
一种基于YOLOv4-TIA 的林业害虫实时检测方法
2022-04-18 10:56候瑞环杨喜旺王智超高佳鑫
计算机工程 2022年4期
候瑞环,杨喜旺,王智超,高佳鑫
(中北大学 大数据学院,太原 030051)
0 概述
林业害虫泛指危害森林的昆虫。当病虫害爆发时,通常会给林业发展造成重大经济损失。因此,在病虫害发生早期,通过智能喷洒装置对害虫进行消杀具有重要意义[1]。因此,对林业害虫图像进行快速精确检测成为目标检测领域的研究热点。昆虫检测主要由工作人员对诱捕到的昆虫进行人工识别与计数,其效率低、劳动量大且及时性差[2]。随着图像采集技术和机器学习的发展,昆虫检测技术通过将人工提取图像特征与支持向量机等机器学习分类方法相结合,并将其应用于自然场景下的昆虫数据分析,但该方法的鲁棒性和泛化能力较差[3]。
近年来,研究人员开始将深度学习算法应用于昆虫图像检测领域中。文献[4]提出基于深度卷积神经网络的油菜虫害检测方法,使用VGG16[5]网络提取图像特征,并生成初步候选区域,再通过Fast R-CNN[6]对候选框进行分类和定位,但是该方法的检测速度较慢。文献[7]提出基于改进的SSD[8]深度学习模型的虫情检测系统,实现了对红脂大小蠹虫情的全自动化监测,然而该系统是针对特定场景设计的,因此只能对一种类型的害虫进行检测,无法实现多类别害虫检测需求。
为实现对林业害虫的实时精确监测,本文提出一种基于YOLOv4-TIA 的昆虫图像检测方法。将检测速度较快且可以进行多目标检测的深度学习模型YOLOv4[9]引入到林业害虫监测领域中,并对其进行改进,通过融合三分支注意力[10]机制与改进的PANet[11]结构,提高模型对林业害虫图像的综合检测能力。
1 YOLOv4 目标检测算法
YOLO 系列算法是一种将目标检测问题转换为回归问题[12-13]的目标检测算法。该模型采用端到端的网络结构,在产生候选区域的同时完成分类和位置调整,从而节省了检测时间且降低了计算资源使用率。
YOLOv4 是YOLO 系列算法的最新版本,其网络结构如图1 所示。与YOLOv3[14]不同,YOLOv4 在数据处理过程中引入mosaic数据增强,CSPDarkNet53和PANet 分别作为主干网络和颈部网络,并通过多种训练方式优化激活函数与损失函数。这些方式能够加快YOLOv4 的检测速度,且实现速度和精度的最佳平衡[15]。
