
无服务器计算技术研究综述*
2022-04-21 05:06杨柏蔼
计算机工程与科学 2022年4期
杨柏蔼,赵 山,刘 芳
(1.湖南大学设计艺术学院,湖南 长沙 410006;2.国防科技大学计算机学院,湖南 长沙 410073)
1 引言
云计算因提供了可靠实惠的远程计算资源服务而受到越来越多开发者的青睐,形成如基础设施即服务IaaS(Infrastructure as a Service)、平台即服务PaaS(Platform as a Service)和软件即服务SaaS(Software as a Service)等多种经典云服务模式[1]。这些模式存在诸如费用高、专业性要求高、基础设施管理事务繁杂(如IaaS),应用及微服务[2,3]部署、调度事务复杂(如PaaS),高度封装、难以拓展等问题。
为了兼顾基础设施集成、应用管理、性价比和可拓展性等指标,无服务器计算应运而生,这项新兴计算模式专注于基础设施透明化,减轻服务器管理负担,解耦应用程序,节省云服务成本[4],让开发者更关注自身业务创新[4]。
无服务器计算技术与服务蕴涵巨大潜力[5]:
(1) 其应用直接由函数组成,具有解耦、直观和动态的特点,带来了开发方式的创新;
(2) 基础设施管理事务向云服务提供商转移,对开发者透明,带来了运维方式的创新;
(3) 它能有效统一设备差异,灵活调度闲置计算资源,降低设备折旧率,避免能源空耗;
(4) 以函数运行时长作为计费的指标,具有较高的性价比,带来了服务运营方式的创新;
(5) 新兴技术社区将进一步发展出成熟的生态体系和函数应用市场。
在技术进步与市场需求的推动下,云原生计算基金会、亚马逊和谷歌等机构提供了丰富的服务器计算开源框架。学术届也在密切参与相关技术研究。本文对近年来无服务器计算的学术研究展开调查研究,整理了无服务器技术在软件工程、大数据、科学计算、人工智能和物联网等前沿领域的先进应用案例,同时简要介绍了当前流行的无服务器计算开源平台及其选型策略,并展开叙述了无服务器计算当前所面临的挑战及其对策。为无服务器计算技术的后续研究与应用提供参考。
2 概念定义与技术特性
2.1 概念定义
“Serverless”常与“Serverful”[6]一词相对,用于描述具有服务器透明化特性的技术与应用[7,8]。2014年Serverless首次以云服务概念被提出[9],它实现了应用开发者与服务器的分离,减轻了开发者在服务器管理、安全等方面的负担[10];另一方面,云提供商托管所有基础设施,消除了底层设备差异对上层应用造成的不良影响。
Serverless服务主要指函数即服务FaaS(Function as a Service),通常还包括了为FaaS配套的后端即服务BaaS(Backend as a Service)。
FaaS提供函数管理平台和运行平台[11],前者包含函数代码托管与调度工具,兼容多种主流编程语言与开发库;后者本质是改进的PaaS[12],维持一批函数专用容器,支持事件驱动、自动伸缩等能力。与传统中心化单体应用相比,FaaS函数应用由互相独立的函数显式编排组成,能直观地表现应用的业务逻辑控制流和数据流。
BaaS本质是后端服务(认证鉴权、安全控制和云存储等)的集成库,可适应多种应用场景,如支持移动应用的M-BaaS(Mobile BaaS)[13]。
表1总结了Serverless技术与其他经典云服务模式的对比。
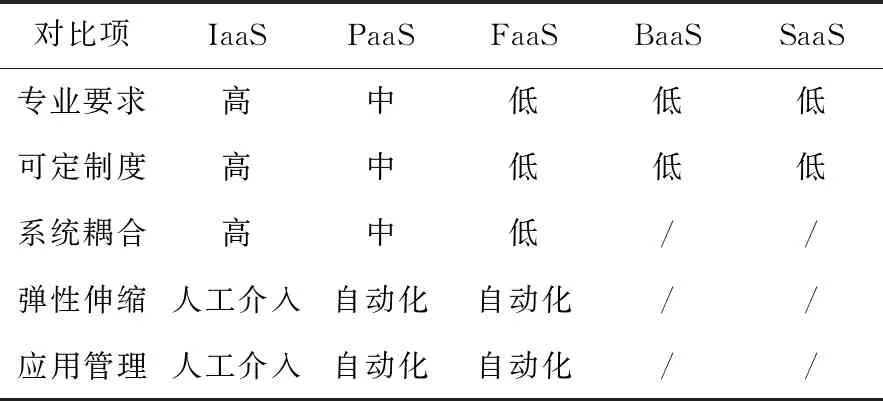
Table 1 Comparison of cloud services in various modes
2.2 系统架构与工作流程
Serverless系统主要由事件触发器、调度器、函数代码仓库、运行环境和BaaS平台组成。函数代码仓库托管开发者提交的函数及其触发规则。系统通过触发器-调度器结构实时监听与规则匹配的事件,调度器会把接收到的事件映射成指定函数,然后把函数实例调度到运行环境中执行。BaaS平台提供如云认证、云存储和云监控等集成服务。无服务器计算系统架构如图1所示。

