
基于BiLSTM-CRF的社会突发事件研判方法
2022-04-19 09:28胡慧君代建华刘茂福
中文信息学报 2022年3期
胡慧君,王 聪,代建华,刘茂福
(1.武汉科技大学 计算机科学与技术学院,湖北 武汉 430065;2.湖南师范大学 智能计算与语言信息处理湖南省重点实验室,湖南 长沙 410081)
0 引言
近年来,社会突发事件频发,给社会带来了巨大影响,也给应急处置带来了巨大挑战。社会突发事件突然发生的特性和所具有的破坏性,要求应急处理必须做到时效性和准确性,从而及时止损。而社会突发事件类型和等级研判作为应急处置的起始部分,决定着后续应急预案能否快速准确地实施。目前,国内对社会突发事件的应急处置已初具规模,但如果让应急决策者手工去处理应急处置中的所有工作,可能会缺乏效率,延误最佳的应急时机。因而,社会突发事件类型和等级的自动研判在应急处置中非常关键。
国内较早便开展了社会突发事件应急处置的相关工作,但当时标准不明,研究多是探索性的。自2005年后,国家陆续发布了社会突发事件的应急管理流程和相关标准,有关研究便逐渐多了起来。然而,由于各省份之间的差异性,颁发的文件中大多都是保证覆盖到各地区的应急处置,而对于突发事件等级研判标准并不详细,导致目前大多数研究更多注重的是对应急处置的综合性评价,强调了应急处置的风险性。Ivica等[1]通过模糊决策的方式来确定雷电的位置对输电网的影响,Sedova等[2]使用模糊推理方法来对海上突发事件进行等级研判,Sun等[3]采用了直觉模糊集理论,并结合层次分析法实现对水利工程施工应急救援方案的定量评价。近些年来,基于机器学习的方法也逐渐开始展露,Hou等[4]将聚类方法运用在突发事件应急物资的分类上,Qiu等[5]和Fu等[6]结合贝叶斯模型在突发事件的应急处置中进行运用,商丽媛等[7]融合支持向量机的方法实现对突发事件的等级研判,徐绪堪等[8]在商丽媛等[7]的基础上,提出了基于随机森林的突发事件等级研判方法。
虽说现有研究有一定的效果,但还是存在一些不足,目前应急处置的等级研判证据大多采用人工或规则方法。人工提取研判证据,需要大量人力,且进行研判时也需要人工识别研判证据,灵活性较差;采用规则方法,规则库的建立需要专家大量的时间进行总结与归纳,并且中文语言灵活多变,还会存在规则库建立不完全的问题,示例如例1和例2所示。