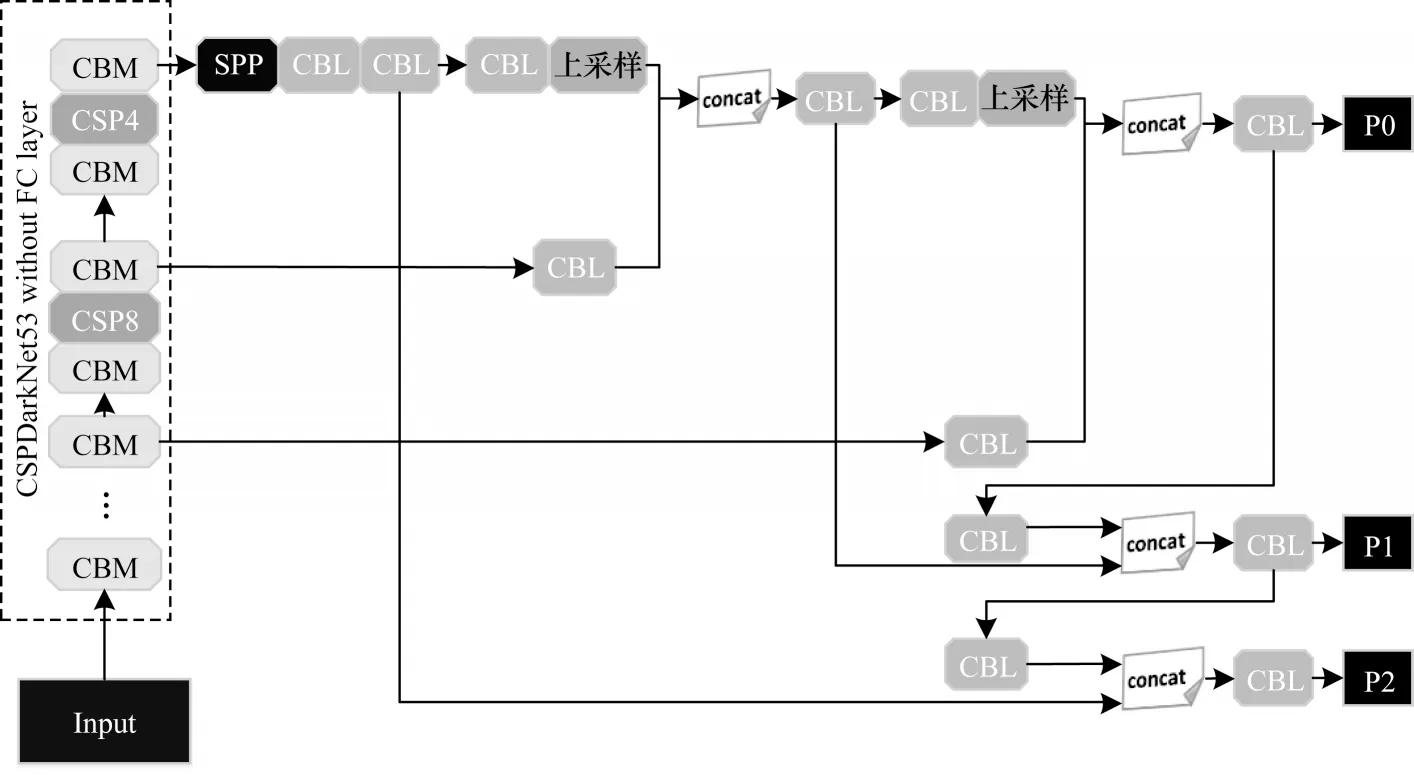
图1 YOLOv4 网络结构Fig.1 Structure of YOLOv4 network
YOLOv4 模型将CSPDarkNet53 作为骨干网络,CSPDarkNet53 主要由CBM 模块和CSP 模块构成,其中CBM 模块由卷积层(Conv)、批归一化层(Batch Normolization,BN)和Mish 激活功能组成,CSP 模块包括两条支路,一条是主干部分的卷积,另一条用于生成大的残差边,通过对两条支路的跨级拼接与通道整合,以增强卷积神经网络(Convolutional Neural Network,CNN)的学习能力。CSP 结构如图2 所示,其中CBL 模块由卷积层(Conv)、批归一化层(Batch Normolization,BN)和Leaky ReLu 激活功能组成。此外,YOLOv4 模型在检测部分使用了空间金字塔池化层SPP 模块,使得任意大小的特征图都能够转换成固定大小的特征向量,利用K-means 聚类生成不同尺度的先验框,并在不同层级的特征图上进行预测。与YOLOv3 相比,YOLOv4 是 基于PANet 的原理对不同层级的特征进行融合。
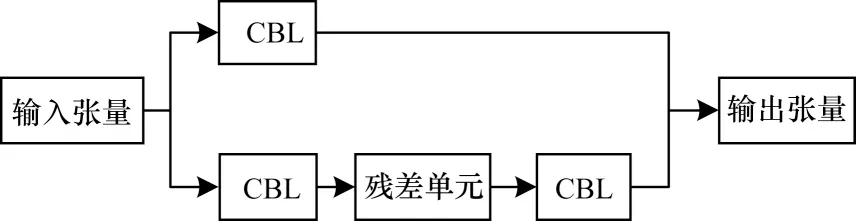
图2 CSP 网络结构Fig.2 Structure of CSP network
2 模型改进
2.1 林业害虫候选区域参数聚类
YOLOv4 模型是在输入图片上生成一系列锚框,锚框是w和h固定的初始候选框,也是生成预测框的前提,anchor 的选用会直接影响模型的性能[16]。YOLOv4 模型使用的锚框是在COCO 数据集上统计较合适的锚框大小。因此,本文通过对林业昆虫数据集进行聚类,得到合适的anchor 大小。利用K-means++聚类算法代替YOLOv4 模型中使用的K-means 算法。K-means 算法流程如图3 所示。
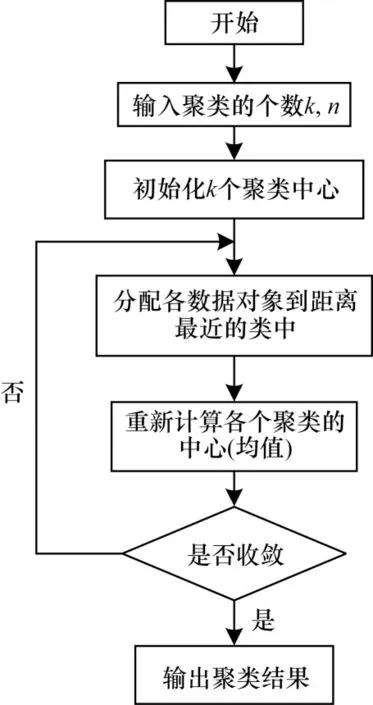
图3 K-means 算法流程Fig.3 Procedure of K-means algorithm
