
对不平衡目标域的多源在线迁移学习
2022-04-21 06:51周晶雨王士同
智能系统学报 2022年2期
周晶雨,王士同
(江南大学 人工智能与计算机学院,江苏 无锡 214122)
迁移学习的主要目的是利用源域的知识来提高目标域的学习性能,多年来进行了广泛的研究[1]。使用一些分布相似的现有数据来提取有用的信息,可以解决目标域的训练数据有限或标记成本太高的问题。在许多实际应用中,与目标域分布相似的离线源域有多个,所以可以轻松地从这些源域中收集辅助信息。为了应对不同来源对与目标域的贡献不同的问题,许多复杂的基于提升方法的多源迁移学习算法[2-3]被设计。基于提升方法的算法根据贡献高低对多个源域附加权重来生成集成分类器,合理利用每个源域的知识。
多源迁移学习通过多个源域中提取的知识来改善目标域上的学习任务的性能,近年来得到了越来越多的关注。Qian 等[4]提出了一个多域鲁棒优化的框架,用于学习多个域的单一模型。Huffman等[5]提出了一种确定交叉熵损失和其他损失分布加权组合解的多源自适应算法。Peng 等[6]提出了多源域自适应矩匹配方法,利用多源域特征分布的矩进行动态对齐,将知识从多标记源域转移到未标记目标域。Kang 等[7]提出了一种在线多源多分类转移学习算法。这些现有的算法可以从多个源域迁移知识到目标域,而本文的目标是解决源域和目标域数据类别不平衡的多源在线迁移学习问题。
现有的大多数迁移学习工作都假设事先提供了源域和目标域的训练数据[8]。但是,在某些实际应用中,目标域的数据可能以在线的方式到达。近十年,在线学习[9-10]得到了广泛的研究。在线学习中,分类器在每个回合中接收一个实例及其标签,然后预测该实例,并根据预测结果和真实标签的损失信息更新分类器。Wang 等[11]提出一种基于最大最小概率机的迁移学习分类算法。Zhao 等[12]提出一种可以立即响应的且高效的在线学习算法来解决在线迁移学习任务。Wu 等[13]提出了一种具有多个源域的在线迁移学习算法,当目标数据到达时,多个源域分类器和目标域分类器同时做出预测,根据各分类器的权重组合最终预测结果,并更新各分类器的权重。
目前,大多数在线迁移学习都默认目标域的类别分布是平衡的,然而现实中存在很多不平衡的数据。例如,机器的故障诊断,医疗诊断以及军事应用等。在大多数现实世界的问题中,少数类实例的错误分类代价往往很大,减少少数类错误分类是至关重要的。处理不平衡数据集的方法可以分为对数据的采样方法[14]、成本敏感方法和算法级方法[15]。采样方法对数据集进行预处理,将类别修改至相对平衡。成本敏感方法对错误分类少数类实例的决策函数施加更大的惩罚。算法级的方法直接修改分类器来处理不平衡问题。
