
基于轻量化VGG的植物病虫害识别*
2022-04-24 12:55王江晴冀星莫海芳帖军刘畅
中国农机化学报 2022年4期
王江晴,冀星,莫海芳,帖军,刘畅
(1. 中南民族大学计算机科学学院,武汉市,430074;2. 湖北省制造企业智能管理工程技术研究中心,武汉市,430074)
0 引言
植物病虫害是农产品质量、产量下降和农业经济损失的主要原因之一[1]。由于植物病虫害种类繁多,人工判断受主观因素影响,很容易造成误判,因此寻找准确快速识别病虫害的方法,是避免损失、提高产量的关键。
近年来,卷积神经网络(Convolutional Neural Networks,CNN)[2]在图像识别中获得了极大的成功,其可以自动提取特征,实现了端到端的训练,因此很多人使用卷积神经网络来解决植物病虫害的识别问题。目前,常见的卷积神经网络是AlexNet[3],InceptionNet[4]和ResNet[5]等。Drumus等[6]使用PlantVillage数据集的番茄图像进行训练,在AlexNet上和SqueezeNet[7]上的准确率高于原模型。Lü等[8]在Alexnet中加入膨胀卷积和多尺度卷积,提取复杂环境下玉米叶片的特征,同时使用批量标准化防止网络过拟合。王国伟等[9]使用LeNet模型对玉米病害进行识别,并用Adam算法进行学习率动态调整来优化模型。李鑫然等[10]采用特征金字塔网络[11]融合浅层的细节信息特征和深层的具有语义信息的特征,避免对苹果叶片病害造成的像素偏差。Zhang等[12]使用EfficientNet[13]构建黄瓜病害识别模型,并进行迁移学习,解决了病害识别中样本不足的问题。肖经纬等[14]降低ResNet卷积层数与卷积核数来精简网络参数,再利用类间相似惩罚项解决相似样本区分度低的问题。
虽然这些模型取得了较高的准确率,但参数量过大,不适合部署在微算力的移动端和嵌入式设备上。而实现识别模型在移动端和嵌入式设备上的部署,有助于帮助病虫害识别算法走出实验室,实现在复杂环境下的应用。因此,对VGG16模型进行改进,提高网络模型的准确率并降低参数量。
1 VGG与轻量化模型介绍
VGG是一个经典的深度神经网络模型,它探索了神经网络深度对其准确率的影响[15]。与最新的网络结构相比,VGG16的结构简单、没有复杂的瓶颈结构,模型中只包含非常小(3×3)的卷积滤波器,如图1所示,VGG16共有13层卷积层、4层最大池化层、3层全连接层和激活函数,依然取得了优越的成绩,在ILSVRC 2014提交的成绩中TOP5错误率仅为7.3%。但是VGG16整个网络的参数量约为14 728 266,模型总共需要的浮点数计算次数(Floating Point of Operations,FLOPs)为313 M。众多的参数使得VGG16网络具有很高的拟合能力,同时也使得VGG16网络需要训练的时间过长,调参难度大。

图1 VGG16各层特征图大小Fig. 1 Feature map size of VGG16 layers
近几年,一些学者提出了提高VGG效率的有效改进方法。主要包括通过剪枝和量化进行模型压缩,减小网络规模。Han等[16]对模型中的小型连接进行修改,将所有权重低于阈值的连接从网络中删除,然后对网络进行重新训练,将AlexNet和VGG16网络模型的参数数量分别减少了9倍和13倍。蒲秀夫等[17]将VGG16模型的权值进行二值化,得到的模型达到原模型近两倍的计算速度。
轻量化模型追求实现更高效的网络计算方式,比如需要更少计算量的卷积方式。SqueezeNet为了降低模型参数,用1×1的卷积核来替换3×3的卷积核。MobileNet[18]引入了深度可分离卷积,将常规卷积分为两步,先对输入特征图的每个通道进行按位相乘,再使用1×1的卷积核进行常规卷积运算,得到n张特征图,降低了参数量。ShuffleNet[19]将输入层的不同特征图进行分组,然后采用不同的卷积核对各个组进行卷积,以此降低卷积的计算量。
虽然这些模型降低了参数量并取得了较高准确率,但在实际应用中表现仍不理想,并且很少被应用在植物病虫害识别上,因此本文将轻量化技术用于解决植物病虫害识别问题,获得的最终模型参数量为0.41 M。
2 模型设计
为了降低VGG16的浮点运算次数FLOPs,同时保证网络模型的准确率,本文对VGG16的网络结构做出了改变。
2.1 Ghost模块
深度神经网络中包含大量的卷积核,产生巨大的计算开销,卷积层的输出特征图通常包括很多冗余或者相似的特征图,没有必要使用大量的参数和FLOPs生成这些冗余特征图。本文使用Han等[20]提出的Ghost模块来替换VGG16中的卷积。将深度神经网络中的卷积操作分为两步,先使用普通卷积生成一部分特征图,然后对这些特征图进行线性变换,得到更多特征图。与普通卷积神经网络相比,在不更改输出特征图大小的情况下,该网络所需的参数量减少了50%,获得了良好的模型性能,该模块结构如图2所示。