Figure 1 Architecture of serverless computing
为了高效应对函数业务请求,提升函数运行效率,无服务器计算系统一方面缓存函数实例和计算结果,以减少读写频率与网络传输;另一方面直接采取从容器环境中复制活跃实例的方式进行快速扩容,节省重新生成函数实例的时间。
2.3 技术特性
Serverless系统具有以下重要技术特性:
(1) 基于函数。轻量化、细粒度和短周期的函数是使Serverless系统简易、稳定和保持高性能的基础。
(2) 无状态特性。函数实例互相独立,单个异常函数不影响系统正常运行,具备一定的容错能力。
(3) 自动伸缩。函数实例可以从活跃节点直接扩容,以应对批量事件,提升系统吞吐性能。
(4) 事件驱动。触发器定义并量化事件-业务的关系,提供实时事件监听服务。
(5) 高兼容性。系统能提供对异构基础设施、运行环境和编程方式[14]等多层次的兼容机制。
可以看出,Serverless技术既适用于短周期、访问量随机波动的即时服务场景,也适用于高吞吐、高并发、数据密集、算力有限和环境多样化等高要求应用场景。
3 国内外研究现状
3.1 Serverless关键技术研究现状
相比传统计算模式,Serverless技术的主要优势表现在极易实现的高并发、低时延等方面,因此,函数与容器的调度、资源管理和分布式应用实践等都是其重要研究内容。图2统计整理了Google Scholar近几年Serverless相关学术成果发表情况。可以看出,这些领域持续有稳定数量的相关成果产出,同时随着Serverless技术日益成熟,结合Serverless技术的创新应用研究成果的数量仍在逐年增加。

Figure 2 Academic achievements related to Serverless in recent years
(1)函数与容器调度相关技术研究。
由于早期Serverless系统底层基础设施封装程度较高,对函数应用的支持存在限制,如限定编程语言、依赖库加载瓶颈等,造成应用开发效率低、管理困难等问题。文献[15]列举了面向资源利用、面向响应时延、面向成本等多个不同目标的Serverless资源调度研究。文献[16]设计了支持容器感知的无服务器架构,定制化地创建和管理函数应用所在的容器镜像,以实现容器镜像实例的灵活调度,细化容器管控粒度,拓展了Serverless系统管控容器的能力。另外,该文献还设计了基于缓存感知的机制,有效缩短了容器镜像实例启动时间,协同容器并发与缓存可以提高系统吞吐量。
针对Serverless系统在容器环境中的安全性与运算性能均不如在虚拟机环境中的问题,AWS的研究人员设计了轻量的工作流管理系统 Firecracker[16,17],其本质是一个新型的虚拟机管理器,维持一批微型虚拟机,提供底层的安全隔离特性,结合虚拟化技术的可控性与容器化技术的兼容性,实现了多租户场景下容器、函数应用或其他计算工作流实体间的安全隔离;同时,面向更底层的系统设计也提升了Serverless系统的性能,最小化系统开销。目前,该系统已被集成到了AWS Lambda 产品中。
(2)资源管理相关技术研究。
Microsoft Azure团队在文献[18]中总结了函数应用与触发器类型、调用频率、调用模式和资源开销的关系与特征模型。为了解决实际工作场景中函数应用在调用频率、资源分配失衡时带来的资源管理瓶颈,该文献以特征模型为指导,采取了一系列实用资源管理策略:①自适应异构调用模式,从函数的实际调用频率和模式中学习函数实例的活跃时间;②预测触发条件,追踪函数调用时间,使函数实例能在调用前“预热”,以减少函数冷启动次数、时延和资源开销。
(3)分布式Serverless相关技术研究。
