
基于广泛激活深度残差网络的图像超分辨率重建
2022-04-21 06:52王凡超丁世飞
智能系统学报 2022年2期
王凡超,丁世飞,2
(1.中国矿业大学 计算机科学与技术学院,江苏 徐州 221116;2.矿山数字化教育部工程研究中心,江苏 徐州 221116)
如今,图像处理技术和信息交互快速发展,图像作为极其重要的信息载体,在公共安防、医学诊疗、卫星遥感等应用领域中愈发重要,但环境和噪声等因素的干扰,导致图像出现质量低或者细节的纹理信息缺乏等问题[1]。图像超分辨率(super resolution,SR),特别单图像超分辨率(single image super-resolution,SISR),几十年来受到广泛关注。单图像超分辨率为了通过技术手段将低分辨率(low-resolution,LR)图像重新构建为高分辨率(high-resolution,HR)图像,使其具有良好的高频、纹理和边缘信息。经过几十年发展,图像超分辨率逐渐被分为基于插值[2-3]、基于重建[4]和基于学习[5]三大类。
基于插值和重建超分辨率算法属于传统算法,都运用经典的数学模型算法,但随着放大因子的增大,这两种算法提供的用于重新构建高分辨率图像的细节信息资源不足的弊端逐渐显露,使得这些传统算法很难达到重建高频信息的目的。
深度学习高速发展以来,图像重建领域也开始使用深度学习模型来完成特定任务。2014 年,Dong 等[6]最先将卷积神经网络应用到图像超分辨率任务上,提出了超分辨率卷积神经网络(super-resolution convolutional neural network,SRCNN)模型,该模型进行端到端的图像对训练,在当时大大提高了重建效果,同时也开辟了超分辨率技术的新时代。2016 年,Kim 等[7]将超分辨率任务与残差思想进行结合,提出了使用非常深的卷积网络超分辨率(super-resolution using very deep convolution network,VDSR)模型,同时将网络的深度增加到了20 层,证明了深层网络能提取出更多的特征,取得更好的重建效果。Lim 等[8]通过对残差结构的改进,提出增强型深度超分辨率网络 (enhanced deep super-resolution network,EDSR)模型,通过移除批规范化处理[9](batch normalization,BN)操作,增加层数,提取更多特征,从而获得更满意的结果。