图2 Ghost模块结构Fig. 2 Structure of Ghost module
首先,假设第一部分普通卷积过程的输入为X∈Rc×h×w,其中c为输入通道数,h和w分别为输入数据的高和宽,生成m个特征图的卷积操作过程见式(1)。
Y=X*f
(1)
式中:*——普通的卷积操作;
Y——输出特征图,通道数为m,高和宽分别为h′和w′;
f——卷积滤波器,卷积核大小为k×k。
在第二部分的线性变换中,本文使用卷积对Y中的每一个特征图进行s次线性变换,线性运算用到的卷积核大小可以为3×3或5×5,最终得到n=m×s个特征图,特征图的高和宽仍然保持不变,该过程见式(2)。
yi,j=Φi,j(yi),∀i=1,…,m,j=1,…,s
(2)
式中:yi——Y中的第i个特征;
yi,j——线性变换yi后得到的第j个特征图;
Φi,j——对yi进行的第j个线性操作;
Φs——恒等映射,用于保留第一部分生成的m个特征图。
2.2 卷积核修剪
VGG16网络中使用了大量3×3的卷积核,其中包含了一些冗余的卷积核,这些卷积核会产生一些重复或极其相似的特征图,因此可以对卷积网络的卷积核进行适当的修剪,且不会显著降低网络模型的性能。
图3显示了VGG中每层卷积层的参数量和内存占用情况,每经过一个最大池化层,特征图的宽和高会变为之前的1/2,因此模型中前期的内存消耗大于后期。从图1可以看出,在模型后期的卷积操作中,特征图的宽度和长度逐渐减小,但通道数一直增大。假设某卷积层输入通道数为c,输出特征图通道数为m,卷积核大小为k×k,该卷积层的参数量见式(3)。
P(k,c,m)=k×k×c×m
(3)
在后期的卷积层中,来自上层输入的特征图和本层输出的特征图通道数都逐渐增大,会使得模型后期的参数量发生激增,在此时减少卷积核个数可以更明显抑制通道数增长引起的参数量激增。

