
如何在资源受限的RISC-V内核上嵌入人工智能?
2022-04-21 09:24AlexeyShchekin
电子产品世界 2022年4期
Alexey Shchekin




人工智能(AI)几十年来一直是一个热门的技术话题。根据Statista和Gartner的预测,人工智能的收入将在未来4年内增长4倍,在2024年后将超过1000亿美元(1美元约为人民币6.4元)。
传统上,复杂的人工智能计算在云端数据中心运行。在GPU加速器和专门的系统级芯片(SoC)的帮助下,在台式机上实现人工智能模型,可以减少云端访问的要求。但在过去的几年里,一个重要的转变是AI处理从云端转到设备级。这主要归功于嵌入式设备/SoC的性能不断提高和安全考虑。这种转变催生了嵌入式人工智能的概念一机器学习和深度学习在设备级嵌入式软件中的应用。
嵌入式人工智能使设备能够在边缘运行简单的人工智能模型,并立即重复使用计算结果。从安全角度以及从降低延迟、最小化数据传输时间/能耗成本和避免使用通信硬件等方面来看是有利的。这可能对关键的工业物联网(IIoT)基础设施特别重要,边缘AI算法可用于收集各种传感器的数据,并实时预测系统故障。
鉴于将人工智能计算转移到边缘的趋势,在为物联网/IIoT应用选择SoC/MCU (微控制器)时,能运行人工智能/机器学习任务的能力成为一个“必备”的选项。同时对于其他的一些案例,如数据传输时间/能耗成本可能超过在设备层运行一个简单的AI模型时,引入边缘人工智能也具有价值。例如,智能可穿戴设备、植入式传感器、资产跟踪、环境传感器、无人机、音频/ AR/VR耳机等应用。
嵌入式设备通常受到资源限制:板上内存小,指令集有限,特定的硬件模块如FPU(Float Point Unit,浮点运算单元)、DSP( Digital Signal Processing,数字信号处理)较少。这些限制使得即使在嵌入式平台上运行简单的人工智能算法也很棘手。从软件的角度来看,它使得通过专用的人工智能框架,如TensorFlow Lite for Microcontrollers(TFLite-Micro)变得更加容易。从硬件的角度来看,使用矢量/图形协处理器或SIMD指令可能是一个解决方案;这两者通常都是与昂贵的高性能 SoC —起交付。如果成本和功耗预算仅限于带有(或甚至没有)DSP模块的MCU,此时怎么办?
用于微控制器的TensorFlow Lite框架
基于神经网络的算法可以提供可靠的结果,同时从头去实现它们通常也相当复杂,包括张量运算和非线性浮点函数。但有几个框架可以简化开发者的繁琐任务。TensorFlow Lite是在2017年推出的,针对的是移动设备上的神经网络推理。而最终TensorFlow Lite for Microcontrollers 在2021年从 TensorFlow Lite 中分离出来,专门针对资源受限的嵌入式系统,将TensorFlow Lite的其余部分留给Android/iOS应用。