K-means 算法需要人为设定初始聚类中心,然而不同的初始聚类中心对聚类结果的影响较大。因此,本文使用K-means++对林业昆虫数据集中昆虫对象的w和h进行聚类。K-means++在对初始聚类中心的选择上进行了优化,首先随机选择一个点作为第1 个初始类簇中心点,然后选择距离该点最远的点作为第2 个初始类簇中心点,最后再选择距离前2 个点距离最远的点作为第3 个初始类簇的中心点,以此类推,直至选出k个初始类簇中心点[17]。在初始点选出后,本文使用标准的K-means 算法进行聚类。
聚类评估标准通常用轮廓系数来表示,如式(1)所示,轮廓系数取值范围为[-1,1],取值越接近1,则说明分类效果越好。

其中:i为已聚类数据中的样本;bi为i到其他各个族群所有样本的距离平均值中的最小值;ai为i到本身簇的距离平均值。
经过聚类与计算轮廓系数后,聚类类别数与轮廓系数的对应关系如图4 所示。
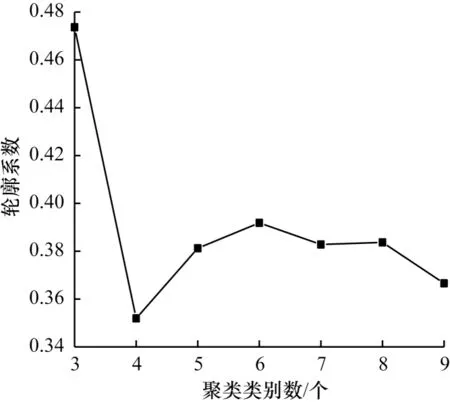
图4 聚类类别数与轮廓系数的对应关系Fig.4 Corresponding relationship between the number of clustering categories and contour coefficient
聚类类别数的取值为3~9。经分析可得,以k表示聚类类别数,当k为3 时,轮廓系数最高,聚类效果最好;当k为6 时,聚类效果次之;当k为7 时,聚类效果较好。本文将三者相结合,最终得到候选区域参数,分别为(51,52)、(68,69)、(63,91)、(88,64)、(92,137)、(99,140)、(136,91)、(140,100)、(146,144)。
2.2 基于三分支注意力机制的YOLOv4-TIA 网络
YOLOv4 网络平等对待每个通道特征,在一定程度上限制了算法的检测性能。为进一步提升模型精度,本文利用三分支注意力机制对YOLOv4 中的CSPDarkNet53 特征提取网络进行改进,改进后的模型命名为YOLOv4-TIA。三分支注意力机制模块是一种可学习参数少、不涉及维数降低且有效的注意力机制[18],其网络结构如图5 所示。
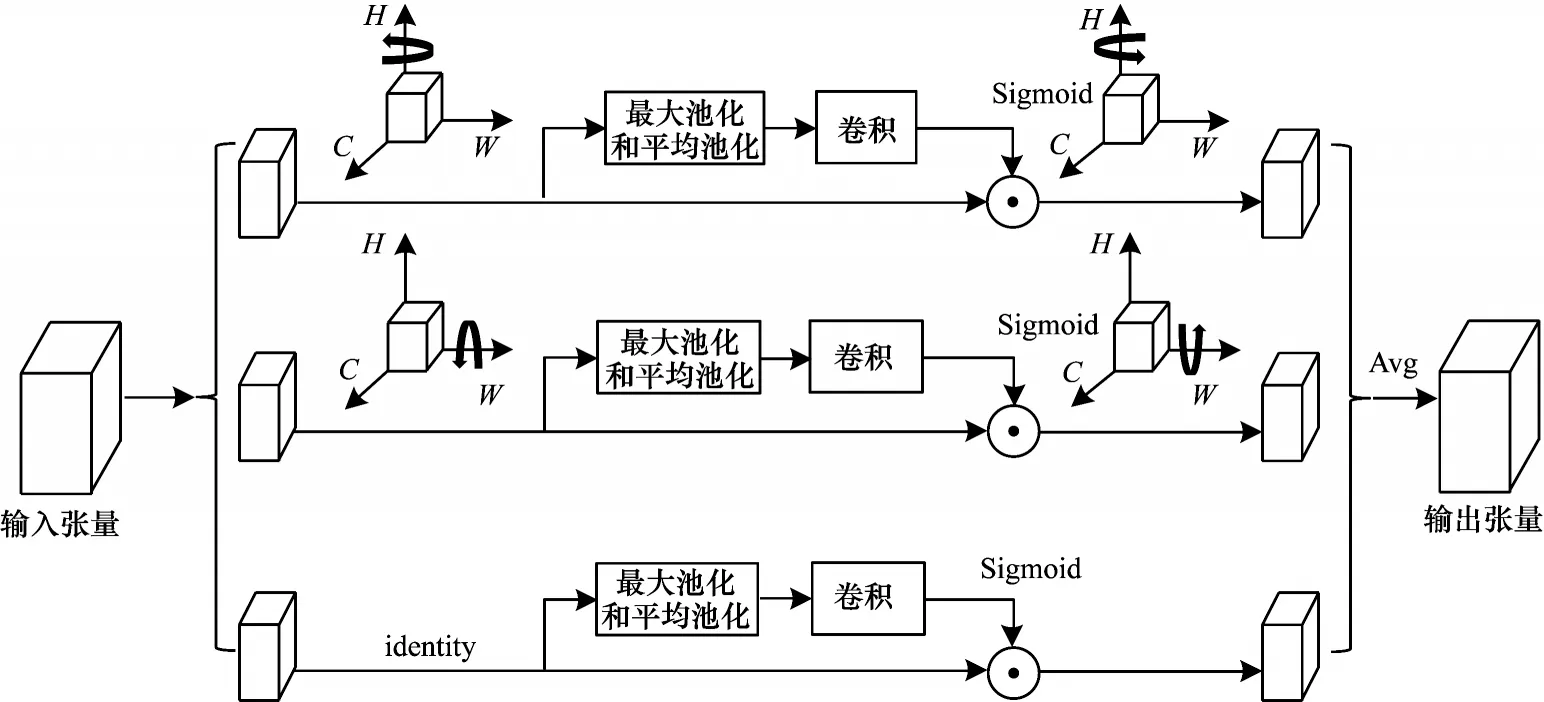
图5 三分支注意力机制网络结构Fig.5 Structure of three branch attention mechanism network