(a) 参数量变化示意图
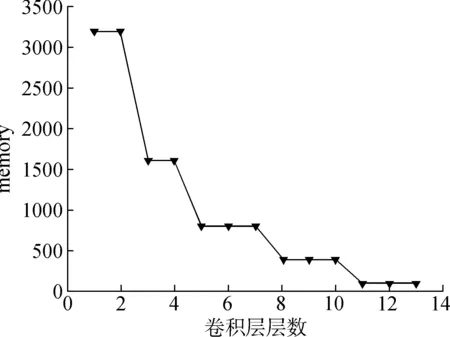
(b) 占用内存变化示意图图3 VGG16各层参数量、占用内存示意图Fig. 3 Schematic diagram of the amount of parameters and memory occupied by each layer of VGG16
探索了减少不同层卷积核个数与模型的准确率和计算量之间的关系,发现减少模型后期的卷积核个数,对准确率造成的损失更小。把模型第5~7和8~10层卷积核个数减半,分别设置为128和256,最终得到的模型FLOPs为172.72 M,再使用Ghost模块后为88.45 M;而把模型第1~4层卷积核减半,得到的FLOPs为232.89 M,再使用Ghost模块为118 M。
2.3 Ranger优化器
通过减少网络的卷积核个数虽然可以减少参数量,但同时导致每层产生的特征图个数减少,引起网络的表达能力下降,为此,需要寻找提高网络模型表达能力的方法。本文尝试了对预训练得到的权重值进行聚类,赋值给模型的第一层卷积核,在试验结果中,模型的准确率得到了大幅度上升,但预训练的开销与训练的开销相同,不符合构建轻量化网络的目的。
本文还尝试用Ranger优化器来替换VGG16的随机梯度下降(SGD)。随机梯度下降是当前神经网络中使用最为广泛的优化算法之一,但该算法训练速度慢,同时很容易使模型陷入局部最优解中。在植物病虫害识别应用上,希望模型具有较好的泛化能力和更快的训练速度,为了实现上述目标,本文引入了Ranger优化器[21],该优化器在训练过程中动态调整学习率,使模型获得更高的收敛速率。
在模型的训练过程中,使用两组权重值:慢速权重φ和快速权重θ,快速权重每更新k次后,更新一次慢速权重,然后将快速权重重置为当前慢速权重值。在快速权重θ的更新过程中,使用了RAdam优化器[22]进行更新,实现学习率的动态调整,在模型训练早期,由于缺乏训练样本,常常会得到不太好的局部最优解,可以通过降低学习率的方差来弥补这个缺陷。为了使学习率具有一致的方差,引入参数r对第t轮的学习率进行校正,第t轮的r计算方式见式(4),当ρt≤4或ρ∞≤4时,该算法退化为带动量的SGD算法。
(4)
式中:ρt——第t轮的SMA长度;
ρ∞——SMA的最大长度;
rt——第t轮的整流项。
由式(5)计算出简单移动平均线(Simple Moving Average,SMA)的最大长度。
(5)
式中:β2——二阶动量衰减率。
第t轮的SMA长度见式(6)。
(6)
2.4 改进后的模型结构
图4为改进后的轻量化VGG网络模型结构,模型中每层卷积使用Ghost模块替换,卷积核的大小为3×3,并保留了VGG16中的池化层和softmax层用于输出最后的分类结果,各卷积层输出特征图通道数如表1所示,在模型的5~10层进行了卷积核减半操作,并引入了Ranger优化器。

图4 模型结构Fig. 4 Structure of the model proposed

表1 各卷积层输出特征图通道数Tab. 1 Number of output feature map channels for each convolutional layer
3 试验结果与分析
3.1 模型参数设置
图5展示了试验中使用的图片,尺寸为224像素×224像素的RGB彩色图像,使用的数据集为公开的PlantVillage植物病虫害数据集,包括辣椒健康叶1 477张、辣椒细菌性斑点病997张、土豆健康叶152张、土豆早疫病1 000张、土豆晚疫病1 000张、番茄轮斑病835张、番茄花叶病373张、番茄黄曲病3 209张、番茄细菌性斑点病2 127张、番茄早疫病1 000张,总共为12 739张图像,为了增加训练集的数据,训练时按照9∶1的比例划分训练集和测试集。初始学习率设定为0.1,批量大小设定为128,迭代次数为100次,Ghost模块的超参数s设置为2,该网络模型在Pytorch框架下进行。

