
面向图像篡改取证的多特征融合U 形深度网络
2022-04-18 10:56路东生张玉金党良慧
计算机工程 2022年4期
路东生,张玉金,党良慧
(上海工程技术大学电子电气工程学院,上海 201620)
0 概述
智能设备与社交软件的升级迭代,促进了数字图像的应用与发展,主流的图像处理软件如Photoshop、Gimp、美图秀秀等,具有强大的图像编辑功能,让图像篡改操作变得更加便利。数字图像篡改可广泛地分为内容保留与内容改变两类,内容保留包括JPEG 压缩[1]、滤波操作[2]、对比度增强等,对图像具有较低的破坏性,并未改变语义信息;内容改变具体分为拼接[3-4]、复制-粘贴[5-6]、移除[7],这些操作将修改图片内容并导致语义信息改变。复制-粘贴操作在同一张图片中进行,即复制图片中的局部区域并粘贴在同一图片的另一个区域从而形成伪造图片[8-9],拼接篡改是把来自2 张或多张图片中不同的局部区域进行拼接以形成伪造图片,移除篡改是依据图片中的背景区域填补同一图片中被移除的区域。一般来说,改变内容的篡改操作是通过隐藏物体或增加物体数量达到信息误导的目,并结合图像模糊、缩放、扭曲等处理操作使篡改图像检测及定位研究更具挑战性,伪造图像经过专业图像篡改者的加工可以不留下任何视觉线索。
目前,有很多研究工作仅对待检测图像进行分类,即一幅图像是否被篡改,只有少数研究工作尝试进行图像块[10-11]的分类或像素级[12-13]篡改区域定位。相较于图像篡改检测,图像篡改区域的定位同样不可忽视,篡改区域定位能够进一步甄别伪造者的意图,在司法鉴定和法医领域发挥重要作用。此外,多数图像篡改取证方法仅仅关注某一特定的篡改类型,如复制-粘贴、拼接、移除等,但针对单一篡改类型的图像取证方法可能不适用于另一种图像篡改类型,例如由于拼接操作类型来源不同源的图像会引入不同的光电响应、噪声等固有特征,而复制-粘贴操作类型的篡改检测方法不能利用固有特征差异,因此无法对该类型图像进行检测。现实生活中的伪造图像复杂多样,这就要求图像篡改取证研究者的工作不能局限于特定的篡改操作类型。
本文提出一种面向图像篡改取证的多特征融合U 形深度网络,以实现端到端的篡改图像检测与定位。利用CNN 网络和SRM 卷积层提取篡改信息,并将其输入到基于编解码网络和多特征融合的特征提取模块,以实现篡改特征提取。在融合定位模块中利用分级监督策略,结合不同分辨率提取的篡改特征,完成对篡改区域的预测。
1 相关工作
在图像篡改取证研究中,通常根据真实图像与篡改图像间不同特性进行图像检测和篡改区域定位,这些特征包括JPEG 压缩效应[1]、边缘不一致[14-15]、噪声模式[16]、色彩一致性、视觉相似度[8-9]、EXIF 一致性[3]、相机模型等特性。
待检测图像若曾被复制粘贴,图像中必然存在局部相似的区域,基于此假设,一般的研究方法[7-8]将待检测图像分为非重叠区域和重叠区域,并利用相似性或相关性进行度量,以确定图像块是否被复制,常用的特征提取方法有局部二值模式(Local Binary Patterns,LBP)、方向梯度直方图(Histogram of Oriented Gradient,HOG)、尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)及其改进的算法。文献[5]通过分割待检测图像,对比各个语义独立补丁的仿射变换矩阵以确定匹配点,并进一步匹配确定相似的补丁。文献[17]所提图像块匹配算法能有效用于计算图像上的近似最近邻域,并使用不变特征来匹配相似图像块,例如圆谐波转换,展现了该应用经过几何变换图像块的鲁棒性。在深度学习出现前,研究主要关注判定图像及图像块是否被篡改,由于深度学习在目标检测、语言分割方面取得了优异表现,复制-粘贴取证也有较大进展。文献[7]定义了两分支的神经网络框架,并分别用于提取篡改区域留下的视觉痕迹、区分篡改区域与背景区域,最终实现像素级的检测定位。文献[8]使用卷积神经网络从图像中提取局部块的特征,计算不同块之间的自相关性,并利用点特征提取器定位匹配点,通过反卷积网络定位篡改区域,对于仿射变换、JPEG 压缩、模糊等各种已知攻击具有较强的鲁棒性。
