
环境统计与排污许可衔接的工业源排放核算研究
2022-04-27 04:57:50周景博周敬峰董广霞
中国环境监测 2022年2期
周景博,吕 卓,周敬峰,王 鑫,董广霞
1.中国人民大学环境学院,北京 100872 2.中国环境监测总站,国家环境保护监测质量控制重点实验室,北京 100012 3.广西壮族自治区海洋环境监测中心站,广西 北海 536000
污染排放总量估算是环境统计的主要任务。环境统计中工业源调查单位分为重点调查单位和非重点调查单位,在目前的环境统计制度体系中,重点调查单位通过逐个发放和填写报表来获得其污染排放情况,非重点调查单位则缺少统计数据,一般采取“比率估算”的方法,以重点调查单位的排放总量来估算非重点调查单位的排放总量[1]。换言之,工业源排放总量的估算前提是已知重点调查单位的排放总量及其占比。
随着排污许可制度的建立和不断完善,环境统计将面临根据排污许可数据来开展工作的新形势[2-3]。2021年3月1日,《排污许可管理条例》正式施行。根据《控制污染物排放许可制实施方案》,排污许可制应作为固定污染源环境管理的核心制度,衔接整合包括环境统计在内的相关环境管理制度。许可制的实施和数据平台建设将从根本上改变工业源环境统计调查工作的现状,推动工作重点从数据采集转向数据分析和统计监督[4-6]。
在“一证式”管理的新形势下,只有排污许可重点管理单位的排放量数据具有可得性。排污许可实施分类管理,根据排污单位污染物的产生和排放量以及对环境的影响程度等因素实行重点管理、简化管理和登记管理。其中,只有重点管理的排污单位需要申报污染物排放数据;简化管理单位只需记录相关污染物排放浓度等数据,但难以据此准确核算其排放量;登记管理单位则只登记污染物去向、执行标准等信息,更无法核算其排放量。
因此,新形势下工业源排放总量估算将面临的问题是排污许可系统的重点管理排污单位与环境统计的重点调查单位是否具有一致性。如果两者基本相同,则许可数据可以直接替代环境统计数据,环境统计非重点调查单位的总量估算方法不变;如果两者差异较大,则需要论证许可重点单位的污染物排放数据是否能够以及应该如何支持环境统计非重点单位的排放总量估算。对这些问题的解答将是衔接排污许可制度与环境统计报表制度的关键问题。本文基于某市排污许可分类信息,结合第二次全国污染源普查数据分析上述问题,对新形势下如何开展工业源排放总量估算提出建议。
1 研究方法与数据来源
1.1 研究方法