因此,本文提出一种针对目标域不平衡的多源在线迁移学习算法。其中,目标域每次到达一批数据。在算法中,从前面已经到达的批次中寻找当前批次样本的k近邻,形成种子和邻居对。然后在样本对之间的线段上适量生成合成的多数类样本,再合成少数类样本使当前批次的类别分布相对平衡。考虑到不同批次的样本之间的特征分布可能发生细微的偏移,生成样本时控制合成样本近似于当前批次中的样本。最后用新生成的样本去改进目标函数,然后再对当前批次的所有样本按序进行在线迁移学习,从而提升整体分类器对少数类的分类性能。此外,还分别设计了在目标域的输入空间和特征空间过采样的方法。在目标域的输入空间生成数据点来平衡类别分布,可以提高目标函数对少数类的分类性能,但也可能生成不代表非线性可分问题的数据点,影响函数精度。所以设计了在目标域特征空间过采样的方法,与文献[16]不同,本文的方法在特征空间生成数据点来训练在线的函数,生成少数样本会导致类别分布得更具代表性,可以克服非线性问题的局限。
1 在线迁移学习
简要介绍多源在线迁移学习算法HomOTLMS。HomOTLMS 根据预先给出的源域数据,在离线批处理学习范式中构建n个源域的决策函数(hS1,hS2,···,hSn)。而在线部分使用被动攻击算法(passive aggressive,PA)[17],在目标域上构造一个以在线的方式更新的决策函数hT,T为目标函数。对于当前到达的实例xj,计算目标域决策函数的铰链损失:

如果决策函数遭受非零损失,则根据式(2)更新目标域函数和添加支持向量:
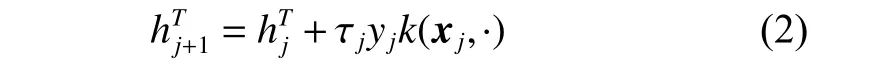
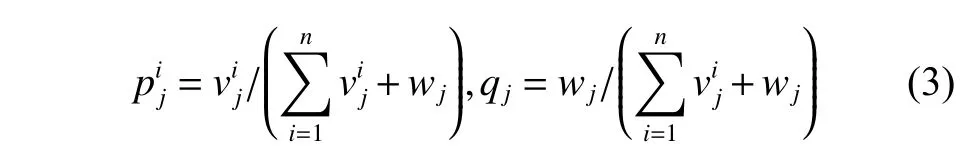
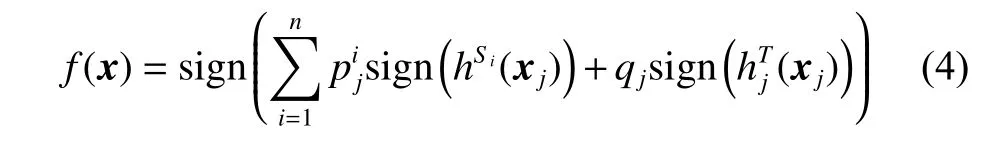
上述算法能够有效解决多个源域的在线迁移学习问题,但并不能应对目标域不平衡的情况。下面介绍了一种新的在线迁移学习方法,可以在在线预测的过程中,人工平衡目标域类别的分布,从而降低总体分类误差。
2 不平衡目标域的在线迁移学习
2.1 问题描述
在多源迁移学习的问题中,对于给定的n个源域,用DS={DS1,DS2,···,DSn}表示,目标域用DT表示。对于第i个源域DSi,源域数据空间用XSi×YSi表示,其中特征空间是XSi=Rdi。用X×Y 表示目标域的数据空间,其中特征空间是X=Rd。这里,源域和目标域共享相同的标签空间 YSi=Y={+1,−1}。
目标域采用被动攻击算法(PA)学习决策函数,当目标域的数据不平衡时,目标决策函数会更加偏向于多数类。若能在在线学习的过程中,扩充每个批次少数类的样本,就可能实现目标领域对少数类更准确的分类。考虑到目标域整体的样本个数有限,可以通过先扩增每个批次的多数类,然后再扩增少数类样本至平衡,提高目标域函数的整体分类性能,从而更好地实现知识迁移。
2.2 在输入空间过采样的在线迁移学习
本节提出一种称为OTLMS_IO(online transfer learning multi-source input space oversampling)的算法,该算法代表在目标域的输入空间进行过采样的多源在线迁移学习。OTLMS_IO 通过增加每个批次中多数类和少数类样本的个数来提升目标域函数的性能。
