
基于文本挖掘的西部城市旅游满意度研究
——以携程西安和成都为例
2022-05-06 13:19刘娅娅
科技和产业 2022年4期
李 爽, 张 政, 刘娅娅
(西安财经大学 统计学院, 西安 710100)
随着信息技术的发展和居民生活水平的提高,特别是近年来移动终端设备的普及,全国网民数量进一步增多,形成了旅游市场巨大的潜在消费群体。第48次《中国互联网络发展状况统计报告》显示,中国2021年网民数量为10.11亿,互联网普及率达到71.6%[1]。据前瞻产业研究院数据,截至2019年,全国在线旅游市场交易规模已突破万亿元,用户规模突破4亿人,其中携程月活跃用户规模居榜首[2]。
成都和西安都位于西部地区,均是传统旅游城市。2018年,西安市旅游总收入达到2 013.2亿元,同比增长超过50%;成都市旅游总收入达到3 712.6亿元,同比增长22.4%。作为西部旅游强市,对两市旅游业的分析研究具有重要意义。翟若琳[3]采用DEA模型对于西安城市旅游效率进行了对比分析;欧启均等[4]以西安市为例研究了城市旅游客流的网络信息驱动特征变化问题;徐茜[5]以成都为例研究了文创与旅游融合的路径问题。鲜有文献对西安、成都两市的旅游满意度进行比较研究。
用户满意度指消费者对产品购买后的使用感知效果与期望进行对比后所产生的情绪状态。以往学者已对用户满意度做了很多工作[6],但通过对文献的梳理发现,研究者通常采用问卷调查[7-10]来收集数据,但问卷调查耗费人力物力较多,且样本数据有限[11],局限性较大。事实上,在线评论中蕴含着用户的情感倾向,若基于线上评论探索满意度,则可补充传统问卷调查获取数据的不足。近年来,诸多学者在多个领域运用了文本挖掘的方法研究用户满意度。蔡珺哲[12]采用文本挖掘方法研究中国当前社交媒体的用户情感问题;张琰等[13]基于酒店评论研究了不同档次酒店顾客满意度的因素对比;黎晶[14]基于决策树方法对移动互联网服务进行满意度研究;赵杨等[15]利用CNN-SVM方法最终构建起评论满意度得分;郭立秀[16]运用了特征词匹配方法,精细化研究了生鲜电商满意度问题;王媛等[17]基于文本挖掘技术收集博客中的文本数据,据此研究了游客对古镇旅游形象的感知问题;刘阳[18]通过文本挖掘研究了哪些因素影响了在线旅游产品的销量因素;范宁[19]依托在线旅游网站评论,研究了消费者对于民宿满意度特征;刘婷[20]使用IPA分析法对提高三亚旅游购物满意水平进行研究。