若伪造图像经过拼接操作,则拼接区域将引入不同于背景区域的固有特征,例如噪声不连续、篡改区域边缘和色彩不一致等线索。MAHDIAN 等[18]利用小波变换原理估计图像块的噪声水平,并设定阈值不断融合领域图像块,根据噪声的局部不一致性进行篡改区域定位。PAN 等[19]利用带通滤波器下的峰值浓度与噪声水平的关系检测篡改区域,该方法首先计算每个局部窗口的噪声,接着对这些噪声值进行K-means 聚类,最终确定拼接区域。当拼接区域和原始图像内在噪声方差的差异较小时,该方法的检测结果不理想。ZENG 等[20]基于主成分分析(Principal Component Analysis,PCA)方法估算每个图像块的协方差矩阵的最小特征值,通过估计较大图像块的噪声水平确定图像块是否为可疑图像块,将较大的图像块继续分割为较小图形块,并再次进行噪声水平估计,该方法能较有效地定位拼接区域。
文献[21]把待检测图像分为水平和垂直的条带,根据局部区域光源颜色的不一致性实现图像块级的拼接区域定位,因深度学习具有高纬数据的特征多级表征学习能力,基于卷积神经网络的方法应运而生。文献[14]使用卷积神经网络提取篡改区域边缘的显著性差异,同时预测篡改区域及其边缘,最终结合几何限制定位篡改区域。文献[4]设计深度稠密匹配层来寻找2 个给定图像特征的潜在拼接区域,并设计了视觉一致性验证模块,该模块通过交叉验证潜在拼接区域上的图像内容来确定检测。文献[3]使用自动记录的照片EXIF 元数据作为训练模型的监督信号,以确定图像是否具有自一致性,将自我一致性模型应用于伪造图像的检测和定位。
文献[9]和文献[22]提出基于修复的图像移除取证方法,可以实现无明显痕迹的物体去除[22]。文献[23]提出一种集成的图像移除篡改检测方法,利用中心像素映射加速相似图像对的搜索,减少处理时间的同时维持了较高的精度,然而针对压缩、低通滤波、模糊等攻击伪造图像效果不理想。文献[9]采用2 种强化监督策略以引导卷积神经网络(Convolutional Neural Networks,CNN)自动学习修补特征而非图像内容特征,该方法采用编码器-解码器网络结构,以实现在不考虑特征提取的情况下自动检测、去除篡改区域。
文献[24-26]提出针对复合篡改类型的深度学习方法用于篡改取证,文献[12]在生成特征图上使用长短期记忆(Long Short-Term Memory,LSTM)网络建立相邻像素之间的相关性,结合卷积神经网络结构获取篡改区域与背景区域的边界不连续特点,实现端到端的像素级定位。若篡改区域边缘未留下明显痕迹,则篡改性能下降。文献[24]利用LSTM网络捕获篡改引起的重采样特征,同时使用编解码网络结构捕获篡改痕迹,融合特征完成篡改区域的定位。文献[25]在文献[24]基础上充分考虑浅层特征图对篡改定位的影响,采用跳跃连接以避免边缘、纹理等线索的丢失,进一步提升篡改定位精度。文献[26]提出两阶段的篡改方法,先通过复制粘贴检测器判断图像是否经过克隆和移除篡改操作,再结合基于深度学习的重采样检测器判断是否经过拼接和重采样篡改操作,在一定程度上提高了检测性能。
2 本文方法
本文提出面向图像篡改取证的多特征融合U 形深度网络(Multi-Feature Fusion U-Structure deep network for image forgeries detection,MFF-US net)用于图像篡改检测和定位,如图1 所示(彩色效果见《计算机工程》官网HTML 版),该网络包含信息融合、特征提取、区域定位3 个模块,相较于现有使用图像分类的预训练模型深度学习方法,MFF-US net 是从0 开始训练的高效深度学习网络,能够避免过量的参数增加计算量。