目标域的数据以在线的方式分批到达,每次到达多个实例。第b个批次到达的实例是,对于其中每个少数类实例,都以欧氏距离(式(5))为标准计算它到前面已经到达批次的所有少数类实例的距离,得到其k近邻。
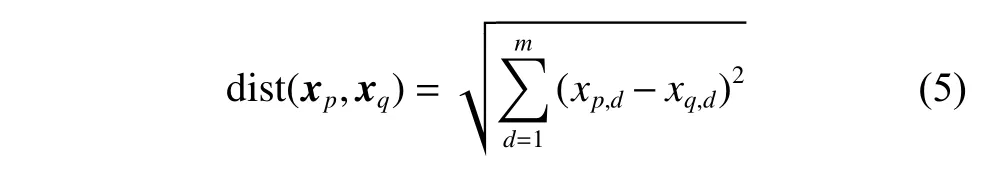
式中:xp是当前批次中的实例,称为种子;xq是前面批次中的实例,称为邻居,m是实例的维数。然后将种子和邻居组合成样本对,一共个,是当前批次b中少数类实例的个数。以同样的方式,可以得到当前批次中多数类实例形成的样本对个。从少数类和多数类的样本对中分别选取 min_num min_num 和ma j_nummaj_num个,用于生成新样本。maj_nummaj_num 的大小决定了当前批次生成样本和真实样本整体的规模,min_nummin_num使得当前批次类别平衡。根据式(6)在每个样本对之间的线段上生成新样本。

同时,考虑到不同批次样本之间的特征分布可能会发生细微的偏移,所以控制均匀分布的随机数δ ∈[0,0.5],使得生成的新样本更加靠近当前批次中的样本。
对生成的一共t个新样本分配相应的标签,在当前批次的样本训练之前,使用新生成的样本改进目标函数,根据式(7):

使用在线被动攻击算法可以轻松学得用新样本改进后的分类器,即根据式(2)对将铰链损失ℓ >0 的新实例都作为支持向量添加到支持向量集中。最后再使用集成决策函数(式(4))分别训练当前批次到达的所有实例,并按照上述方法对后面所有批次进行同样的操作可以得到训练好的集成函数。
2.3 在特征空间过采样的在线迁移学习
与在输入空间过采样不同,本节提出了一种称为OTLMS_FO(online transfer learning multisource feature space oversampling)的算法,该算法表示在特征空间过采样的多源在线迁移学习。目标域的函数通过核函数进行预测,所以OTLMS_FO 能利用与SVM 分类器相同的核技巧,合成样本利用特征空间中的点积生成而不需要知道特征映射函数φ(x)。特征空间生成数据点在高维的空间具有更好的线性可分性,可以用来改进目标函数。
OTLMS_FO 算法在目标域第b个批次的样本到达时,从中挑选出少数类样本和多数类样本。然后从前面已经到达的批次中分别找到当前到达批次中少数类和多数类样本的k近邻。由于是在特征空间中计算样本间的距离,需要将种子xp和近邻xq映射为特征空间的φ(xp)和φ(xq),然后计算两个实例之间的距离。特征空间中,两个实例之间的距离为
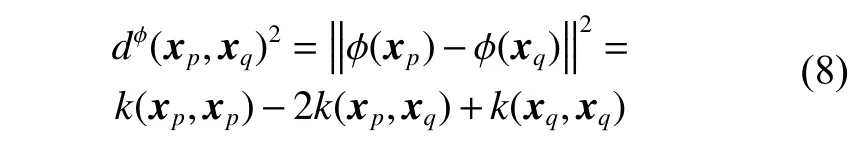
根据式(8)可以找到当前批次中的每个少数类样本的k近邻,种子和邻居组成的样本对构成集合,一共个,给少数类样本对分配+1 标签。然后以同样的方法生成当前批次多数类的集合,并分配−1 标签。从集合中随机选择min_num个少数类的样本对和maj_num个多数类的样本对,在特征空间中合成新的实例,生成新实例的式子可以写成:
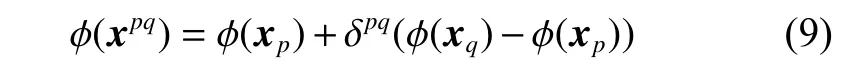
式中:δpq是一个0~0.5 的随机数,在特征空间同样控制生成的数据点更加靠近当前批次的样本,使得扩增的样本和当前批次中的样本的特征分布更加相似。
对当前批次的样本进行训练之前,先用生成的样本改进目标决策函数。最后使用集成决策函数(式(4)) 依次对当前批次的所有实例进行预测。然而,使用式(7)生成的新少数类实例利用通常未知的特征转换函数φ(x),所以新的合成实例 φ(xpq)并不能具体得到。目标域通过决策函数中支持向量的核函数计算两个特征空间中实例的内积来训练,可以将合成实例代入目标域决策函数的核函数中计算,其中核函数的计算分为2 种情况:
1)xj是合成实例,x是普通实例时,它们在特征空间的内积为
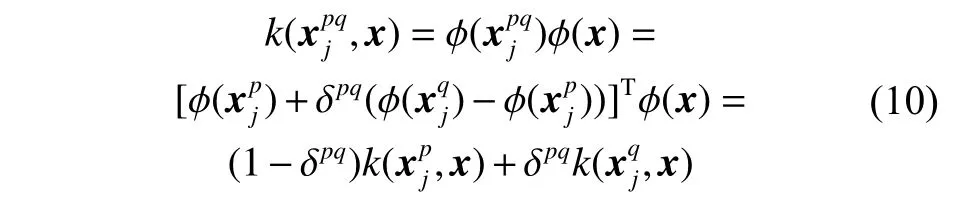
2)xj和x都是合成样本时,特征空间的内积:
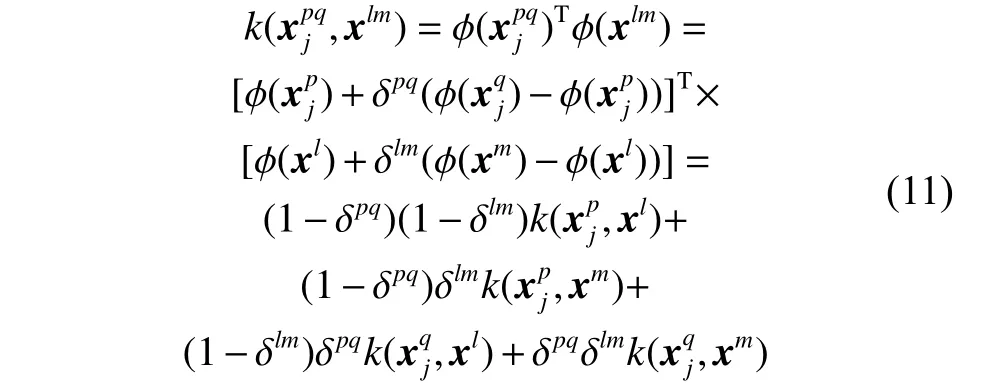
使用合成实例改进目标域决策函数,当铰链损失大于0 时,将合成实例作为支持向量添加到支持向量集,并且也能保持特征空间的可分性,即
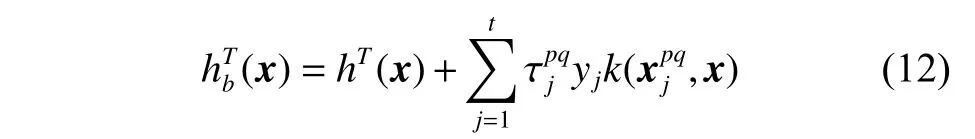
定理1在目标域的特征空间中添加合成样本同样能保证类别可分。
证明目标域函数由支持向量组成,可以表示为
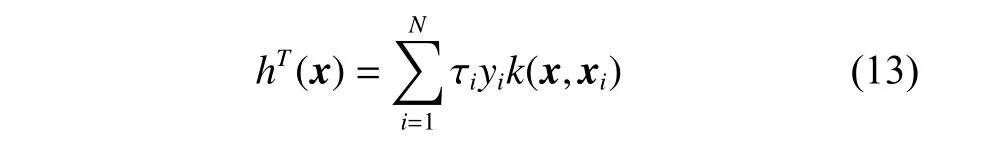
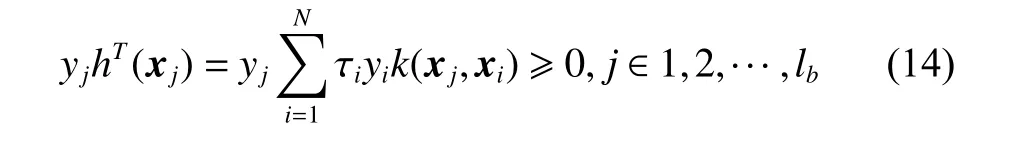
将式(9)生成少数类样本φ(xpq)代入目标函数:
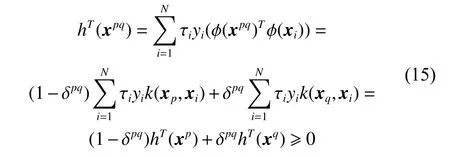
式中:hT(xp)和hT(xq)都不小于0,xp和xq都属于少数类;δpq∈[0,0.5]。
所以在目标域的特征空间中生成的样本同样可以保证类别可分。每批次生成的新样本都会优化目标函数在特征空间中的超平面,提高目标函数的性能,从而最终提高整体函数的性能。
2.4 算法描述和复杂度分析
OTLMS_IO 和OTLMS_FO 算法的步骤近似,下面提供OTLMS_FO 算法的算法描述和复杂度分析。
算法OTLMS_FO 的算法描述

2)输出训练好的集成决策函数(见式(4))。
上述算法中,①寻找k近邻的时间复杂度是O(3m1m2d+3M1M2d),其中m1、M1和m2、M2分别是当前批次和前面批次中的少数类和多数类,d是样本的维数。③使用新样本改进目标函数的时间复杂度是O(4svd),s是合成样本的总数,v是支持向量的个数。④训练当前批次真实样本的时间复杂度是O(2nvd),一共n个真实样本。在输入空间训练一个批次样本的复杂度是O(3m1m2d+3M1M2d+4svd+2nvd),整个目标域一共N个批次,所以总的时间复杂度是O(N(3m1m2d+3M1M2d+4svd+2nvd)),可以近似为O(N(m1m2d+M1M2d+svd+nvd))。