关于文本的情感分析,Cambria等指出情感分析通过判断评论的情感极性和强度[21],在一定程度上能够反映旅客的满意度。情感分析方法一般为两种,一种是情感词典法。Zhang等[22]定义了相关领域的情感词典,并按照词语倾向性建立了情感倾向分析模型;丁蔚[23]将情感词典法与机器学习方法相结合对评论进行分类,提高了预测的准确性和泛用性;崔志刚[24]将情感分析方法用于分析电商用户的喜好;刘楠[25]构建了多元词特征分析法对微博短文本进行分类,并进行情感倾向的研究。另一种是机器学习方法。Li等[26]对评论的情感倾向进行聚类分析,最终统计了正面、中性、负面评论的占比;徐军等[27]利用朴素贝叶斯和最大熵两种方法研究情感倾向分类,并比较两者间最高准确率;徐琳宏[28]建立文本倾向识别机制,并使用SVM模型进行文本感情倾向分析。张英[29]基于深度神经网络研究了微博短文本分类和情感预测问题。鲜有文献构建适用于旅游领域的情感词典,因此现有研究对旅游评论的情感分析存在偏差。
基于上述讨论,利用携程网西安和成都的旅游在线评论数据,通过词云图、社会网络语义图、LDA主题模型挖掘旅游满意度影响因素,构建了城市旅游满意度评价体系。进一步构建适用于研究的情感词典,计算指标情感值,结合层次分析法确定指标权重,据此计算游客的满意度。所得的指标体系不仅可用于西安、成都两地,也可用于其他城市的旅游满意度研究,具有一定的通用性。
1 基于文本挖掘的游客满意度指标体系构建
1.1 数据来源
爬取2016年1月1日至2019年3月1日来自携程旅游网西安和成都页面中的跟团游项目的在线评论数据。西安市实际爬取28 268条数据,经过预处理得到18 452条有效数据。成都市实际爬取22 450条数据,经过预处理得到14 568条有效数据。
1.2 游客满意度影响因素挖掘
1.2.1 基于词云图和语义图的影响因素初探
