
引入高斯掩码自注意力模块的YOLOv3目标检测方法
2022-04-29 01:34:56孔雅洁
液晶与显示 2022年4期
孔雅洁,张 叶
(1. 中国科学院 长春光学精密机械与物理研究所 应用光学国家重点实验室,吉林 长春 130033;2. 中国科学院大学,北京 100049)
1 引 言
随着科技不断进步和社会快速发展,居民生活水平逐渐提高,汽车成为家庭出行的重要交通工具。政府报告资料显示,2016~2020 年间,中国汽车年销量均在2 500 万辆以上,全国地区汽车保有量也高达2.5 亿辆[1]。汽车的普及给人民生活带来极大便利的同时,也给道路交通运输带来巨大压力,不仅导致交通拥堵,而且增大事故隐患。因此,辅助驾驶、自动驾驶等智能系统的研究应用得到政府、企业、研究机构的广泛关注。驾驶员借助智能驾驶系统,可以及时发现行车危险,有效提升驾驶安全性,降低交通事故发生的几率。在各类智能驾驶系统中,感知环境是第一步,如何快速精准地感知、检测、测量行车过程中出现的各类目标,一直是研究的热点。车载摄像头的拍摄可以获取大量行车图像,而图像数据具有采集成本低、信息丰富等特点,可以提取诸多有用的环境信息以指导驾驶,比如识别前方车辆、行人等。
目标检测作为视觉感知识别的重要任务之一,吸引了许多研究人员的注意,大量的检测算法得到研究和应用。传统的目标检测通过人工提取图像区域特征,并用预先设定的分类器对其进行分类来达到检测的目的。特征描述准确度对于检测结果影响很大,而且结合多个低级图像特征设计的复杂的分类器难以获得很好的性能。随着深度学习的快速发展,算法模型可以自动学习语义,提取图像的深层特征,检测速度和效果都得到很大的提高,已成为目标检测领域的主流方法。基于深度学习的目标检测算法主要分为两类:一类是基于区域选取的二阶段目标检测,算法被分为两步,首先从图像中生成最有可能包含目标的子区域,然后对子区域做图像分类并生成最终的物体边框;另一类是基于回归的一阶段目标检测,可以直接对物体进行分类,生成类别概率和位置坐标。一阶段算法基于卷积特征图同时计算边界框回归和目标分类问题,避免了计算成本很高的子区域生成过程,因此,相较于二阶段算法,一阶段算法具有检测速度快的优势,更适用于辅助驾驶、自动驾驶等对检测速度要求高的应用场景。一阶段算法的典型代表是YOLO 系列算法。
卷积神经网络(Convolutional Neural Network,CNN)作为计算机视觉(Computer Vision,CV)领域的主流深度学习模型,取得了很好的效果。在图像问题中,卷积计算具有平移等价性、局部性等天然优势,但也存在感受野固定且有限这一缺陷,通常需要堆叠卷积层来获取更大的感受 野。近 两 年 来,Transformer[2]开 始 在 计 算 机 视觉领域大放异彩,被广泛应用于图像分类、目标检测、语义分割以及图像生成等任务当中,其核心自注意力(Self-attention)机制通过在输入向量之间相互执行注意力操作来提取特征,可以获得全局特征关系,通过全局范围的依赖关系来抑制无关信息、突出有用区域,以提高检测的准确性,有效弥补了卷积感受野固定的缺陷。