3 实验结果与分析
本文对提出的算法和在线迁移学习的基线算法进行了比较,并在多个真实数据集上进行了实验:Office-Home 数据集、Office-31 数据集和20Newsgroups 数据集。为了获得可靠的结果,在相同参数设置的前提下,通过更改测试实例的到达顺序来将每个实验重复10 次。结果表明,本文提出的算法比基线算法获得了更好的性能。
3.1 数据集介绍
3.1.1 Office-Home 数据集
Office-Home 数据集[18]由4个不同领域的图像组成:艺术图像(Art)、剪贴画(Clipart)、产品图像(Product)和现实世界图像(Real World),一共大约15 500 张图像。对于每个域,数据集包含65个类别的图像。在我们的实验中,将现实世界图像域作为目标域,其余3个领域作为源域。并在目标域中随机选择一个样本数小于50 的类别作为负类(少数类),选一个样本数大于80 的类别作为正类(多数类),3个源域也选取这两个类别,然后构成一个迁移学习任务。并对原始图片进行了预处理,每张图片都对应一个1×10 000 的向量。实验一共生成了30 组迁移学习任务。
3.1.2 Office-31 数据集
Office-31 数据集[19]是一个用于图像分类的迁移学习数据集。其包含3个领域的子集:Amazon(A)、Webcam(w)、Dslr(D),分为31个类别,共有4 652张图片。在Office-31 数据集中,不仅各个领域的样本总数不同,而且各个域内部类别分布也不平衡,所以可以通过不平衡方法处理Office-31 数据集,促使迁移学习效果提升。实验中,预处理数据集,每个图片都是1×10 000 的向量。将Webcam 作为目标域,其余两个域作为源域。然后选取Webcam 中的一个样本数多的和一个样本数少的类别构成一组迁移学习任务,一共生成了16 组任务。
3.1.3 20newsgroups 数据集
20newsgroups 数据集(http://qwone.com/~jason/20Newsgroups/)由大约20 000个不同主题的新闻组文档组成,这些数据被组织成20个不同的新闻组,每个组对应一个不同的主题,一共5个主题。例如:os、ibm、mac 和x 是comp 主题的新闻组,crypt、electronics、med 和space 是sci 主题的新闻组。其中comp 主题的新闻组标记为正例,而sci 主题的新闻组标记为负例,一共构成4个学习任务:os_vs_crypt、ibm_vs_electronics、mac_vs_med和x_vs_space。随机选择一个作为目标域,其余作为源域,一共构成4 组迁移任务。
3.2 基线算法和评价指标