排污许可系统的重点管理排污单位能否替代环境统计的重点调查单位,取决于两者是否具有一致性。这里的一致性包含2层含义,一是两者所涵盖的企业清单相同,二是两者所涵盖的企业具有相同的统计特征。2个体系的数据肯定会存在或多或少的差异,不可能完全相同,因此,一致性指统计意义上的无显著差异。
首先,采用列联表分析按环境统计标准识别的重点单位与按排污许可制度确定的重点单位之间是否具有一致性,即两者所涵盖的企业是否相同。其次,应用描述统计方法比较许可重点单位和非重点单位污染排放量的统计特征,并分析其是否满足环境统计的需求,即检验两者所涵盖的企业特征是否相同。最后,分别对环境统计非重点单位和许可非重点单位进行简单随机抽样,比较相同误差下的理论样本量差别及相同样本量下的总量估算误差,分析许可重点单位的污染物排放数据是否能够支持环境统计非重点单位的排放总量估算。
1.2 数据来源
本文以我国西南地区C市为研究对象,具体研究范围为建材、纺织、造纸和化工4个行业,该市这4个行业排污许可发放基本完成,可以保证数据完整性,4个行业规模有明显差异,可以保证研究结果具有较好的普适性。选择了6类环境管理中的重点污染物,包括大气污染物4类(SO2、NOx、烟粉尘和VOCs)和水污染物2类(COD和氨氮)。最终数据集中包括2类变量(表1):企业基本信息变量(主要包括企业所属行业及其在环境统计和排污许可管理平台上的分类)和污染物排放量(包括6类污染物排放量指标)。
采用第二次全国污染源普查(以下简称二污普)数据来区分和界定环境统计工业源重点调查单位和非重点调查单位。《环境统计报表制度》中界定重点调查工业企业(以下简称环境统计重点单位)为“主要污染物排放量占各地区(以地市级行政区域为基本单元)全年排放总量85%以上的工业企业”。理论上,对某污染物,应将地区全部工业企业按排放量由高到低排序,计算累计排放量,累计排放量达到排放总量85%时的企业即为环境统计重点单位,其余为非重点调查单位。显然,理论操作意味着各工业企业的排放量都已知,也就不存在对非重点调查单位的总量估算问题了。因此,实践中一般基于污染源普查来确定环境统计重点单位,在非普查年份进行动态调整更新。二污普是目前最新和最完整的污染源数据库,提供了全部工业源调查单位的排放量信息。因此,本研究没有采用环境统计实践中对工业企业的实际类别,而是基于二污普数据、根据《环境统计报表制度》中的理论界定计算和区分了环境统计重点单位和非重点单位。
