数据为普通评分数据和情感数值化评分数据的并集.最后,通过用户相似度计算公式挖掘邻域用户,根据用户对物品的评分对相似物品进行聚类,为邻域用户提供个性化推荐,见图3.

图3 ABFR算法的模型图Fig.3 Model diagram of ABFR algorithm
3.2 相似度计算
因为协同过滤推荐算法的原理是通过计算用户相似度和物品相似度来构建最近邻居集合,并为最近邻居推荐用户偏好相似的物品,所以用户相似度和物品相似度计算是推荐算法的核心.
3.2.1 用户相似度
在用户-物品评分矩阵中,因为两个用户对相同物品评分的均方差越小则表示两个用户相似度越高,所以本文使用用户评分均方差来计算用户相似度,计算方式可以表示为:
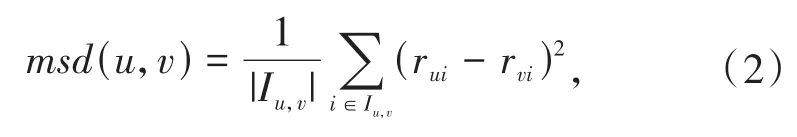
其中,Iu,v表示用户u和用户v都评价过的物品集合,msd(u,v)表示用户u和用户v对相同物品评分的均方差,则用户的相似度的计算方式可以表示为:
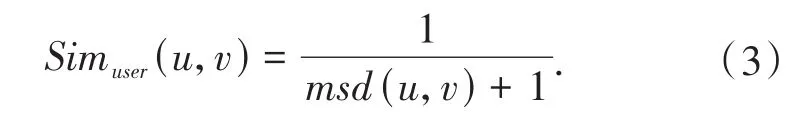
3.2.2 物品相似度
WENG等[8]指出在用户对物品评分数据稀疏的情况下,针对物品的特征属性对物品进行聚类能够在一定程度上缓解数据稀疏性导致物品相似度度量不准确的问题.物品相似度的计算方式可以表示为:

其中,F为物品的特征总数,fi表示物品i所具有的特征数,fj表示物品j所具有的特征数.故公式(4)中的分子表示物品i和物品j所具有相同特征的个数,分母表示物品特征总数和物品i,j都不具有的特征数的差值.
3.2.3 物品相似度归一化
XIANG等[9]发现在基于物品相似度的协同过滤推荐算法中,如果将物品的相似矩阵按照矩阵最大值进行归一化可以提高推荐的准确率.而KARYPIS等[10]提出对物品的相似矩阵按照矩阵最大值进行归一化可以提高推荐算法的覆盖率和多样性.因此,当物品的相似矩阵构建以后可以按照公式(5)进行归一化,物品相似度计算方式可以进一步表示为公式(5):

其中,Sim'item(i,j)表示物品i和物品j的相似度,max表示相似度矩阵的最大值.
3.3 预测评分公式
用户u对物品i的评分计算方式可以表示为:
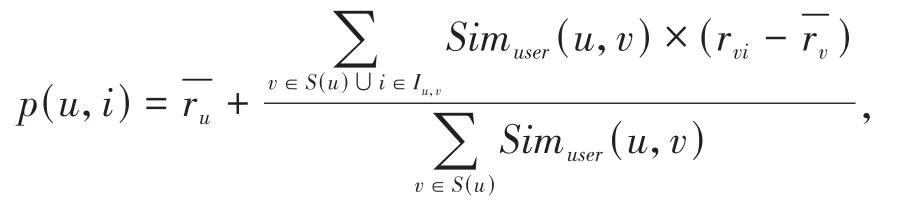
其中,S(u)表示与当前用户相似度最高的前n个用户所组成的集合,Iu,v表示用户u和用户v共同评分的物品的集合.Simuser(u,v)是用户u和用户v通过公式(3)计算得到的相似度.rvi表示用户v对物品i的评分表示用户u对物品的平均评分表示用户v对物品的平均评分.
4 实验
4.1 实验数据集介绍
实验数据来自于豆瓣电影评论数据集——DMSCD数据集,通过分时多次爬取,在各个时间段内对热门电影爬取用户评论数据,爬取的字段包括用户id、用户名称、观看时间、电影id、电影名称、评论信息.该数据集包含了129490个独立用户对58514部电影的1048446条评论信息,达到实验所需数据量.本实验先将数据进行清洗,将重复记录、逻辑错误记录和信息缺失记录剔除,剩余987494条数据,按照8∶2的比例设置训练集和测试集.
4.2 实验参数设置
实验参数设置如表1所示.