三分支注意力机制网络的原理是通过旋转操作和残差变换建立维度间的依存关系,主要包含3 个分支,其中2 个分支分别用于捕获通道C维度和空间维度W/H之间的跨维度交互,剩下的1 个分支捕捉(H,W)维间的依赖关系,通过均衡3 个分支的输出,实现跨维度交互。
传统通道注意力的计算是通过选取高层特征图进行全局池化,将每个通道的二维特征压缩为1 个实数,如式(2)所示:
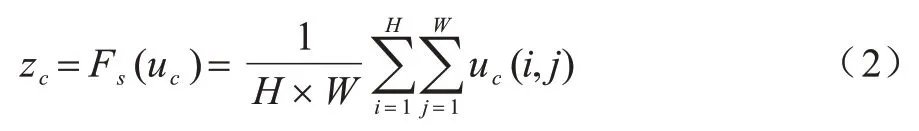
由于zc是根据二维特征的所有值计算得到,因此在某种程度上具有全局的感受野。但该计算方式会丢失大量的空间信息,也无法体现通道维数和空间维数之间的相互依赖性,传统的空间注意力计算同理。虽然基于空间和通道的卷积模块注意力机制(CBAM)可以体现通道与空间之间的相互依赖性,但是通道注意与空间注意是分离的,其计算也是相互独立的。三分支注意力机制的优点主要有以下3 个方面:1)不会丢失大量的空间与通道信息;2)可以进行跨维度交互;3)需要的可学习参数量少,算力消耗小。
本文使用三分支注意力模块对CSPDarkNet53网络进行改进,使网络可以通过自动学习获取跨维度交互,以提高有效的特征通道权重,从而使网络重点关注重要的特征通道。结合三分支注意力模块改进的YOLOv4-TIA 骨干网络结构如图6所示。

图6 YOLOv4-TIA 骨干网络结构Fig.6 Structure of YOLOv4-TIA backbone network
2.3 融合改进PANet 结构的YOLOv4-TIA
通过YOLOv4-TIA 网络中的骨干网络提取输入图片特征后,经过检测颈部网络进行预测输出。YOLOv4 采用PANet 作为颈部网络,其网络结构如图7 所示。该网络采用自上而下和自下而上的路径聚合方式,利用准确的低层定位信号增强整个特征层次,从而缩短低层与顶层特征之间的信息路径。
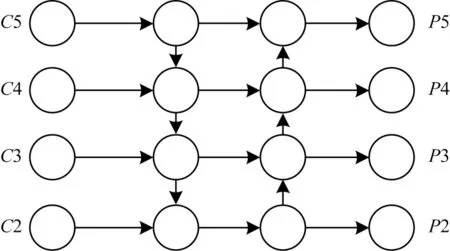
图7 PANet 网络结构Fig.7 Structure of PANet network
图7 中C表示输入特征图,P表示输出特征图。PANet 网络结构虽然可以将高层特征图的强语义信息与低层特征图的定位信息进行双向融合,但是在融合时是将不同层级的特征直接进行相加。为了使网络可以融合更多的特征及学习不同输入特征的权重,本文提出一种改进的PANet 结构,如图8 所示。