针对上述模型中存在的对不同层的图像信息使用率不足等问题,本文提出了融合感知损失的广泛激活的深度残差网络的超分辨率模型(widely-activated deep residual network for super-resolution combining perceptual loss,PWDSR),通过已训练的VGG 模型[10]提取激活前的特征,使用激活前的特征会克服两个缺点:第一,深层网络中,激活后得到的稀疏特征能够提供的监督效果非常弱,影响性能;第二,激活后的特征会使得重建后的图像与真实图像在亮度上有所差异。融合感知损失更着眼于纹理而不是目标物体。
本文的主要贡献包括以下方面:
1)使用权重归一化代替批量归一化,提高了学习率和训练、测试准确率;
2)使用预训练的深度模型提取激活前的特征得到感知损失,通过构建的图像与真实图像计算对抗损失,并结合图像的像素损失,构建了新损失函数;
3)使用全局跳跃连接避免梯度消失的问题,促进梯度的反向传播,从而加快训练过程;
4)实验证明了本文提出的损失函数改进在不同数据集上可以取得更好的评价指标,在主观视觉效果也有所提高;
5)本文提供了高倍重建任务中优化损失函数、调整残差块等新的研究方向。
1 相关工作
1.1 超分辨率网络
从超分辨率卷积神经网络[6](SRCNN)首次提出端到端卷积神经网络作为新的映射方式开始,超分辨率与卷积神经网络模型越来越密切。
1.1.1 上采样
超分辨率卷积神经网络[6](SRCNN)对图像进行上采样,在高分辨率特征空间上计算卷积导致其效率是低分辨率空间的S2倍(S为放大因子),因此效率低下。另一个有效的替代方案是子像素卷积[11](sub-pixel convolution),该卷积比反卷积层引入更少的伪像误差。
1.1.2 标准化
从3 层的超分辨率卷积神经网络[6](SRCNN)到160 层的多尺度超分辨率网络[8](multi-scale deep super-resolution,MDSR),图像超分辨率网络越来越深入,训练变得更加困难。批量归一化[9](batch normalization,BN)在许多任务中能解决训练困难的问题,例如SRResNet[12](super-resolution residual network)中使用了批量归一化。