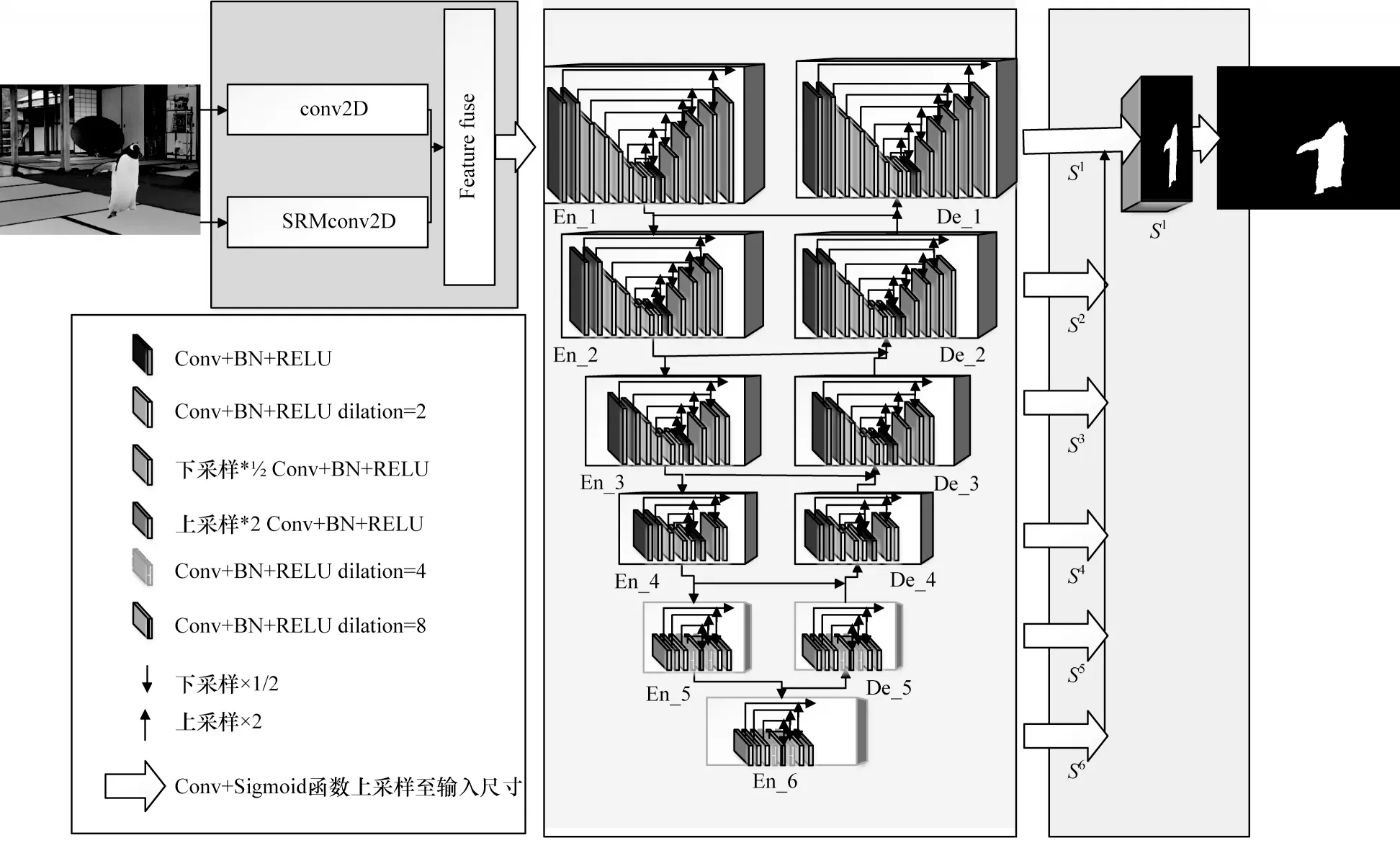
图1 MFF-US net 的框架Fig.1 Framework of MFF-US net
在篡改图像颜色空间,对篡改区域边缘和对比度差异等语义特征建模并不能充分利用篡改区域遗留的噪声痕迹。因此,在信息融合模块中加入富隐写模型卷积层自动提取噪声特征,通过联结操作最大程度地保留篡改线索,并在特征提取模块中利用编码-解码网络多尺度地提取上下文信息。在区域定位模块中,为了避免篡改特征表征的损失,将提取的融合特征分级进行监督并逐层实现特征融合,实现篡改区域检测和高置信度的像素级分类。
本文的贡献主要有以下3 个方面:
1)提出一种并不依赖预训练模型的图像篡改取证方法,更加关注篡改区域与真实区域间的特征建模,并在多个公共数据集上取得较优性能。
2)利用SRM 模型提取噪声分布特征并融合RGB 视觉线索,实现像素级的检测与定位。
3)篡改区域和真实区域存在样本标签不平衡的情况,常篡改区域的像素数量远小于真实的背景区域,因此引入损失函数缓解样本不平衡问题。
3 具体方案
图像篡改取证与目标检测任务相比,后者关注于物体的检测,前者更强调篡改区域遗留的痕迹且要求深度学习网络需要学习更丰富的特征。因此,本文在融合RGB 信息和噪声信息的基础上,引入U 型残差块[27]构造可堆叠U 型结构的MFF-US net,以捕捉更多上下文信息。该网络不同于Hourgalss network、Docu-Net、CU-Net 等网络[27],其网络的堆叠不会引起计算参数和消耗量被成倍放大,满足高效提取多尺度伪造特征的篡改取证网络。
3.1 信息融合模块
图像作为网络的输入,不需要额外进行预处理操作。在信息融合阶段通过对输入图像进行双分支处理,SRM 卷积层和2D 卷积层经过卷积处理分别生成相同维度的特征,通过联结所获取的特征作为特征提取模块的输入信息。
3.1.1 RGB 信息
复制-粘贴、拼接、移除等图像篡改操作普遍会留下视觉痕迹,在篡改区域形成的过程中,容易造成篡改区域边缘不自然和纹理不连续的现象,如图2(b)所示,篡改区域边缘相较于自然物体边缘更模糊,自然物体边缘视觉上过渡更加自然。

图2 篡改痕迹示例Fig.2 Examples of tamper marks
卷积神经网络具有局部感知和参数共享的特点,在目标检测、物体分类等领域表现出较大的潜力,同样能够提取篡改遗留的视觉痕迹。专业的图像篡改者为了使篡改区域与背景区域相似及避免篡改图像上语义信息的不合理性,常使用后处理操作,如旋转、缩放、扭曲、模糊及其组合篡改等操作。从语义信息考虑蒲公英花的拼接、广告牌信息的擦除、赛车数量的增加等符合自然事物的存在,篡改区域边缘的篡改痕迹经过模糊等后处理操作,很难被人察觉,尤其是图2 第2 行的移除篡改类型,篡改区域为融合背景区域的领域信息,在纹理、对比度等方面无明显差异。经过精心的后处理操作能够使篡改边缘和对比度差异减弱,RGB 图像遗留的篡改痕迹并不明显,其采用了噪声特征分支信息来弥补颜色信息空间的不足,因此本文引入局部噪声信息。
3.1.2 噪声信息
相较于RGB 图像信息较多关注图像内容提取的低级、高级特征,噪声信息更加注重局部噪声的分布规律。经过篡改的图像必然导致噪声分布不均,图像上的噪声信息作为篡改痕迹的补充,在一定程度上能够解决视觉差异不明显的问题,通过对比噪声估计方法,更好地体现局部噪声特征[28]。采用图3 所示的SRM 卷积核,图像经过SRM卷积后生成噪声图像,如图2第3列所示。显然,噪声图像强调局部噪声而非图像内容,并能够显示RGB 通道中不可见的篡改痕迹,通过相邻元素间的残差建模,形成噪声图表示元素间的共存关系。实验室设置中,2D 卷积层的卷积核维度和SRM 卷积层相同,维度为5×5×3,并保证得到相同维度的输出。
