
基于注意力机制的煤矿工作面遮挡行人检测
2022-04-22 02:45冯磊FENGLei李斌LIBin何勇HEYong
价值工程 2022年14期
冯磊FENG Lei;李斌LI Bin;何勇HE Yong
(①国家能源集团新疆能源有限责任公司,乌鲁木齐 830000;②中国煤炭科工集团太原研究院,太原 030006)
0 引言
行人检测技术作为目标检测领域的重要应用方向,一直以来都是研究人员关注的热点问题。行人检测的任务本质是在识别行人的同时对行人位置进行定位。也就是说,行人检测技术就是计算机对于给定的视频和图像,判断出其中是否有行人存在,同时标记出行人位置。
实际应用场景中,由于行人的非刚性特点,外观特征易受姿态,形状,视角,衣着等变化因素影响,并且在外界光照,遮挡,背景环境变化时,检测精度也易受到影响。因此,行人检测性能的提升是目标检测中极具挑战性的课题。而这其中,行人遮挡是亟待解决的重要问题。由于行人遮挡往往造成漏检和误检,影响行人检测的准确率和精确率,因此对于行人检测技术而言,研究行人遮挡对于行人检测性能提升意义重大。本文以不同遮挡程度的行人为研究对象,采用基于深度学习算法的双阶段检测器Faster RCNN 为基础架构,设计了一种基于注意力机制的网络,从而降低行人检测的漏检率,增强了遮挡行人的检测鲁棒性。
1 Faster R-CNN 结构与原理
1.1 Faster R-CNN 基本原理
Faster R-CNN 的主要结构包括主干特征提取网络(ResNet50),候选区域网络(RPN),池化层网络(RoI pooling 层),分类网络(Classification 层)等。
Faster R-CNN 的主要原理如下:①首先将输入图像预处理,然后用主干特征提取网络提取图片特征,输出对应的特征图(Feature Map);②接着将特征图(Feature Map)输入RPN 网络,经过3×3 卷积之后分别执行18 通道和36通道的1×1 卷积,输出一系列候选框(Proposal);③然后将特征图,候选框,原图相关信息等输入候选框特征池化层,经过分块池化操作,输出大小一致的候选框特征图;④最后将大小一致的候选框特征图输入分类网络,并经过分类全连接网络和回归全连接网络对候选框识别与定位。
ResNet 是残差网络(Residual Network) 的缩写,ResNet50 表示网络层数为50 的深度残差网络。
1.2 Faster R-CNN 主干网络
Faster R-CNN 主干网络采用ResNet50,ResNet50 表示网络层数为50 的深度残差网络。残差网络ResNet50 由两个基本的模块组成,分别命名为卷积残差块(Conv Block)和恒等残差块(Identity Block)。由卷积残差块和恒等残差块构成的ResNet50 结构如图1 所示,第一个模块由1 个卷积层构成(如图1 第二个模块),第二个网络模块由3×3 个卷积层构成(如图1 第三个模块),第三个模块由3×4 个卷积层构成(如图1 第四个模块),第四个模块由3×6 个卷积层构成(如图1 第五个模块),第五个模块由3×3个卷积层构成(如图1 第六个模块),最后再加一个全连接层,一共是1+3×3+3×4+3×6+3×3+1=50 层。