例1: 从首例病毒性肺炎到首例死亡病例……截至2020年1月7日21时,实验室检出一种新型冠状病毒,获得该病毒的全基因组序列,经核酸检测方法共检出新型冠状病毒阳性结果15例(1)https://www.bjnews.com.cn/news/2020/01/20/676837.html。
例2: 截至目前,我市累计报告新型冠状病毒感染的肺炎病例41例,已治愈出院12例,在治重症5例,死亡2例,其余患者病情稳定,患者均在武汉市定点医疗机构接受隔离治疗(2)http://www.nhc.gov.cn/xcs/yqtb/202001/2f222cfb607e-4952a705ac34c420c057.shtml。
例1和例2中,“首例死亡病例”和“死亡2例”同时指向了死亡人数,而“新型冠状病毒阳性结果15例”和“感染的肺炎病例41例”同时指向了感染人数,对“死亡”和“感染”人数方面的研判证据采用了不同的描述形式,规则方法将无法保证规则集覆盖所有的研判证据描述。
从上述例子可以看出,现有研究方法在研判证据提取上还存在着许多不足,这些不足直接影响了后续应急处置的精准性。本文提出的基于BiLSTM-CRF的序列标注研判方法,实现了对研判证据更加细粒度化的识别,并结合注意力机制达到对社会突发事件精准研判的目的。相比较于以往研究,本文采用序列标注模型识别出研判证据,具有更好的灵活性和准确性。其次,以往研究大多只考虑了应急处置中的某一个环节,而忽略了不同环节之间的影响,本文将突发事件分类和等级研判结合,类别信息分别融入研判证据抽取和等级研判,从而提高等级研判效果。
1 基于BiLSTM-CRF的突发事件研判方法
社会突发事件研判任务是指针对某一条突发事件文本判定其具体突发事件类型和突发事件等级。受Mu等[9]和He等[10]的启发,参考“事件抽取”的思想,将社会突发事件研判任务划分为事件识别、事件分类、研判证据识别和等级研判四个子任务,通过对整个研判任务的细致划分,获取更加精准的事件语义信息,达到增强研判效果的目的。
事件识别通过识别事件触发词,判断文本中是否含有事件,来达到识别事件的目的,如“婚庆现场发生了爆炸”,以 “爆炸”为事件的触发词,判断文本中是否包含突发事件,进而对触发词进行分类,从而确定突发事件的类型,由此便可知发生了什么事件,是什么类型。对于突发事件等级研判,其关键是研判证据的识别,但中文语言的不规则化和灵活性导致现有研判证据识别准确率低,突发事件等级研判效果差。为了提高突发事件等级研判证据识别的准确率,本文在研判证据识别中结合事件分类任务,融入突发事件类别信息。