按统一社会信用代码和企业名称比对了二污普数据库和排污许可管理平台数据,采用排污许可管理平台对排污单位的分类来区分和界定排污许可系统中的重点管理、简化管理和登记管理单位(以下分别简称许可重点单位、许可简化单位和许可登记单位)。
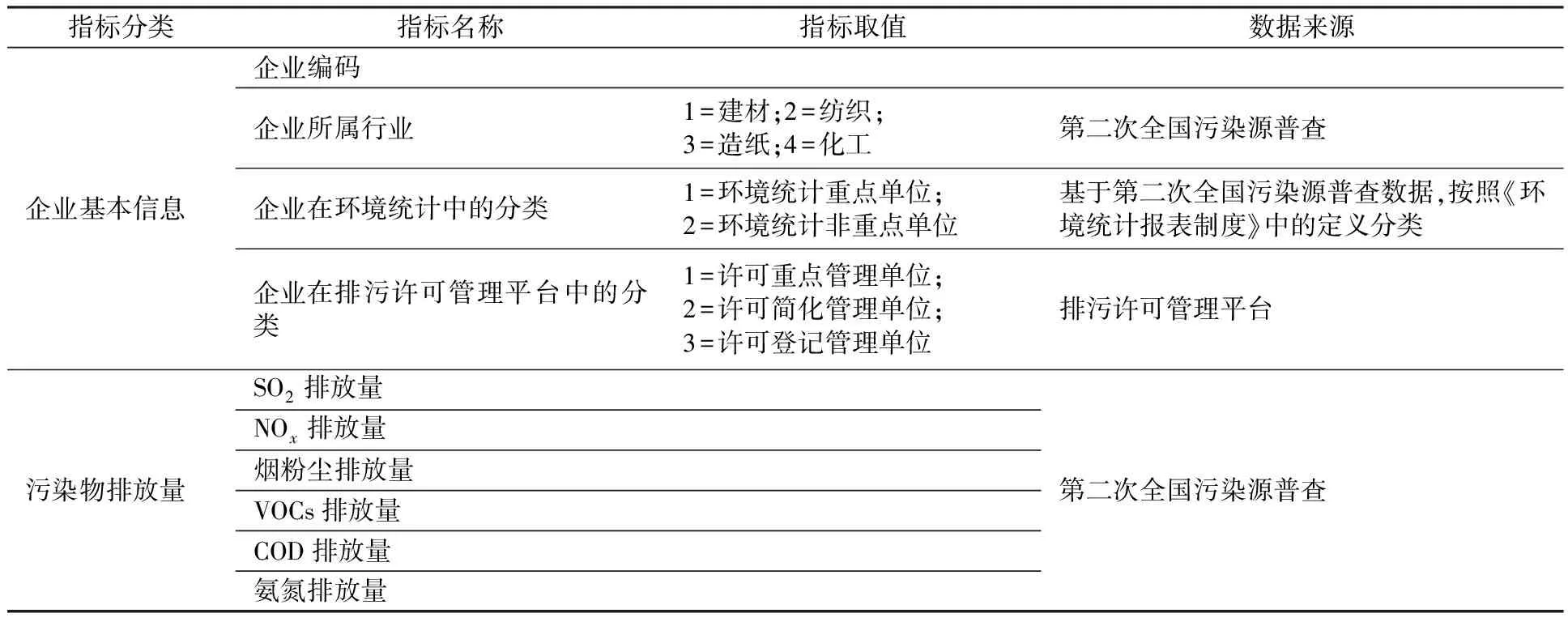
表1 变量清单Table 1 List of variables
排放量数据全部来源于二污普。一方面,二污普数据本身具有权威性和全面性;另一方面,因为排污许可管理平台仍在完善之中,即使是许可重点管理单位,排放量数据也存在不完整或仍需审核确认,且按照许可制管理规定,许可简化单位和登记单位无需报送排放量数据。
C市4个行业6类污染物构成24个子总体,子总体间规模差异较大(表2)。从行业总体规模看,建材行业规模最大,有近5 000家企业,其次是化工和造纸行业,纺织行业规模最小,只有61家企业;从污染物类别看,建材行业的氨氮指标,纺织行业全部6个污染物指标,造纸行业SO2、NOx、烟粉尘、COD和氨氮指标,这12个子总体规模均很小。对较小的子总体进行全面统计监测的成本较低,区分重点调查和非重点调查企业的意义不大,因此,下文的分析主要针对其余12个规模相对较大的子总体进行。

表2 按行业和污染物分类的工业污染企业数Table 2 Number of industrial polluting enterprises by industry and pollutant
2 结果与讨论
2.1 环境统计重点单位与许可重点单位的一致性分析结果
根据环境统计报表制度的界定标准,环境统计重点单位是按污染物排放量从大到小对企业进行排序后累计排放量达到85%的前若干家企业,需逐一调查,其余为环境统计非重点单位,只估算总量。根据排污许可制度,只有排污许可重点管理单位需要报告排污量,如果以排污许可数据作为环境统计数据源,则许可重点管理单位数据可得,简化管理和登记管理单位数据不可得,需要估算。因此,在一致性比较中,将许可简化和登记管理合并,视为许可标准下的非重点单位。
一致性比较的结果(表3)表明,排污许可系统和环境统计的重点与非重点调查单位的分类具有很大差异。如表3所示,按行业和污染物分类,得到12个子总体,第3列和第4列为各类企业数占比。对每个子总体,对角线上的元素为在环境统计和排污许可2个体系下分类一致的企业数占比,合并得到第6列;非对角线上的原色为分类不一致的企业数占比,合并得到第7列。第8列为采用列联表分析得到的χ2统计量及其显著性。从表3可以看到,在2个体系下均为重点单位的企业数量相对较少,最高为39.7%,最低为2%,符合环境统计中多数污染排放指标表现为高度偏斜分布的特征[7]。但2个体系分类的一致性不高,分类相同的企业数占比最高仅为42.2%,最低为1.7%。按5%的显著性水平,除建材行业COD无许可重点企业外,其余11个子总体中10个子总体的分类具有显著差异。