图1 ResNet50 网络结构
1.3 候选区域网络(RPN)
Faster R-CNN 不再使用选择搜索算法生成候选区域,而是直接用卷积神经网络(RPN)生成候选区。具体操作流程如下:首先生成feature Map 对应的锚框(anchor),每个feature Map 上的特征点对应9 个anchor;其次对feature Map 进行3×3 卷积,然后分别进行18 通道和36 通道的1×1 卷积,分别表示9 个anchor 对应的前景背景得分和回归系数;然后分别对anchor 进行回归微调和对anchor 是否为前景或背景打分,最终获得候选框(proposal)。
1.4 RoI 池化层
RoI pooling 的作用是将尺寸各异的输入特征转化为尺寸一致的输出特征。RoI 处理流程:首先计算Feature Map 与输入图片的尺度比例,然后将RoI 各个坐标除以该比例获得Feature Map 对应的坐标,最后将Feature Map 中对应的区域分块进行最大值池化或者平均值池化操作,获得尺寸一致的特征图输出。
1.5 分类网络
通过RoI 对公用特征层截取并经过RoI pooling 层之后,RoI pooling 层输出的特征层是对应RoI 区域尺寸大小一致的特征层,然后对特征层卷积操作和平均池化,最后将其结果进行回归操作和softmax 分类操作。
2 基于注意力机制的Faster R-CNN 检测网络
2.1 注意力(Attention)机制模型
注意力机制(Attention)的核心思想是更多关注局部信息,比如图像中的某一空间区域或者某一通道维度。计算机视觉中的注意力机制,主要灵感来源于人类的生物视觉系统。其核心思想与人类视觉注意类似,也是为了使计算机视觉针对当前任务能够更高效准确地提取出图像中的关键信息。注意力机制按照作用原理角度可分为三类:通道注意力模型,空间注意力模型,空间和通道注意力机制的融合模型。
2.2 CBAM 结构与原理
CBAM 是典型的融合空间和通道注意力机制的网络,CBAM 注意力机制模块主要作用原理是将中间特征层与集成了空间和通道两个维度的注意力模块结合在一起,然后通过训练学习对应维度的注意力权重,并将权重与原特征层相乘来对特征层进行自适应调整。
整个CBAM 的注意力机制模块如图2 所示,其具体计算流程为:

图2 CMAB 注意力机制模块
①输入特征图F;
②F 进入通道注意力机制模块Mc(F),Mc(F)中的参数与对应通道相乘,得到通道加权的F’;
③F’继续进入到空间注意力机制模块Ms(F’),Ms(F’)中参数与对应的空间特征点相乘,得到空间加权的F”
其对应的公式为(1):

其中Ms表示空间注意模块,Mc表示通道注意模块。
CBAM 之所以要用AvgPool 和MaxPool 两条并行的池化路径,是因为AvgPool 更多注意宏观上的信息,而MaxPool 更多注意局部的信息,同时使用两种方法并行池化有利用网络获得鲁棒性。
2.3 基于CBAM 的改进网络结构
本文选用ResNet50 为骨架网络。针对遮挡行人特征不足的问题,本文将CBAM 加入到ResNet50 中,形成新的特征提取网络,将Faster R-CNN 主干网络与CBAM 进行有效的结合。原理如图3 所示。