表1 实验参数Tab.1 Experimental parameters
4.3 实验评价指标
本实验使用准确率(Accuracy)作为情感分类对比实验的评价指标,使用精确率(Precision)和召回率(Recall)[11]作为推荐模型对比实验的评价指标.
(1)准确率:被正确分类的样本数占全体样本数的比例,准确率越高,分类器的分类效果越好.具体的计算方式可以表示为:
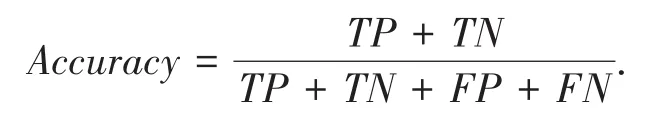
(2)精确率:在训练集中,针对目标用户u所推荐的物品列表中真正的正样本占预测为正的样本的比例.具体的计算方式可以表示为:

(3)召回率:在训练集中,针对目标用户u推荐的物品列表中有多少正例被正确预测.具体的计算方式可以表示为:
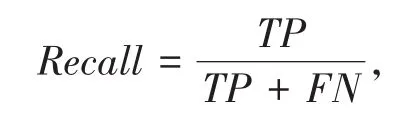
其中,TP是正确预测出的正样本个数;TN是正确预测出的负样本个数;FP是错误预测出的正样本个数;FN是错误预测出的负样本个数.
4.4 评论短文本情感分类对比实验
近年来,研究人员在文本情感分析领域提出了基于机器学习的SVM[12]模型来解决非线性高维度情感分析的问题.随着神经网络的发现,国内外学者先后利用RNN[13]、RNTN[14]、LSTM[15]、BiLSTM[16]和CNN[17]网络挖掘文本的情感倾向.
(1)SVM:支持向量机,是一个非常高效的分类模型,通过寻找不同情感的分界面,使得情感二分类的样本尽量落在分界面的两边,可用于检测评论文本中词所在类别所表达的情感.
(2)RNN:循环神经网络,能够挖掘出具有序列特性的时序信息和语义中包含的情感信息.
(3)RNTN:递归张量神经网络,通过往词向量中添加一个矩阵来组成一个词向量-矩阵的形式,RNTN能够允许乘法类型的词向量之间相互作用,可以用于处理复杂的词向量数据.
(4)LSTM:长短期记忆网络,通过有效保存长距离单向词向量的语义信息,根据词向量之间的语义依赖关系对情感信息进行分类.
(5)BiLSTM:双向长短期记忆网络,通过对词向量之间语义依赖关系进行双向解析,对情感信息进行分类.
(6)CNN:卷积神经网络,通过捕捉词向量的短距离语义依赖特征来获取文本中的局部信息,对文本中的局部信息进行解析从而获取文本中的情感信息.
为了对比不同方法针对文本情感分析的准确性,本节在DMSCD数据集上进行了情感分类任务,将算法使用的ALBERT-BiLSTM分类模型与多个模型进行了对比实验,实验结果见表2.