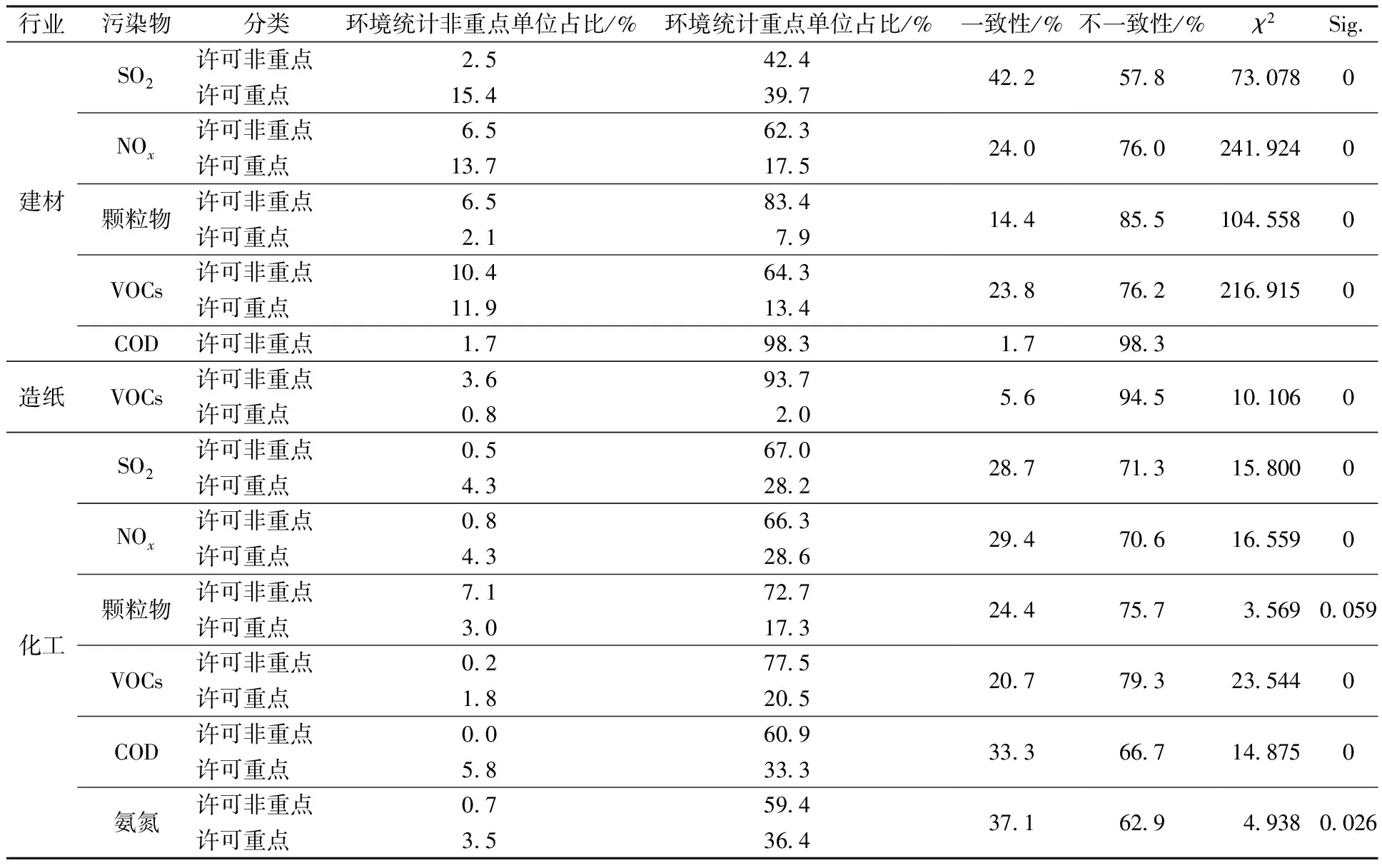
表3 环境统计重点单位与许可重点单位的一致性Table 3 Consistency of key investigation enterprises between environmental statistics and pollutant discharge permit
2.2 许可重点单位与简化和登记单位的统计特征比较
显然,环境统计与排污许可2个体系的企业分类有显著差异。有必要分析许可重点、简化和登记管理单位的统计特征,以判断其是否能够满足环境统计的需求。
环境统计报表制度的主要目的是尽可能以较低调查成本获得污染排放量的主体数据,同时能够估算出其余的污染排放量数据。工业企业污染排放指标的统计分布多为高度偏斜分布,即少数企业污染排放大,大量企业污染排放小。因此,对前者进行逐一调查,对后者进行抽样调查或简单估算总量的统计方法成本较低且可以满足污染排放总量统计需求。基于此,将少数污染排放大的企业界定为重点调查单位,其余为非重点调查单位。环境统计报表制度中累计污染排放85%分界点的确定,则主要是基于对环境管理的需求。我国各类环境管理制度都强调通过抓重点的方式来进行环境监管,虽然有“重点调查单位”“重点监控企业”“重点排污单位”“重点管理排污单位”等名称差异,但一般都采用污染排放量累积占比的方式来确定重点源,针对不同需求,有85%、65%、50%等比率选择[8]。
因此,从环境统计的需求和目的看,首先有必要区分重点和非重点调查单位,重点单位的特征应是污染排放量大(通过均值反映)且差异大(通过标准差反映),数量少(通过企业数占比反映)但累计排放占比高(通过累计排放量占比反映),非重点单位则相反;其次,重点单位累计污染排放占比可以不同于85%,但一般应高于50%。
从不同排污许可管理类别企业污染排放的统计特征看(表4和表5),12个子总体中有8个子总体的重点管理企业排放均值和标准差高于简化和登记管理企业,符合重点与非重点单位的应有差异,但建材行业的4个指标(NOx、颗粒物、VOCs和COD),简化管理企业的平均排放甚至高于重点管理企业,且简化和登记管理企业的排放差异也高于重点管理企业。从累计排放量占比看,重点管理企业中6个子总体在80%以上,能够满足环境管理“抓重点”的需求,除建材行业COD无重点企业累计排放量占比为0%外,其余5个子总体的累计排放量占比则不足50%。