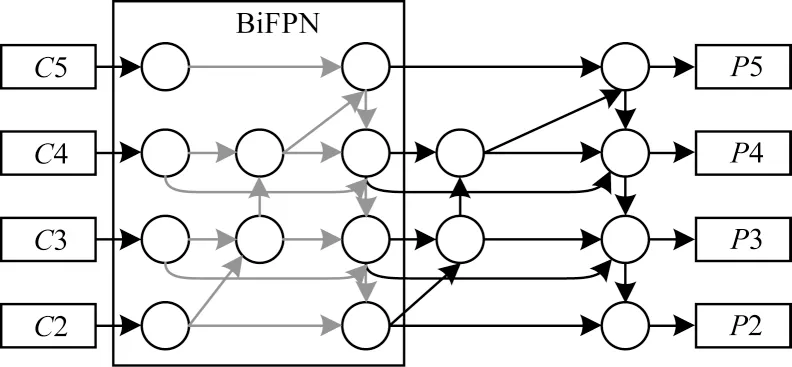
图8 改进的PANet 网络结构Fig.8 Structure of improved PANet network
改进的PANet 网络结构去除了PANet 结构中只有一条输入边和输出边的节点,并且当输入和输出节点是同一层级时,通过残差的方式增加一条额外的边,这样可以在不增加计算开销的同时融合更多的特征[19]。输入图片经过CSPDarkNet53 骨干网络得到各层级的特征图后,通过跨级连接和同级跳跃连接的多尺度特征融合方式获得尺度分别为152、76、38 和19 的4 个层级的特征图,并在此基础上进行预测。
2.4 Focal loss 函数
在林业监测中采集到的昆虫数据存在样本不均衡且不容易分类的问题,为此,在YOLOv4-TIA 中使用Focal loss 函数优化分类损失。Focal loss 函数可以用于解决一阶段模型中背景分类不均衡和正负样本严重失衡的问题[20]。YOLOv4 中的损失函数分为位置损失、置信度损失和类别损失3 个部分,将Sigmoid 与交叉熵损失函数相结合进行计算。在多分类任务中,交叉熵表示激活函数实际输出值与期望输出值的距离,交叉熵越小表示两者的概率分布越近[21],如式(3)所示:

其中:L为交叉熵;C为分类类别数;y为期望输出;y'为经过激活函数的实际输出。改进后Focal loss 计算如式(4)所示:

其中:α取0.25,α因子的作用是平衡样本数量;β取2,β>0 的作用是减少易分类目标。
3 实验与结果分析
3.1 数据集与数据预处理
本文实验所使用的数据集(北京林业大学昆虫)共有2 183 幅图像,其中1 693 幅作为训练集,245 幅作为验证集,其他245 幅作为测试集。数据集共有Boerner、Leconte、Linnaeus、acuminatus、armandi、coleoptera和linnaeus7 类昆虫目标。在使用模型对数据集进行训练前先对训练集中每类目标样本数量进行统计,以均衡检测样本分布,统计结果如表1 所示。
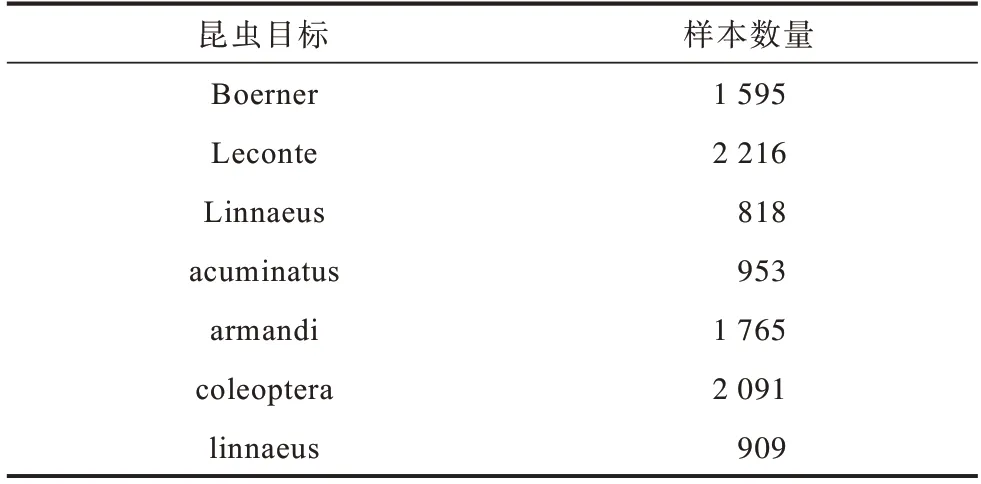