BN 通过再次校准中间特征的均值和方差来解决训练深度神经网络时内部协变量偏移的问题。简单来说,如果忽略BN 中可学习参数的重新缩放,那么训练期间可用训练小批量的均值和方差对每一层的特征进行归一化:

式中:xB是当前训练批次的特征,它是一个较小的值用来避免零除。然后将一阶和二阶统计信息更新为全局统计信息:
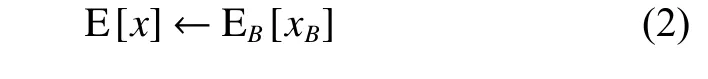

其中←表示分配移动线。这些全局统计信息将用于标准化:
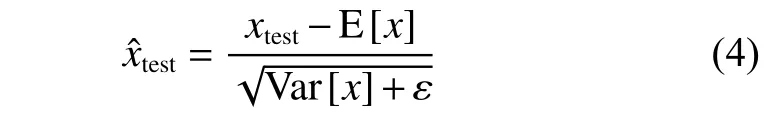
但BN 用于超分辨率任务时存在以下问题:1)图像SR 通常仅使用较小的图像块(48×48)来加快训练速度,小图像块的均值和方差相差很大,影响统计数据;2)图像SR 网络中没有使用正则化器会过度拟合训练数据集;3)图像SR 网络的训练和测试时使用不同公式会降低密集像素值预测的准确性。
1.1.3 跳跃连接
跳跃连接在深层神经网络中具有优良表现,其可以兼顾低级特征和高级特征。非常深的卷积网络超分辨率[7](super-resolution using very deep convolution network,VDSR)模型使用全局跳跃连接。残差密集网络[13](RDN)使用所有卷积层的分层特征。
1.1.4 分组卷积和深度可分离卷积
分组卷积将特征按通道划分为多个组,并分别在组内执行卷积,然后进行串联以形成最终输出。在组卷积中,参数的数量可以减少g倍,其中g是组数。
深度可分离卷积是深度非线性卷积(即在输入的每个通道上独立执行的空间卷积),然后是点卷积(即1×1 卷积)。也可以将其视为特定类型的组卷积,其中组数g是通道数。
1.2 广泛激活的深度残差网络
广泛激活的深度残差网络[14](widely-activated deep residual network for super-resolution,WDSR)在ReLU 激活层之前扩展特征,同时追求不会额外增加运算量。该模型压缩残差等价映射路径的特征,同时扩展激活前的特征,如图1 所示,并与增强型深度超分辨率网络[8](EDSR)中的基础残差块(图1(a))进行对比。WDSR-A 中的(图1(b))具有细长的映射路径,在每个残差块中激活之前都具有较宽的(2~4 倍)通道。WDSR-B(图1(c))具有线性低秩卷积堆栈,同时在不额外增加运算量的情况下加宽激活范围(6~9 倍)。首先使用1×1 卷积核增加通道数,在ReLU 激活层之后使用有效的线性低秩卷积,用两个低秩的卷积核替换一个大的卷积核(1×1 卷积核降低通道数,3×3 卷积核执行空间特征提取)。在WDSR-A 和WDSRB 中,所有ReLU 激活层仅应用于两个较宽的功能部件(具有较大通道的功能部件)之间。