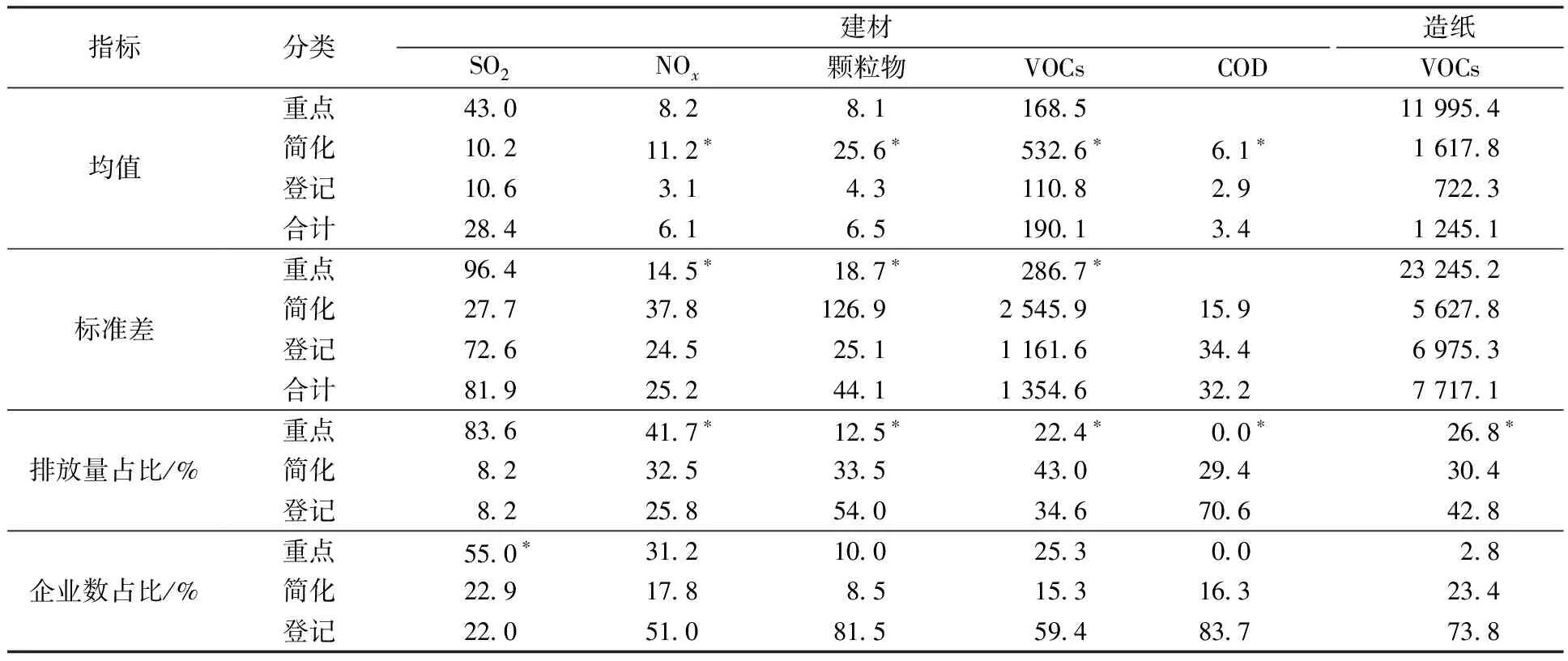
表4 排污许可不同管理类别企业排放的统计特征(建材行业和造纸行业)Table 4 Statistical characteristics of enterprises’ pollutant emission in different management categoriesunder pollutant discharge permit system(building materials industry and paper industry)
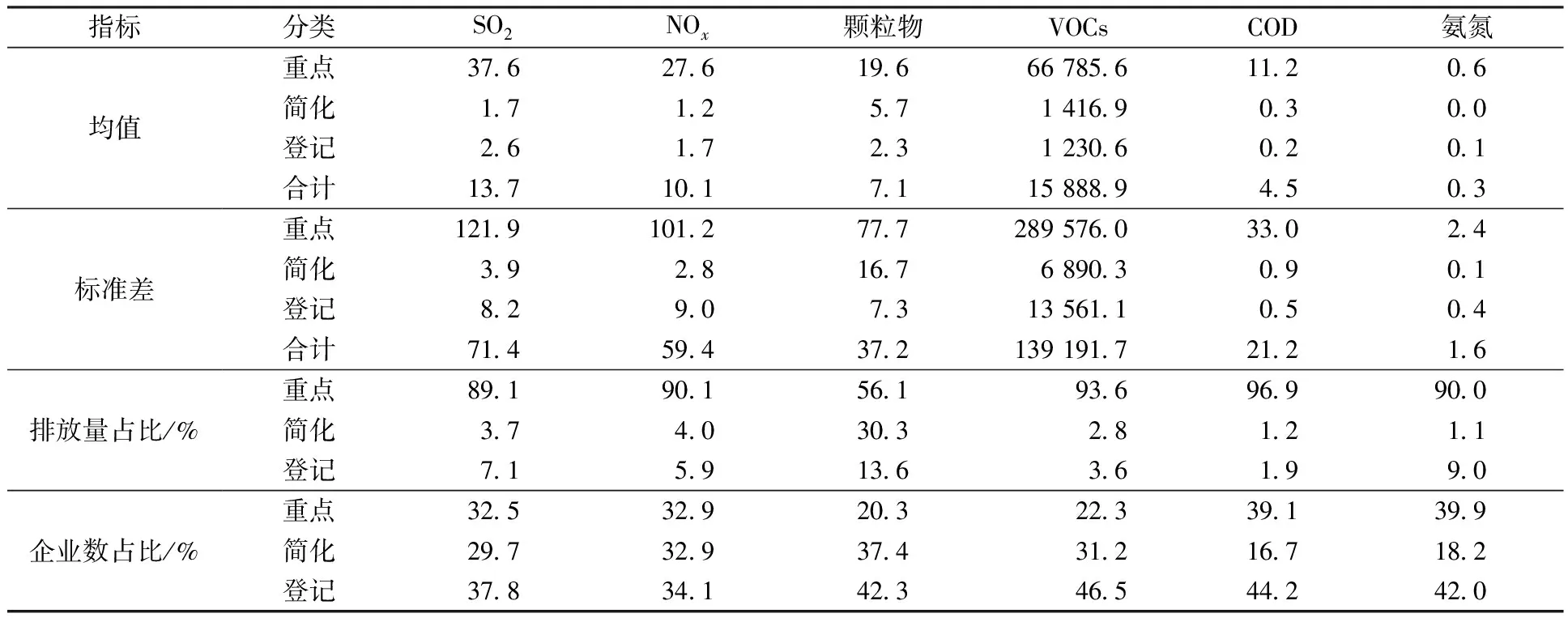
表5 排污许可不同管理类别企业排放的统计特征(化工行业)Table 5 Statistical characteristics of enterprises’ pollutant emission in different management categoriesunder pollutant discharge permit system (chemical industry)
同时还应注意到,排污许可重点管理企业的数量较多,除了建材行业COD指标下无重点行业外,造纸行业VOCs指标重点管理企业数量占比为2.8%,但其累计排放量占比也只有26.8%,达不到环境统计重点管理的需求,其余10个子总体重点管理企业的数量占比最低为10%,多数在20%以上,最高达到55%。而实际上,如果按照污染排放从大到小排序(表6),则除了建材行业SO2指标下需要调查6.2%的企业才能获得60%的排放量数据外,其余行业指标只需调查排放量最大的前5%的企业,就可以实现50%~60%的排放量统计需求。而要达到排放量85%的统计需求,除少数行业指标(建材NOx和VOCs)需要调查略高于20%以上的企业外,多数行业指标需要调查的企业数占比都在10%以下。
2.3 基于排污许可的非重点单位排放总量估算结果
许可重点单位与环境统计重点单位不一致,且各行业指标累计排放占比差异很大,难以沿用环境统计根据重点单位排放总量按比例估算非重点单位排放总量的方法。对于数量多且排放量较小的企业,需要采用抽样调查方法来估算其排放总量。本研究应用简单随机抽样方法,采用2种方法进行抽样估算:一是在给定相对误差的基础上来确定理论样本量;二是在给定样本量的基础上来进行估算。