突发事件类型不仅会加强研判证据的识别能力,并且对突发事件等级研判有很大影响,如“台风登陆时中心附近最大风力有13级(38米/秒)”,通过识别“台风”,可知突发事件发生,事件类型为“气象灾害”,若人为知道突发事件类型为“气象灾害”,可推断到突发事件类型有“台风”“暴雨”“大雾”等具体事件[11-12],从而推测出研判证据为“风力”“降雨量”“能见度”等。为了使模型也能学习到这种关系,本文将类别信息融入研判证据识别任务中,进而增加研判证据识别效果。在进行等级研判时,为了避免其他因素的干扰,只将事件类型信息和研判证据作为等级研判的判别特征,整体方法框架如图1所示。
图1中,方法流程为先进行事件识别和事件分类,再进行研判证据识别,最后完成等级研判。研判证据的识别在输入层结合了事件分类的结果,再将识别出来的研判证据和分类结果进行等级研判。对研判证据的精准识别,可在进行等级研判时减少其他因素的影响,让等级研判只跟识别出的研判证据和类别信息相关,由此研判的等级会更加精确。
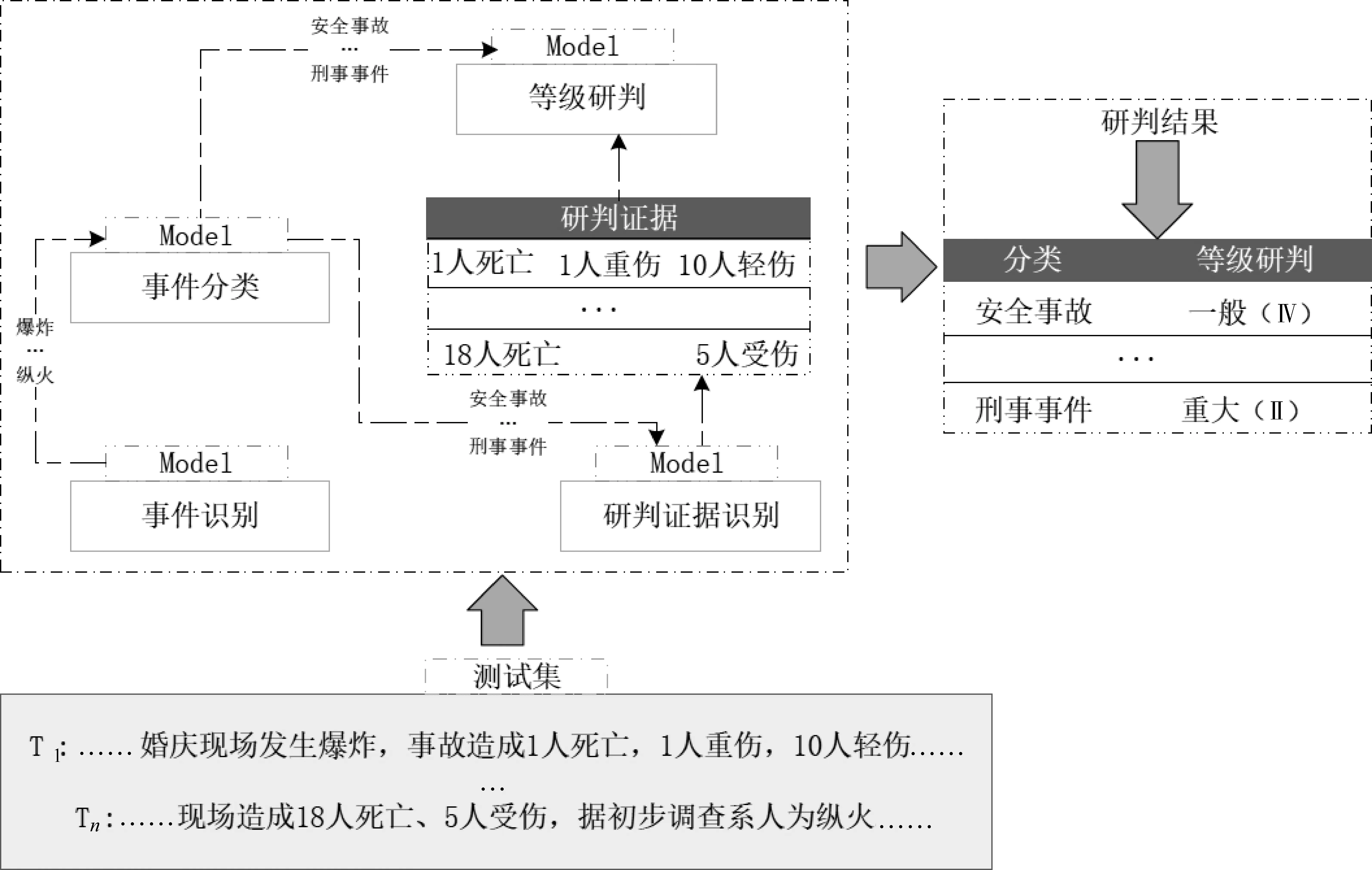
图1 方法框架
1.1 事件分类与研判证据识别
事件分类用标注模型实现,包括触发词的识别和分类,将识别出的触发词进行分类,即可确定突发事件的类别[13]。与分类模型相比,标注模型对识别文本语义相似的不同类别事件有着更好的效果。事件分类的实现方法基于BiLSTM-CRF模型[14],BiLSTM-CRF模型可以同时完成触发词识别和突发事件分类,减少错误传播,从而最终分类结果较好。首先文本经过字符嵌入后,输入到BiLSTM模型中,再通过CRF方法获取序列标注结果。由图1可以看出,文本经过模型识别出“爆炸”“纵火”等为激活事件元素[15],进而进行事件分类,分成“安全事故”“刑事事件”等类别,从而得到了事件类型信息。
在本文提出的方法中,突发事件类型会作为等级研判环节的一部分,并将其当作研判证据之一[16-17]。主要影响表现为:一是作为研判证据,成为等级研判的输入,而与其他研判证据不同的是,突发事件类型含有突发事件的类别信息,既可作为单独任务提供信息,也可结合其他任务。当作为单独任务时,属于事件分类任务,对识别事件进行分类,获取突发事件类别信息。而不作为单独任务时,则可成为等级研判的一环,从而提升等级研判的效果。