
一种改进的基于交叉网络的CTR预估方法
2022-04-24 09:11:48付志昊
技术与市场 2022年4期
付志昊
(东北大学理学院,辽宁 沈阳 110819)
1 研究背景
随着科学技术的进步,广告行业借助传播迅速且应用广泛的互联网取得了蓬勃发展。为了对用户实现广告的精准投放,广告点击率预估的准确性显得尤为重要。
关于广告点击率预估的研究由来已久。Rendle等[1]提出了因子分解机(Factorization Machine,简称FM)模型,该模型通过学习每个特征唯一对应的隐向量来构造出二阶特征交叉项的权重。J等人[2]于2017年提出了注意力机制因子分解机(Attentional Factorization Machine,简称AFM)模型,它于FM模型的区别就在于二阶特征交互项。
2016年,Google[3]提出了Wide & Deep模型,该模型将逻辑回归与神经网络结合。同一年Qu等人[4]提出了基于Product层的神经网络(Product-based Neural Network,简称PNN)模型,该模型将嵌入后的特征细分为线性部分和非线性部分。 2017年,华为[5]提出了深度因子分解机(Deep Factorization Machine,简称DeepFM)模型,DeepFM模型由FM模型和神经网络两部分并行组合而成,这两部分分别负责低阶和高阶特征的提取。2017年,斯坦福大学和谷歌公司[6]提出了深度交叉网络(Deep & Cross Network,简称DCN)模型,该模型引入了一个交叉网络,将其与全连接层融合。
本文提出的XCS模型,将交叉网络和堆栈式自编码器(stacked autoencoder,简称SAE)结合,SAE是经常被用来学习原始数据的一个更好的表示,描述数据的非线性关联关系,以此来探索高阶特征交互。另外,使用XGBoost在特征工程阶段来选择非常重要的特征,通过设定决策树的深度来决定XGBoost部分的特征交互阶数,XGBoost可以弥补交叉网络和SAE部分的不足。
2 相关工作
神经网络提出后,特征交互的改进变得更加复杂和精细。较为典型的模型有DCN模型,通过结合交叉网络和全连接层的输出来提升特征交互能力。由一些学者于2019年提出的ASAE模型引入了自编码器算法,类似的还有SAEFL模型,该模型将门控回归单元网络与堆栈式自编码器结合。
3 基于XCS模型的点击率预估模型
3.1 XCS模型基本思想
XCS模型的主要思想,是将交叉网络与堆栈式自编码器结合,其中交叉网络能显式地进行特征交叉,而堆栈式自编码器可以捕捉特征之间非线性的相互作用。另外,运用XGBoost在特征工程阶段来选择非常重要的特征,再输入进逻辑回归模型得出结果。
XCS模型由3部分构成:交叉网络、堆栈式自编码器与XGBoost。模型整体也分为3层:第一层为嵌入层,用于将高维稀疏向量转化为稠密特征向量;第二层是交叉网络、堆栈式自编码器、XGBoost三个模块的组合,其中,交叉网络与堆栈式自编码器共用同一个嵌入层;在堆栈式自动编码器中,多个自编码器形成多层深度网络结构,它的每一个隐藏层都是前一层输出的非线性变换; XGBoost可以自动提取和组合特征,并且可以通过设置决策树的数量来决定特征交互的阶数。
3.2 XGBoost部分
XGBoost全称Extreme Gradient Boosting,可译为极限梯度提升算法。
其使用如下前向分布算法:
(1)
(2)
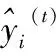
3.3 Cross Network部分
交叉网络由交叉层组成。
第l+1层的计算如式(3)所示:
Xl+1=X0XlTWl+bl+Xl
(3)
其中,X0是由嵌入向量和连续型特征向量叠加形成的向量,如式(4)所示:
X0=[XTembed,1,……,XTembed,k,XTdense]
(4)
3.4 SAE部分
自编码器经常用于数据可视化与数据降噪。
若给定训练集X={X(1),X(2),…,X(n)},编码器会将X(i)映射到y(i),从输入层X(i)到隐藏层y(i),表示如下:
y(i)=f(W(1)·X(i)+b(1))
(5)
其中,W(1)是编码权重矩阵,b(1)是偏置项。