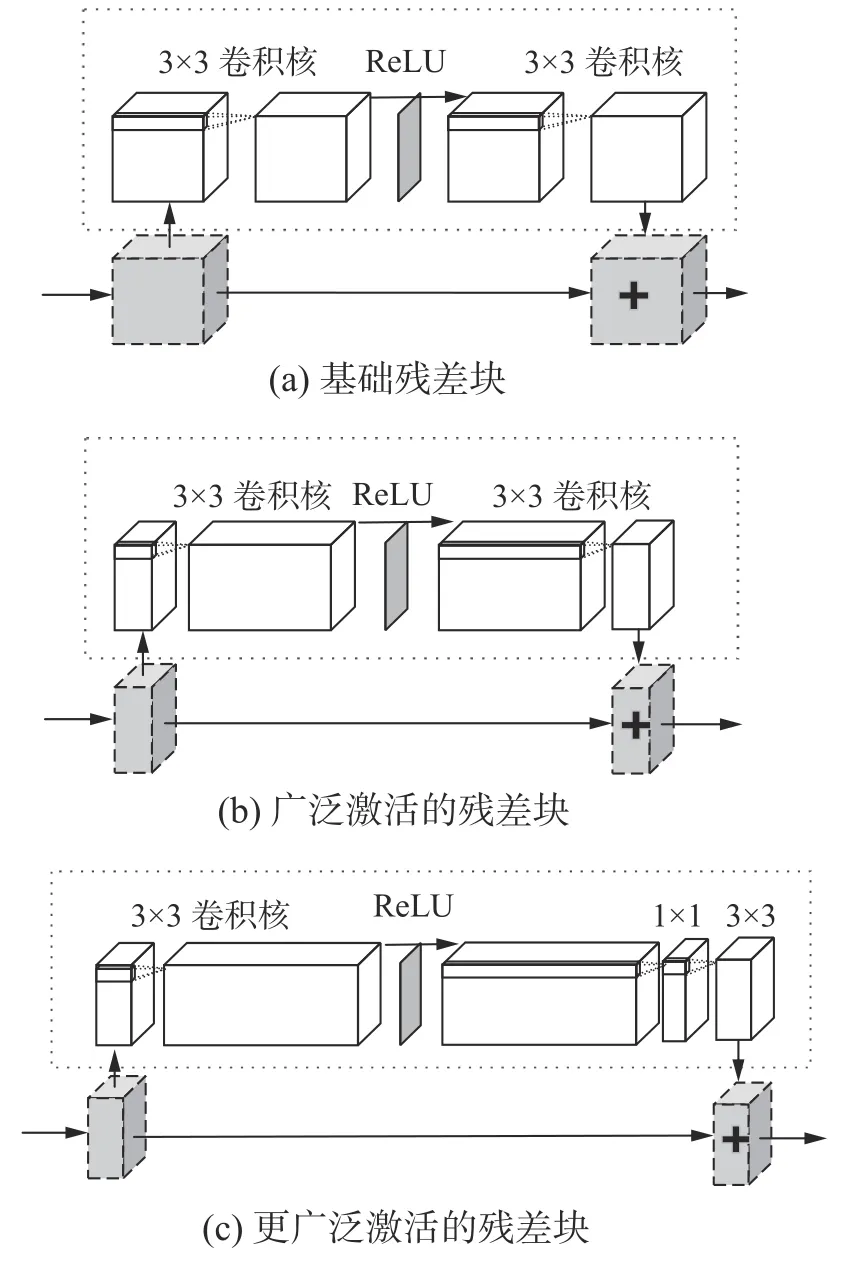
图1 广泛激活的残差块与基础残差块的对比Fig.1 Comparison of the residual block with wide activation and the original residual block
2 本文模型
受增强型超分辨率生成对抗网络[15](enhanced super-resolution generative adversarial networks,ESRGAN)中使用感知域损失的启发,本文针对广泛激活的深度残差网络存在对不同层级图像信息使用不足的问题,引入感知域损失,通过调整损失权重进行优化。本文网络模型如图2 所示。
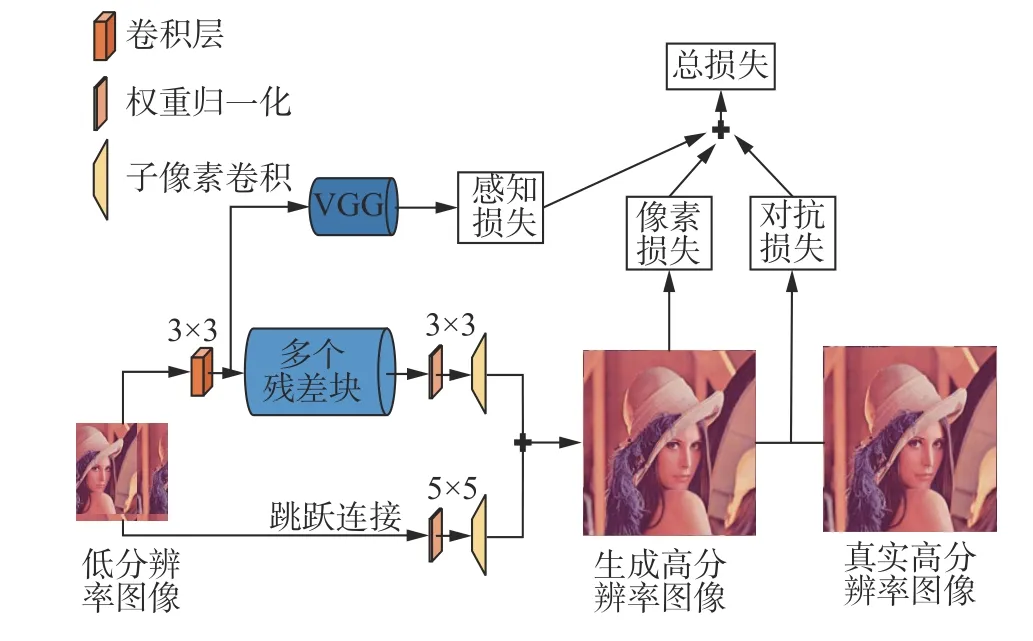
图2 融合感知损失的广泛激活的深度残差网络的超分辨率模型Fig.2 Widely-activated deep residual network for superresolution combining perceptual loss
本文调用已训练的VGG19 模型作为特征提取器。VGG 网络模型[10]如图3 所示。
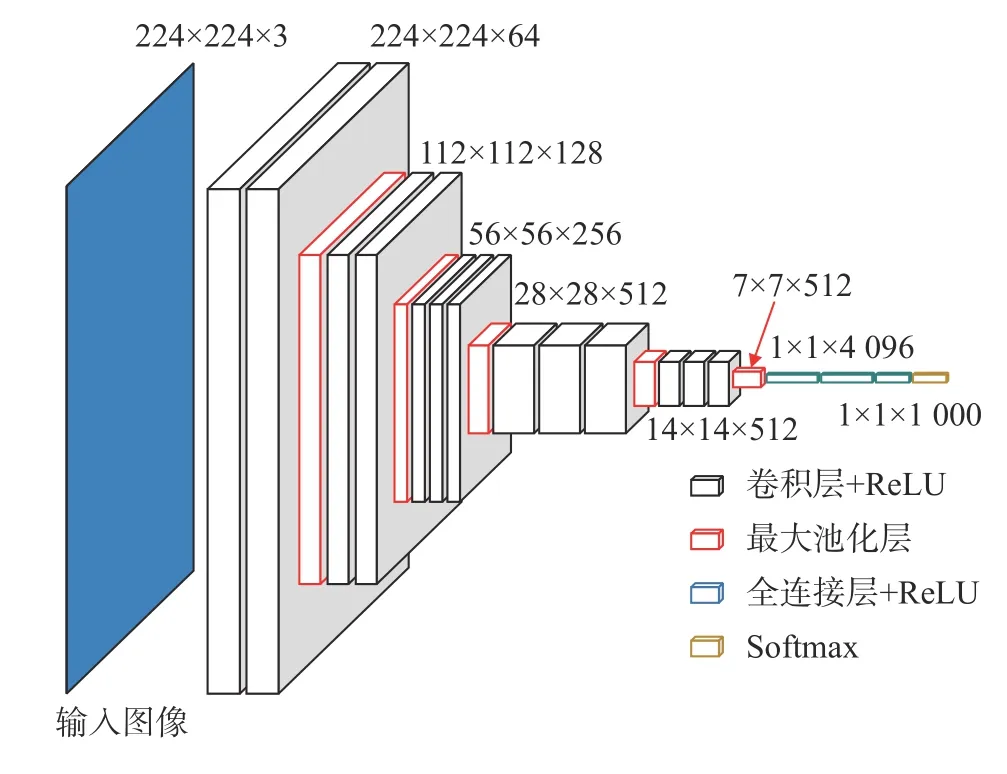
图3 VGG 结构模型Fig.3 VGG structure model
2.1 权重归一化
由于批量归一化干扰图像超分辨率的准确性,故本文使用权重归一化(weigh normalization,WN)来代替批量归一化。权重归一化是神经网络中权重向量的重新参数化,将这些权重向量的长度与其方向解耦,使其不会在小批量中引入示例之间的依赖关系,并且在训练和测试中具有相同的表示形式。输出y的形式为

式中:w是k维权重向量;b是标量偏差项;x是输入的k维向量。WN 使用以下参数重新参数化权重向量:
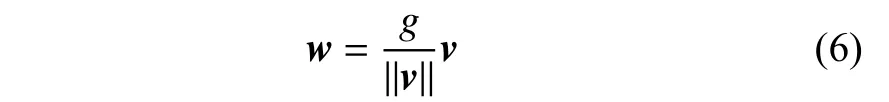