因此,针对辅助驾驶系统中车辆、行人的目标检测任务,本文在YOLOv3 算法模型的基础之上,引入自注意力机制,并对加入的模块进行高斯掩码优化,提出了YOLOv3-GMSA 目标检测方法。此外,为了对方法进行评估验证,我们在MS COCO 2017 数 据 集 上 对YOLOv3-GMSA 方法进行了训练和评估,结果表明该方法在保证检测速度的同时有效提高了检测效果。
2 相关工作
2.1 目标检测
目标检测是CV 领域的一个重要研究方向,其任务是在图像或视频中找出感兴趣的物体,同时检测出它们的位置和大小。不同于图像分类任务,目标检测不仅要解决分类问题,还需要解决定位问题。传统的目标检测主要关注图像处理、特征提取算法,但是基于手工提取的特征无法适应复杂多变的现实场景,准确率不高。直到2012 年,CNN 的兴起将目标检测相关研究推向了新的台阶。
2.1.1 二阶段目标检测算法
二阶段算法将目标检测过程划分为两个步骤,首先根据算法产生一系列候选框,然后根据深度神经网络对候选框进行分类和回归。最具代表性二阶段目标检测算法是R-CNN[3],通过选择性搜索算法从一组候选框中选择可能出现的对象框,然后将对象框中的图像处理后送入CNN提取特征,最后将提取的特征送入分类器进行预测。R-CNN 在VOC-07 数据集上取得了质的飞跃,平均精度由传统算法的33.7% 提高到58.5%。针对R-CNN 训练流程复杂、存储空间占用大等不足,Girshick 等提出具有ROI 池化层并且利用Softmax 和线性回归同时返回分类结果和边界框的Fast R-CNN[4],该网络在VOC-07 数据集上将检测精度提高到70.0%,检测速度也得到了很大的提高。由于选择性搜索算法寻找感兴趣区域运算速度慢,Ren 等提出了Faster RCNN[5]模型,创造性地采用卷积网络产生候选框,极大提升了候选检测框的生成速度。2017 年,Lin 等[6]在Faster R-CNN 的基础上进一步提出特征金字塔网络(Feature Pyramid Networks,FPN)结构,有效解决了深层特征图缺乏空间信息影响定位精度的问题。总的来说,二阶段目标检测器可以达到与人类相当甚至更好的精度性能,但是大量的计算阻碍了其在实时系统中的应用。
2.1.2 一阶段目标检测算法