图5 PlantVillage部分图片Fig. 5 Images of PlantVillage
3.2 结果分析
3.2.1 减少各层卷积核的结果比较
为分析减少的卷积核个数对模型准确率的影响,将8~10层卷积层的卷积核个数分别减少25%、50%、75%,因为这部分卷积层被两个最大池化层隔开,而且卷积核个数较多。图6为减少不同的卷积核个数对模型计算次数的影响,由于卷积核减少有利于实现轻量化,但卷积核过少时准确率出现明显下降,后续试验中使用卷积核减半策略。
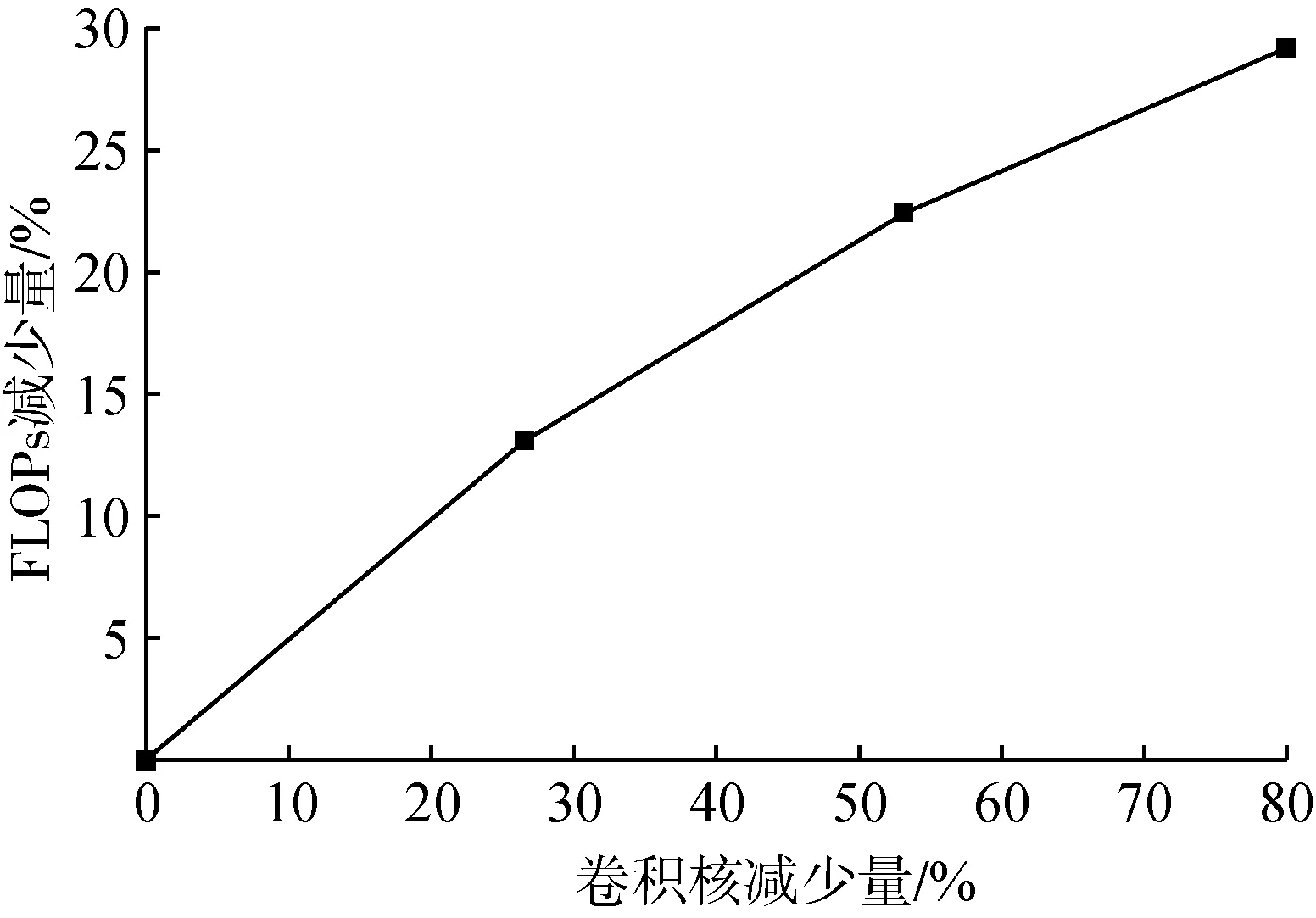
图6 减少不同卷积核个数得到的FLOPsFig. 6 FLOPs of reducing different convolution kernels number
进行4组对比试验,尝试对VGG16的不同层的卷积核个数进行减半,模型采用交叉熵损失函数计算损失值。试验中,把最大池化层隔开的卷积层看作一个整体,分阶段进行减半操作。在A组试验中,把VGG16的第1~4卷积层卷积核个数减少一半,其他层不变;B组试验把第3~7卷积层卷积核个数减少一半,其他层不变;C组试验把第5~10卷积层卷积核个数减少一半,其他层不变;D组试验把第8~13卷积层卷积核个数减少一半,其他层不变。模型的准确率、FLOPs和参数量的变化情况如表2所示。最终,本文选用了FLOPs最低的一组(C组),即在VGG16的第5~10层卷积层中将卷积核进行减半。