其中,v是一个k维矢量,g是一个标量,||v||表示v的欧几里得范数。通过这种形式化,得到||w||=g,而与参数v无关。对于图像超分辨率,WN 只是一种重新参数化技术,并且具有完全相同的表示能力,因此不会影响准确性。同时,WN 可以提高学习率,并提高训练和测试准确性。
2.2 损失函数改进
模型重新构建图像的结果很大程度上取决于损失函数的选择,一般超分辨率模型选择平均绝对误差(mean absolute error,MAE)或者均方误差(mean-square error,MSE)作为优化的目标,原因是在测试时可以获得较高的评价指标,但是在进行8 倍等大尺度的超分辨率重建任务中,重新构建的图像缺失大量高频信息,导致构建的图像不能达到视觉要求。本文模型使用感知损失函数lp,像素损失函数l1和对抗损失函数lg,通过配置3 种损失函数不同权重使其更好地对高频信息进行重新构建,总损失函数可表示为
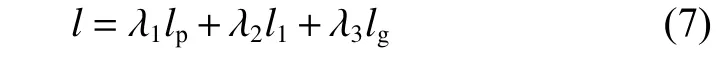
其中,λi代表调节各个损失项权重的正则因子,i=1,2,3。
为了在重建时保证重建图像与对应低分辨率图像在低频部分保持图像结构的一致性,像素损失使用平均绝对误差,公式为
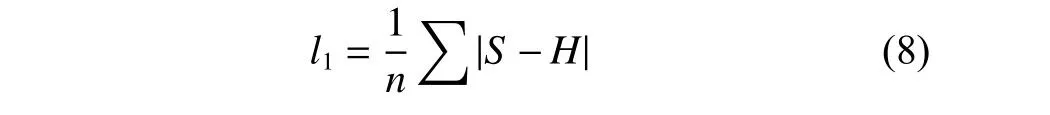
式中:S代表生成图像;H代表真实高分辨率图像;n代表网络超参数batch 的大小。
根据生成对抗网络的思想,在网络重建出一幅高分辨率图像之后,与其对应真实高分辨率图像进行比较计算,假设N个batch,生成n个标签,公式为
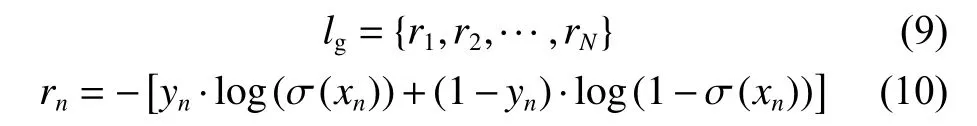
其中,σ(xn)为sigmoid 函数,可以把x映射到(0,1)之间:
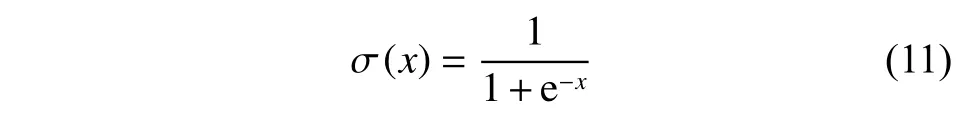
本文使用的特征是预训练的深度网络激活层前的特征。公式为
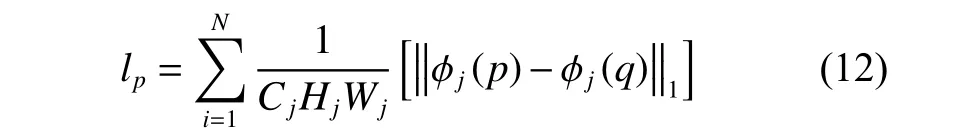
式中:p、q分别代表真实高分辨率图像和生成图像;φ表示预训练的神经网络;j表示该网络的第j层;Cj×Hj×Wj为第j层特征图的形状,使用的是每个卷积模块的激活值。
为确定损失函数中不同分量的权重值,本文进行了参数实验,根据收敛情况确定权重值,图4~6 分别为感知损失、像素损失、对抗损失随权重的变化曲线,损失函数收敛到最小值时对应值即为正则因子λi权重值,i= 1,2,3。

图4 感知损失收敛曲线Fig.4 Perceptual loss convergence curve