一阶段算法不需要产生候选框,直接将目标框定位问题转化为回归问题处理,仅使用一个CNN 网络就可以预测不同目标的类别概率和边界框,因此具有更快的检测速度。YOLO[7]作为第一个一阶段目标检测算法,将图像分割为S×S个网格,然后为每个网格预测边界框并同时给出类别概率,在VOC-07 数据集上实现了155 FPS的实时性能,但同时也存在检测精度相对较低的缺点。针对YOLO 小目标检测精度偏低的问题,Liu 等[8]提出了采用先验框和多尺度特征图结合的SSD 多框预测算法,不同的分支可以检测不同尺度的目标。随后,YOLOv2[9]通过引入新的特征提取网络Darknet-19、批归一化、卷积加先验框预测和多尺度训练等多种改进策略,有效解决YOLO 检测精度不足的问题。YOLOv3[10-12]则借鉴各类研究成果进一步优化网络,采用了先进的Darknet-53 残差网络和多分支检测结构,可以有效检测不同尺寸的对象。总的来说,一阶段目标检测器具有很快的运行速度,能够满足实时系统的要求,但预测精度相对二阶段算法较低。
2.2 Transformer 与自注意力机制
2017 年,Google 团队在自然语言处理(Natural language processing,NLP)领域提出了经典算法Transformer,该模型抛弃了传统的CNN、RNN,网络结构由自注意力机制组成,不仅可以并行化训练,而且能够包含全局信息,基于Transformer 的BERT[13]词向量生成模型在NLP的11 项测试中取得了最佳成绩。Transformer 在NLP 中取得的耀眼成绩引起了AI 研究人员的浓厚兴趣,许多相关应用也出现在CV 领域中,并取得了很好的效果。
受Transformer 中的自注意力机制启发,Wang 等[14]提出了Non-local 神经网络,利用全局图像之间的依赖关系为特征进行加权。尽管自注意力机制能够捕捉图像的全局信息,但是需要占用较多的显卡资源,因此Huang 等[15]提出了交叉注意力模块,仅在纵横交错的路径上执行注意力操作,有效限制了对存储和计算资源的占用。Yi 等通过对空间特征关系进行建模提出了ASSD[16]检测器,对全局特征信息进行可靠引导,在精度上实现了很大的提升,但是这些方法都忽略了局部信息的重要影响,在检测精度上仍无法取得满意效果。ViT[17]是第一个在大规模视觉数据集上完全用Transformer 取代标准卷积操作的深度学习模型,其将图像划分成固定大小的块,通过线性变换得到块向量,随后送入Transformer 进行特征提取并分类,模型在大规模数据集上做预训练随后在目标数据集进行微调,在ImageNet 数据集上可以得到CNN 方法相当的成绩,而且随着数据集的扩大,ViT 将发挥更大的优势。Facebook AI 团队首次将Transformer 应用到目标检测任务,提出了DERT[18]模型,取代了现有模型中需要手工设计的工作,如非极大值抑制和锚框生成等,在准确率和运行时间上能够取得与Faster R-CNN 相当的成绩。