TFLite-Micro采用了带有静态内存规划器的直译器形式,支持方案提供商特有的优化项。它解决了嵌入式系统的常见问题,如内存小和功耗限制等,并考虑到了支持各种架构/微架构的需要。它在任何嵌入式平台上开箱即用,支持最小的TensorFlow操作集,如卷积、张量乘法、调整大小和切片,并仍然足以运行丰富的人工智能应用,如图像分类、时间序列处理或关键词检测。Codasip构建了特定应用的平台,因此TFLite-Micro对特定领域专用优化项的支持,与Codasip Studio工具完美吻合。
事实上,Codasip处理器设计工具简化了 ASIP (专用指令集处理器)设计过程中最耗时的阶段,包括:1)高级架构描述和ISA探索,2)自动编译器生成,3)剖析器(profiler)和调试分析工具,4)周期精确的(硬件级)仿真,5)綜合验证环境。
下面以Codasip的支持TFLite Micro 的 L31 RISC-V 嵌入式内核为例来进行分析,来对标准RISC-V和自定义扩展都进行了评估。客户可以利用这些扩展,使功率、性能和面积的权衡超出传统设计的MCU所能做到的性能。评估结果将显示该范围有多广,并为进一步的改进提供建议。
未来许多客户将开发他们自己的神经网络,但基础机制是相似的。因此可以使用标准软件;在这个示例中,使用了著名的"MNIST手写体数字分类”。自卷积神经网络发明以来,这一直被认为是一个基准。
它是一个大小为28x28像素的灰度图像,包含一个手写的数字和该图像最可能输出的数字(见图1)。尽管任务表面上很简单,但这包括了TFLite-Micro支持的大量运算符子集。通常用于解决它的神经网络架构包含两个卷积层和池化层、至少一个全连接层、向量化非线性函数、数据调整大小和规范化操作等(见图2)。
为了探索这段代码在L31 CPU上的性能,CodasipStudio的内置剖析器提供了详细的PPA (性能-功耗-面积)预估,源代码覆盖率和单个指令的使用。这使得新的指令可以被快速试用并分析其性能优势。
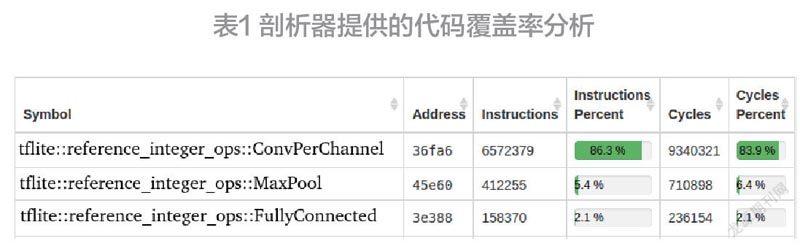
表1显示了剖析器所提供的代码覆盖率分析。正如预期的那样,对于图像分类任务来说,大部分的时间(~84%)都花在了图像卷积函数上。从这个信息开始,我们可以进入相应的'ConvPerChannel'源代码,对其进行更详细的探索。TFLite-Micro中的卷积是以嵌套 for-loop的形式编写的,索引各种卷积窗口尺寸以及训练数据批次。最深的for-loop扫描了图像输入通道,根据分析信息显示,CPU在这里花费的时间最多。