其次便是类别信息对研判证据的影响,如上所述,当发生了“气象灾害”事件时,可以推断出“风力”“降雨量”等可能为其研判证据,由此便可看出类别信息很大程度上能帮助研判证据的识别。现有的突发事件等级研判方法,由于研判证据的非标准化,传统方法很难精准识别出研判证据,而BiLSTM-CRF的序列标注模型则可以细粒度地识别这些研判证据信息,考虑到类别信息对研判证据识别的影响,本文提出了基于类型信息融合的研判证据识别方法,此方法以BiLSTM-CRF模型为基础,通过结合类别信息和原始文本,将得到的突发事件分类结果融合到研判证据的识别中,从而提高研判证据识别准确度,研判证据识别模型的框架如图2所示。
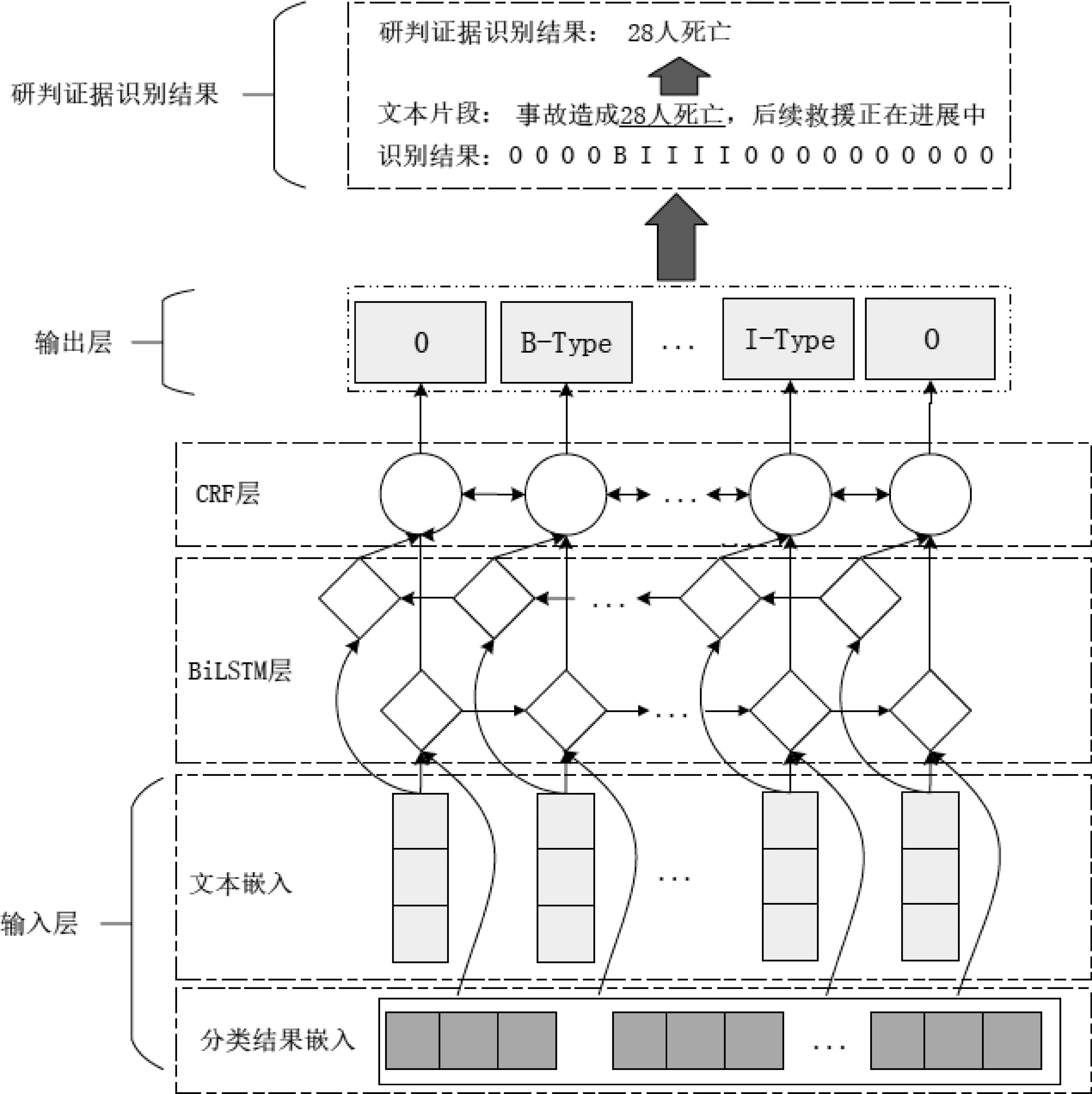
图2 研判证据识别模型的框架
在研判证据识别模型中,输入层中由下往上分别表示突发事件分类输出结果和文本向量表示,将其类别信息与当前输入结合,经过BiLSTM层进行处理,再通过CRF层得到预测的序列标注结果,则可得到研判证据识别结果。
输入层:类别信息向量矩阵和输入文本向量矩阵的结合语义向量表示。采用了预训练模型BERT(Bidirectional Encoder Representation from Transformers)来获取文本的语义向量表示,BERT采用了双向Transformer作为特征抽取,可以获取更丰富的语义信息,文本经过BERT模型将字符级嵌入转换成向量形式[18]。类别信息和输入文本经过BERT获取到各自的语义向量表示,结合后作为输入层。
BiLSTM层:由BERT传过来的向量矩阵,经过BiLSTM层可以得到更多的语义信息。LSTM(Long Short-Term Memory)为长短时记忆神经网络,是RNN的一个变种,可解决RNN在时间序列中长期依赖丢失的问题[19]。LSTM的输入为向量矩阵,经过下列步骤则可以得到隐藏层的向量表示。
CRF层:BiLSTM传过来的概率矩阵通过条件随机场(CRF)的方法来获取序列的最优标记。在以往研究中,已表明CRF在序列标注求解问题上有很好的效果。传入的BiLSTM的输出的概率矩阵为Om*l,其中Oij表示第i个字符映射到第j个标签上的概率。当已知序列seq={w1,w2,…,wn}的预测的标签序列为y={y1,y2,…,yn},则从式(7)可以得到当前序列的得分。
(7)
其中,A为转移概率矩阵,该矩阵在对当前位置进行标注时可以利用之前的标注信息,Ayi,yi+1表示标签yi移到标签yi+1时的概率。通过求解f(x,y)的最大值来获取最优的标签序列,再采用动态规划算法来得到最优标注路径。