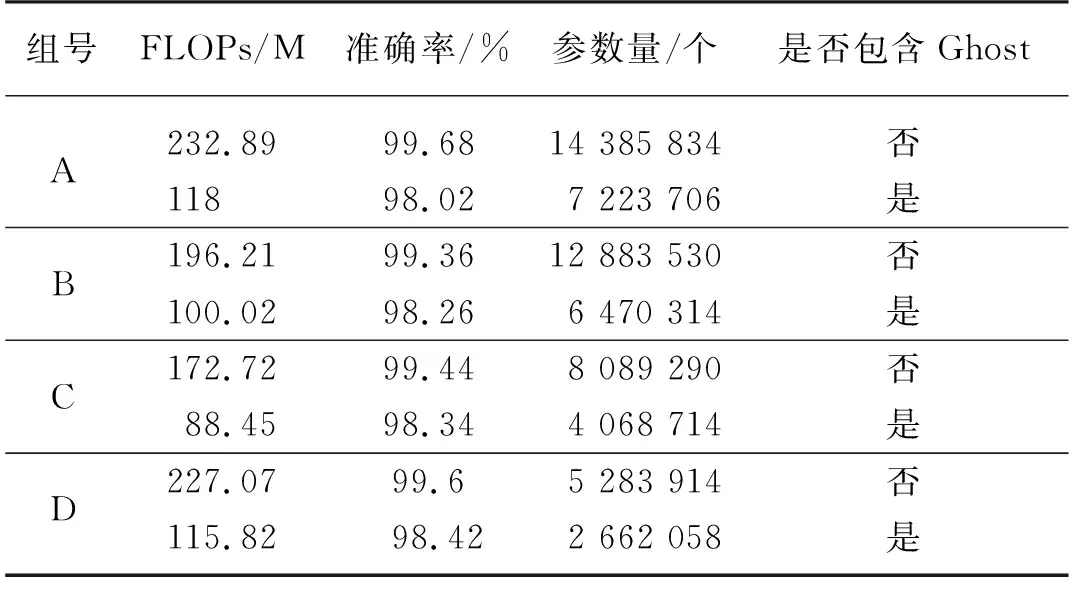
表2 各组试验的结果对比Tab. 2 Results comparison of each experiments
3.2.2 VGG16与本文模型试验结果比较
在减少卷积核的基础上,加入Ghost模块和Ranger优化器,构成最终的网络模型。为了验证本文改进后VGG16网络的性能,本文将改进后的VGG16网络模型与传统的VGG16、使用Ghost模块替换VGG16中的卷积层的网络(表3中的Ghost-VGG16)进行对比,模型损失函数均为交叉熵损失函数,试验结果从FLOPs、测试集的准确率和参数量、识别时间四个方面进行比较。
与传统的VGG16相比,该模型结构参数量减少了72.37%,模型需要的浮点运算次数FLOPs下降了71.86%,识别时间缩短25.8%,而准确率提高了0.24%,说明该模型实现了VGG16的轻量化,同时也轻微提高模型的准确率,这也证明VGG16中存在大量冗余的卷积核,这些冗余的卷积核增加不必要的计算开销。表4为不同模型在测试集上对不同病虫害的识别准确率和识别时间。
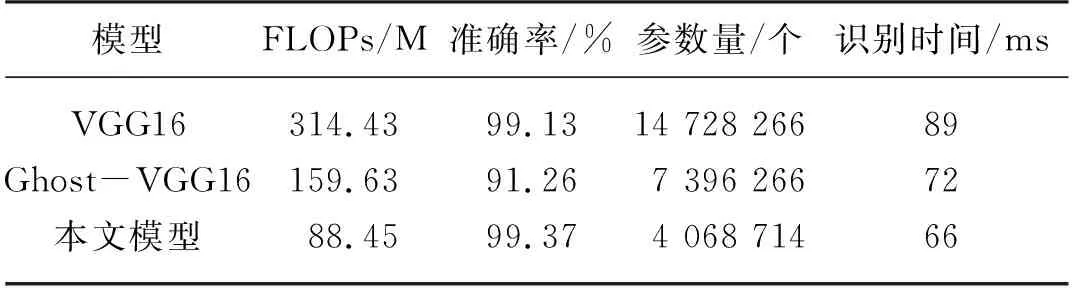
表3 PlantVillage数据集识别结果对比Tab. 3 Comparison of identification results on PlantVillage dataset