从隐藏层y(i)到输出层Z(i)使用如下线性映射从y(i)映射到Z(i):
Z(i)=W(2)·y(i)+b(2)≈X(i)
(6)
其中,W(2)是解码权重矩阵,b(2)是偏置项。
多个自编码器构成堆栈式自编码器。堆栈式自编码器的结构是关于中间隐层对称的,因为只有对称结构才可以将输入压缩成潜在空间表征,然后通过这种表征重构输出。
3.5 XCS模型
为了弥补现有CTR模型的不足,本文提出了名为XCS模型的融合模型,该模型充分利用了上下文特征,并且可以在特征交互的同时,进行显式的特征交互。XCS模型的结构如图1所示。

图1 XCS模型的结构
在XCS模型中,本文利用XGBoost来自动地选取和组合特征,同时引入交叉网络,交叉网络能以有效的方式应用显式特征交叉;并且为了捕捉特征之间高度非线性的相互作用,采用堆栈式自编码器来学习高阶特征。
4 实验与结果分析
4.1 数据集介绍与实验设置
实验数据集采用公开的广告点击率数据集Criteo。实验中对于所有模型均采用Adam作为优化器,其中嵌入向量维度均为8,学习率均设置为0.05,随机失活率均设置为0.5,L2正则化参数均设置为0.2,另外对于所有深层模型,网络层均设置为[32,32,32]。
4.2 模型对比
在相同的实验环境下,分别采用FM模型、DeepFM模型、PNN模型、NFM模型、DCN模型和XCS模型进行对比实验。
4.3 评价指标
由于正负样本极度不平衡,预测准确率等指标不能准确地反映模型性能,因此本实验采用均方根误差(RMSE)和AUC值作为模型评价指标。
均方根误差用于衡量模型预测值与真实值之间的偏差。其计算公式如下:
(7)
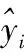
AUC值为ROC曲线下的面积。 AUC值取值范围为[0,1],AUC值越大,说明模型分类效果越好。
4.4 实验结果与分析
本节在Criteo数据集上依次评估了第(3.2)节中列出的5个模型与本文提出的模型,依据指定的评价指标对模型分类效果进行了比较。
不同模型在Criteo数据集上的效果比较如表1所示。
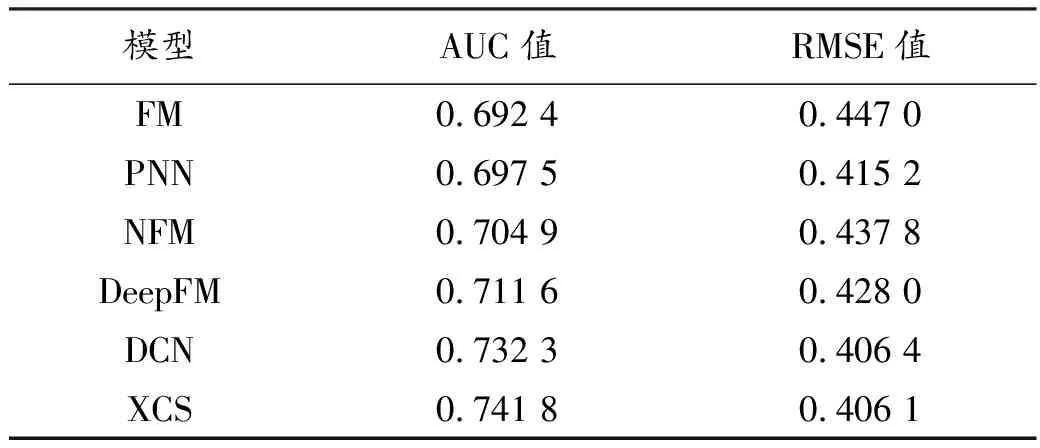
表1 不同模型在Criteo数据集上的效果比较
由表1可知以下结果。
1)相比于只建模高阶或低阶特征交互的模型,同时兼顾高阶和低阶特征交互的模型预测效果更佳。如表1所示,与FM模型和PNN模型相比,同时兼顾高阶和低阶特征的DCN模型在Criteo数据集上的AUC指标分别提高了3.99%和3.48%,RMSE指标分别减小了4.06%和0.88%。
2)交叉网络由于其独特的结构使得对于点击率预估有很好的效果。如表1所示,使用交叉网络的DCN模型和XCS模型在该Criteo数据集上的AUC指标与RMSE指标均优于其他模型。
5 结语
为提高模型对于CTR的预测效果,本文提出了一个新的融合模型——XCS模型。该模型一是通过引入XGBoost来在特征工程阶段进行特征组合和选择;二是引入堆栈式自编码器,将其与交叉网络结合,自编码器部分可以建模高阶特征交互。通过公开数据集,测试了模型预测效果,并与几种CTR经典模型进行了对比。实验表明:本文提出的XCS模型相比于现有的CTR模型在AUC指标与RMSE指标上都有不同程度的提升,同时也说明模型之间的有效融合对于提升CTR预估效果有重要意义。
猜你喜欢
数学物理学报(2021年1期)2021-03-29 03:13:48
数学物理学报(2020年6期)2021-01-14 01:00:36
哈尔滨轴承(2020年1期)2020-11-03 09:16:02
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
单片机与嵌入式系统应用(2018年2期)2018-03-01 00:36:52
数学物理学报(2017年5期)2017-11-23 07:51:31
军事运筹与系统工程(2017年1期)2017-07-31 18:19:01
天津师范大学学报(自然科学版)(2015年2期)2015-03-11 18:46:50
新课程学习·中(2013年3期)2013-06-14 05:55:20