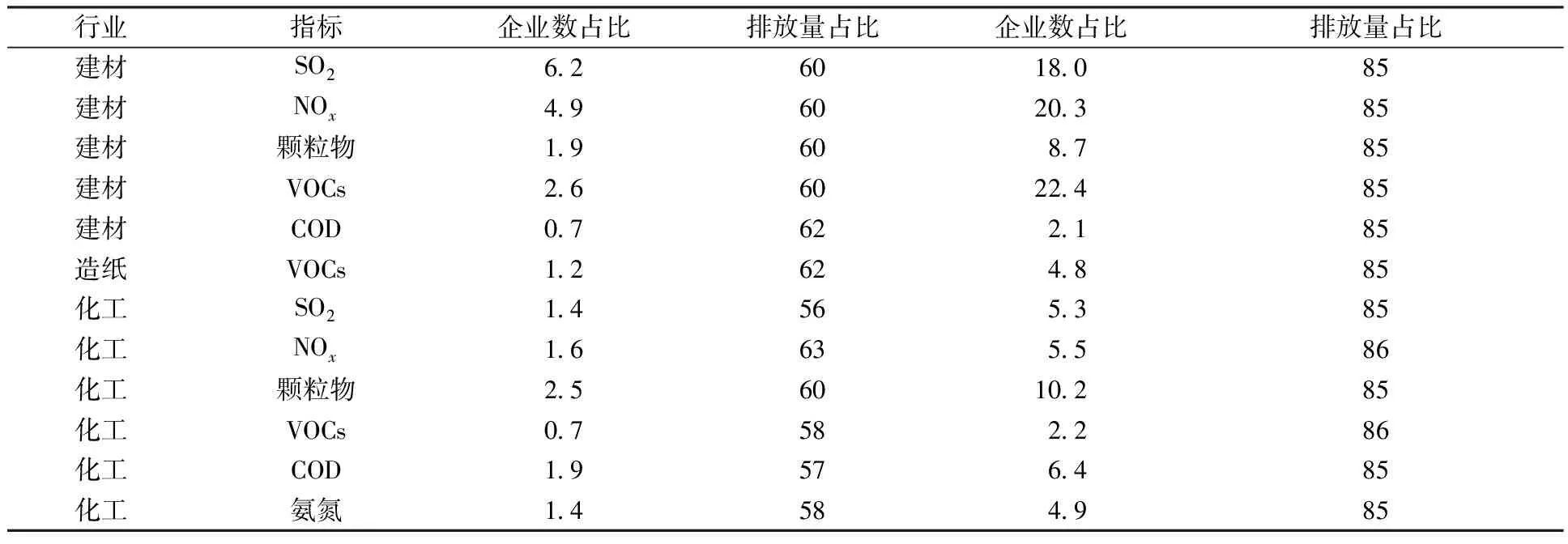
表6 企业数与累计排放量占比Table 6 Proportion of enterprises and cumulative emission %
2.3.1 给定相对误差
在给定相对误差的前提下,计算样本量
(1)
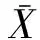
相对误差依次取5%、10%和20%,计算得到抽样比例(n/N)如表7所示。
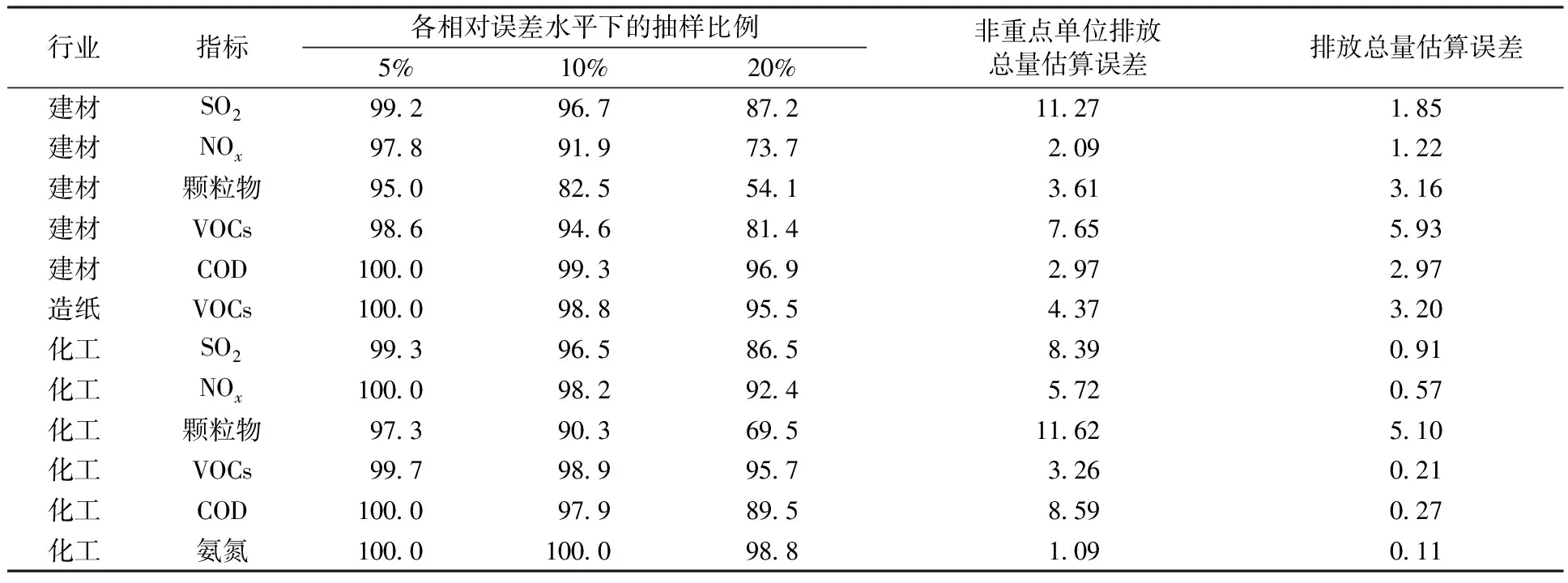
表7 给定抽样误差下的样本量与抽样估算误差Table 7 Sampling proportion and sampling estimation error under given sampling error %
从表7可以看出,在相对误差较小时,所需样本量几乎达到了普查要求,即使相对误差选择20%,所需样本量也非常大,抽样比例最低为54.1%(建材行业颗粒物指标),最高达到98.8%(化工行业氨氮指标)。
选择20%的相对误差所确定的相对较少的样本量,对许可非重点单位(即简单和登记管理企业)进行简单随机抽样,为减少一次抽样可能产生的偏差,模拟抽样1000次计算均值,得到非重点单位排放总量估算值,与实际值比较计算估算相对误差,并进一步计算得到工业污染排放总量估算的相对误差,计算公式:
工业污染排放总量估算值=非重点单位排放总量估算值+重点单位排放总量实际值
(2)
(3)
工业污染排放总量实际值=非重点单位排放总量实际值+重点单位排放总量实际值
(4)
(5)
从估算结果看(表7),各行业非重点单位排放量估算的相对误差最低为1.09%(化工行业氨氮指标),最高为11.62%(化工行业颗粒物指标),平均为5.89%,基本可以接受。由于非重点单位排放总量占比相对较低,因此总体污染排放总量的估算误差会进一步下降,最低为0.11%,最高为5.93%(建材行业VOCs指标),平均为2.12%,能够保证估算的可靠性。
2.3.2 给定样本量
为便于操作,抽样调查中也可以采用固定样本量的方法。考虑到部分子总体企业数量较少,因此统一设定样本量为50,在各子总体分别模拟1 000次简单随机抽样,估算非重点单位排放总量以及全部排放量并计算误差(表8)。