总的来说,自注意力机制可以有效捕获图像的全局特征关系,弥补CNN 感受野受限的不足,设计过程中也需要注意显卡资源占用情况,同时还需要考虑全局特征和局部特征进行融合时的权重。
3 引入GSMA 模块的模型设计
YOLOv3 是对YOLO、YOLOv2 进一步优化后提出的一阶段目标检测深度学习模型,只需要一次端到端计算就可以得到目标的类别概率和边界框,具有运算速度快的特点,适用于实时场景下的目标检测任务。考虑到随着特征层的增加,图像的上下文信息和全局关系会逐渐减少,影响了模型的检测精度,因此,本文在YOLOv3的网络结构中引入自注意力机制,并在自注意力模块中加入高斯掩码操作,使模型在捕获全局特征关系的同时仍然重视局部特征的影响,以取得更好的检测效果。
3.1 网络模型
YOLOv3 的模型架构主要分为两个部分:Darknet-53 和多分支预测网络。相比于YOLOv2 的Darknet-19,模型采用了具有残差单元的Darknet-53 特征提取网络,构建的网络层次更深。另外,为了使多种尺度下的目标都具有较好的检测效果,模型采用具有FPN 架构的多分支检测结构,采用3 个尺度的特征图分别对大、中、小3 类目标进行检测。
3.1.1 Darknet-53 与多分支预测网络
为了达到更好的分类效果,YOLOv3 的作者借鉴残差网络的思想,设计了Darknet-53 特征提取网络。Darknet-53 网络是一个全卷积网络,包含23 层残差单元(Residual Unit),具有非常多的残差跳层连接,其结构见图1,左上是网络的结构,下方的虚线框展示了各模块的具体结构,模块中的数字表示其重复的次数。为了缓解池化操作带来的梯度负面效果,网络用卷积层替代池化层,通过调整卷积的步长为2 实现降采样。

图1 YOLOv3-GMSA 网络模型架构Fig.1 Architecture of YOLOv3-GMSA network
多分支预测网络构建3 个预测分支,其结构如图2 所示。当输入图片大小为640×640 时,3 个尺度的特征图大小见表1,缩小的倍数分别为32,16,8。特征图尺寸越小,聚合的信息范围就越大,对大目标检测越有利;反之,特征图尺寸越大,保留的局部细节信息就越多,对小目标检测越有用。为了在大尺寸特征图中保留小尺寸特征图包含的更高层语义信息,FPN 结构采用了上采样和融合的做法,将较小尺寸特征图上采样至较大尺寸,然后与较大尺寸特征图进行拼接融合。
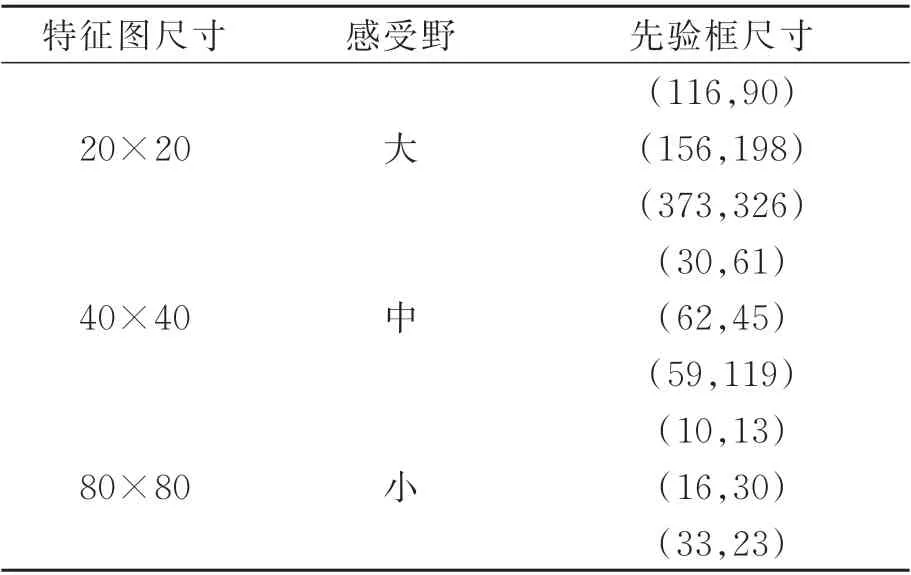
表1 图片大小为640×640 时特征图尺寸和先验框尺寸Tab.1 Feature map size and prior frame size with picture size of 640×640
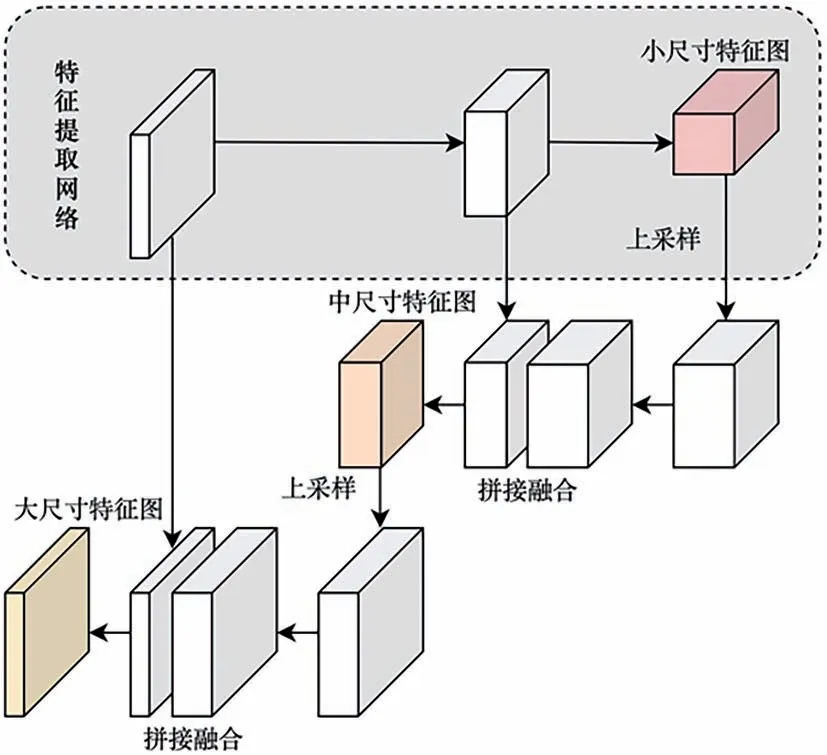