在异构的边缘环境中,早期Serverless系统由于节点算力有限、内部同步通信开销占用大等问题,并不能表现出比中心化Serverless架构更好的性能。文献[19]对中心化与分布式这2类重要的无服务器计算目标场景进行了深入研究,设计了混合的分布式Serverless服务机制。当边缘节点发生空间移动或配置变更时,Serverless系统以中心化的全局视角,为客户端提供最优的边缘无服务器计算环境;当客户端发生空间移动时,以局部的视角委托当前最优的服务器提供不中断的函数调度Serverless服务。
在实际应用场景中,智能手机、车载设备和无人机等终端在运行中会不断发生空间移动,因此需要实时保障终端与Serverless服务器间的连接。此外,来自不同提供商的边缘设备呈现出多样化的特征,导致多种设备混合组网时系统兼容性差。针对上述问题,文献[20]提出了Serverless和雾计算相结合的融合方案——雾函数,即在雾节点上部署分布式函数服务。该研究的主要优势有:①缩短服务端与客户端的空间距离,降低服务时延,在近场应用场景中支持弹性伸缩和高容错;②函数实例可以在雾节点之间转移,当设备发生空间移动时,系统定位出空间上更近的雾节点,将函数实例与服务连接转移到新的环境中,实现业务的无缝衔接;③借助容器技术,模糊各类底层边缘设备和环境的差异性,解决系统兼容问题,保证使用者对基础设施无感。
3.2 开源框架
云原生计算基金会致力于推广开源容器技术在云计算上的应用,提供了Kubernetes[21]等众多项目,近年来也在积极布局Serverless生态[22],文献[23]指出,65%的受访者表示在用或已关注,公有云Serverless服务平台占比63%,其余为自建的私有云Serverless平台,一般通过开源的可安装式的集成框架[24]搭建。
(1)Apache OpenWhisk[25]。
OpenWhisk是IBM公有云Serverless服务 Cloud Functions的核心框架,是由IBM、Apache等机构提供的,可直接安装于各类物理机、操作系统和容器等环境,集成了Docker、Nginx和Kafka等组件,支持负载均衡、消息队列等拓展功能。OpenWhisk基于订阅源服务的方式支持事件驱动特性,基于包管理的方式实现函数管理,是最完整的Serverless解决方案之一,适用于构建以数据中心、大型云平台为基础的Serverless系统。
其技术优势表现在:①借助容器编排技术兼容多种底层环境,使用者对复杂的底层环境无感;②组件模块化,通过模块化集成套件,降低管理与监控复杂度;③订阅源服务支持丰富的事件源类型,包括消息源、传感器、聊天机器人和规划任务等;④包的管理与运行环境支持安全性与私有性。
(2)OpenFaaS[26]。
OpenFaaS框架旨在提供轻量易用的微服务与函数服务平台[27]。为了兼容容器技术生态,减少系统重复配置,OpenFaaS基于Kubernetes的环境运行,并通过Kubernetes自定义资源特性实现了大部分内部组件。
OpenFaaS系统具有体量小、概念简单、依赖的第三方服务组件少等优点,适用于如小微型分布式应用等在设备算力与网络资源有限的场景。为了方便开发,还提供了模板系统和函数商店,受到大量中小型团队的欢迎。
(3)Knative[28]。
Knative是由Google、Pivotal和SAP等团队提供的,位于Kubernetes生态的应用服务层,其内核完全基于Kubernetes扩展实现,提供函数服务与微服务运行环境。Knative旨在解决混合云场景,是为应对混合云场景而提出的标准化Serverless架构,所提供的高兼容度的解决方案有利于实现跨平台业务迁移、自动化混合部署、分布式应用构建、消除提供商锁定等目标。目前,Knative已实施于Google、Pivotal和SAP等机构的Serverless平台。
表2从项目背景、架构环境与组件、应用场景等方面对上述开源框架进行了对比。

Table 2 Comparison of OpenWhisk,OpenFaaS and Knative
3.3 现有公有云Serverless服务
2014年AWS率先发布Amazon Lambda,随即国内外主要公有云提供商相继推出了Serverless/FaaS服务[29,30],如表3所示。