为了评估算法的性能,将提出的算法和最新的几种方法进行了比较。在线被动攻击PA 算法是一种传统的在线学习算法[17],采用PA 作为基线方法,无需知识迁移。考虑到被动攻击PA 并非针对迁移学习问题而设计,通过使用在整个源域中训练过的分类器初始化PA,来实现PA 算法的一种变体,称为在线迁移学习的“PAIO”。还与一种著名的在线迁移学习算法HomOTLMS 进行了比较,该算法从多个源域迁移知识来增强目标域的性能。所有的算法均使用Python 语言实现和运行。
为了验证算法的可靠性,实验结果采用分类精度和G-mean 作为评价指标。其中G-mean 是正例准确率与负例准确率的综合指标。当数据不平衡时,可以评价模型表现,若所有样本都被划分为同一个类别,G-mean 值是0。表1 是二分类混淆矩阵,G-mean 的计算公式为
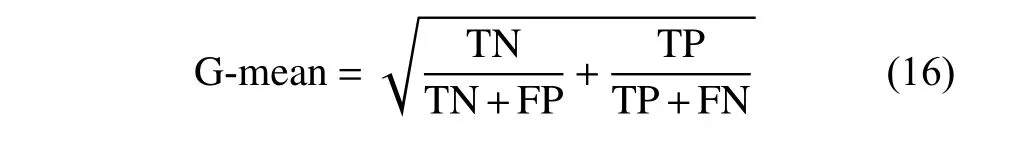

表1 二分类混淆矩阵Table1 Two-classification confusion matrix
3.3 实验结果及参数设置
3.3.1 参数设置
首先将OTLMS_IO 和OTLMS_FO 算法与Office-Home、Office-31 和20newsgroups 数据集上的所有基线算法进行比较。在3个数据集上,设置所有算法的折衷参数C为5,寻找近邻的k都设为3,并且设置多个分类器的权重折扣参数β=0.999。目标域使用高斯核,带宽 σ 搜索范围是 [10−2,102]。因为在不同的数据集中一些使算法达到最优的性能的参数往往是不同的,所以各数据集上的其他参数设置如下:在Office-Home 数据集中,为了使目标域整体的类别分布相对平衡,每批次过采样的少数类和多数类样本的个数分别是6 和2,其中 σ=31.6。在Office-31 数据集中,每批次过采样3个少数类和1个多数类样本,高斯核带宽 σ=31.6。在20newsgroups 数据集上,OTLMS_IO 和OTLMS_FO 算法每次过采样40个少数类和10个多数类样本,其中高斯核函数的带宽 σ=1.12。
3.3.2 Office-Home 和Office-31 数据集上的结果
表2 和表3 分别列出了在Office-Home 和Office-31 数据集上随机选取的4 组任务的数值结果,并从准确率和G-mean 指标对所有算法做出评价。其中,HomOTLMS、OTLMS_IO 和OTLMS_FO算法都优于PA 和PAIO 算法,这表明从多个源域进行知识迁移对目标域是有帮助的。从两种评价指标可以看出,OTLMS_IO 和OTLMS_FO 算法在应对不平衡的目标域都有着比所有基线更好的性能,这是因为目标域整体的样本量被扩充了,尤其是少数类样本,增加目标分类器对少数类的偏向。其中,OTLMS_FO 算法的性能要强于OTLMS_IO,因为OTLMS_FO 算法在特征空间扩增的样本使类别的分布更加近似。提出的OTLMS_FO 算法在训练当前批次的样本之前,会根据前面几个批次中的样本生成新样本,因为只在几个批次中就能创建新的样本,所以提出的算法能够保持很好的实时性。
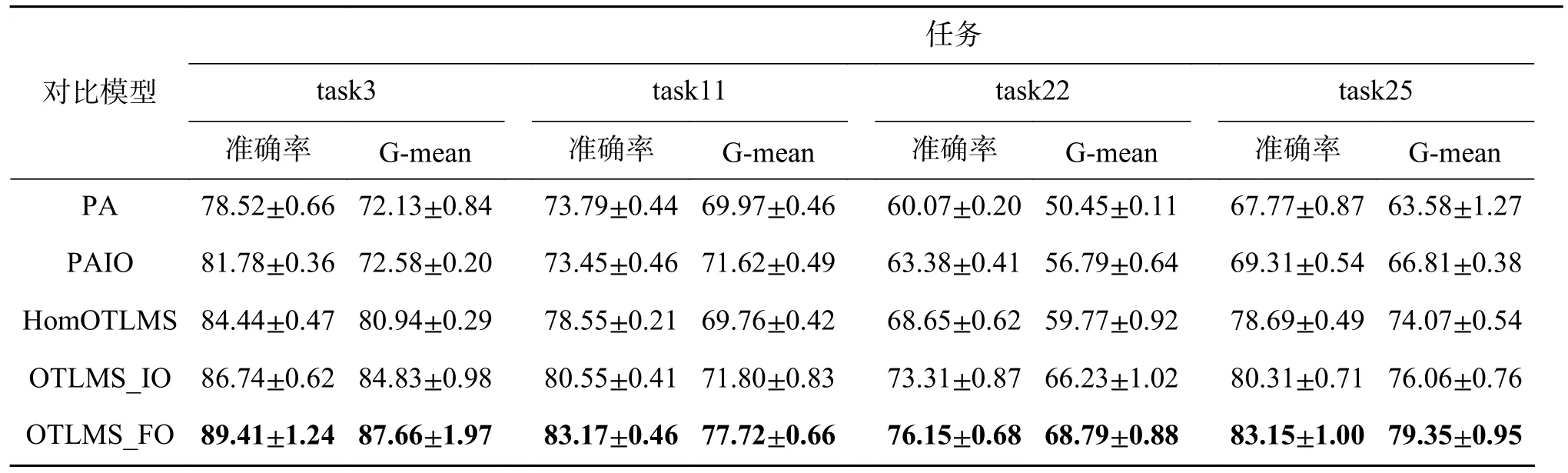