表2 情感分类对比实验数据结果统计Tab.2 Comparative experimental data statistics of emotion classification %
如表2所示,在情感分类的任务上,BiLSTM相较于传统的机器学习方法有着显著的性能提升.BiLSTM通过双向捕捉词向量之间的语义依赖关系使得情感分类的准确率达到了82.6%,这一结果与SVM方法相比准确率提升了6.4%,与CNN卷积神经网络方法相比准确率提升了1.1%.本算法所使用的基于ALBERT-BiLSTM的情感分类方法相较于BiLSTM方法在对单句情感分类的实验上准确率提升了2.8%;在对所有句子情感分类的实验上准确率提升了3.1%.实验证明,本文所使用的基于ALBERTBiLSTM的情感分类方法具有更好的分类效果.
4.5 推荐算法对比实验
为了比较ABFR算法和其他算法在电影推荐场景下精确率的优劣,本节在豆瓣电影评论数据集上进行了对比实验,对比算法如下:
(1)基于热度的推荐算法(TopPop):按照电影评分的人数来确定电影的热度,电影评分人数越多则该电影的热度越高,筛选出热度最高的前N部电影推荐给当前用户.
(2)基于用户的推荐算法(UserKNN):寻找与当前用户相似度最高的前k个用户,然后推荐相似用户感兴趣的电影给当前用户.
(3)基于物品的推荐算法(ItemKNN):将与当前用户感兴趣的电影相似的电影推荐给当前用户.
(4)加权正则的矩阵分解方法(WRMF)[18]:通过将用户的隐式反馈行为转化为用户对电影偏好可信度的权重,将用户偏好可信度较高的电影推荐给当前用户.
(5)稀疏线性模型推荐方法(SLIM)[19]:通过以一个稀疏矩阵R作为权重,来给矩阵打分,通过线性的方式学习电影之间的相似度,为用户推荐与其偏好电影相似的电影.
针对上述推荐算法预测结果的精确率和召回率进行实验.在DMSCD数据集上分别进行top5和top10推荐,精确率的实验结果如表3所示,召回率的实验结果如图4所示.
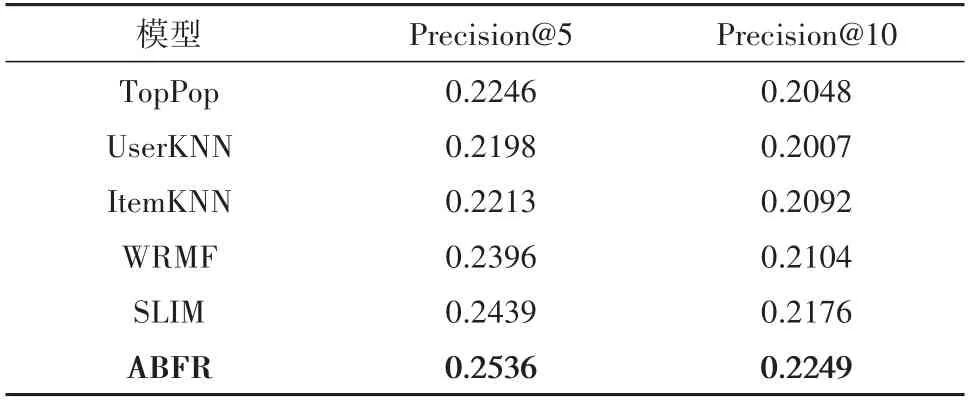
表3 DMSCD数据集上的不同模型精确率对比结果Tab.3 Comparison results of precision of different models on DMSCD dataset
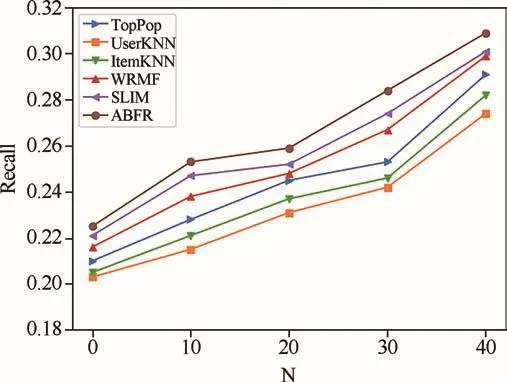
图4 DMSCD数据集上不同模型的召回率Fig.4 Recall of different models on DMSCD dataset
从表3可知,本文所提出的ABFR算法相较于基线算法:基于用户的推荐算法和基于物品的推荐算法在精确率上有显著的提升.这是因为ABFR算法能够精准地捕捉到用户对电影评论文本中的情感倾向,将情感倾向二值化代入到用户对电影的评分矩阵中,有效解决了评分矩阵中数据稀疏性的问题,从而能够更加精确地进行推荐.由于ABFR算法引入了神经网络来更好地学习语料文本中的信息进而获取词向量之间的语义依赖关系,从而能够更好地融合双向语义关联信息,因此ABFR算法相较于加权正则的矩阵分解方法和稀疏线性模型推荐方法精确率也有所提升.
从图4可知,在DMSCD数据集上进行top10、top20、top30、top40推荐的实验,ABFR算法的召回率指标优于其他推荐模型,证明ABFR算法具有优秀的推荐性能.
5 结论
在可获取用户评论数据的场景下,为了挖掘用户对电影评论信息中的情感倾向,根据用户的情感倾向来为用户推荐感兴趣的电影,本文提出了一个基于ALBERT-BiLSTM模型的推荐算法ABFR.ABFR算法首先利用ALBERT模型对评论短文本语料进行预训练并转化为词向量,然后使用BiLSTM网络来挖掘词向量之间的语义依赖关系并分析语料信息的情感倾向,将分析出的情感以评分的形式代入到用户-物品评分矩阵中,最后利用相似度算法来为当前用户推荐感兴趣的电影.实验结果表明:本文提出的ABFR算法能够有效地利用评论信息判断用户的情感倾向,更加准确地挖掘用户的兴趣点.ABFR算法在精确率和召回率两个评价指标上都明显优于其他推荐方法.未来还会考虑通过分析用户的社交关系来强化相似度的计算,期望能够进一步提升推荐算法的性能.
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