Table 3 Comparison of Serverless/FaaS services in primary public cloud
4 应用案例
基于轻量化、低时延和高并发等特点,Serverless带来了开发方式与科研应用的创新,在软件工程、大数据处理、科学计算、机器学习和物联网IoT等领域得到了许多实践与研究,本节将展开叙述。
4.1 Serverless与新型系统开发
经典“Serverful”模式主要有客户端-服务器C-S(Client-Service)[31]和浏览器-服务器B-S(Brouser-Service)[32]2类。人机交互由C、B端负责,应用业务由S端的单体应用提供。
传统单体应用往往耦合度高、迭代与维护难度大、专业性要求高,当前面临创新的需要:①受限于移动设备的算力与能耗,移动即时应用面临轻量化和低能耗要求[33];②为了应对数据的汇总、监控和分发等需求,管理信息系统有着实时性能敏感、系统组成复杂等特性。随着产业转型与新增需求的推动,众多旧应用将面临改造或重构,成本低廉的Serverless服务被各类社会部门所采纳。
当前,陆良县田地玉米机械化程度不高,这是由玉米农业经济发展不均衡的客观现实决定的:一些大块田地多由农机合作社承包,他们自然有实力来选用先进的农业机械来实现玉米全程机械化,完成高质量、高效率的玉米种植机械操作。但一些小块田地,一方面是因为经济实力所限,难以选用到更加先进的农业机械,且一些大型玉米收获机在小面积田地中也很难得到充分施展,无法真正发挥全部性能,极容易造成粮食和资源浪费。
此外,随着互联网应用与大数据的规模不断扩大,人们面临更严峻的数据孤岛现象,尤其体现在传统文化、创新设计和现代科教等众多细分领域。为了打通数据孤岛,充分挖掘这些细分领域大数据的价值,人们有着强烈的在细分领域建设大数据平台的需求。以往构建大数据平台耗时长、成本高昂且专业要求高,而Serverless的出现为各类细分领域大数据平台的建设带来了机遇,使得从业者能更快速、更经济、更容易地构建大数据平台。
表4整理了Serverless在多个实际应用中的实施情况。

Table 4 Innovation application cases of Serverless
4.2 Serverless与大数据处理
大数据最显著的特征是持续扩大的数据规模及其复杂度,这对传统数据处理系统提出了挑战。为了解决吞吐率及算力瓶颈,除了纵向增加单台计算机的算力,研究人员还尝试以横向拓展的方式,组织分布式计算集群来处理数据。MapReduce[44]是该类模型中最经典的模型之一,其核心思想是先切割数据集,再执行多线程并发处理,降低单次作业的数据规模,以提升系统总体数据处理性能。
传统场景中,研究人员不仅要设计算法,还要额外安排大量时间管理众多设备,负责进程管理、负载均衡和系统容错等细节[45]。因此,研究人员尝试借助Serverless改变这一现状,文献[46]通过云端实现数据集、算法代码和运行环境的显式管理,同时Serverless的高并发特性免去了数据处理程序中复杂的多线程配置。文献[47]提出,在应对实时系统、物联网等数据密集型场景下动态连续的数据流时,同样可以先将数据流转换成有序且有界的数据块,再执行数据处理作业。
先对数据集进行切割然后再通过Serverless并发处理的思路可以推广到超大型文件处理领域,相关的研究与实践还有:Netflix视频转码系统[48]、可编程式视频处理框架Sprocket[49]、生化数据(DNA、RNA序列)分析平台[50,51]和高吞吐文件处理应用[52]等。
4.3 Serverless与科学计算
科学计算涉及数学计算、数字仿真建模和高性能计算等课题,具有高精度、高吞吐和高并发的需求。为了降低软件工程开发难度,研究人员把目光投向了Serverless技术。
文献[54]描述了一些借助Serverless平台实施的问题求解实验:(1)根据贝利-波尔温-普劳夫公式,计算指定精度的圆周率;(2)通过划分求解空间,批量运行SHA256穷举碰撞来破解密码。