图2 特征金字塔结构的多尺度特征融合Fig.2 Multi-scale feature fusion of feature pyramid network
3.1.2 边界框预测
不同于二阶段算法需要生成候选框,YOLO系列算法将图像分割为S×S个网格,划分的网格对应特征图的尺寸。在各检测分支中,YOLOv3 对目标采用了K-means 聚类,每个分支设置3 个先验框,先验框尺寸如表1 所示。模型采用全卷积的网络结构,最后一层卷积输出的卷积核个数是3×(N+4+1),对应3 个预测边界框,每个预测边界框包含N个类别概率、4 个边界框位置信息和1 个边界框的置信率。针对MS COCO 数据集的80 个类别,最后一层卷积的卷积核个数是255。
不同于YOLO 采用Softmax 计算类别概率并用最大概率的标签表示边界框内的目标,YOLOv3 可以实现对检测目标的多标签分类,方法是对先验框中的图像采用二元逻辑回归(Logistic Regression),在每一类别上计算是该类别的概率,并设定阈值对多标签进行预测。
3.2 高斯掩码自注意力模块
为了增强模型对全局特征关系的捕捉能力,本文引入Transformer 的自注意力机制,在多分支检测网络的出口附近嵌入高斯掩码自注意力模块,如图1 所示。该模块分别对大、中、小3 种尺寸的特征图进行自注意力操作,让特征图中包含更多的大范围信息,提高算法的检测精度。
3.2.1 自注意力机制
注意力(Attention)机制[19]最早由Bengio 等在2014 年提出,其思想就是将有限的注意力集中到重点信息上。在Transformer 中,进出自注意力结构的输入和输出都是一个向量序列,每个向量都表示一个项,将输入序列对自身进行注意力操作,根据完整的输入序列来聚合全局信息以更新序列的每一个项,可以从全局范围对各项之间的相关性进行建模,例如在自然语言处理中可以评估哪几个词更可能组成一个句子。
图3(a)展示了自注意力基本块的运算结构。对 于 包 含n个 项 的 序 列(x1,x2,…,xn),用X∈Rn×d表示,其中d是每个项的向量长度。自注意力的目标是通过全局上下文对每个项进行编码来捕获n个项的相互关系,其方式是定义3 个可学习的权重矩阵WK、WQ、WV将X转换为查询Q=XWQ、键K=XWK以 及 值V=XWV。自注意力模块的输出由公式(1)给出:
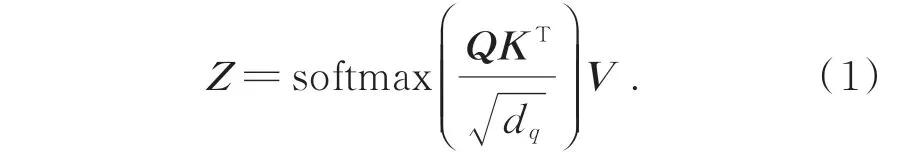
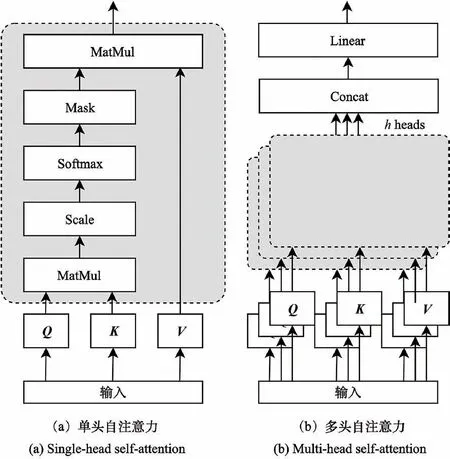
图3 自注意力计算结构示意图Fig.3 Structure of self-attention
对于每一个项,自注意力模块将其查询向量与全部项的键向量做内积,然后用Softmax 激活函数做归一化得到注意力得分,基于注意力得分可以用全部项对每一项进行加权求和得到新的输出。