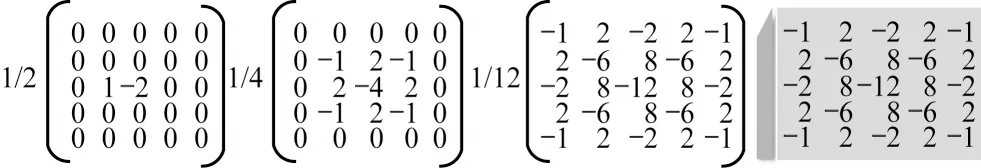
图3 SRM 卷积核Fig.3 SRM convolution kernel
3.2 特征提取模块
由于现实生活中伪造图像的篡改区域存在大小和形状多样性,因此要求深度学习网络必须具有多尺度特征学习能力,较为常见的处理方法为高频使用1×1、3×3较小卷积核提取特征,以便占用较小的储存空间,以及避免在减少计算量的同时在特征提取阶段只能提取局部特征信息的情况发生。VGG、ResNet、DenseNet[27]等网络并不能满足篡改检测任务对全局信息和局部信息高效提取的要求,他们为提取高分辨率特征图的全局上下文信息,通常使用inception 网络,在网络框架的浅层阶段使用空洞卷积增加接受野,但这将导致计算和内存资源消耗增加。为减少计算资源占用,PoolNet在下采样阶段使用较小卷积核代替空洞卷积。由于在多尺度特征融合阶段,上采样和连接操作会导致高分辨率特征信息的损失,因此引入残差U-blocks 块作为信息提取的结构。
残差块和残差U 型块的结构如图4 所示。残差U-blocks 能够获取多尺度块内特征,其结构为RSUL(Cin,M,Cout),如图4(c)所示。
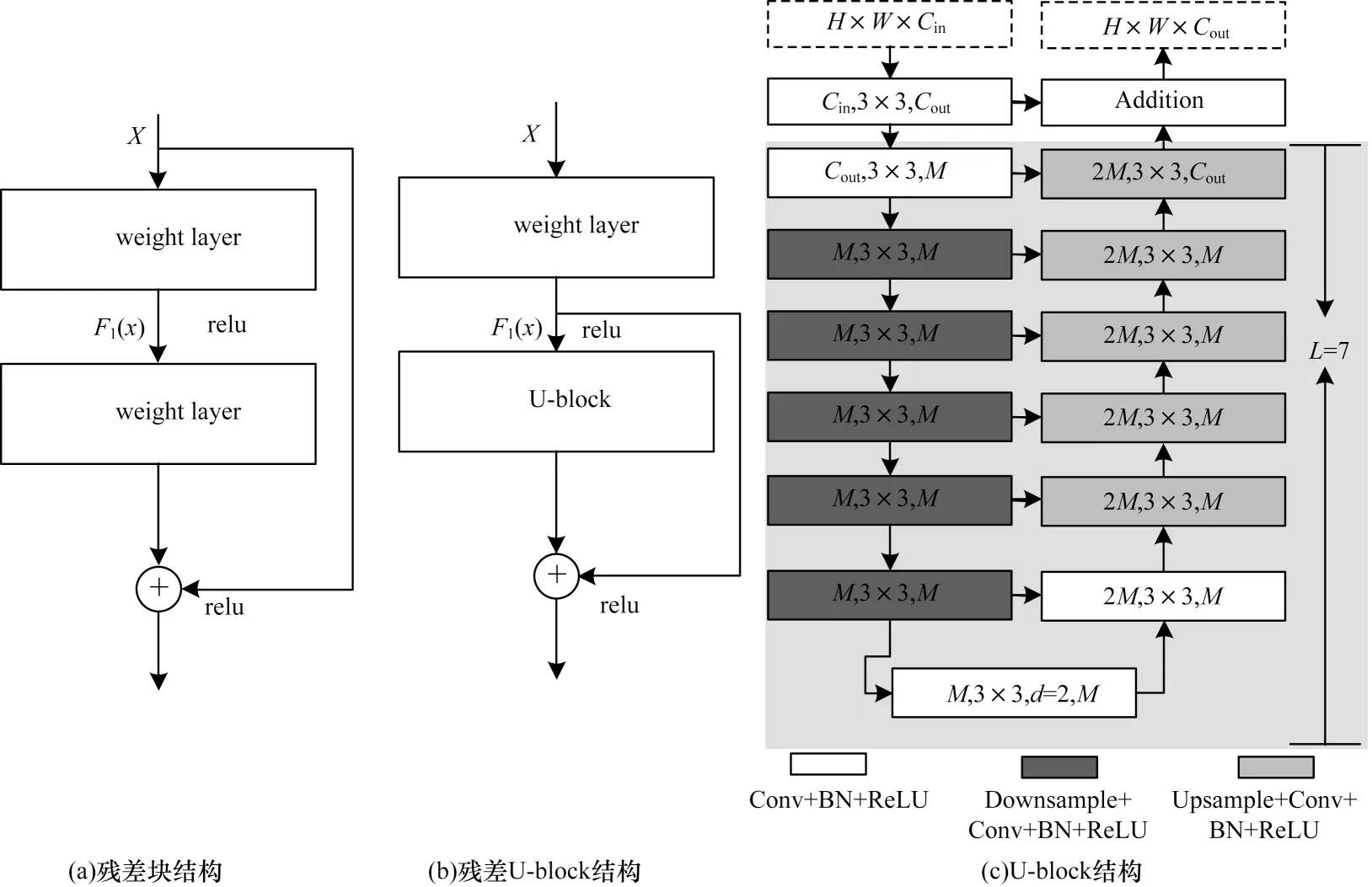
图4 残差块和残差U 型块的结构Fig.4 Structure of the residual block and RSU
在图4(c)中:L代表编码阶段层数;Cin、Cout分别代表输入、输出特征通道;M为RSU 内中间层通道数,主要由3 个部分组成:
1)普通卷积层,用于提取局部特征信息,将输入特征图x(H×w×Cin)转换为中间映射F1(x)。
2)高度为L的对称U 型结构的编码-解码结构,能够提取并编码多尺度上下文信息u(F1(x)),L越大,代表更多的池化操作、更广范围的感受野、更多的局部和全局特征信息。编码-解码结构逐步在下采样的特征图中提取多尺度特征,并通过逐步上采样、拼接和卷积操作编码成高分辨率特征图,这一过程能够减少大尺度特征直接上采样造成的细节损失。
3)残差连接结构,用于融合局部特征和多尺度特征u(F1(x))+F1(x)。
为更清晰地阐述残差U-blocks 和原始残差块的差异,原始残差块被定义为:H(x)=F2(F1(x))+x,其中:H(x)为输入特征x的映射结果;F2和F1分别表示权重层的卷积操作。残差U-blocks 最大的差异在于使用U型结构代替卷积结构,其定义为:HRSU(x)=u(F1(x))+F1(x),其中:u代表多尺度的U 型框架,由于U 型框架较小,在提取多尺度特征的过程中不会消耗明显的计算力。
编码-解码结构是对称结构,能有效提取各分辨率特征图的多尺度信息,避免有效信息的损失。编码阶段如图1 所示,共6 个块,其中En-1、En-2、En-3、En-4 分别为不同L的残差U-block 块,相对应的L为7、6、5、4,L取决于输入图像特征图的分辨率大小。对于En-5、En-6 块,此时的特征图尺寸较小,进一步的下采样和池化会导致有效信息的丢失。采用空洞卷积代替下采样或者池化操作,此时输入与输出的维度相同。解码结构与编码结构相似,并使用相对应的上采样和拼接操作,能够逐步恢复特征图的分辨率,有效避免特征信息的损失。解码阶段分为5 个块,其中,De-1、De-2、De-3、De-4 对应 编码阶段 的残差U-block 块,De-5 与En-5 结构相似。
3.3 区域定位模块