输出层:已标注的序列文本。
通过输出层输出的已标注的序列,可以识别出需要的研判证据,进而通过研判证据决定突发事件的等级。
1.2 等级研判
等级研判为社会突发事件研判任务中的最后一个环节,该环节融合了分类结果和证据识别结果,当获取到突发事件类别信息和研判证据后,则可进行等级研判。突发事件的等级研判只受类型和研判证据的影响,从而避免其他不相关因素对等级研判的影响。识别出来的研判证据结果和突发事件分类输出结果进行结合,作为等级研判任务的输入,经过BiLSTM层,再结合注意力机制,最终预测出当前文本的突发事件等级。等级研判模型的框如图3所示。

图3 等级研判模型的框架
图3中的“类型”表示事件分类的输出结果。“研判证据”则表示研判证据的识别结果,将这两部分同时输入,进行编码,转换成向量矩阵,输入到BiLSTM层处理信息,再经过注意力层,通过注意力机制来调节各个证据之间的权重大小。近些年,注意力机制在各个自然语言处理任务中已取得了不错的成绩,由于等级研判时不同证据对研判的影响不同,加入注意力机制可以有效地处理这个问题,从而提高等级研判的准确性。由BiLSTM层输出的特征向量矩阵H,经过以下步骤得到注意力层的输出γ,如式(8)~式(11)所示。
得到注意力层的输出后,经Softmax层分类输出研判等级。
2 实验
2.1 数据集
社会突发事件的研判语料来源于政府网站信息公开的突发事件通报及微博中突发事件新闻报道,标注过程中参照《国家特别重大、重大突发公共事件分级标准(试行)》《贵州省突发事件分级标准》文件,确立标注规范,标注了突发事件的事件触发词、事件类型、研判证据和突发事件等级四部分,其中事件类型包括了安全事故、公共卫生事件、地震灾害、气象灾害及刑事事件五大类,突发事件等级包括特别重大(Ⅰ)、重大(Ⅱ)、较大(Ⅲ)和一般(Ⅳ)四个等级,按照此规范,共标注突发事件数据2 000条,形成突发事件研判语料集,具体语料分布情况如表1所示。
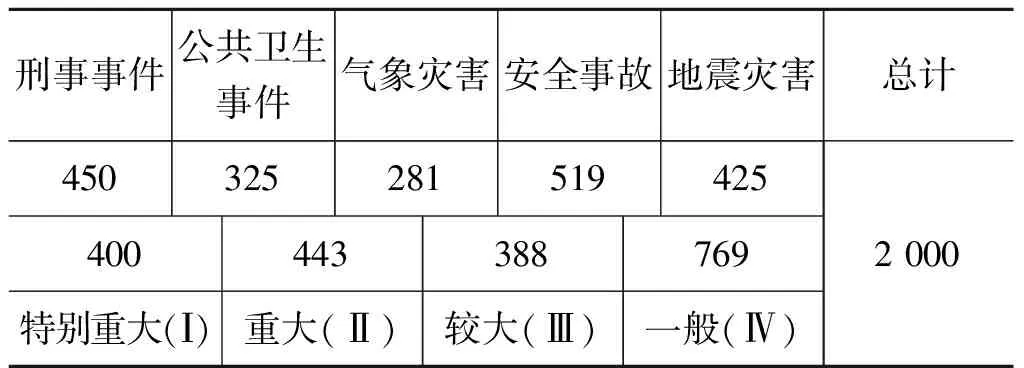
表1 语料分布表
社会突发事件研判语料按照BIO标注方式进行标注,标注出上述五个类型的事件触发词,即激活事件的事件元素和事件类型,同时标注出用于等级研判的研判证据和突发事件等级,如例3所示。