一个标准的注意力模块会对所有项进行注意力操作,但是对于图像数据而言,局部特征关系的重要性大于全局特征关系,因此,本文对获取的注意力得分进行高斯掩码计算,增加局部信息的比重,削减全局信息的比重。二维高斯分布计算公式如式(2)所示:
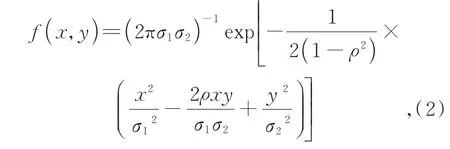
其中参数ρ、σ1、σ2是可学习参数,根据全部项相对某一项的距离计算得到高斯分布的掩码向量,然后与该项的注意力得分向量计算哈达玛积,归一化后得到新的注意力得分。
为了对序列内各项之间的复杂关系进行建模,Transformer 采用了具有多个自注意力基本块的多头自注意力(Multi-head Self-attention)机制,其结构如图3(b)中所示。每一个基本块拥有 自 己 的 权 重 矩 阵{WQi,WKi,WVi},其 中i=0,1,…,h-1,h是包含基本块的个数。将输出[Z0,Z1,…,Zh-1]∈Rn×h·dv拼 接 后 与 权 重 矩 阵W∈Rh·dv×d做内积即可得到最终的输出。
3.2.2 位置嵌入
与卷积神经网络不同,自注意力模块需要将输入的二维特征图转换为一维序列处理,具有排序无关的特性,因此丢失了每一个特征块的位置信息。在缺失位置信息的情况下对特征块之间的语义进行学习将会增大学习成本,所以需要提供位置嵌入(Position Embedding),即特征块的位置编码,编码公式如式(3)所示:

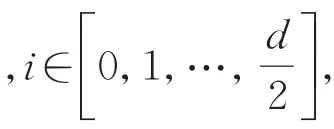
3.2.3 GMSA 模块结构
加入YOLOv3 网络模型的高斯掩码自注意力模块结构如图4 所示。该模块输入与输出均为batchsize×channel×width×height 的 四 维 张量,在进行注意力操作之前,首先将二维特征图转换为一维序列,然后计算其位置嵌入向量并相加。对嵌入位置信息的序列执行带有高斯掩码的多头自注意力操作,获得带有全局信息的序列,将该序列与嵌入位置信息的序列相加并归一化后得到输出序列,最后进行维度调整即可得到输出特征图。
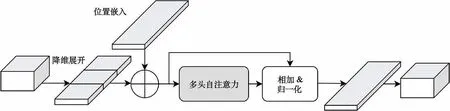
图4 GMSA 模块结构Fig.4 Structure of GMSA module
4 实验结果及分析
为了评估改进的YOLOv3-GMSA 目标检测模型相关性能,本文在公开数据集上进行了一系列实验,并对YOLOv3 和改进后的YOLOv3-GMSA 进行了对比,相关内容介绍如下。
4.1 训练环境及相关参数