篡改定位融合模块用于生成篡改区域概率图。首先,分别在En-6、De-5、De-4、De-3、De-2 和De-1 中使用一个3×3 的卷积层和一个sigmoid 函数,用于产生篡改区域概率图。其次,将3×3的卷积层卷积输出(logit)篡改区域映射到输入图像的尺寸,并将他们进行拼接操作,最后通过卷积层和sigmoid函数生成最终篡改区域概率图S0。
3.4 损失函数
实验设置中,在训练阶段使用深度监督策略,训练损失被定义为:

其中:(r,c) 为像素坐标;(H,W)分别为图片尺寸高和宽;分别为对应输入图片的Groundtruth 和预测出来的概率图。
然而对于篡改检测而言,篡改区域面积与背景区域存在较大差异,易造成不同类间的不均衡。
在式(2)的基础上,增加参数β以控制类别不平衡,定义新的损失函数Lt如式(3)所示:
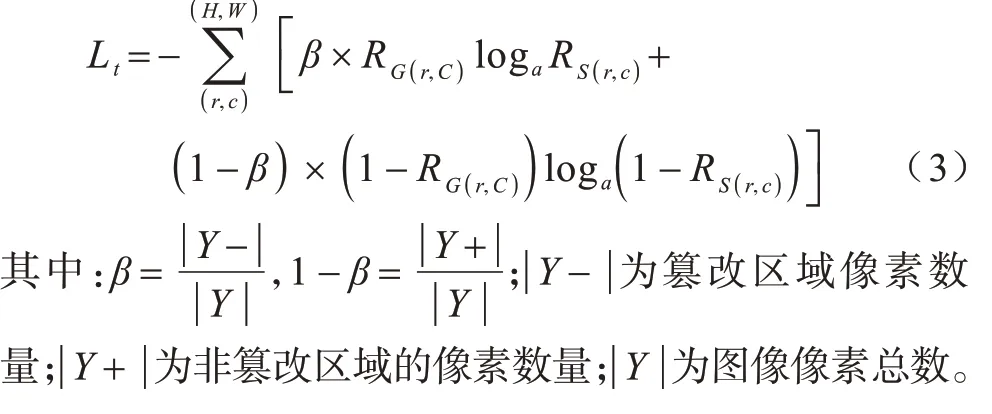
4 实验
本节将验证本文方法在4 个标准公共数据集上的篡改效果,包含NIST Nimble 2016[29](NIST16)、CASIA[30]、COVER[15]以 及Columbia dataset[31]数 据集,通过F1、AUC、ROC 曲线、定位结果等多方面分析模型的泛化能力,同时采用缩放、JPEG 压缩等后处理操作实验,分析模型的鲁棒性。
4.1 数据准备
在实验过程中,使用NIST Nimble 2016、CASIA、COVER、Columbia dataset 和文献[24]的synthesized 数据集共同作为本文实验的训练集。
1)NIST16 数据集。应用于竞赛中,包含3 种篡改类型,分别为拼接、复制-粘贴和移除,篡改的数字图像经过后处理操作难以通过视觉痕迹观察到,此数据集中的图片具有不同的背景、光照条件和物体,并提供了篡改图像相对应的Ground-truth 图像。
2)CASIA 数据集。其包含大量物体的复制粘贴和拼接图像,篡改区域经过精心选择、滤波模糊等后处理操作。该数据集提供了相对应的Ground-truth图像,本文使用CASIA 2.0 进行训练,在CASIA 1.0中进行测试性能。
3)COVER 数据集。专注于复制粘贴的小型数据集,通过缩放、旋转、扭曲、改变光照等手段产生相似的物体形成篡改图像,并利用多种指标衡量篡改图像的相似度,该数据集也提供篡改图像相对应的mask数据。
4)Columbia 数据集。含有拼接图像与真实图像共363 幅,其中183 幅来自不同数码相机拍摄的真实图像,180 幅为拼接而成的图像,图像格式为TIFF 格式,尺寸大小范围为757×568 像素~1 152×768 像素,这些图像主要在室内拍摄而成,场景包含走廊、办公桌、人物、盆栽植物等。
本着公平原则,训练数据集的图像数量划分如表1所示。为加强模型的泛化能力,对输入图像进行缩放、随机垂直翻转、裁剪为280×280 等操作以避免过拟合现象的出现,图像缩放使用的是双线性插值方法。

表1 不同数据集中训练集和测试集的图像数量划分Table 1 Image quantity division of training set and test set in different data sets
4.2 实验参数
在训练模型过程中,采用Pytorch 定义深度网络框架,使用单张GPU,利用NVIDIA TITAN RTX GPU 在不同设置条件下进行实验,使用Adam 优化算法,初始化学习率为0.001,betas=(0.9,0.999),eps=1×10-8,weight decay=0,通过batch-size 为183 000 个epoch 迭代训练模型。
4.3 实验分析