例3:2007年8月13日16时45分,湖南省湘西土家族苗族自治州凤凰县正在建设的堤溪沱江大桥发生特别重大坍塌事故,造成64人死亡、4人重伤、18人轻伤,直接经济损失3 974.7万元。事故发生后,党中央、国务院领导同志作出重要批示,华建敏国务委员赶赴事故现场指导抢险救援工作(3)https://www.bbaqw.com/js/701.html。
在例3中,将“坍塌事故”标注为当前文本的事件触发词,并确定当前文本事件类型为“安全事故”。而“64人死亡”“4人重伤”“18人轻伤”和“经济损失3 974.7万元”是突发事件等级研判任务中的主要因素。在此文本中,这些证据同时作为评判突发事件等级的关键特征,都需要标注,并按照标注规范,确定当前文本突发事件等级为“特别重大(Ⅰ)”。整个突发事件研判语料集采用例3中标注方法进行标注,以小组内交叉检验方式进行复查,歧义语料服从多数为准原则。本文选取了已标注突发事件研判语料集中的1 000份作为训练集,500份作为验证集,剩余500份为测试集。
2.2 实验设置
社会突发事件的研判研究,本文将其划分为四个子任务,在事件识别任务中,对于结果的判定,要求其预测的触发词与预先标注好的触发词匹配,才能判定正确;在事件分类任务中,目的是得到整个文本的突发事件类型,因此对于识别出的事件触发词,要求其类型正确,这是正确分类的前提。实验参数设置如下:输入的维度max_seq_length为256,训练集的batch_size为16,测试集的batch_size为8,训练学习率为1×10-5,使用dropout来防止过拟合,值为0.5。对于突发事件研判证据识别,同样要求预测出的研判证据与预先标注好的研判证据一致,据此进行判断,而对于突发事件等级研判,要求预测出的等级和预先标注等级一致。在研判证据识别任务中,使用了与事件分类任务相同的实验参数设置。对于等级研判任务,实验参数设置如下:输入的维度max_seq_length为126,训练集与测试集batch_size为256,训练学习率为 1×10-3,dropout值为0.5。
评价标准采用了精准度(P)、召回率(R)和F-score(F值)来评估事件识别和分类、研判证据识别和等级研判的效果,如式(12)~式(14)所示。
2.3 实验设置
按照上述方法和模型,将数据集划分为训练集、验证集和测试集,用训练集和验证集进行训练与验证,将训练好的模型在测试集上进行预测,根据预测结果与真实结果之间的差异进行评估,评估结果如表2所示。