表1 在训练集中每类目标样本的统计结果Table 1 Statistical results of each target sample in the training set
从表1可以看出,Linnaeus、acuminatus和linnaeus3类目标的样本数较少。为了使每类样本数量分布更均衡,本文对包含这3 类目标的图片进行数据增强操作。每幅图片包含多类目标,因图像旋转、色调变换等常见数据增强方式会导致其他样本数目增加,因此增强后的整体样本数据分布仍不均匀。
本文采用的增强方式是将数目较少的类别目标区域进行复制,经过放大、旋转、平移等方式粘贴回原图,以达到精准类别增强。本文以Linnaeus 目标为例进行数据增强,增强前后的效果对比如图9所示。

图9 精准数据增强前后的效果Fig.9 Effect of data before and after accurate enhancement
本文对数据集进行预处理后,每类目标样本数目如表2 所示。
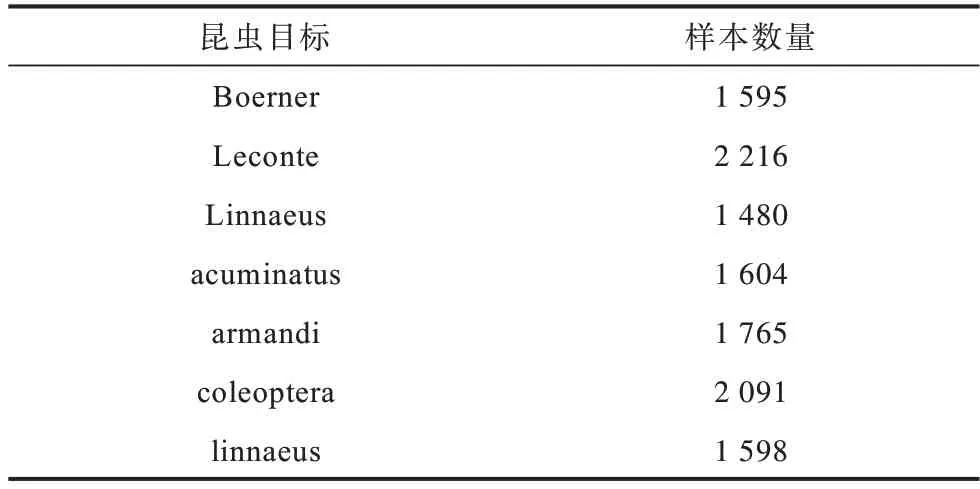
表2 数据增强后每类目标样本的统计结果Table 2 Statistical results of each target sample after data enhancement
3.2 训练结果对比分析
本文使用调整后的数据集作为训练集,分别对改进前后的模型进行训练。本文实验的操作系统为windows10,CPU 为E5-2630L v3,内存16 GB,GPU为1080 Ti,显存11 GB。训练时batchsize 设置为16,学习率为0.001,优化器为Adam,根据训练日志绘制出模型损失函数值的变化曲线如图10 所示。从图10 可以看出,当YOLOv4 训练进行到约9 000 次时,整体曲线趋于平稳并无明显震荡,模型收敛。改进后YOLOv4-TIA 模型的最终损失函数值明显低于原模型,损失函数最低值仅为0.12。
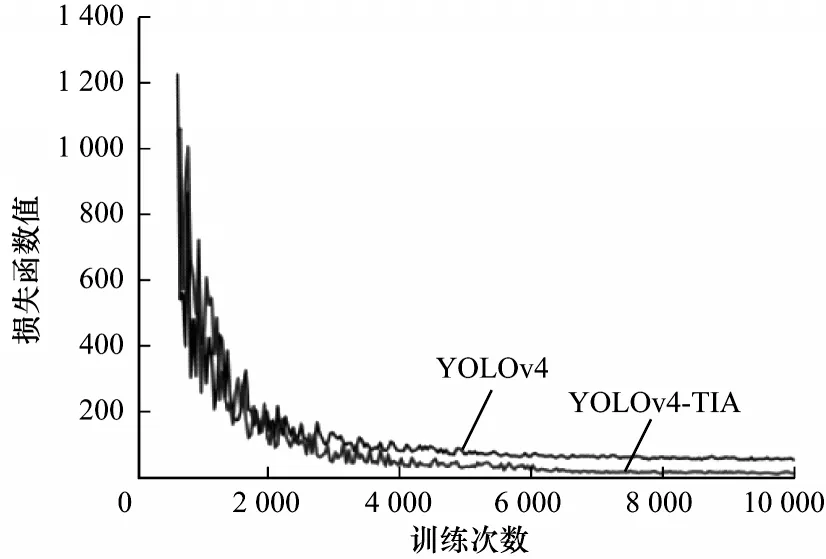
图10 改进前后模型的训练结果Fig.10 Training results of models before and after improvement
在完成模型训练后,本文将YOLOv4、VGG16、Faster R-CNN 作为对比模型,在测试集上采用以下评定指标分别对4 个模型进行综合性能对比,结果如表3 所示。