为定量评价本文方法的有效性,采用F1 分数和接收器操作特性曲线(Receiver Operating Characteristic,ROC)作为对比性能的评价标准,F1 得分表示对于篡改检测像素水平的评估标准,利用不同的阈值及最高F1 得分作为每张图片最终得分,其定义如式(4)所示。正确检测率(True Positive Rate,TPR)和错误检测率(False Positive Rate,FPR)的计算公式如式(5)和式(6)所示,其中,FFN表示篡改像素点被误检测为真实像素点的数量,FFP表示真实像素点被误检测为篡改像素点的数量,TTN表示真实像素点被正确检测出的数量,TTP表示篡改像素点被正确检测出的数量。
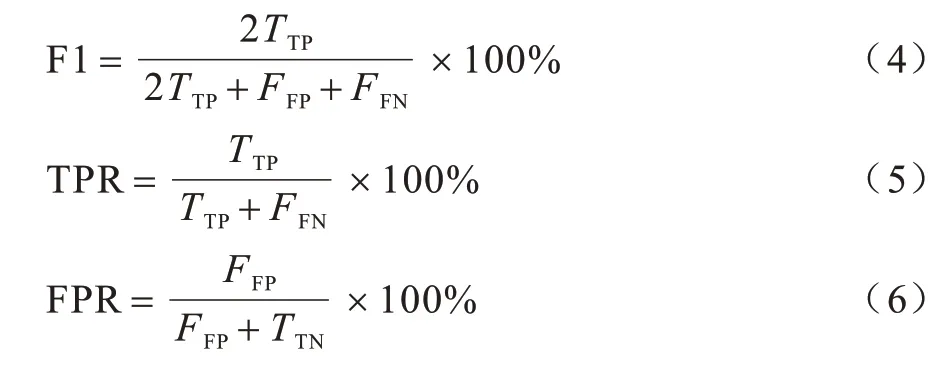
ROC 曲线是描述不同阈值下二分类的预测表现,ROC 曲线的面积表示不同方法下二分类的性能表现,其定义为根据不同的分类阈值,即设置判断像素点为篡改像素点的阈值t,若像素点的分类概率≥阈值t(常取t=0.5),则判定样本为篡改像素点,其中TPR 为纵坐标,FPR 为横坐标。根据TPR 和FPR 的值不同,将他们的值绘制形成曲线,即为ROC 曲线。
4.3.1 与现有方法的对比
现有的图像篡改取证方法分为传统的手工特征提取网络和基于深度学习的篡改网络,本节对比现有方法,采用消融实验验证本文方法的有效性,实验中采用以下方法进行对比。
1)ELA[32]方法,通过查找在不同压缩因子情况下篡改区域与背景区域间的压缩错误差异以定位篡改区域。
2)NOI1 方法,利用高频的小波系数来模拟局部噪声,设定阈值并不断融合领域图像块,依据噪声的局部不连续性进行篡改区域定位[18]。
3)CFA1 方法,假设图像是使用一个彩色滤波器阵列获得的,并且篡改消除了由马赛克算法产生的伪影,通过在局部水平上测量CFA 伪影的存在推理出篡改区域[33]。
4)MFCN 方法,构造全卷积网络实现篡改边缘和初步篡改区域的预测,利用几何知识整合篡改边缘和初步篡改区域并确定最终篡改区域[14]。
5)J-LSTM 方法,联 合LSTM 网络和CNN 网络完成篡改块的判定和像素级的篡改区域分割[12]。
6)RGB-N 方法,通过利用双线性池化融合图像信息和噪声信息实现篡改区域的定位[34]。
7)MANTRA-NET 方法,利用CNN 网络解决篡改痕迹提取和局部异常检测问题,实现篡改区域像素级的定位[35]。
8)Single-RGB 方法,本文所提方法采用单流输入的方式,即只考虑RGB 信息的输入,记为Single-RGB。
9)Single-Noise 方法,Single-RGB,本文所提方法采用单流输入的方式,即只考虑噪声信息的输入,记为Single-Noise。
对比现有方法包括ELA、NOI、CFA1、MFCN、RGBN 和本文方法的F1 指标,结果如表2 所示。其中:对比Single-RGB、Single-Noise 和本文方法可知,具有融合特征的网络优于单流输入的噪声信息和RGB 信息。在NIST16、COVER 和CASIA 数据集上的数据结果可知,Single-RGB方法略优于Single-Nois。然而在Columbia数据 集中,Single-Noise 取 得的F1 值比Single-RGB 方法高2.3 个百分点,原因是Columbia为未压缩的拼接图像,噪声差异较为明显,并未受到后处理操作的影响。

表2 不同方法在不同数据集上的F1 值对比Table 2 Comparison of F1 values of different methods on different data sets
基于深度学习的篡改检测方法要远优于传统特征提取方法,单一特征的篡改取证方法容易导致多数伪造图像的检测任务失败,这是因为ELA、NOI、CFA1 特征提取方法只强调单一的篡改痕迹,且多类型的篡改取证需要更丰富的区分特征。