由于采集到的数据量较大,过滤掉部分与研究无关的词语,绘制游客满意度影响因素词云图,如图1所示。图字体的颜色和大小反映了词频高低和重要程度。综合来看,两市在线旅游评论反映出的主题有很多相似之处,占两市词云图中显示面积最大的词语均是“行程”和“安排”,这两词基本可视为同义词,由于行程路线安排会反映在旅行的价格上,而这些因素又很大程度上决定了游玩的综合体验,因此游客的关注度最高。词云图中也显示出了“峨眉山”“大雁塔”等景点名称,表明游客对这些知名景点产生了深刻印象,游客可能正是为了此景点而来的。此外,从词云图中也可以看出“导游”“讲解”也是游客关注的重点。最后,成都的词云图中提及了旅游线路购物方面的问题,这点是西安词云图不曾涉及之处。
词云图只能大致看出游客们关注哪些影响因素,但是很难发现之间的关联,因此可利用网络语义图,进一步分析旅游评论的特征。采用ROST CM 6软件分别对两市评论进行语义网络分析,得出的部分结果如图2、图3所示。

图1 两市满意度影响因素的词云图对比
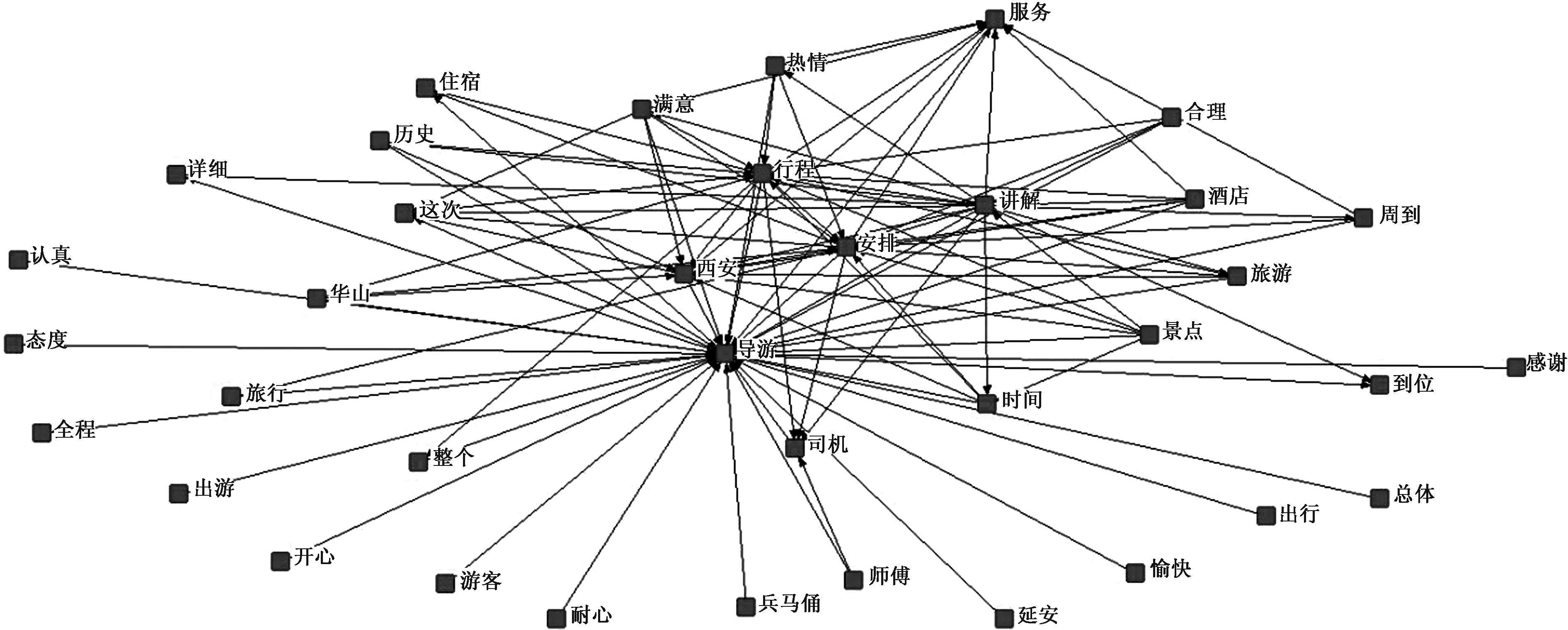
图2 西安旅游影响因素网络语义图

图3 成都旅游影响因素网络语义图
从两城网络语义图总体来看,两城的影响因素较为相似,“行程”“安排”“讲解”“导游”“服务”这几个词作为中心节点连接了其他节点。进一步分析可知,以“导游”为节点的密切相连的评价词有“详细”“认真”“满意”等词,说明游客对于导游总体上的评价是相对正面的。另外,导游的“态度”也是游客关注的一个要点。这些可以归纳为游客对于导游的服务非常敏感。以“行程”“安排”为节点的,与周边的“住宿”“时间”等形成语义关系,行程一般是提前在旅游网站上预定好的线路行程,而实际旅游时由于当地情况变化,临时安排也成为决定游客体验的一个重要因素。此外,这几个节点也都指向了“司机”这个节点,可见司机情况也影响了游客在旅途中的感受。在现实情况中,跟团游的游客每天可能会有较长的时间在车辆中,司机也会相当程度上影响游客的体验。以“讲解”为节点的,与“景点”“热情”形成了语义关系,说明游客的旅游体验中,在景点能否受到好的服务也是很重要的一点。
综合以上分析,得出旅游满意度的影响因素大致包括“行程”“安排”“司机”“服务”“导游讲解”等。
1.2.2 基于LDA主题模型的影响因素挖掘