表2 在Office-Home 数据集上应用不同学习算法的结果 (平均±标准差)Table2 Results of different learning algorithms on the Office-Home dataset (mean±standard deviations)%
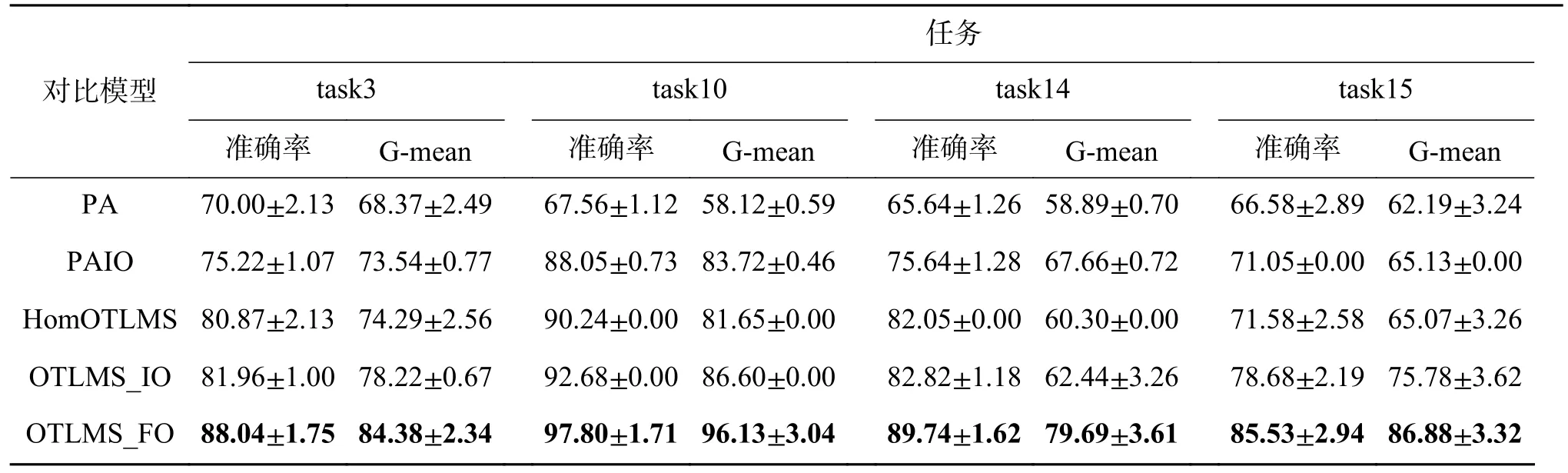
表3 在Office-31 数据集上应用不同学习算法的结果 (平均 ± 标准差)Table3 Results of different learning algorithms to the Office-31 dataset (mean±standard deviations)%
在Office-Home 和Office-31 数据集上分别实验了30 和16 组任务,由于受空间和可观测的局限,在图1 和图2 中分别给出了Office-Home 和Office-31 数据集上的PA、OTLMS、OTLMS_FO 的准确率,而忽略了其他算法的结果。在大多数任务上,使用多源迁移的OTLMS_IO 和OTLMS_FO的性能都要优于PA。并且在特征空间对目标域过采样的OTLMS_FO 算法性能要更好,证明了本文提出的算法更加适用于不平衡的目标域。
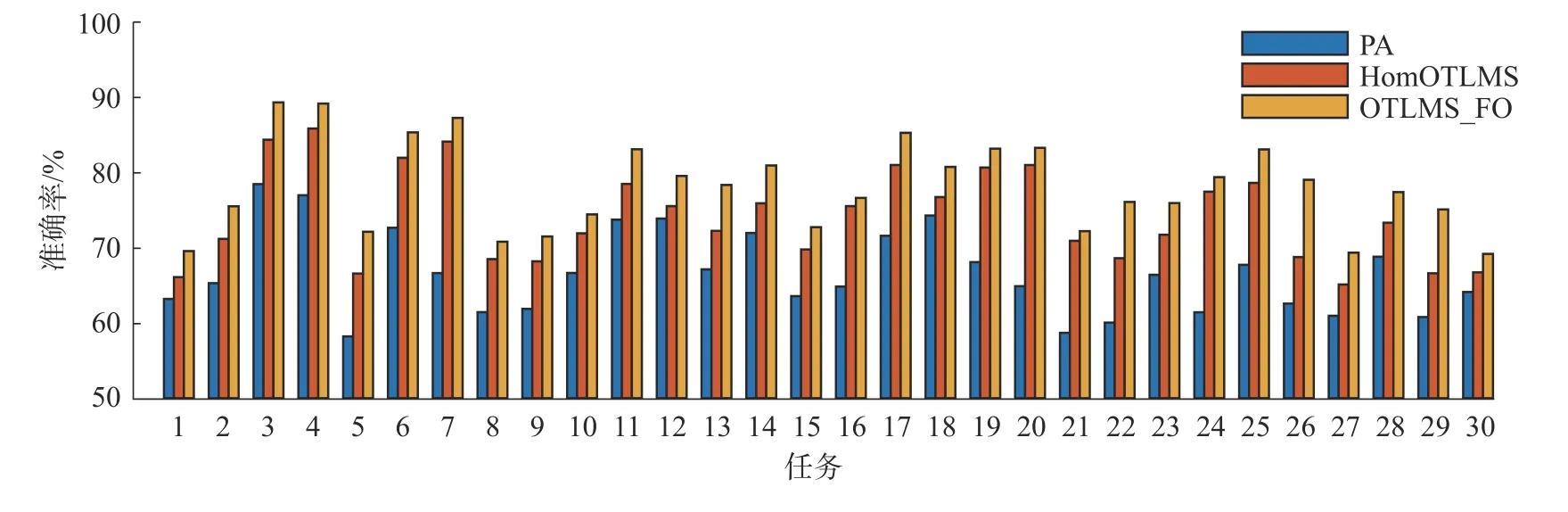
图1 在Office-Home 数据集的30 组任务的准确率Fig.1 Accuracy of 30 sets of tasks in the Office-Home dataset
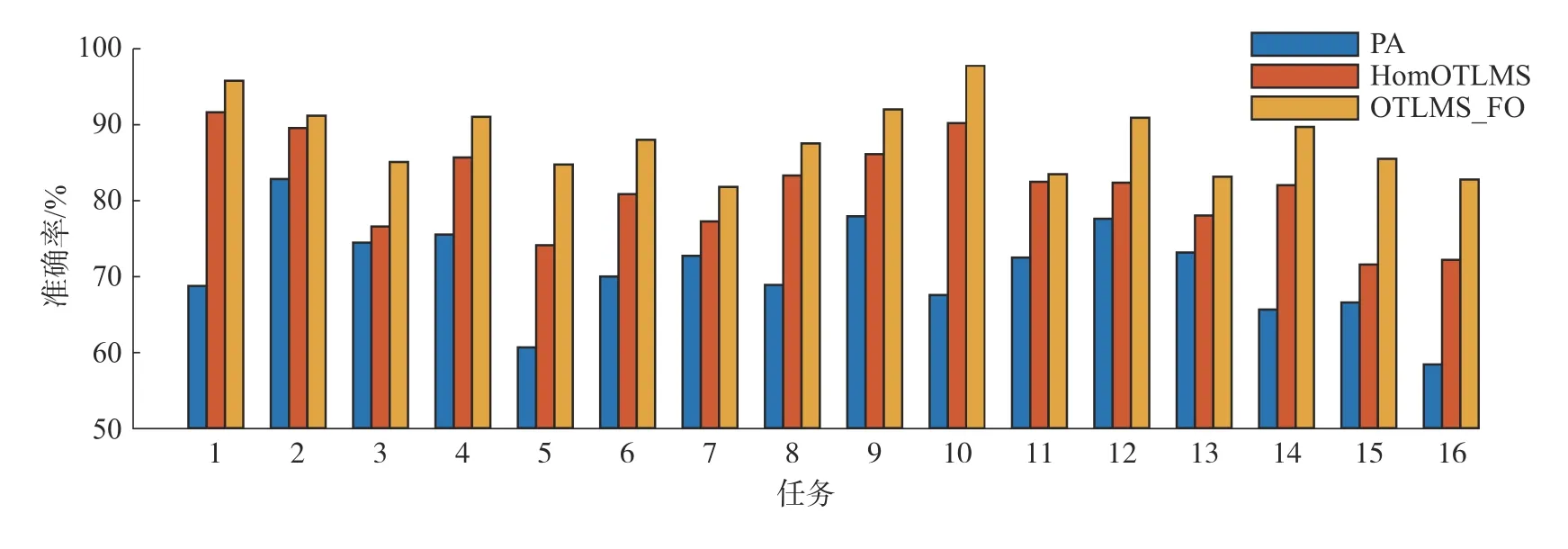
图2 在Office-31 数据集的16 组任务的准确率Fig.2 Accuracy of 16 sets of tasks in the Office-31 dataset
图3 给出了PA、HomOTLMS 和OTLMS_FO在G-mean 指标上的实验结果。可以看出从多个源域迁移知识的OTLMS_FO 和HomOTLMS 算法在多数任务上对少数类有着更好的表现。但是OTLMS_FO 显然更加适合不平衡的目标域,这种过采样的方法可以从已有数据中提取更多的信息。

图3 在Office-31 和Office-Home 数据集上各个任务的G-meanFig.3 G-mean for individual tasks on the Office-31 and Office-Home data sets
3.3.3 20newsgroups 数据集上的结果