本文方法在NIST16、Columbia、CASIA 数据集上表现较优,分别高于RGB-N 方法11.9、2.6 和19.7 个百分点。在深度学习方法中,MFCN 方法的表现性能较差,这是因为在特征提取过程中,采用较小尺寸的卷积核和上采样操作容易致使低层特征损失及较小篡改区域检测效果不理想。与RGB-N 方法相比,本文方法采用了RSU 结构和分级监督策略,具有丰富的多尺度特征,在一定程度上能够避免较大篡改区域的边缘与较小篡改区域的细节丢失。由表2 还可知,本文方法在COVER 数据集上的F1 值低于RGB-N 方法1.9 个百分点,这是因为复制粘贴操作产生类似的噪声分布不利于产生区分特征。由此可见本文所提方法的综合性能优于现有方法。
4.3.2 ROC 曲线
本节采用ROC 曲线对比不同方法的性能,包括ELA、NOI、CFA1、J-LSTM、MANTRA-NET 和RGB-N方法,其中ROC 曲线与横轴坐标轴形成的区域面积称为AUC 值,AUC 值越高代表该方法的泛化能力越强。
如表3所示,与基于CNN的深度学习方法相比,ELA方法、NOI方法和CFA1方法因无法实现通用的取证模型表现出较弱的泛化能力,通过对比本文方法、Single-RGB方法和Single-Noise方法在不同数据集上的AUC值高低,验证了本文方法的有效性。其中,J-LSTM方法利用CNN提取浅层特征图并分块输入LSTM 网络中,在一定程度上造成篡改区域的边缘定位不准确,在NIST16和COVER数据集上的AUC值分别为0.764和0.614,泛化能力较弱。本文方法在NIST16、Columbia、CASIA数据集上的AUC值均为最高,分别高于MANTRA-NET方法14.7、8.5和2.8个百分点,且MANTRA-NET方法利用多层CNN 提取特征过程中易造成浅层特征的丢失,如篡改区域的边缘等细节不准确。本文所提方法在NIST16、Columbia、COVER 和CASIA 数据集上的AUC 值分别为0.942、0.909、0.727和0.845,其相对应的ROC曲线为图5所示像素级分割的ROC曲线,由图5可知由于不同数据集分布不同,单一的阈值设置并不能取得最优性能,这进一步说明了本文所提方法具有较强的泛化能力。
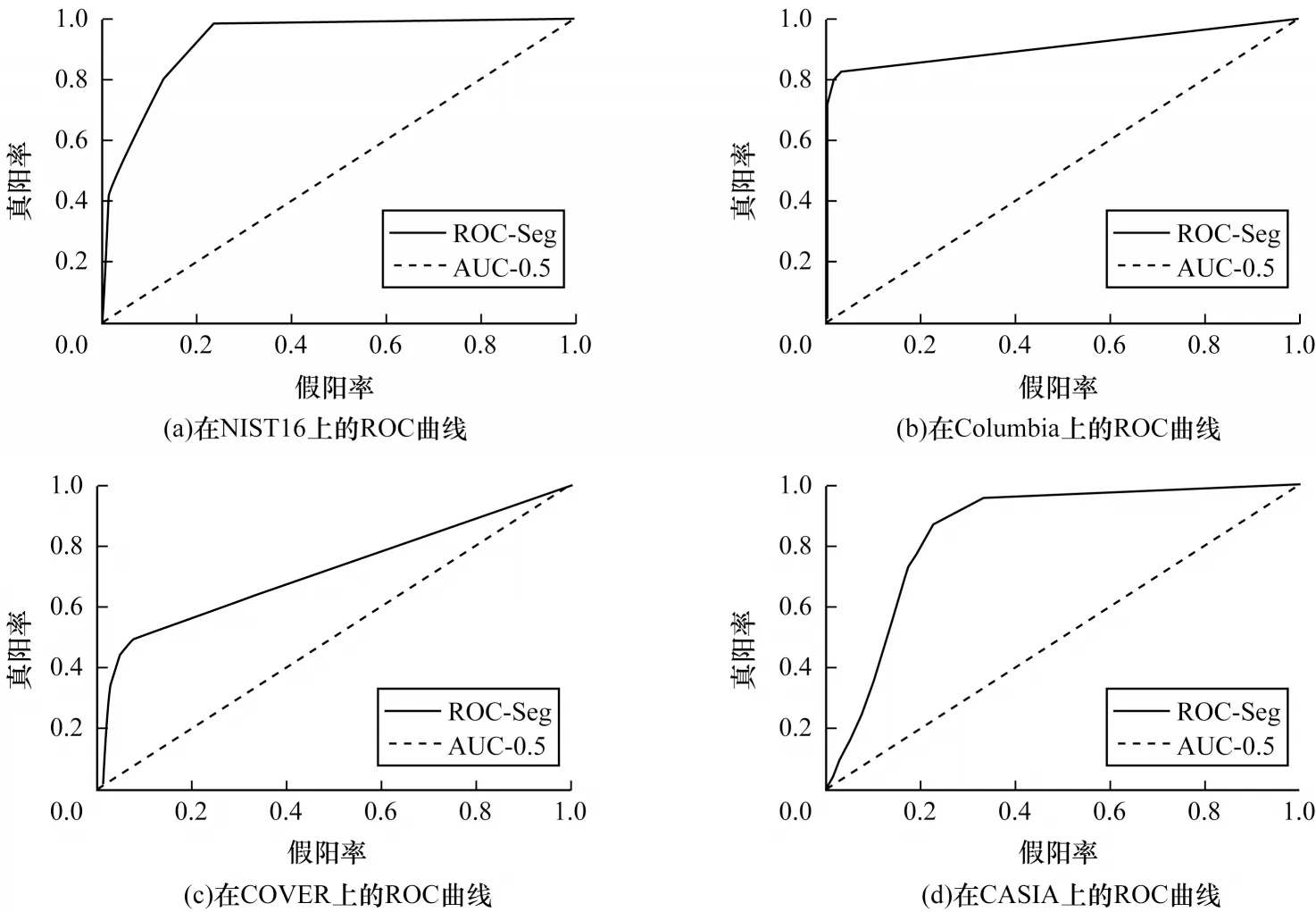
图5 在4 个标准数据集上像素级分类的ROC 曲线Fig.5 ROC curve of pixel-level classification on four standard data sets
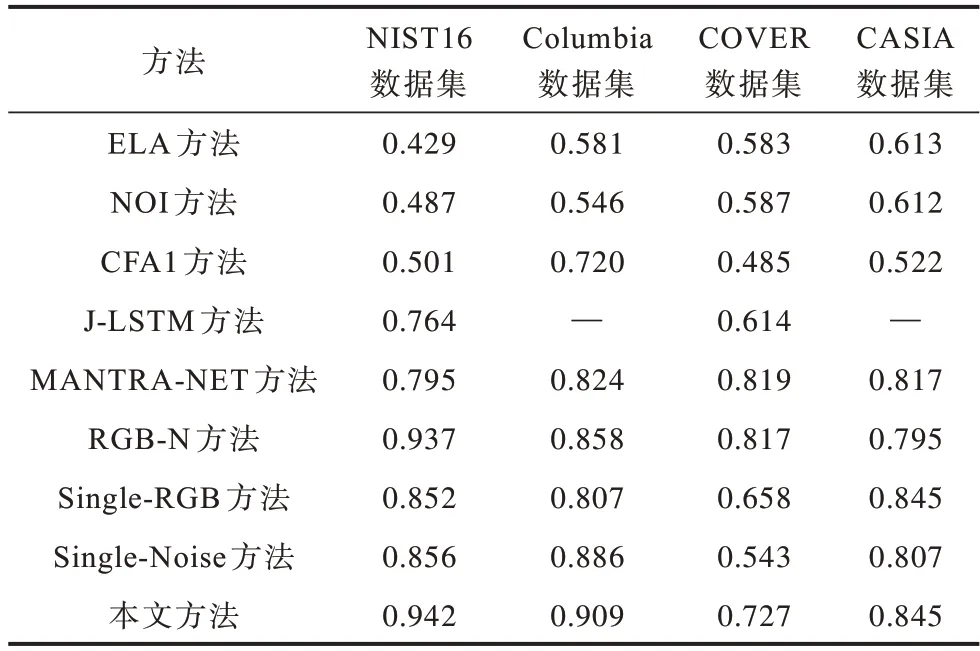
表3 在标准数据集上AUC 值的比较Table 3 Comparison of AUC values on the standard data set
4.3.3 定位结果分析
为进一步验证本文方法的有效性,本节对一些伪造图像进行了篡改检测与定位,图6 所示的是来源于4 个标准数据集中的篡改检测实例,其中包括篡改图像、噪声图像、Ground-truth 图像以及本文方法的检测结果。图6(a)、图6(b)、图6(c)和图6(d)分别来自数据集NIST16、Columbia、COVER 和CASIA,包括拼接、复制-粘贴和移除篡改类型,第1 列为待检测的篡改图像直接输入到网络模型中,无需缩放等预处理操作,第2 列为噪声图像,第3 列为Ground-truth 图像,第4 列为本文方法的输出结果。显然,由于MFF-US 网络具有多尺度高分辨率特征提取能力,篡改区域能够应对任意图像尺寸的篡改检测,并且在较小篡改区域检测和较大篡改区域边缘均取得高置信度的检测结果。从图6(c)和图6(d)中可以发现检测结果存在漏检篡改区域的情况,对于多数篡改图像能够精确地检测并分割篡改区域。