图3 CBAM 在Resnet50 中的原理图
ResNet50 的两个基本组成模块为卷积残差块(Conv Block)和恒等残差块(Identity Block),其整体结构是由若干基本组成模块卷积残差块和恒等残差块有序堆叠而成。
由于ResNet50 整体网络层数较深,为了整个网络的简洁高效,本文不选择在每个卷积残差块和恒等残差块之后都加一个CBAM,而是选择在每一次特征维度发生变化时加入CBAM,其网络的整体结构如图4 所示。
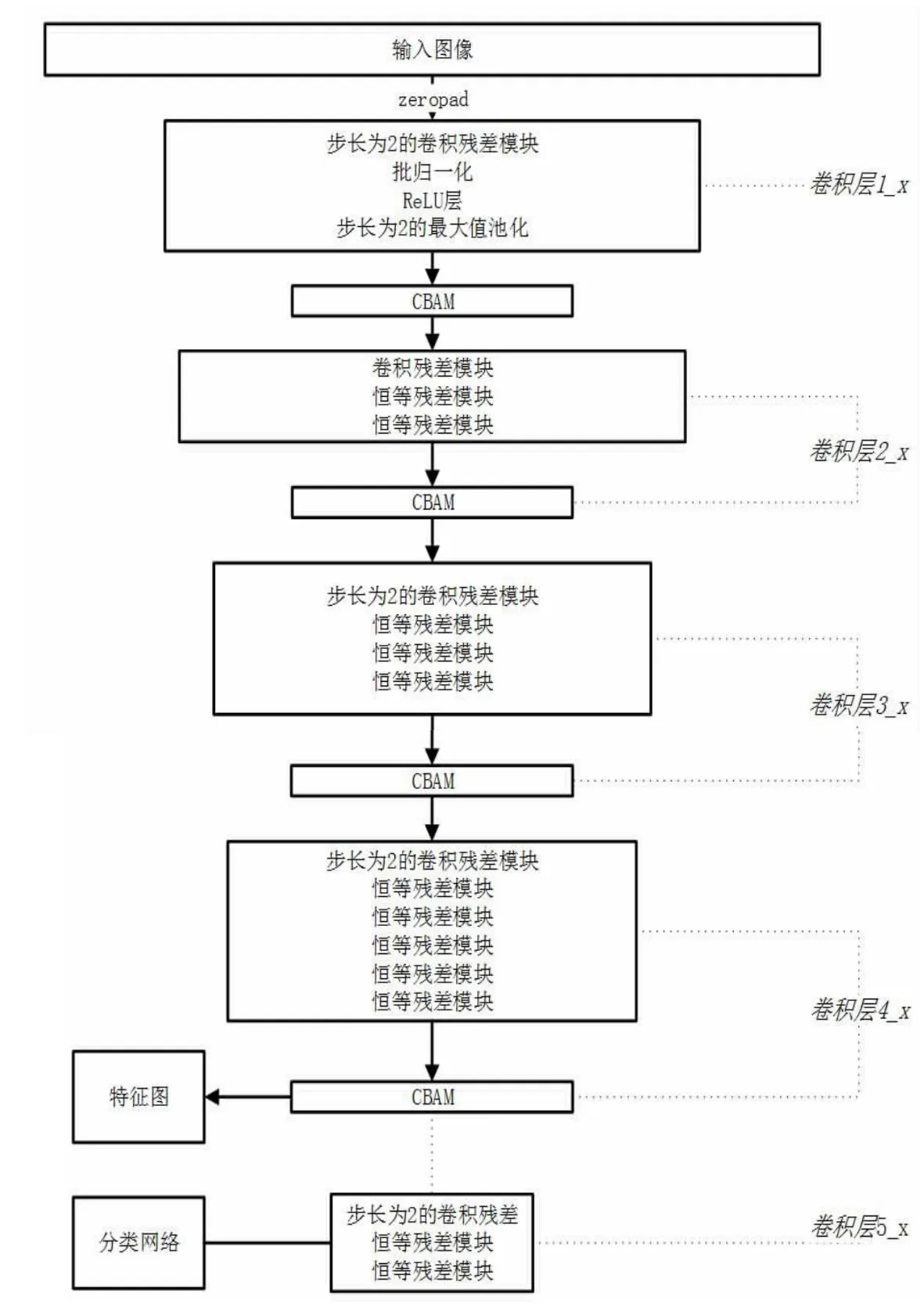
图4 ResNet50 结合CBAM 结构图
在基于注意力机制CBAM 的ResNet50 结构中,卷积层1_x 采用了一个7×7,64 通道,步长为2 的卷积;在进入卷积层2_x 之前要使用一个3×3,步长为2 的最大值池化操作,之后增加一个CBAM 模块;卷积层2_x 由1 个卷积残差块和2 个恒等残差块顺序连接构成,之后增加一个CBAM 模块;卷积层3_x 由1 个卷积残差块(步长为2)和3 个恒等残差块顺序连接构成,之后增加一个CBAM 模块;卷积层4_x 由1 个卷积残差块(步长为2)和5 个恒等残差块顺序连接构成,之后增加一个CBAM 模块,之后增加一个CBAM 模块,经此处输出的特征层则作为公用特征层(Feature Map)输入RPN 网络和RoI pooling 层;卷积层5_x 由1 个卷积残差块(步长为2)和2 个恒等残差块顺序连接构成,构成分类层(Classification),经此处输出的特征层用于分类和回归,对行人进行检测。
3 实验与分析
3.1 实验数据集和评价指标
Caltech 数据集和Cityperson 数据集不仅标注了行人的完整边界框,而且标注了行人可见区域的边界框,能够区别不同行人的遮挡程度,因此本文选择这两个数据集进行实验并对实验结果进行综合评估。行人检测中最常用的评价准则之一是MR-FPPI(Miss rate against False positive per image)曲线和平均对数漏检率MR-2(log-average miss rate)。其中FPPI(False positive per image)为横坐标,表示平均每张测试图片的误检数量,漏检率为纵坐标,都采用对数刻度。若MR-FPPI 的曲线与X 轴之间的面积越小,表示整个算法漏检率更小。通过MR-FPPI 曲线,可以在每张图像误检数在[10-2,100]范围内均匀取9 个FPPI 对应的漏检率求平均值得到对数平均漏检率MR-2。
3.2 实验软硬件平台
本实验是基于64 位windows10 操作系统,中央处理器为Intel Core(TM)i5-10400F CPU@2.90GHz,内存RAM 为16G,GPU 为GTX1080,显存8G。python3.7,Pytorch1.2.0,Cuda 版本10.0,Cudnn 版本7.4.1.5。主要用到的第三方库包括numpy,matplotlib,cupy,opencv,PIL,os 等。