源代码(图3)中标明了在该处花费的周期数,给出了周期数的百分比和绝对数。反汇编显示了这些“热点”的CPU指令。这些信息表明,哪里需要优化?哪些指令可以被加入/替换以获得更好的性能?例如,在TFLite卷积的特殊情况下,大部分时间花在乘法+累加操作上(mul后面是c.add),以及随后的(向量)内存加载(for-statement后面的lb指令)。此外,合并乘法和加法,以及用即时地址增量加载字节,似乎是一个可以提高性能的定制方案。我们将在后面的自定义指令部分再来讨论这个话题。
Codasip Studio工具中提供的剖析器还可以预估ASIP的功率和面积,提供设计中每个硬件块的信息。这使设计者能够在L31内核的标准变体之间进行选择,并评估使用TFLite-Micro 进行量化的好处。
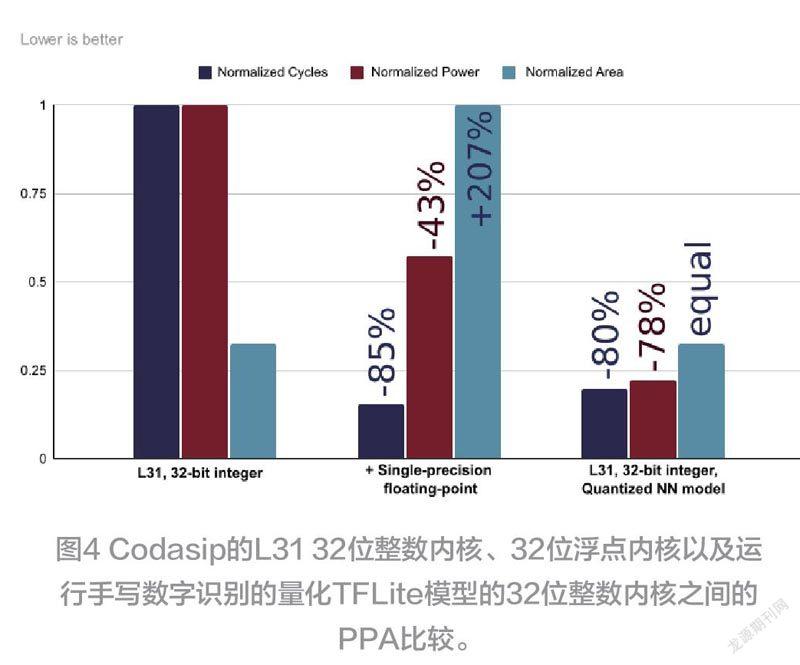
图 4 包含了 PPA 图表,显示了识别测试集的单一图像所需的相对时钟周期数、消耗的能量和利用的芯片面积。没有浮点硬件的基本 L31 配置是有效的,但性能相对较慢,因为 FP 操作必须在软件中模拟。而通过在L31 中添加硬件浮点单元可以解决这个问题,并使总时间减少近 85%,功耗减少 42%,但代价是芯片面积扩大(+207%)。
此外还有一个解决方案:TFLite-Micro支持神经网络参数和输入数据的量化。这个功能是从最初的TensorFlow Lite框架中提取的,并提供了将任何TensorFlow模型转换为整数(有符号/无符号8/16位)表示的能力,因此它可以直接在整数内核上运行。图4显示,在标准整数L31内核上运行的int8量化模型几乎达到了浮點内核的性能,运行时间减少了80%以上,功耗比初始水平进一步提高了78%,而不需要增加内核的复杂性和硅面积。
神经网络模型的量化总是在预测精度和算法复杂性之间进行权衡。从浮点版本切换到int16和int8不可避免地会降低精度,而用户有责任确保它不会降太多。量化 ( int8)和初始浮点模型都在包含10,000张图片的测试集上得到了验证,结果准确率为98.91% ( fp32)和98.89% ( int8 ) ,这似乎是对资源、功率和性能增益的合理权衡。
自定义指令集的优势
在SoC设计的框架内,“传统”处理器( MCU、DSP、GPU等)提供了一些特定的强大功能。为特定需求创建领域专用处理器,在面积、功耗和性能方面有很大优势。一个优化的指令集结构(ISA)与最小的所需指令会产生一个更紧凑和高效的内核,可在更少的周期内执行所需的任务,从而也降低了功耗。