图6 不同数据集的篡改检测结果示例Fig.6 Examples of tamper detection results for different data sets
4.3.4 鲁棒性分析
JPEG 图像压缩及几何变换是常见的拼接图像后处理操作,为进一步评估本文所提方法的鲁棒性,统计NIST16 数据库中的测试集分别经过压缩因子QF=70的JPEG 压缩,QF=50 的JPEG 压缩缩放0.7 和缩放0.5操作后检测的F1 值,结果如表4 所示。由表4 可知,本文方法相较于现有其他方法具有较强的抗缩放和抗JPEG攻击的能力,在压缩因子为70和缩放0.7的情况下,F1值略有降低,分别减少2.3 和2.7 个百分点,在压缩因子为50和缩放0.5的情况下,F1值有明显下降,分别减少10.3和5.4 个百分点,本文方法的F1 值相较于RGB-N 方法分别提高了6.1 和10.6 个百分点。综上所述,本文所提方法具有较强的鲁棒性和泛化能力。
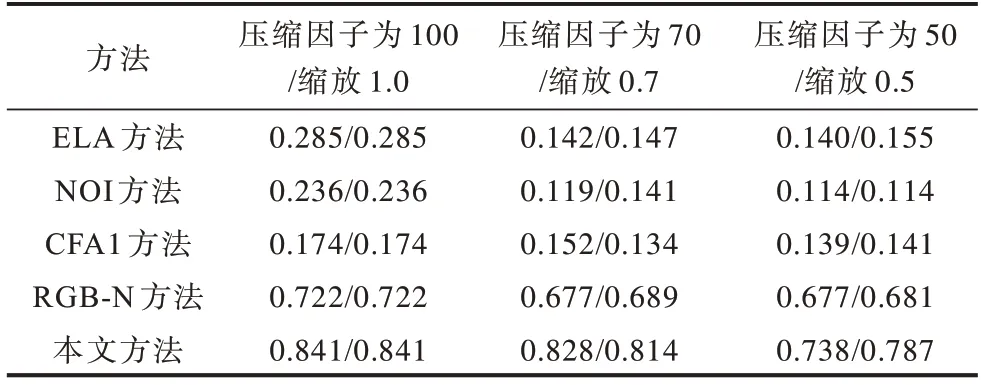
表4 不同方法在NIST16 测试集JPEG 压缩和缩放情况下的F1 值Table 4 F1 value of different methods under JPEG compression and scaling of NIST16 test set
4.3.5 复杂度分析
本节针对现有基于深度学习的方法复杂度进行分析,结果如表5 所示。表5 所示为不同方法模型的参数量和图像的平均推理帧率,用于图像伪造取证的本文方法参数量为168M,仅高于MANTRA-net 参数量,远低于MFCN 和RGB-N 模型参数量,这是因为采用残差U-blocks 结构代替常用的卷积层有助于减少模型空间和时间复杂度。在时间复杂度方面,本文方法的帧率达20 frame/s,高于其他方法,能有效满足现实生活中对于篡改取证实时性和有效性的需求。
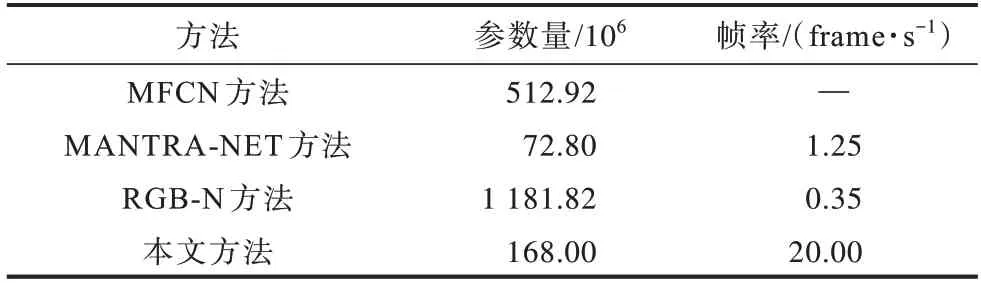
表5 不同方法模型参数量和耗时的对比Table 5 Comparison of model parameters and time-consuming of different methods
5 结束语
本文提出一种用于图像伪造取证的高效U 形深度网络MFF-US net,实现篡改区域的检测与分割。利用CNN 网络和SRM 卷积层构建特征融合模块,以提取并融合RGB 和噪声信息。同时,引入RSU 结构并构造出具有多尺度特征的噪声提取模块,并在融合定位模块利用分级监督策略,以融合不同分辨率提取的篡改特征,实现篡改区域检测与像素级的分割。实验结果表明,基于编解码网络和多特征融合的取证方法能够自动学习篡改特征,且无需考虑特征提取和分类设计。与MFCN、RGB-N、MANTRA-net 等现有方法相比,本文方法在多个标准篡改取证数据集上均取得较优性能,针对缩放、JPEG 压缩等攻击操作具有较强的鲁棒性。下一步将通过生成对抗网络,产生更丰富的篡改数据,加强篡改取证中小目标检测,以应对复杂伪造图像的情况。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
中学生数理化·七年级数学人教版(2022年6期)2022-06-05
北京航空航天大学学报(2021年9期)2021-11-02
导航定位与授时(2020年5期)2020-09-23
铁道通信信号(2020年9期)2020-02-06
电子制作(2019年13期)2020-01-14
中国外汇(2019年20期)2019-11-25
电子制作(2019年11期)2019-07-04
劳动保护(2019年3期)2019-05-16
北京航空航天大学学报(2018年1期)2018-04-20