PWDSR 算法描述如下:

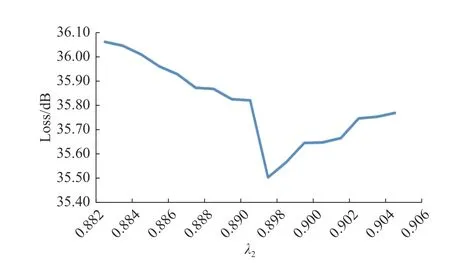
图5 像素损失收敛曲线Fig.5 Pixel loss convergence curve
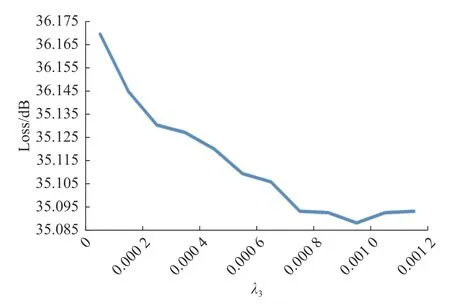
图6 对抗损失收敛曲线Fig.6 Adversarial loss convergence curve
3 实验设置
本实验在Windows 10 操作系统中使用PyTorch 深度学习框架,Python 版本为3.7.6,硬件配置为Intel(R)Core(TM)i5-7300HQ CPU @ 2.50 GHz,24 GB 内存,显卡为NIDIA GeForce GTX 1 050 Ti,使用CUDA 10.2 + cudnn 7.4.1 进行GPU 加速,在训练过程中,采用Adam 梯度下降算法,设置初始学习率为0.001,模型的epoch 设置为200,每10 次保存一次网络模型。
3.1 数据集
DIV2K 数据集是用于NTIRE 大赛的标准数据集,该数据集包含1 000 张2K 分辨率的高清图像,其中800 张作为训练数据集,100 张用于验证,100 张用于测试。该数据集还包含高清分辨率图像对应的低分辨率图像(使用插值法获得)便于训练。本文中,将DIV2K 数据集中编号1~800 的图像作为训练集,编号801~900 的图像作为验证集,编号901~1 000 的图像作为测试集,另选Set5、Set14 为测试集进行对比。Set5 为5 张动植物的图像,Set14 数据集包含14 张自然景象的图像。
3.2 评价指标
图像超分辨率效果的客观评价指标为峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似性(structural similarity,SSIM)。
3.2.1 峰值信噪比
峰值信噪比是图像超分辨率评价指标中使用最多的一种标准,其使用均方误差来对图片质量作判断。对于单色m×n的高清原图I与超分辨率得到的图片K,两者之间的均方误差公式为
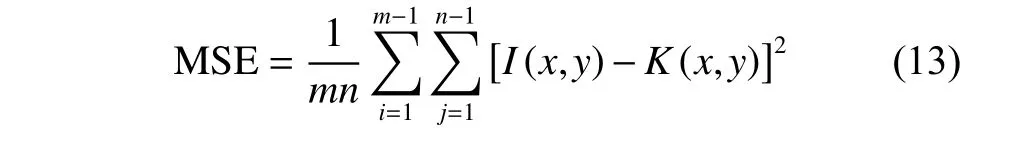
峰值信噪比的公式为

式中:MAXI表示像素最大值,如果采样点用8 位表示,则为255。可见,MSE 与PSNR 成反比,PSNR 越大代表重新构建的图像效果越好。