表4 不同病虫害识别结果Tab. 4 Identification results of different diseases
在Ghost-VGG16中,仅仅用Ghost模块替换了VGG16网络中的卷积层,分析试验结果可以得出,本文提出的方法参数量更小,准确率更高,而且从图7可以看出本文提出的方法在模型训练的过程中更快地达到了收敛。这是因为Ranger优化器根据每一轮的训练情况实时调整学习率,使模型获得更高的收敛速度。
为了验证模型在图像分类问题上的适用性,在同样的试验环境下在Cifar10数据集验证,该数据集由60 000张大小为32像素×32像素的RGB图片组成,包含10个分类,其中训练集包含50 000张图片,测试集包含10 000张图片。从表5中的试验结果可以看出,本文提出的模型在Cifar10上仍然取得了较高的准确率,而且参数量和计算次数更少,识别时间比VGG16减少了37.37%。

表5 Cifar10数据集识别结果对比Tab. 5 Comparison of identification results on Cifar10 dataset

(a) 模型的准确率比较
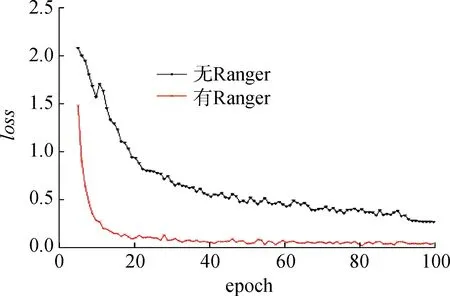
(b) 交叉熵损失值比较图7 准确率和损失值变化比较Fig. 7 Comparison of accuracy and loss value changes
3.2.3 复杂环境下的识别结果
为了测试本文提出的模型在复杂情况下识别准确率,构建了包含17 591张RGB图片的数据集,图像大小为224像素×224像素,均拍摄于自然光照下,图8给出了部分图像示例。

图8 复杂环境下图像示例Fig. 8 Images of complex environment
其中包含苹果酒锈病1 662张、苹果蛙眼斑病2 814张、苹果健康叶4 138张、苹果白粉病1 041张、苹果疮痂病4 311张、柑橘健康叶101张、柑橘溃疡病2 130张、咖啡健康叶712张、咖啡红蜘蛛螨病151张、咖啡叶锈病542张,训练集与测试集仍然按照9∶1的比例划分。表6为本文模型与其他模型在测试集上的对比结果,从表6可以看出本文提出的模型在复杂环境下仍然取得了较高的准确率,识别时间却仅为VGG16耗时的50%,模型需要的计算量和参数量也更少,更适合部署在微算力的嵌入式设备上。

表6 不同方法在复杂环境下的识别结果Tab. 6 Identification results of different models based on complex environment
4 结论
1) 针对VGG16网络模型的参数量大,计算开销大等问题,提出了一种基于VGG的轻量化网络模型。该方法首先使用Ghost模块替换VGG16中的卷积层,再对卷积层中的卷积核进行修剪,最后使用Ranger优化器提高模型的准确率。
2) 本文提出的改进在植物病虫害识别中具有明显优势,在PlantVillage上的准确率达到99.37%,而FLOPs比VGG16网络减少了71.86%,识别时间也更少。
3) 改进后的模型在复杂环境下识别准确率为92.4%,还有待提高,因此下一步将考虑去除杂草或其他叶片的遮挡、光照等因素的影响,对网络结构进一步优化,提高网络模型的泛化能力。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
上海师范大学学报·自然科学版(2019年5期)2019-12-13
学生导报·东方少年(2019年27期)2019-01-14
中国新通信(2017年9期)2017-05-27
读写算·小学低年级(2015年12期)2015-12-12