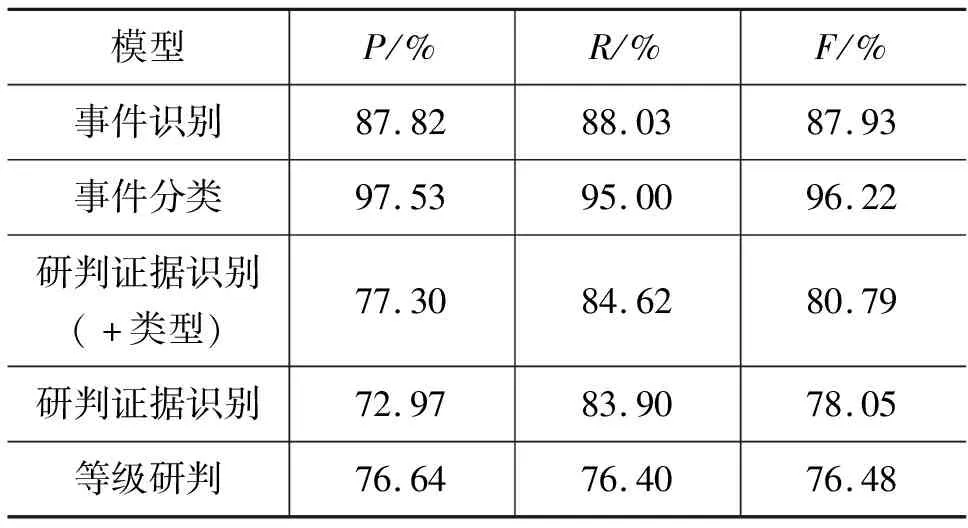
表2 基于序列标注模型的研判结果表 (单位: %)
从表2中可以看到,事件识别和事件分类的F值相差了8.29%,造成如此差距是相近触发词导致。本文对于突发事件的类型分类,在于整个文本所属类别,当出现了触发词,但识别的位置和词语与预先标注好的不一致,预测的突发事件类型一样时,也将判定为正确,具体示例如例4所示。
例4:9月13日上午,海口市东湖南里发生一起故意伤害致死案:一男子持刀行凶,造成3名男子1死2伤(4)http://www.hinews.cn/news/system/2015/09/13/017797825.shtml。
例4中,标注的事件触发词为“行凶”,事件类型为“刑事事件”,在进行预测时并未识别出“行凶”,而将“故意伤害”作为事件的触发词识别出来,类型同样也为“刑事事件”。在进行突发事件类型判定时,其对于文本而言预测出来的类型正确则为正确。
表2中的研判证据识别(+类型)和研判证据识别分别表示在加入分类结果和不加入分类结果的研判证据识别效果,从表中可以看出,在融入了分类结果后,研判证据抽取的F值有明显的提升。
突发等级研判与事件分类不同,从表2中可以看出,研判证据识别的F值比等级研判的F值高,研判证据正确识别决定等级研判的准确性,若缺少研判证据,则大部分情况下都会造成判定的等级过低,具体示例如例5所示。
例5:8月19日15时05分,一辆安阳市区至安阳县北郭乡的公交车上发生持刀抢劫杀人案。车上33名乘客,15人被捅伤,其中2人在救治途中死亡,1名伤者经抢救无效死亡(5)http://news.cntv.cn/special/anyanggjqja。
例5中,通过文中模型可以识别出当前类型为“刑事事件”,但对于其他等级研判特征的识别并未识别完全,文中模型识别出了“15人被捅伤”,而未识别出死亡研判证据,因此导致了最终的研判等级变低。
社会突发事件等级研判任务的最终目的是突发事件分类和等级研判,从表2中可以看到以BiLSTM-CRF的序列标注模型完成的突发事件分类和等级研判的效果,为了证明序列标注模型的有效性,本文将徐绪堪等[8]所使用的随机森林模型进行复现,从而作为对比,同时也加入了BERT模型作为对比,结果如表3所示。
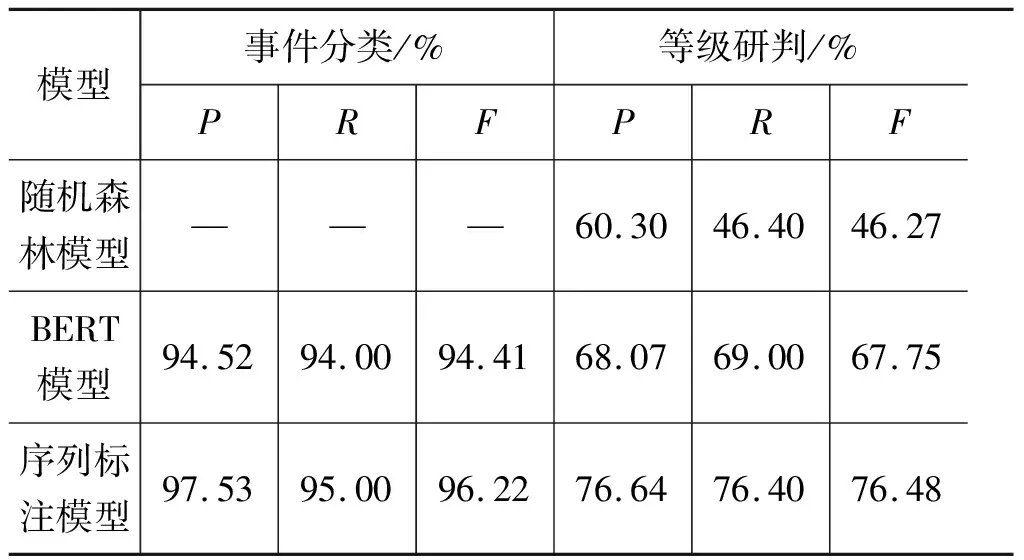
表3 实验对比表