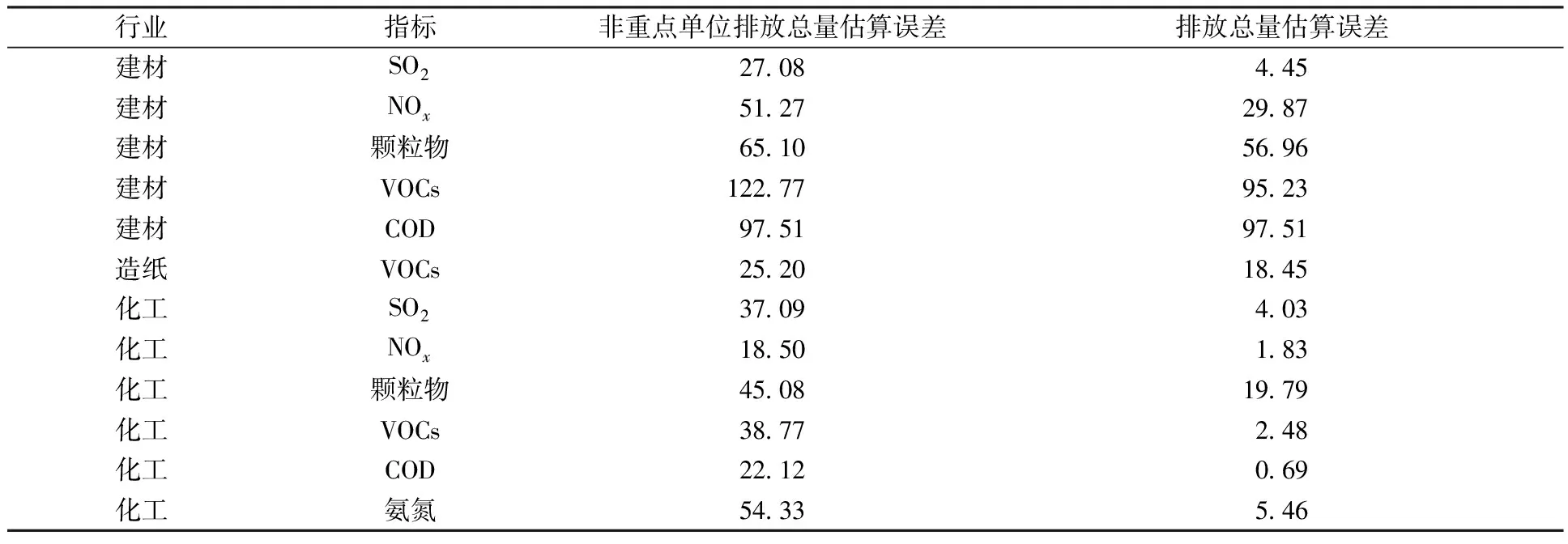
表8 固定样本量为50时的样本量与抽样估算误差Table 8 Sampling estimation error with fixed sample size 50 %
从估算结果看(表8),由于固定样本量比理论样本量大幅减少,抽样误差也明显提高。非重点单位排放量估算相对误差最低为18.50%,最高达到了122.77%,平均为50.40%,高于一般可接受水平。各行业指标排放总量的估算误差也有提高,但提高幅度相对小于非重点源,最低为0.69%,最高接近100%,平均为28.06%,仍然偏高。
2.4 讨论
尽管本研究只基于某市4个行业的6个指标开展分析,但对统计对象的描述和所发现的问题具有一定普遍性。
分析表明,环境统计对重点调查单位逐个发表统计,对非重点调查单位进行调查估算的方法具有合理性。各行业污染排放指标均表现为高度偏斜分布,理论上都可以分为两部分:即数量少但排放量大的重点调查单位和数量多但排放量小的非重点调查单位。对多数行业污染物指标,只需要调查10%左右的企业,就可以统计到85%的排放量。环境统计非重点单位数量多、排污量小且差异不大,一般经济体量也相对小,分布分散,发展不稳定,产生和消亡速度快,统计成本较高而环境影响相对较小,作为环境统计常规统计对象的成本很高。因此,环境统计现行的重点调查和统计估算方法可以以较低的调查或报表填报成本实现环境管理抓重点的统计需求,而以排污许可证作为统一的环境管理平台提高了环境管理信息化程度[9],便于环境统计区分重点调查单位和非重点调查单位。
同时应看到,排污许可分类体系下的重点管理单位与环境统计的重点调查单位存在显著差异。并且,在部分行业污染物指标上,许可重点单位并不具有重点单位所应具有的统计特征,存在平均排放量小、总排放量占比低、相对差异小等问题。究其原因,许可重点管理单位与简化和登记管理单位在污染排放量上并不存在清晰界限,很多重点管理单位的污染排放量甚至小于简化和登记管理单位。依托二污普数据和近年环境统计数据,完善排污许可管理对企业管理类别的界定有必要性[10-11]。在其余行业污染物指标上,虽然许可重点单位表现出应有特征,但企业数量占比远高于环境统计重点单位数量占比,累计排放量占比却远低于85%,即较高的统计核查成本并不能完全满足环境管理把握污染排放主体的需求。