上述两种方法对两市旅游评论的特征进行了初步研究,下面选用LDA主题模型进一步分析。在LDA主题模型中,每一句评论可视为一个文档,找出文档的主题,通过观察主题中的特征词,最终归纳出影响旅游评论的特征因素。LDA的数学模型过程描述如下:
词是组成语料的基本要素,词库中的词汇量视为V,那么可以将该词表示成一个V维向量,这样第v个词出现时,即为向量w的第v个分量wv=1,其他分量wu=0(v≠u)。
文档是由N个词组成的序列,可为d=(w1,w2,…,wN),其中wn是文档中的第n个词。
文档集是M个文档组成的集合,可为D=(d1,d2,…,dM),生成的过程为。
选择N~Possion(ξ)和θ~Dir(α)。
在文档中生成第n个词wn:
依据多项式分布zn~Mutinomial(θ)抽样所得的主题zn;
根据概率p(wn|zn)抽样得到具体的词wn。
给定参数α和参数β,LDA生成文档d,N个主题Z,N个词语w的联合概率分布为
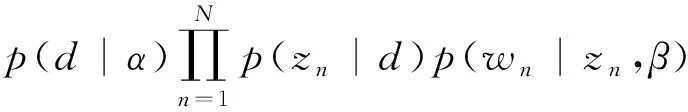
(1)
通过期望最大化算法求最大似然式(2)从而估计α和β的参数值,进而确定模型
(2)
LDA主题建模的主要问题在于主题数的确定,可用式(3)困惑度来判断,其判别标准为在合理数量范围内选择困惑度小的主题数为最优,困惑度的计算公式为
(3)
式中:p(w)为测试集中出现的每一个词的概率;N为测试集中出现的所有词的个数。
分别将预处理好的数据输入LDA主题模型,此处使用Python机器学习工具包scikit-learn进行训练,选择GIbbs Sampling估计模型的后验参数。关于主题数目,首先根据词云图和语义图可大致确定主题数目的范围为3~8,经过人工测试并分析困惑度发现,当主题数设为6个时,模型的困惑度较低,特征词拥有较好的分布,主题的区分度比较合适,模型的涵盖度较高。
综合LDA主题模型来看,景点体验、行程安排、酒店住宿、导游服务、导游讲解、地区旅游特质、司机情况这7种特征基本涵盖了游客对西安和成都旅游方面的大部分特征,因此可以选这7个因素作为特征因素作为进一步分析满意度的依据。地区旅游特质指的是某地的旅游特色。
1.2.3 满意度评价体系构建
1.2.3.1 词性标注
词性标注是对句中词汇确定词性,词性成分主要包括名词、动词和形容词等,为下一步确定特征对评论精细分类做准备。采用Python中的jieba模块对两市评论进行分词标注。