为了更好地验证算法的性能,在20个新闻组的文本数据集上进行了4 组实验。每个目标域选取750个样本,其中少数类占比30%,并且每个样本的维数是61 188,然后进行多源在线迁移。表4展示了文本数据集上的实验结果。与基线方法相比,我们提出的两种方法OTLMS_IO 和OTLMS_FO在绝大部分任务上的性能都超过了基线。并且从实验结果可以看出OTLMS_FO 的结果要普遍强于OTLMS_IO,原因是OTLMS_FO 在核空间合成少数类,样本距离更加相似,特别是对维数较大的样本。从标准差可以看到提出的两种算法的稳定性稍弱于基线方法。因为合成样本使用了随机数δ,但考虑到更好的性能,牺牲一点稳定性是值得的。提出的OTLMS_FO 算法具有很好的时效性,因为该算法只需要通过前面几个批次来扩充当前到达批次的样本,而不用在整个目标域中寻找近邻生成型样本。
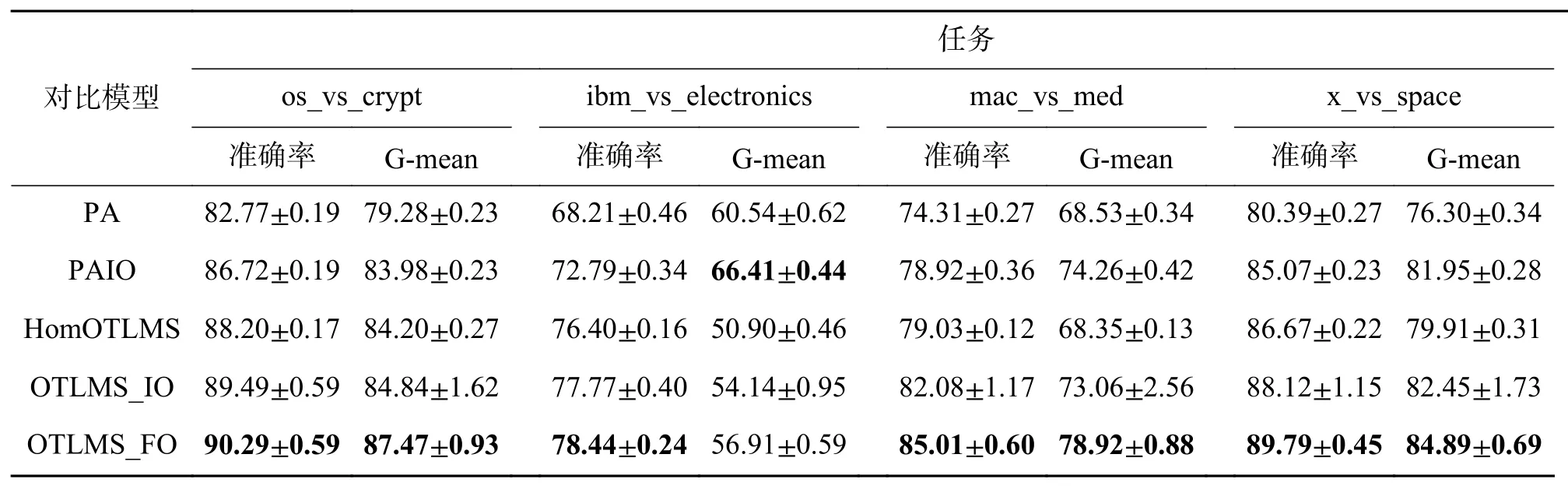
表4 在20newsgroups 数据集上应用不同学习算法的结果 (平均 ± 标准差)Table4 Results of different learning algorithms to the 20newsgroups dataset (mean±standard deviations)%
3.4 时间成本
为了评估所提出算法的时间效率,在20newsgroups 数据集上生成多个任务对算法进行测试。实验基于python3.7 实现,并在具有12×2.6 GHz的CPU(i7-9750H)和16 GB 运行内存的Windows10专业版机器上进行。图4 展示了HomOTLMS、OTLMS_IO 和OTLMS_FO 算法的平均运行时间。实验中,对目标域样本的维数都是61 188。从实验结果可以看出,随着过采样样本数的增加,两种对目标域过采样的算法所需的平均运行时间也随着增加。同时也可以发现在特征空间对目标域的样本过采样比输入空间需要花费更多的时间成本,这是因为在特征空间中合成样本的生成需要通过多个核函数的计算才能得到。

图4 不同维数和过采样样本数的时间成本Fig.4 Time cost of different dimensions and oversampled sample size
4 结束语
本文提出了一种针对目标域不平衡的多源在线迁移学习算法。同时,分别设计了在输入空间和特征空间中对目标域的样本过采样的方法。与忽略目标域类别分布的多源在线迁移学习算法相比,提出的方法可以利用目标域已经到达的样本对当前到达的样本进行过采样,用新生成的样本改进目标域函数,进而提高集成决策函数的性能,并且时间成本的增加是可以接受的。在3个实际数据集上的实验结果表明,所提出的算法与基线算法相比,整体上实现了更好的分类性能,也提高了对少数类预测的精度。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
计算机应用(2020年12期)2020-12-31
计算机技术与发展(2020年11期)2020-12-04
电子技术与软件工程(2019年18期)2019-11-18
电子技术与软件工程(2017年14期)2017-09-08
青年文学家(2015年29期)2016-05-09
文苑(2015年9期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