此外,不同行业不同污染物许可重点管理单位数量占比和累计排放量占比的差异较大,没有一致的比例系数,难以应用传统环境统计的比例估算方法来估算非重点单位(简化和登记管理单位)的总排放量,需要通过抽样调查方法来进行估算。而在许可非重点单位个体排放量差异较大的情况下,达到一定抽样精度所需的理论样本量非常高,在部分行业甚至几乎达到普查的程度。尽管非重点单位污染排放总量在总体污染排放总量中占比相对较小,但估算误差也难以忽略。
3 结论
1)环境统计与排污许可2个体系下企业的分类属性具有显著差异。2个体系目前数据的比较分析表明,许可重点单位与环境统计重点单位不具有一致性,不能直接以许可重点单位替代环境统计重点单位。不能沿用环境统计的重点调查和比率估算方法进行污染排放总量核算。
2)从污染排放统计特征看,许可重点单位与简化和登记管理单位之间的分类界限并不清晰。从现有排污许可数据特征看,在部分行业污染指标上,非重点单位具有排放量大且差异大等特征,导致通过抽样调查进行总量核算的调查成本较高或抽样误差较大,难以满足环境统计以及环境管理的需求,是“一证式”管理形势下环境统计将面临的挑战。
3)以排污许可数据作为环境统计数据源可以降低统计成本,但需进一步完善分类标准。以排污许可证作为统一的环境管理平台提高了环境管理信息化程度,直接按照目前的重点、简化和登记管理分类作为环境统计中重点和非重点调查单位的确定标准,有利于简化重点和非重点单位的识别过程,提高统计效率。建议依托二污普数据和近年环境统计数据,完善排污许可管理对企业管理类别的界定,保证排放量较大的企业可以进入排污许可重点管理范围,部分排放量较小的企业可以放入简化或登记管理范围,提高许可重点单位的统计代表性。
猜你喜欢
华北电力大学学报(社会科学版)(2022年3期)2022-06-25 05:54:24
华北电力大学学报(社会科学版)(2022年1期)2022-03-04 11:18:48
内蒙古统计(2021年4期)2021-12-06 02:49:20
今日农业(2021年3期)2021-12-05 01:46:23
今日农业(2021年10期)2021-11-27 09:45:24
华北电力大学学报(社会科学版)(2021年1期)2021-03-01 08:19:06
民族高等教育研究(2020年3期)2020-09-14 07:57:58
中国化肥信息(2019年1期)2019-01-17 21:31:12
测控技术(2018年4期)2018-11-25 09:46:52
上海精神医学(2017年5期)2017-11-29 06:03:10