1.2.3.2 特征情感词对的匹配
用分词和词性标注的结果,结合特征词和情感词对的抽取,总结特征词与情感词共同出现的词法模板,根据这些模板匹配评论数据,从而得到所有的关系对。匹配好的词对数量和示例见表1。
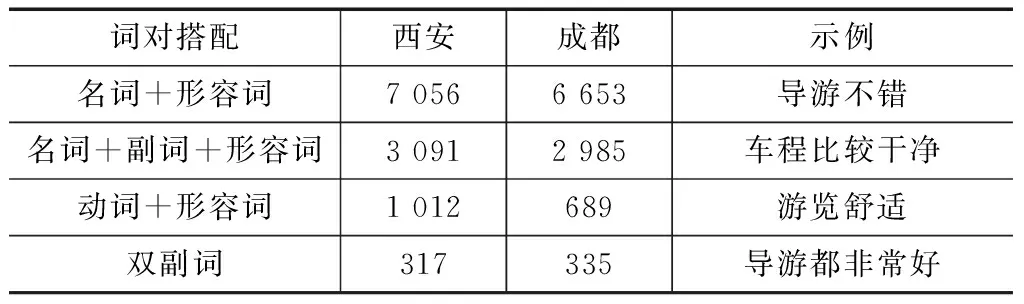
表1 西安-成都两市评论各特征词对数量 单位:对
匹配之后进行特征情感词对的抽取。选用谷歌开发的Word2vec模型对已经确定的特征词对进行扩充,将这些词输入CBOW模型进行训练,最终计算出各个词汇的相似度,使用K-means方法对词汇进行聚类。将指标“景点”“行程安排”“酒店住宿”“导游服务”“导游讲解”“西安旅游特征”“成都旅游特征”“司机情况”使用上述模型,分别得出7个特征词对应的相似度最高的前10个词汇,得出与这7个特征方面关系相近的词汇,见表2。
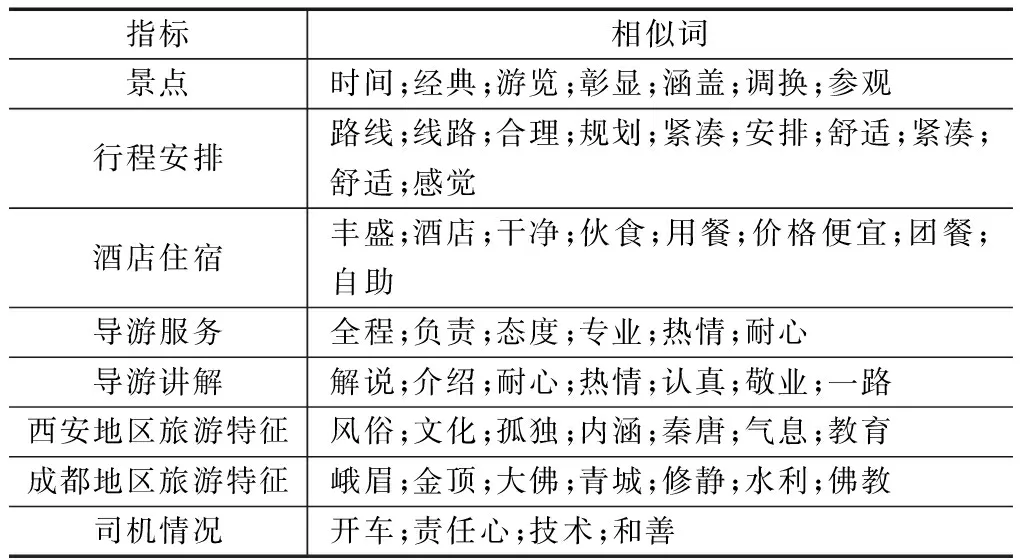
表2 游客满意度指标和对应的相似词
在得出特征词相似词的集合后,下一步进行筛选特征情感词对操作,首先找出特定词性组合的词对,再进一步使用正则表达式方法找出含有特征词的词对集合,最后删去一些明显无意义和错误的词对,完成筛选。具体流程如图4所示。
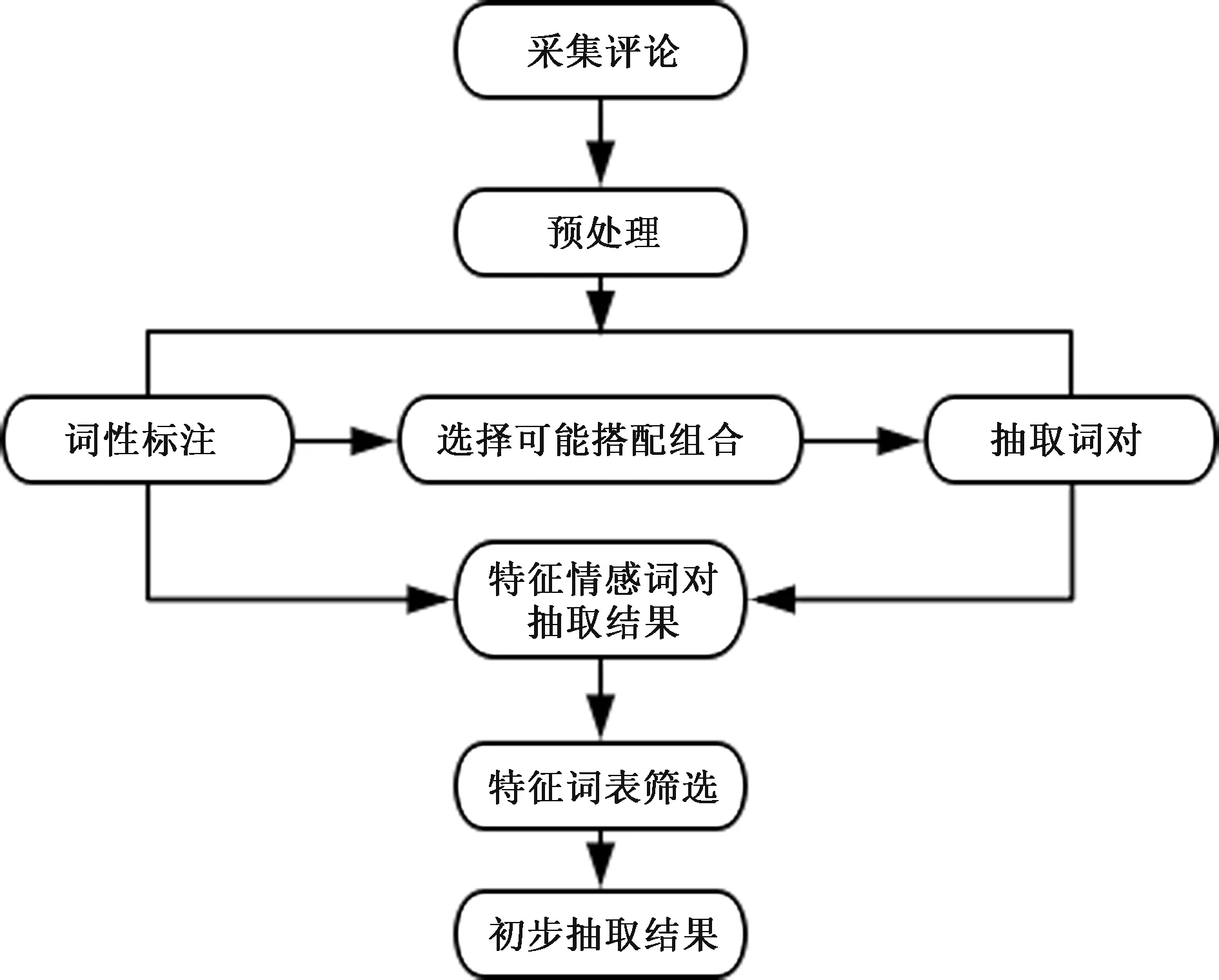
图4 词对抽取流程图
抽取的词对示例:[旅游景点/n, 不错/a;景区/n];[最好/a 景点/n, 完全/a];[服务态度/n, 好/a 景点/n, 壮观/a];[整体/n, 不错/a 路线/n, 不错/a 导游/n, 不错/a]。
2 游客满意度的度量
2.1 评论情感值的计算
2.1.1 构建情感词库
情感词典的含义是指表达人们日常语言中含有情感倾向词语所构成的词典,表示情感倾向的词语主要包括消极词和积极词。所使用的情感词典是知网情感词典和Boson情感词典。并将获取到的在线旅游评论中的网络词相关情感词也添加进去,如“太爽了”“炒鸡棒”“炫酷”等词。添加的方法仍然是将词缀为/a的词用正则表达式的方法筛选出来,再人工筛选出其中能表示情感倾向的网络词语。