由表3可以看出,序列标注模型的实验结果最好。当使用徐绪堪等[8]的方法,其效果与BERT模型以及序列标注模型都相差较多,造成这种情况的可能原因便是随机森林模型在徐绪堪等[8]的实验中所使用的语料集规模较少,只有一种突发事件类型,当扩大语料集和突发事件类别种类时便达不到较好的效果。序列标注模型在事件分类中比BERT模型F值提高了1.81%,在事件分类任务中,序列标注模型能更加有效地识别文中的类别信息,即事件的触发词,相比较于BERT模型直接用整句语义向量进行分类而言,序列标注模型能有效避免噪点信息的干扰。等级研判中序列标注模型与随机森林模型和BERT模型相比,F值分别提高了30.21%和8.73%。随机森林模型除上述提到的数据规模扩大、效果不佳的情况外,另一个较为重要的原因便是由于语言的灵活性,采用规则的方法[20-21]并不能很好地识别研判证据,从而导致等级研判结果较差,而BERT模型采用了句子语义信息来作为研判证据,其证据不如采用序列模型识别出的证据精确,如此便忽略了类别信息对研判证据的影响。本文通过对社会突发事件研判任务的重新划分,结合类别信息来增加社会突发事件研判证据识别的准确性,从而提高等级研判的准确性。如此,本文序列标注模型在实验中表现最佳。
3 总结与展望
本文中提出了基于序列标注模型来完成社会突发事件的研判方法,相比较以往研究,此方法能更加灵活准确地识别出研判证据,通过使用BiLSTM-CRF的方法提高识别的准确率,同时将事件分类和等级研判结合起来,来优化等级研判的效果。目前本文中只考虑到了单一突发事件的情况,但有时一个社会突发事件的发生可能产生其他衍生突发事件,此时若要对当前突发事件进行等级研判则需考虑到其衍生突发事件的影响。接下来的工作将会加入衍生突发事件,若当前突发事件产生了其他衍生突发事件,则判定其对当前突发事件有联系性和影响性,再而进行突发事件的等级研判。
猜你喜欢
理财周刊(2022年4期)2022-04-30
国际太空(2021年10期)2021-12-02
陶瓷学报(2021年4期)2021-10-14
少儿画王(3-6岁)(2020年4期)2020-09-13
中国外汇(2019年20期)2019-11-25
中国外汇(2019年18期)2019-11-25
领导科学论坛(2016年10期)2016-06-05
文史春秋(2016年8期)2016-02-28
小说月刊(2014年10期)2014-04-23
微型计算机(2009年4期)2009-12-23