3.2.2 结构相似度
结构相似度是图像超分辨率重建的另一个应用较为广泛的测量指标,其输入是两张图像,其中一张是未经压缩的无失真图像y,另一张是重新构建出的图像x,那么SSIM 公式为
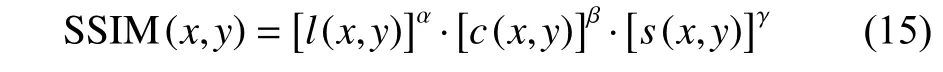
式中:α>0,β>0,γ>0,l是亮度(luminance)比较,c是对比度(contrast)比较,s是结构(structure)比较:
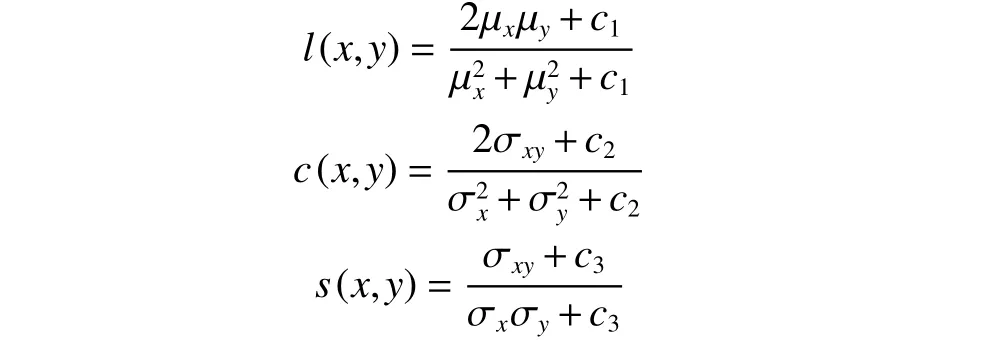
一般c3=c2/2,其中μx、μy表示均值。表示方差,σxy表示x与y的协方差。在实际应用中通常设α=β=γ=1,故可将式(15)简化为
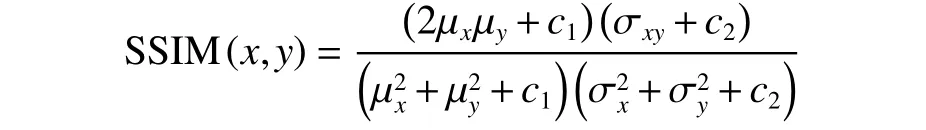
可以看出,SSIM 具有对称性,即SSIM(x,y)=SSIM(y,x),SSIM∈[0,1],SSIM 与输出图像和无失真图像的差距成反比,SSIM 越大图像质量越好。当两幅图像一模一样时,SSIM=1。
3.3 实验结果及分析
本实验从客观评价结果和主观评价结果两方面来表现改进模型的超分辨率能力,通过不同方式证明了本文提出的模型改进能优于其他模型。
3.3.1 客观评价结果
本文在3个公开数据集上测试了WDSR-A、WDSR-B 以及本文模型,分别计算在不同数据集上采用不同算法进行上采样2、3、4 倍时的PSNR和SSIM,对比结果如表1 所示。
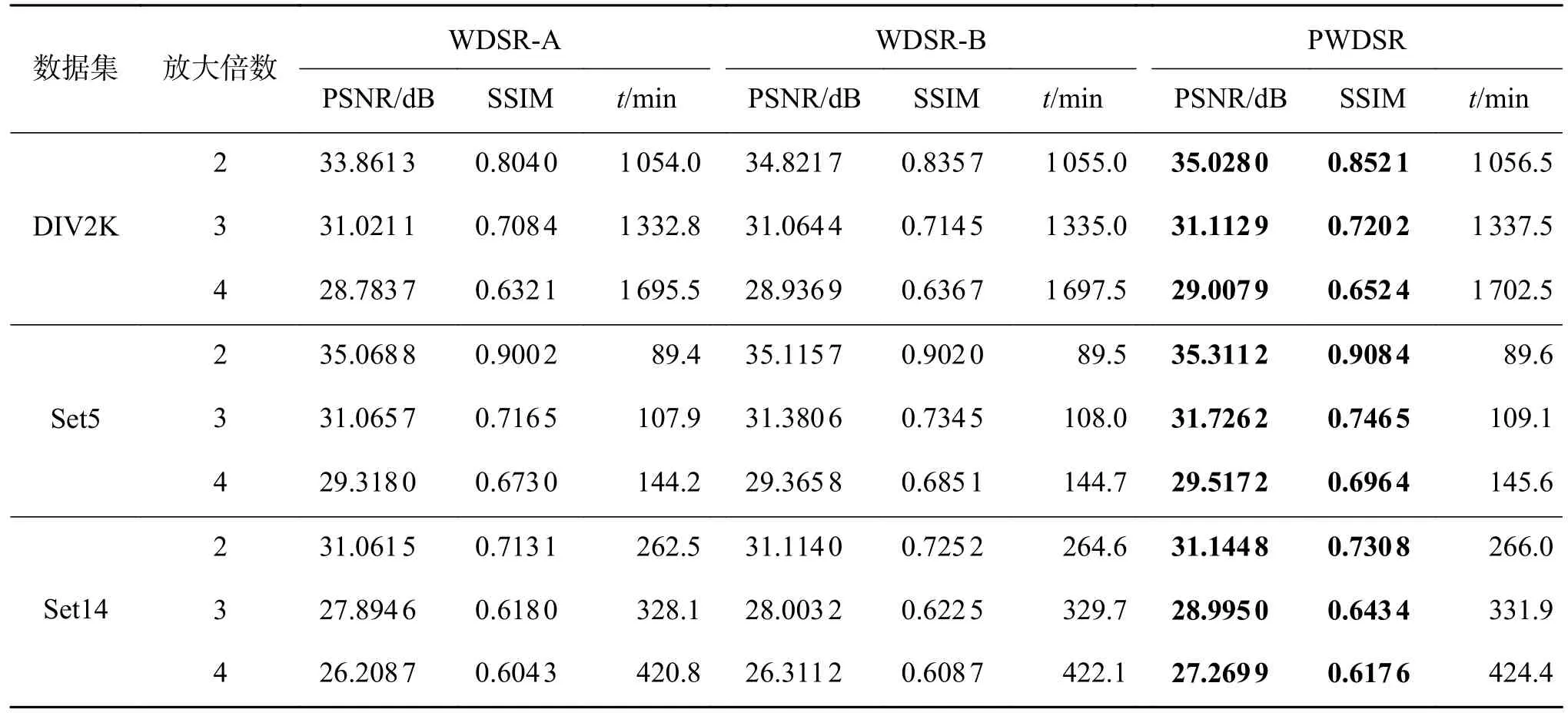
表1 在不同数据集上对比放大倍数为2、3、4 的重构图像的PSNR 和SSIMTable1 Comparison of PSNR and SSIM of 2,3,and 4 times reconstructed images on different datasets
从实验结果不难发现,更换不同数据集,本文提出的方法在2、3、4 倍重建任务中,都能够取得较好的PSNR 和SSIM 值,相较于其他模型,在客观指标上有所提升。
3.3.2 主观评价结果
本文分别选取了DIV2K、Set5、Set14 数据集中的3 张高分辨率图像进行放大倍数为2、3、4 的重构对比,为了更好地体现对比结果,本文将选取不同图片的不同细节进行放大对比:图7 选取DIV2K 数据集中图像绿叶的右端枝叶部分进行4 倍重建对比,图8 选取Set5 数据集中图像婴儿的左眼及上方部分进行3 倍重建对比,图9 选取Set14 数据集中图像女孩的左眼及下方部分进行4 倍重建对比。