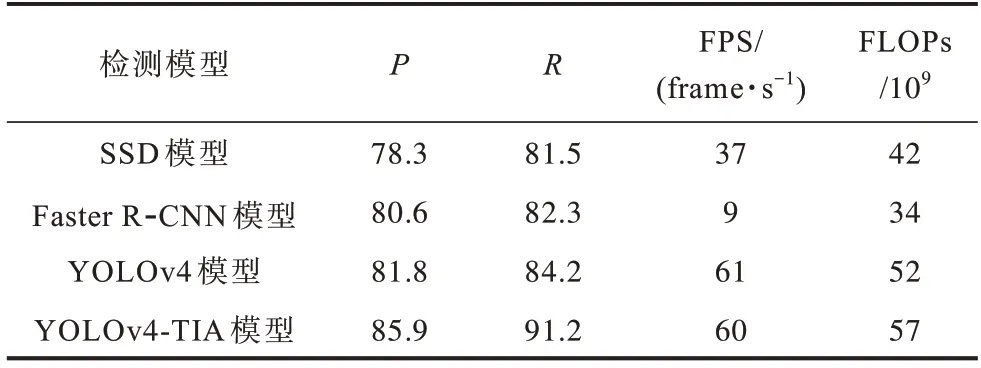
表3 不同检测模型进行林业害虫检测的综合性能对比Table 3 Comprehensive performances comparison among different detection models for forestry pests detection
1)精确率(P),通过计算正确检测目标数量与整体检测到的目标数量的比例,以衡量模型的分类能力。
2)召回率(R),通过计算正确检测目标数与验证集目标总数的比例,衡量模型的查全能力。
3)面积交并比(IoU),通过计算模型预测目标的矩形区域与验证集中目标标定的矩形区域的面积交并比,衡量模型的位置预测能力。
从表3 可以看出,改进的YOLOv4-TIA 模型检测速度与YOLOv4 相差不大,比SSD 快1.6 倍,比Faster R-CNN 快6.7 倍。相比SSD、Faster R-CNN 和YOLOv4方法,改进的YOLOv4-TIA的准确率更高,且在比Faster R-CNN 模型检测速度加快了6 倍的情况下,准确率仍提高了6.5%。因此,YOLOv4-TIA 通过捕捉跨维度交互增强了网络特征表达能力,利用高效的多尺度连接方式与Focal loss函数,进一步提高模型的检测精确率,能够检测到更小的目标,YOLOv4-TIA 的召回率相比于YOLOv4 提升了8.3%。
根据精确率和召回率,本文对每类目标的平均精准度(Average Precision,AP)和模型整体的mAP(mean Average Precision)进行计算对比,结果如表4 所示。优化后YOLOv4-TIA 模型的整体mAP 相比于YOLOv4提升了5.6%,结合表3 的对比数据,优化后模型的鲁棒性较优。YOLOv4-TIA 与YOLOv4 模型的mAP 值分别为85.7%和80.7%。YOLOv4-TIA 与YOLOv4 模型的FLOPs 分别为57×109和52×109。本文对每类目标的的AP 值进行分析,由于YOLOv4 样本数量分布不均导致AP 值差异较大,而YOLOv4-TIA 模型经过数据增强后每类AP 值较均衡,且无明显波动。
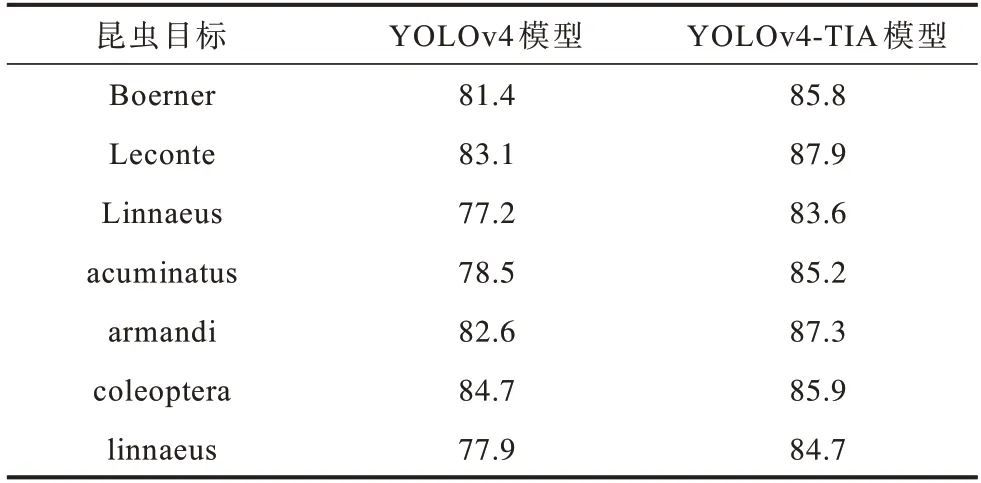