可以发现,上述科学计算的实验中,实验人员先把原始问题分解为计算量更小且逻辑一致的单元问题,再并行求解各单元,最后汇总求出目标解。实验表明,相比于传统多线程单体应用,函数应用效率显著提高,且单元问题越简单、并发规模越大,效率提升越明显。
4.4 Serverless与机器学习
机器学习仍是近来人工智能领域最热门的研究课题之一,其核心工作是通过原始数据集构建达到目标精度的机器学习模型。随着训练样本规模不断增大,所需计算资源不断增加,资源管理和性能瓶颈成为其中不可回避的挑战。
现有机器学习框架在资源管理方面存在以下限制:(1)各类基础设施管理事务占据实验人员相当比例的工作量;(2)固定的、过度的资源配置使实验人员无法为计算集群准确设置资源的配额,导致资源浪费、负载不均。文献[55]在现有技术基础上提出了改进的机器学习平台,实现了云端托管算法代码和训练集,远程下发模型训练作业等支持。Serverless环境不仅支持计算节点与资源动态调度,且具备一定的容错能力。实验显示,相较于同等费用的虚拟机集群,该应用在同样的训练任务中节省了44%的时间。
在改进机器学习训练效率方面,文献[56]沿用了函数应用与大数据、科学计算结合的思路,先拆分原始训练集进行耗时更短的局部训练,得到较小的局部梯度计算单元,然后再将并行求解得到的局部梯度合并,经过多次迭代得到拟合结果。在给定内存、进程数和迭代次数的情况下,相比传统机器学习模型,该模型表现出更高的吞吐率和更低的时延。
4.5 Serverless与IoT、边缘计算
IoT系统通常由处在云端、边缘端的服务器以及大量终端设备组成。终端设备-边缘服务器、边缘服务器-云服务器等方向时刻进行着大规模的数据传输,这对系统时延、带宽等性能提出了巨大的挑战。异构的分布式终端与边缘服务器还涉及设备兼容、系统容错、弹性伸缩和服务质量等需求[57]。
因此,IoT-Serverless解决方案应运而生。文献[43]基于Serverless平台设计了跨越云-边-端架构的实时数据分析系统,结合了中心云的高性能算力、大容量存储以及边缘Serverless系统的高并发、低时延等优点,区分了基于时间敏感的多级的实时数据分析工作流。该文献还实现了由人体穿戴设备组网的实时人体数据分析系统,分别模拟了灾害与日常2类重要场景中人体关键数据实时分析的实验。
5 面临的挑战
5.1 缩容至零(Scale to Zero)问题
Serverless系统的高吞吐特性源自函数实例快速扩容机制。然而,当访问量降至零时,系统将释放全部函数实例与计算资源。若之后请求到达而运行环境中没有对应的活跃函数实例时,系统将重新生成该函数实例,该过程称为冷启动[58]。相比已有实例的快速扩容机制,冷启动存在着不可忽视的时延问题。
问题的关键在于延长函数实例的活跃期或采用缓存技术支持失活实例的热启动。当请求再次到达时,系统跳过检索仓库与生成实例的环节,直接从缓存中检出已有的函数实例副本,缩短响应时延。文献[59]将空闲的尚未释放的容器节点和函数实例组织成队列结构,以提高缓存检索效率,减小系统时延。文献[60]提出一种通过管理冷启动的信号标识来控制函数调度的方法,根据函数依赖关系和冷启动次数等信息提前指示函数实例的异步加载,减小函数实例启动时延。由于缓存组件容量有限,存在超时失效机制,因此,仍需解决诸如函数依赖预加载策略、请求事件预测等相关问题。
5.2 数据调度与缓存性能瓶颈
函数运行伴随着数据传输,当数据源与函数运行环境在网络、地理空间上相距较远且数据集规模足够大时,则性能瓶颈出现在数据集的调度与传输上,造成严重的网络负载与时延。文献[5]把规模小得多的函数文件传输到数据源附近的环境中运行,从而降低网络负载。然而该方法只有函数计算结果规模远小于输入数据集时才有提升效果。该文献也遗留了分布式多数据源场景中数据传输、流式Serverless函数计算等未解决的问题。