图7 编号0803(DIV2K)4 倍重建视觉比较Fig.7 Visual comparison of SR results of “0803” (DIV2K)with scale factor 4
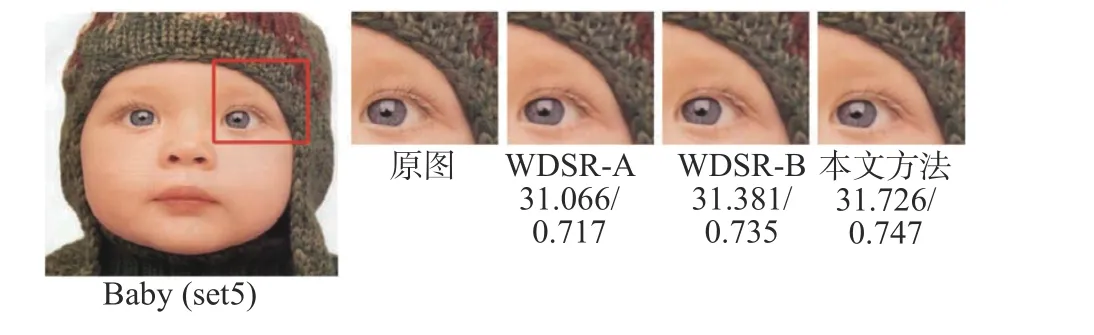
图8 baby(Set5)3 倍重建视觉比较Fig.8 Visual comparison of SR results of “baby” (Set5)with scale factor 3

图9 comic(Set14)4 倍重建视觉比较Fig.9 Visual comparison of SR results of “comic” (Set14)with scale factor 4
从视觉对比结果可以看出,3 种模型在2、3、4 倍的重建任务中都可以完成重建高分辨率图像,但本文提出模型在不同倍数重建任务中,能够重建出更好的纹理细节,达到更好的视觉效果,说明重新构建出的图像更接近原始高分辨率图像。
4 结束语
本文在广泛激活的深度残差网络的基础上,融合感知损失、对抗损失、像素损失,对整体损失函数进行优化,使用已训练好的VGG19 模型提取激活前的特征得到感知损失,避免了使用激活后的稀疏特征导致的性能不良等问题。本文使用权重归一化代替批量归一化,提高了学习率和训练、测试准确率。使用全局跳跃连接,避免梯度消失的问题,同时有助于梯度的反向传播,加快训练过程。从实验结果可以看出,本文提出的损失函数改进在不同数据集上可以取得更好的评价指标,在主观视觉效果也有所提高。在高倍重建任务上还有提升空间,后续工作以调整残差块和优化损失函数等方向进行展开。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
数学小灵通·3-4年级(2021年5期)2021-07-16
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
今日农业(2019年15期)2019-01-03
家庭影院技术(2018年9期)2018-11-02
共产党员(辽宁)(2015年2期)2015-12-06
读者·校园版(2015年19期)2015-05-14