运行TFLite图像分类任务的标准L31内核“热点”识别提供了提示,即哪些指令可以合并或优化以促进特定的任务?为了优化矢量存储器的加载和卷积乘法和累加序列,增加了两条自定义指令:mac3将乘法和加法合并到一个时钟周期,lb.pi在加载指令后立即增加地址。这两条指令目的在于减少频繁重复指令序列所花费的时钟周期数。
Codasip的CodAL高级处理器描述语言提供了一种有效的方式来描述汇编编码和程序员对指令功能的想法。这使得迭代尝试新指令和重新编制代码以衡量其有效性变得非常快。5图是一个如何在CodAL中定义新指令的例子。
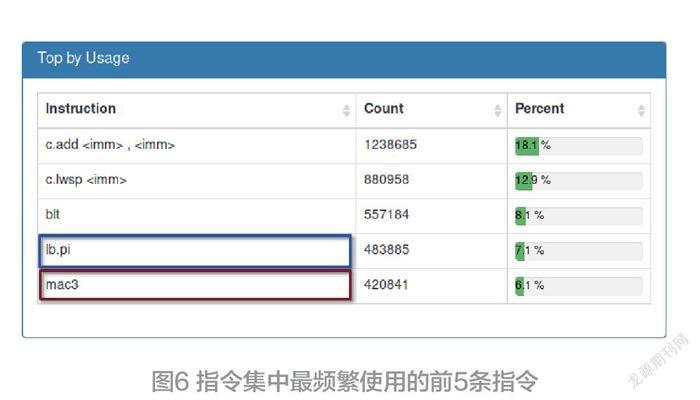
通过对运行相同图像分类任务的定制L31整数内核进行分析,表明新指令可以被广泛使用。图6总结了指令集中最频繁使用的前5条指令;其中乘法累积和带地址增量的字节加载包含其中。
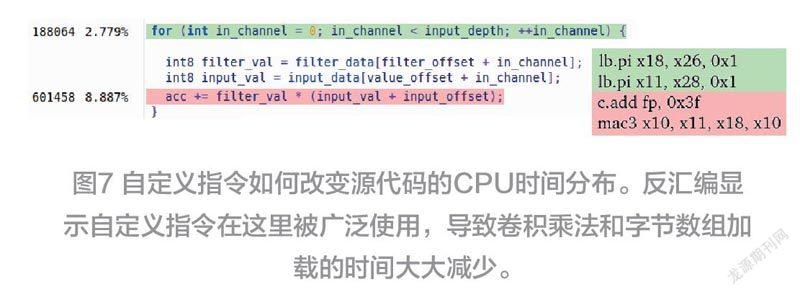
利用定制的L31内核进行的源代码分析显示,以前发现的“热点”性能得到了改善。反汇编(图7)显示,它们是在新的定制指令的帮助下执行的,最深的for-loop 中的净周期数已经大大减少。
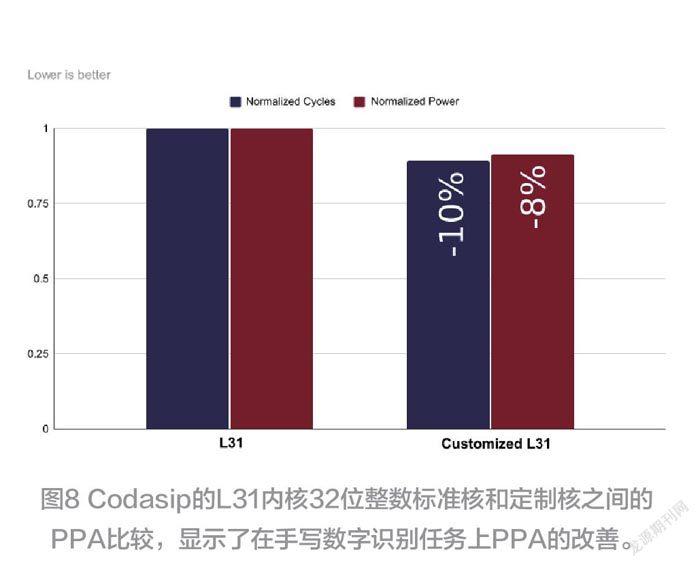
图8显示了这些架构/微架构的定制是如何进一步改善L31内核在图像分类任务上的PPA ( Power,Performance,and Area,功耗,性能和尺寸))指标?两张图比较了定制的L31的 PPA和之前在量化 int8图像分类任务上的标准32位整数内核的参数。
通过仅增加两条新指令,算法优化和从内存加载数组的方法,与在标准内核上运行的量化模型相比,总运行时间提高了10%以上,功耗降低了8%以上,而面积只增加了0.8%,这似乎是一个合理的定制成本。使用 SIMD( Single Instruction Multiple Data,单指令多数据流)指令可能会进一步提升性能,但很可能会大大增加面积。
对于许多人工智能公司来说,用于加速其设计的确切机制往往是企业的“秘密武器”。因此,Codasip的处理器设计自动化工具Studio使客户能够灵活地定制机器学习(ML )特定的内核并创建专有的加速器解决方案。
猜你喜欢
北京航空航天大学学报(2022年7期)2022-08-06
今日农业(2021年9期)2021-07-28
成都信息工程大学学报(2018年4期)2019-01-23
信息安全研究(2018年12期)2018-12-29
铁道通信信号(2018年2期)2018-04-18
电镀与环保(2016年3期)2017-01-20
电子制作(2016年19期)2016-08-24
电源技术(2015年11期)2015-08-22
单片机与嵌入式系统应用(2014年9期)2014-03-11
自动化博览(2014年4期)2014-02-28