训练算法模型使用MS COCO 2017 数据集。该数据集由微软公司制作收集,用于目标检测、分割、图像描述等任务,包含目标检测、关键点检测、实例分割、全景分割和图像描述等5 种标注类型,本文采用目标检测标注对模型进行训练。该公开数据集包含80 个类别,官方共划分成3 个部分,其中训练数据集包含11.8 万多张图片,存储空间占用18 GB;训练验证数据集包含5 千张图片,存储空间占用1 GB;模型测试数据集包含4 万多张图片,存储空间占用6 GB。模型训练过程中,图片尺寸为640×640。训练环境的配置如表2 所示,算法模型采用PyTorch 框架搭建,底层通过CUDA 接口使用显卡资源进行加速。
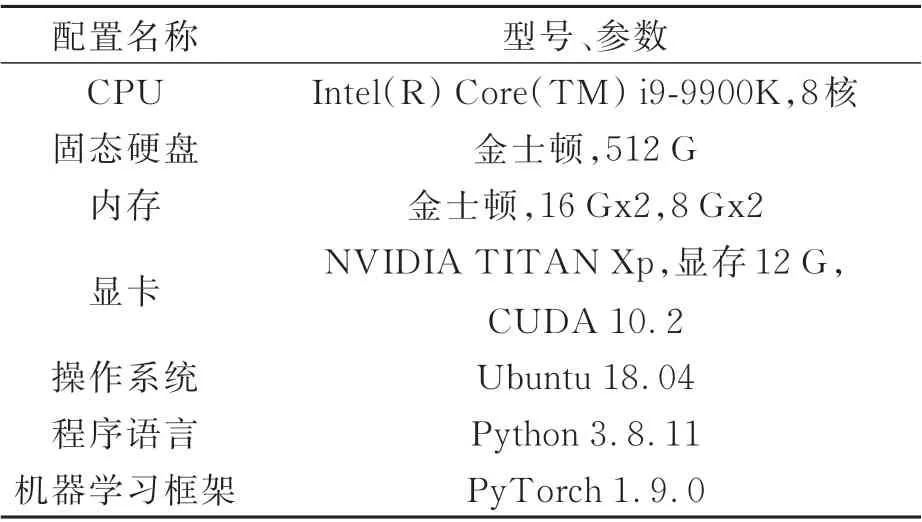
表2 训练环境配置Tab.2 Training environment
训练相关参数如表3 所示,其中批处理大小、迭代次数等参数在官方参考数值之上结合硬件条件及训练情况进行了适当调整,训练的优化算法采用Adam。
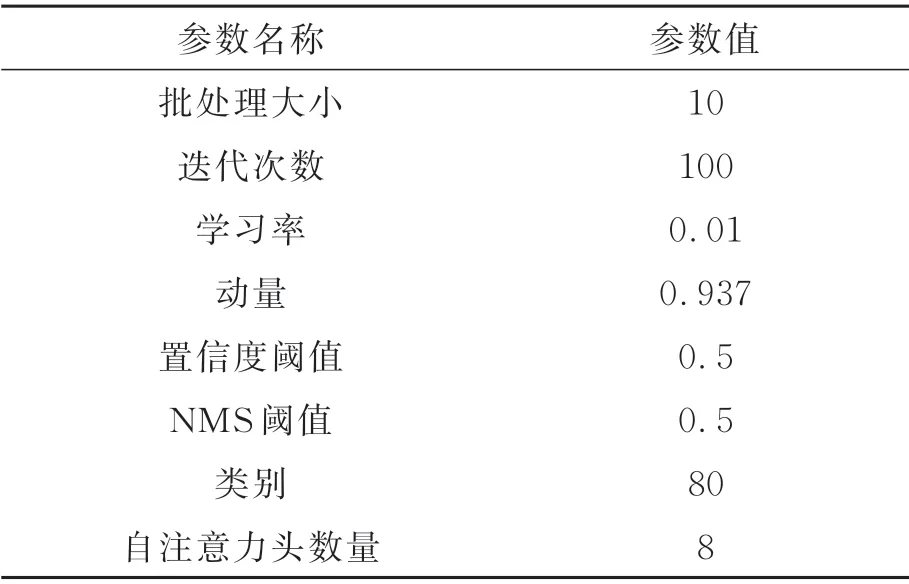
表3 训练参数Tab.3 Training parameters
4.2 实验结果对比分析
本文在MS COCO 2017 数据集上,基于Py-Torch 框架在Ubuntu 18.04 系统和NVIDIA TITAN Xp 显卡之上对改进后的YOLOv3-GMSA算法进行了训练。经过100 轮训练之后,使用模型测试数据集对算法性能进行评估,模型的性能对比如表4 所示。

表4 算法模型性能对比Tab.4 Performance evaluation
从表中可以看出,改进后模型YOLOv3-GMSA 训练的结果mAP@0.5 达到56.88%,精度达到65.31%,召回率达到53.18%。与YOLOv3 相比,mAP@0.5 提高了2.56%,精度提高了3.53%,召回率提高了1.22%,目标检测的效果显著提高。模型的检测效果相比于二阶段检测算法Faster R-CNN 略有不足,但在检测速度方面具有较大的优势。人眼自然帧率是24 FPS,车载视觉传感器常见帧率一般不低于该数值,实际场景中显卡等硬件资源受限,处理速度将进一步下降,二阶段算法难以满足实时性要求。相比于SSD、ASSD 等目标检测算法,改进后模型的检测效果更好,检测速度更快。由于嵌入了高斯掩码自注意力模块,模型复杂度增加,参数增多,检测速度有所下降。改进后的模型检测处理速度达到39.38 FPS,相比于YOLOv3 下降3.88,但仍满足实时检测的要求。通过以上数据分析可以得出,在YOLOv3 网络深层插入高斯掩码自注意力模块以加强网络模型对全局特征关系的捕捉能力,使特征图包含更多的全局信息,更有意义,可以有效提高目标检测的效果。