表4 YOLOv4-TIA 与YOLOv4 模型的AP 对比Table 4 AP comparison of YOLOv4-TIA and YOLOv4 models %
在测试集上YOLOv4 模型和YOLOv4-TIA 模型的昆虫图像实际检测效果对比如图11 和图12 所示。从图中可以看出,所有昆虫对象检测结果用矩形框标示,在直接使用YOLOv4 模型进行检测时,存在一些昆虫对象漏检的情况,然而使用YOLOv4-TIA 模型均无漏检情况。
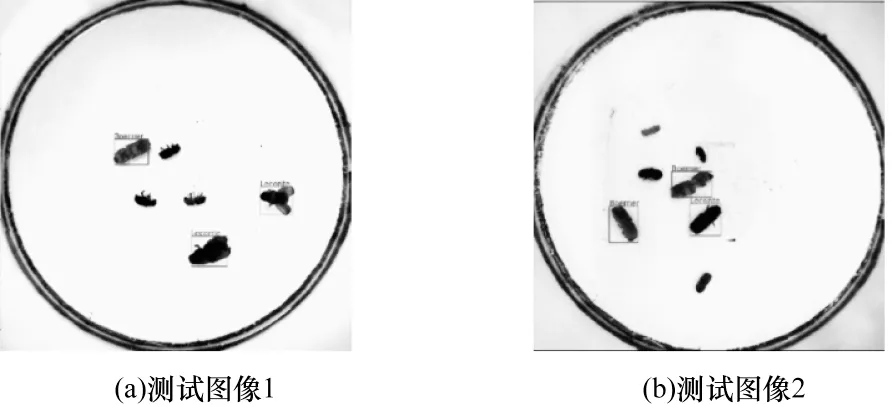
图11 YOLOv4 模型检测结果Fig.11 Detection results of YOLOv4 model
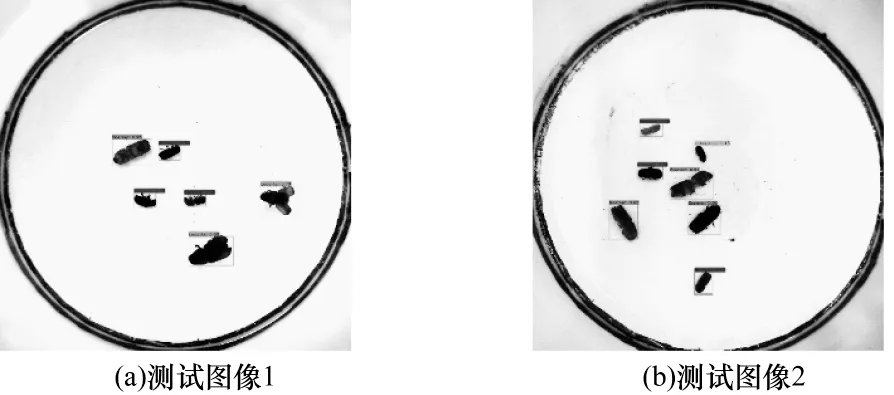
图12 YOLOv4-TIA 模型检测结果Fig.12 Detection results of YOLOv4-TIA model
因此,YOLOv4-TIA 的目标检测精确率和召回率都要高于YOLOv4,其小目标的检测能力也更优。
4 结束语
本文提出基于YOLOv4-TIA 的林业害虫目标检测方法,通过对数据集进行精准数据增强,利用三分支注意力机制对CSPDarkNet53 网络进行改进,并将其与优化的PANet 网络相结合,获取更丰富的语义信息和位置信息,实现对诱捕器镜头下林业害虫的监测。实验结果表明,YOLOv4-TIA 方法的精确率和召回率分别达到85.9%和91.2%,相比SSD、Faster R-CNN、YOLOv4方法,在保证实时性的前提下,能够有效提高检测精度。
猜你喜欢
玩具世界(2022年3期)2022-09-20
西安邮电大学学报(2020年1期)2020-12-17
甘肃教育(2020年2期)2020-09-11
铁道通信信号(2019年6期)2019-10-08
计算机系统应用(2019年9期)2019-09-24
小学生必读(低年级版)(2018年11期)2018-03-13
雷达学报(2017年6期)2017-03-26
军事运筹与系统工程(2016年4期)2016-07-10
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