本文提出的改进faster R-CNN 算法骨架网络为ResNet50,在训练之前该骨架网络在ImageNet 上经过预训练,训练时使用预训练好的网络权值作为骨架网络ResNet50 的初始化权重。所有经过改进之后新添加的网络结构均使用Xavier 方法[59]对权重进行初始化。整个网络采用端到端的训练,整个网络使用自适应学习率的梯度下降方法Aadm 算法训练,动量(momentum)设为0.9,设置权重衰减系数为0.0005。在Caltech 数据集上,我们一共进行100 个世代(epoch)的训练,每个epoch 训练图片为4250 张,前50 个世代冻结ResNet50 的预训练权重进行微调,训练初始的学习率1×10-4,之后50 个世代解冻预训练权重训练,初始学习率设为1×10-5,学习率以指数方式衰减,系数为0.95。在Cityperson 数据集上,我们一共进行100 个世代的训练,每个epoch 的训练验证图片为2975 张图片,前50 个世代冻结ResNet50的预训练权重进行微调,训练初始的学习率为1×10-3,之后50 个世代解冻预训练权重训练,初始学习率设为1×10-4,学习率以指数方式衰减,系数为0.95。
3.3 基于注意力机制的网络实验与分析
本文针对遮挡问题引进了注意力机制并选择遮挡程度不同的若干子集实验。
如表1 所示为注意力机制Faster R-CNN 在Cityperson 数据集的实验结果,表中数据表示对数平均漏检率MR-2。引进注意力机制的方法在合理遮挡,严重遮挡,部分遮挡和几乎无遮挡四个子集上MR-2分别降低了3.6%,8.8 %,4.5%,0.7%,表明基于注意力机制的特征融合网络能够有效改善网络性能,尤其在行人遮挡严重的情况下。

表1 改进的Faster R-CNN 在Cityperson 数据集的MR-2 实验结果
如表2 所示为注意力机制Faster R-CNN 在Caltech 数据集的实验结果,检测网络在Caltech 数据集的检测效果整体好于Cityperson,主要是因为Cityperson 相比于Caltech,数据集场景更加多样,行人数量和行人密度更大,并且行人的遮挡程度更加严重,因此对检测器性能的抗遮挡性能有更高要求。由表中数据可知,采用基于注意力机制网络训练,在无遮挡、部分遮挡、严重遮挡子集上MR-2分别降低了2.6%,3.4%,6.5%,性能提升明显。

表2 改进的Faster R-CNN 在Caltech 数据集的MR-2 实验结果
4 总结与展望
本文以煤矿工作面遮挡行人为主要研究对象,基于Faster R-CNN 检测框架,对提升遮挡行人检测性能展开研究。针对遮挡行人可见区域有限,可见部分不完整,本文采用注意力机制模块(CBAM)对遮挡行人的特征从空间维度和通道维度增强其权重分配。在此基础上,将两种方法结合起来提出基于注意力机制的特征融合模块,增强遮挡行人的特征提取,获得了更好的检测效果。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
传媒评论(2017年3期)2017-06-13
河南科技(2015年8期)2015-03-11
上海理工大学学报(2012年2期)2012-03-20