为了更好地观察YOLOv3-GMSA 改进算法的训练情况,图5 记录了其训练过程中mAP@0.5、mAP@0.5∶0.95、精度以及召回率的趋势曲线。可以看到mAP@0.5、mAP@0.5∶0.95 始终呈上升趋势,在40 轮左右逐渐收敛,精度和召回率则在上下波动中整体呈上升趋势,且精度和召回率的波动趋势相反,这是精度和召回率本身存在一定矛盾所致。

图5 YOLOv3-GMSA 模型训练关键参数曲线Fig.5 Training curve of pivotal parameters in YOLOv3-GMSA
为了更直观地感受改进后算法的检测效果,图6 通过对3 张实际行车环境中拍摄得到的照片进行检测,对比了YOLOv3 和改进后的YOLOv3-GMSA 算法检测效果,检测时置信度阈值设置为0.25。图中第一列是原图,第二列是YOLOv3 的检测结果,第三列是YOLOv3-GMSA 的检测结果。从第一行图中可以看出,YOLOv3 和改进算法均具有良好的检测效果,能够对马路上的行人进行检测定位,相比于YOLOv3,改进后算法具有更高的置信度;第二行图中,YOLOv3 出现明显的识别错误,将巴士的后视镜识别为人,置信度达到0.36,而改进后的算法能够有效捕捉全局信息,融入全局特征关系,没有出现类似的误识别情况;第三行图中,YOLOv3 没有识别出汽车驾驶员以及车后骑自行车的行人,改进后算法则有效标定了这两块地方,置信度达到0.26。

图6 检测结果对比Fig.6 Comparison of detection results
总而言之,YOLOv3-GMSA 改进算法通过引入自注意力机制,增强了模型对全局特征关系的捕捉能力,在牺牲一定检测速度的前提下,可以有效提高目标检测的效果。
5 结 论
针对辅助驾驶的目标检测场景,受计算机视觉领域的Transformer 应用启发,本文在一阶段目标检测算法YOLOv3 的基础之上,嵌入了高斯掩码自注意力模块,加强网络模型对全局特征关系的捕捉能力,以提高检测精度。在公开数据集MS COCO 2017 上训练后的实验结果表明,改进后的模型将mAP@0.5 提高了2.56%,虽然在检测速度上略有损失,但仍能满足实时性需求。该方法为辅助驾驶系统中的目标检测提供了一种新的优化方案,而且通过调整自注意力模块的设计,可以在检测精度和检测速度之间进行有效权衡,以适应不同场景下的检测要求。
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:07:12
数学物理学报(2022年2期)2022-04-26 14:08:04
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
金桥(2018年4期)2018-09-26 02:24:54
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
中国卫生(2014年5期)2014-11-10 02:11:26