引入缓存组件能有效提升数据处理性能,因此还需要研究适用于Serverless系统的动态分布式数据集缓存策略。当前,云提供商会为每一个运行环境提供可“就地”使用的数据缓存服务,而这种方法价格不菲,且尚未解决多函数-多数据集异步协作、分布式负载均衡等场景中的缓存需求。
5.3 触发器-调度器性能瓶颈
触发器-调度器是Serverless系统重要结构,通常由API网关和调度队列实现,负责事件监听、任务分发等作业。对比中心化与分布式2种调度架构,前者暴露出吞吐瓶颈,而后者存在自治节点负载不均的问题[61]。文献[62]实现了总体负载均衡的分布式调度架构,在并行计算单元队列的基础上设置全局负载均衡器,实时进行队列负载监控和健康检查,当队列容量饱和或异常时,当前队列中的任务可以转移到其他队列,以兼顾负载均衡和吞吐性能。
5.4 系统安全
文献[63]列举了目前应用于Serverless系统的安全措施:(1)采用JWT(JSON Web Token)、SSL/TLS(Secure Socket Layer/Transport Layer Security)等网络通信加密手段;(2)采用云认证方式的租户隔离与管理;(3)在API网关处设置防火墙;(4)借助Serverless服务自身的并发机制来分析和探测可能的网络攻击。
值得注意的是,Serverless的特性也带来了一些安全隐患。攻击者可以通过分析暴露的单个函数行为而逐步推导出整个函数应用的安全漏洞;高并发特性给资源耗尽攻击提供了可能,致使系统资源配额(函数最大并发、缓存上限和带宽上限等)被恶意占用并耗尽,造成系统崩溃。由于Serverless基于容器技术,不可避免地涉及了容器领域的安全难题,例如熔断攻击、幽灵攻击等[64]。
5.5 生态体系
Serverless技术生态的构建需要软硬件的支撑。关于Serverless应用调试工具[65]、函数依赖管理工具等研究已经取得可观的成果,但实际应用场景中,异构多样化的底层基础设施、云服务平台和编程语言等在Serverless上的兼容方案尚不成熟。现有的大部分开发工具库还不能直接迁移到Serverless平台上使用。除软件体系外,Serverless也需要相关硬件支持,文献[66]指出现有Serverless技术尚不支持GPU硬件加速,这在一定程度上影响了其在深度学习领域的发展。
形成统一的标准与定义是构建技术生态的重要环节。文献[67]提出争论,认为Serverless更像是PaaS的改进应用,性能提升有限,在应用开发部署、基础设施管理和下一代云架构等方面还有很多关于标准化内容需要进一步设计和讨论。文献[68]认为目前NIST(National Institute of Standards and Technology)标准中关于云计算的定义已经足够陈旧,可以考虑将FaaS、BaaS等众多新兴云服务模式收录其中,以适应当前云计算领域快速发展的需求。
6 结束语
Serverless技术相比于其他传统的云服务模式在基础设施管理、软件开发、并发性和专业性要求等方面存在诸多优势。在云计算快速发展和传统产业转型的背景下,合理选择Serverless作为应用开发的支撑技术将有助于业务的高效实现。本文首先介绍了Serverless系统架构与技术特性,整理了无服务器计算当前的研究现状;然后描述了无服务器计算在新型系统开发、大数据处理、科学计算、机器学习和边缘计算等前沿应用领域的实施案例;最后梳理了无服务器计算目前面临的较为突出的挑战。
猜你喜欢
中学生数理化·八年级物理人教版(2022年4期)2022-04-26
铁道通信信号(2020年10期)2020-02-07
读者·校园版(2019年24期)2019-12-10
电子制作(2019年20期)2019-12-04
北京航空航天大学学报(2019年9期)2019-10-26
计算机测量与控制(2019年6期)2019-06-27
小朋友·聪明学堂(2015年8期)2015-11-30
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