将上述相关网络词汇添加完毕后,就得到了可以使用的综合情感词汇表,此外还需要建立副词词表,因为“很”“非常”以及“有点”“稍微”“太”这些程度副词中蕴含了对于情感的暗中褒贬,隐藏了一定的情绪意义。当这些程度副词之前或之后跟随情感词时,这个词组表达的情感含义就将会和单独情感词表达的词义产生一定程度上的偏移。因此,在使用基于词典方法的情感分析时,需要将这些程度副词也加以挑选出并赋值。这里的副词词表一部分源于知网程度副词词表,一部分人工添加,这些程度副词分为5个等级,其中权重大小参考了已有的研究成果[28],见表3。

表3 副词权重
否定词在性质上与程度副词的性质类似,但不同的是,否定词会直接改变情感词的原本情感指向。所使用的否定词词表是从互联网上获得的,再添加适合在线旅游评论的否定词。新添加的否定词的分数以-1作为权值,共计68个。
2.1.2 短句情感值的计算
利用构建的情感词库对短句的特征词进行情感计算。通过确定特征值的位置,进一步确定特征词位置附近的相关词汇,进而综合计算出短句的情感得分。具体分以下几种情况,利用Python编程分别计算:
1)短句中不含情感词。识别出短句有特征词但没有情感词,则该短句的情感值为0,可以将其视为中性句子。
2)短句中只包含情感词。即特征词与情感词组合,计算方法是依据情感词词表的相应权值,依次进行计算即可得出句子的情感值。
3)短句中包含了程度副词但不含否定词。计算方法为依据情感词表和副词词表的相应权重,综合计算情感值。
4)短句中含有否定词。共两种情况,一是特征词+否定词+情感词,二是特征词+否定词+副词+情感词。其计算公式为
(4)
式中:n代表副词个数;m代表否定词个数;g代表否定词权值的选定,否定词为奇数时,为-1,为偶数则为1,再根据构建的情感词表、副词词表相应的权重,计算短句情感值。
2.1.3 西安-成都两市各指标评论情感分布
根据评论情感值的正负情况可以将评论分为正面情感和负面情感,两市各特征的情感分布情况如图5所示。
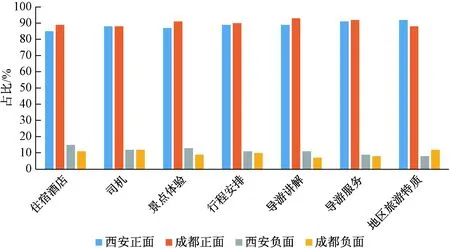
图5 携程西安-成都旅游评论情感极性对比
由图5可以看出,两市所有特征的正面情感占比均在85%以上,在地区旅游特质方面,西安正面情感比例高于成都4个百分点;在司机服务方面,两市持平,占比为88%,相对于其他特征来说评价不算好;在其他5个方面,成都正面情感占比均高于西安。西安市的7个特征中, 地区旅游特质的正面评论占比最高,而游客有关住宿酒店的正面情感占比最低;成都市的导游讲解与服务特征的正面情感占比最高,地区旅游特质和司机服务特征正面情感占比最低。
2.2 游客满意度指标体系构建与计算
2.2.1 确定指标权重
采用层次分析法计算各个评价指标的权重。层次分析法的判断矩阵构造并未采用传统的专家打分法,而是结合西安及成都客观数据,依据两指标的比例差,将其范围与标度对应起来。具体占比见表4。
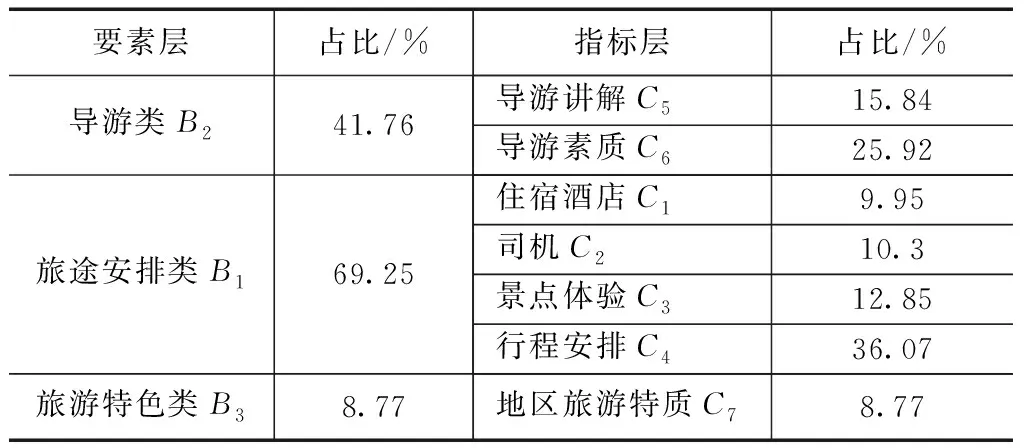
表4 范围标度比例差
根据表4得出的各指标之间的比例,构造判断矩阵并计算各指标的权重向量。判断矩阵采用Saaty的1~9级标度法,该法对比时采用相对尺度,以尽可能减少性质不同因素相互比较的困难,提高准确度。表4中计算出来的最大比例差为0.604 8,共有9级标度,因此以0.06为单位划分标度。
在使用层次分析法计算权重的过程中,需要对判断矩阵进行层次排序以及检验一致性。一致性检验是通过计算一致性指数CI与平均随机一致性指标RI的比值CR来检验,CI的公式为
(5)
(6)
式中:λmax为判断矩阵的最大特征根;RI则可以根据矩阵的阶数查表得出。当CR<0.1时,判断矩阵的一致性是可以接受的,若CR>0.1,则需要对矩阵进行修正。
根据计算可得,要素层CR=0.086,旅途安排类CR=0.002,导游类特色CR=0,皆符合一致性检验要求。整合上述各因素权重,计算综合权重,结果见表5。

表5 指标体系综合权重
可以看出在指标评价体系中,旅途安排类因素在整体评价中相对重要,其次是导游类因素,而旅游特色因素虽受到游客关注但占比不高,在指标层的因素中,行程安排和导游服务最受游客关注。
2.2.2 西安-成都两市旅游满意度的计算
依据已经得出的权重和特征词情感值,游客的满意度计算公式为
C=∑Wi∑WjXj
(7)
式中:C代表游客满意度;Wi代表要素层的权重;Wj代表指标层的权重;Xj代表各个特征词的综合情感值。
根据式(7),计算得到各个指标下的满意度,最终得到两市的综合满意度见表6。西安的综合满意度为11.3,成都为13.207,表明总体上来说游客对成都的旅游满意度高于西安1.907。西安在景点体验和旅游特色方面的满意度高于成都,主要是其拥有悠久的历史文化古迹,旅游特色满意度高;导游服务、导游讲解、形成安排和司机服务方面,成都的满意度高于西安。特别的,在行程安排方面成都的满意度高于西安1.175,表明成都在行程安排方面比西安做得好。

表6 两城市综合满意度
3 结论与讨论
在线评论数据反映了游客的游览体验和情感,既可以为潜在消费者提供旅游借鉴,也可以为城市改进旅游服务提供信息反馈。本文结合词云图、网络语义图和LDA主题模型挖掘游客满意度影响因素,并根据同义词聚合方法,提取7项特征作为评价指标。进一步,基于情感分析和层次分析法计算出两市各旅游评价特征的权重和得分,构建满意度指标评价体系。结果显示,满意度影响因素中最重要的是行程安排和导游,成都市综合旅游满意度略高于西安市。
筛选出的7项评价指标不仅适于西安成都两市,也基本涵盖了国内旅游体验的各个方面,具有一定的普遍性。从基于文本挖掘的旅游满意度评价体系构建过程与传统基于问卷调查方式对比来看,后者一般是事前已经设计好评价指标体系,然后结合评价指标设置问卷问题,而前者则需要首先挖掘数据确定特征指标,并结合情感分析方法,构建评价体系。总的来说,基于在线评论的旅游满意度分析方法样本的代表性较为充足,可以节省大量人力、物力成本。当然这并不意味问卷调查方法已不重要,由于在线评论没有显示评价者年龄、职业等信息,这正好可结合问卷调查等方法来弥补。因此,探索多源数据的融合技术,是下一步值得研究的问题。
猜你喜欢
音乐天地(音乐创作版)(2022年1期)2022-04-26
音乐天地(音乐创作版)(2022年1期)2022-04-26
奇妙博物馆(2021年2期)2021-03-18
娃娃画报(2019年8期)2019-08-05
当代陕西(2019年6期)2019-04-17
东坡赤壁诗词(2017年3期)2017-07-05
现代青年·精英版(2016年10期)2017-04-04
党的生活(黑龙江)(2016年10期)2016-10-17
快乐作文·低年级(2015年11期)2015-12-08
高中生学习·高三版(2014年3期)2014-04-29
